
10 Yaygın Teknik SEO sorunu – ve nasıl tespit edilir
Yayınlanan: 2019-06-04Bir dizi endüstride SEO hizmetleri yürüttükten sonra, özellikle WordPress, Shopify veya SquareSpace gibi ortak bir CMS üzerinde çalışırken bazen ortak sorunları yakalayabilirsiniz.
Burada, bir web sitesini optimize ederken karşılaşabileceğiniz oldukça yaygın 10 teknik SEO sorununu özetledim.
Bu sorunların sizin veya müşteriniz için kesinlikle sorunlu olacağını söylemiyorum – çoğu zaman bağlam hala çok önemlidir. Her zaman tüm çözümlere uyan tek bir çözüm yoktur, ancak yine de aşağıda özetlenen senaryolara karşı dikkatli olmak iyidir.
1 – Googlebot'a erişimi engelleyen Robots.txt dosyası
Bu, çoğu teknik SEO uzmanı için yeni bir şey değildir, ancak robot dosyasını kontrol etmeyi ihmal etmek hala çok kolaydır - ve sadece teknik bir denetim yürütme noktasında değil, yinelenen bir kontrol olarak.
Google'ın erişim sorunları olup olmadığını incelemek için Search Console (eski sürüm) gibi bir araç kullanabilir veya OnCrawl gibi bir araçla sitenizi Googlebot olarak taramayı deneyebilirsiniz (yalnızca Kullanıcı Aracısını seçin). OnCrawl, siz aksini söylemediğiniz sürece robots.txt dosyasına uyacaktır.
Tarama sonuçlarını dışa aktarın ve sitenizdeki bilinen bir sayfa listesiyle karşılaştırın ve tarayıcıda kör nokta olup olmadığını kontrol edin.
Bunun hala oldukça sık olduğunu ve bazı oldukça büyük sitelerde olduğunu göstermek için, birkaç hafta önce Pingdom'un Hız Testi aracının Google'da engellendiğini fark ettim.
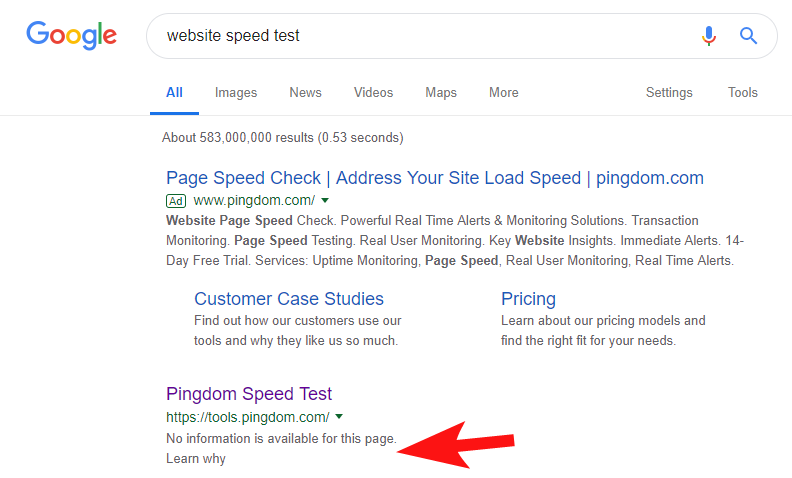
Robot dosyalarına bakmak (ve ardından Googlebot olarak OnCrawl'dan sayfalarını taramaya çalışmak), sitelerine erişimi engellediklerine dair şüphelerimi doğruladı.
Suçlu robots.txt dosyası aşağıda gösterilmiştir:

Onlara bir "Bilginize" ile ulaştım ancak yanıt alamadım, ancak birkaç gün sonra her şeyin normale döndüğünü gördüm. Phew - Tekrar kolayca uyuyabilirim!
Onların durumunda, sitenizi hız denetiminin bir parçası olarak taradığınızda, yukarıdaki robots dosyasında vurgulanan karma karakteri içeren bir URL oluşturuyor gibi görünüyordu.
Belki bunlar taranıyordu ve hatta bir şekilde indeksleniyordu ve bunu kontrol etmek istiyorlardı (ki bu çok anlaşılır olurdu). Bu durumda, muhtemelen potansiyel etkiyi tam olarak test etmediler - ki bu muhtemelen sonunda minimum oldu.
İşte ilgilenen herkes için mevcut robotları.

Bazı durumlarda, Internet Wayback Machine'i kullanarak tarihi robots.txt dosyası değişikliklerine erişebileceğinizi belirtmekte fayda var. Tecrübelerime göre bu, tahmin edebileceğiniz gibi daha büyük sitelerde en iyi sonucu verir – bunlar çok daha sık Wayback Machine arşivleyicisi tarafından taranır.
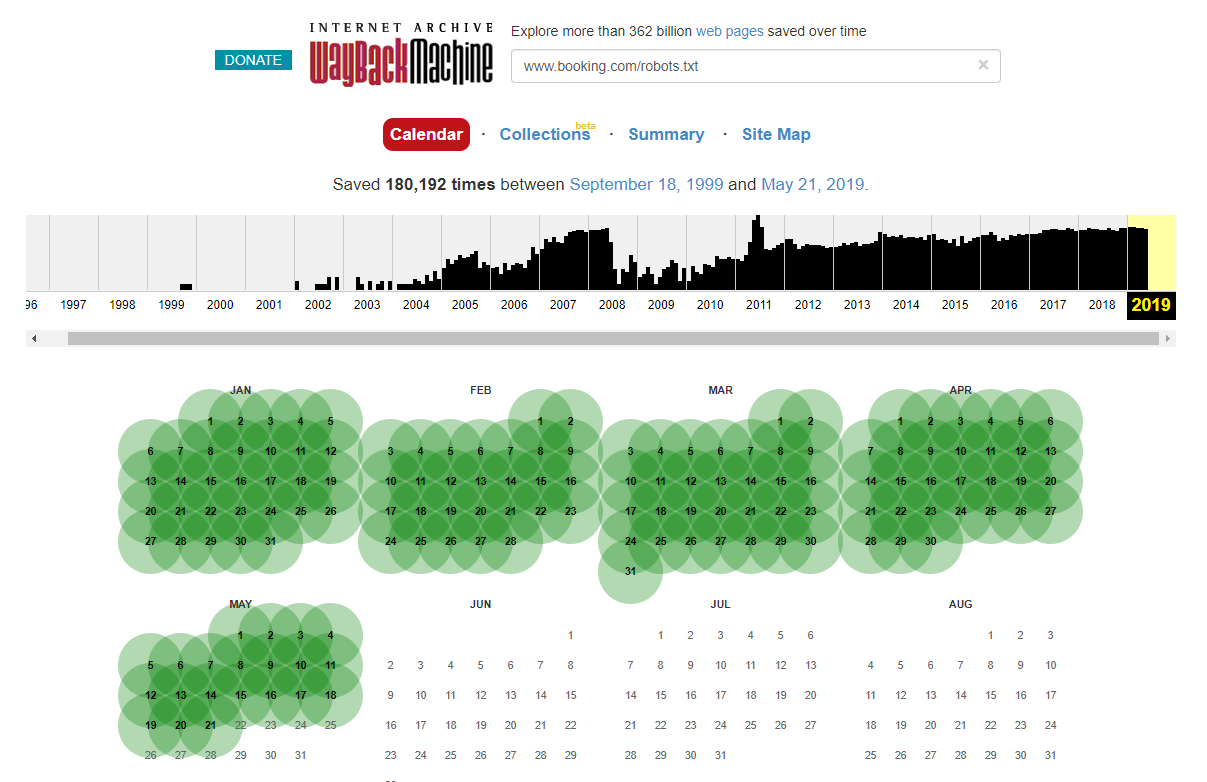
SERPS'de biraz hasara neden olan, vahşi doğada canlı bir robots.txt dosyasını ilk kez görmüyorum. Ve kesinlikle son olmayacak – ihmal edilmesi çok basit bir şey (sonuçta kelimenin tam anlamıyla tek bir dosya) ama onu kontrol etmek her SEO'nun devam eden çalışma programının bir parçası olmalıdır.
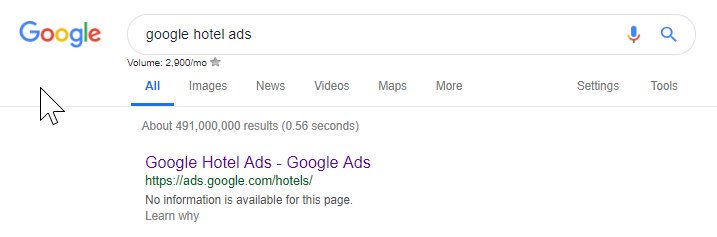
Yukarıdan, Google'ın bile bazen robots dosyalarını karıştırdığını ve içeriklerine erişmelerini engellediğini görebilirsiniz. Bu kasıtlı olabilirdi, ancak aşağıdaki robot dosyalarının diline baktığımda bundan bir şekilde şüpheliyim.
