
Semantik Ağın SEO İçin Önemi: Sorgu ve Belge Şablonları ile Semantik İçerik Ağları Oluşturma – Örnek Olay
Yayınlanan: 2022-01-11Anlamsal Ağ, ilişkisel bağlantıları olan şeyler için gerçek dünya bilgilerini temsil edebilen bir bilgi tabanı kavramına bağlıdır. Bir bilgi tabanı, milyarlarca varlık ve trilyonlarca gerçekle binlerce ilişki türüne sahip olabilir. Ağırlık, boyut, tip, koku veya renk gibi ortak özelliklerle gerçek dünyadaki herhangi bir varoluştan anlamsal bir ağ oluşturulabilir. Semantik Ağlar ve Semantik Web arasındaki ilişki, semantik arama motorları ve optimizasyon ile oluşturulur.
Semantik Ağlar Semantik Ayrıştırma, Kelime Anlamı Belirsizliği Giderme, WordNet Oluşturma, Grafik Teorisi, Doğal Dil İşleme, Anlama ve Oluşturmada kullanılır. Bir Semantik Ağın perspektifi, anlamsal bir içerik ağı sağlayarak Anlamsal Arama Motoru Optimizasyonu içinde kullanılabilir.
Bu SEO Vaka Çalışmasında, Sorgu, Belge, Amaç şablonları ve bunların arkasındaki varlık-özellik çiftleri temel alınarak aynı bakış açısına sahip iki farklı yöntemle iki farklı web sitesi açıklanacaktır.
Arama motorlarının bilgiyi nasıl temsil ettiğini ve bilginin temsilini nasıl genişlettiklerini anlayarak, inanılmaz sıralama sonuçları üretmek için bundan yararlanabiliyorum. Temel kavramları anladığınızda, bunları iki farklı web sitesine nasıl uyguladığımı açıklayacağım ve ardından kullandığım yöntemleri detaylandıracağım.
Semantik Ağlar, Web Sitenizin Sıralamasına nasıl yardımcı olabilir?
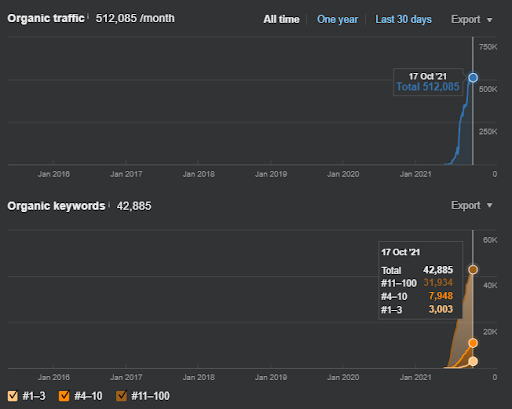
Aşağıda, Proje I için genel ham sonuçları bulacaksınız.
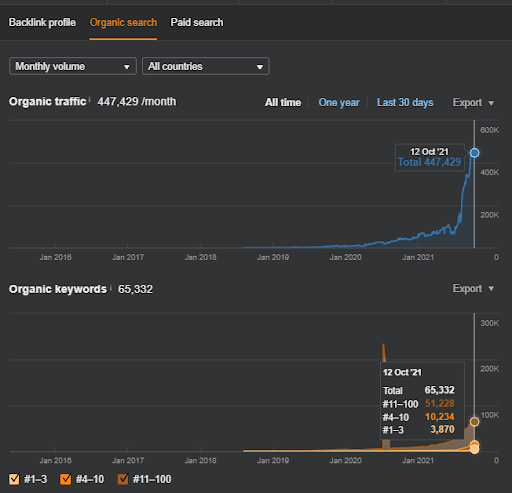
İstanbulBogaziciEnstitu.com olan Birinci Proje Sonuçları. Sorgu ve belge şablonları ile “Semantik Ağlar”ın SEO için kullanılabileceğini kanıtlamak için Project One'dan iki farklı içerik ağı göstereceğim. Semantic Content Network Two sayesinde Project One yakın gelecekte çok daha iyi sonuçlar elde edecek. İstemci bu ikinci ağın dağıtımından sorumlu olacak, ancak mantığını da açıklayacağım.
17 gün sonra, Proje I'de kaydedilen ilerleme: 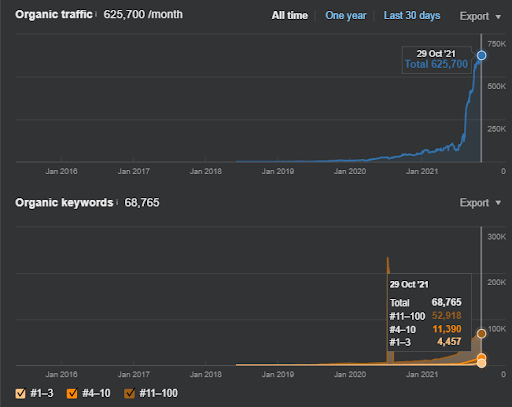
17 gün sonra Semantic Content Network'ün yeniden sıralama süreci daha net görülüyor.
Semantik İçerik Ağı kavramları, aynı türden varlıklar için sorgu, arama amacı, davranış ve belge şablonlarının değerini anlamamıza yardımcı olur. Bu Semantik Ağ odaklı SEO Vaka Çalışmasında, önceki Topikal Otorite ve Semantik SEO Vaka Çalışması, aynı varlık türleri etrafında anlamsal olarak oluşturulmuş içerik ağlarını kullanan iki yeni web sitesi aracılığıyla derinleştirilecektir.
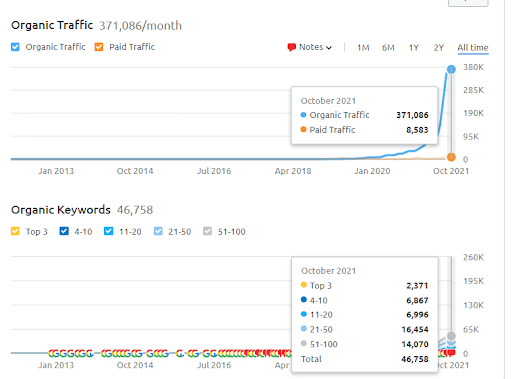
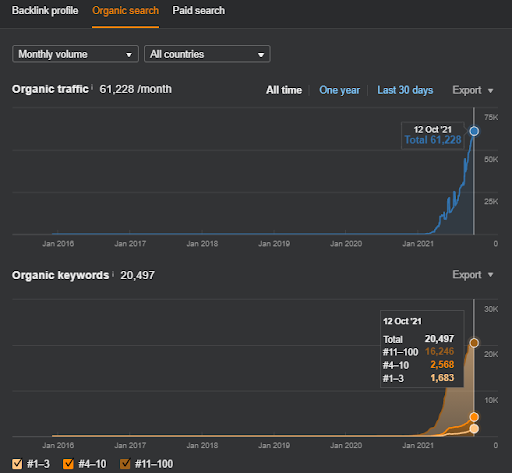
Bu, Birinci Proje'nin SEMRush grafiğidir. Bu web sitesinin Haziran Geniş Çekirdek Algoritma Güncellemesini kaybettiğini de belirtmeliyim, “Sıralanabilirliğini” kaybetmeseydi, sonuçlar daha iyi olurdu. Bir sonraki Geniş Çekirdek Algoritma Güncellemesi için, daha iyi bir topikal yetki, kapsam ve geçmiş verilerle, "Sıralanabilirliği" kolayca kurtarabilir.
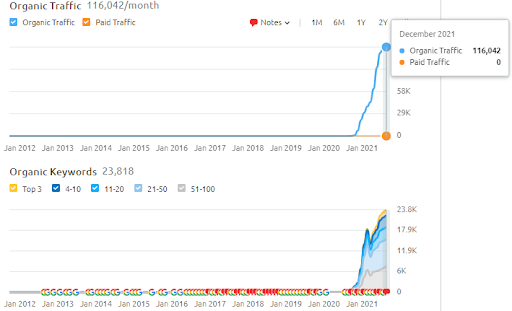
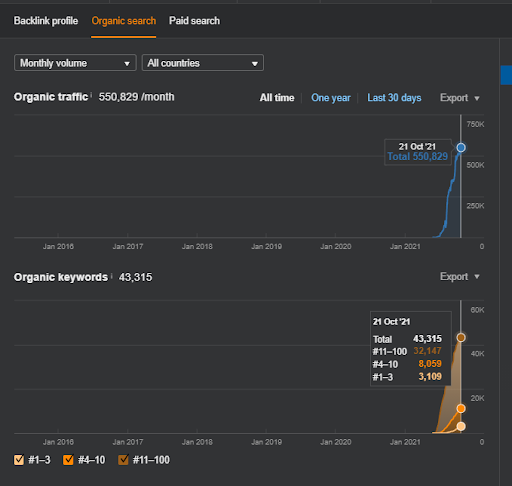
İkinci Projenin adı Vizem.net. Project One'dan farklı olarak, Vizem.net'in daha yavaş ama istikrarlı bir artışa sahip olduğunu görebilirsiniz. Bunun nedeni, Semantik İçerik Ağlarını biraz farklı bakış açılarıyla kullanmalarıdır. Aşağıda İkinci Proje'nin Ahrefs sonuçlarını görebilirsiniz.
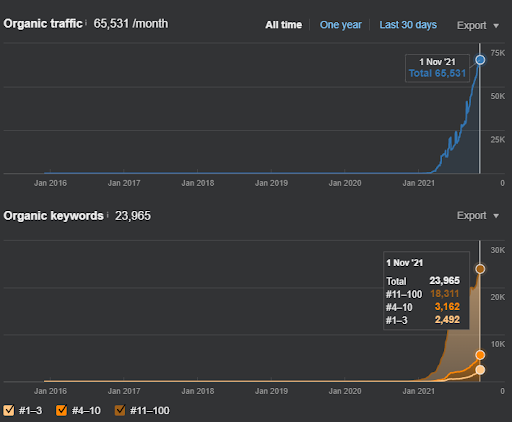
İkinci Projenin sonuçları, Konulu Kapsamı ve Otoriteyi kademeli olarak geliştirerek bir “Yavaş Yeniden Sıralama Sürecini” temsil eder. Semantik İçerik Ağları ile ilgili kavramlardan sonra “Yeniden Sıralama” ve “İlk Sıralama” terimleri açıklanacaktır. Grafiklerdeki "kararlılığı" fark ettiyseniz, bunun nedeni kaynakta yeni içerik yayınlamayı bırakmamdır. Ve İlk 3 Sorgu Sayısından da anladığınız üzere Yeniden Sıralama Sürecini etkiler. Temel kavramların açıklanmasından sonra “Momentum” ve “Yeniden Sıralama” ilişkileri bulunabilir.
Aşağıda Vizem.net'in SEMRush sonuçlarını bulabilirsiniz.
Bu web sitesinin gerçek trafiği, SEMRush'ta belirtilen sayının 3 katıdır. Aynı “kararlılık” ve “momentum” kavramlarını bu grafiklerde de gerçekleştirebilirsiniz.
Topikal Otorite SEO Vaka Çalışmasını yazarken, bakış açımı eğittiği için Bill Slawski'ye teşekkür ettim. Semantic Content Network SEO Case Study için de tekrarlıyorum. “Re-rank” ve “Initial-rank” kavramlarını anlamak için “Arama Motorlarının Arama Sonuçlarını Yeniden Sıralama Yolları” okunmalıdır.
18 Mart 2021'de Oncrawl, RankSense ve Holistic SEO & Digital bir Python SEO ve Veri Bilimi Web Semineri yayınladı. Webinarda sonuç farklılıklarının canlandırılabilmesi için SERP kaydı yapılmıştır. Arama motorunun, belirli kaynakların sıralamasını diğerleriyle benzer sıklıkta değiştirdiği görülebilir.
Devam etmeden önce, bunun uzun bir makale olduğunu biliyorum. Ancak, aslında bu, oldukça karmaşık bir SEO metodolojisinin kısa bir açıklamasıdır. Anlamsal İçerik Ağları, onları tasarlarken çok fazla düşünmeyi ve müşteriler, yazarlar ve işe alım ile birlikte aylarca eğitim gerektirir. Bu nedenle, bu yazıda, mümkün olan en iyi yürütülebilir kısa öneriler ve önemli Google ile kavramların tanımlarına ve diğer arama motorlarının patentlerine, araştırma makalelerine ve kendi kavramlarına odaklanmak istiyorum. Uzun versiyonunda (temelde bir kitap), anlamsal içerik ağlarının “ilk sıralaması” ve “yeniden sıralaması”na odaklandım.
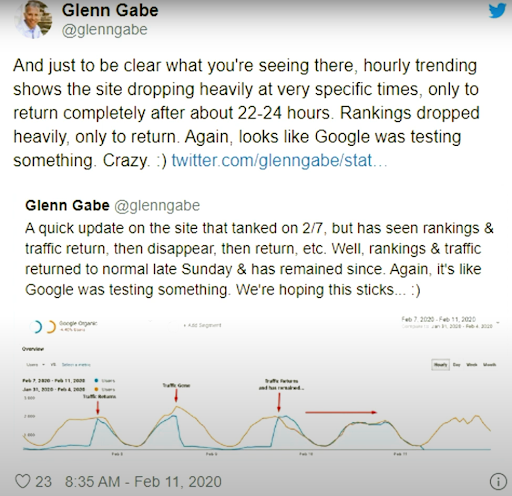
11 Şubat 2020'den itibaren Glenn Gabe, Arama Motorlarının görsel olarak Yeniden Sıralama ve test etme metodolojisi için iyi bir örneğe sahiptir.
Daha fazlasını öğrenmek istiyorsanız, “SEO için İlk Sıralamanın ve Yeniden Sıralamanın Önemi”ni okuyun.
SEO Vaka Çalışması için gerçek dünya verilerine derinlemesine dalmak için Semantik İçerik Ağı'nı anlamaya yönelik kavramlar, Arama Motoru Anlama-İletişim perspektifiyle işlenmelidir.
