
Oncrawl dışında, Oncrawl verileriyle karmaşık veri soruları nasıl yanıtlanır?
Yayınlanan: 2022-01-04Kurumsal SEO için Oncrawl'ın avantajlarından biri, ham verilerinize tam erişime sahip olmaktır. SEO verilerinizi bir BI veya veri bilimi iş akışına bağlıyor, kendi analizlerinizi yapıyor veya kuruluşunuz için veri güvenliği yönergeleri dahilinde çalışıyor olsanız da, ham SEO ve web sitesi denetim verileri birçok amaca hizmet edebilir.
Bugün karmaşık veri sorularını yanıtlamak için Oncrawl verilerinin nasıl kullanılacağına bakacağız.
Karmaşık veri sorusu nedir?
Karmaşık veri soruları, basit bir veritabanı aramasıyla yanıtlanamayan, ancak yanıtı elde etmek için veri işleme gerektiren sorulardır.
SEO'ların sıklıkla sahip olduğu "karmaşık" veri sorularına ilişkin birkaç yaygın örnek:
- 404 durumuyla diğer sayfalara yönlendiren sayfalara işaret eden tüm bağlantıların bir listesini oluşturma
- URL olmayan metriklere dayalı bir segmentasyonda tüm bağlantıların ve sayfalara işaret eden bağlantı metinlerinin bir listesini oluşturma
Oncrawl'da karmaşık veri soruları nasıl yanıtlanır?
Oncrawl'ın veri yapısı, neredeyse tüm sitelerin neredeyse gerçek zamanlı olarak veri aramasına izin verecek şekilde oluşturulmuştur. Bu, arayüzde arama sürelerinin minimumda tutulmasını sağlamak için farklı veri kümelerinde farklı veri türlerinin depolanmasını içerir. Örneğin, URL'lerle ilişkili tüm verileri tek bir veri kümesinde saklarız: yanıt kodu, giden bağlantı sayısı, mevcut yapılandırılmış veri türü, sözcük sayısı, organik ziyaret sayısı... Ve bağlantılarla ilgili tüm verileri ayrı bir veri kümesinde saklarız: bağlantı hedefi, bağlantı kaynağı, bağlantı metni…
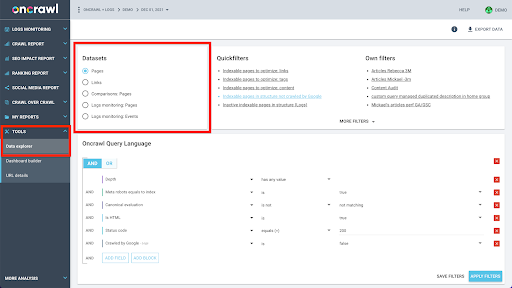
Bu veri kümelerine katılmak, hesaplama açısından karmaşıktır ve Oncrawl uygulamasının arabiriminde her zaman desteklenmez. Bir veri kümesini diğerinde aramak için filtrelemeyi gerektiren bir şey aramakla ilgileniyorsanız, ham verileri kendi başınıza manipüle etmenizi öneririz.
Tüm Oncrawl verileri sizin için mevcut olduğundan, veri kümelerini birleştirmenin ve karmaşık sorguları ifade etmenin birçok yolu vardır.
Bu makalede, birçok müşterimizin yüksek hacimli sayfalara sahip sitelerin verilerini incelerken karşılaştığı çok büyük veri kümeleri için uygun olan Google Cloud ve BigQuery kullanarak bunlardan birine bakacağız.
Neye ihtiyacın olacak
Bu makalede tartışacağımız yöntemi takip etmek için aşağıdaki araçlara erişmeniz gerekir:
- tarama
- Büyük Veri Dışa Aktarma ile Oncrawl API'si
- Google Bulut Depolama
- BigQuery
- Oncrawl'dan BigQuery'ye veri aktarmak için bir Python betiği (Bunu makale sırasında oluşturacağız.)
Başlamadan önce Oncrawl'da tamamlanmış bir tarama raporuna erişiminiz olması gerekir.
Google BigQuery'de Oncrawl verilerinden nasıl yararlanılır?
Bugünkü yazının planı şu şekilde:
- İlk olarak, Google Cloud Storage'ın Oncrawl'dan veri alacak şekilde ayarlandığından emin olacağız.
- Ardından, belirli bir taramadan verileri bir Google Cloud Storage paketine dışa aktarmak için Oncrawl'ın Büyük Veri dışa aktarmalarını çalıştırmak için bir Python komut dosyası kullanacağız. İki veri kümesini dışa aktaracağız: sayfalar ve bağlantılar.
- Bu yapıldığında, Google BigQuery'de bir veri seti oluşturacağız. Ardından, BigQuery veri kümesindeki iki dışa aktarmanın her birinden bir tablo oluşturacağız.
- Son olarak, karmaşık bir sorunun cevabını bulmak için tek tek veri kümelerini ve ardından her iki veri kümesini birlikte sorgulamayı deneyeceğiz.
Oncrawl verilerini almak için Google Cloud içinde kurulum
Bu kılavuzu özel, korumalı bir ortamda çalıştırmak için, devam eden mevcut projelerinizden ayırmak için yeni bir Google Cloud projesi oluşturmanızı öneririz.
Google Cloud'un evinden başlayalım.
Google Cloud ana sayfanızdan Bulut Depolamaya ek olarak birçok şeye erişebilirsiniz. Google Cloud Platform'un bulut depolama katmanında bulunan Bulut Depolama paketleri ile ilgileniyoruz: 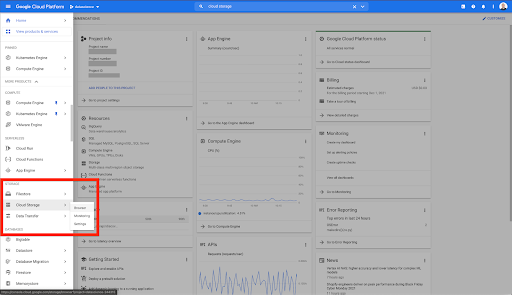
Bulut Depolama tarayıcısına doğrudan https://console.cloud.google.com/storage/browser adresinden de ulaşabilirsiniz.
