
Bir metinden kavramları ve anahtar kelimeleri otomatik olarak çıkarın (Bölüm I : Geleneksel yöntemler)
Yayınlanan: 2022-02-22Oncrawl'ın Ar-Ge departmanında, Web sayfalarınızın anlamsal içeriğini giderek daha fazla geliştirmeye çalışıyoruz. Doğal dil işleme (NLP) için Makine Öğrenimi modellerini kullanarak sayfalarınızın içeriğini ayrıntılı olarak karşılaştırabilir, otomatik özetler oluşturabilir, makalelerinizin etiketlerini tamamlayabilir veya düzeltebilir, içeriği Google Arama Konsolu verilerinize göre optimize edebiliriz vb.
Önceki bir makalede, HTML sayfalarından metin içeriği çıkarmaktan bahsetmiştik. Bu sefer bir metinden anahtar kelimelerin otomatik olarak çıkarılmasından bahsetmek istiyoruz. Bu konu iki gönderiye bölünecektir:
- ilki, bağlamı ve “geleneksel” olarak adlandırılan yöntemleri birkaç somut örnekle kapsayacaktır.
- yakında gelecek olan ikincisi, bu farklı yöntemleri kıyaslamak için transformatörlere ve değerlendirme yöntemlerine dayalı daha semantik yaklaşımlarla ilgilenecektir.
Bağlam
Bir başlığın veya özetin ötesinde, bir metnin, bilimsel makalenin veya web sayfasının içeriğini belirlemenin birkaç anahtar kelimeden daha iyi bir yolu olabilir. Çok daha uzun bir metnin konusunu ve kavramlarını belirlemenin basit ve çok etkili bir yoludur. Ayrıca, bir dizi metni kategorilere ayırmanın iyi bir yolu olabilir: onları tanımlayın ve anahtar kelimelere göre gruplandırın. PubMed veya arxiv.org gibi bilimsel makaleler sunan siteler, bu anahtar kelimelere dayalı kategoriler ve öneriler sunabilir.
Anahtar kelimeler ayrıca çok büyük belgeleri indekslemek ve arama motorları tarafından iyi bilinen bir uzmanlık alanı olan bilgi almak için çok kullanışlıdır.
Anahtar kelime eksikliği, bilimsel makalelerin otomatik olarak sınıflandırılmasında tekrarlayan bir sorundur [1]: birçok makaleye atanmış anahtar kelimeler yoktur. Bu nedenle, bir metinden kavramları ve anahtar kelimeleri otomatik olarak çıkarmak için yöntemler bulunmalıdır. Otomatik olarak çıkarılan bir anahtar kelime grubunun alaka düzeyini değerlendirmek için, veri kümeleri genellikle bir algoritma tarafından çıkarılan anahtar kelimeleri birkaç insan tarafından çıkarılan anahtar kelimelerle karşılaştırır.
Tahmin edebileceğiniz gibi bu, arama motorlarının web sayfalarını kategorize ederken paylaştığı bir sorundur. Otomatik anahtar kelime çıkarma süreçlerinin daha iyi anlaşılması, bir web sayfasının neden şu veya bu anahtar kelime için konumlandırıldığını daha iyi anlamayı sağlar. Ayrıca, hedeflediğiniz anahtar kelime için iyi bir sıralama elde etmesini engelleyen anlamsal boşlukları da ortaya çıkarabilir.
Bir metinden veya paragraftan anahtar kelimeleri çıkarmanın elbette birkaç yolu vardır. Bu ilk gönderide, sözde “klasik” yaklaşımları anlatacağız.
[Ebook] Veri SEO'su: Sonraki Büyük Macera
 e-kitabı okuyun
e-kitabı okuyunkısıtlamalar
Yine de, bir algoritma seçiminde bazı sınırlamalarımız ve ön koşullarımız var:
- Yöntem, anahtar kelimeleri tek bir belgeden çıkarabilmelidir. Bazı yöntemler tam bir külliyat, yani birkaç yüz hatta binlerce belge gerektirir. Bu yöntemler arama motorları tarafından kullanılabilse de tek bir belge için faydalı olmayacaktır.
- Denetimsiz bir Makine Öğrenimi durumundayız. Elimizde Fransızca, İngilizce veya diğer dillerde açıklamalı veriler içeren bir veri setimiz yok. Başka bir deyişle, halihazırda çıkarılmış anahtar kelimeler içeren binlerce belgemiz yok.
