
[Webinar Digest] SEO ใน Orbit: มุมมองใหม่เกี่ยวกับเนื้อหาที่ซ้ำกัน
เผยแพร่แล้ว: 2019-11-20การสัมมนาผ่านเว็บ มุมมองใหม่เกี่ยวกับเนื้อหาที่ซ้ำกันเป็นตอนสุดท้ายของ SEO ในซีรี่ส์ Orbit และออกอากาศในวันที่ 24 มิถุนายน 2019 ในตอนนี้ เข้าร่วม OnCrawl Ambassador Omi Sido และ Alexis Sanders ขณะที่พวกเขาสำรวจคำถามเกี่ยวกับเนื้อหาที่ซ้ำกัน พวกเขาจัดการกับคำถามเช่น: ปัจจัยการจัดอันดับและเทคโนโลยีการค้นหาที่เปลี่ยนแปลงไปส่งผลต่อวิธีที่เราจัดการกับเนื้อหาที่ซ้ำกันอย่างไร และ: อนาคตจะเป็นอย่างไรสำหรับเนื้อหาที่คล้ายกันบนเว็บ
SEO ใน Orbit คือชุดการสัมมนาผ่านเว็บชุดแรกที่ส่ง SEO สู่อวกาศ ตลอดทั้งซีรีส์ เราได้พูดคุยถึงปัจจุบันและอนาคตของเทคนิค SEO กับผู้เชี่ยวชาญ SEO ที่เก่งที่สุดบางคน และส่งเคล็ดลับยอดนิยมของพวกเขาไปยังพื้นที่ในวันที่ 27 มิถุนายน 2019
ดูย้อนหลังได้ที่นี่:
นำเสนอ อเล็กซิส แซนเดอร์ส
Alexis Sanders ทำงานเป็นผู้จัดการบัญชีด้านเทคนิค SEO ที่ Merkle ทีมเทคนิค SEO รับรองความถูกต้อง ความเป็นไปได้ และความสามารถในการปรับขนาดของคำแนะนำทางเทคนิคของเอเจนซีในแนวดิ่งทั้งหมด เธอเป็นผู้ร่วมเขียนบล็อก Moz และผู้สร้างความท้าทาย TechnicalSEO.expert และ SEO ในพอดคาสต์ Lab
ตอนนี้เป็นเจ้าภาพโดย Omi Sido Omi เป็นนักพูดระดับนานาชาติที่ช่ำชองและเป็นที่รู้จักในอุตสาหกรรมนี้ด้วยอารมณ์ขันและความสามารถในการนำเสนอข้อมูลเชิงลึกที่นำไปปฏิบัติได้จริงซึ่งผู้ฟังสามารถเริ่มใช้งานได้ทันที ตั้งแต่การให้คำปรึกษาด้าน SEO กับบริษัทโทรคมนาคมและการเดินทางที่ใหญ่ที่สุดในโลก ไปจนถึงการจัดการ SEO ภายในองค์กรที่ HostelWorld และ Daily Mail Omi ชอบเจาะลึกข้อมูลที่ซับซ้อนและค้นหาจุดสว่าง ปัจจุบัน Omi เป็น SEO ด้านเทคนิคอาวุโสที่ Canon Europe และ OnCrawl Ambassador
เนื้อหาที่ซ้ำกันคืออะไร?