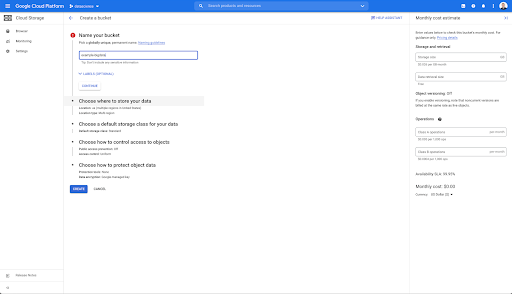
Ardından, bir Bulut Depolama paketi oluşturmanız ve Oncrawl Hizmet Hesabının seçtiğiniz önek altında buna yazmasına izin verilmesi için doğru izinleri vermeniz gerekir.
Google Cloud Storage paketi, Oncrawl'dan Büyük Veri dışa aktarmalarını Google BigQuery'ye yüklemeden önce tutmak için geçici bir depolama görevi görecek.
Bu kovada ayrıca iki klasör oluşturdum: "bağlantılar" ve "sayfalar": 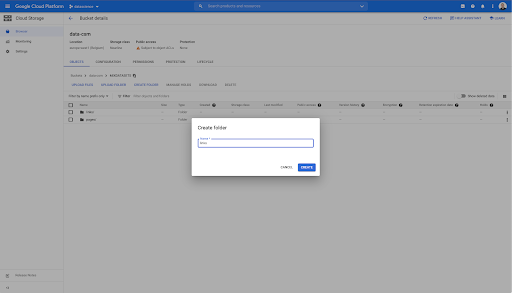
Oncrawl'dan Veri Kümelerini Dışa Aktarma
Artık verileri kaydetmek istediğimiz alanı ayarladık, onu Oncrawl'dan dışa aktarmamız gerekiyor. Verileri doğru biçimde dışa aktarabildiğimiz ve doğrudan kovaya kaydedebildiğimiz için, Oncrawl ile bir Google Cloud Storage paketine dışa aktarmak özellikle kolaydır. Bu, ekstra adımları ortadan kaldırır.
API anahtarı oluşturma
Oncrawl'dan BigQuery için Parquet biçiminde verilerin dışa aktarılması, Oncrawl hesabının sahibi adına API üzerinde programlı olarak hareket etmek için bir API anahtarının kullanılmasını gerektirir. Oncrawl uygulaması, hesabınızın her zaman iyi organize edilmiş ve temiz olması için kullanıcıların adlandırılmış API anahtarları oluşturmasına olanak tanır. API anahtarları, anahtarları ve amaçlarını yönetebilmeniz için farklı izinlerle (kapsamlar) da ilişkilendirilir.
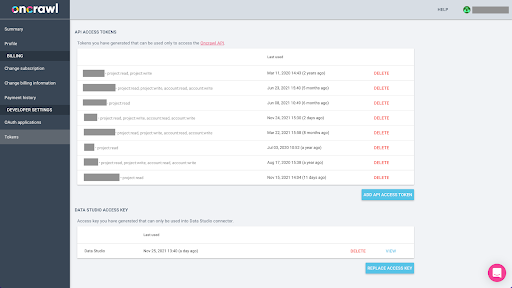
Yeni anahtarımıza 'Bilgi oturum anahtarı' adını verelim. Veri dışa aktarmalarını oluşturduğumuz için Büyük Veri dışa aktarma özelliği, hesapta yazma izinleri gerektirir. Bunu gerçekleştirmek için projede okuma erişimimiz ve hesapta okuma ve yazma erişimimiz olması gerekir.
Şimdi panoma kopyalayacağım yeni bir API anahtarımız var.
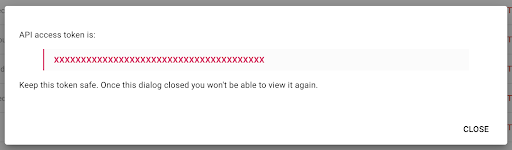
Güvenlik nedenleriyle anahtarı yalnızca bir kez kopyalayabileceğinizi unutmayın. Anahtarı kopyalamayı unutursanız, anahtarı silmeniz ve yeni bir tane oluşturmanız gerekecektir.
Python betiğinizi oluşturma
Bunun için bir Google Colab not defteri oluşturdum, ancak kendi araçlarınızı veya kendi defterinizi oluşturabilmeniz için aşağıdaki kodu paylaşacağım.
1. API anahtarınızı global bir değişkende saklayın
İlk olarak ortamı önyükliyoruz ve API anahtarını “Oncrawl Token” adlı global bir değişkende bildiriyoruz. Ardından, deneyin geri kalanı için hazırlanırız:
#@title Oncrawl API'sine erişin
#@markdown Bu not defterinin Oncrawl verilerinize erişmesine izin vermek için API simgenizi aşağıda sağlayın:
# ONCRAWL API İÇİN TOKENİNİZ
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip cezaevi yükleme
IPython.display'den clear_output içe aktarın
clear_output()
print('Hepsi yüklendi.') 
2. Birlikte çalışmak istediğiniz Oncrawl projesini seçmek için bir açılır liste oluşturun
Ardından, bu anahtarı kullanarak, projelerin listesini alarak ve bu listeden bir açılır pencere öğesi oluşturarak oynamak istediğimiz projeyi seçebilmek istiyoruz. İkinci kod bloğunu çalıştırarak aşağıdaki adımları gerçekleştirin:
- Yeni gönderilen API anahtarını kullanarak hesaptaki projelerin listesini almak için Oncrawl API'sini arayacağız.
- API yanıtından projenin listesini aldıktan sonra, projenin adını ve projenin başlangıç URL'sini kullanarak onu bir liste olarak biçimlendiririz.
- Yanıtta sağlanan projenin kimliğini saklarız.
- Bir açılır menü oluşturuyoruz ve bunu kod bloğunun altında gösteriyoruz.