- Yöntem, belgenin etki alanından / sözcük alanından bağımsız olmalıdır. Her tür belgeden anahtar sözcükleri ayıklayabilmek istiyoruz: haber makaleleri, web sayfaları, vb. Her bir belge için zaten anahtar sözcükleri ayıklanmış olan bazı veri kümelerinin genellikle alana özgü tıp, bilgisayar bilimi vb. olduğunu unutmayın.
- Bazı yöntemler, POS etiketleme modellerine, yani bir NLP modelinin bir cümledeki kelimeleri gramer türlerine göre tanımlama becerisine dayanır: fiil, isim, belirleyici. Bir belirleyiciden ziyade bir isim olan bir anahtar kelimenin önemini belirlemek açıkça alakalıdır. Ancak, dile bağlı olarak, POS etiketleme modelleri bazen çok eşit olmayan kalitede olabilir.
Geleneksel yöntemler hakkında
Sözde "geleneksel" yöntemler ile sözcük yerleştirme ve bağlamsal yerleştirme gibi NLP - Doğal Dil İşleme - teknikleri kullanan daha yeni yöntemler arasında ayrım yapıyoruz. Bu konu gelecekteki bir gönderide ele alınacaktır. Ama önce klasik yaklaşımlara geri dönelim, ikisini ayırt edelim:
- istatistik yaklaşımı
- grafik yaklaşımı
İstatistik yaklaşımı esas olarak kelime frekanslarına ve bunların birlikte ortaya çıkmasına dayanacaktır. Buluşsal yöntemler oluşturmak ve önemli sözcükleri çıkarmak için basit hipotezlerle başlıyoruz: çok sık kullanılan bir sözcük, birkaç kez görünen bir dizi ardışık sözcük, vb. Grafik tabanlı yöntemler, her düğümün bir sözcük, bir grup kelime veya cümle. Daha sonra her yay, bu sözcükleri birlikte gözlemleme olasılığını (veya sıklığını) temsil edebilir.
İşte birkaç yöntem:
- İstatistik tabanlı
- TF-IDF
- tırmık
- YAKE
- grafik tabanlı
- MetinSırası
- Konu Sıralaması
- Tek Sıra
Verilen tüm örneklerde bu web sayfasından alınan metin kullanılmıştır: Jazz veya Tresor : John Coltrane – Impressions Graz 1962.
İstatistik yaklaşımı
Sizi iki yöntemle Rake ve Yake ile tanıştıracağız. Bir SEO bağlamında, TF-IDF yöntemini duymuş olabilirsiniz. Ancak bir belge külliyatı gerektirdiği için burada ele almayacağız.
tırmık
RAKE, Hızlı Otomatik Anahtar Kelime Çıkarma anlamına gelir. Bu yöntemin Python'da rake-nltk dahil birkaç uygulaması vardır. Birkaç kelime içerdiğinden anahtar kelime olarak da adlandırılan her bir anahtar kelimenin puanı, iki öğeye dayanır: kelimelerin sıklığı ve birlikte bulunmalarının toplamı. Her bir anahtar kelimenin yapısı çok basittir, şunlardan oluşur:
- metni cümlelere böl
- her cümleyi anahtar kelimelere ayırın
Aşağıdaki cümlede, noktalama işaretleri veya stopwords ile ayrılmış tüm kelime gruplarını alacağız:
Hemen öncesinde, Coltrane bir beşliyi yönetiyordu, yanında Eric Dolphy ve kontrbasta Reggie Workman vardı.
Bu, aşağıdaki anahtar sözcüklerle sonuçlanabilir:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Durdurulan kelimelerin the “ ”, “ in ”, “ve” or “ it ” gibi çok sık kullanılan bir dizi kelime olduğunu unutmayın. Klasik yöntemler genellikle kelimelerin kullanılma sıklığının hesaplanmasına dayandığından, kilit kelimelerinizi dikkatli bir şekilde seçmeniz önemlidir. Anahtar kelime önerilerimizde çoğu zaman >"to" , "the" or "of" gibi kelimelerin olmasını istemiyoruz. Aslında, bu yasak sözcükler belirli bir sözlük alanıyla ilişkili değildir ve bu nedenle örneğin “ jazz ” veya “ saxophone ” sözcüklerinden çok daha az alakalıdır.

Birkaç aday anahtar kelimeyi ayırdıktan sonra, onlara kelimelerin sıklığına ve birlikte bulunmalarına göre bir puan veriyoruz. Puan ne kadar yüksek olursa, anahtar sözcüklerin o kadar alakalı olması gerekir.