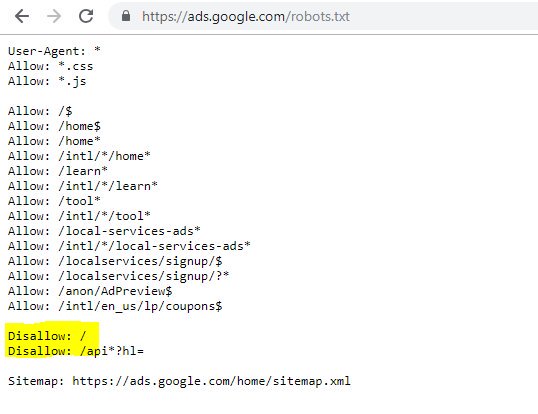
Vurgulanan İzin Verme: / bu durumda herhangi bir URL yoluna erişimi engelledi; bunun yerine sitenin taranmaması gereken belirli bölümlerini listelemek daha güvenli olurdu.
2 – DNS Düzeyinde Etki Alanı Yapılandırma Sorunları
Bu şaşırtıcı derecede yaygın bir durumdur, ancak genellikle hızlı bir düzeltmedir. Bu, teknik SEO'nun sevdiği düşük maliyetli, *potansiyel olarak* yüksek etkili SEO değişikliklerinden biridir.
Genellikle SSL uygulamalarında, 302'nin bir sonraki URL'ye yeniden yönlendirilmesi ve bir zincir oluşturması veya en kötü durum senaryosunun hiç yüklenmemesi gibi WWW olmayan etki alanı sürümünün doğru şekilde yapılandırıldığını göremiyorum.
Burada iyi bir örnek, Hotel Football web sitesidir.
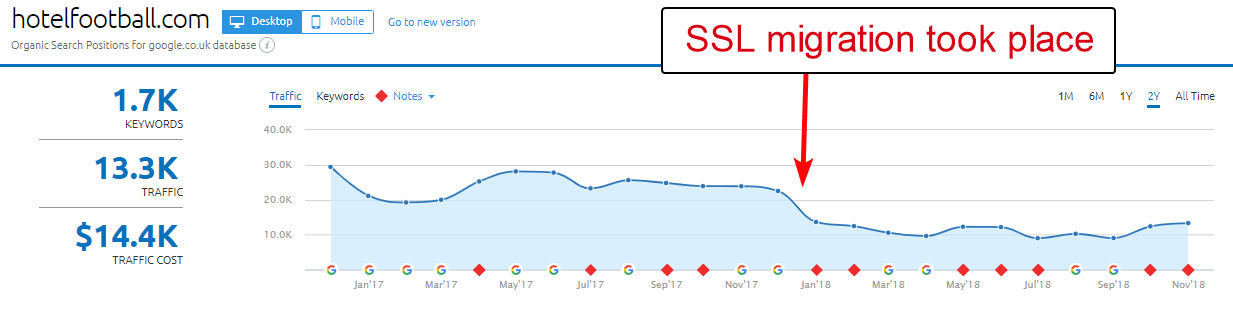
Geçen yılın başlarında bir SSL geçişinden geçtiler ve bu, SEMRush'ın yukarıdaki alan genel bakış raporuna bakılırsa onlar için pek iyi sonuçlanmadı.
Seyahat ve konaklama endüstrisinde çok çalıştığım için bunu bir süre önce fark etmiştim - ve keskin bir futbol sevgisiyle web sitelerinin nasıl olduğunu görmek ilgimi çekti (artı tabii ki organik olarak nasıl gidiyor! ).
Bunu teşhis etmek aslında çok kolaydı – sitede, tümü http://www.hotelfootball.com/ adresindeki SSL olmayan, WWW alanına işaret eden tonlarca son derece iyi geri bağlantı vardı.
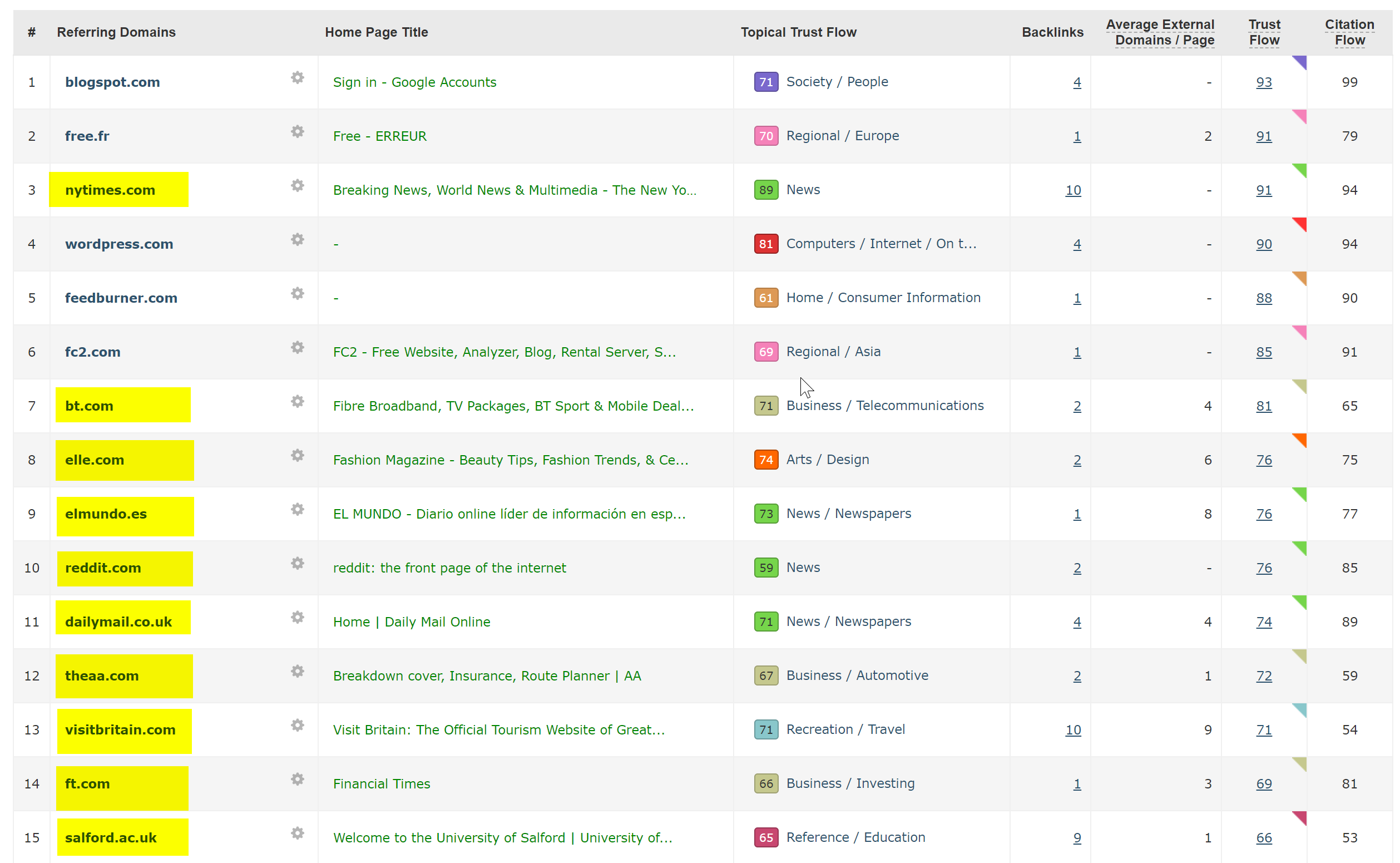
Yine de yukarıdaki URL'ye erişmeyi denerseniz, yüklenmez. Hata. Ve en azından yaklaşık 18 aydır böyle. Siteyi yöneten ajansa Twitter üzerinden haber vermek için ulaştım, ancak yanıt alamadım.
Bununla yapmaları gereken tek şey, etki alanının “WWW” sürümü için doğru IP adresini gösteren bir “A” kaydı ile DNS bölgesi ayarlarının doğru olduğundan emin olmaktır (bir CNAME de işe yarayacaktır). Bu, etki alanının çözümlenmemesini önleyecektir.
Tek dezavantajı veya bunun çözülmesinin bu kadar uzun sürmesinin nedeni, bir sitenin alan yönetim paneline erişmenin zor olabilmesi, hatta şifrelerin kaybedilmiş olması veya yüksek öncelikli olarak görülmemesidir.
Alan adının anahtarlarını elinde tutan, teknik bilgisi olmayan bir kişiye düzeltme talimatları göndermek de her zaman iyi bir fikir değildir.
Yukarıdaki ayarlamayı yapabildiklerinde/yapabildiklerinde organik etkiyi görmek isterim – özellikle WWW olmayan alanın otelin eski Manchester United futbolcuları Gary Neville, Ryan Giggs tarafından açılmasından bu yana oluşturduğu tüm geri bağlantıları göz önünde bulundurarak ve şirket.
Otel adları için Google'da 1. sırada yer alsalar da (tahmin edeceğiniz gibi), daha rekabetçi, markasız arama terimlerinin hiçbiri için güçlü sıralamalara sahip görünmüyorlar (şu anda 10. sıradalar). Google'da "Old Trafford yakınlarındaki otel" için).
Yukarıdakilerle biraz kendi kalesine gol attılar - ancak bu sorunu çözmek en azından bunu çözmenin bir yolunu bulabilir.