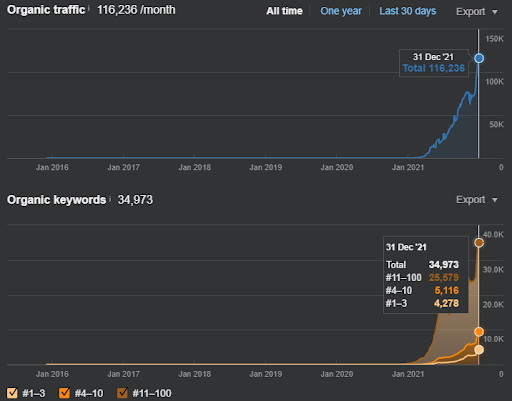
Vizem.net'in yeniden sıralama örneği olarak güncellenen durum yukarıda görülebilir. SEO Vaka Çalışmasının ileriki bölümlerinde, SEO için Google'ın Yeniden Sıralama Algoritmaları için daha fazla açıklama olacak.
Semantik Ağ nedir?
Semantik ağ, nesnelerin internetini bağlamak ve analiz etmek için kullanılabilir. Teknoloji pazarındaki potansiyel alıcıları tanımak veya anahtar kelime ağı oluşturma ve kümeleme için sadece ortak kelime analizi yapmak faydalı olabilir. Semantik bir ağ, navigasyonu desteklemek ve ilişkilerin yapısını veya bir şeyin başka bir şeye göreli önemini ortaya çıkarmak için kullanılabilir. Semantik Ağ aşağıdaki bileşenlere sahiptir:
- Sözlüksel Anlambilim: Hangi sözcük ve kavramın hangi sözcüklerle hangi farklılıklarla bağlantılı olduğunu anlamak.
- Yapısal Bileşen: Hangi düğümün hangi bilgi ile hangi uca bağlı olduğunu anlamak.
- Semantik Bileşen: Olguların tanımı.
- Prosedürel Bölüm: Bileşenler arasında daha fazla bağlantı oluşturmaya yardımcı olur.
Anlamsal ağlar çok amaçlı olduğundan, NLP algoritmaları karmaşık sağlık sorunlarının belirlenmesine yardımcı olmak gibi çok çeşitli amaçlar için de kullanılabilir. Aynı anlamsal ağ yapısı, bu diğer alanlar birbirleri arasında anlamsal bir ilişkiye sahip olduğu sürece, birden fazla alanda uygulanabilir.
Birinci Proje'nin son 6 aylık karşılaştırması.
Bilgi tabanı nedir?
Bilgi tabanı, makine tarafından okunabilir biçimde sınıflandırılmış bir bilgi kitaplığıdır. Bir bilgi tabanı, sorguya göre daraltılabilen ve derinleştirilebilen bir ansiklopedi olarak kullanılabilir. Önermelere, olgu çıkarımına ve bilgi çıkarımına dayalı bir bilgi tabanı oluşturulabilir. Semantik ağ ile bilgi tabanı arasındaki ilişki, anlamsal ağda bulunan her şeyin gerçekler çıkarılırken bilgi tabanına yerleştirilmesidir.
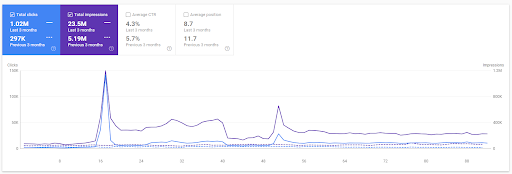
Birinci Proje'nin son 3 aylık karşılaştırması
Semantik İçerik Ağı nedir?
Anlamsal İçerik Ağı, anlamsal ağ bileşenleri ve anlayışı temel alınarak hazırlanmış bir içerik ağıdır. Bir anlamsal içerik ağı, bir bilgi tabanını daha ayrıntılı olarak sağlamak için bir varlıktan veya aynı gruptan varlıklardan birden çok öznitelik içerebilir.
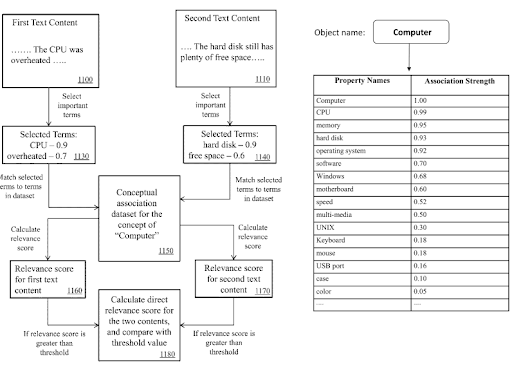
Anlamsal İçerik Ağı içinde, Bilgi Alanı Terimleri ve Üçlüler, bir belgenin ana amacını ve olası komşu içerik parçalarını belirtmek için kullanılabilir.
Bir arama motoru, kendi bilgi tabanını bir web sitesinin içeriğinden oluşturulabilecek bilgi tabanıyla karşılaştırabilir. Web sitesinin farklı bağlamsal katmanlar için yüksek düzeyde doğruluk ve anlaşılırlığı varsa, arama motoru web sitesinin içeriğinden kendi bilgi tabanını geliştirebilir. Bir arama motoru, açık web üzerindeki başka bir kaynaktan kendi bilgi tabanını geliştirir ve genişletirse, bu, yüksek düzeyde Bilgiye Dayalı Güvenin bir işaretidir.
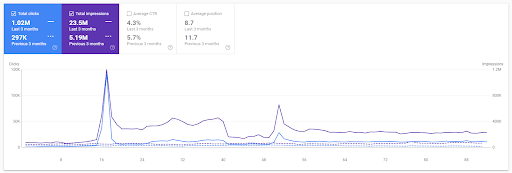
İlk Projeye Dayalı Son 3 Ay için Yıldan Yıla Karşılaştırma.
Bilgiye Dayalı Güven Nedir?
Bilgiye Dayalı Güven, "PageRank" yerine "bilginin doğruluğu"na dayalı açık web'e odaklanır. RankMerge'e benzer bir algoritmadır. Bilgiye Dayalı Güven, metin belirsizliğini ortadan kaldırarak üçüzler, gerçek çıkarma, doğruluk kontrolü ve metnin anlaşılmasını içerir. Bilgiye dayalı güven, farklı ancak ilgili bağlamsal katmanlara dayalı olarak, makale içinde güçlü bir şekilde bağlantılı bileşenlere sahip olan anlamsal içerik ağları sağlanarak elde edilebilir.
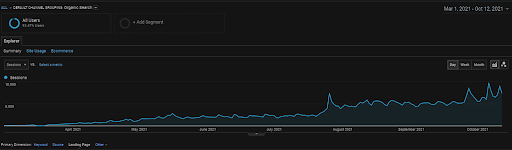
GA'dan Vizem.net'in Son 6 Aylık Organik Oturumu.
Aşağıda, Luna Dong'dan bir Bilgiye Dayalı Güven sunumu örneği göreceksiniz. Bir arama motorunun dışsal sıralama faktörleri yerine "iç sıralama faktörlerine" nasıl odaklanabileceğini gösterir. Yüksek bir PageRank'in, içerik için tek başına yüksek kalite ve doğruluğu temsil edemeyeceğini açıklar. Bu nedenle, bir KBT'ye (Bilgiye Dayalı Güven) sahip olmak önemlidir.
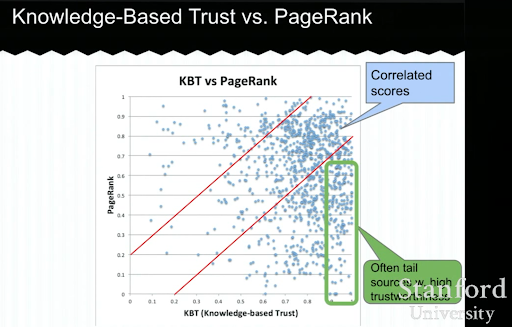
Özel bir SEO sohbeti sırasında bu eğitici dersi benimle paylaşan Arnout Hellemans'a çok teşekkürler. Bilgiye Dayalı Güven hakkında daha fazla bilgi edinmek istiyorsanız: Stanford Semineri – Bilgi Kasası ve Bilgiye Dayalı Güven
Bağlamsal Kapsama Nedir?
Bağlamsal Kapsama ve Konuya Dayalı Kapsam, Bilgi Alanı ile aynı değildir ve Bağlamsal Alan aynı değildir. Bağlamsal bir kapsam, bir kavramın işlem açılarını temsil eder. Bir kavram, diğer şeylerle olan ortak noktalarına göre işlenebilir. Varlık bir ülkeymiş gibi, çevresel krize karşı duruşu işlenebilir. Diğer ülkeler de aynı açıdan işlenirse, bağlamsal bir alanı kapsıyoruz demektir.

Google Arama Motoru, araştırma makalelerini ve patentlerini zaman içinde oluşturur. Yukarıdaki bölümden sağdaki alıntı "bağlam vektörlerine" bir niteliktir, sol kısım ise "ifade sınıflandırmasına" bir niteliktir. İşin ilginç yanı, örneğin “dijital kamera” bile aynı.
Bu kombinasyonların derinleştirilmiş ayrıntıları ve alt parçaları, bağlamsal bir etki alanındaki bağlamsal katmanları temsil eder. Adlandırılmış olsun ya da olmasın, her varlık birçok bağlamsal etki alanına sahiptir. Böylece, Google daha fazla bağlamsal alan alır ve kullanıcılar her yıl daha uzun sorgular arar. Doğal Dil İşleme ve Doğal Dil Anlayışı geliştirildiğinde, sorgular ve belgeler detay ve bağlam açısından birlikte genişler.
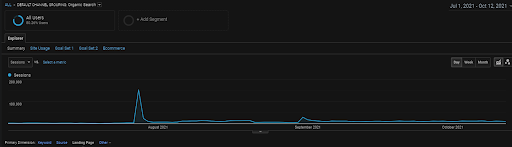
BoğaziçiEnstitu Projesi'nin son 4 ayına ait GA Organik Oturumlar grafiği. Projenin “Tarihsel Veri Toplama Aşaması” nedeniyle, artan detaylar lineer olarak görülemeyecek kadar net değildir.
Bağlamsal bir kapsam, “bağlam niteleyicileri” ile anlaşılabilir. Bir bağlam niteleyicisi bir sıfat, zarf veya "for, in, at, sırasında, while" ile başlayan ifadeler gibi başka herhangi bir edat olabilir. Aşağıdaki varlıkla ilgili sorular bağlamsal alan açısından aynı değildir:
- Uykusuzluk çeken çocuklar için en faydalı meyveler nelerdir?
- Kaygılı çocuklar için en faydalı meyveler nelerdir?
Aşağıdaki varlıkla ilgili sorular bağlamsal katman açısından aynı değildir:
- 6 yaş üstü şiddetli uykusuzluk çeken çocuklar için en faydalı meyveler nelerdir?
- 6 yaş altı düşük düzeyde kaygısı olan çocuklar için en faydalı meyveler nelerdir?
Aşağıdaki varlıkla ilgili sorular, bilgi alanları açısından aynı değildir:
- 6 yaş üstü şiddetli uykusuzluk çeken çocuklar için en faydalı kitaplar nelerdir?
- 6 yaş altı düşük düzeyde kaygısı olan çocuklar için en faydalı oyunlar nelerdir?
Ancak bu soruların tümü aynı Semantik İçerik Ağı'nda olabilir, çünkü hepsi aynı "kavram" ve "ilgi alanı" ile ilgili, benzer arama etkinliği ve aramayla ilgili gerçek dünya etkinliği ile ilgilidir.
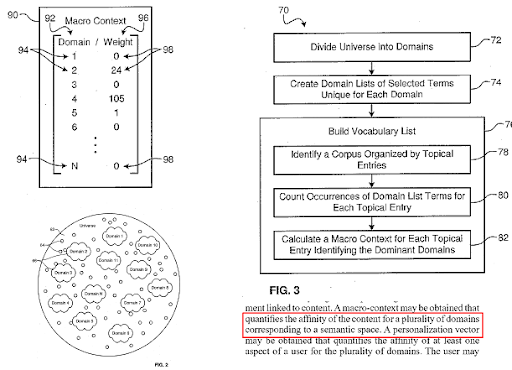
Bir arama motoru, web'i farklı bilgi alanlarına böler ve aynı anda bir kaynak, web sayfası ve web sayfası bölümü için makro ve mikro bağlam puanlarını hesaplar.
Sizin için bir sürü yeni konseptim olduğunu biliyorum ve bu yazının kısa versiyonu olduğu için burada her şeyden bahsedemeyeceğim ama ilerideki bir Semantik SEO Kursunda bunları işleyeceğim. "arama etkinliği" ile "aramayla ilgili gerçek dünya etkinliği" arasındaki fark.
Biraz daha somut şeylere devam edelim.
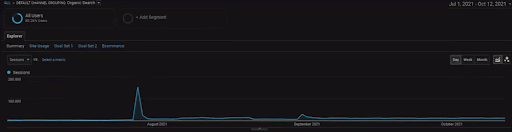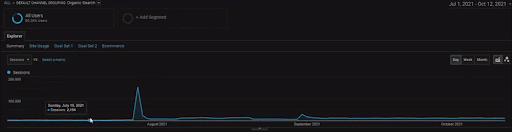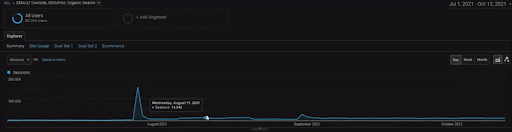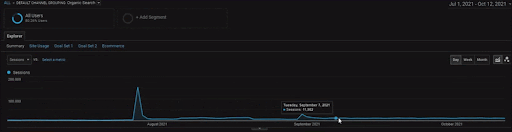
BoğaziçiEnstitu Projesinin detaylarını göstermek için interaktif görsel versiyonunu inceleyebilirsiniz. Arama motorlarının test etme ve yeniden sıralama süreci, bu projede tarihsel veri kaynağı olayından sonra daha nettir.
MuM, Semantik İçerik Ağlarıyla Nasıl İlişkili?
