
Tarama ve Dizine Eklemeyi Kontrol Etme: Robots.txt ve Etiketler için SEO Kılavuzu
Yayınlanan: 2019-02-19Tarama bütçesini optimize etmek ve botların sayfaları dizine eklemesini engellemek, birçok SEO uzmanının aşina olduğu kavramlardır. Ama şeytan ayrıntıda gizlidir. Özellikle en iyi uygulamalar son yıllarda önemli ölçüde değiştiği için.
Bir robots.txt dosyasında veya robots etiketlerinde yapılacak küçük bir değişiklik, web siteniz üzerinde önemli bir etkiye sahip olabilir. Etkisinin siteniz için her zaman olumlu olmasını sağlamak için bugün şunları inceleyeceğiz:
Tarama Bütçesini Optimize Etme
Robots.txt Dosyası Nedir?
Meta Robot Etiketleri Nedir?
X-Robots-Etiketler nelerdir
Robot Yönergeleri ve SEO
En İyi Uygulama Robotları Kontrol Listesi
Tarama Bütçesini Optimize Etme
Bir arama motoru örümceğinin sitenizde kaç sayfa tarayabileceği ve taramak istediği konusunda bir "ödeneği" vardır. Bu, "tarama bütçesi" olarak bilinir.
Google Arama Konsolu (GSC) "Tarama İstatistikleri" raporunda sitenizin tarama bütçesini bulun. GSC'nin tümü SEO'ya tahsis edilmemiş 12 bottan oluşan bir toplam olduğunu unutmayın. Ayrıca, SEA botları olan AdWords veya AdSense botlarını da toplar. Bu nedenle, bu araç size global tarama bütçeniz hakkında bir fikir verir, ancak tam olarak yeniden bölümlendirilmesi hakkında bilgi vermez.
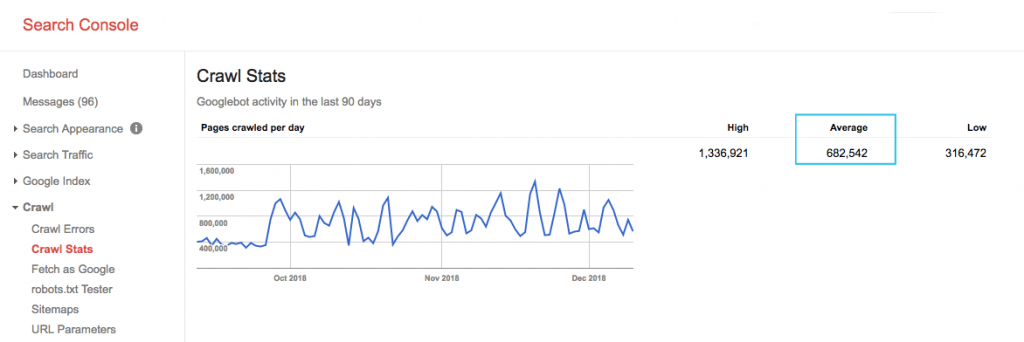
Sayıyı daha uygulanabilir hale getirmek için, günde taranan ortalama sayfa sayısını sitenizdeki toplam taranabilir sayfaya bölün; bu sayıyı geliştiricinizden isteyebilir veya sınırsız bir site tarayıcısı çalıştırabilirsiniz. Bu, optimizasyona başlamanız için size beklenen bir tarama oranı verecektir.
Daha derine inmek ister misin? Sitenizin sunucu günlük dosyalarını analiz ederek, diğer tarayıcıların istatistiklerinin yanı sıra hangi sayfaların ziyaret edildiği gibi Googlebot etkinliğinin daha ayrıntılı bir dökümünü alın.
Tarama bütçesini optimize etmenin birçok yolu vardır, ancak başlamak için kolay bir yer, Google'ın mevcut tarama ve dizine ekleme davranışını anlamak için GSC "Kapsam" raporunu kontrol etmektir.
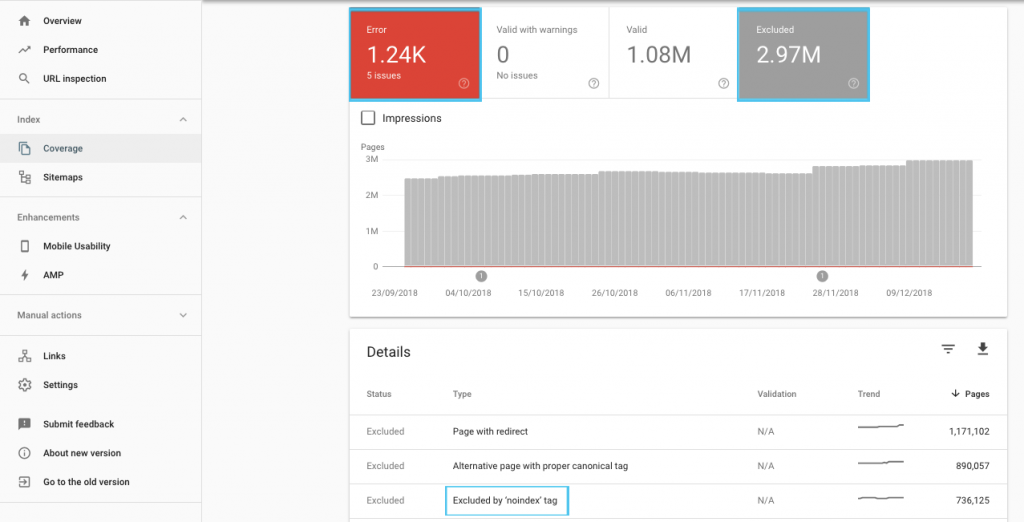
"Gönderilen URL 'noindex' olarak işaretlendi" veya "Gönderilen URL robots.txt tarafından engellendi" gibi hatalar görürseniz, bunları düzeltmek için geliştiricinizle birlikte çalışın. Herhangi bir robot hariç tutma için, bir SEO perspektifinden stratejik olup olmadıklarını anlamak için onları araştırın.