Oncrawl SEO Tarayıcısı
 Daha fazla bilgi edin
Daha fazla bilgi edin3 – XML Site Haritasındaki Hileli Sayfalar
Yine bu oldukça basit ama garip bir şekilde yaygın – bir sitelerin XML site haritasını incelerken (neredeyse her zaman domain.com/sitemap.xml veya domain.com/sitemap_index.xml'dedir), burada listelenen ve gerçekten alakasız sayfalar olabilir. indekslenmeye gerek yok.
Tipik suçlular arasında gizli teşekkür sayfaları (bir iletişim formu gönderdiğiniz için teşekkürler), yinelenen içerik sorunlarına neden olabilecek PPC açılış sayfaları veya başka bir yerde indekslemediğiniz diğer sayfa/yazı/taksonomi biçimleri bulunur.
Bunları XML site haritasına yeniden dahil etmek, arama motorlarına çelişkili sinyaller gönderebilir - gerçekten yalnızca bulmalarını ve dizine eklemelerini istediğiniz sayfaları listelemelisiniz, bu esas olarak site haritasının amacıdır.
Artık, URL'yi Denetle seçeneği aracılığıyla sayfaların bir site XML site haritasına dahil edilip edilmediğini öğrenmek için Search Console'daki kullanışlı raporu kullanabilirsiniz.
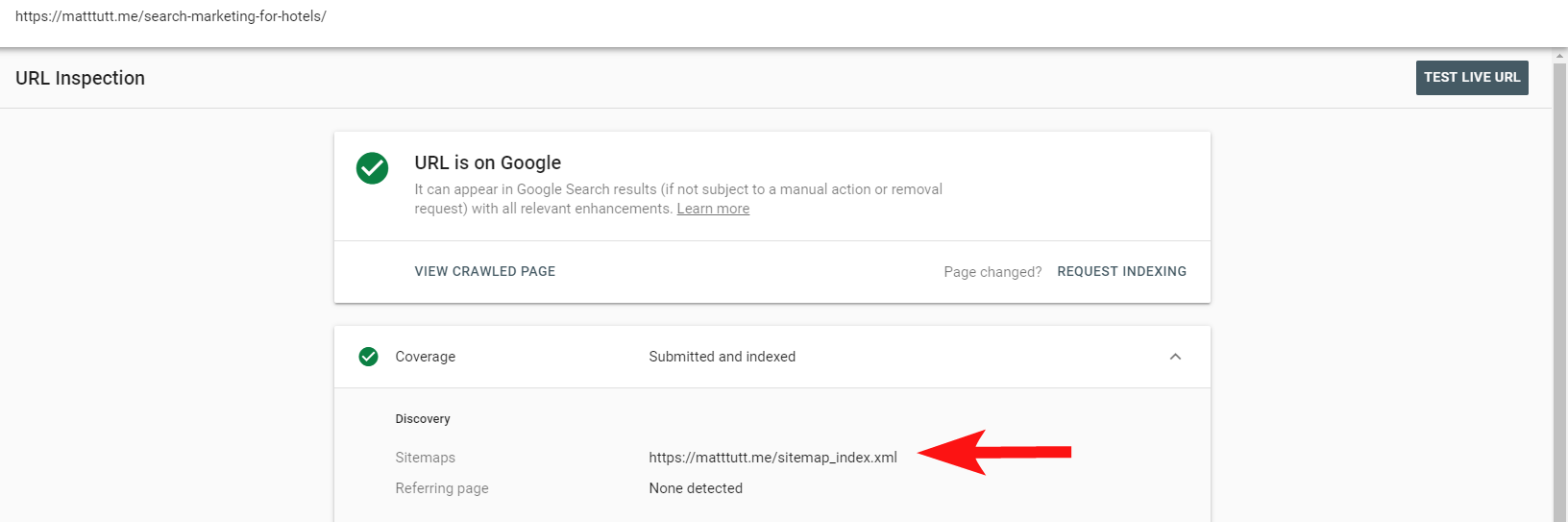
Oldukça küçük bir siteniz varsa, muhtemelen XML site haritanızı tarayıcınızda manuel olarak inceleyebilirsiniz - aksi takdirde indirin ve dizine eklenebilir URL'lerinizin tam taramasıyla karşılaştırın.
Genellikle bu tür düşük kaliteli, paha biçilmez içeriği, dizine eklenmiş her şeyi döndürmek için Google'da bir site:domain.com araması yaparak yakalayabilirsiniz.
Burada bunun eski içeriği içerebileceğini ve %100 güncel olduğuna güvenilmemesi gerektiğini belirtmekte fayda var, ancak SEO çabalarınızı şişiren ve tarama bütçelerini tüketen tekneler dolusu içerik olmadığından emin olmak için kolay bir kontrol.
4 – İçeriğinizi Oluşturan Googlebot ile İlgili Sorunlar
Bu, kendisine adanmış bir makalenin tamamına layık ve kişisel olarak, Google'ın getirme ve oluşturma aracıyla bir ömür geçirmiş gibi hissediyorum.
Bu (ve JavaScript hakkında) çok yetenekli SEO'lar tarafından zaten çok şey söylendi, bu yüzden bunu çok derinlemesine incelemeyeceğim, ancak Googlebot'un sitenizi nasıl oluşturduğunu kontrol etmek her zaman zaman ayırmaya değer.
Çevrimiçi araçlar aracılığıyla birkaç kontrol yapmak, Googlebot'un kör noktalarını (sitede erişemedikleri alanlar), barındırma ortamınızla ilgili sorunları, sorunlu JavaScript kaynaklarını yakmayı ve hatta ekran ölçekleme sorunlarını ortaya çıkarmaya yardımcı olabilir.
Normalde bu üçüncü taraf araçlar, sorunu teşhis etmede oldukça yardımcıdır (örneğin, robotlar dosyanız nedeniyle bir kaynağın engellendiğini Google bile söyler) ancak bazen kendinizi çevrelerde dolaşırken bulabilirsiniz.
Sorunlu bir sitenin canlı örneğini göstermek için kendimi ayağımdan vuracağım ve kendi kişisel web siteme ve kullandığım özellikle sinir bozucu bir WordPress temasına atıfta bulunacağım.
Bazen Search Console'dan bir URL Denetimi çalıştırırken “Sayfa mobil uyumlu değil” uyarısı alıyorum (aşağıya bakın).
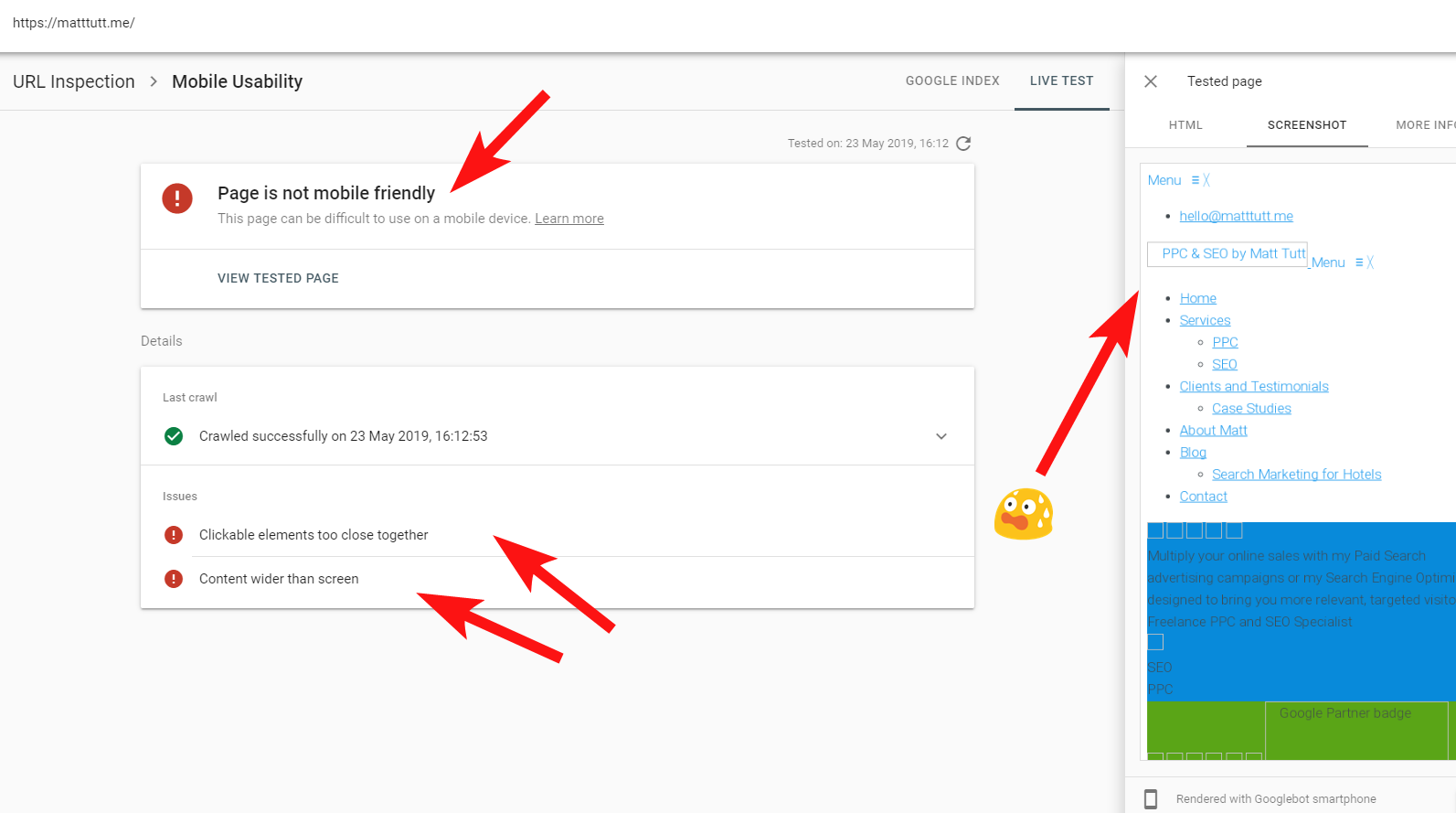
Daha Fazla Bilgi sekmesini (sağ üstte) tıkladığınızda, o zaman Googlebot tarafından erişilemeyen, çoğunlukla CSS ve resim dosyaları olan kaynakların bir listesini verir.