Birleşik Transformatör veya Çoklu Görev Birleşik Modeli ile Çoklu Görev Öğrenme, görsel girdilerin yanı sıra metinleri de değerlendirmek için dil modellerini eğitir. Anlama ile birlikte metin üretebilir. Ek olarak, MuM dilden bağımsızdır, diğer bir deyişle Semantik SEO dil becerisine bağlıdır, ancak bir dil ile sınırlı değildir. Varlıkların bir dili olmadığı ve anlam evrensel olduğu için MuM, birden çok dilden ve birden çok bağlamdan gelen bilgileri tek bir bilgi tabanında kullanır.
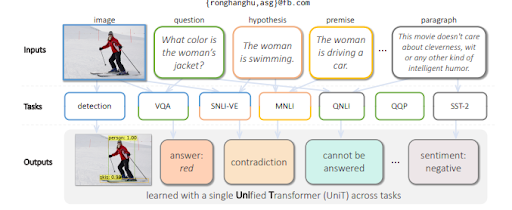
Bir görselden gelen soruları cevaplamak için MuM, bir görüntü içinde tespit edilen nesnelere dayalı olarak sorular üretir. Yakın gelecekte, ses ve video ile ilgili sorular da oluşturulabilecektir.
MuM, bir transformatör kodlayıcı-kod çözücü yapısı ile nesne algılama ve doğal dil anlayışı için farklı etki alanları kullanır. Her girdi, açık ağın farklı bir alanından gelirken, tümü tek bir paylaşılan kod çözücüden değerlendirilir. Aşağıda, araştırma makalesinden başka bir örnek görebileceksiniz.
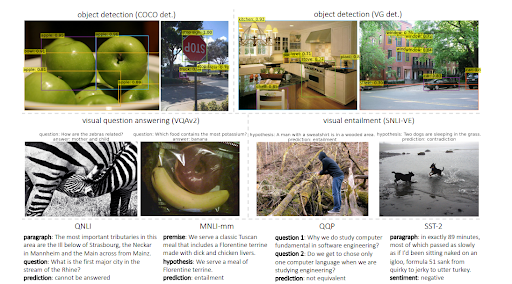
Bir not olarak, MuM, BERT'den 1000 kat daha güçlü olabilir, ancak BERT, MuM'nin Metin Kodlayıcısında hala kullanılmaktadır. MuM'nin ana avantajı, görseller ve doğrudan ses için kullanılabilmesidir, bu nedenle “çoklu görev” modeli olarak adlandırılabilir. İkinci avantajı ise tüm dil engellerini doğrudan ortadan kaldırmasıdır. Üçüncü avantajı ise ekstra aracılara ihtiyaç duymadan her şeyi başka bir şeye bağlayabilmesidir. Dördüncü avantaj, MuM'nin BERT'den farklı olarak metin üretebilmesidir.
MuM, Bilgi Tabanı, Semantik Ağlar ve Bağlamsal Kapsam arasındaki bağlantı, arama motorunun bağlam niteleyicileri ve bunların olası bilgi alanlarıyla kombinasyonları aracılığıyla çok daha fazla bağlamsal alan bulabilmesidir. Bu nedenle, uygun bir Konu Haritası ve Kaynak Bağlam ile şekillendirilmiş iyi yapılandırılmış bir Semantik İçerik Ağı, Konusal Otorite ile birlikte Bilgi Bankası Güvenini geliştirebilir.
Kaynağın Bağlamı nedir?
Kaynağın Bağlamı iki şeyi temsil eder. Kaynağın merkezi arama interneti ve ilgili arama faaliyeti ile yapılabilecek merkezi arama faaliyeti. Bir e-ticaret web sitesi için kaynak bağlam, belirli bir ürünü veya belirli bir ürün türünü satın almaktır. Bu bir seyahat web sitesiyse, kaynağın bağlamı farklı türde yiyecekler, manzaralar veya sadece iş için başka bir yerden bir yere gidiyor. Kaynağın Bağlamına dayalı olarak, Semantik İçerik Ağı tasarımı ve Konusal Haritanın daha fazla yapılandırılması gerekecektir. Bu, konu haritası içindeki merkezi bölümlerin ve konu haritası içindeki ek bölümlerin seçilmesini gerektirir.
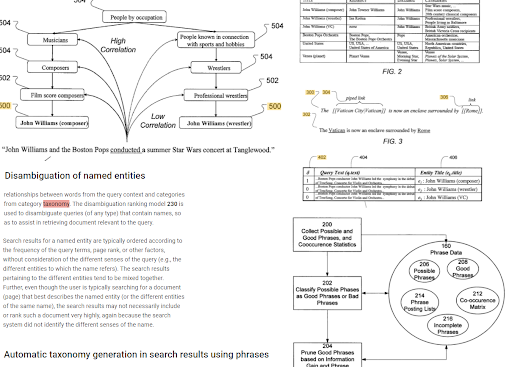
Cümle tabanlı indeksleme ve varlık odaklı arama anlayışı, anlambilime dayalı olarak birbirine bağlanır. Yukarıda, “Bağlam”ın belirlenmesi için “Adlandırılmış Varlık Belirsizliği” ve “Arama sonuçlarında kelime öbekleri kullanılarak otomatik sınıflandırma oluşturma” birlikte görülebilir. Bir konu için iyi ifadeler ve benzersiz ancak ilişkili bilgiler, daha iyi başlangıç ve yeniden sıralama için yardımcı olacaktır.
Yine bu kavramlardan bazıları, “topik harita konfigürasyonu”, “anlamsal içerik ağı tasarımı” henüz tanımlanmadı ve burası bunun için doğru yer değil. Ancak, ilgili arama etkinliği, kurallı arama amacı ve bu kurallı arama amaçları için temsili ifadelerle birlikte açıklanmıştır.
Semantik Ağ Odaklı SEO Vaka Çalışmasının Arka Planı
Yukarıdaki kavramlara dayanarak, Semantic Networks'ü bir SEO Case Study oluşturmak için kullandım. Bu makalenin başında bahsettiğim iki web sitesi projesine bakacağız ve sonuçları ve bunları üretmek için Semantik Ağları nasıl uyguladığımı inceleyeceğiz.
Bu ağların ne kadar güçlü olabileceği konusunda size bir fikir vermek için Semantik Ağ odaklı SEO Vaka Çalışması için SEO ile ilgili sonuçlar aşağıda listelenmiştir.
- Anlamsal Ağ Anlayışı, uygun bir Konu Haritası oluşturmak için bir zorunluluktur.
- Her iki proje için de semantik SEO'nun etkilerini izole etmek için Teknik SEO kullanılmamıştır.
- Aynı nedenle Sayfa Hızı Optimizasyonu kullanılmaz.
- Tasarım ve WUX (Web Sitesi Kullanıcı Deneyimi) Optimizasyonu kullanılmamaktadır.
- Geri bağlantılar (Dış Referanslar ve PageRank akışı) kullanılmaz.
- Her iki markanın da geçmiş verileri yok. Vizem.net tamamen yeni, BoğaziçiEnstitusu'nun daha eski bir geçmişi var ama asıl şirketten daha düşüktü.
- OnPage SEO veya SEO'nun diğer dikeyleri kullanılmaz.
- Her iki markanın da önceki Topikal Otorite Vaka Çalışması örneğinden daha iyi bir sunucusu var.
Bu Semantik Ağ odaklı SEO Vaka Çalışması, Semantik SEO bakış açısını iki farklı web sitesine odaklanan iki farklı metodoloji ve konseptle geliştirmek isteyenlere yardımcı olacaktır.
İkinci Proje: Vizem.net Vize Başvuru Sürecine odaklanmaktadır. Bu projeleri yazmadan, yayınlamadan ve hatta başlatmadan önce, bu web sitelerinin her ikisini de diğer müşterilerime veya ortaklarıma birçok kez gösterdim. Ve Vizem.net geçtiğimiz günlerde “Güncel Otorite” yolculuğuna başladı.
Semantic Networks Case Study tabanlı SEO iki farklı versiyonda yazılmıştır. Arama motorlarının karar ağaçlarını daha iyi anlarken, ilgili tüm patentleri, araştırma makalelerini ve derinlemesine detaylı incelemeleri, yorumları arama motoru bakış açısından okumak istiyorsanız, İlk Sıralamanın Önemi ve Yeniden Sıralama SEO'sunu okuyabilirsiniz. 30.000 kelimeden uzun Vaka Çalışması makalesi. SEO konusunda yeterli teorik bilgiye ve tarihsel geçmişe sahip değilseniz, yönetici özetini okumaya devam edebilirsiniz.
Aşağıda SEMRush'tan Second Project (Vizem.net) grafiğini görebilirsiniz.
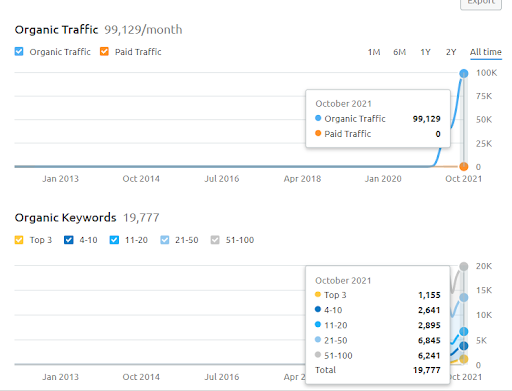
İkinci Web Sitesinin SEMRush grafiği. Vizem.net, “Visa Başvurusu” gibi köklü rakiplerin yüksek düzeyde olduğu sektörleri hedefleyen tamamen yeni bir kaynaktır. Özellikle Türkiye'de yaşanan son gelişmeler nedeniyle sektörün rekabet düzeyi artıyor. Bu nedenle, bir İçerik Ağı oluşturmak için Anlamsal Ağ perspektifini kullanmak faydalıdır.
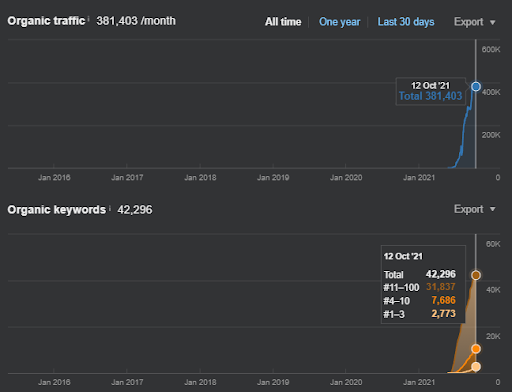
Birinci Proje: İstanbul Boğaziçi Enstitüsü: 3 Ayda %600 Organik Tıklama Artışı – Kaldıraçlı Geçmiş Veriler ve İlk Sıralama
İstanbulBoğaziçi Enstitüsü, Arama Motorları nedeniyle değil, insanlar ve sağlık sorunlarım nedeniyle gerçekleştirdiğim en zor SEO Vaka Çalışmalarından biridir. Böylece projeden ayrıldım ve kaynağın bağlamına dayalı olarak anlamsal ilişkileri tamamlamak için tasarlanmış üçüncü anlamsal içerik ağını yayınlamadım. Bilgi alanı terimlerine ve düzgün bir şekilde uygulanan bağlamsal ifadelere sahip olmasa bile, üçüncü içerik ağı ise ayda üç milyondan fazla oturumluk genel bir organik arama performansına izin vermek için yeterli düzeyde anlamsal bağlantı ve doğrulukla yapılandırılır. gelecekte yayınlanacak, ikinci anlamsal içerik ağının da artan etkisini hesaba katacak.
Aşağıda İstanbul Boğaziçi Enstitüsünün GSC'de son 12 ayda değişen grafiklerini göreceksiniz. Proje Mayıs 2021'de uygun bir şekilde başlatıldı ve Eylül 2021'de iki Semantik İçerik Ağı yayınlanarak sona erdi.
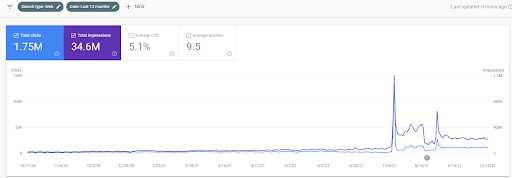
Aşağıda daha ayrıntılı sürümü görebilirsiniz. Organik Arama performansında günlük 1400 tıklamadan 140000 tıklamaya ve ardından günde düzenli 10.000+ tıklama görülebilir
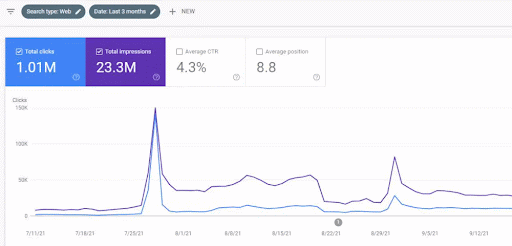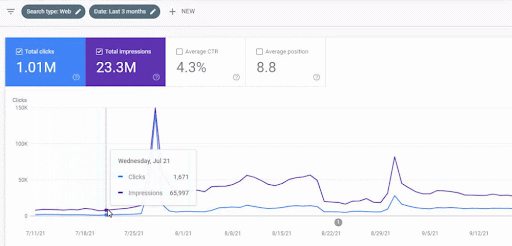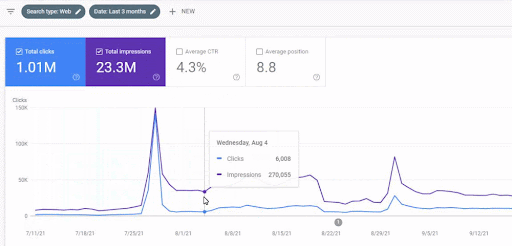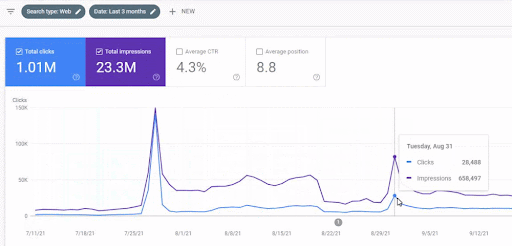
İlk içerik ağının lansmandan sonraki trafik artışı aşağıda görülebilir.
Bu ekran görüntüsü First Semantic Content Network'ün 4. ayını göstermektedir.
