
Data Scraping คืออะไรและคุณจะใช้งานได้อย่างไร?
เผยแพร่แล้ว: 2017-09-13การขูดข้อมูลคืออะไร?
การขูดข้อมูลหรือที่เรียกว่าการขูดเว็บเป็นกระบวนการนำเข้าข้อมูลจากเว็บไซต์ลงในสเปรดชีตหรือไฟล์ในเครื่องที่บันทึกไว้ในคอมพิวเตอร์ของคุณ เป็นวิธีที่มีประสิทธิภาพมากที่สุดวิธีหนึ่งในการรับข้อมูลจากเว็บ และในบางกรณีเพื่อนำข้อมูลนั้นไปยังเว็บไซต์อื่น การขูดข้อมูลที่นิยมใช้ ได้แก่:
- การวิจัยเนื้อหาเว็บ/ข่าวกรองธุรกิจ
- ราคาสำหรับเว็บไซต์จองการเดินทาง/เว็บไซต์เปรียบเทียบราคา
- การค้นหาโอกาสในการขาย/ดำเนินการวิจัยตลาดโดยรวบรวมข้อมูลจากแหล่งข้อมูลสาธารณะ (เช่น Yell และ Twitter)
- การส่งข้อมูลผลิตภัณฑ์จากเว็บไซต์อีคอมเมิร์ซไปยังผู้ขายออนไลน์รายอื่น (เช่น Google Shopping)
และรายการนั้นเป็นเพียงการขีดข่วนพื้นผิว การขูดข้อมูลมีแอปพลิเคชันจำนวนมาก ซึ่งมีประโยชน์ในทุกกรณีที่จำเป็นต้องย้ายข้อมูลจากที่หนึ่งไปยังอีกที่หนึ่ง
พื้นฐานของการขูดข้อมูลนั้นค่อนข้างง่ายที่จะเชี่ยวชาญ มาดูวิธีตั้งค่าการดำเนินการขูดข้อมูลอย่างง่ายโดยใช้ Excel กัน
Data Scraping พร้อมการสืบค้นเว็บแบบไดนามิกใน Microsoft Excel
การตั้งค่าคิวรีเว็บแบบไดนามิกใน Microsoft Excel เป็นวิธีที่ง่ายและหลากหลายในการดึงข้อมูล ซึ่งช่วยให้คุณตั้งค่าฟีดข้อมูลจากเว็บไซต์ภายนอก (หรือหลายเว็บไซต์) ลงในสเปรดชีตได้
ดูวิดีโอแนะนำการใช้งานที่ยอดเยี่ยมนี้เพื่อเรียนรู้วิธีนำเข้าข้อมูลจากเว็บไปยัง Excel หรือหากต้องการ ให้ใช้คำแนะนำที่เป็นลายลักษณ์อักษรด้านล่าง:
- เปิดสมุดงานใหม่ใน Excel
- คลิกเซลล์ที่คุณต้องการนำเข้าข้อมูลลงใน
- คลิกแท็บ 'ข้อมูล'
- คลิก 'รับข้อมูลภายนอก'
- คลิกสัญลักษณ์ 'จากเว็บ'
- สังเกตลูกศรสีเหลืองเล็กๆ ที่ปรากฏที่ด้านบนซ้ายของหน้าเว็บและข้างเนื้อหาบางอย่าง
- วาง URL ของหน้าเว็บที่คุณต้องการนำเข้าข้อมูลจากแถบที่อยู่ (เราแนะนำให้เลือกไซต์ที่ข้อมูลแสดงในตาราง)
- คลิก 'ไป'
- คลิกลูกศรสีเหลืองถัดจากข้อมูลที่คุณต้องการนำเข้า
- คลิก 'นำเข้า'
- กล่องโต้ตอบ 'นำเข้าข้อมูล' จะปรากฏขึ้น
- คลิก 'ตกลง' (หรือเปลี่ยนการเลือกเซลล์ ถ้าคุณต้องการ)
หากคุณทำตามขั้นตอนเหล่านี้แล้ว คุณจะสามารถดูข้อมูลจากเว็บไซต์ที่กำหนดไว้ในสเปรดชีตของคุณได้
สิ่งที่ยอดเยี่ยมเกี่ยวกับการสืบค้นข้อมูลในเว็บแบบไดนามิกก็คือ พวกมันไม่ได้นำเข้าข้อมูลลงในสเปรดชีตของคุณแบบครั้งเดียวเท่านั้น แต่ยังป้อนเข้า หมายความว่าสเปรดชีตจะได้รับการอัปเดตเป็นประจำด้วยข้อมูลเวอร์ชันล่าสุดตามที่ปรากฏใน เว็บไซต์ต้นทาง นั่นเป็นเหตุผลที่เราเรียกมันว่าไดนามิก
ในการกำหนดค่าว่าการสืบค้นเว็บแบบไดนามิกของคุณอัปเดตข้อมูลที่นำเข้าเป็นประจำเพียงใด ให้ไปที่ 'ข้อมูล' จากนั้นไปที่ 'คุณสมบัติ' จากนั้นเลือกความถี่ ("รีเฟรชทุกๆ X นาที")