Omi ให้คำจำกัดความของเนื้อหาที่ซ้ำกันดังต่อไปนี้:
ทำซ้ำเนื้อหาที่คล้ายหรือใกล้เคียงกับเนื้อหาที่อยู่ใน URL อื่นในเว็บไซต์เดียวกัน (หรือต่างกัน)
มายาคติเรื่องบทลงโทษของเนื้อหาที่ซ้ำกัน
ไม่มีบทลงโทษเนื้อหาที่ซ้ำกัน
นี่เป็นปัญหาด้านประสิทธิภาพ เราไม่ต้องการให้บอทดู URL เฉพาะสอง URL และคิดว่าเป็นเนื้อหาที่แตกต่างกันสองรายการที่สามารถจัดอันดับติดกันได้
Alexis เปรียบเทียบความเข้าใจของบอทเกี่ยวกับเว็บไซต์ของคุณกับรูปภาพของ Joey จาก 10 สิ่งที่ฉันเกลียดเกี่ยวกับคุณ: เป็นไปไม่ได้ที่บอทจะค้นหาความแตกต่างที่สำคัญระหว่างทั้งสองเวอร์ชัน

คุณต้องการหลีกเลี่ยงการมีสองสิ่งที่เหมือนกันทุกประการที่ต้องแข่งขันกันในสถานการณ์การจัดอันดับของเครื่องมือค้นหา คุณต้องการมีประสบการณ์เดียวที่สามารถจัดอันดับและดำเนินการในเครื่องมือค้นหาได้
ความแตกต่างระหว่างสิ่งที่ผู้ใช้และบอทเห็น
ผู้ใช้อาจเห็น URL เดียวที่น่าเชื่อถือ แต่บ็อตอาจยังคงเห็นหลายเวอร์ชันที่ดูเหมือนกัน
– ผลกระทบต่องบประมาณการรวบรวมข้อมูลสำหรับไซต์ขนาดใหญ่มาก
สำหรับไซต์ที่มีขนาดใหญ่มาก เช่น Zillow หรือ Walmart งบประมาณในการรวบรวมข้อมูลอาจแตกต่างกันไปตามหน้าต่างๆ
ตามที่อเล็กซิสกล่าวถึงในบทความปี 2018 โดยอิงจากการนำเสนอโดย Frederic Dubut ที่ SMX East งบประมาณจะกำหนดไว้ที่ระดับต่างๆ กัน ที่ระดับโดเมนย่อย ที่ระดับเซิร์ฟเวอร์ต่างกัน เครื่องมือค้นหา ไม่ว่าจะเป็น Google หรือ Bing ต้องการเป็นโปรแกรมรวบรวมข้อมูลที่สุภาพ พวกเขาไม่ต้องการทำให้ประสิทธิภาพการทำงานช้าลงสำหรับผู้ใช้จริง เมื่อใดก็ตามที่พวกเขารู้สึกถึงการเปลี่ยนแปลงในประสิทธิภาพ พวกเขาจะถอยกลับ สิ่งนี้สามารถเกิดขึ้นได้ในระดับต่างๆ ไม่ใช่แค่ระดับไซต์