#@title İlgili Oncrawl projesini seçerek analiz edilecek web sitesini seçin
içe aktarma istekleri
ithal hapishane
ipywidget'ları widget olarak içe aktar
json'u içe aktar
# Projelerin listesini al
yanıt = request.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
sınır=1000,
sort='ad:artan'
),
headers={ 'Yetkilendirme': 'Taşıyıcı '+ONCRAWL_TOKEN }
)
json_res = yanıt.json()
Kullanıcının bir proje seçmesine izin vermek için #prepare açılır menüsü
projeler = []
json_res['projects'] içindeki öğe için:
projeler.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
çıktı = widgets.Output()
açılan_amaç = widgets.Dropdown(seçenekler = projeler, açıklama="Proje: ")
def dropdown_project_eventhandler(değiştir):
çıktı.clear_output()
çıktı ile:
ekran(projeler)
açılan_amaç.observe(dropdown_project_eventhandler, isimler='değer')
göster(dropdown_amacı) Bunun oluşturduğu açılır menüden API anahtarının erişebildiği projenin tam listesini görebilirsiniz. 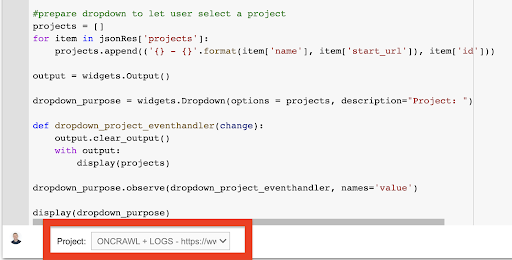
Bugünkü gösterim amacıyla, Oncrawl web sitesine dayalı bir demo projesi kullanıyoruz.
3. Birlikte çalışmak istediğiniz proje içindeki gezinme profilini seçmek için bir açılır liste oluşturun.
Ardından, hangi tarama profilinin kullanılacağına karar vereceğiz. Bu projede bir tarama profili seçmek istiyoruz. Demo projesinin birçok farklı tarama yapılandırması vardır: 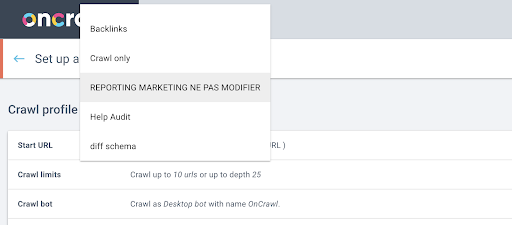
Bu durumda, Oncrawl ekiplerinin deneyler için sıklıkla kullandığı bir projeye bakıyoruz, bu yüzden Oncrawl web sitesinin performansını izlemek için pazarlama ekibi tarafından kullanılan tarama profilini seçeceğim. Bunun en kararlı tarama profili olması gerektiği için, bugünkü deney için iyi bir seçimdir.
Tarama profilini almak için, projedeki her bir tarama profilinde son taramayı istemek üzere Oncrawl API'sini kullanacağız:
- Verilen proje için Oncrawl API'sini sorgulamaya hazırlanıyoruz.
- "Oluşturulma" tarihine göre azalan sırayla döndürülen tüm taramaları isteyeceğiz.
içe aktarma istekleri
json'u içe aktar
ipywidget'ları widget olarak içe aktar
proje_kimliği = açılır_amaç.değer
# Proje ayrıntılarını alın (projedeki tüm taramaları dahil edin)
proje = request.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=Doğru, sort="created_at:desc"),
headers={ 'Yetkilendirme': 'Taşıyıcı '+ONCRAWL_TOKEN }).json()
# Tarama profiline göre grup taramaları (tarama adı)
crawls_by_config = {}
denemek:
['taramalar'] projesinde gezinme için:
["bitti"] içinde tarama['durum'] ise:
tarama['crawl_config']['name'], crawls_by_config.keys() içinde değilse:
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
eğer tarama['status'] == "arşivlendi":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Doğru
e olarak İstisna hariç:
İstisnayı yükselt ("hata {} , {}".format(e, proje))
# Açılır seçim için listeyi oluşturun
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) için k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = liste, açıklama="Tarama yapılandırmaları: ")
def dropdown_cc_eventhandler(değiştir):
çıktı.clear_output()
çıktı ile:
göster(crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Bu projede canlı tarama bulunamadı')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, name='değer')
göster(dropdown_crawl_configs)Bu kod çalıştırıldığında, Oncrawl API “created at” özelliğine inerek taramaların listesi ile bize yanıt verecektir.
Ardından, sadece biten taramalara odaklanmak istediğimiz için taramaların listesine geçeceğiz. "Tamamlandı" durumundaki her bir tarama için, tarama profilinin adını kaydedeceğiz ve tarama kimliğini saklayacağız.
Çok fazla tarama göstermek istemememiz için, tarama profiline göre en fazla bir tarama tutacağız.
Sonuç, projedeki gezinme profilleri listesinden oluşturulan bu yeni açılır menüdür. İstediğimizi seçeceğiz. Bu, pazarlama ekibi tarafından yürütülen son taramayı alacaktır: 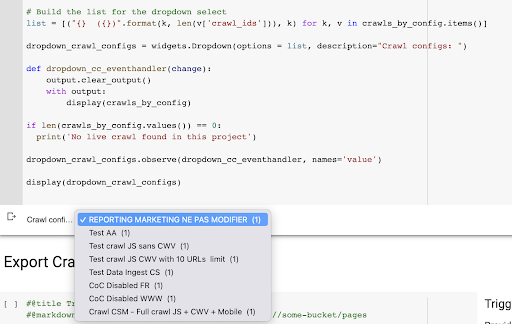
4. Kullanmak istediğimiz profille son taramayı tanımlayın
Seçilen profildeki son taramayla ilişkili tarama kimliğine zaten sahibiz. "crawl_by_config" nesne sözlüğünde gizlidir. 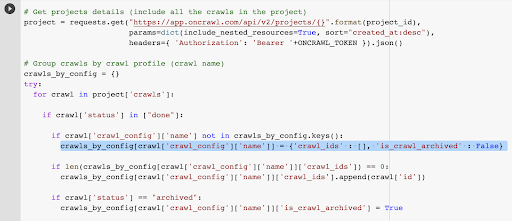
Bunu arayüzde kolayca kontrol edebilirsiniz: Bu profil analizinde en son tamamlanan taramayı bulun. 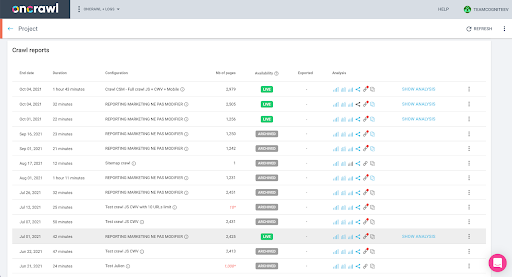
Analizi görüntülemek için tıklarsak, tarama kimliğinin E617 ile bittiğini görürüz. 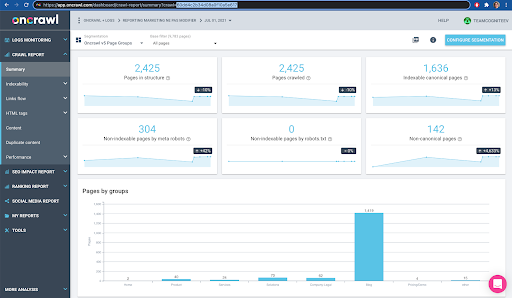
Bugünkü gösterimin amacı için tarama kimliğini not edelim.