Bu, Googlebot'un sayfayı oluşturmak için her zaman tam "enerjisini" verememesi muhtemeldir - bazen bunun nedeni, Google'ın sitemi çökertmekten çekinmesidir (ki bu bir tür sitedir) ve diğer zamanlarda, onların kullandıkları kadar sınırlı olabilirim. sitemi almak ve işlemek için çok fazla kaynak var.
Bazen yukarıdakilerden dolayı, daha gerçek bir hikaye elde etmek için bu testleri dağınık aralıklarla birkaç kez çalıştırmaya değer. Ayrıca, Googlebot'un site içeriğinize nasıl eriştiğini (veya erişmediğini) kontrol etmek için mümkünse sunucu günlüklerini kontrol etmenizi de öneririm.
404'ler veya bu kaynaklar için diğer kötü durumlar, özellikle tutarlıysa, açıkça kötü bir işaret olacaktır.
Benim durumumda, Google, siteyi mobil uyumlu olmadığı için çağırıyor; bu, esas olarak, belirli CSS stil dosyalarının oluşturma sırasında başarısız olmasının bir sonucudur ve bu, haklı olarak alarm zillerini çalabilir.
Google'ın Mobil Dostu Testini çalıştırırken veya başka herhangi bir üçüncü taraf aracı kullanırken sorunları daha da kafa karıştırıcı hale getirmek için herhangi bir sorun algılanmaz: site mobil uyumludur.
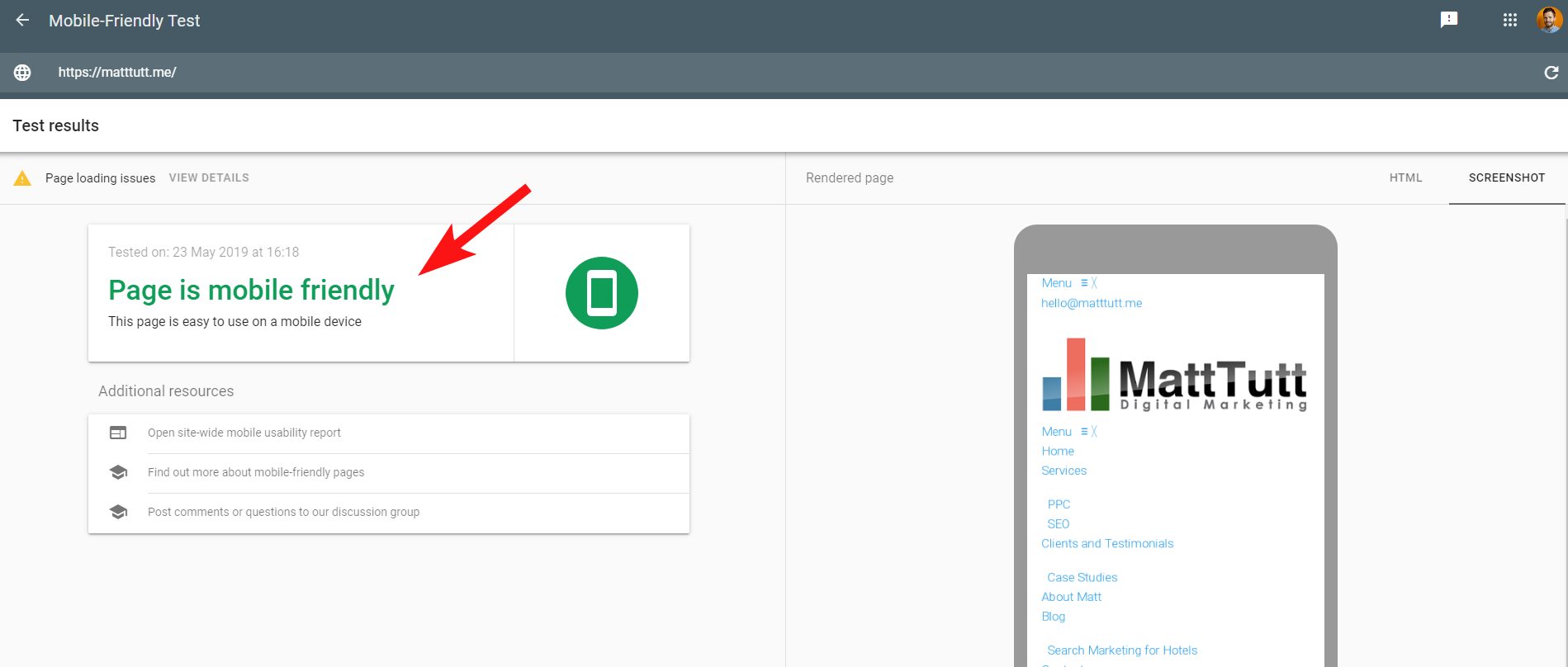
Google'dan gelen bu çelişkili mesajların kodunu çözmesi SEO'lar ve web geliştiricileri için zor olabilir. Daha fazla anlamak için web barındırıcımı kontrol etmemi (sorun yok) ve CSS dosyasının gerçekten Google tarafından önbelleğe alınabileceğini öneren John Mueller'e ulaştım.
Search Console, Mobil Dostu Araçla karşılaştırıldığında daha eski bir Web Oluşturma Hizmeti (WRS) kullanır, bu nedenle günümüzde ikincisine daha fazla ağırlık verme eğilimindeyim.
Google, en son oluşturma özelliklerine sahip daha yeni bir Googlebot'u duyurduğunda, bunların tümü değişebilir, bu nedenle, kontrolleri oluşturmak için en iyi hangi araçların kullanılacağı konusunda güncel kalmaya değer.
Burada başka bir ipucu – bir sayfanın tam kaydırılabilir bir görüntüsünü görmek istiyorsanız, Google'ın mobil test aracından HTML sekmesine geçebilir, oluşturulan tüm HTML kodunu vurgulamak için CTRL+A'ya basabilir, ardından kopyalayıp bir metin düzenleyiciye yapıştırabilir ve HTML dosyası olarak kaydedin.
Bunu tarayıcınızda açmanız (parmaklar çarpıştı, bazen kullanılan CMS'ye bağlıdır!) size kaydırılabilir bir görüntü verecektir. Bunun avantajı, herhangi bir sitenin nasıl oluşturulduğunu kontrol edebilmenizdir - Search Console erişimine ihtiyacınız yoktur.
5 – Saldırıya Uğramış Siteler ve İstenmeyen Geri Bağlantılar
Bu, WordPress'in eski sürümlerinde veya düzenli güvenlik güncellemeleri gerektiren diğer CMS platformlarında çalışan sitelere yakalanması oldukça eğlencelidir ve genellikle gizlice girebilir.
Bu müşteriyle (bir güzellik spası), Search Console'da görünen bazı garip arama terimleri fark ettim.