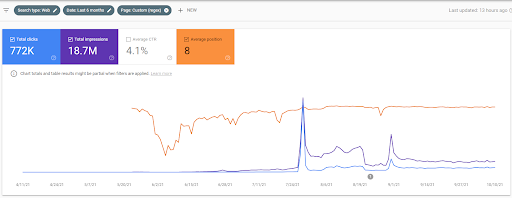
Grafikten de görebileceğiniz gibi, web sitesinin genel trafiğinin tamamı, “eğitim dallarına” odaklanan Birinci Semantik İçerik Ağı'ndan etkilenmiş ve domine edilmiştir. Bu web sitesi ile başlattığım ikinci içerik ağı aşağıda Google Arama Konsolundan görülebilir. Aşağıdaki ekran görüntüsü, ikinci anlamsal içerik ağının 16. gününden.
İlk sıralama ve yeniden sıralama, bir kaynağı test etmeden önce sıralama algoritmalarının aşamalarını, türleri ve amaçları ile birlikte tanımladıkları ve popülerliği olan daha önemli sorgular için SERP içindeki kaynaktan bir web sayfası tanımladıkları için makale içinde kullanılmıştır. .
İlk Projenin Odaklandığı İlk Semantik İçerik Ağı Nedir?
"Semantik İçerik Ağı", bilgi tabanındaki şeyler arasındaki ana, ikincil ve üçüncül ilişkileri açıklamak için bir bilgi tabanından bir anlamsal ağ kullanır. Bu nedenle, bir Semantik İçerik Ağı oluşturmak, bir sonraki anlamsal içerik ağının, web sitesinin ana işlevi olan kaynağın bağlamına dayalı olarak tasarlanmasını gerektirir. Bu bağlamda ilk anlamsal içerik ağı, “üniversite bölümleri, eğitim dalları ve belirli bir kurum ve dal içinde üniversite eğitimi için gereklilikler” üzerine odaklanmıştır.
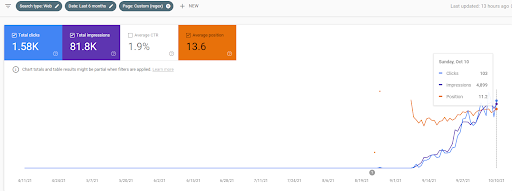
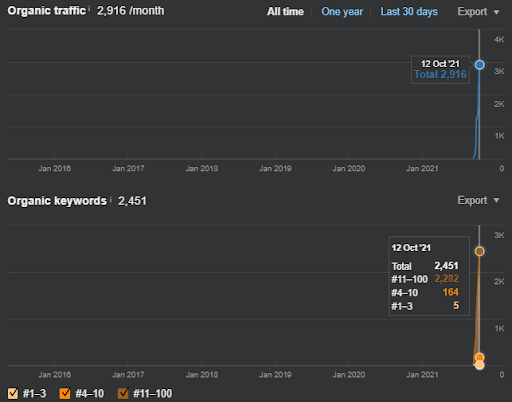
Aşağıda, Birinci Semantik İçerik Ağı'nın Ahrefs Grafiği'ni bulacaksınız.
Bu, önceki ekran görüntüsünden beş gün sonra.
“Kök: istanbulbogazicienstitu.com/bolum”, ilk sıralama aşamasından sonra yeniden sıralama süreci daha verimli ve verimlidir.
“Yeniden sıralamanın” doğasını desteklemek için dört gün sonraki sürümü aşağıdaki gibi görebilirsiniz.
Birinci Projenin İkinci Semantik İçerik Ağı Neye Odaklandı?
İkinci anlamsal içerik ağı mesleklere, mesleklere, becerilere ve bu beceriler veya rutin için gerekli eğitime odaklanmıştır. Birinci anlamsal içerik ağına dayalı olarak, ikinci anlamsal içerik ağı desteklenmiştir. Ve “sorgu şablonları-niyet şablonları”na göre iki farklı anlamsal alt içerik ağı daha oluşturulur ve üst benzer hiyerarşik düzeylere bağlanırken “ilişkisel bağlantılar” ile yerleştirilir.
Bu bölümlerin sizin için karmaşık olduğunu biliyorum çünkü aşağıdaki şeyler için henüz bir tanım görmediniz.
- Semantik İçerik Ağı
- Kaynak Bağlam
- Semantik Alt İçerik Ağı
- Bilgi tabanı
- İlişkisel Bağlantılar
- İlk Sıralama
- yeniden sıralama
- Bağlamsal Kapsam
- Karşılaştırma Sıralaması
- Gerçek Çıkarma
İkinci siteyi açıkladıktan sonra bu kavramları ve cümleleri anlamak daha kolay olacaktır.
Vizem.net: 6 Ayda Günde 0'dan 9.000'e Kadar Günlük Tıklama – İçeriğe Dayalı Kapsamlı Kaldıraçlı Karşılaştırmalı Sıralama
Vizem.net'in son 12 aya ait grafiğini görebilirsiniz. Bu proje için yatırımcının spor salonu sektöründen olması nedeniyle Covid-19 nedeniyle birçok ekonomik sıkıntı yaşadık. Dolayısıyla ekonomik sorunların projeyi yavaşlattığını ve “yeniden sıralama süreçlerinde” bir miktar gecikmeye neden olduğunu söyleyebilirim.
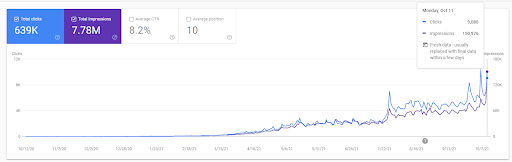
İlk sıralamayı anlamak ve biraz daha yeniden sıralamak için aşağıdaki grafiği kullanabilirsiniz.
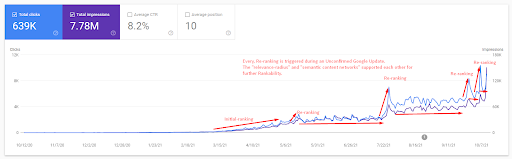
Yukarıdaki grafikten İlk Sıralama ve Yeniden Sıralama ile ilgili tanımlardan bazıları aşağıda bulunabilir.
- Büyük sıralama sıçramaları, Onaylanmamış Google Güncellemeleri sırasında gerçekleşti. Bazı testler bazı Öne Çıkan Snippet'ler verdi ve İnsanlar Ayrıca Sorular Sordu.
- Google'dan yapılan bazı testler FS ve PAA kazançlarını kaldırdı.
- Her seferinde, iki yeniden sıralama süreci arasındaki zaman çizelgesi daha kısaydı.
- Yeniden sıralama süreçleri, kaynağın Sıralanabilirliğini her seferinde iyileştirdi.
- Kaynak, sorgu kümelerini genişletirken her zaman alaka yarıçapını geliştirdi.
Sadece bir not olarak, aşağıya bir cümle bırakabilirim.
Bir Arama Motoru web sayfanızı dizine eklerse, bu arama motorunun web sayfasını anladığı anlamına gelmez. Dizin oluşturma, anlamaktan daha hızlı gerçekleşir ve çoğu zaman bir arama motoru, bir web sayfasını "başlangıçta" tahminlerle sıralar. Anlamadan sonra “yeniden sıralama” gerçekleşir. 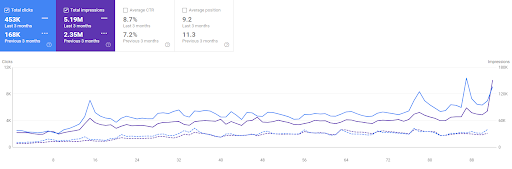
Vizem.net'in son 3 aylık karşılaştırması
Vizem.net'in Semantik İçerik Ağı Nasıldır?
Bir çok müşterime, arkadaşıma veya gizli SEO Gruplarıma toplantılarda her iki siteyi de “patlayacaklar” diyerek gösterdiğimi hatırlıyorum. Ve bu yazıyı yazarken size şunu söylüyorum:
“istanbulbogazicienstitu.com/meslek” Semantik İçerik Ağı'nı izleyin çünkü patlayacak. Ve bu makaleyi yazmadan önce yayınladığım ve sezonluk bir olaydan “Tarihsel Veriler” ve bunun İlk ve Yeniden Sıralama süreçlerine etkisini gösterirken yayınladığım bir video bulabilirsiniz. Aşağıda görebilirsiniz.
Bundan yola çıkarak Vizem.net'in Semantik İçerik Ağı, İstanbul Boğaziçi Enstitüsü'ne benzemiyor, bu nedenle “yoğun bir Konu Kapsamı ve Tarihsel Veri artışı” kullanmadım, belirli konularla ilgili otorite oluşturmam gerekiyordu. varlık türleri, nitelikleri ve bu varlık-öznitelik çiftleri için sorguların arkasındaki olası eylemler. Vizem.net'in bünyesinde sadece “eğitim üniversitesi şubeleri” veya “meslekler ve online dersler” bulunmamaktadır. “Vize başvuruları için ülkeler” var. Bu nedenle, yeterli düzeyde Konusal Otorite oluşturmak, en az 190 farklı anlamsal içerik ağı ile zaman içinde tutarlılık gerektirir.
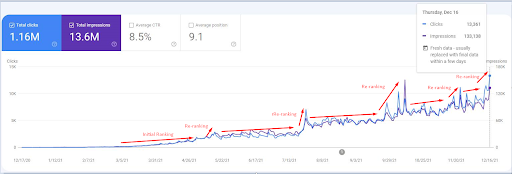
18 Aralık 2021'den bir ekran görüntüsü. Gösterimlerin ve tıklamaların sürekli yeniden sıralamasını ve artışını görebilirsiniz. Bu, önceki ekran görüntüsünden 4 hafta sonradır.
Yeniden sıralama olaylarını görmek için Semantik SEO'nun etkisini gösteren organik arama performansı grafiğinin çıplak versiyonunu karşılaştırabilirsiniz. 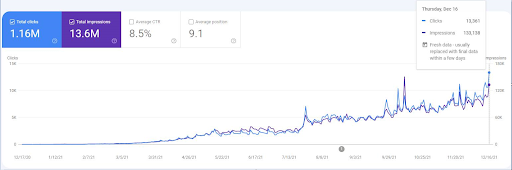
Bu 190 farklı semantik içerik ağı, “ülke”nin kendisine göre şekillendirilir ve ülkeler, arama faaliyeti kapsamını iyileştirmek için olası her bağlamsal katmanla birlikte topikal haritanın merkezine yerleştirilir.
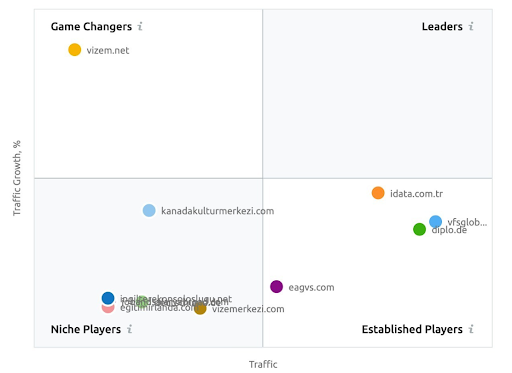
SEMRush'tan diğer sektör oyuncularının aksine Vizem.net'e yönelik algılarını gösteren bir ekran görüntüsü.
Ayrıca sadece Vizem.net için bir video daha yayınladım. Bu videoda sitenin son durumu yok, o yüzden bugün ile o gün arasında güzel bir karşılaştırma da yapıldığına inanıyorum.
Son olarak, alakasız bir makale, web sitesi segmenti veya kaynak içinde alakasız şeyler yayınlamak, web varlığının belirli bilgi alanıyla genel alaka düzeyini azaltabilir. Vizem.net gerçek değerini gösterecek ve gelecekte Rankability çok daha iyi olacak.
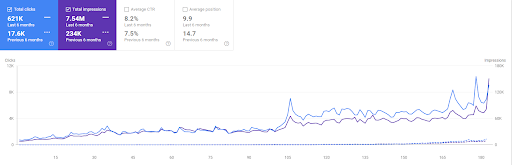
Vizem.net'in son 6 aylık karşılaştırması.
Devam etmeden önce, bunun uzun bir makale olduğunu biliyorum. Ancak, aslında bu, oldukça karmaşık bir SEO metodolojisinin kısa bir açıklamasıdır. Anlamsal İçerik Ağları, onları tasarlarken çok fazla düşünmeyi ve müşteriler, yazarlar ve işe alım ile birlikte aylarca eğitim gerektirir. Bu nedenle, bu yazıda, mümkün olan en iyi yürütülebilir kısa öneriler ve önemli Google ile kavramların tanımlarına ve diğer arama motorlarının patentlerine, araştırma makalelerine ve kendi kavramlarına odaklanmak istiyorum. Uzun versiyonunda (temelde bir kitap), anlamsal içerik ağlarının “ilk sıralaması” ve “yeniden sıralaması”na odaklandım.
Daha fazlasını öğrenmek istiyorsanız, “SEO için İlk Sıralamanın ve Yeniden Sıralamanın Önemi”ni okuyun.
Şimdiye kadar, aşağıdakileri işledik.
- anlamsal ağ
- Bilgi tabanı
- Semantik İçerik Ağı
- Bilgiye Dayalı Güven
- Bağlamsal Kapsam
- Bağlamsal Etki Alanı ve Katmanlar
- MuM'nin Semantik İçerik Ağlarıyla Alakası
- Kaynağın İçeriği
Bu kavramlar, Semantik İçerik Ağlarının nasıl çalıştığını ve bunların bir konu haritası ile nasıl kullanılabileceğini anlamak içindir. Sonraki bölümler, bir arama motorunun Semantik İçerik Ağlarını Başlangıçta ve daha sonra Değiştirme olarak nasıl sıraladığıyla ilgili olacaktır. Bu kapsamda aşağıdaki hususlar işlenecektir.
- İlk Sıralama
- yeniden sıralama
- Sorgu Şablonu
- Belge Şablonu
- Arama Amacı Şablonu
- Anlamsal İçerik Ağlarından yararlanmak için yapmanız gerekenler
SEO için İlk Sıralama Nedir?