ขูดข้อมูลอัตโนมัติด้วยเครื่องมือ
ทำความเข้าใจกับการใช้คิวรีเว็บแบบไดนามิกใน Excel เป็นวิธีที่มีประโยชน์ในการทำความเข้าใจเกี่ยวกับการดึงข้อมูล อย่างไรก็ตาม หากคุณตั้งใจจะใช้ข้อมูลในการดึงข้อมูลเป็นประจำ คุณอาจพบว่าเครื่องมือดึงข้อมูลเฉพาะมีประสิทธิภาพมากกว่า
นี่คือความคิดของเราเกี่ยวกับเครื่องมือขูดข้อมูลที่เป็นที่นิยมที่สุดบางส่วนในตลาด:
Data Scraper (ปลั๊กอิน Chrome)
Data Scraper เสียบเข้ากับส่วนขยายเบราว์เซอร์ Chrome ของคุณโดยตรง ทำให้คุณสามารถเลือก “สูตร” สำหรับการขูดข้อมูลแบบสำเร็จรูปเพื่อดึงข้อมูลจากหน้าเว็บใดก็ตามที่โหลดในเบราว์เซอร์ของคุณ
เครื่องมือนี้ทำงานได้ดีกับแหล่งข้อมูลยอดนิยมอย่างเช่น Twitter และ Wikipedia เนื่องจากปลั๊กอินนี้มีตัวเลือกสูตรอาหารที่หลากหลายสำหรับไซต์ดังกล่าว
เราลองใช้ Data Scraper โดยขุดแฮชแท็ก Twitter “#jourrequest” เพื่อโอกาสในการประชาสัมพันธ์โดยใช้หนึ่งในสูตรสาธารณะของเครื่องมือ นี่คือรสชาติของข้อมูลที่เราได้รับกลับมา:
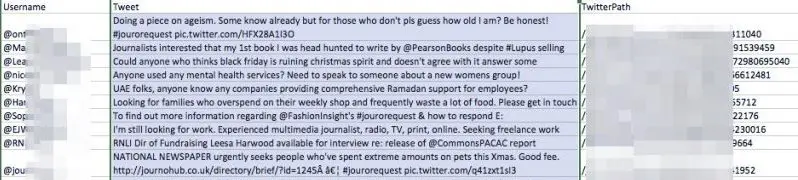
อย่างที่คุณเห็น เครื่องมือได้จัดเตรียมตารางที่มีชื่อผู้ใช้ของทุกบัญชีที่เพิ่งโพสต์บนแฮชแท็ก รวมทั้งทวีตและ URL ของบัญชีนั้น
การมีข้อมูลในรูปแบบนี้จะเป็นประโยชน์ต่อตัวแทนประชาสัมพันธ์มากกว่าแค่การดูข้อมูลในมุมมองเบราว์เซอร์ของ Twitter ด้วยเหตุผลหลายประการ:
- สามารถใช้เพื่อช่วยสร้างฐานข้อมูลของสื่อติดต่อ
- คุณสามารถอ้างอิงกลับมาที่รายการนี้และค้นหาสิ่งที่คุณต้องการได้อย่างง่ายดาย ในขณะที่ Twitter อัปเดตอย่างต่อเนื่อง
- รายการสามารถจัดเรียงและแก้ไขได้
- ช่วยให้คุณเป็นเจ้าของข้อมูล – ซึ่งสามารถออฟไลน์หรือเปลี่ยนแปลงได้ทุกเมื่อ
เรารู้สึกประทับใจกับ Data Scraper แม้ว่าบางครั้งสูตรสาธารณะของมันจะค่อนข้างหยาบเล็กน้อยก็ตาม ลองติดตั้งเวอร์ชันฟรีบน Chrome และลองแยกข้อมูลดู อย่าลืมชมภาพยนตร์แนะนำที่พวกเขาให้ไว้เพื่อให้ทราบถึงวิธีการทำงานของเครื่องมือและวิธีง่ายๆ ในการดึงข้อมูลที่คุณต้องการ
WebHarvy
WebHarvy เป็นเครื่องขูดข้อมูลแบบชี้แล้วคลิกพร้อมรุ่นทดลองใช้ฟรี จุดขายที่ใหญ่ที่สุดคือความยืดหยุ่น คุณสามารถใช้เว็บเบราว์เซอร์ในตัวของเครื่องมือเพื่อนำทางไปยังข้อมูลที่คุณต้องการนำเข้า จากนั้นจึงสร้างข้อกำหนดการขุดของคุณเองเพื่อดึงสิ่งที่คุณต้องการจากเว็บไซต์ต้นทาง
import.io
Import.io เป็นชุดเครื่องมือขุดข้อมูลที่มีคุณลักษณะมากมายซึ่งทำงานหนักมากสำหรับคุณ มีคุณสมบัติที่น่าสนใจ ได้แก่ "มีอะไรเปลี่ยนแปลงบ้าง" รายงานที่สามารถแจ้งให้คุณทราบถึงการอัปเดตของเว็บไซต์ที่ระบุ – เหมาะสำหรับการวิเคราะห์คู่แข่งในเชิงลึก
นักการตลาดใช้ data scraping อย่างไร?