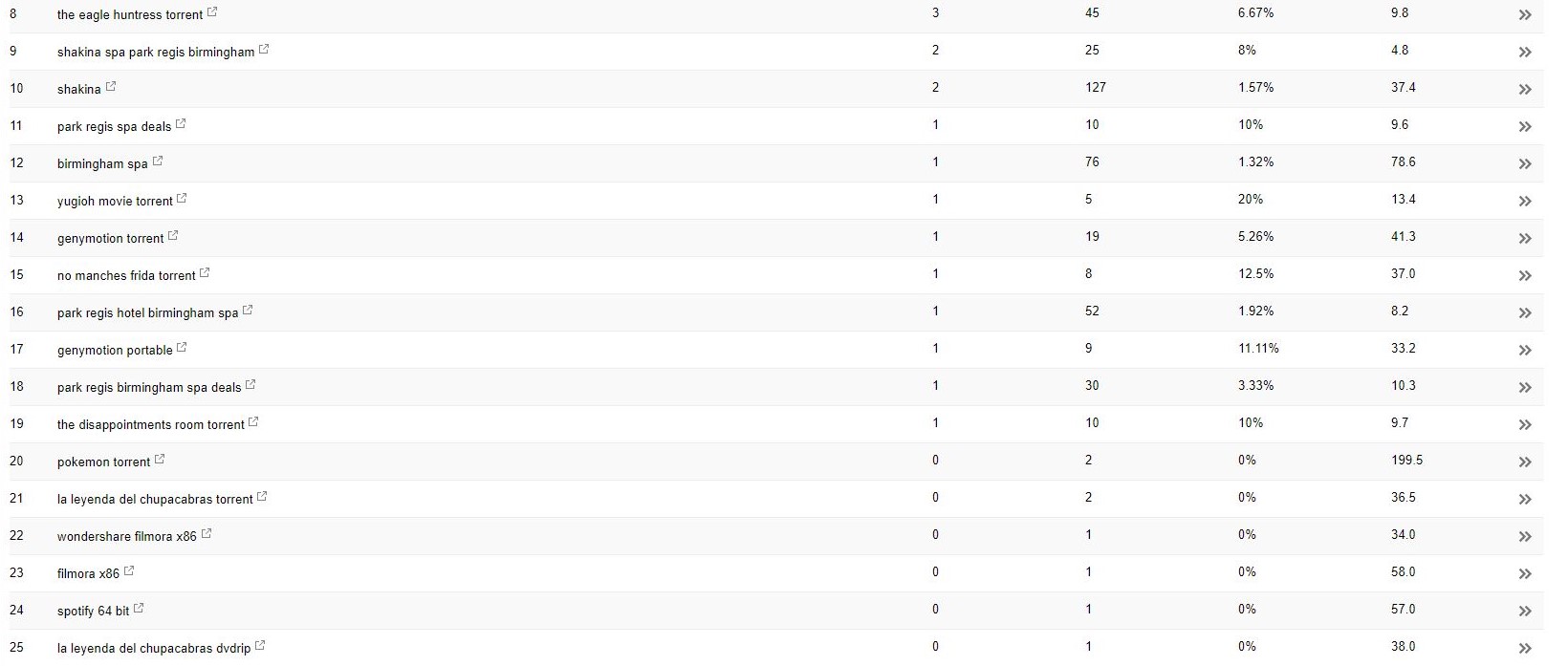
Şaşırtıcı bir şekilde, yalnızca Search Console'da gösterimleri değil, aynı zamanda Tıklamaları da vardı - bu, etki alanında bir şeyin dizine eklenmiş olması gerektiği anlamına gelir.
Sorgulara bakılırsa, çok spam olduğu ve müşterinin işiyle ilişkilendirilmesini isteyeceği bir şey olmadığı açıktı.
Google'da basit bir "site:domain.com" araması yapmak, müşterinin kendi sitesinde barındırdığı varsayılan yüzlerce sayfalık torrentleri ortaya çıkardı.
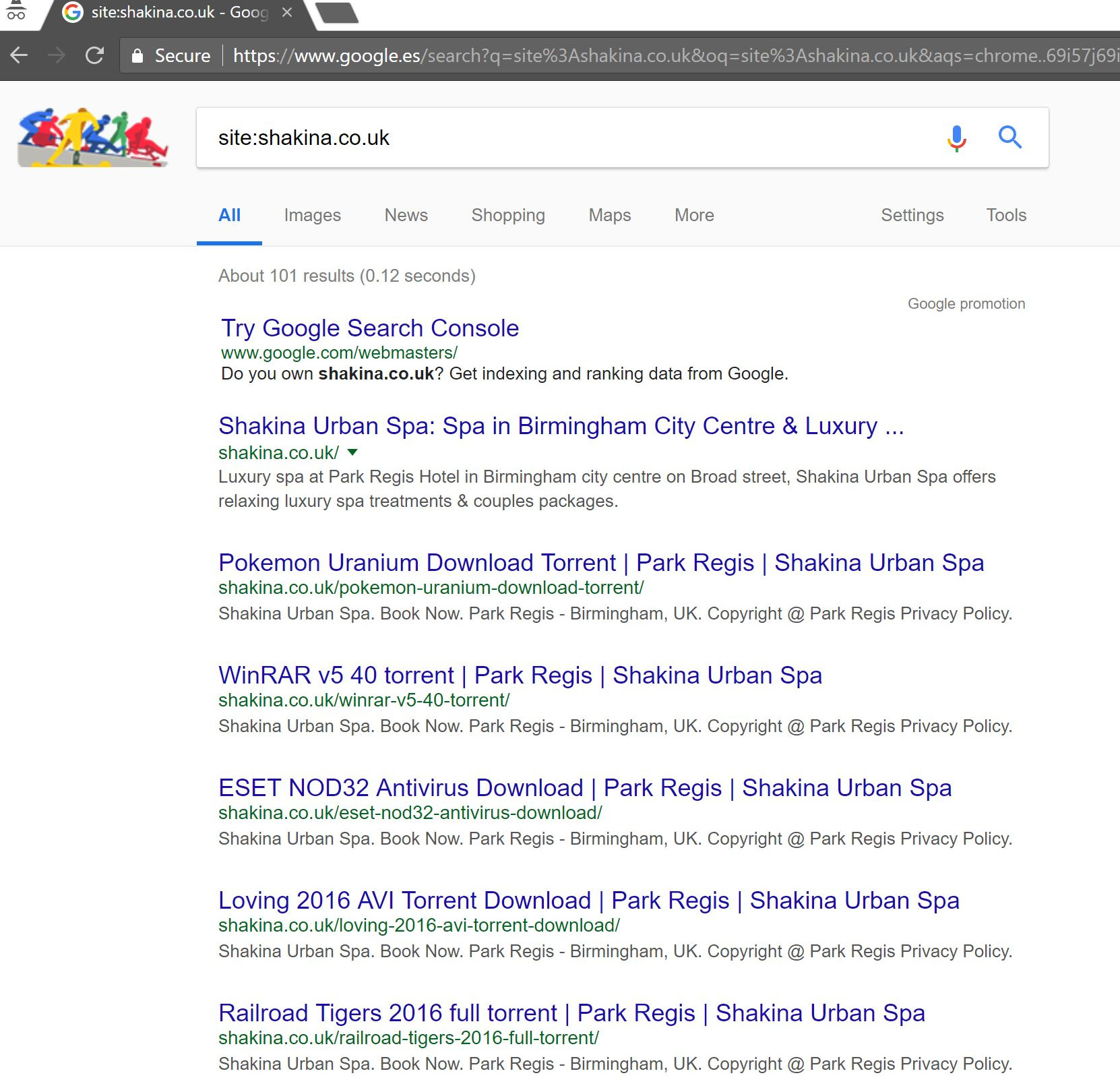
Bu URL'lerden herhangi birinin ziyaret edilmesi aslında bir 404 ile sonuçlandı - ancak yine de dizine eklendi (çeşitli Kullanıcı Aracılarını da kontrol ettim ve hepsi aynı 404 hatasını aldı).
Daha sonra etki alanını Majestic'in geri bağlantı denetleyicisinden geçirdim ve istemci sitelerindeki bu sayfalara işaret eden çok düşük kaliteli geri bağlantıların uzun bir listesini verdi - bu da muhtemelen onların dizine eklenmesine yardımcı oluyordu.
Majestic'in Anchor Cloud geri bağlantılarına bakmak, sorunun boyutunu gerçekten gösterdi.


Buradaki tek düzeltme, etki alanına göre tüm bu geri bağlantıları reddetmek ve ardından herhangi bir kod enjeksiyonunu temizleme umuduyla WordPress kurulumunu temiz bir şekilde taramak veya WordPress'in yeni bir kopyasını yüklemekti.
Yukarıdaki gibi durumlarda dizine eklenen içerikle gerçekten ilgileniyorsanız, arama tarayıcılarıyla ilgili şeyleri gerçekten netleştirmek için 410 durum kodu da sunabilirsiniz.
Yukarıdakiler, film yapımcılarının telif hakkı iddiaları nedeniyle yasal uyarıların sunulduğu sitelere uygundur - sorun hızlı bir şekilde çözülmezse bazen bu gibi durumlarda ortaya çıkabilir.
6 – Kötü Uluslararası SEO kurulumları
İspanya'da ikamet ediyorum, ancak internette anadili İngilizcemle geziniyorum, genellikle kendimi bir web sitesinin İspanyolca versiyonuna otomatik olarak yönlendirildiğimi görüyorum.
Mantığını anlasam da (İspanya'da yaşıyorum, bu nedenle siteye İspanyolca olarak göz atmak istiyorum), kullanıcı deneyimi açısından oldukça can sıkıcı ve doğru şekilde yapılmazsa, uluslararası SEO'nuzda biraz hasara neden olabilir.
Google Ads gibi siteler bunu başka bir düzeye taşıyor - konumuma dayalı olarak dinamik olarak içerik oluşturmak için Angular JavaScript'i kullanıyor, hatta herhangi bir türde bir sayfa yönlendirmesinden bile geçmeyip içeriği doğrudan DOM'ye yüklüyor.
Birden fazla dil mevcut olduğunda tercih ettiğim yöntem, 302 bir kullanıcıyı İnternet tarayıcı ayarlarına göre bir dile yönlendirmek.
Bu nedenle, biri Google Chrome'da varsayılan dili Almancaysa, fiziksel konumundan bağımsız olarak siteyi Almanca olarak okumakta büyük olasılıkla rahattır.
