
Word Vectors คืออะไร & มาร์กอัปที่มีโครงสร้างเพิ่มพลังให้พวกเขาอย่างไร
เผยแพร่แล้ว: 2021-07-28คุณกำหนดคำเวกเตอร์ได้อย่างไร? ในบทความนี้ ผมจะแนะนำคุณเกี่ยวกับแนวคิดของเวกเตอร์คำ เราจะพูดถึงการฝังคำประเภทต่างๆ และที่สำคัญกว่านั้น การทำงานของเวกเตอร์คำ จากนั้นเราจะสามารถเห็นผลกระทบของเวกเตอร์คำใน SEO ซึ่งจะทำให้เราเข้าใจว่ามาร์กอัป Schema.org สำหรับข้อมูลที่มีโครงสร้างสามารถช่วยให้คุณใช้ประโยชน์จากเวกเตอร์คำใน SEO ได้อย่างไร
อ่านโพสต์นี้ต่อไปหากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับหัวข้อเหล่านี้
ไปดำน้ำกันเลย
เวกเตอร์คำคืออะไร?
เวกเตอร์คำ (เรียกอีกอย่างว่าการฝังคำ) เป็นประเภทของการแสดงคำที่ช่วยให้คำที่มีความหมายคล้ายกันมีการแสดงที่เท่าเทียมกัน
ในแง่ง่ายๆ: เวกเตอร์คำคือการแสดงเวกเตอร์ของคำใดคำหนึ่ง
ตามวิกิพีเดีย:
เป็นเทคนิคที่ใช้ในการประมวลผลภาษาธรรมชาติ (NLP) สำหรับแสดงคำสำหรับการวิเคราะห์ข้อความ โดยทั่วไปเป็นเวกเตอร์มูลค่าจริงที่เข้ารหัสความหมายของคำเพื่อให้คำที่อยู่ใกล้ในพื้นที่เวกเตอร์มีแนวโน้มที่จะมีความหมายคล้ายกัน
ตัวอย่างต่อไปนี้จะช่วยให้เราเข้าใจสิ่งนี้ได้ดีขึ้น:
ดูประโยคที่คล้ายกันเหล่านี้:
มีวันที่ดี และ มีวันที่ดี
พวกเขาแทบไม่มีความหมายที่แตกต่างกัน ถ้าเราสร้างคำศัพท์ที่ละเอียดถี่ถ้วน (เรียกมันว่า V) ก็จะมี V = {Have, a, good, great, day} รวมคำทั้งหมด เราสามารถเข้ารหัสคำได้ดังนี้
การแสดงเวกเตอร์ของคำอาจเป็น เวกเตอร์ที่เข้ารหัสแบบร้อนครั้งเดียว โดย ที่ 1 แทนตำแหน่งที่มีคำนั้นอยู่ และ 0 แสดงถึงส่วนที่เหลือ
มี = [1,0,0,0,0]
a=[0,1,0,0,0]
ดี=[0,0,1,0,0]
ยิ่งใหญ่=[0,0,0,1,0]
วัน=[0,0,0,0,1]
สมมติว่าคำศัพท์ของเรามีเพียงห้าคำ: King, Queen, Man, Woman และ Child เราสามารถเข้ารหัสคำเป็น:
คิง = [1,0,0,0,0]
ราชินี = [0,1,0,0,0]
ผู้ชาย = [0,0,1,00]
ผู้หญิง = [0,0,0,1,0]
เด็ก = [0,0,0,0,1]
ประเภทของคำฝัง (Word Vectors)
การฝังคำเป็นเทคนิคหนึ่งที่เวกเตอร์แสดงข้อความ ต่อไปนี้คือประเภทของคำที่ได้รับความนิยมมากขึ้น การฝัง:
- การฝังตามความถี่
- การฝังตามการคาดการณ์
เราจะไม่ลงลึกถึงการฝังตามความถี่และการฝังตามการคาดการณ์ที่นี่ แต่คุณอาจพบว่าคำแนะนำต่อไปนี้มีประโยชน์ในการทำความเข้าใจทั้งสองอย่าง:
ความเข้าใจที่เข้าใจง่ายของการฝังคำและบทนำอย่างรวดเร็วเกี่ยวกับ Bag-of-Words (BOW) และ TF-IDF สำหรับการสร้างคุณสมบัติจากข้อความ
ข้อมูลเบื้องต้นเกี่ยวกับ WORD2Vec
แม้ว่าการฝังตามความถี่จะได้รับความนิยม แต่ก็ยังมีช่องว่างในการทำความเข้าใจบริบทของคำและจำกัดการแสดงคำ
การฝังตามการคาดการณ์ (WORD2Vec) ถูกสร้างขึ้น จดสิทธิบัตร และแนะนำให้รู้จักกับชุมชน NLP ในปี 2013 โดยทีมนักวิจัยที่นำโดย Tomas Mikolov ที่ Google
ตามวิกิพีเดีย อัลกอริธึม word2vec ใช้โมเดลโครงข่ายประสาทเทียมเพื่อเรียนรู้การเชื่อมโยงคำจากคลังข้อความขนาดใหญ่ (ชุดข้อความขนาดใหญ่และมีโครงสร้าง)
เมื่อได้รับการฝึกอบรมแล้ว โมเดลดังกล่าวสามารถตรวจจับคำที่มีความหมายเหมือนกันหรือแนะนำคำเพิ่มเติมสำหรับประโยคบางส่วนได้ ตัวอย่างเช่น ด้วย Word2Vec คุณสามารถสร้างผลลัพธ์ดังกล่าวได้อย่างง่ายดาย: King – man + woman = Queen ซึ่งถือว่าเป็นผลลัพธ์ที่เกือบจะมหัศจรรย์
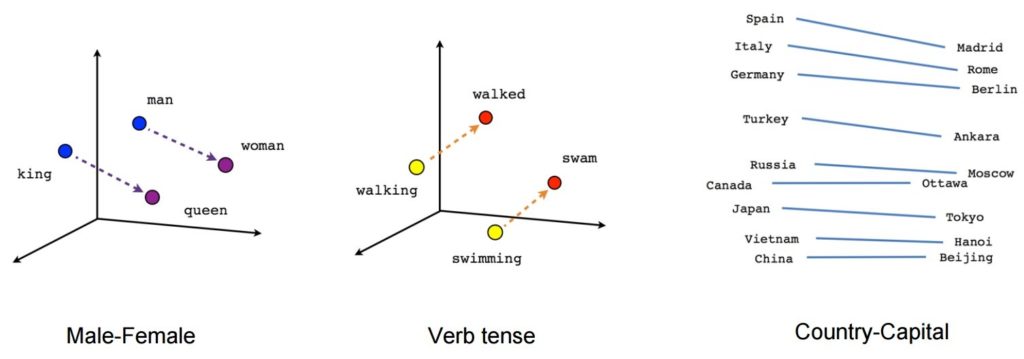 แหล่งที่มาของภาพ: Tensorflow
แหล่งที่มาของภาพ: Tensorflow
- [ราชา] – [ชาย] + [หญิง] ~= [ราชินี] (วิธีคิดอีกอย่างคือ [ราชา] – [ราชินี] กำลังเข้ารหัสเฉพาะส่วนที่เป็นเพศของ [ราชา])
- [เดิน] – [ว่ายน้ำ] + [ว่ายน้ำ] ~= [เดิน] (หรือ [ว่ายน้ำ] – [ว่ายน้ำ] กำลังเข้ารหัสเพียง "อดีตกาล" ของคำกริยา)
- [มาดริด] – [สเปน] + [ฝรั่งเศส] ~= [ปารีส] (หรือ [มาดริด] – [สเปน] ~= [ปารีส] – [ฝรั่งเศส] ซึ่งน่าจะเป็น "เมืองหลวง")
ที่มา: Brainslab Digital
ฉันรู้ว่านี่เป็นเทคนิคเล็กน้อย แต่ Stitch Fix ได้รวบรวมโพสต์ที่ยอดเยี่ยมเกี่ยวกับความสัมพันธ์ทางความหมายและเวกเตอร์คำ
อัลกอริธึม Word2Vec ไม่ใช่อัลกอริธึมเดียว แต่เป็นการรวมกันของสองเทคนิคที่ใช้วิธีการ AI สองสามวิธีในการเชื่อมโยงความเข้าใจของมนุษย์และความเข้าใจของเครื่องจักร เทคนิคนี้มีความจำเป็นในการแก้ปัญหาต่างๆ ของ NLP
สองเทคนิคเหล่านี้คือ:
- – CBOW (ถุงคำต่อเนื่อง) หรือรุ่น CBOW
- – รุ่นข้ามกรัม
ทั้งสองเป็นโครงข่ายประสาทเทียมแบบตื้นที่ให้ความน่าจะเป็นของคำและได้รับการพิสูจน์แล้วว่ามีประโยชน์ในงานต่างๆ เช่น การเปรียบเทียบคำและการเปรียบเทียบคำ