John Coltrane hakkındaki makaledeki metinle hızlıca deneyelim.
tırmık için # python snippet'i rake_nltk'den komisyonu içe aktar # makalenin zaten 'metin' değişkeninde olduğunu varsayalım tırmık = Rake(stopwords=FRANSIZCA_STOPWORDS, maks_uzunluk=4) rake.extract_keywords_from_text(metin) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
İşte ilk 5 anahtar kelime:
“Avusturya ulusal halk radyosu”, “lirik zirveler daha cennet gibi”, “grazın iki özelliği var”, “john coltrane tenor saksafon”, “sadece kayıtlı versiyon”
Bu yöntemin birkaç dezavantajı vardır. Birincisi, bir cümleyi aday anahtar kelimelere bölmek için kullanıldıkları için, stopwords seçiminin önemidir. İkincisi, anahtar kelimeler çok uzun olduğunda, mevcut kelimelerin birlikte ortaya çıkması nedeniyle genellikle daha yüksek bir puan alacaklardır. Anahtar sözcüklerin uzunluğunu sınırlamak için, yöntemi max_length=4 ile ayarladık.
YAKE
YAKE, Yet Another Anahtar Kelime Çıkarıcı anlamına gelir. Bu yöntem aşağıdaki makaleye dayanmaktadır YAKE! 2020'den kalma birden çok yerel özellik kullanılarak tek belgelerden anahtar kelime çıkarma. Yazarları Github'da bir Python uygulaması öneren RAKE'den daha yeni bir yöntemdir.
RAKE'ye gelince, kelime sıklığına ve birlikte oluşumuna güveneceğiz. Yazarlar ayrıca bazı ilginç buluşsal yöntemler de ekleyecekler:
- küçük harfli sözcükleri ve büyük harfli sözcükleri (ilk harf veya tüm sözcük) ayırt edeceğiz. Burada büyük harfle başlayan kelimelerin (cümlenin başlangıcı hariç) diğerlerinden daha alakalı olduğunu varsayacağız: kişi isimleri, şehirler, ülkeler, markalar. Bu, tüm büyük harfli kelimeler için aynı ilkedir.
- her aday anahtar kelimenin puanı, metindeki konumuna bağlı olacaktır. Aday anahtar sözcükler metnin başında görünüyorsa, sonunda göründüğünden daha yüksek puan alacaklardır. Örneğin, haber makaleleri genellikle makalenin başında önemli kavramlardan bahseder.
# yake için piton parçacığı yake'den KeywordExtractor'ı Yake olarak içe aktarın yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(metin)
RAKE gibi, işte en iyi 5 sonuç:
“Treasure Jazz”, “John Coltrane”, “İzlenimler Graz”, “Graz”, “Coltrane”
Bazı anahtar sözcüklerde bazı sözcüklerin yinelenmesine rağmen, bu yöntem oldukça ilginç görünmektedir.
grafik yaklaşımı
Bu tür bir yaklaşım, kelime birlikteliklerini de hesaplayacağımız anlamında istatistiksel yaklaşımdan çok uzak değildir. TextRank gibi bazı yöntem adlarıyla ilişkilendirilen Rank soneki, her sayfanın popülerliğini gelen ve giden bağlantılarına göre hesaplamak için PageRank algo ilkesine dayanır.
[Ebook] Oncrawl ile SEO'yu Otomatikleştirme
 e-kitabı okuyun
e-kitabı okuyunMetinSırası
Bu algoritma TextRank: Bringing Order to Texts from 2004 belgesinden gelir ve PageRank algoritması ile aynı ilkelere dayanır. Ancak sayfalar ve bağlantılarla bir grafik oluşturmak yerine, kelimelerle bir grafik oluşturacağız. Her kelime, birlikte oluşlarına göre diğer kelimelerle bağlantılı olacaktır.
Python'da birkaç uygulama vardır. Bu yazımda pytextrank'ı tanıtacağım. POS etiketleme ile ilgili kısıtlamalarımızdan birini kıracağız. Gerçekten de, grafiği oluştururken tüm kelimeleri düğüm olarak dahil etmeyeceğiz. Sadece fiiller ve isimler dikkate alınacaktır. İlgisiz adayları filtrelemek için stopwords kullanan önceki yöntemler gibi, TextRank algo da dilbilgisel kelime türlerini kullanır.