ดังที่คุณจะได้รวบรวมมา ณ จุดนี้ การดึงข้อมูลจะมีประโยชน์ในทุกที่ที่มีการใช้ข้อมูล ต่อไปนี้คือตัวอย่างที่สำคัญบางประการเกี่ยวกับวิธีการใช้เทคโนโลยีนี้โดยนักการตลาด:
การรวบรวมข้อมูลที่แตกต่างกัน
Marcin Rosinski ซีอีโอของ FeedOptimise กล่าวว่าข้อดีอย่างหนึ่งของการขูดข้อมูลคือสามารถช่วยให้คุณรวบรวมข้อมูลต่างๆ ไว้ในที่เดียวได้ "การรวบรวมข้อมูลช่วยให้เราสามารถนำข้อมูลที่ไม่มีโครงสร้างและกระจัดกระจายจากหลายแหล่งมารวมกันในที่เดียวและทำให้เป็นโครงสร้างได้" Marcin กล่าว “หากคุณมีเว็บไซต์หลายแห่งที่ควบคุมโดยหน่วยงานที่แตกต่างกัน คุณสามารถรวมเว็บไซต์ทั้งหมดไว้ในฟีดเดียวได้

“สเปกตรัมของกรณีการใช้งานนี้ไม่มีที่สิ้นสุด”
FeedOptimise นำเสนอบริการดึงข้อมูลและฟีดข้อมูลที่หลากหลาย ซึ่งคุณสามารถหาข้อมูลเพิ่มเติมได้จากเว็บไซต์ของพวกเขา
เร่งวิจัย
การใช้งานที่ง่ายที่สุดสำหรับการดึงข้อมูลคือการดึงข้อมูลจากแหล่งเดียว หากมีหน้าเว็บที่มีข้อมูลจำนวนมากที่อาจเป็นประโยชน์สำหรับคุณ วิธีที่ง่ายที่สุดในการรับข้อมูลนั้นไปยังคอมพิวเตอร์ในรูปแบบที่เป็นระเบียบอาจเป็นการดึงข้อมูล
ลองค้นหารายชื่อผู้ติดต่อที่มีประโยชน์บน Twitter และนำเข้าข้อมูลโดยใช้การดึงข้อมูล วิธีนี้จะทำให้คุณได้ลิ้มรสว่ากระบวนการนี้เหมาะกับงานประจำวันของคุณอย่างไร
การส่งออกฟีด XML ไปยังไซต์บุคคลที่สาม
การป้อนข้อมูลผลิตภัณฑ์จากไซต์ของคุณไปยัง Google Shopping และผู้ขายบุคคลที่สามรายอื่นๆ เป็นแอปพลิเคชันหลักในการดึงข้อมูลสำหรับอีคอมเมิร์ซ ช่วยให้คุณสามารถทำให้กระบวนการที่อาจลำบากในการอัปเดตรายละเอียดผลิตภัณฑ์ของคุณเป็นไปโดยอัตโนมัติ ซึ่งเป็นสิ่งสำคัญหากสต็อกของคุณเปลี่ยนแปลงบ่อย
“การขูดข้อมูลสามารถส่งออกฟีด XML ของคุณสำหรับ Google Shopping” Ciaran Rogers ผู้อำนวยการฝ่ายการตลาดของ Target Internet กล่าว “ ฉันได้ทำงานร่วมกับผู้ค้าปลีกออนไลน์จำนวนหนึ่งซึ่งเพิ่ม SKU ใหม่อย่างต่อเนื่องในไซต์ของตนเมื่อมีสินค้าเข้าในสต็อก หากโซลูชันอีคอมเมิร์ซของคุณไม่แสดงผลฟีด XML ที่เหมาะสม ซึ่งคุณสามารถเชื่อมต่อกับ Google Merchant Center ได้ เพื่อให้คุณโฆษณาผลิตภัณฑ์ที่ดีที่สุดที่อาจเป็นปัญหาได้ บ่อยครั้งที่ผลิตภัณฑ์ล่าสุดของคุณอาจเป็นสินค้าขายดี