วิธีการทำงานของ word vectors และ word2vecs
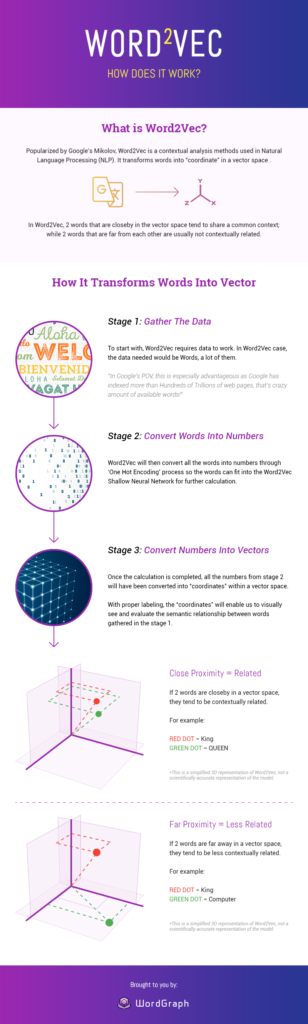
Word Vector เป็นโมเดล AI ที่พัฒนาโดย Google และช่วยให้เราแก้ปัญหา NLP ที่ซับซ้อนได้
“โมเดล Word Vector มีเป้าหมายหลักอย่างหนึ่งที่คุณควรรู้:
เป็นอัลกอริธึมที่ช่วย Google ในการตรวจหาความสัมพันธ์ทางความหมายระหว่างคำต่างๆ”
แต่ละคำถูกเข้ารหัสในเวกเตอร์ (เป็นตัวเลขที่แสดงในหลายมิติ) เพื่อจับคู่เวกเตอร์ของคำที่ปรากฏในบริบทที่คล้ายคลึงกัน ดังนั้นเวกเตอร์หนาแน่นจึงถูกสร้างขึ้นสำหรับข้อความ
แบบจำลองเวกเตอร์เหล่านี้จับคู่วลีที่มีความหมายคล้ายกันกับจุดใกล้เคียงโดยพิจารณาจากความเท่าเทียมกัน ความคล้ายคลึง หรือความเกี่ยวข้องของความคิดและภาษา
[กรณีศึกษา] ขับเคลื่อนการเติบโตในตลาดใหม่ด้วย SEO บนหน้าเว็บ
 อ่านกรณีศึกษา
อ่านกรณีศึกษาWord2Vec- มันทำงานอย่างไร
แหล่งที่มาของภาพ: Seopressor
ข้อดีและข้อเสียของ Word2Vec
เราได้เห็นแล้วว่า Word2vec เป็นเทคนิคที่มีประสิทธิภาพมากในการสร้างความคล้ายคลึงในการกระจาย ฉันได้ระบุข้อดีอื่นๆ บางส่วนไว้ที่นี่:
- ไม่มีปัญหาในการทำความเข้าใจแนวคิดของ Word2vec Word2Vec ไม่ได้ซับซ้อนมากจนคุณไม่รู้ว่าเกิดอะไรขึ้นเบื้องหลัง
- สถาปัตยกรรมของ Word2Vec นั้นทรงพลังและใช้งานง่ายมาก เมื่อเทียบกับเทคนิคอื่นๆ การฝึกจะเร็ว
- การฝึกอบรมเป็นไปโดยอัตโนมัติเกือบทั้งหมดที่นี่ ดังนั้นจึงไม่จำเป็นต้องใช้ข้อมูลที่ติดแท็กโดยมนุษย์อีกต่อไป
- เทคนิคนี้ใช้ได้กับชุดข้อมูลทั้งขนาดเล็กและขนาดใหญ่ เป็นผลให้มันเป็นแบบจำลองที่ง่ายต่อการปรับขนาด
- หากคุณรู้แนวคิด คุณสามารถทำซ้ำทั้งแนวคิดและอัลกอริธึมได้อย่างง่ายดาย
- จับความคล้ายคลึงกันทางความหมายได้เป็นอย่างดี
- แม่นยำและมีประสิทธิภาพในการคำนวณ
- เนื่องจากวิธีการนี้ไม่มีการควบคุมดูแล จึงช่วยประหยัดเวลาได้มากในแง่ของความพยายาม
ความท้าทายของ Word2Vec
แนวคิดของ Word2vec นั้นมีประสิทธิภาพมาก แต่คุณอาจพบว่าบางประเด็นมีความท้าทายเล็กน้อย ต่อไปนี้คือความท้าทายบางส่วนที่พบบ่อยที่สุด
- เมื่อพัฒนาโมเดล word2vec สำหรับชุดข้อมูลของคุณ การดีบักอาจเป็นความท้าทายที่สำคัญ เนื่องจากโมเดล word2vec นั้นพัฒนาได้ง่ายแต่ยากต่อการดีบั๊ก