Genel olarak, SEO'lar robotlardaki tarama kısıtlamalarını en aza indirmeyi hedeflemelidir. URL'leri arama motorları için kullanışlı ve erişilebilir kılmak için web sitenizin mimarisini geliştirmek en iyi stratejidir.
Google, "sağlam bir bilgi mimarisinin, tarama önceliğine odaklanmaktan çok daha verimli bir kaynak kullanımı olacağını" belirtiyor.
Bununla birlikte, tarama, indeksleme ve bağlantı eşitliğinin geçişine rehberlik etmesi için robots.txt dosyaları ve robot etiketleri ile neler yapılabileceğini anlamak faydalıdır. Ve daha da önemlisi, modern SEO için bundan en iyi şekilde ne zaman ve nasıl yararlanılacağı.
[Örnek Olay] Google'ın bot taramasını yönetme
 Örnek olayı okuyun
Örnek olayı okuyunRobots.txt Dosyası Nedir?
Bir arama motoru herhangi bir sayfayı taramadan önce robots.txt dosyasını kontrol eder. Bu dosya, botlara hangi URL yollarını ziyaret etme iznine sahip olduklarını söyler. Ancak bu girdiler sadece direktiflerdir, emirler değil.
Robots.txt, bir güvenlik duvarı veya parola koruması gibi taramayı güvenilir bir şekilde engelleyemez . Kilidi açılmış bir kapıdaki “lütfen girmeyin” işaretinin dijital karşılığıdır.
Büyük arama motorları gibi kibar tarayıcılar genellikle talimatlara uyar. Site güvenlik açıklarını tarayan e-posta kazıyıcıları, spam robotları, kötü amaçlı yazılımlar ve örümcekler gibi düşmanca tarayıcılar genellikle hiç dikkat etmez.
Dahası, bu herkese açık bir dosyadır . Yönergelerinizi herkes görebilir.
robots.txt dosyanızı şu amaçlarla kullanmayın:
- Hassas bilgileri gizlemek için. Parola koruması kullanın.
- Hazırlama ve/veya geliştirme sitenize erişimi engellemek için. Sunucu tarafı kimlik doğrulamasını kullanın.
- Düşman tarayıcıları açıkça engellemek için. IP engellemeyi veya kullanıcı aracısı engellemeyi kullanın (diğer bir deyişle, .htaccess dosyanızdaki bir kural veya CloudFlare gibi bir araçla belirli bir tarayıcı erişimini engelleyin).
Her web sitesinde en az bir yönerge gruplaması olan geçerli bir robots.txt dosyası olmalıdır. Biri olmadan, tüm botlara varsayılan olarak tam erişim verilir - bu nedenle her sayfa taranabilir olarak kabul edilir. Niyetiniz bu olsa bile, bunu bir robots.txt dosyasıyla tüm paydaşlar için netleştirmek daha iyidir. Ayrıca, bir tane olmadan, sunucu günlükleriniz robots.txt için başarısız isteklerle dolu olacaktır.
robots.txt dosyasının yapısı
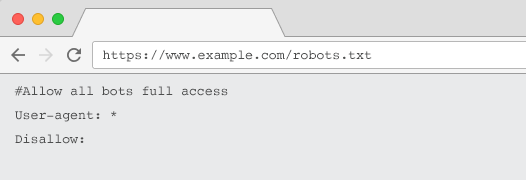
Tarayıcılar tarafından onaylanması için robots.txt dosyanız:
- “robots.txt” adlı bir metin dosyası olun. Dosya adı büyük/küçük harf duyarlıdır. “Robots.TXT” veya diğer varyasyonlar çalışmaz.
- Kurallı alan adınızın ve varsa alt alan adlarının en üst düzey dizininde yer alın. Örneğin, https://www.example.com altındaki tüm URL'lerde taramayı kontrol etmek için robots.txt dosyası https://www.example.com/robots.txt adresinde ve subdomain.example.com için şu adreste bulunmalıdır: subdomain.example.com/robots.txt.
- 200 OK HTTP durumunu döndür.