Tabii ki, ne yaptığınızı zaten biliyorsanız, projelerin listesini ve tarama profiline göre taramaların listesini almak için Oncrawl API'sini çağırmak için az önce ele aldığımız adımları atlayabilirsiniz: zaten tarama kimliğine sahipsiniz. arabirim ve bu kimlik, dışa aktarmayı çalıştırmak için ihtiyacınız olan tek şey.
Şu ana kadar gerçekleştirdiğimiz adımlar, API anahtarının neye erişimi olduğu göz önüne alındığında, verilen projenin verilen tarama profilinin son taramasını alma sürecini kolaylaştırmak içindir. Bu çözümü diğer kullanıcılara sağlıyorsanız veya otomatikleştirmek istiyorsanız bu yararlı olabilir.
5. Tarama sonuçlarını dışa aktarın
Şimdi dışa aktarma komutuna bakacağız:
#@title Büyük veri dışa aktarımını tetikleyin
#@markdown GCS Paketinizi ve gs://some-bucket/pages ön ekini sağlayın
# GCS KEPİNİZ
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# Verilen proje / tarama profilinden son tarama kimliğini al
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Veri dışa aktarma sorgusu için şablon yükü
yük = {
"veri_dışa aktarma": {
"data_type": 'sayfa',
"resource_id": last_crawl_id,
"output_format": 'parke',
"hedef": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Dışa aktarmayı tetikle
dışa aktarma = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Yetkilendirme': 'Taşıyıcı '+ONCRAWL_TOKEN }).json()
# API yanıtını görüntüle
görüntüleme(dışa aktarma)
# İhracat kimliğini ileride kullanmak üzere saklayın
export_id = dışa aktar['data_export']['id']Daha önce kurduğumuz Cloud Storage paketine ihracat yapmak istiyoruz.
Bunun içinde, son tarama kimliği için sayfaları dışa aktaracağız:
- Son tarama kimliği, 3. adımda oluşturulan "crawls_by_config" sözlüğünde bir yerde saklanan tarama kimlikleri listesinden elde edilir.
- 4. adımda açılan menüye karşılık gelen olanı seçmek istiyoruz, bu nedenle açılır menünün value niteliğini kullanıyoruz.
- Ardından, crawl_ID özniteliğini çıkarırız. Bu bir liste. Listedeki ilk 50 öğeyi tutacağız. Bunu yapmamız gerekiyor çünkü 2. adımda, hatırlayacağınız gibi, crawls_by_config sözlüğünü oluşturduğumuzda, yapılandırma adı başına yalnızca bir tarama kimliği depoladık.
Dışa aktarmayı göndermek istediğimiz Google Cloud Storage paketini ve önekini veya klasörünü sağlamayı kolaylaştırmak için giriş alanları ayarladım. 
Gösteri amacıyla bugün, zaten kurduğum klasörlerden birinin içindeki “karma veri kümesi” klasörüne yazacağız. Google Cloud Storage'da kovamızı kurduğumuzda, "bağlantılar" dışa aktarma ve "sayfalar" dışa aktarma için klasörler hazırladığımı hatırlayacaksınız.
İlk dışa aktarma için, sayfaları Parke dosya biçimini kullanarak son tarama kimliği için "sayfalar" klasörüne dışa aktarmak isteyeceğiz. 
Aşağıdaki sonuçlarda, bir API anahtarı kullanarak Büyük Veri dışa aktarma isteğinde bulunmak için uç nokta olan veri dışa aktarma uç noktasına gönderilecek yükü göreceksiniz:
# Veri dışa aktarma sorgusu için şablon yükü
yük = {
"veri_dışa aktarma": {
"data_type": 'sayfa',
"resource_id": last_crawl_id,
"output_format": 'parke',
"hedef": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Bu, dışa aktarmak istediğiniz veri kümesinin türü de dahil olmak üzere birkaç öğe içerir. Sayfa veri kümesini, bağlantı veri kümesini, kümeler veri kümesini veya yapılandırılmış veri kümesini dışa aktarabilirsiniz. Ne yapılabileceğini bilmiyorsanız, buraya bir hata girebilirsiniz ve API'yi aradığınızda, veri türü seçiminin sayfa veya bağlantı veya küme veya yapılandırılmış veri olması gerektiğini belirten bir mesaj alırsınız. Mesaj şöyle görünür:

{'fields': [{'message': 'Geçerli bir seçim değil. "Sayfa", "bağlantı", "küme", "yapılandırılmış_veriler"den biri olmalıdır.',
'ad': 'veri_türü',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
Bugünkü denemenin amacı için, sayfa veri kümesini ve bağlantı veri kümesini ayrı dışa aktarmalarda dışa aktaracağız.
Sayfa veri kümesiyle başlayalım. Bu kod bloğunu çalıştırdığımda, şuna benzeyen API çağrısının çıktısını yazdırdım:
{'data_export': {'data_type': 'sayfa',
'export_failure_reason': Yok,
'kimlik': 'XXXXXXXXXXXXXXX',
'output_format': 'parke',
'output_format_parameters': Yok,
'output_row_count': Yok,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'durum': 'İSTENİLEN',
'hedef': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
Bu, ihracatın talep edildiğini görmemi sağlıyor.