Bu aynı zamanda, İsviçre'de olduğu gibi Fransızca, İtalyanca, Almanca ve Romanşça'nın hepsinin kullanıldığı çeşitli dillerin konuşulduğu bir bölgede bulunan birisinin yaşadığı zorluklarda gezinmeye de yardımcı olur.
Diller arasında geçiş yapmak istemeleri durumunda tercihinize göre diller arasında geçiş yapma seçeneği olduğundan emin olmak, kullanılabilirlik açısından da önemlidir.
Bir durumda, SEO etkisi dikkate alınmadan bir siteye bir JavaScript dili yeniden yönlendirme komut dosyasının eklendiği Barselona merkezli bir otelle çalıştım.
Bu komut dosyası, istemci tarafı JavaScript yönlendirmesi aracılığıyla kullanıcıları tarayıcı dil ayarlarına (kendi içinde çok da kötü olmayan) göre yeniden yönlendirdi.
Ne yazık ki bu durumda, sitelerin kalıcı bağlantılarının garip bir yapılandırması nedeniyle komut dosyası doğru şekilde kurulmadı ve sitedeki tüm sayfalarda HTML lang etiketinin eksik olması gerçeğiyle birleştiğinde, Googlebot biraz kafayı yedi…
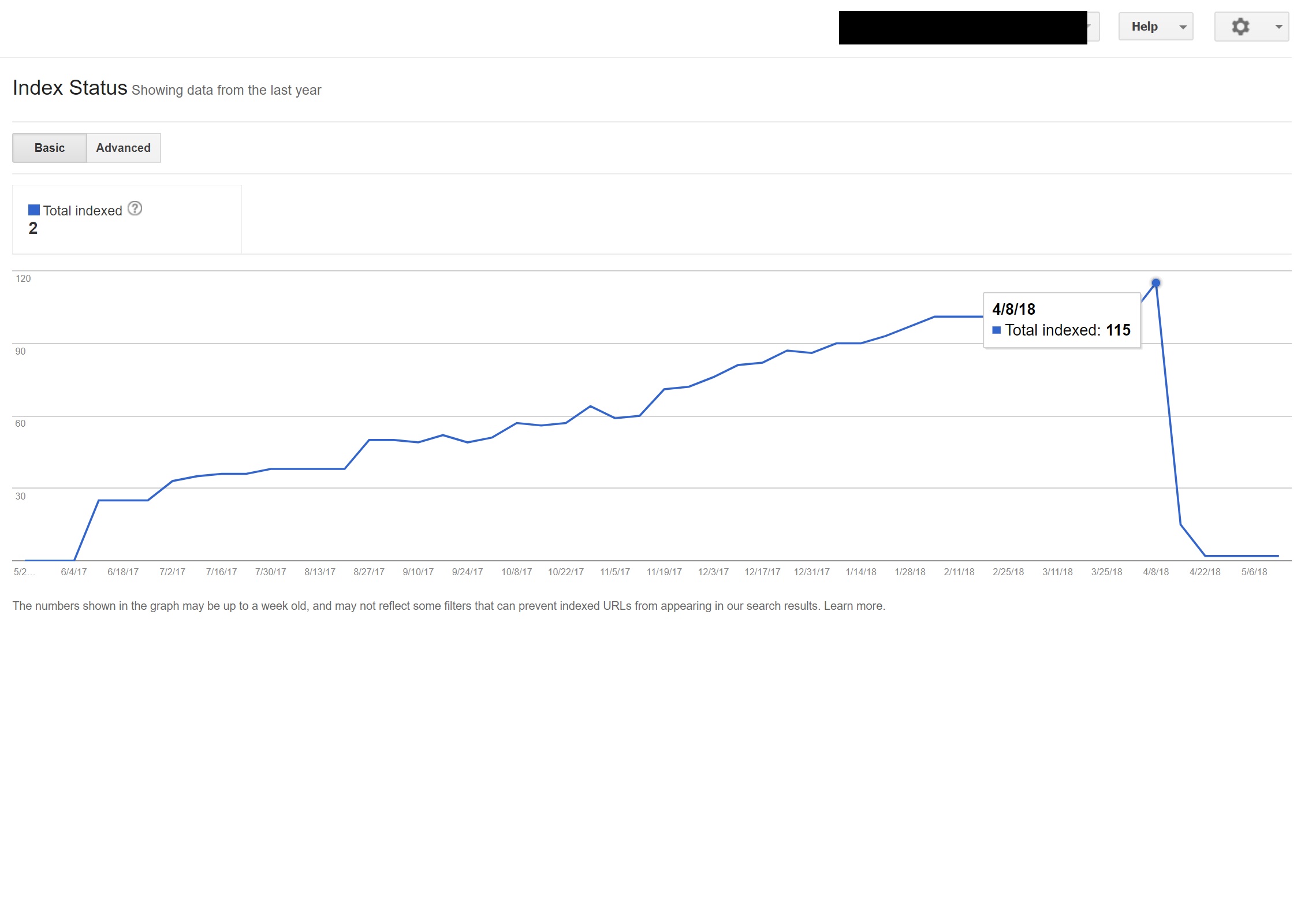
Bu örnekte, sitedeki neredeyse tüm İngilizce olmayan içeriğin dizini Google tarafından kaldırılmıştır, çünkü bunlar var olmayan sayfalara yönlendirilmekte ve böylece birden çok 404 hatası vermektedir.
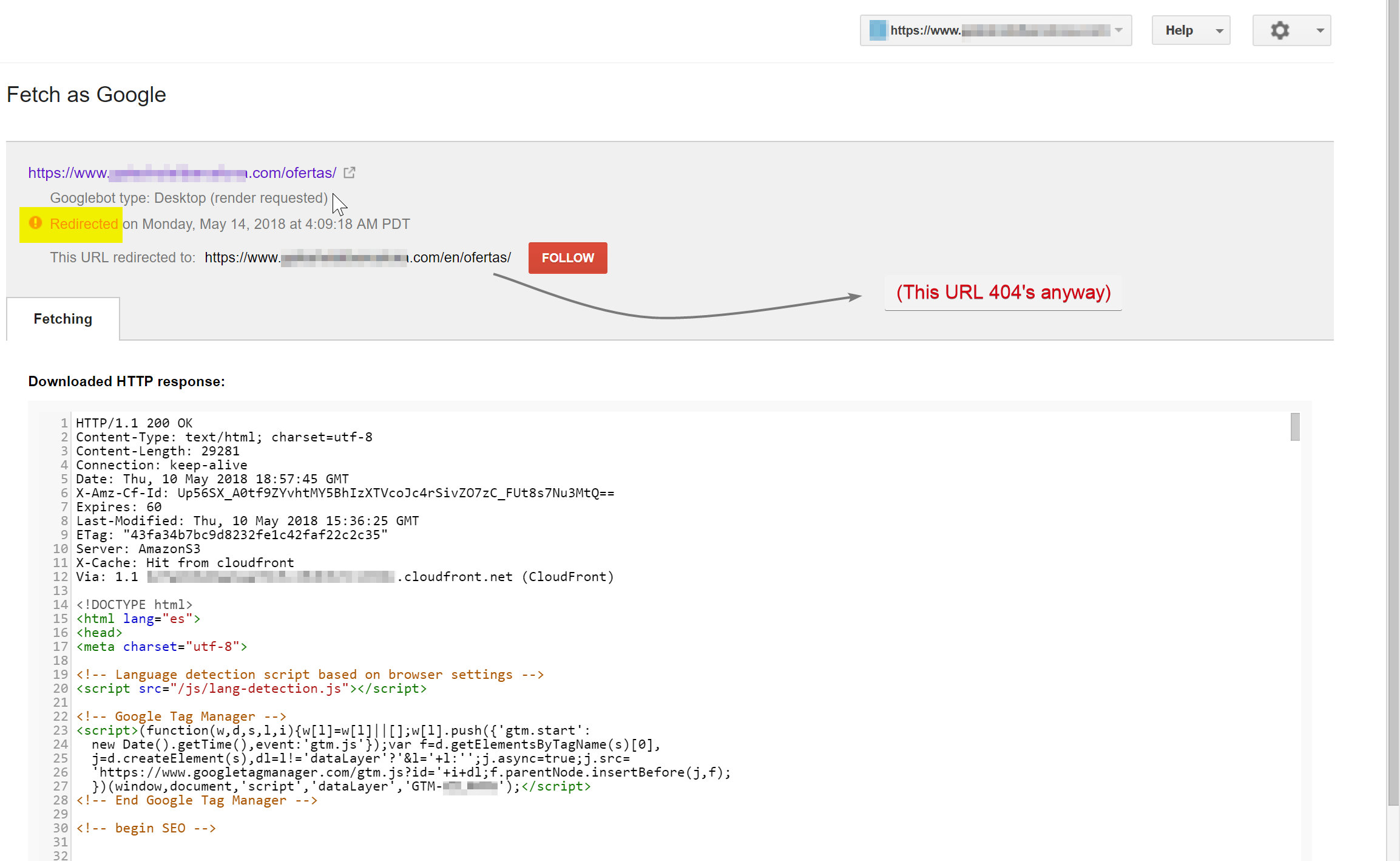
Googlebot, (hotelname.com/ofertas adresinde bulunan) İspanyolca içeriğini taramaya çalışıyordu ve var olmayan bir URL olan hotelname.com/en/ofertas'a yönlendiriliyordu.