- ไม่ได้จัดการกับความคลุมเครือ ดังนั้น ในกรณีของคำที่มีหลายความหมาย การฝังจะสะท้อนค่าเฉลี่ยของความหมายเหล่านี้ในปริภูมิเวกเตอร์
- ไม่สามารถจัดการกับคำที่ไม่รู้จักหรือ OOV ได้: ปัญหาที่ใหญ่ที่สุดของ word2vec คือการไม่สามารถจัดการกับคำที่ไม่รู้จักหรือนอกคำศัพท์ (OOV)
Word Vectors: ตัวเปลี่ยนเกมในการเพิ่มประสิทธิภาพกลไกค้นหา?
ผู้เชี่ยวชาญด้าน SEO หลายคนเชื่อว่า Word Vector ส่งผลต่อการจัดอันดับเว็บไซต์ในผลลัพธ์ของเครื่องมือค้นหา
ในช่วงห้าปีที่ผ่านมา Google ได้แนะนำการอัปเดตอัลกอริธึมสองรายการซึ่งเน้นที่คุณภาพเนื้อหาและความครอบคลุมของภาษาอย่างชัดเจน
ลองย้อนกลับไปและพูดคุยเกี่ยวกับการอัปเดต:
นกฮัมมิ่งเบิร์ด
ในปี 2013 Hummingbird ได้ให้เครื่องมือค้นหามีความสามารถในการวิเคราะห์เชิงความหมาย ด้วยการใช้และผสมผสานทฤษฎีความหมายในอัลกอริธึม พวกเขาเปิดเส้นทางใหม่สู่โลกแห่งการค้นหา
Google Hummingbird เป็นการเปลี่ยนแปลงครั้งใหญ่ที่สุดในเครื่องมือค้นหานับตั้งแต่ Caffeine ในปี 2010 โดยได้ชื่อมาจากคำว่า "แม่นยำและรวดเร็ว"
จากข้อมูลของ Search Engine Land ระบุว่า Hummingbird ให้ความสำคัญกับแต่ละคำในข้อความค้นหามากขึ้น เพื่อให้มั่นใจว่าคำค้นหาทั้งหมดได้รับการพิจารณา ไม่ใช่แค่คำบางคำเท่านั้น

เป้าหมายหลักของ Hummingbird คือการให้ผลลัพธ์ที่ดีขึ้นโดยการทำความเข้าใจบริบทของข้อความค้นหาแทนที่จะส่งคืนผลลัพธ์สำหรับคำหลักเฉพาะ
“Google Hummingbird เปิดตัวในเดือนกันยายน 2556”
RankBrain
ในปี 2015 Google ได้ประกาศ RankBrain ซึ่งเป็นกลยุทธ์ที่รวมปัญญาประดิษฐ์ (AI)
RankBrain เป็นอัลกอริธึมที่ช่วยให้ Google แยกคำค้นหาที่ซับซ้อนออกเป็นคำที่ง่ายกว่า RankBrain แปลงคำค้นหาจากภาษา "มนุษย์" เป็นภาษาที่ Google เข้าใจได้ง่าย
Google ยืนยันการใช้ RankBrain เมื่อวันที่ 26 ตุลาคม 2015 ในบทความที่เผยแพร่โดย Bloomberg
BERT
เมื่อวันที่ 21 ตุลาคม 2019 BERT เริ่มเปิดตัวในระบบการค้นหาของ Google
BERT ย่อมาจาก Bidirectional Encoder Representations จาก Transformers ซึ่งเป็นเทคนิคที่ใช้โครงข่ายประสาทเทียมที่ Google ใช้สำหรับการฝึกอบรมล่วงหน้าในการประมวลผลภาษาธรรมชาติ (NLP)
กล่าวโดยย่อ BERT ช่วยให้คอมพิวเตอร์เข้าใจภาษาเหมือนมนุษย์มากขึ้น และเป็นการเปลี่ยนแปลงครั้งใหญ่ที่สุดในการค้นหานับตั้งแต่ Google เปิดตัว RankBrain