İhracatın durumunu kontrol etmek istersek, bu çok basit. Bu kod bloğunun sonunda kaydettiğimiz dışa aktarma kimliğini kullanarak, aşağıdaki API çağrısı ile herhangi bir zamanda dışa aktarmanın durumunu talep edebiliriz:
# İHRACAT DURUMU
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Yetkilendirme': 'Taşıyıcı '+ONCRAWL_TOKEN }).json ()
göster(export_status)
Bu, döndürülen JSON nesnesinin bir parçası olarak bir durumu gösterir:
{'data_export': {'data_type': 'sayfa',
'export_failure_reason': Yok,
'kimlik': 'XXXXXXXXXXXXXXX',
'output_format': 'parke',
'output_format_parameters': Yok,
'output_row_count': Yok,
'output_size_in_bytes': Yok,
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'durum': 'İHRACAT',
'hedef': 'gcs',
'target_parameters': {'gcs_bucket': 'veri-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} Dışa aktarma tamamlandığında ( 'status': 'DONE' ), Google Cloud Storage'a dönebiliriz.
Kovamıza bakarsak ve “bağlantılar” klasörüne girersek, sayfaları dışa aktardığımız için burada henüz bir şey yok. 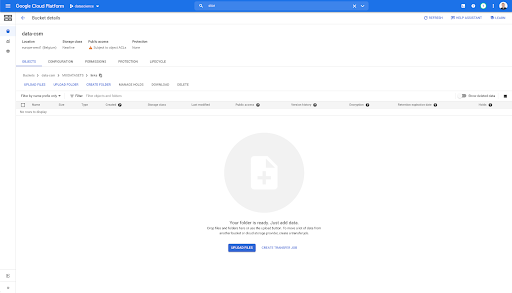
Ancak “sayfalar” klasörüne baktığımızda dışa aktarmanın başarılı olduğunu görebiliriz. Bir Parke dosyamız var: 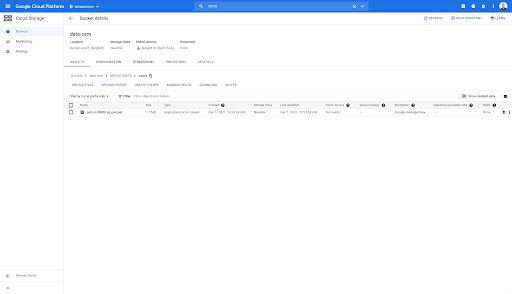
Bu aşamada, sayfalar veri kümesi BigQuery'de içe aktarılmaya hazırdır, ancak önce bağlantılar için Parquet dosyasını almak için yukarıdaki adımları tekrarlayacağız:
- Bağlantı önekini ayarladığınızdan emin olun.
- "Bağlantı" veri türünü seçin.
- İkinci dışa aktarmayı istemek için bu kod bloğunu yeniden çalıştırın.

Bu, “bağlantılar” klasöründe bir Parke dosyası üretecektir.
BigQuery veri kümeleri oluşturma
Dışa aktarma işlemi devam ederken ilerleyip BigQuery'de veri kümeleri oluşturmaya başlayabilir ve Parke dosyalarını ayrı tablolara aktarabiliriz. Sonra birlikte sofralara geçeceğiz.
Şimdi yapmak istediğimiz şey, Google Cloud Platform'un bir parçası olan Google Big Query ile oynamak. Ekranın üst kısmındaki arama çubuğunu kullanabilir veya doğrudan https://console.cloud.google.com/bigquery adresine gidebilirsiniz.
İşiniz için bir veri seti oluşturma
Google BigQuery içinde bir veri kümesi oluşturmamız gerekecek: 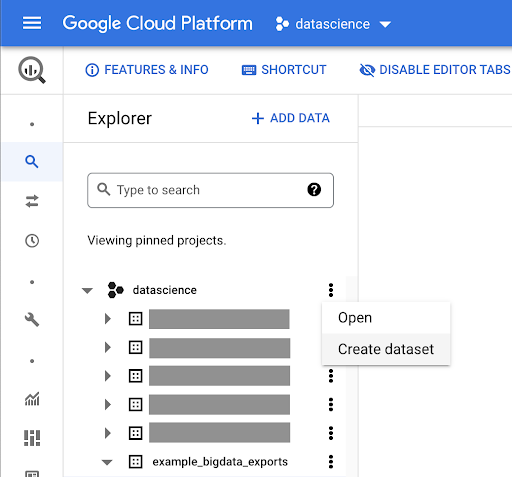
Veri kümesine bir ad vermeniz ve verilerin depolanacağı konumu seçmeniz gerekir. Bu önemlidir, çünkü verilerin işlendiği yeri belirler ve değiştirilemez. Verileriniz GDPR veya diğer gizlilik yasaları kapsamındaki bilgileri içeriyorsa, bunun bir etkisi olabilir. 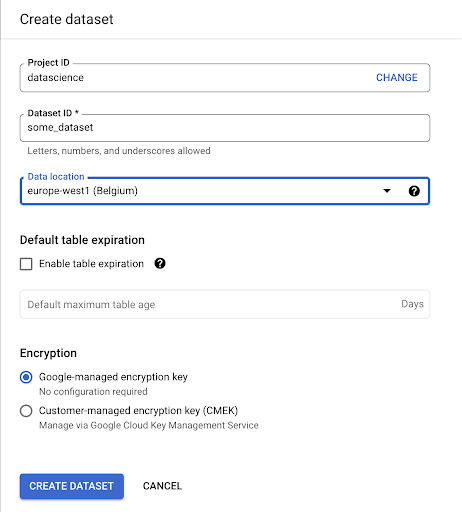
Bu veri kümesi başlangıçta boştur. Açtığınızda, bir tablo oluşturabilecek, veri kümesini paylaşabilecek, kopyalayabilecek, silebilecek vb.
Verileriniz için tablolar oluşturma
Bu veri setinde bir tablo oluşturacağız. 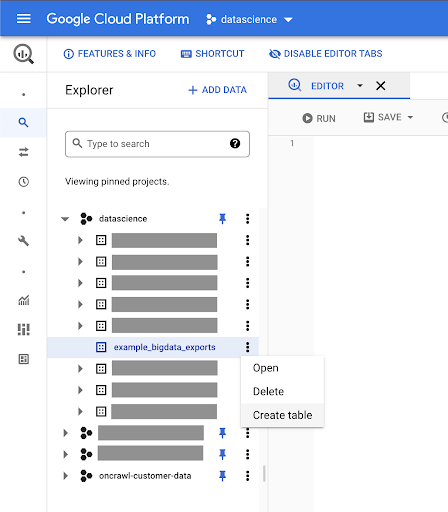
Boş bir tablo oluşturabilir ve ardından şemayı sağlayabilirsiniz. Şema, tablodaki sütunların tanımıdır. Kendinizinkini tanımlayabilir veya bir dosyadan şema seçmek için Google Bulut Depolama'ya göz atabilirsiniz.