คุณจึงต้องการโฆษณาทันทีที่เผยแพร่ ฉันใช้การดึงข้อมูลเพื่อสร้างรายการล่าสุดเพื่อป้อนลงใน Google Merchant Center เป็นวิธีแก้ปัญหาที่ยอดเยี่ยม และจริงๆ แล้ว มีข้อมูลมากมายที่คุณสามารถทำได้เมื่อคุณมี คุณสามารถใช้ฟีดเพื่อติดแท็กผลิตภัณฑ์ที่แปลงได้ดีที่สุดในแต่ละวัน เพื่อให้คุณสามารถแบ่งปันข้อมูลนั้นกับ Google Adwords และทำให้แน่ใจว่าคุณเสนอราคาที่แข่งขันได้สำหรับผลิตภัณฑ์เหล่านั้น เมื่อคุณตั้งค่าทั้งหมดแล้ว จะเป็นแบบอัตโนมัติทั้งหมด ความยืดหยุ่นของฟีดที่ดีที่คุณควบคุมได้ด้วยวิธีนี้นั้นยอดเยี่ยม และสามารถนำไปสู่การปรับปรุงที่ชัดเจนในแคมเปญที่ลูกค้าชื่นชอบ”
เป็นไปได้ที่จะตั้งค่าฟีดข้อมูลอย่างง่ายใน Google Merchant Center ด้วยตัวคุณเอง นี่คือวิธีการ:
วิธีตั้งค่าฟีดข้อมูลไปยัง Google Merchant Center
ใช้เทคนิคหรือเครื่องมืออย่างใดอย่างหนึ่งที่อธิบายไว้ก่อนหน้านี้ สร้างไฟล์ที่ใช้คิวรีเว็บไซต์แบบไดนามิกเพื่อนำเข้ารายละเอียดของผลิตภัณฑ์ที่แสดงอยู่บนไซต์ของคุณ ไฟล์นี้ควรอัปเดตโดยอัตโนมัติเป็นระยะ
ควรกำหนดรายละเอียดตามที่ระบุไว้ที่นี่
- อัปโหลดไฟล์นี้ไปยัง URL ที่ป้องกันด้วยรหัสผ่าน
- ไปที่ Google Merchant Center และเข้าสู่ระบบ (ตรวจสอบให้แน่ใจว่าบัญชี Merchant Center ของคุณได้รับการตั้งค่าอย่างถูกต้องก่อน)
- ไปที่ผลิตภัณฑ์
- คลิกปุ่มบวก
- ป้อนประเทศเป้าหมายของคุณและสร้างชื่อฟีด
- เลือกตัวเลือก 'การดึงข้อมูลตามกำหนดเวลา'
- เพิ่ม URL ของไฟล์ข้อมูลผลิตภัณฑ์ของคุณ พร้อมด้วยชื่อผู้ใช้และรหัสผ่านที่จำเป็นสำหรับการเข้าถึง
- เลือกความถี่ในการดึงข้อมูลที่ตรงกับกำหนดการอัปโหลดผลิตภัณฑ์ของคุณมากที่สุด
- คลิกบันทึก
- ข้อมูลผลิตภัณฑ์ของคุณควรมีอยู่ใน Google Merchant Center แล้ว เพียงให้แน่ใจว่าคุณคลิกที่แท็บ 'การวินิจฉัย' เพื่อตรวจสอบสถานะและให้แน่ใจว่าทุกอย่างทำงานได้อย่างราบรื่น
ด้านมืดของการขูดข้อมูล
การขูดข้อมูลมีประโยชน์หลายอย่าง แต่ก็มีคนกลุ่มน้อยที่ละเมิดด้วยเช่นกัน
การใช้ข้อมูลในทางที่ผิดที่แพร่หลายมากที่สุดคือการเก็บเกี่ยวอีเมล ซึ่งเป็นการดึงข้อมูลจากเว็บไซต์ โซเชียลมีเดีย และไดเร็กทอรีเพื่อเปิดเผยที่อยู่อีเมลของผู้คน ซึ่งจะขายให้กับนักส่งสแปมหรือนักต้มตุ๋น ในเขตอำนาจศาลบางแห่ง การใช้วิธีการอัตโนมัติ เช่น การดึงข้อมูลเพื่อรวบรวมที่อยู่อีเมลที่มีเจตนาทางการค้าถือเป็นสิ่งผิดกฎหมาย และเกือบจะถือว่าเป็นแนวทางปฏิบัติทางการตลาดที่ไม่ดี