- Geçerli robots.txt sözdizimini kullanın – Google Arama Konsolu robots.txt test aracını kullanarak kontrol edin.
Bir robots.txt dosyası, yönerge gruplarından oluşur. Girişler çoğunlukla şunlardan oluşur:
- 1. Kullanıcı aracısı: Çeşitli tarayıcılara hitap eder. Tüm robotlar için bir grubunuz olabilir veya belirli arama motorlarını adlandırmak için grupları kullanabilirsiniz.
- 2. İzin Verme: Yukarıdaki kullanıcı aracısı tarafından taranmaktan hariç tutulacak dosya veya dizinleri belirtir. Blok başına bu satırlardan bir veya daha fazlasına sahip olabilirsiniz.
Kullanıcı aracısı adlarının tam listesi ve daha fazla yönerge örneği için Yoast'taki robots.txt kılavuzuna bakın.
“User-agent” ve “Disallow” direktiflerine ek olarak, standart olmayan bazı direktifler de vardır:
- İzin Ver: Bir üst dizin için izin verilmeyen yönergeye ilişkin istisnaları belirtin.
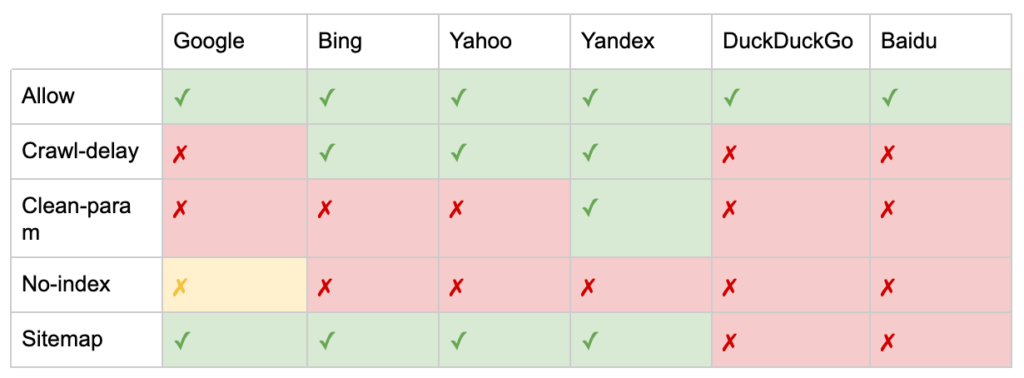
- Tarama gecikmesi: Bir sayfayı ziyaret etmeden önce botlara kaç saniye beklemeleri gerektiğini söyleyerek ağır tarayıcıları kısıtlayın. Birkaç organik oturum alıyorsanız, tarama gecikmesi sunucu bant genişliğinden tasarruf sağlayabilir. Ancak, yalnızca tarayıcılar aktif olarak sunucu yükleme sorunlarına neden oluyorsa çaba harcardım. Google bu komutu kabul etmez, Google Arama Konsolunda tarama hızını sınırlama seçeneği sunar.
- Clean-param: Dinamik parametreler tarafından oluşturulan yinelenen içeriği yeniden taramaktan kaçının.
- İndeks yok: Herhangi bir tarama bütçesi kullanmadan indekslemeyi kontrol etmek için tasarlanmıştır. Artık resmi olarak Google tarafından desteklenmiyor. Hala etkisi olabileceğine dair kanıtlar olsa da, güvenilir değildir ve John Mueller gibi uzmanlar tarafından önerilmemektedir.
@maxxeight @google @DeepCrawl Orada noindex kullanmaktan gerçekten kaçınırdım.
— ???? John ???? (@JohnMu) 1 Eylül 2015
- Site Haritası: XML site haritanızı göndermenin en uygun yolu Google Arama Konsolu ve diğer arama motorunun Web Yöneticisi Araçları'dır. Ancak robots.txt dosyanızın tabanına bir site haritası yönergesi eklemek, gönderme seçeneği sunmayan diğer tarayıcılara yardımcı olur.
SEO için robots.txt sınırlamaları
robots.txt dosyasının tüm botlar için taramayı engelleyemeyeceğini zaten biliyoruz. Aynı şekilde, bir sayfadaki tarayıcılara izin vermemek, o sayfanın arama motoru sonuç sayfalarına (SERP'ler) dahil edilmesini engellemez.
Engellenen bir sayfanın başka güçlü sıralama sinyalleri varsa, Google, sayfanın arama sonuçlarında gösterilmesiyle alakalı olduğunu düşünebilir. Sayfayı taramamış olmasına rağmen.
Bu URL'nin içeriği Google tarafından bilinmediğinden arama sonucu şöyle görünür:

Bir sayfanın SERP'lerde görünmesini kesin olarak engellemek için bir "noindex" robots meta etiketi veya X-Robots-Tag HTTP başlığı kullanmanız gerekir.
Bu durumda robots.txt içindeki sayfaya izin vermeyin çünkü “noindex” etiketinin görülebilmesi ve uyulması için sayfanın taranması gerekir. URL engellenirse, tüm robot etiketleri etkisizdir.