ไม่ใช่การแทนที่ RankBrain แต่เป็นการเพิ่มเติมวิธีการทำความเข้าใจเนื้อหาและข้อความค้นหา
Google ใช้ BERT ในระบบการจัดอันดับเป็นส่วนเสริม อัลกอริทึม RankBrain ยังคงมีอยู่สำหรับข้อความค้นหาบางรายการและจะยังคงมีอยู่ต่อไป แต่เมื่อ Google รู้สึกว่า BERT เข้าใจคำถามได้ดีขึ้น พวกเขาก็จะใช้วิธีนั้น
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ BERT โปรดดูโพสต์นี้โดย Barry Schwartz รวมถึงการดำน้ำในเชิงลึกของ Dawn Anderson
จัดอันดับไซต์ของคุณด้วย Word Vectors
ฉันคิดว่าคุณได้สร้างและเผยแพร่เนื้อหาที่ไม่ซ้ำใครแล้ว และแม้หลังจากขัดเกลามันซ้ำแล้วซ้ำเล่า ก็ไม่สามารถปรับปรุงอันดับหรือการเข้าชมของคุณได้
คุณสงสัยหรือไม่ว่าทำไมสิ่งนี้ถึงเกิดขึ้นกับคุณ?
อาจเป็นเพราะคุณไม่ได้ใส่ Word Vector: โมเดล AI ของ Google
- ขั้นตอนแรกคือการระบุ Word Vectors ของการจัดอันดับ SERP 10 อันดับแรกสำหรับช่องของคุณ
- รู้ว่าคู่แข่งของคุณใช้คำหลักใดและสิ่งที่คุณอาจมองข้าม
ด้วยการใช้ Word2Vec ซึ่งใช้ประโยชน์จากเทคนิคการประมวลผลภาษาธรรมชาติขั้นสูงและเฟรมเวิร์กการเรียนรู้ของเครื่อง คุณจะสามารถเห็นทุกอย่างโดยละเอียด
แต่สิ่งเหล่านี้เป็นไปได้ถ้าคุณรู้เทคนิคการเรียนรู้ของเครื่องและ NLP แต่เราสามารถ ใช้เวกเตอร์คำในเนื้อหา โดยใช้เครื่องมือต่อไปนี้:
WordGraph เครื่องมือเวกเตอร์คำแรกของโลก
เครื่องมือปัญญาประดิษฐ์นี้สร้างขึ้นด้วย Neural Networks สำหรับการประมวลผลภาษาธรรมชาติ และฝึกฝนด้วย Machine Learning
โดยใช้ปัญญาประดิษฐ์ WordGraph วิเคราะห์เนื้อหาของคุณและช่วยให้คุณปรับปรุงความเกี่ยวข้องกับเว็บไซต์อันดับ 10 อันดับแรก
โดยจะแนะนำคีย์เวิร์ดที่เกี่ยวข้องกับคีย์เวิร์ดหลักทางคณิตศาสตร์และตามบริบท
โดยส่วนตัวแล้ว ฉันจับคู่กับ BIQ ซึ่งเป็นเครื่องมือ SEO ที่ทรงพลังซึ่งทำงานได้ดีกับ WordGraph
เพิ่มเนื้อหาของคุณลงในเครื่องมือข่าวกรองเนื้อหาที่สร้างขึ้นใน Biq จะแสดงรายการ เคล็ดลับ SEO ในหน้า ทั้งหมดที่คุณสามารถเพิ่มได้หากต้องการให้อยู่ในตำแหน่งบนสุด
คุณสามารถดูว่าความฉลาดของเนื้อหาทำงานอย่างไรในตัวอย่างนี้ รายการจะช่วยให้คุณเชี่ยวชาญ SEO ในหน้าและจัดอันดับโดยใช้วิธีการดำเนินการได้!