Bu, SEO için yeni bir terim ve kavramdır, ancak Arama Motorları için eskidir. “Semantik ağ odaklı SEO Vaka Çalışması”nın uzun versiyonu, sorguya bağlı, belgeye bağlı, kaynağa bağlı algoritmalara ve çoklu patentlere dayalı Sıralama Algoritmalarına odaklanır. Tahmine Dayalı Bilgi Alma veya tahmine dayalı sıralama algoritmaları, hesaplama maliyetini düşürmeye çalışır. Ve indeksleme bir günde gerçekleşse bile, bir belgeyi anlamak aylar hatta yıllar alabilir. Bu nedenle ilk sıralamayı hesaplamak, maliyeti düşürürken SERP Kalitesini iyileştirmenin bir yoludur. Arama Motoru ile ilgili bazı görevler, dizini canlı, taze ve yeterince yüksek kalitede tutmak için diğerlerinden daha yüksek önceliğe sahiptir.

İlk sıralama terimi, arama motoru üreticileri arasında klasik bir bakış açısı olduğu için on binlerce farklı Google Patentinde ve araştırma makalesinde yer almaktadır. Bu nedenle, yukarıda, aynı paragrafların devamı ile farklı patent belgelerini ve terimin ilk sıralamasında küçük değişikliklere sahip terimleri görebilirsiniz.
İlk sıralama, indekslendikten hemen sonra SERP'deki bir belgenin sıralamasını temsil eder. Bir belgenin ilk sıralaması, genel yetkiyi ve kaynağın belirli bir konu, sorgu şablonu ve arama amacı ile ilişkisini temsil eder. Aynı içerik, farklı kaynaklar arasında ilk sıralama açısından farklı şekilde sıralanabilir. Kaynağın genel kalitesini ve yetki artışını görmek için Semantik İçerik Ağlarını kullanırken ilk sıralama önemlidir. Anlamsal içerik ağı tasarımı doğru yapılandırılmışsa, her yeni belge ilk sıralamasını artırırken dizin oluşturma gecikmesini azaltır.
İlk sıralama, yeniden sıralama sürecini ve kaynak için verimliliğini destekler. Ve “bir kaynağın sıralanabilirliği” bu iki terimle, yani ilk ve yeniden sıralama ile işlenmelidir.
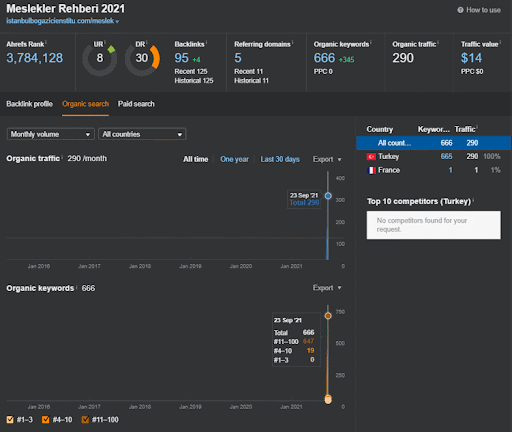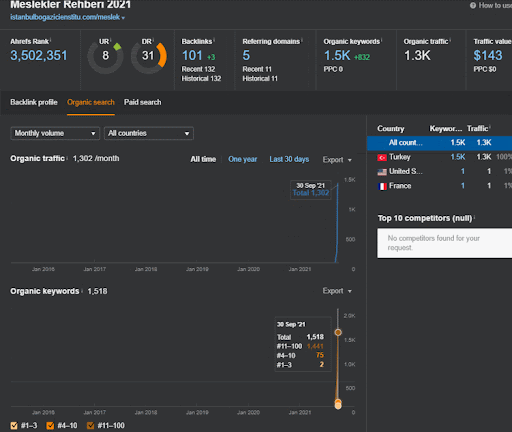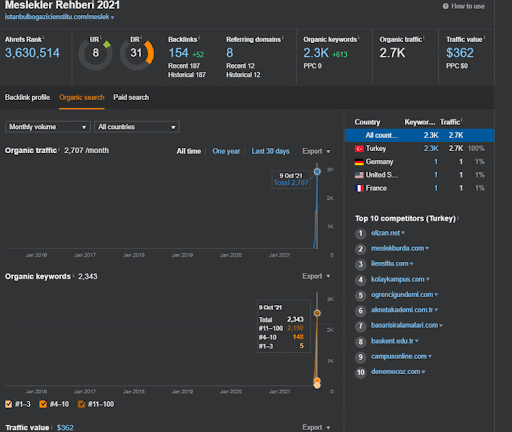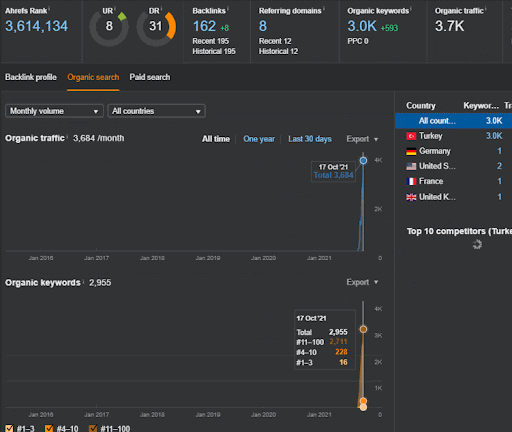
İkinci İçerik Ağı'nın organik performans değişikliğinin ilk 20 gününü Proje I'den izleyebilirsiniz.
Bu bağlamda, Vizem.net ne zaman yeni bir belge yayınlasa veya İstanbul Boğaziçi Enstitüsü ne zaman yeni bir anlamsal içerik ağı yayınlasa, içerik daha hızlı indekslenirken ilk sıralama eskisinden daha iyi oluyor.
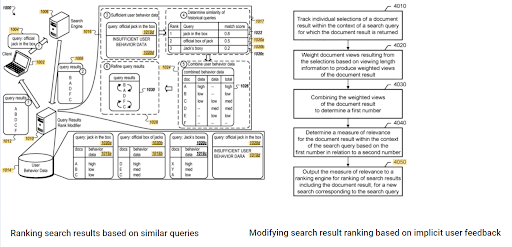
Bu iki tamamlayıcı Google patenti arasında ilk sıralamanın önemi ve geçmiş veriler görülebilir. Biri, örtük kullanıcı geri bildirimine dayalı olarak ilk ve yeniden sıralama belgeleri içindir. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 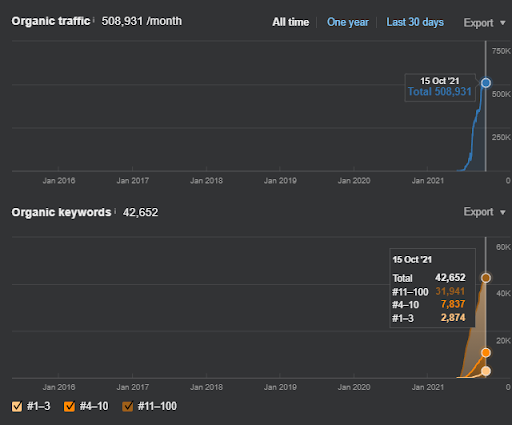
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 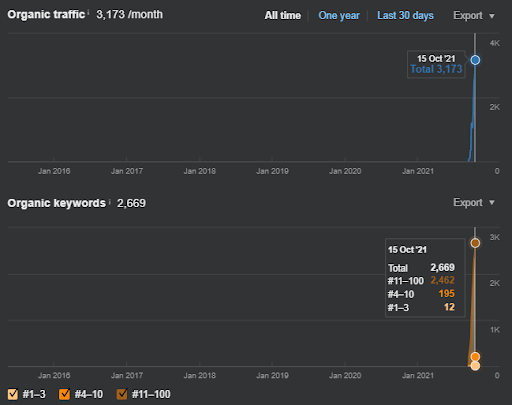
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 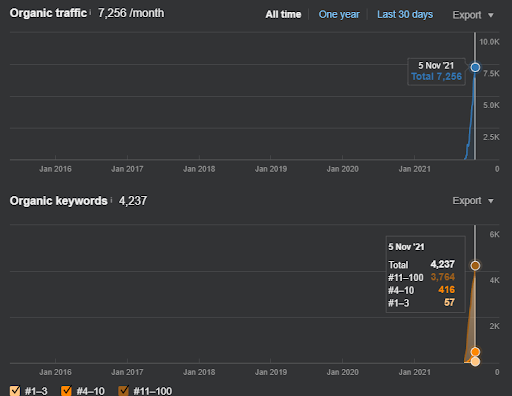
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 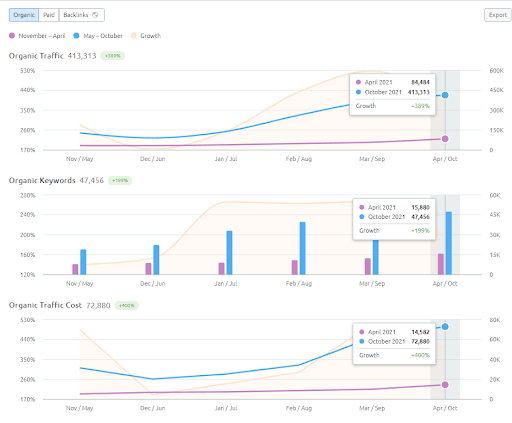
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.
The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Tarama Verileri³
 Daha fazla bilgi edin
Daha fazla bilgi edinWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 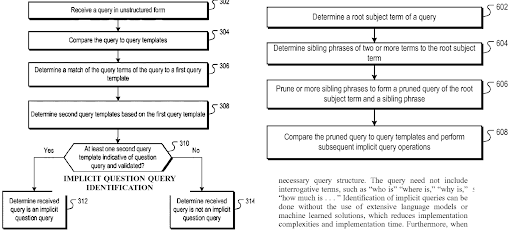
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.

In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Evet onlar. Olasılık Sıralaması ve Azaltılmış Uygunluk Sıralaması, kullanıcıları anlamak ve olasılık durumları için hazırlanmış mümkün olan en yüksek kaliteli SERP'yi oluşturmak için anlamsal bir arama motorunun ana sütunlarıdır. 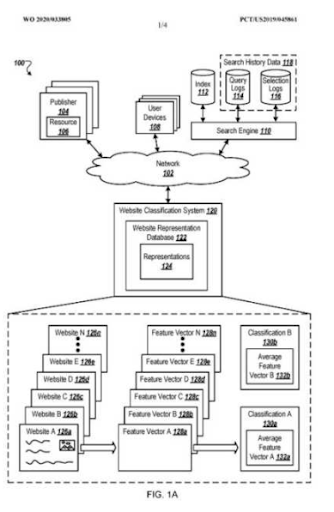
Daha önce, Bill Slawski, “web sitesi tasarımı ve görünümü veya tonalitesini” web siteleri için temsil öğrenimi için bir argüman haline getirmek için “Web Sitesi Temsil Vektörleri” yazmıştı.
Arama amacı şablonu nedir?
Bir arama amacı şablonu, sorgu şablonunun arkasındaki ihtiyaçla temsil edilebilir. Bir sorgu-belge şablonu, bir niyet şablonuna dayalı olarak birleştirilebilir. Olası "Düşürülmüş Uygunluk Sıralaması" ve "Olasılık Sıralaması" anlayışına sahip bir arama amacı şablonuna sahip olmak, mümkün olan en iyi arama etkinliğinin ve doğru sıra ile arama amacı kapsamının oluşturulmasına yardımcı olacaktır. Anlamsal İçerik Ağı oluştururken, en önemli şey, bilgi tabanlı güveni ve topikal otoriteyi geliştirmek için bağlamsal kapsamı geliştirerek bir bilgi alanına dayalı anlamsal bir ağı tamamlamak için kaynağın bağlamına dayalı olarak belge-sorgu-amaç şablonunu ayarlamaktır. . 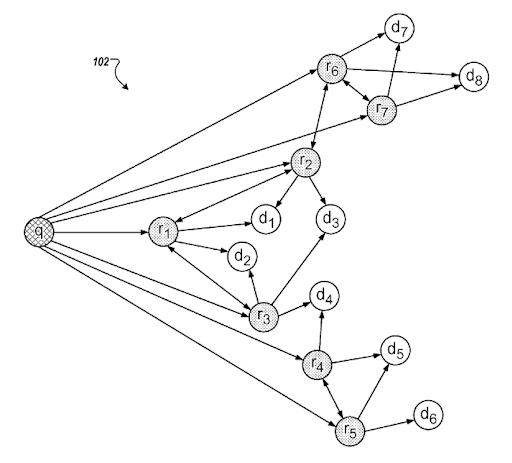
Google'ın "Tahmin Edilen Niyete Dayalı Sorgu İyileştirmeleri"nden bir bölüm. Anlamsal bağlantılara sahip sorgu kümeleri ve amaç şablonları aracılığıyla çalışır. Bunu farklı kelime öbeği sınıflandırma seviyelerinde deneyimleyebilirsiniz.
Bazı somut örneklere ve daha iyi bir anlamsal içerik ağı oluşturmanıza yardımcı olacak önerilere geçmeden önce, bu SEO Vaka Çalışmasının basit versiyonunun bile yüksek düzeyde arama motoru anlayışı ve iletişim becerileri gerektirdiğini söylemeliyim. Dolayısıyla üst düzey bilgiler verdiğimi hissetsem de oluşturacağım Semantik SEO kursunun size daha somut ve somut örnekler göstereceğini biliyorum. 
Aynı patent, farklı “sorgu yolları” ve “bağlam kaymaları” arasındaki uygun bağlantıları açıklar.
Anlamsal İçerik Ağlarından yararlanma hakkında bilmeniz gerekenler?
Anlamsal İçerik Ağı oluşturmak için, ilgili tüm ayrıntıları sözcüksel anlambilime veya varlıklar ve deyimler arasındaki ilişki türlerine göre koyarsanız, bazen basit bir anlamsal içerik özeti ve tasarımı bile bir saat sürebilir. Bir içeriğin genel olarak bağlamsal bir alanla bağlamsal alaka düzeyini veya bireysel alt içerik türlerine dayalı olarak alaka düzeyini hesaplamak için kelime öbeği tabanlı indeksleme ve kelime vektörleri veya bağlam vektörleri gibi aynı anda birden fazla açı kullanarak, yüksek düzeyde semantik arama motoru anlayışı gerektirir.