Ayrıca, bir sayfa çok sayıda gelen bağlantı aldıysa, ancak Google'ın bu sayfaları taraması robots.txt tarafından engellendiyse ve bağlantılar Google tarafından biliniyorsa bağlantı değeri kaybedilir.
Meta Robot Etiketleri Nedir?
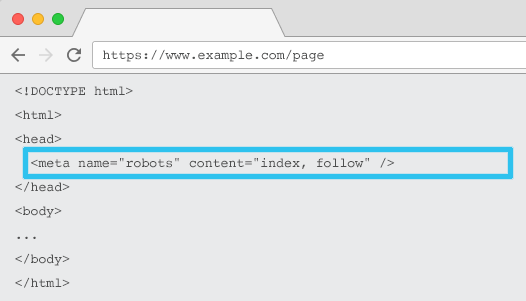
Her bir URL'nin HTML'sine yerleştirilen meta name=”robots”, tarayıcılara içeriğin "indekslenmesi" ve "izlenmesi" (yani, taranması) ile bağlantı eşitliği yoluyla tüm sayfa bağlantılarının "takip edilip edilmeyeceğini" (yani, taranıp taranmayacağını) söyler.
Genel meta name=“robots” kullanıldığında, yönerge tüm tarayıcılara uygulanır. Ayrıca belirli bir kullanıcı aracısı belirtebilirsiniz. Örneğin, meta adı = ”googlebot”. Ancak belirli örümcekler için talimatlar ayarlamak için birden fazla meta robot etiketi kullanmaya ihtiyaç duyulması nadirdir.
Meta robot etiketlerini kullanırken iki önemli nokta vardır:
- Robots.txt'ye benzer şekilde, meta etiketler direktiflerdir, zorunlu değildir, bu nedenle bazı botlar tarafından yoksayılabilir.
- Robots nofollow yönergesi yalnızca o sayfadaki bağlantılar için geçerlidir. Bir tarayıcının, nofollow olmadan başka bir sayfadan veya web sitesinden gelen bağlantıyı takip etmesi mümkündür. Böylece bot yine de istenmeyen sayfanıza ulaşabilir ve dizine ekleyebilir.
İşte tüm meta robot etiketi direktiflerinin listesi:
- index: Arama motorlarına bu sayfayı arama sonuçlarında göstermelerini söyler. Bu, herhangi bir yönerge belirtilmemişse varsayılan durumdur.
- noindex: Arama motorlarına bu sayfayı arama sonuçlarında göstermemelerini söyler.
- takip et: Arama motorlarına bu sayfadaki tüm bağlantıları takip etmelerini ve sayfa dizine eklenmemiş olsa bile eşitliği geçmelerini söyler. Bu, herhangi bir yönerge belirtilmemişse varsayılan durumdur.
- nofollow: Arama motorlarına bu sayfadaki herhangi bir bağlantıyı takip etmemelerini veya eşitlikten geçmemelerini söyler.
- tümü: "indeks, takip et" ile eşdeğerdir.
- yok: “noindex, nofollow” ile eşdeğerdir.
- noimageindex: Arama motorlarına bu sayfadaki hiçbir görseli dizine eklememelerini söyler.
- noarchive: Arama motorlarına, arama sonuçlarında bu sayfaya önbelleğe alınmış bir bağlantı göstermemelerini söyler.
- nocache: Noarchive ile aynıdır, ancak yalnızca Internet Explorer ve Firefox tarafından kullanılır.
- nosnippet: Arama motorlarına, arama sonuçlarında bu sayfa için bir meta açıklama veya video önizlemesi göstermemelerini söyler.
- notranslate: Arama motoruna bu sayfanın çevirisini arama sonuçlarında sunmamasını söyler.
- unavailable_after: Arama motorlarına belirli bir tarihten sonra bu sayfayı artık indekslememesini söyleyin.
- noodp: Artık kullanımdan kaldırıldı, bir zamanlar arama motorlarının arama sonuçlarında DMOZ'daki sayfa açıklamasını kullanmasını engelledi.
- noydir: Artık kullanımdan kaldırıldı, bir zamanlar Yahoo'nun arama sonuçlarında Yahoo dizinindeki sayfa açıklamasını kullanmasını engelledi.
- noyaca: Yandex'in arama sonuçlarında Yandex dizinindeki sayfa açıklamasını kullanmasını engeller.
Yoast tarafından belgelendiği gibi, tüm arama motorları tüm robot meta etiketlerini desteklemez veya ne yaptıkları ve desteklemedikleri bile net değildir.