วิธีเพิ่มพลังให้ Word Vectors: การใช้ Markup ข้อมูลที่มีโครงสร้าง
มาร์กอัปสคีมาหรือข้อมูลที่มีโครงสร้างเป็นโค้ดประเภทหนึ่ง (เขียนด้วย JSON, Java-Script Object Notation) ที่สร้างขึ้นโดยใช้คำศัพท์ schema.org ที่ช่วยให้เครื่องมือค้นหารวบรวมข้อมูล จัดระเบียบ และแสดงเนื้อหาของคุณ
วิธีเพิ่มข้อมูลที่มีโครงสร้าง
ข้อมูลที่มีโครงสร้างสามารถเพิ่มลงในเว็บไซต์ของคุณได้อย่างง่ายดายโดยการเพิ่มสคริปต์อินไลน์ใน html . ของคุณ
ตัวอย่างด้านล่างแสดงวิธีกำหนดข้อมูลที่มีโครงสร้างขององค์กรในรูปแบบที่ง่ายที่สุด
ในการสร้าง Schema Markup ฉันใช้ Schema Markup Generator (JSON-LD)
นี่คือตัวอย่างสดของมาร์กอัปสคีมาสำหรับ https://www.telecloudvoip.com/ ตรวจสอบซอร์สโค้ดและค้นหา JSON
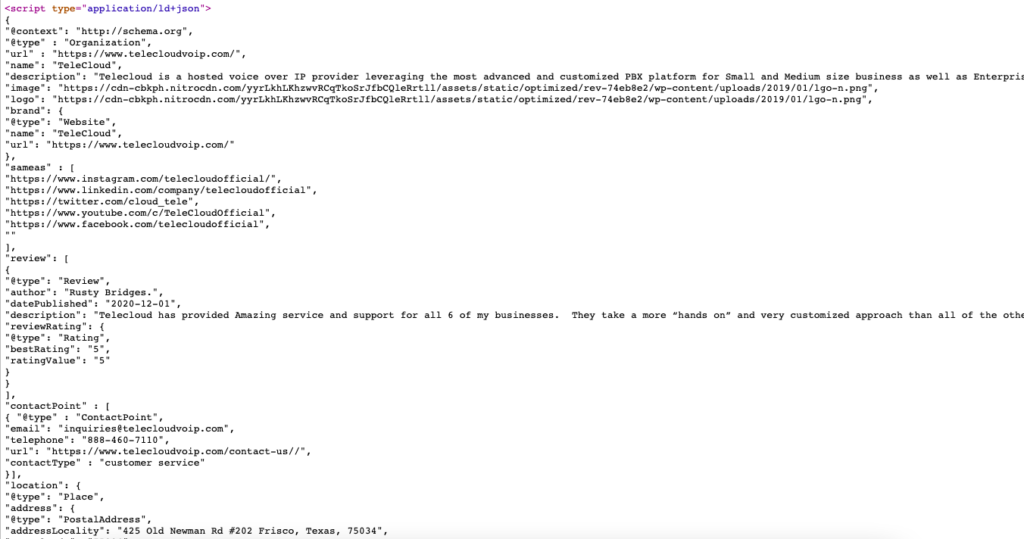
หลังจากสร้างโค้ดมาร์กอัปสคีมาแล้ว ให้ใช้การทดสอบผลการค้นหาที่เป็นสื่อสมบูรณ์ของ Google เพื่อดูว่าหน้ารองรับผลการค้นหาที่เป็นสื่อสมบูรณ์หรือไม่
คุณยังสามารถใช้เครื่องมือตรวจสอบไซต์ Semrush เพื่อสำรวจรายการข้อมูลที่มีโครงสร้างสำหรับ URL แต่ละรายการ และระบุว่าหน้าใดมีสิทธิ์แสดงในผลการค้นหาที่เป็นสื่อสมบูรณ์ 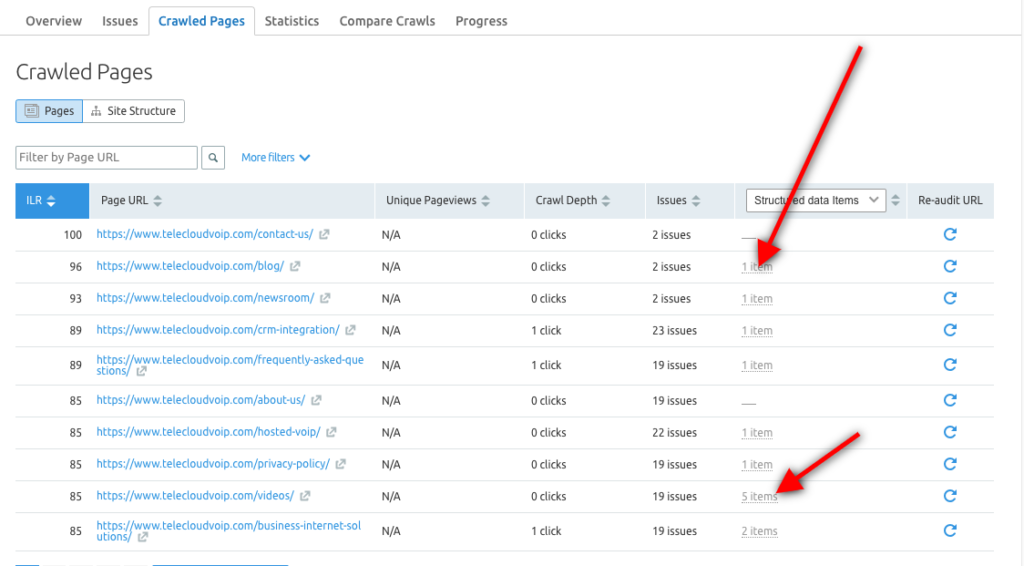
เหตุใดข้อมูลที่มีโครงสร้างจึงมีความสำคัญสำหรับ SEO
ข้อมูลที่มีโครงสร้างมีความสำคัญสำหรับ SEO เพราะจะช่วยให้ Google เข้าใจว่าเว็บไซต์และหน้าของคุณเกี่ยวกับอะไร ส่งผลให้การจัดอันดับเนื้อหาของคุณแม่นยำยิ่งขึ้น
ข้อมูลที่มีโครงสร้างช่วยปรับปรุงทั้งประสบการณ์ของบอทการค้นหาและประสบการณ์ของผู้ใช้ด้วยการปรับปรุง SERP (หน้าผลลัพธ์ของเครื่องมือค้นหา) ด้วยข้อมูลและความแม่นยำที่มากขึ้น