Bu son seçeneği kullanacağız. Kovamıza, ardından “sayfalar” klasörüne gideceğiz. Sayfalar dosyasını seçelim. Sadece bir dosya var, bu yüzden sadece birini seçebiliyoruz, ancak dışa aktarma birkaç dosya oluşturmuş olsaydı hepsini seçebilirdik. 
Dosyayı seçtiğimizde Parquet dosya formatında olduğunu otomatik olarak algılıyor. “Sayfalar” adında bir tablo oluşturmak istiyoruz ve şema kaynak dosya tarafından tanımlanacak. 
Bir Parke dosyası yüklediğimizde, bir şema gömer. Başka bir deyişle, oluşturduğumuz tablonun sütunlarının tanımı, Parquet dosyasında zaten var olan şemadan çıkarılacaktır. Burası aslında sihrin bir parçasının gerçekleştiği yer.
Şimdi ilerleyelim ve basitçe Parquet dosyasından tabloyu oluşturalım. 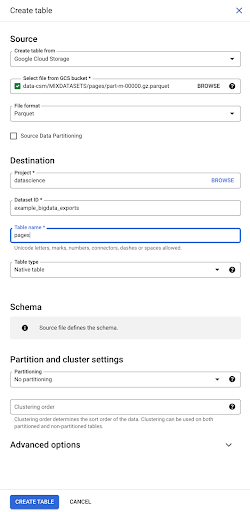
Sol kenar çubuğunda, veri kümemizde tam olarak istediğimiz gibi bir tablonun göründüğünü görebiliriz:
Böylece, şimdi, Parquet dosyasından otomatik olarak çıkarılan tüm alanları içeren sayfalar tablosunun şemasına sahibiz. Inrank, sayfanın derinliği, sayfa bir yönlendirme ise vb. 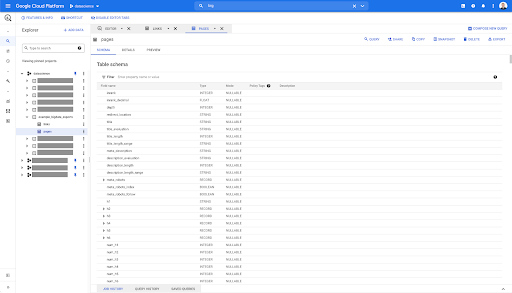
Bu alanların çoğu, Data Studio'da Oncrawl Data Studio bağlayıcısı aracılığıyla kullanıma sunulanlarla ve Oncrawl arabirimindeki Veri Gezgini'nde gördüklerinizle aynıdır. 
Ancak, bazı farklılıklar vardır. Ham büyük veri dışa aktarma ile oynadığımızda, tüm ham verilere sahipsiniz.
- Data Studio'da bazı alanlar yeniden adlandırılır, bazı alanlar gizlenir ve durum gibi bazı alanlar eklenir.
- Veri Gezgini'nde bazı alanlar "sanal alanlar" olarak adlandırdığımız alanlardır; bu, bunların temel alan için bir tür kısayol olabileceği anlamına gelir. Veri Gezgini'nde bulunan bu sanal alanlar şemada listelenmeyecektir, ancak Parke dosyasında mevcut olana göre yeniden oluşturulabilirler.
Şimdi bu tabloyu kapatalım ve linkler için tekrar yapalım.
Bağlantılar tablosu için şema biraz daha küçüktür. 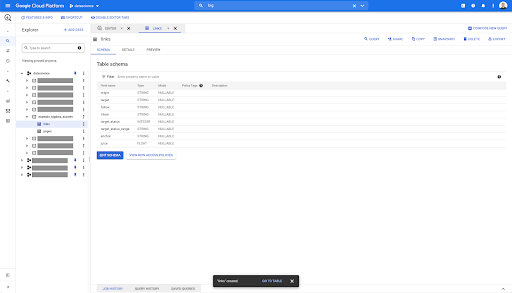
Yalnızca aşağıdaki alanları içerir:
- Bağlantının kaynağı,
- Bağlantının hedefi,
- Takip özelliği,
- İç mülkiyet,
- hedef durumu,
- Hedef durum aralığı,
- Bağlantı metni ve
- Bağlantı tarafından satın alınan meyve suyu veya hisse senedi.
BigQuery'deki herhangi bir tabloda, önizleme sekmesini tıkladığınızda, veritabanını sorgulamadan tablonun bir önizlemesine sahip olursunuz: 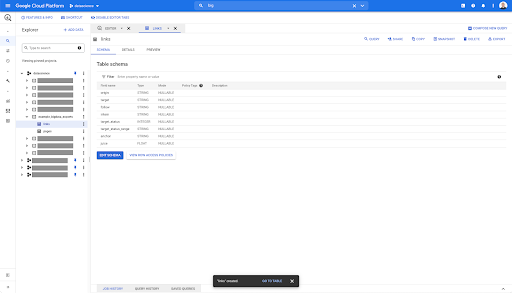
Bu, içinde nelerin mevcut olduğuna dair hızlı bir görünüm sağlar. Yukarıdaki bağlantılar tablosunun önizlemesinde, her bir satırın ve tüm sütunların bir önizlemesine sahipsiniz.
Bazı Oncrawl veri kümelerinde, birkaç satıra yayılan bazı satırlar görebilirsiniz. Size bir örneğim yok ama durum buysa, bunun nedeni bazı alanların bir değerler listesi içermesidir. Örneğin, bir sayfadaki h2 başlıkları listesinde, Big Query'de tek bir satır birkaç satıra yayılacaktır. Bir örnek görürsek buna daha sonra bakacağız.
Sorgunuzu oluşturma
BigQuery'de hiç sorgu oluşturmadıysanız, şimdi nasıl çalıştığını öğrenmek için bununla oynamanın zamanı geldi. BigQuery, verileri aramak için SQL kullanır.
Sorgular nasıl çalışır?