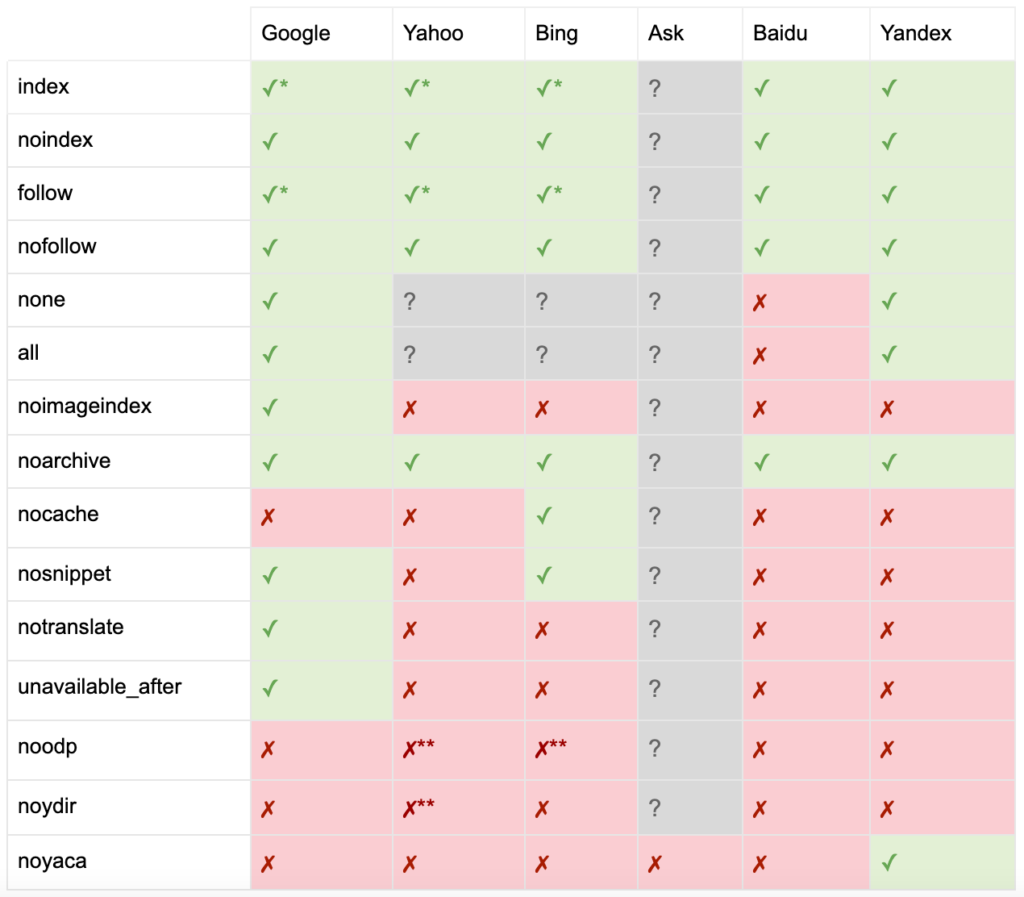
* Çoğu arama motorunun bunun için özel bir dokümantasyonu yoktur, ancak parametreleri hariç tutma desteğinin (örn. nofollow) pozitif eşdeğeri (örn., takip et) desteklediğini varsaymaktadır.
** noodp ve noydir öznitelikleri hala 'destekleniyor' olsa da, dizinler artık mevcut değil ve muhtemelen bu değerler hiçbir şey yapmıyor.

Genellikle robot etiketleri "indeks, takip et" olarak ayarlanır. Bazı SEO'lar, bu etiketi HTML'ye eklemeyi varsayılan olduğu kadar gereksiz görür. Karşı argüman, direktiflerin net bir şekilde belirtilmesinin, herhangi bir insan karışıklığının önlenmesine yardımcı olabileceğidir.
Şunu unutmayın: "noindex" etiketine sahip URL'ler daha az taranır ve uzun süredir mevcutsa, sonunda Google'ın sayfanın bağlantılarını izlememesine neden olur.
Meta robots etiketine sahip bir sayfadaki tüm bağlantıları "nofollow" yapmak için bir kullanım örneği bulmak nadirdir. Bir rel=”nofollow” bağlantı özniteliği kullanılarak bireysel bağlantılara “nofollow” eklendiğini görmek daha yaygındır. Örneğin, kullanıcı tarafından oluşturulan yorumlara veya ücretli bağlantılara rel=”nofollow” özelliği eklemeyi düşünebilirsiniz.
Önbelleğe alma, görüntü indeksleme ve snippet işleme vb. gibi temel indeksleme ve takip davranışlarını ele almayan robot etiketi direktifleri için bir SEO kullanım örneğine sahip olmak daha da nadirdir.
Meta robot etiketleriyle ilgili zorluk, bunların resim, video veya PDF belgeleri gibi HTML olmayan dosyalar için kullanılamamasıdır. Burası X-Robots-Tags'e dönebileceğiniz yerdir.
X-Robots-Etiketler nelerdir
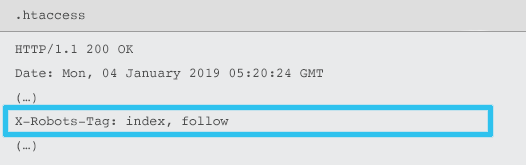
X-Robots-Tag, sunucu tarafından .htaccess ve httpd.conf dosyalarını kullanan belirli bir URL için HTTP yanıt başlığının bir öğesi olarak gönderilir.