หากต้องการดูผลกระทบในการค้นหาของ Google ให้ไปที่ Search Console และในส่วนประสิทธิภาพ > ผลการค้นหา > ลักษณะที่ปรากฏของการค้นหา คุณสามารถดูรายละเอียดประเภทผลการค้นหาที่เป็นสื่อสมบูรณ์ทั้งหมด เช่น "วิดีโอ" และ "คำถามที่พบบ่อย" และดูการแสดงผลและจำนวนคลิกที่เกิดขึ้นเองได้ สำหรับเนื้อหาของคุณ
ข้อดีบางประการของข้อมูลที่มีโครงสร้างมีดังนี้
- ข้อมูลที่มีโครงสร้างรองรับการค้นหาเชิงความหมาย
- นอกจากนี้ยังรองรับ E‑AT ของคุณ (ความเชี่ยวชาญ ความน่าเชื่อถือ และความไว้วางใจ)
- การมีข้อมูลที่มีโครงสร้างสามารถเพิ่มอัตราการแปลงได้ เนื่องจากผู้คนจะเห็นรายชื่อของคุณมากขึ้น ซึ่งจะเพิ่มโอกาสที่พวกเขาจะซื้อจากคุณ
- การใช้ข้อมูลที่มีโครงสร้างทำให้เสิร์ชเอ็นจิ้นสามารถเข้าใจแบรนด์ เว็บไซต์ และเนื้อหาของคุณได้ดีขึ้น
- เครื่องมือค้นหาจะแยกความแตกต่างระหว่างหน้าติดต่อ คำอธิบายผลิตภัณฑ์ หน้าสูตรอาหาร หน้ากิจกรรม และบทวิจารณ์ของลูกค้าได้ง่ายขึ้น
- ด้วยความช่วยเหลือของข้อมูลที่มีโครงสร้าง Google จะสร้างกราฟความรู้และแผงความรู้ที่ดีขึ้นและแม่นยำยิ่งขึ้นเกี่ยวกับแบรนด์ของคุณ
- การปรับปรุงเหล่านี้สามารถส่งผลให้มีการแสดงผลที่เกิดขึ้นเองและการคลิกที่เกิดขึ้นเองมากขึ้น
ปัจจุบัน Google ใช้ข้อมูลที่มีโครงสร้างเพื่อปรับปรุงผลการค้นหา เมื่อมีคนค้นหาหน้าเว็บของคุณโดยใช้คำหลัก ข้อมูลที่มีโครงสร้างจะช่วยให้คุณได้ผลลัพธ์ที่ดีขึ้น เครื่องมือค้นหาจะสังเกตเห็นเนื้อหาของคุณมากขึ้นหากเราเพิ่มมาร์กอัปสคีมา
คุณสามารถใช้มาร์กอัปสคีมากับรายการต่างๆ ได้ ด้านล่างนี้เป็นพื้นที่บางส่วนที่สามารถใช้สคีมาได้:
- บทความ
- บล็อกโพสต์
- บทความข่าว