Bu nedenle, üretken bir metodoloji kullanmak, yukarıda size anlattığım kavramlarla her şeyi kolaylaştıracaktır, çünkü her semantik içerik ağı parçasını mükemmel bir şekilde hazırlasanız bile, yazarlar ve yazarlar veya içerik yöneticileri onu yazamayacaklardır. vizyonunuzu takip edemezsiniz. Bu yüzden sizi boş yere yorabilir ve bu SEO Vaka Çalışması Projelerinin bazılarında yaptığım gibi kavramı yeterince, canlı ve denetlenebilir bir şekilde kanıtladıktan sonra bir projeden ayrılmanıza neden olabilir.
Aşağıdaki öneriler yalnızca size yardımcı olacak kolay yürütülebilir ve kısa adımlar için olacaktır.
1. Her Semantik İçerik Ağı Ağından Sabit Kenar Çubuğu Bağlantılarını kullanmayın
Her bağlantı, bir web sayfasındaki her kelime gibi iki köprü metni belgesi arasında bir bağlantı açıklamasına sahip olmalıdır. Semantik HTML Kullanımı, bir web sayfasındaki bir belgenin konumunu ve işlevini belirlemeye yardımcı olurken, arama motorlarının bölümleri bağlam açısından farklı şekilde ağırlıklandırmasına yardımcı olabilir.
Vizem.net örneğinde aynı kenar çubuğu tasarımını kullanmadım. Kenar çubuğu en son gönderileri veya en kritik olanları göstermedi. Kenar çubukları yalnızca merkezi varlıkların niteliklerini gösterir ve sabit değildirler, dinamiktirler. Başka bir deyişle, konu haritası içindeki hiyerarşiye bağlı olarak, anlamsal içerik ağı ağları, kenar çubuğunda olsalar bile değişir. 
Makul Sörfçü ve İhtiyatlı Sörfçü Modelleri hakkında düşünmek, bir SEO'nun farklı hiper metin belgeleri arasında daha iyi bir alaka düzeyi oluşturmasına yardımcı olabilir.
Ek olarak, bağlantı önem açısından akar ve popülerlik, kaynağın bağlamını mümkün olan en iyi bağlantılardan takip etmelidir. Aşağıda, ayarlanmış Semantik HTML kodları ile kenar çubuğu bölümlerini görebilirsiniz. 
Kullanıcının oturumunda aktif olan makalenin hiyerarşisine göre sekmeler, sekmelerin sırası, sekmeler içindeki bağlantılar değişecektir. Yukarıdaki örnek, aşağıdaki içerik haritası hiyerarşisinden alınmıştır. ![]()
2. Semantik İçerik Ağlarını PageRank ile Destekleyin
Harici PageRank harici kaynaklardan şart olmasa da, onu kullanabiliyorsanız, ilk sıralamanın ve yeniden sıralamanın daha iyi olacağını fark edeceksiniz. Bu projelerin her ikisi için de kullanmadım ama bu sefer amaç bu değildi. Vizem.net için ekonomik sorunlar vardı ve bütçeyi dijital PR ve sosyal yardıma harcamak istemedim. İstanbul Boğaziçi Enstitüsü için, belirli bir konu için kaynağın gerçekliğini desteklemek için birkaç “yerel olarak birbirine bağlı kaynak” ayarladım, ancak yine şirket bunu bütçe ve organizasyonel disiplin sorunları nedeniyle uygulayamadı. 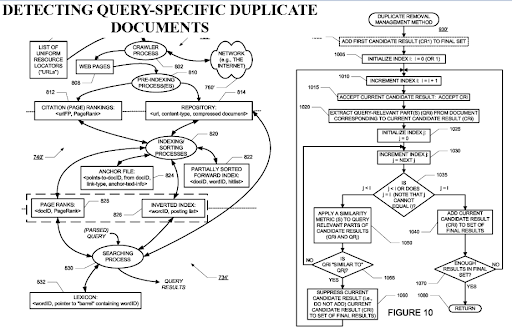
Sorguya Özgü Yinelenen Belgeleri Algılamak, Arama Motorları açısından önemli bir bakış açısıdır, çünkü PageRank, bir belgenin çoğaltılmış olsa bile değerli olarak filtrelenmesine yardımcı olabilir. Oldukça organize semantik içerik ağları birbirine benzeyebileceğinden, PageRank akışı ve geçmiş veriler yararlıdır.
Bu tür anlamsal içerik ağları için harici PageRank akış noktasını seçmek söz konusu olduğunda, geçmiş verileri içeren kaynakları kullanın. Benim durumumda, bu PageRank uç noktalarını, ilk anlamsal içerik ağını başlatmadan ve yayınlamadan önce düzenlemiştim. Bu sayede doğrudan rakiplerden dış referanslar alabildim, ancak anlamsal içerik ağını yayınladığımda rakipler kaynağın bir rakip olarak kitlesel artışını gördükleri için kaynak bağlamayı bıraktılar.
Bu durum bizi üçüncü öneriye getiriyor. PageRank akışını harici referanslardan kullanabilseydik, yeniden sıralama süreci daha hızlı olurdu ve ilk sıralama daha yüksek olurdu.
3. Belirgin Semantik İçerik Ağı Bölümleri için Altbilgi, Üstbilgi ve Ana İçerikten Farklı Bağlantı Metinleri Kullanın
Bağlantı metinleri veya arama motorunun bakış açısından "bağlantı metni", bir hiper metin belgesinin diğerine uygunluğunu işaret eder. PageRank'in orijinal belgesine göre, bağlantı sayısı PageRank akışıyla orantılıdır. Ancak daha sonra Google, “bağlantı doldurmayı” önlemek için bunu değiştirdi ve PageRank'i gerçekten geçebilecek bağlantıları sınırladı. Buna dayanarak TrustRank, Cautious Surfer, Hilltop Algoritması veya Reasonable Surfer Modelleri geliştirildi. 
Bunlar BoğaziçiEnstitusu için iki farklı anlamsal içerik ağına iki bağlantı, ancak teknik SEO veya UX iyileştirmeleri yapmadığım için düğme tasarımlarının “ucuzluğunu” fark edebilirsiniz.
Google'a göre, aynı bağlantı PageRank'i ikinci kez başka bir web sayfasına geçiremezken, PageRank yalnızca ilk bağlantıdan geçirilecektir. Ve PageRank algoritmasının orijinal biçiminde, bir köprü metni belgesi PageRank'ini geliştirmek için kendi kendine bağlanabilir veya bağlantı hedef belgesinin PageRank'ini almak için 301 yönlendirmeleri kullanılabilir. Bu durumların her ikisi de, yalnızca PageRank'ini almak için bir web sayfasını geçici olarak diğerine yönlendirmek gibi eski Siyah Şapka Tekniklerini yarattı. Bu, SEO'ların Google Arama Konsolu veya SERP'den bir web sayfasının PageRank'ini görebildiği günlerdendi. Daha sonra Danny Sullivan, 301 yönlendirmelerinin PageRank'i tamamen geçeceğini açıklarken, Google her yönlendirme ile PageRank'i düşürmeye başladı. Tüm bu değişikliklerin yanında burada önemli olan ikinci link PageRank'i geçemese bile link metninin alaka düzeyini geçmesidir. 
Semantik İçerik Ağının öne çıkan bölümlerine, "fiiller, yüklemler" veya "arama etkinlikleri"ni içeren "orta sorgu iyileştirmelerine" dayalı olarak Ana Sayfadan bağlantı verilmiştir.
Bu nedenle Semantik İçerik Ağı'nın öne çıkan bölümleri üstbilgi ve altbilgi menüsünden üst taksonomi bölümleriyle bağlantılandırılmalı ve bağlantı metinleri birbirinden farklı olmalıdır. Bu örneklerde, altbilgi örneklerini daha uzun tutarken, öne çıkan ancak kısa bağlantı metinleriyle başlık bağlantılarını kullandım. 
"Bir web tarayıcı sisteminde Bağlantı Etiketi dizinleme" bölümünün bir bölümü, bir bağlantı metninin ve bir web sayfasını sorgu kümeleri ve web sayfası kümeleri içinde konumlandırmak için açıklama metninin önemini özetler.
Semantik İçerik Ağı bölümü, PageRank ve tarama önceliğini düzgün bir şekilde geçemeyecek kadar belirginse, en önemli bölümleri uygun bağlantı metinleri ve ilgili N-Gramların farklı varyasyonlarıyla öne çıkan özellikleri içeren açıklayıcı paragraflar ile bağladım. 
Bu, Vizem.net'in ana sayfasından ikinci bağlantılı alandır, bir akordeonun arkasındadır ve sorgulardaki ülkelere odaklanır ve anlamsal içerik ağının orta bölümünü birbirine bağlar.
Not: Bağlantı metinlerinin çevresinde, bağlantının amacının kesinliğini geliştirmek için her zaman planlı bir “açıklama metni” kullanılmıştır.
4. Bağlantı Sayısı Kısıtlamasını ve Masaüstü ve Mobil Bağlantıları ve Ana İçeriği Eşleştirmeyi Sınırlayın
Her iki proje de web sayfası başına 150'den az dahili bağlantıya sahip olacak şekilde sınırlandırılmıştır. Semantik HTML yardımı ile bağlantıların yerleri ve bağlantıların işlevleri tarayıcılara anlaşılır hale getirilir. İstanbul Boğaziçi Enstitüsü'nün web sayfası başına 450'den fazla bağlantı vardı ve bunlardan bazıları kendi kendine bağlantılardı (aynı sayfadan aynı sayfaya bağlantı). En kötü yanı, bu bağlantıların yarısının içeriğin mobil versiyonunda bulunmaması. 
URL Koruma Puanı, Tarama Puanı ve diğer puan türleri, bir bağlantının dahili URL Haritası içindeki önemini belirlemek için kullanılabilir ve farklı katmanlardaki belge tanımlama etiketleri, dizini sorgudan bağımsız alaka düzeyi puanlarına göre sıralamak için kullanılabilir.
Google, yalnızca mobil cihazlar için dizin oluşturmayı kullandığından, içerik mobil sürümde mevcut değilse yok sayılır ve alaka değerlendirmesi ve sıralama amaçları için kullanılmaz. Böylece mobil ve masaüstü içeriği birbiriyle eşleşecek şekilde yapılandırıldı. Google, masaüstü ve mobil sürümler arasındaki içerik uyumsuzluklarını tolere etse bile, arama motorları için bir web sayfasını anlamayı ve sıralamayı zorlaştırıyor. 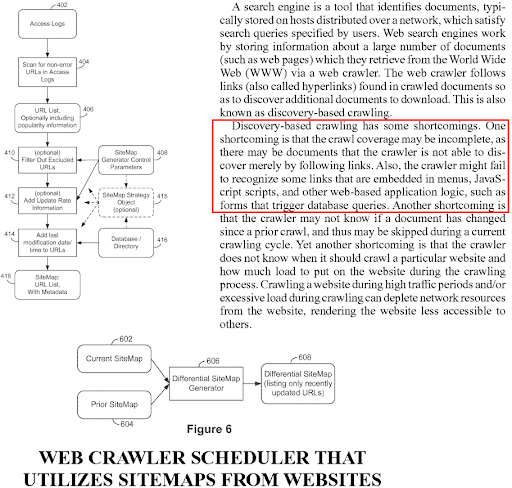
Bir arama motoru, web sitesi için bir site haritası oluşturabilir ve bağlantılar ve URL meta verileri, kullanıcı aracıları veya zaman çizelgeleri arasında eşleşmezse, bu site haritası bir döngü içinde yeniden oluşturulabilir. Bu nedenle, tarama yolunu kısa tutmak, tarama kuyruğunu kısa tutmak ve dahili bağlantıları tutarlı tutmak önemlidir.
Farklı web sayfaları arasındaki bağlantıların yanı sıra “içerik tablosu” ve “URL Fragmanları” ile web sayfalarının alt bölümlerine yönelik bağlantılar da kullanılmaktadır. Bu URL Parçaları, web sayfasının belirli bir alt bölümünü doğru bir şekilde adlandırırken hedefler ve belirli bölüm, h2 ile bir bölüm etiketine yerleştirilmiştir. “Sayfa içi gezinme bağlantılarına” sahip URL Fragmanları yardımıyla, bir kullanıcının SERP'den web sayfasının belirli bir bölümüne inmesi daha kolay olurken, içeriğin alt bölümleri, içeriğin arkasındaki ihtiyacı karşılamak için daha belirgin hale getirildi. sorgu.
5. SEO Projeleriniz İçin Askeri Düzeyde Bir Disiplininiz Olsun
Bu tamamen başka bir konudur ve askeri düzeydeki disiplinin ne anlama geldiğini veya bir SEO Projesi için neden yararlı olduğunu tanımlamak için başka bir makale yazılabilir. Ancak şunu söylemeliyim ki, bu son 2 ay boyunca, kurs tasarımımın iyi çalışıp çalışmayacağını görmek için ekipleriyle birlikte birçok CEO'yu ve diğer ajanslardan SEO'ları eğittim.
Yaptığım eğitimlerde ne zaman bir başarı, ne zaman yüksek bir kavrayış görsem, içimde güçlü bir irade ve azim var. Asıl sorun, Semantik SEO'nun diğer SEO Dikeylerinden çok daha zor olmasıdır. Teknik SEO evrenseldir ve hatta her adım için yazılı kılavuzlara sahiptir. OnPage SEO veya WUX ve Layout Design, sayısal ölçümlerle izlenebilir. Semantik denilince, karmaşık bir adaptif sistem üzerine çalışan bir makinenin bakış açısını, makinenin nasıl çalıştığını anlamayan homo-sapiens ile birleştirme pratiğidir.
Bu ayrım, projenin ilk gününden itibaren atılması gereken somut bir temel gerektirmektedir. Çoğu zaman aşağıdaki kuralları kullanırım.
- İçerik tasarımları ve anlamsal içerik ağı, bir yazar veya yazar için mantıklı olmak zorunda değildir.
- İçerik yöneticisinin görevi, içeriğin içerik tasarımıyla uyumluluğunu denetlemektir.
- Yazarın görevi, içeriği yüksek düzeyde doğruluk ve ayrıntı içeren ilgili bilgilerle yazmaktır.