หากคุณมีไซต์ขนาดใหญ่ คุณต้องแน่ใจว่าคุณกำลังมอบประสบการณ์ที่รวมเป็นหนึ่งเดียวซึ่งเกี่ยวข้องกับผู้ใช้ของคุณมากที่สุด
เนื้อหาที่ซ้ำกันเป็นเนื้อหาหรือปัญหาทางเทคนิคหรือไม่?
แม้ว่าคำว่า "เนื้อหา" ใน "เนื้อหาที่ซ้ำกัน" ก็เป็นส่วนหนึ่งของปัญหาทางเทคนิค
– แหล่งที่มาของการทำซ้ำ – [07:50]
มีหลายปัจจัยที่อาจทำให้เกิดการซ้ำซ้อน แม้แต่รายการบางส่วนก็ดูเหมือนจะคงอยู่ตลอดไป:
- หน้าซ้ำ
- ไซต์การแสดงละคร
- HTTP กับ HTTPS URLS
- โดเมนย่อยต่างๆ
- กรณีต่างๆ
- นามสกุลไฟล์ต่างๆ
- เครื่องหมายทับ
- หน้าดัชนี
- พารามิเตอร์ URL
- แง่มุม
- เรียง
- รุ่นที่เป็นมิตรกับเครื่องพิมพ์
- หน้าประตู
- รายการสิ่งของ
- เนื้อหาที่รวบรวม
- ข่าวประชาสัมพันธ์
- เผยแพร่เนื้อหาซ้ำ
- เนื้อหาที่ลอกเลียนแบบ
- เนื้อหาที่แปลแล้ว
- เนื้อหาบาง
- เฉพาะภาพ
- การค้นหาไซต์ภายใน
- แยกไซต์มือถือ
- เนื้อหาไม่ซ้ำกัน
- …
– การกระจายปัญหาระหว่างเทคนิค SEO และเนื้อหา
อันที่จริง แหล่งที่มาของเนื้อหาที่ซ้ำกันเหล่านี้สามารถแบ่งออกเป็นแหล่งที่มาทางเทคนิคและการพัฒนา และแหล่งที่มาตามเนื้อหา และบางส่วนที่อยู่ในโซนที่ทับซ้อนกันระหว่างทั้งสอง
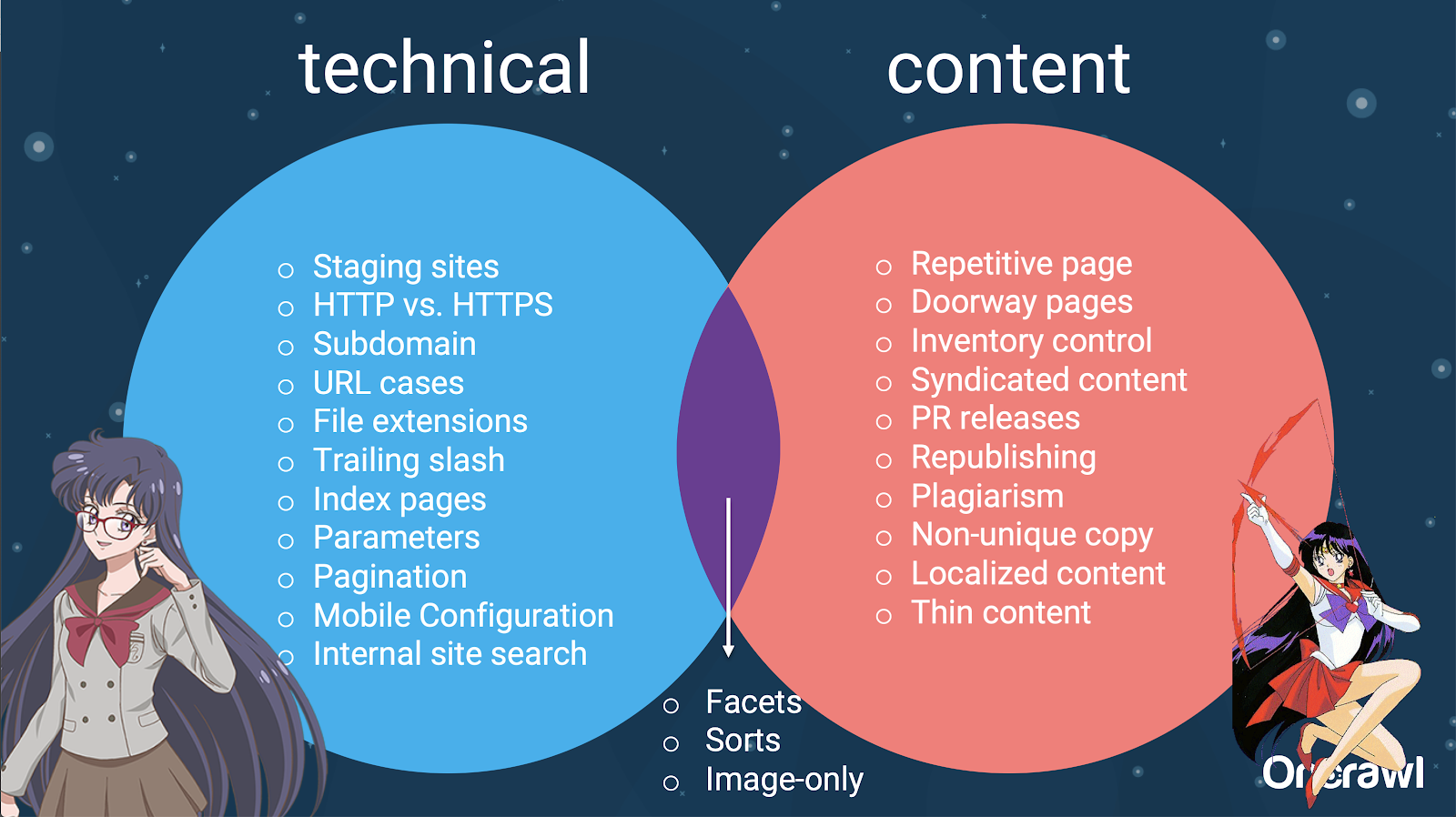
สิ่งนี้ทำให้เนื้อหาที่ซ้ำกันเป็นปัญหาข้ามทีม ซึ่งเป็นส่วนหนึ่งของสิ่งที่ทำให้เนื้อหานั้นน่าสนใจ
วิธีค้นหาเนื้อหาที่ซ้ำกัน
เนื้อหาที่ซ้ำกันส่วนใหญ่ไม่ได้ตั้งใจ สำหรับ Omi สิ่งนี้บ่งชี้ว่ามีความรับผิดชอบร่วมกันระหว่างทีมเนื้อหาและทีมเทคนิคในการค้นหาและแก้ไขเนื้อหาที่ซ้ำกัน
– เครื่องมือโปรดของโอมิ: Grammarly