- กิจกรรม
- สินค้า
- วิดีโอ
- บริการ
- ความคิดเห็น
- คะแนนรวม
- ร้านอาหาร
- ธุรกิจในท้องถิ่น
นี่คือรายการทั้งหมดของรายการที่คุณสามารถมาร์กอัปด้วยสคีมา
ข้อมูลที่มีโครงสร้างที่มีการฝังเอนทิตี
คำว่า "เอนทิตี" หมายถึงการเป็นตัวแทนของวัตถุ แนวคิด หรือหัวเรื่องใดๆ เอนทิตีอาจเป็นบุคคล ภาพยนตร์ หนังสือ ความคิด สถานที่ บริษัท หรือเหตุการณ์
แม้ว่าเครื่องจักรจะไม่เข้าใจคำศัพท์จริงๆ ด้วยการฝังเอนทิตี พวกเขาสามารถเข้าใจความสัมพันธ์ระหว่างราชา – ราชินี = สามี – ภรรยาได้อย่างง่ายดาย
การฝังเอนทิตีทำงานได้ดีกว่าการเข้ารหัสแบบใช้ครั้งเดียว
Google ใช้อัลกอริธึมของคำเพื่อค้นหาความสัมพันธ์ทางความหมายระหว่างคำ และเมื่อรวมกับข้อมูลที่มีโครงสร้าง เราจะลงเอยด้วยเว็บที่มีการปรับปรุงความหมาย
การใช้ข้อมูลที่มีโครงสร้างทำให้คุณมีส่วนร่วมในเว็บที่มีความหมายมากขึ้น นี่คือเว็บที่ได้รับการปรับปรุงซึ่งเราอธิบายข้อมูลในรูปแบบที่เครื่องอ่านได้
ข้อมูลเชิงความหมายบนเว็บไซต์ของคุณช่วยให้เครื่องมือค้นหาจับคู่เนื้อหาของคุณกับผู้ชมที่เหมาะสม การใช้ NLP, Machine Learning และ Deep Learning ช่วยลดช่องว่างระหว่างสิ่งที่ผู้คนค้นหาและชื่อที่มีให้ใช้งาน
ความคิดสุดท้าย
เมื่อคุณเข้าใจแนวคิดของเวกเตอร์คำและความสำคัญของคำแล้ว คุณสามารถทำให้กลยุทธ์การค้นหาทั่วไปมีประสิทธิภาพและประสิทธิผลมากขึ้นโดยใช้เวกเตอร์คำ การฝังเอนทิตี และข้อมูลเชิงความหมายที่มีโครงสร้าง
เพื่อให้ได้อันดับ การเข้าชม และการแปลงสูงสุด คุณต้องใช้เวกเตอร์คำ การฝังเอนทิตี และข้อมูลความหมายที่มีโครงสร้างเพื่อแสดงให้ Google เห็นว่าเนื้อหาบนหน้าเว็บของคุณถูกต้อง แม่นยำ และน่าเชื่อถือ