Algo tarafından oluşturulacak grafiğin bir parçasının bir örneği: 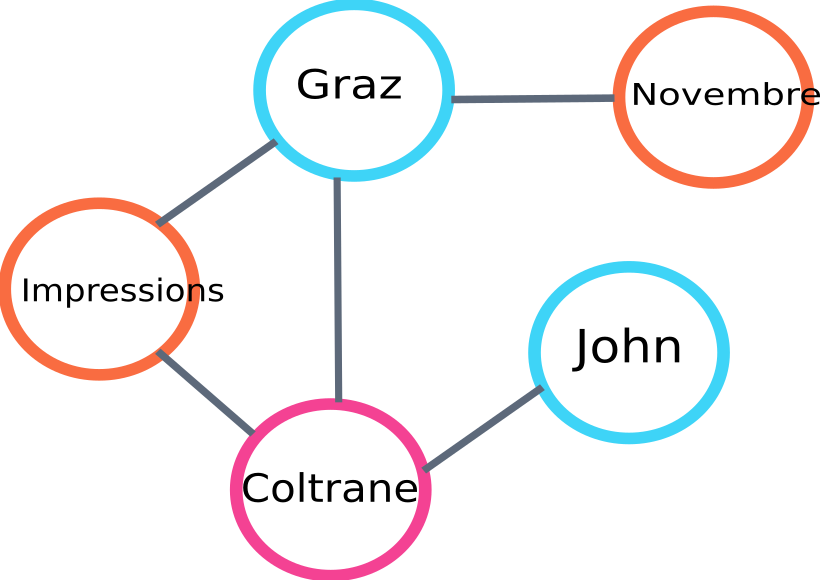
metin sıralaması grafiği örneği
İşte Python'da bir kullanım örneği. Bu uygulamanın spaCy kitaplığının ardışık düzen mekanizmasını kullandığını unutmayın. POS etiketleme yapabilen bu kütüphanedir.
# pytextrank için python parçacığı
ithalat alanı
pytextrank'i içe aktar
# bir fransız modeli yükle
nlp = spacy.load("fr_core_news_sm")
# boruya pytextrank ekleyin
nlp.add_pipe("textrank")
doc = nlp(metin)
textrank_keyphrases = doc._.phrases
İşte en iyi 5 sonuç:
“Kopenhag”, “novembre”, “İzlenimler Graz”, “Graz”, “John Coltrane”
TextRank, anahtar sözcükleri ayıklamanın yanı sıra cümleleri de çıkarır. Bu, sözde "özetleyici özetler" yapmak için çok yararlı olabilir - bu konu bu makalede ele alınmayacaktır.
Sonuçlar
Burada test edilen üç yöntemden son ikisi bize metnin konusuyla oldukça alakalı görünüyor. Bu yaklaşımları daha iyi karşılaştırmak için, elbette bu farklı modelleri daha fazla sayıda örnek üzerinde değerlendirmemiz gerekecekti. Bu anahtar kelime çıkarma modellerinin alaka düzeyini ölçmek için gerçekten de ölçümler var.
Bu sözde geleneksel modeller tarafından üretilen anahtar kelime listeleri, sayfalarınızın iyi hedeflendiğini kontrol etmek için mükemmel bir temel sağlar. Ek olarak, bir arama motorunun içeriği nasıl anlayabileceği ve sınıflandırabileceğine dair bir ilk tahminde bulunurlar.
Öte yandan, BERT gibi önceden eğitilmiş NLP modellerini kullanan diğer yöntemler de bir belgeden kavramları çıkarmak için kullanılabilir. Sözde klasik yaklaşımın aksine, bu yöntemler genellikle anlambilimin daha iyi yakalanmasını sağlar.
Farklı değerlendirme yöntemleri, bağlamsal yerleştirmeler ve transformatörler, konuyla ilgili ikinci bir makalede sunulacak!
Bahsedilen üç yöntemden biriyle bu makaleden çıkarılan anahtar kelimelerin listesi:
"yöntemler", "anahtar kelimeler", "anahtar kelimeler", "metin", "çıkartılan anahtar kelimeler", "Doğal Dil İşleme"
bibliyografik referanslar
- [1] Daha Fazla Dil Bilgisi Sağlanan İyileştirilmiş Otomatik Anahtar Kelime Çıkarma, Anette Hulth, 2003
- [2] Bireysel Belgelerden Otomatik Anahtar Kelime Çıkarma, Stuart Rose et. diğerleri, 2010
- [3] YAKA! Birden çok yerel özellik kullanarak tek bir belgeden anahtar kelime çıkarma, Ricardo Campos et. al, 2020
- [4] TextRank: Metinlere Düzen Getirmek, Rada Mihalcea et. diğerleri, 2004
14 günlük ücretsiz denemenizi başlatın
 Denemenizi başlatın
Denemenizi başlatın