Örnek olarak, tüm URL'lere ve sıralarına bakalım…
url SEÇ, inrank ...
sayfalar veri setinden…
url SEÇ, `datascience-oncrawl.example_bigdata_exports.pages` den rütbe al...
sayfanın durum kodunun 200 olduğu yerde…
URL SEÇİN, `datascience-oncrawl.example_bigdata_exports.pages` NEREDE durum_kodu = 200'DEN sıralama ...
ve yalnızca ilk 10 sonucu saklayın:
URL SEÇİN, `datascience-oncrawl.example_bigdata_exports.pages` NEREDE durum_kodu = 200 LIMIT 10'dan sıralama
Bu sorguyu çalıştırdığımızda durum kodunun 200 olduğu sayfaların listesinin ilk 10 satırını alacağız.
Bu özelliklerden herhangi biri değiştirilebilir. f 10 yerine 1000 satır istiyorum, 1000 satır ayarlayabilirim:
URL SEÇİN, `datascience-oncrawl.example_bigdata_exports.pages` NEREDE durum_kodu = 200 LIMIT 1000'DEN sıralama
Sıralamak istersem, bunu “order-by” ile yapabilirim: bu bana, Inrank sırasına göre azalan tüm satırları verecektir.
url SEÇİN, `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000'DEN derece alın
Bu benim ilk sorgum. İstersem kaydedebilirim, bu da bana daha sonra istersem bu sorguyu yeniden kullanma yeteneği verir: 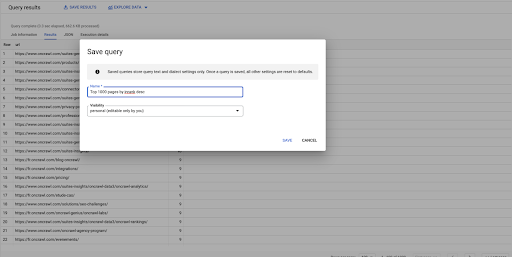
Basit soruları yanıtlamak için sorguları kullanma: 301 statüsüne sahip sayfaların tüm dahili bağlantılarını listeleme
Artık bir sorgunun nasıl oluşturulacağını bildiğimize göre, asıl problemimize geri dönelim.
İster basit ister karmaşık olsun, veri sorularını yanıtlamak istedik. "301 (yönlendirildi) durumu olan sayfalara işaret eden tüm dahili bağlantılar nelerdir ve bunları nerede bulabilirim?" gibi basit bir soruyla başlayalım.
Yeni bir sorgu oluşturma
Bunun nasıl çalıştığını keşfederek başlayacağız.
"Bağlantılar" veritabanından aşağıdaki öğeler için sütunlar isteyeceğim:
- Menşei
- Hedef
- Hedef durum kodu
`datascience-oncrawl.example_bigdata_exports.links` DAN kaynak, hedef, target_status SEÇİN
Bunları sadece dahili linklerle sınırlamak istiyorum ama diyelim ki kolonun adını veya linkin dahili mi harici mi olduğunu gösteren değeri hatırlamıyorum. Aramak için şemaya gidebilir ve değeri görüntülemek için önizlemeyi kullanabilirim: 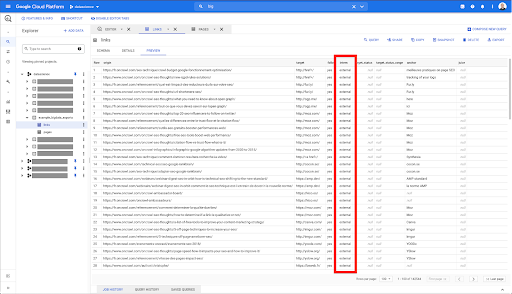
Bu bana sütunun "intern" olarak adlandırıldığını ve olası değer aralığının "harici" veya "dahili" olduğunu söylüyor.
Sorgumda “intern nerede dahilidir” belirtmek ve sonuçları şimdilik ilk 100 ile sınırlamak istiyorum:
`datascience-oncrawl.example_bigdata_exports.links` NEREDE stajyer GİBİ 'dahili' SINIR 100'DEN Origin, target, target_status SEÇİN
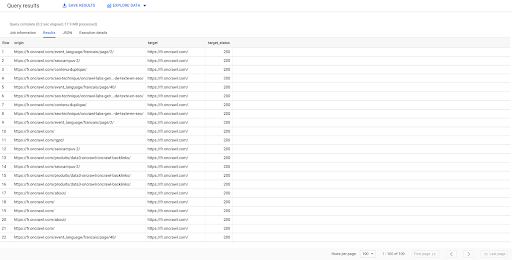
Yukarıdaki sonuç, hedef durumlarıyla birlikte bağlantıların listesini gösterir. Yalnızca dahili bağlantılarımız var ve sorguda belirtildiği gibi 100 tanesine sahibiz.
Yönlendirilen sayfalara yalnızca bu noktaya dahili bağlantılara sahip olmak istiyorsak, 'internatif gibi dahili ve hedef durumun 301'e eşit olduğu yerde' diyebiliriz:
'datascience-oncrawl.example_bigdata_exports.links' DAN 'datascience-oncrawl.exports.links' NEREDE stajyer GİBİ 'dahili' VE target_status = 301'den Origin, target, target_status SEÇİN
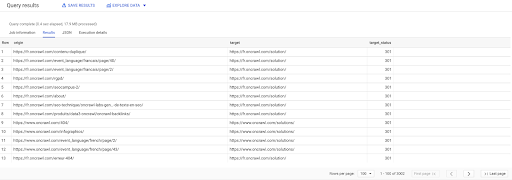
Kaç tane olduğunu bilmiyorsak, bu yeni sorguyu çalıştırabiliriz ve hedef durumu 301 olan 3002 dahili bağlantı olduğunu göreceğiz.
Tablolara katılma: yeniden yönlendirilen sayfalara işaret eden bağlantıların son durum kodlarını bulma
Bir web sitesinde, genellikle yeniden yönlendirilen sayfalara bağlantılar bulunur. Yönlendirildikleri sayfanın durum kodunu (veya nihai hedef URL'yi) bilmek istiyoruz.
Bir veri kümesinde, bağlantılarla ilgili bilgilere sahipsiniz: kaynak sayfa, hedef sayfa ve durum kodu (301 gibi), ancak yeniden yönlendirilen sayfanın işaret ettiği URL değil. Diğerinde, yönlendirmeler ve nihai hedefleri hakkında bilgi var, ancak bunlara bağlantının bulunduğu orijinal sayfa yok.