ผู้ใช้เว็บจำนวนมากใช้เทคนิคต่างๆ เพื่อช่วยลดความเสี่ยงที่ผู้รวบรวมอีเมลจะได้รับที่อยู่อีเมลของตน ซึ่งรวมถึง:
- การแก้ไขที่อยู่: เปลี่ยนรูปแบบที่อยู่อีเมลของคุณเมื่อโพสต์แบบสาธารณะ เช่น พิมพ์ 'patrick[at]gmail.com' แทน '[email protected]' นี่เป็นวิธีการที่ง่ายแต่ไม่น่าเชื่อถือเล็กน้อยในการปกป้องที่อยู่อีเมลของคุณบนโซเชียลมีเดีย ผู้เก็บเกี่ยวบางรายจะค้นหาชุดค่าผสมที่สับสนอลหม่านต่างๆ รวมทั้งอีเมลในรูปแบบปกติ ดังนั้นจึงไม่ได้ปิดสนิททั้งหมด
- แบบฟอร์มการติดต่อ: ใช้แบบฟอร์มติดต่อแทนการโพสต์ที่อยู่อีเมลบนเว็บไซต์ของคุณ
- รูปภาพ: หากที่อยู่อีเมลของคุณถูกนำเสนอในรูปแบบรูปภาพบนเว็บไซต์ของคุณ ที่อยู่อีเมลนั้นจะอยู่นอกเหนือการเข้าถึงทางเทคโนโลยีของคนส่วนใหญ่ที่เกี่ยวข้องกับการเก็บเกี่ยวอีเมล
อนาคตของการขูดข้อมูล
ไม่ว่าคุณจะตั้งใจจะใช้การดึงข้อมูลในงานของคุณหรือไม่ก็ตาม ขอแนะนำให้ศึกษาเกี่ยวกับเรื่องนี้ด้วยตนเอง เนื่องจากมีแนวโน้มว่าจะมีความสำคัญมากขึ้นในอีกไม่กี่ปีข้างหน้า
ขณะนี้มีการขูดข้อมูล AI ในตลาดที่สามารถใช้การเรียนรู้ของเครื่องเพื่อให้จดจำอินพุตได้ดีขึ้นซึ่งมีเพียงมนุษย์เท่านั้นที่สามารถตีความได้เช่นภาพ
การปรับปรุงครั้งใหญ่ในการดึงข้อมูลออกจากรูปภาพและวิดีโอจะส่งผลอย่างมากต่อนักการตลาดดิจิทัล เมื่อการขูดรูปภาพมีความลึกมากขึ้น เราจะสามารถรู้มากขึ้นเกี่ยวกับรูปภาพออนไลน์ก่อนที่เราจะได้พบเห็นด้วยตนเอง และสิ่งนี้ เช่นเดียวกับการขูดข้อมูลแบบข้อความ จะช่วยให้เราทำสิ่งต่างๆ ได้ดีขึ้นมากมาย
แล้วมีเครื่องขูดข้อมูลที่ใหญ่ที่สุด - Google ประสบการณ์การค้นหาเว็บทั้งหมดจะเปลี่ยนไปเมื่อ Google สามารถอนุมานได้อย่างแม่นยำจากรูปภาพจากหน้าสำเนา และเพิ่มเป็นสองเท่าจากมุมมองด้านการตลาดดิจิทัล
หากคุณสงสัยว่าสิ่งนี้จะเกิดขึ้นในอนาคตอันใกล้นี้หรือไม่ ให้ลองใช้ API การตีความรูปภาพของ Google, Cloud Vision และแจ้งให้เราทราบว่าคุณคิดอย่างไร สมัครสมาชิกฟรีตอนนี้ - ไม่ต้องใช้บัตรเครดิต
สมาชิกฟรี 