Şaşırtıcı bir şekilde, bu durumda Googlebot tüm bu JavaScript yönlendirmelerini takip ediyordu ve bu URL'leri bulamadığı için onları dizininden çıkarmak zorunda kaldı.
Yukarıdaki durumda, sitenin sunucu günlüklerine erişerek, Googlebot'a filtreleyerek ve 404'lerin nerede sunulduğunu kontrol ederek bunu onaylayabildim.
Hatalı JavaScript yeniden yönlendirme komut dosyasının kaldırılması sorunu çözdü ve neyse ki çevrilen sayfalar uzun süre dizine eklenmedi.
Her şeyi tam olarak test etmek her zaman iyi bir fikirdir - bir VPN'ye yatırım yapmak bu tür senaryoları teşhis etmenize ve hatta Chrome tarayıcıda konumunuzu ve/veya dilinizi değiştirmenize yardımcı olabilir.
[Örnek Olay] Birden çok site denetimini yönetme
 Örnek olayı okuyun
Örnek olayı okuyun7 – Yinelenen İçerik
Yinelenen içerik oldukça yaygın ve iyi tartışılan bir konudur ve sitenizdeki yinelenen içeriği kontrol etmenin birçok yolu vardır - Richard Baxter kısa süre önce bu konuyla ilgili harika bir yazı yazdı.
Benim durumumda sorun muhtemelen biraz daha basit. Sık sık bir blog yazısı olarak harika içerik yayınlayan siteleri düzenli olarak gördüm, ancak daha sonra bu içeriği neredeyse anında Medium.com gibi bir 3. taraf web sitesinde paylaştım.
Medium, daha geniş kitlelere ulaşmak için mevcut içeriği yeniden kullanmak için harika bir sitedir, ancak buna nasıl yaklaşılacağına dikkat edilmelidir.
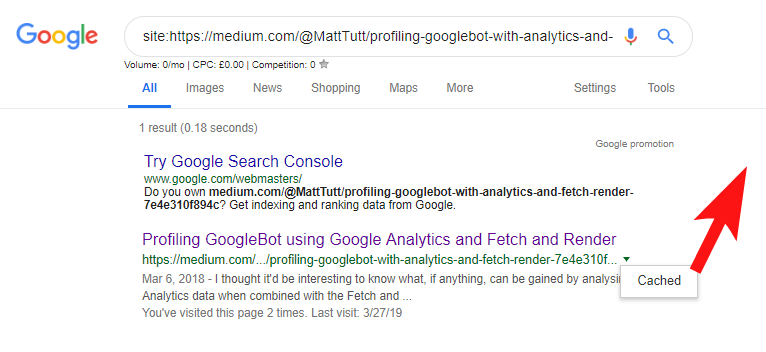
İçeriği WordPress'ten Medium'a aktarırken, bu işlem sırasında Medium, web sitenizin URL'sini standart etiket olarak kullanır. Bu nedenle teoride, orijinal kaynak olarak web sitenize içerik için kredi vermenize yardımcı olmalıdır.
Bazı analizlerime göre, her zaman böyle çalışmıyor.
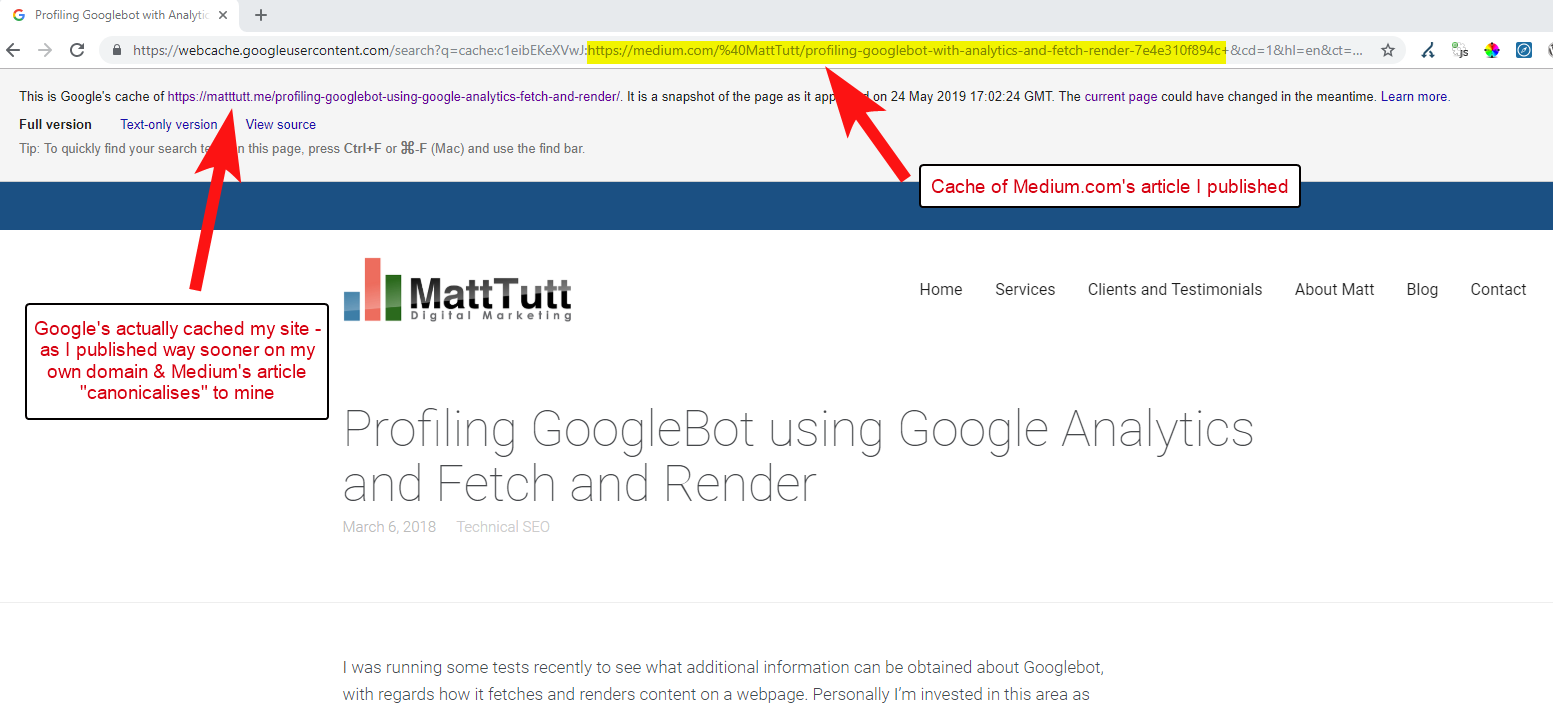
Durumun böyle olduğuna inanıyorum, çünkü bir makale Google'ın alan adınızda makaleyi taramasına ve dizine eklemesine izin vermeden Medium'da yayınlandığında, makale Medium'da iyi giderse (biraz isabetli veya özlenen) içeriğiniz alır. sizin sitenize standart olarak işaret etmelerine rağmen dizine eklendi ve Medium'un sitesiyle ilişkilendirildi.
İçerik Medium'a eklendiğinde (ve özellikle popülerse), parçanın hemen hemen başka bir yerde kazınacağını ve web'de yeniden yayınlanacağını hemen hemen garanti edebilirsiniz - böylece yine içeriğiniz başka bir yerde kopyalanıyor.
Tüm bunlar olurken, alan adınız yetki açısından oldukça küçükse, Google'ın yayınladığınız içeriği tarama ve dizine ekleme şansı bile olmayabilir - ve hatta bu durumun oluşturma öğesi bile olabilir. tarama/dizin henüz tamamlanmadı veya bu içeriğin taranması, oluşturulması ve dizine eklenmesi arasında büyük bir gecikmeye neden olan yoğun JavaScript var.
Büyük bir şirketin harika bir makale yayınladığı durumlar gördüm, ancak ertesi gün bunu büyük bir endüstri haberleri blogunda düşünce parçası olarak yayınladılar. Bunun da ötesinde, sitelerinde içeriğin https://domain.com ve https://www.domain.com adreslerinde çoğaltıldığı (ve dizine eklendiği) bir sorun vardı.
Yayınlandıktan birkaç gün sonra, Google'da alıntılarla makalenin tam bir ifadesini ararken, şirketin web sitesi hiçbir yerde görünmüyordu. Bunun yerine, yetkili endüstri blogu ilk sırada yer aldı ve diğer yeniden yayıncılar sonraki pozisyonları aldı.
Bu durumda içerik endüstri blogu ile ilişkilendirilmiştir ve bu nedenle parçanın kazandığı tüm bağlantılar orijinal yayıncıya değil, o web sitesine fayda sağlayacaktır.
Web'de herhangi bir yerde içeriği başka bir amaçla kullanacaksanız, dizine eklenmesi muhtemelse, içeriğin Google tarafından kendi alanınızda dizine eklendiğinden tamamen emin olana kadar gerçekten beklemeniz gerekir.
Muhtemelen içeriğinizi oluşturmak ve işlemek için çok çalışıyorsunuz - başka bir yerde yeniden yayınlamaya çok hevesli olarak tüm bunları çöpe atmayın!