Herhangi bir robots meta etiketi yönergesi, bir X-Robots-Tag olarak da belirtilebilir. Bununla birlikte, bir X-Robots-Tag, bazı ek esneklik ve işlevsellik sunar.
Aşağıdakileri yapmak istiyorsanız, meta robot etiketleri üzerinde X-Robots-Tag'i kullanırsınız:
- Yalnızca HTML dosyaları yerine HTML olmayan dosyalar için robotların davranışını kontrol edin.
- Sayfanın tamamı yerine sayfanın belirli bir öğesinin indekslenmesini kontrol edin.
- Bir sayfanın dizine eklenip eklenmeyeceğine ilişkin kurallar ekleyin. Örneğin, bir yazarın 5'ten fazla yayınlanmış makalesi varsa, profil sayfasını indeksleyin.
- Sayfaya özel değil, site genelinde dizin uygulayın ve yönergeleri izleyin.
- Normal ifadeler kullanın.
Aynı sayfada hem meta robotları hem de x-robots etiketini kullanmaktan kaçının - bunu yapmak gereksiz olacaktır.
X-Robots-Tags'i görüntülemek için Google Search Console'daki "Google Gibi Getir" özelliğini kullanabilirsiniz.
Robot Yönergeleri ve SEO
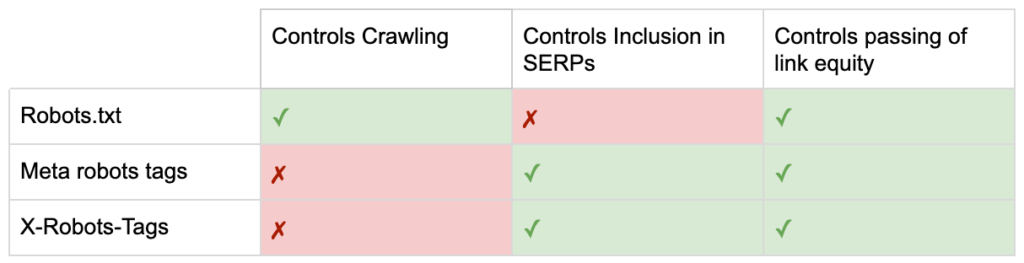
Artık üç robot yönergesi arasındaki farkları biliyorsunuz.
robots.txt, tarama bütçesinden tasarruf etmeye odaklanır, ancak bir sayfanın arama sonuçlarında gösterilmesini engellemez. Web sitenizin ilk bekçisi olarak görev yapar ve botları sayfa istenmeden önce erişmemeye yönlendirir.
Her iki robot etiketi türü de indekslemeyi ve link eşitliğinin geçişini kontrol etmeye odaklanır. Robots meta etiketleri, yalnızca sayfa yüklendikten sonra etkilidir. X-Robots-Tag başlıkları daha ayrıntılı kontrol sunar ve sunucu bir sayfa isteğine yanıt verdikten sonra etkilidir.
Bu anlayışla SEO'lar, tarama ve indeksleme zorluklarını çözmek için robot direktiflerini kullanma şeklimizi geliştirebilir.
Sunucu Bant Genişliğini Kaydetmek için Botları Engelleme
Sorun: Günlük dosyalarınızı analiz ederken, birçok kullanıcı aracısının bant genişliği aldığını ancak çok az değer verdiğini göreceksiniz.
- MJ12bot (Majestic'ten) veya Ahrefsbot (Ahrefs'ten) gibi SEO tarayıcıları.
- Webcopier veya Teleport gibi dijital içeriği çevrimdışına kaydeden araçlar.
- Baiduspider veya Yandex gibi pazarınızla alakalı olmayan arama motorları.
Yetersiz çözüm: Bu örümcekleri robots.txt ile engellemek, onurlandırılacağı garanti edilmez ve ilgili taraflara rekabet bilgileri verebilecek daha çok kamuya açık bir bildiridir.
En iyi uygulama yaklaşımı: Daha incelikli kullanıcı aracısı engelleme yönergesi. Bu, farklı yollarla gerçekleştirilebilir, ancak genellikle .htaccess dosyanızı istenmeyen örümcek isteklerini 403 – Yasaklanmış bir sayfaya yönlendirmek için düzenleyerek yapılır.
Tarama Bütçesini Kullanan Dahili Site Arama Sayfaları
Sorun: Birçok web sitesinde, dahili site arama sonucu sayfaları statik URL'lerde dinamik olarak oluşturulur, bu daha sonra tarama bütçesini tüketir ve dizine eklenirse yetersiz içerik veya yinelenen içerik sorunlarına neden olabilir.
Alt optimal çözüm: robots.txt içeren dizine izin vermeyin. Bu, tarayıcı tuzaklarını önleyebilse de, önemli müşteri aramaları için sıralama yeteneğinizi ve bu tür sayfaların bağlantı eşitliğini geçmesini sınırlar.