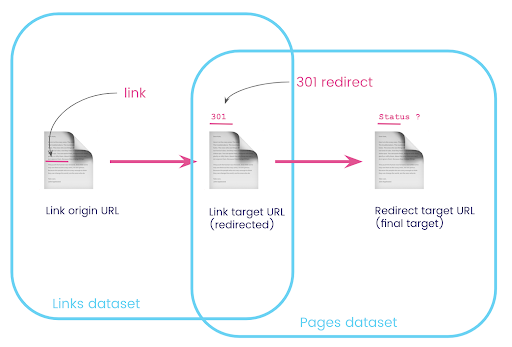
Bunu parçalayalım:
İlk olarak, yönlendirmelere bağlantılar istiyoruz. Bunu bir yere yazalım. İstiyoruz:
- Köken.
- Hedef. Hedefin bir 301 durum kodu olmalıdır.
- Yönlendirmenin son hedefi.
Başka bir deyişle, bağlantı veri setinde şunları istiyoruz:
- Bağlantının kökeni
- Bağlantının hedefi
Sayfalar veri setinde şunları istiyoruz:
- Yönlendirilen tüm hedefler
- Yönlendirmenin son hedefi
Bu bize şöyle bir sorgu verecektir:
URL, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` sayfalarını NEREDE durum_kodu = 301 VEYA durum_kodu = 302 olarak SEÇİN
Bu bana denklemin ilk kısmını vermeli.
Şimdi, az önce oluşturduğum sorgunun sonuçları olan, veri kümelerim için takma adlar kullanan ve bunları bağlantı hedef URL'sinde ve sayfa URL'sinde birleştiren tüm bağlantılara ihtiyacım var. Bu, bu bölümün başındaki diyagramdaki iki veri kümesinin örtüşen alanına karşılık gelir.
SEÇME linkler.orijin, sayfalar.url, sayfalar.final_yönlendirme_konumu, sayfalar.final_yönlendirme_durumu İTİBAREN "datascience-oncrawl.example_bigdata_exports.pages" AS sayfaları KATILMAK "datascience-oncrawl.example_bigdata_exports.links" AS bağlantıları ÜZERİNDE linkler.target = sayfalar.url NEREDE sayfalar.durum_kodu = 301 VEYA sayfalar.durum_kodu = 302 TARAFINDAN SİPARİŞ köken ASC
Sorgu sonuçlarında, işleri daha net hale getirmek için sütunları yeniden adlandırabilirim, ancak zaten ilk sütundaki bir sayfadan bir bağlantım olduğunu görebiliyorum, bu da ikinci sütundaki sayfaya gidiyor ve bu da şuraya yönlendiriliyor: üçüncü sütundaki sayfa. Dördüncü sütunda, nihai hedefin durum koduna sahibim: 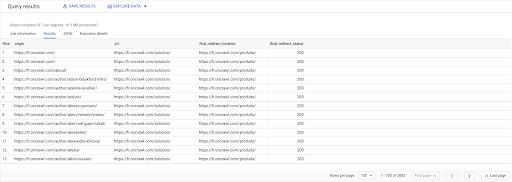
Artık hangi bağlantıların yeniden yönlendirilen ve 200 sayfaya çözümlenmeyen sayfaları işaret ettiğini söyleyebilirim. Belki de 404'lerdir, bu da bana düzeltmem için öncelikli bir bağlantı listesi verir.
Daha önce bir sorgunun nasıl kaydedileceğini gördük. Ayrıca 16000 satıra kadar sonuç için sonuçları kaydedebiliriz: 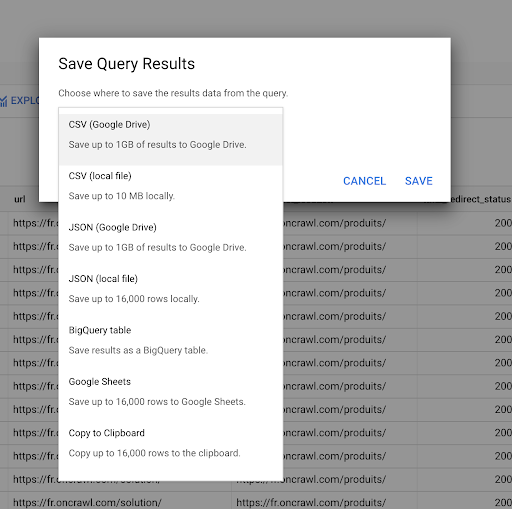
Daha sonra bu sonuçları birçok farklı şekilde kullanabiliriz. İşte birkaç örnek:
- Bunu yerel olarak bir CSV veya JSON dosyası olarak kaydedebiliriz.
- Bunu bir Google E-Tablolar e-tablosu olarak kaydedebilir ve ekibin geri kalanıyla paylaşabiliriz.
- Ayrıca doğrudan Data Studio'ya da aktarabiliriz.
Stratejik bir avantaj olarak veri
Tüm bu olanaklarla, karmaşık sorularınızın yanıtlarını stratejik olarak kullanmak kolaydır. BigQuery sonuçlarını Data Studio'ya veya diğer veri görselleştirme platformlarına bağlama konusunda zaten deneyiminiz olabilir veya bilgileri bir mühendislik ekibine, hatta bir iş zekası veya veri analizi iş akışına ileten bir süreciniz zaten mevcut olabilir.
Bu makaledeki adımları bir sürecin parçası olarak eklediyseniz, BigQuery'deki tüm adımları otomatikleştirebileceğinizi unutmayın: Bu makalede gerçekleştirdiğimiz tüm işlemlere BigQuery API üzerinden de erişilebilir. Bu, bir komut dosyasının veya özel aracın parçası olarak programlı olarak çalıştırılabilecekleri anlamına gelir.
Sonraki adımlarınız ne olursa olsun, ilk adım her zaman ham SEO ve web sitesi verilerine erişmektir. Bu verilere erişimin teknik analizin en önemli bölümlerinden biri olduğuna inanıyoruz: Oncrawl ile ham verilerinize her zaman tam erişime sahip olacaksınız.
Verilere erişim aynı zamanda Oncrawl arayüzünde mümkün olanın ötesine geçebileceğiniz ve sorduğunuz sorular ne kadar karmaşık olursa olsun verileriniz arasındaki tüm ilişkileri keşfedebileceğiniz anlamına gelir.