- Bağlantılar, tanımlar, kanıtlar, karşılaştırmalar, önermeler, göndermeler hav ile değil somut örneklerle yapılmalıdır.
- Gereksiz her kelime, bağlam ve kavram için bir seyreltmedir.
Okuduğunuzda uygulaması kolay gelebilir ama o kadar kolay değil. Bu nedenle, kendi çalışanlarımdan bazılarını işten çıkarmak üzere olduğumu bile söyleyebilirim. En azından şimdilik yapmadığım için mutluyum. Normal şartlarda size sorulacak çok soru olacaktır, soru sahibi SEO veya firma sahibi değilse cevaplamayın. Enerjinizi, sıralamalara gereksiz ve alakasız geri bildirimleri değil, olumlu geri bildirimlerinizi depolayacak arama motorunun veri deposuna kaydedin.
6. Bağlamsal Uygunlukla Kaynağı Genişletin
Bu bölüm tamamen Google'ın MuM oluşturma ihtiyacını anlamakla ilgilidir. Bir Konu Haritası tasarladığınızda, site düzeyinde daha iyi bir Bilgi Tabanı sağlayacak çok sayıda Semantik İçerik Ağı içerecektir. Bu nedenle, bu alt bölümleri yayınlarken, kaynağın bağlamına bağlanabilmelidirler veya arama motorunun kaynağı nasıl gördüğünü değiştirebilir ve web sitesinin teması başka bir bilgi alanına geçebilir. Örneğin, kavramları ve ilgi alanlarını olası eylemlerle ilişkilendirmek, karmaşık anlamların birbirleriyle olan bağlantılarını anlamayı gerektirir. Bu bağlantıları bir kullanıcıya, bir yazara ve aynı zamanda bir makineye açık hale getirmek Semantik İçerik Ağı oluşturma sürecidir. 
Bunu başarmak için, web sitesinin her yeni bölümü, konu haritasının merkezi bölümüne bağlanabilmelidir. Bu bağlamsal köprüler, Google'ın kendi LaMDA tasarımı ve açıklamasından görülebilir.
“Başka bir konu hakkında mı yazayım”, “İki farklı nişim olsa zararı olur mu?” gibi pek çok soruyla karşılaşıyorum. Tüm bu alt bölümleri, web sitesi segmentlerini güçlü bağlantılı bileşenler olarak birleştirirseniz, bu anlamsal içerik ağları, marka kimliğini ve topikal otoriteyi iki farklı ve alakasız konu için bölmek yerine daha iyi sıralamalar için birbirini destekleyecektir.
7. Gerçek Trafik Oluşturun ve Google Analytics Özel Segmentasyonu ile denetleyin
Gerçek Trafik, Bilgi Tabanlı Güven'in PageRank'e bağlı olduğu şekilde RankMerge'e bağlanır. Yakında, arama motorunun neden PageRank'i yan sinyallerle etkilemeye çalıştığını açıklamak için “PageRank Yalan Olduğunda…” başlıklı başka bir makale yazmayı düşünüyorum. Aslında PageRank, bir kaynağın otoritesini, uzmanlığını ve güvenilirliğini gösteren kesin bir sinyal değildir. Sıralama için bir işaret ve bir faktör olabilir, ancak tek başına güvenilir olamaz. RankMerge, web sitesi trafiğini ve PageRank'i, web sitesinin arama motoruna anlamlı gelecek şekilde birleştirme işlemidir. Yüksek PageRank ve düşük trafik, "popüler olmayan trafiğin" veya "PageRank manipülasyonunun" sinyalini verebilir.
Bu nedenle, kaynağın geçmiş verilerini iyileştirmek için sezonluk SEO Etkinliklerini kullandım ve “marka + jenerik terim” sorgularını arttırdım. Doğrudan trafik ve işaretlenmiş web sayfaları, gerçek ve özgün trafikle artırılır.
Bu tür veriler, bir arama motorunun SERP'de daha üst sıralarda yer aldığı için ona güvenmesine yardımcı olur.
Semantik İçerik Ağı'ndan gelen bu gerçek trafiği denetleyebilmek için bir SEO, doğrudan trafik olarak nasıl geldiklerini görmek için Google Analytics'ten özel bir segment oluşturabilir. Ayrıca, ilk Semantik İçerik Ağından İkinci İçerik Ağı'na olası bir arama yolculuğu oluşturmak gibi özel Hedefler oluşturulabilir. Bu, anlamsal ağın ilgi alanları, kavramlar ve olası arama ile ilgili eylemler etrafında kurulduğunun kavramının kanıtıdır.
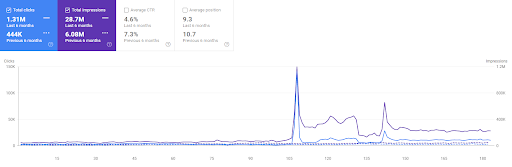
Aşağıda, organik trafik yoluyla elde edilen doğrudan trafiği göstermek için ilk Semantik İçerik Ağı'na yerleştirilen web sayfalarından biri için sadece bir örnek bulacaksınız. 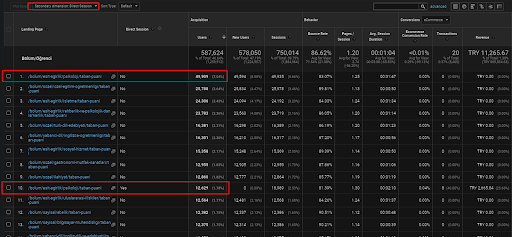
Son 3 ayda ilk anlamsal içerik ağından sadece bir web sayfası 49.000 organik kullanıcı tarafından kullanıldı. Ve ilk defa organik arama ile elde edilen direkt trafik olarak 12.900 ekstra kullanıcı geldi. Ayrıca, bu kullanıcı segmentleri için oturum/sayfa metrikleri ve ortalama oturum süresi daha yüksektir.
Daha önce de belirtildiği gibi, bir arama motoru sorguları, belgeleri, amaçları, kavramları, ilgi alanlarını, eylemleri kümeleyebilir, aynı zamanda kullanıcıları da kümeleyebilir. Bir kullanıcı grubu, bu web sayfalarını yer imlerine ekleyerek, doğrudan adres çubuğuna yazıp, marka adı ile birlikte jenerik terimleri aratarak bir marka değeri oluştururken olumlu geri bildirimler bırakırsa, kaynağın otoritesini ve arama motorunu geliştirdiğini gösterir. SERP, Chrome ve kendi DNS adreslerinden her şeyi tanıyabilir. 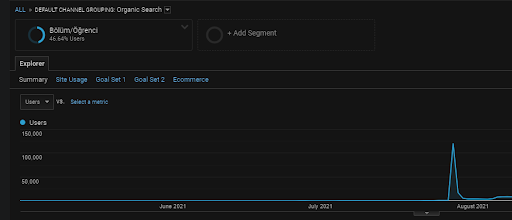
Yukarıda, First Content Network'ün kullanıcı segmentini görebilirsiniz. Her Semantik İçerik Ağı için özel hedeflerle bir kullanıcı segmenti oluşturabilir ve Semantik alt içerik ağları için de alt kullanıcı segmentleri ekleyebilirsiniz.
8. Arama Faaliyetlerine Dayalı Alt Bölümlerle Anlamsal İçerik Ağlarını Destekleyin
Bu bölüm ayrıca varlık öznitelik çözümlemesi ve başka bir konu olan analiz hakkındadır. Ancak, basitçe söylemek gerekirse, bağlamsal alanlara dayalı bu varlıkların bazı nitelikleri, üst hiyerarşiye değil, daha düşük bir hiyerarşiye yerleştirilmelidir. Bu durumda “Vizem.net” daha iyi bir örnek verebilirken Boğaziçi Enstitüsü için “Meslek Maaşları” ve “Üniversitelerin Sınav Puanları” ile gösterilebilir. Bu iki öne çıkan nitelik, sorgu ve belge şablonlarına dayalı olarak anlamsal alt içerik ağlarına yerleştirilmiştir. 
Bir arama sorgusu içinden Semantik Birimlerin Tanımlanması, ifadeleri farklı anlamsal kategorilere ayıran ve bir belgenin alaka düzeyini sorgunun tüm varyasyonlarına yakınlığına göre toplayan başka bir Google patentidir.
Daha önceki bir SEO Vaka Çalışmasında, bu tür bir yapıyı takip etmedim, “kronoloji” ve kesinlikle sınırlı iç bağlantılara dayalı bir tarama yolu oluşturdum. Bu yazılarda ana-içerik yerleştirilmiş iç link miktarı bir öncekinden daha fazladır.
9. URL'lerde Tematik Kelimeler Kullanın
Google, herhangi bir kanonikleştirme sinyali olmadan aynı içeriğe sahip iki farklı URL ile karşılaşırsa, kısa olanı kanonik olarak seçer. Çünkü kısa URL'lerin ayrıştırılması, çözülmesi ve talep edilmesi daha kolaydır. Her gün milyarlarca kez yenilediğiniz trilyonlarca web sayfanız olduğunda, URL'lerdeki harfler bile bir web sitesinin "maliyet/kalite dengesini" gösterebilir. Daha önce de söylediğim gibi, “almanın maliyeti”, “almamanın maliyetinden” daha düşük olmalıdır. Bir arama motoru tarafından anlaşılmak istiyorsanız, URL'ler de dahil olmak üzere her seviyeye “sıralı ve tamamlayıcı bağlam sinyalleri” koymalısınız. 
Kanıt toplama yoluyla "kanıta dayalı" sıralamadan bir bölüm. Bir cevabın bir soruyla nasıl eşleştirilebileceğini açıklar.
Bu bağlamda çoğu zaman URL içinde tek bir kelime kullanıyorum. Bunlar, anlamsal içerik ağının hiyerarşisini ve yapısını yansıtabilir. Bazıları hala URL'deki "katman sayısının" tarama sıklığını etkilediğini düşünüyor, 2019'dan önce bu doğruydu. Ancak içerik mantıklı olduğu ve kullanıcıları popüler veya öne çıkan bir konudan tatmin ettiği sürece böyle bir durumdan etkilenmeyecektir.
Bunu göstermek için aşağıdaki örneği takip edebilirsiniz.
- Kök-alan/semantik-içerik-ağ-1/tür-1/alt-içerik-ağ-bölüm-tür-1
- Kök-alan/semantik-içerik-ağ-2/tür-2/alt-içerik-ağ-bölüm-tür-2
Bu iki anlamsal içerik ağı, aynı hiyerarşiden birbirine bağlanabilir ve alaka düzeyine göre de kendilerini bağlayabilirler. Burada “Entity Grouper Contents – Hub Type Content” gibi bahsedebileceğimiz daha çok şey var ama başka bir günün konusu.
Not: Planlanan Üçüncü Semantik İçerik Ağı, “Kavramsal Gruplayıcı İçerik Ağı” olarak da işlenebilir. Ve eğer yayınlanırsa İkinci Semantik İçerik Ağının etkisiyle toplam Organik Trafik ayda 3 milyonun üzerinde oturum olabilir.
10. Yuvalama ve Bağlanma Arasındaki Farkı Anlayın
Pratik bir metodolojik fark olarak, bağlama, bağlamsal bir alana dayalı olarak benzer şeyleri birbirine bağlamaktır; yuvalama, benzer içeriği aynı amaç için bir arada gruplandırmaktır. Bu kümeleme, bir arama motorunun birbirine benzer içerikleri daha hızlı bulmasına ve bu gruplar için bir kaynak kalite puanı oluşturmasına yardımcı olacak veya anlamsal bir ağa dayalı bu iç içe içerikler daha kolay olacaktır. 
Aşağıdaki gibi iki farklı tarama yolu olduğunu hayal edin.
- Tarama Yolu 1: Bir şablon, benzerlik ve bağlamsal alaka düzeyi olmadan URL'lerle rastgele karşılaşır.
- Tarama Yolu 2: Bir şablon, bağlama dayalı yüksek düzeyde benzerlik ve alaka düzeyi ile URL'nin kendisinden bile anlamlı olan URL'lerle karşılaşır.
Tarama yolundan bile içerik mantıklı geliyorsa, “arama motorunun kapsam anlayışına dayalı yeniden sıralama tetiklemesi” sayesinde “ilk sıralama” ve “yeniden sıralama” daha iyi olacaktır.
Not: İç bağlantıların tümce-taksonomisi ile doğru bir şekilde kullanılması, yuvalama ve bağlantı için önemlidir.
Bu bizi kısaca son iki pratik metodoloji paylaşımına getiriyor. Ve bu bölüm yine üst düzey disiplin ve organizasyon yeterliliği ile ilgilidir. 
Trystan Upstill ve Steven D. Baker'dan HTML Listelerinde birlikte meydana gelen terimleri tanımak için bir patent. Bu patentin önemi, bir konu için birlikte ortaya çıkan terim listelerini veya ifade taksonomisinin bir bölümünü belirlemek için tek bir HTML Listesinin değerini göstermesidir.
11. Semantik İçerik Ağının Ne Zaman Düzenlenmiş Sıklıkta Yayınlanacağını Anlayın
Bu daha önce açıklanmıştır, ancak bu SEO Vaka Çalışması Projelerinden birinde bir günde yaklaşık 400 adet içerik yayınladım. Diğerine gelince, bir anda sadece 10-15 içerik yayınlamaya başladım, ardından Covid kaynaklı Ekonomik sorunlar başlayana kadar zamanla bir istikrarla hızımı arttırdım.
Yeni bir kaynak yeni bir Semantik İçerik Ağı oluşturursa, ilk gün yayınlamak düşündüğünüzden biraz daha zor olabilir, web sayfasındaki tüm dahili bağlantıları, gramerleri ve bilgileri kontrol etmek o kadar kolay değildir. Ancak, içeriğin tamamı tek bir konudan ve bir sorgu şablonundan oluşuyorsa ve kaynağın o konuyla ilgili bir geçmişi yoksa, anlamsal içerik ağının büyük bir bölümünü yayınlamak, daha hızlı indeksleme, anlama ve anlama gibi avantajlara sahiptir. yeniden sıralama.