En iyi uygulama yaklaşımı: Alakalı, yüksek hacimli sorguları mevcut arama motoru dostu URL'lerle eşleyin. Örneğin, /search/samsung-phone için yeni bir sayfa oluşturmak yerine "samsung phone" için arama yaparsam, /phones/samsung'a yönlendirin.
Bunun mümkün olmadığı durumlarda, parametre tabanlı bir URL oluşturun. Ardından, parametrenin taranmasını isteyip istemediğinizi Google Search Console'da kolayca belirleyebilirsiniz.
Taramaya izin veriyorsanız, bu tür sayfaların sıralama için yeterince yüksek kalitede olup olmadığını analiz edin. Değilse, hem SEO'ya hem de kullanıcı deneyimine yardımcı olmak için sonuç kalitesini nasıl iyileştireceğinizi stratejilerken kısa vadeli bir çözüm olarak bir "noindex, takip et" yönergesi ekleyin.
Robotlarla Parametreleri Engelleme
Sorun: Yönlü gezinme veya izleme tarafından oluşturulanlar gibi sorgu dizesi parametreleri, tarama bütçesini tüketmek, yinelenen içerik URL'leri oluşturmak ve sıralama sinyallerini bölmekle ünlüdür.
Alt optimal çözüm: Parametrelerin robots.txt veya "noindex" robots meta etiketi ile taranmasına izin vermeyin, çünkü her ikisi de (birincisi hemen, daha sonra daha uzun bir süre boyunca) bağlantı eşitliği akışını önleyecektir.
En iyi uygulama yaklaşımı: Her parametrenin var olmak için açık bir nedeni olduğundan emin olun ve anahtarları yalnızca bir kez kullanan ve boş değerleri önleyen sıralama kurallarını uygulayın. Sıralama yeteneğini birleştirmek için uygun parametre sayfalarına bir rel=canonical bağlantı niteliği ekleyin. Ardından, tarama tercihlerini iletmek için daha ayrıntılı seçeneğin bulunduğu Google Arama Konsolunda tüm parametreleri yapılandırın. Daha fazla ayrıntı için Arama Motoru Dergisi'nin parametre işleme kılavuzuna bakın.
Yönetici veya Hesap Alanlarını Engelleme
Sorun: Arama motorunun herhangi bir özel içeriği taramasını ve dizine eklemesini önleyin.
Alt optimal çözüm: Özel sayfaları SERP'lerin dışında tutma garantisi olmadığından dizini engellemek için robots.txt kullanmak.
En iyi uygulama yaklaşımı: Tarayıcıların sayfalara erişmesini ve HTTP başlığında "noindex" yönergesinin geri çekilmesini önlemek için parola koruması kullanın.
Pazarlama Açılış Sayfalarını ve Teşekkür Sayfalarını Engelleme
Sorun: Genellikle, özel e-posta veya TBM kampanyası açılış sayfaları gibi organik aramaya yönelik olmayan URL'leri hariç tutmanız gerekir. Aynı şekilde, dönüşüm gerçekleştirmemiş kişilerin SERP'ler aracılığıyla teşekkür sayfalarınızı ziyaret etmesini istemezsiniz.
Yetersiz çözüm: Bağlantının arama sonuçlarına eklenmesini engellemeyeceğinden robots.txt içeren dosyalara izin vermeyin.
En iyi uygulama yaklaşımı: Bir "noindex" meta etiketi kullanın.
Site İçi Yinelenen İçeriği Yönetin
Sorun: Bazı web siteleri, bir sayfanın yazıcı dostu sürümü gibi kullanıcı deneyimi nedenleriyle belirli içeriğin bir kopyasına ihtiyaç duyuyor, ancak yinelenen sayfanın değil standart sayfanın arama motorları tarafından tanınmasını istiyor. Diğer web sitelerinde, yinelenen içerik, aynı öğenin birden çok kategori URL'sinde satışa sunulması gibi zayıf geliştirme uygulamalarından kaynaklanmaktadır.
Alt optimal çözüm: robots.txt içeren URL'lere izin verilmemesi, yinelenen sayfanın herhangi bir sıralama sinyali iletmesini engeller. Robotlar için noindexing, sonunda Google'ın bağlantıları "nofollow" olarak ele almasına yol açacak ve yinelenen sayfanın herhangi bir bağlantı eşitliğinden geçmesini önleyecektir.
En iyi uygulama yaklaşımı: Yinelenen içeriğin var olması için bir neden yoksa, kaynağı kaldırın ve 301'i arama motoru dostu URL'ye yönlendirin. Var olmak için bir neden varsa, sıralama sinyallerini konsolide eden bir rel=canonical link niteliği ekleyin.
Erişilebilir Hesapla İlgili Sayfaların İnce İçeriği
Sorun: Oturum açma, kayıt olma, alışveriş sepeti, ödeme veya iletişim formları gibi hesapla ilgili sayfalar genellikle içerik açısından hafiftir ve arama motorlarına çok az değer sunar, ancak kullanıcılar için gereklidir.