8 – Kötü AMP Yapılandırması (AMP URL bildirimi eksik)
Yardım ettiğim müşterilerin yalnızca bir kısmı, belki de kullanımıyla ilgili Google tarafından finanse edilen birçok vaka çalışmasına dayanarak AMP'ye bir şans vermeyi seçti.
Bazen, bir müşterinin sitelerinin AMP sürümüne sahip olduğunun hiç farkında bile değildim – Analytics tavsiye raporlarında bazı garip trafik görülüyordu – burada sitenin AMP sürümünün AMP olmayan site sürümüne bağlantı verdiği görülüyordu.
Bu durumda, AMP olmayan sayfaların başlığından URL referansı olmadığı için AMP sayfası sürümleri doğru şekilde yapılandırılmamıştır.

Arama motorlarına belirli bir URL'de bir AMP sayfasının bulunduğunu söylemeden, AMP kurulumuna sahip olmanın pek bir anlamı yoktur – mesele şu ki, mobil kullanıcılar için SERPS'de dizine eklenir ve döndürülür.
AMP olmayan sayfanıza referans eklemek, Google'a AMP sayfası hakkında bilgi vermenin önemli bir yoludur ve AMP sayfalarındaki kurallı etiketlerin kendi kendine referans vermemesi gerektiğini hatırlamak önemlidir: AMP olmayan sayfaya geri bağlanırlar.
Ve gerçekten teknik bir SEO düşüncesi olmasa da, herhangi bir trafik ve kullanıcı davranışı bilgisi hakkında rapor yapabilmek istiyorsanız, AMP sayfalarına izleme kodu eklemeniz gerektiğini belirtmekte fayda var.
Tipik olarak SEO denetimlerimin bir parçası olarak, analitik uygulamasının bazı temel kontrollerini de yapmayı seviyorum - aksi takdirde, sağladığınız veriler aslında o kadar da yardımcı olmayabilir, özellikle de sağlam bir analitik kurulumu varsa.
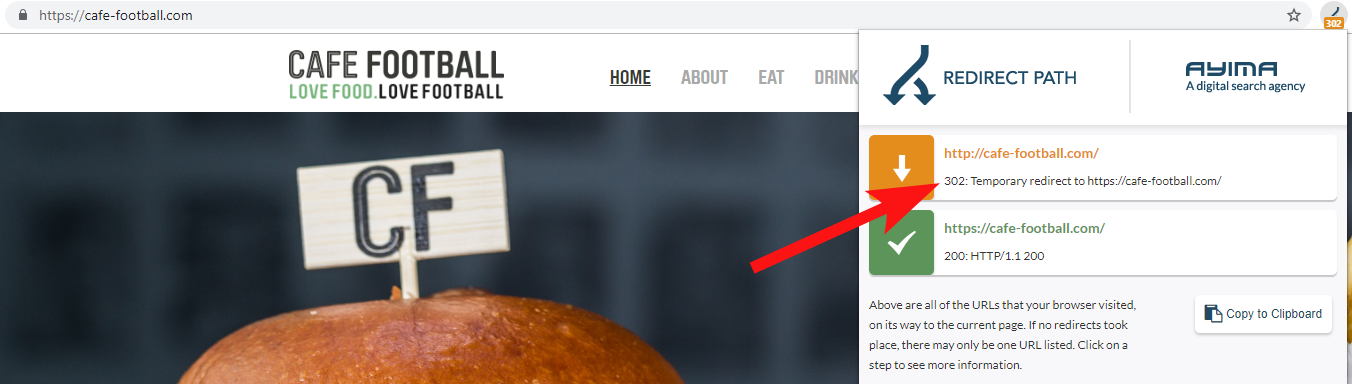
9 – 302 yeniden yönlendiren veya bir yeniden yönlendirme zinciri oluşturan Eski Etki Alanları
ABD'de son birkaç yılda birkaç marka değişikliği geçiren (otelcilik endüstrisinde oldukça yaygın olan) büyük bir bağımsız otel markasıyla çalışırken, önceki alan adı isteklerinin nasıl davrandığını izlemek önemlidir.
Bunu unutmak kolaydır, ancak OnCrawl gibi bir araç kullanarak eski sitelerini taramaya çalışmanın basit bir yarı düzenli kontrolü veya durum kodlarını ve yönlendirmeleri kontrol eden bir üçüncü taraf sitesi bile olabilir.
Çoğu zaman, 302 alan adının nihai hedefe (301 her zaman burada en iyi bahistir) veya 302'nin, nihai URL'ye ulaşmadan önce birkaç yeniden yönlendirmeden geçmeden önce URL'nin WWW olmayan bir sürümüne yönlendirdiğini görürsünüz.
Google'dan John Mueller, daha önce, pes etmeden önce yalnızca 5 yönlendirmeyi takip ettiklerini belirtmişti, ayrıca geçen her yönlendirme için bağlantı değerinin bir kısmının kaybolduğu da biliniyor. Bu nedenlerden dolayı, mümkün olduğunca temiz olan 301 yönlendirmelerine bağlı kalmayı tercih ediyorum.
Redirect Path by Ayima, web'de gezinirken durumları yeniden yönlendirmenizi gösterecek harika bir Chrome tarayıcı uzantısıdır.
Bir müşteriye ait eski alan adlarını tespit etmenin başka bir yolu da, Google'da telefon numaralarını tam olarak eşleşen alıntıları veya adreslerinin bölümlerini kullanarak aramaktır.
Otel gibi bir işletme genellikle adres değiştirmez (en azından bir kısmı zaten) ve eski bir alana bağlanan eski dizinleri/işletme profillerini bulabilirsiniz.
Majestic veya Ahrefs gibi bir geri bağlantı aracı kullanmak, önceki etki alanlarından bazı eski bağlantıları da gösterebilir, bu nedenle bu da iyi bir bağlantı noktasıdır - özellikle müşteriyle doğrudan iletişim halinde değilseniz.
10 – Dahili Arama İçeriğiyle Kötü Başa Çıkmak
Bu aslında daha önce burada OnCrawl'da yazdığım bir konu - ama tekrar ekliyorum çünkü hala sorunlu dahili içeriğin "vahşi doğada" çok sık gerçekleştiğini görüyorum.
Bu parçaya, çıktıkları içeriğin taranmasını ve dizine eklenmesini önlemek için dışarıdan bakıldığında bir düzeltme gibi görünen Pingdom'un robots.txt yönergesi sorunu hakkında konuşmaya başladım.
İçerik olarak Google'a dahili arama sonuçları sunan veya çok sayıda kullanıcı tarafından oluşturulan içerik üreten herhangi bir site, bunu yapma yöntemleri konusunda çok dikkatli olmalıdır.
Bir site, dahili arama sonuçlarını Google'a çok doğrudan bir şekilde sunuyorsa, bu bir tür manuel cezaya yol açabilir. Google muhtemelen bunu kötü bir kullanıcı deneyimi olarak görecektir - X'i ararlar, ardından istediklerini manuel olarak filtrelemeleri gereken bir siteye girerler.
Bazı durumlarda dahili içerik sunmanın iyi olabileceğine inanıyorum, bu sadece bağlama ve koşullara bağlı. Örneğin bir iş sitesi, neredeyse her gün güncellenen en son iş sonuçlarını sunmak isteyebilir - bu yüzden neredeyse bununla uğraşmak zorunda kalırlar.
Nitekim, popüler arama sorgularına dayalı olarak her türlü içeriği üreten, belki de bunu çok ileri götüren ünlü bir iş sitesi örneğidir (bu taktiği kullanırsanız neler olabileceğini görmek için aşağıya bakın).
Buna rağmen, SEMRush verilerine göre organik trafikleri harika gidiyor - ancak bunlar ince çizgiler ve böyle davranmak sizi Google cezası riskine sokar.
Çevrimiçi perakendeci Wayfair.com, rüzgara yakın yelken açmayı seven başka bir markadır. Milyonlarca dizine eklenmiş URL (ve otomatik olarak oluşturulmuş çok sayıda anahtar kelime URL'si) ile organik trafik açısından harika gidiyorlar - ancak arama motorlarına bu şekilde içerik sundukları için cezalandırılma riskleri yüksek.
Tüm içeriği kategorilere ayırmayı, farklı üst/alt hiyerarşileri oluşturmayı, hatta etiketleri veya diğer özel sınıflandırmaları kullanmayı içeren uygun bir site yapısı uygulayarak, müşteri ve arama tarayıcısında gezinmeye yardımcı olabilirsiniz.
Yukarıdaki gibi hileleri kullanmak kısa vadede kazandırabilir, ancak uzun vadede sizin için pek bir şey yapması pek olası değildir. Bu, site yapısını en baştan elde etmeyi veya en azından önceden düzgün bir şekilde planlamayı önemli kılar.
toparlamak
Bu makalede tartışılan 10 hata, site denetimleri sırasında karşılaştığım en yaygın teknik sorunlardan bazıları.
Sitenizdeki bu hataları düzeltmek, sitenizin teknik olarak sağlıklı olduğundan emin olmanın ilk adımıdır. Bu sorunlar düzeltildikten sonra, teknik denetimler sitenize özgü sorunlara odaklanabilir.