Benim durumumda mevsimselliği olan tarihi bir olay da vardı. Bu yüzden amacım, arama motoru tarafından belirli varlıklar ve arama faaliyetleri için eski kaynaklara karşı test edilebilecek duruma gelene kadar yeterli düzeyde ortalama konuma sahip olmaktı. Böylece sezon etkinliğine 45 gün kala üst düzeyde hazırlıklı ilk Semantik İçerik Ağı'nı yayınlamış oldum.
Ardından, Arama Motorunun kaynağı tekrar tekrar nasıl test ettiğini aşağıdaki gibi görebilirsiniz. 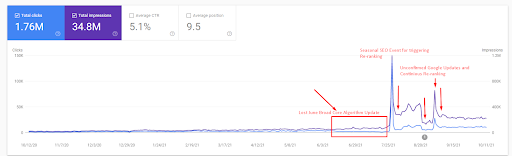
Daha ayrıntılı bir açıklama aşağıda bulunabilir. 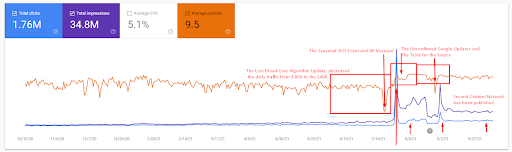
Yukarıdaki ekran görüntüsü açıklaması için aşağıda hızlı bir doğruluk kontrolü bulunabilir.
- Geniş Çekirdek Algoritma Güncellemesi, web sitesinin trafiğini %200'den fazla azalttı.
- Web sitesi ayrıca 15.000'den fazla sorguyu kaybetti.
- Bu, ayrıntılı SEO Case Study makalesinde daha iyi açıklandığı gibi, yeni semantik içerik ağı için kaynağın genel indekslenmesini etkiledi.
- Sezonluk SEO Etkinliği sayesinde, yeniden sıralama daha erken gerçekleşti ve sezonluk SEO Etkinliğinden sonra arama motoru, onaylanmamış güncellemeler sırasında gerçek trafiğe göre kaynağın sıralamasını normalleştirdi.
- First Semantic Content Network ve Seasonal Event sayesinde elde edilen sorgular ve sıralamalar korundu ve daha da geliştirildi.
- İlk Semantik İçerik Ağı, yeni ve ikinci Semantik İçerik Ağı'nı da destekledi.
Sorgu kaybı ve ortalama sıralama kaybı da aşağıdaki gibi Ahrefs'ten görülebilir. Haziran 2021 Google Geniş Çekirdek Algoritma Güncellemesi (GBCAU) efektini, onaylanmamış güncellemenin etkisiyle birlikte kontrol edebilirsiniz. 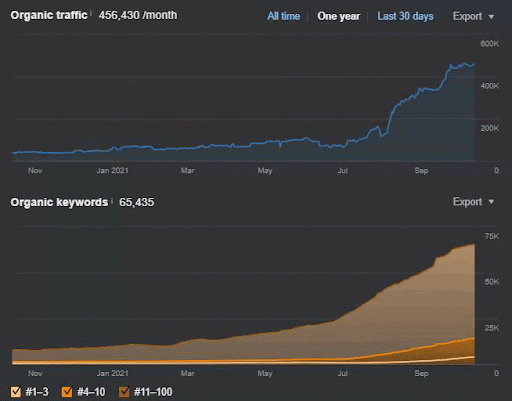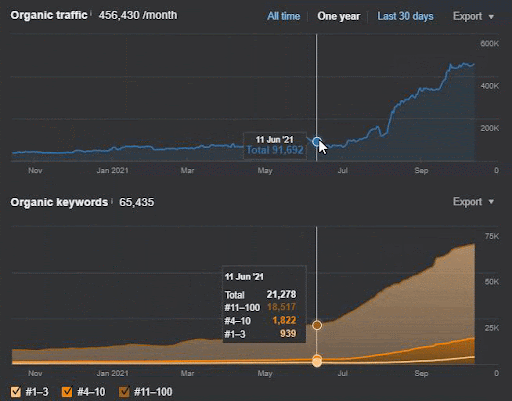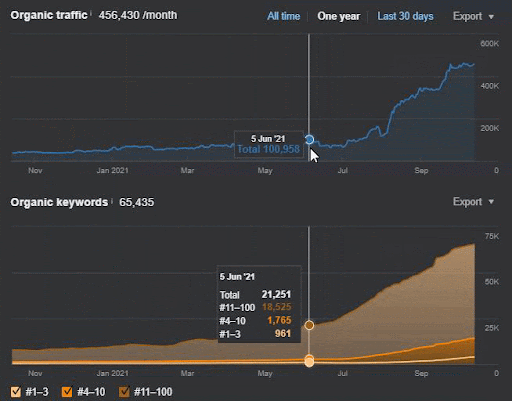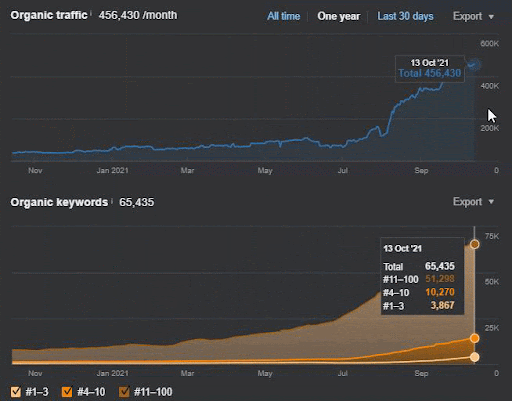
Bu nedenle, birden çok olası stratejiye sahip bir Semantik İçerik Ağı kullanmak bir zorunluluktur. GCBAU kaybolsa bile, yine de, arama motoru natura ile ilgili diğer faktörler sayesinde bir SEO'ya yardımcı olabilir. Bu nedenle, bunları bir yazara veya müşteriye açıklamanın neden Teknik SEO'dan daha zor olduğunu hayal edebilirsiniz. Semantik SEO sayısal değerler kullanmaz, patentler, araştırma makaleleri, deneyim ve tarihsel duyurular yoluyla Arama Motoru Anlayışından gelen Teorik Bilgiyi kullanır.
12. Daha İyi Olgusal Yapı için Sayfa İçi Cümle Optimizasyonu Kullanın
Dürüst olmak gerekirse, 10. sıra bile tamamen yeni bir konu ve buraya 20.000 kelime yazmak bile gerekebiliyor. Ancak basit bir örnekle başlayacağım.
- X, Y'dir.
- Y, X'tir.
Yukarıdaki örnek cümleler için aşağıdakileri anlayabilirsiniz.
- Yukarıdaki cümleler kopya içerik değildir.
- Yukarıdaki önermeler çifttir.
- İki cümle arasındaki ilişkisel açıklamalar aynıdır.
- Anlamsal Rol Etiketleri %100 farklıdır.
- Adlandırılmış Varlık Tanıma çıktısı %100 aynıdır.
Sayfa İçi Cümle Optimizasyonu, Soru Oluşturma Algoritmaları ve Soru-cevap eşleştirme teknolojileriyle ilgilidir. Bir soru formatı, belirli bir cümle türü gerektirir. Ve belirli türdeki sorulara, belirli tür cümlelerle cevap verilmelidir. İçerik formatı, NER ve Gerçek Çıkarma, cümle yapısı optimizasyonundan etkilenecektir. 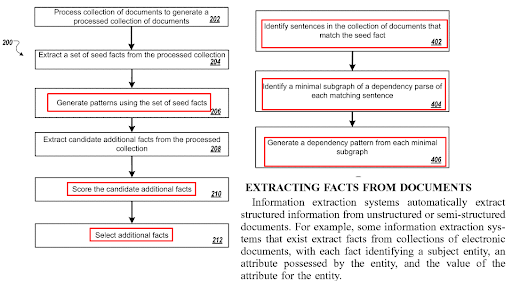
Üçlüler (bir nesne, iki özne) daha hızlı bir şekilde ayıklanabilir ve doğruluk açısından kontrol edilebilir. Birbirine benzeyen iki cümle, birbirinin tekrarı değil, cümle yapısı bakımından birbirine yakın oldukları anlamına gelir. Önerme farklı olduğu sürece, farklı sorgu-niyet çiftleri için benzer belge şablonları arasında benzer cümleler kullanmak, anlamsal içerik ağı oluşturmak için bir zorunluluktur. 
Uygun bir kalıba sahip net cümle yapıları, bir arama motorunun adlandırılmış varlıkları, konuları, nitelikleri ve bunların birbirlerine göre değerlerini tanımasına yardımcı olurken, metin parçalarını birbiriyle daha alakalı hale getirmek için yararlıdır.
Ayrıca, bir makalenin hangi bölümünün daha iyi hale getirilebileceğini ve içeriğinizin ne tür kelime çiftleri, kelime vektörleri ve niyetleri için daha iyi sıralandığı Topikal Ağlarda görmenize yardımcı olacaktır. Çünkü, birden fazla web sayfasında belirli soru türleri için belirli cümle yapıları gözlemlenebilirse, sonsuz miktarda veri örneği ve test örnekleri içeren Gelişmiş SEO A/B Testleri için yardımcı olacaktır. Bir arama motorunun gerçekleri karşılaştırmak için nasıl çıkardığını kontrol etmek için birden çok sayfa içi cümle tasarımı oluşturabilirsiniz. 
Gerçekleri vermeye gelince, “Bilgi Kasası” ve Luna Dong hatırlanmalıdır.
13. Kabarık Fikirler Değil, Gerçek Dünya Bilgilerini Kesinlik ve Tutarlılıkla Verin
Buradaki kesinlik, sayısal değerlerle veya kavramsal somut ilişkilerle karşılaştırılabilme anlamına gelir. Tutarlılık, belirli bir teklif için duruşunuzu koruduğunuz anlamına gelir. Örneğin, Y ile ilgili her ürün incelemesi için “X ürünü Y için en iyisidir” demeyin. Site genelinde birbiriyle çelişen önermeler vermeyin. Ve eğer ürün en iyisi ise, bunun kanıtı nedir? Malzeme, boyut veya renk ve koku? Metin içindeki havlama, gereksiz köprü sözcükleri kullanmanız, ispatı mümkün olmayan ya da gerçekle çelişen şeyler söylememeniz anlamına gelir.
Bazı örneklerle desteklenen bu tanımlayıcı olmayan talimatlar bağlamında, Google'ın Dil Modellerinden biri olan KeALM'i kontrol edebilirsiniz.
Veriden metne modeller ile bir veri tabanından metin üretmek içindir ve içeriğin doğruluğunu kontrol etmek içindir. 
KELM, metinden veriye yöntemleri olan önermeler için bir Doğruluk Denetimi örneğidir.
Bu da biraz “Üçlü” ve “Bilinmeyen Varlıklar İçin Açık Bilgi Çıkarımı” tanımıyla ilgili ama bildiğiniz gibi bu kısa versiyon ve sanırım yeterince anlattım. Temel olarak, web sitenizde yanlış bilgi verdiğinizde, kaynağın Bilgiye Dayalı Güvenini azaltmak için Google'ın bunu anlayabildiğinden emin olun. Burada, Bilgi Tabanını genişletebildiğiniz için, PageRank ve Bilgi Tabanı Güven ile İlişkili bir Kaynağınız varsa, bir arama motorunun bilgilerinize göre kendi bilgi tabanını değiştirebileceğini de bilmeniz gerekebilir. yüksek doğruluk ve benzersiz üçlüler ile.
14. Varlıklar için Anlamsal Bağımlılık Ağacını Anlayın
Anlamsal Bağımlılık Ağacı, diğer varlıklarla ilişkileri işaret eden niteliklerin aralarında hiyerarşik bir bağımlılığa sahip olduğu anlamına gelir. Anlamsal Bağımlılık Ağacı, bir ülkenin bir kuruluşa üye olabileceği gibi birden çok varlık profili ve açıları kontrol edilerek gözlemlenebilir ve başka bir varlık olarak, bu kuruluş, çıkarsanan ilişkilerle bağlantılı ülkelere atfedilebilecek başka niteliklere sahip olabilir.
Aşağıda, doğrudan Arama Motorundan basit bir örnek görebileceksiniz. 
REALM, belirsiz metinden bilgi çıkarmak için Anlamsal Bağımlılık Ağaçlarını kullanan bir yöntemdir.
Açık ağda, açık bilgi ayıklaması, yeni adlandırılmış varlıkları tanıyabilir ve bu aynı varlıkları diğer varlıklarla birlikte ortaya çıktıkları şekilde çıkarabilir. Makale içindeki bu birlikte oluşumlar ve karşılıklı nitelikler, varlıklar arasında bir bağlam ve aday ilişki türü atayabilir. Bağlantılara ve varlığın türüne göre anlamsal bağımlılık ağacı oluşturulabilir. Aynı mantık Sözlüksel Anlambilim için de geçerlidir. “Oğlan” kelimesinin bazı olası anlamları ve bazı kesin başka anlamları vardır. Örneğin, bir erkek bir erkektir ve muhtemelen evli olmayan bir gençtir. Öğrenciye yakın olarak da kullanılabilir. “Kraliçe” kelimesi ise “kadın”, “vali olmak” gibi diğer yan ve kesin anlamları içermektedir. Bu nedenle, yönetilecek bir şeye sahip olmak, “Queen of…” veya “For Quen” gibi bazı belirli sorgu şablonlarını işaret edebilen doğal bir anlamsal bağımlılık ağacı hiyerarşisidir. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 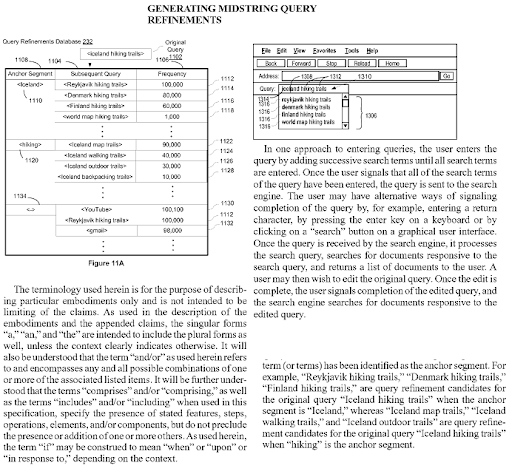
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.