Yetersiz çözüm: Bağlantının arama sonuçlarına eklenmesini engellemeyeceğinden robots.txt içeren dosyalara izin vermeyin.
En iyi uygulama yaklaşımı: Çoğu web sitesi için bu sayfaların sayısı çok az olmalıdır ve robot işleme uygulamasının hiçbir KPI etkisi görmeyebilirsiniz. İhtiyaç hissediyorsanız, bu tür sayfalar için arama sorguları olmadığı sürece bir “noindex” yönergesi kullanmak en iyisidir.
Tarama Bütçesini Kullanarak Sayfaları Etiketleyin
Sorun: Kontrolsüz etiketleme, tarama bütçesini tüketiyor ve genellikle yetersiz içerik sorunlarına yol açıyor.
Optimum olmayan çözümler: Robots.txt ile izin verilmemesi veya bir "noindex" etiketi eklenmesi, çünkü her ikisi de SEO ile ilgili etiketlerin sıralamasını engelleyecek ve (hemen veya sonunda) bağlantı eşitliğinin geçmesini önleyecektir.
En iyi uygulama yaklaşımı: Mevcut etiketlerinizin her birinin değerini değerlendirin. Veriler, sayfanın arama motorlarına veya kullanıcılara çok az değer kattığını gösteriyorsa, 301 onları yönlendirir. Kaldırımdan kurtulan sayfalar için, hem kullanıcılar hem de botlar için değerli hale gelmeleri için sayfadaki öğeleri iyileştirmeye çalışın.
JavaScript ve CSS Tarama
Sorun: Önceden, botlar JavaScript'i ve diğer zengin medya içeriğini tarayamıyordu. Bu değişti ve isteğe bağlı olarak sayfaları oluşturmak için arama motorlarının JS ve CSS dosyalarına erişmesine izin verilmesi şiddetle tavsiye ediliyor.
Optimum olmayan çözüm: Tarama bütçesinden tasarruf etmek için robots.txt içeren JavaScript ve CSS dosyalarına izin verilmemesi, zayıf dizine eklemeye ve sıralamaları olumsuz etkileyebilir. Örneğin, bir reklam geçiş reklamı sunan veya kullanıcıları yönlendiren JavaScript'e arama motorunun erişimini engellemek, gizleme olarak görülebilir.
En iyi uygulama yaklaşımı: "Google Gibi Getir" aracıyla oluşturma sorunlarını kontrol edin veya her ikisi de Google Arama Konsolunda bulunan "Engellenen Kaynaklar" raporuyla hangi kaynakların engellendiğine dair hızlı bir genel bakış alın. Arama motorlarının sayfayı düzgün bir şekilde oluşturmasını engelleyebilecek herhangi bir kaynak engellenirse, robots.txt izin vermeme özelliğini kaldırın.
Oncrawl SEO Tarayıcısı
 Daha fazla bilgi edin
Daha fazla bilgi edinEn İyi Uygulama Robotları Kontrol Listesi
Bir web sitesinin, bir robot kontrol hatası tarafından yanlışlıkla Google'dan kaldırılması korkutucu derecede yaygındır.
Bununla birlikte, nasıl kullanılacağını bildiğinizde, robotların kullanımı, SEO cephaneliğinize güçlü bir katkı olabilir. Sadece akıllıca ve dikkatli bir şekilde ilerlediğinizden emin olun.
Yardımcı olmak için işte hızlı bir kontrol listesi:
- Parola koruması kullanarak özel bilgilerin güvenliğini sağlayın
- Sunucu tarafı kimlik doğrulamasını kullanarak geliştirme sitelerine erişimi engelleyin
- Bant genişliği alan ancak kullanıcı aracısı engelleme ile çok az değer sunan tarayıcıları kısıtlayın
- Birincil alan adının ve tüm alt alan adlarının üst düzey dizinde 200 kod döndüren "robots.txt" adlı bir metin dosyasına sahip olduğundan emin olun
- robots.txt dosyasının kullanıcı aracısı satırı ve izin verilmeyen satırı olan en az bir bloğu olduğundan emin olun
- robots.txt dosyasının son satır olarak girilen en az bir site haritası satırına sahip olduğundan emin olun
- GSC robots.txt test cihazında robots.txt dosyasını doğrulayın
- Dizine eklenebilir her sayfanın robot etiketi yönergelerini belirttiğinden emin olun
- robots.txt, robots meta etiketleri, X-Robots-Tags, .htaccess dosyası ve GSC parametre işleme arasında çelişkili veya gereksiz yönergeler olmadığından emin olun
- GSC kapsam raporunda herhangi bir "Gönderilen URL 'noindex' olarak işaretlendi" veya "Gönderilen URL robots.txt tarafından engellendi" hatalarını düzeltin
- GSC kapsam raporunda robotlarla ilgili istisnaların nedenini anlayın
- GSC "Engellenen Kaynaklar" raporunda yalnızca ilgili sayfaların gösterildiğinden emin olun
Gidip robotlarınızın kullanımını kontrol edin ve doğru yaptığınızdan emin olun.