Grammarly เป็นเครื่องมือโปรดของ Omi ในการค้นหาเนื้อหาที่ซ้ำกัน และไม่ใช่เครื่องมือ SEO ด้วยซ้ำ เขาใช้ตัวตรวจสอบการลอกเลียนแบบ เขาขอให้ผู้จัดพิมพ์เนื้อหาตรวจสอบว่ามีการเผยแพร่เนื้อหาชิ้นใหม่ที่อื่นแล้วหรือไม่
– ปริมาณของเนื้อหาที่ซ้ำกันโดยไม่ได้ตั้งใจ
ปัญหาของเนื้อหาที่ซ้ำกันโดยไม่ได้ตั้งใจเป็นปัญหาที่วิศวกรคุ้นเคย ในหนังสือชื่อ Introduction to Information Retrieval (2008) ซึ่งเห็นได้ชัดว่าล้าสมัย พวกเขาคาดว่าประมาณ 40% ของเว็บในขณะนั้นมีการทำซ้ำ

– จัดลำดับความสำคัญของกลยุทธ์ในการจัดการกับเนื้อหาที่ซ้ำกัน
ในการจัดการกับเนื้อหาที่ซ้ำกัน คุณควร:
- เริ่มต้นด้วยการรู้เส้นทางของผู้ใช้ของคุณ ซึ่งจะช่วยให้คุณเข้าใจว่าเนื้อหาทุกส่วนเหมาะกับส่วนใด สิ่งนี้สามารถทำได้ยากมาก โดยเฉพาะอย่างยิ่งเมื่อเว็บไซต์ถูกสร้างขึ้นเมื่อ 20 ปีที่แล้ว เมื่อเราไม่รู้ว่าเว็บไซต์จะใหญ่แค่ไหน หรือจะขยายขนาดได้อย่างไร การรู้ว่าผู้ใช้ของคุณอยู่ที่จุดใดในการเดินทางของพวกเขา จะช่วยให้คุณจัดลำดับความสำคัญในขั้นตอนถัดไป
- คุณจะต้องมีลำดับชั้นที่ใช้งานได้ เพื่อจัดเตรียมที่สำหรับเนื้อหาแต่ละประเภท การทำความเข้าใจสถาปัตยกรรมข้อมูลของคุณนั้นสูงมากในขั้นตอนในการจัดการกับเนื้อหาที่ซ้ำกัน
- จัดลำดับความสำคัญของเนื้อหาที่ซ้ำกันซึ่งส่งผลต่อประสิทธิภาพการทำงาน รายการแหล่งที่มาบางส่วนข้างต้นยาวเกินไปที่จะเป็นสิ่งที่คุณสามารถโจมตีทั้งหมดในคราวเดียวได้อย่างสมจริง
- จัดการกับความซ้ำซ้อน 100%
- ส่งสัญญาณเนื้อหาที่ซ้ำกัน
- สร้างทางเลือกเชิงกลยุทธ์ในการจัดการกับความซ้ำซ้อน: รวม สร้าง ลบ เพิ่มประสิทธิภาพ
- จัดการกับเนื้อหาที่ถูกขโมย

– เครื่องมือ: การใช้การแบ่งส่วนใน OnCrawl
Alexis ชอบความสามารถในการแบ่งกลุ่มเว็บไซต์ของคุณใน OnCrawl ซึ่งช่วยให้คุณเจาะลึกสิ่งที่มีความหมายสำหรับคุณ
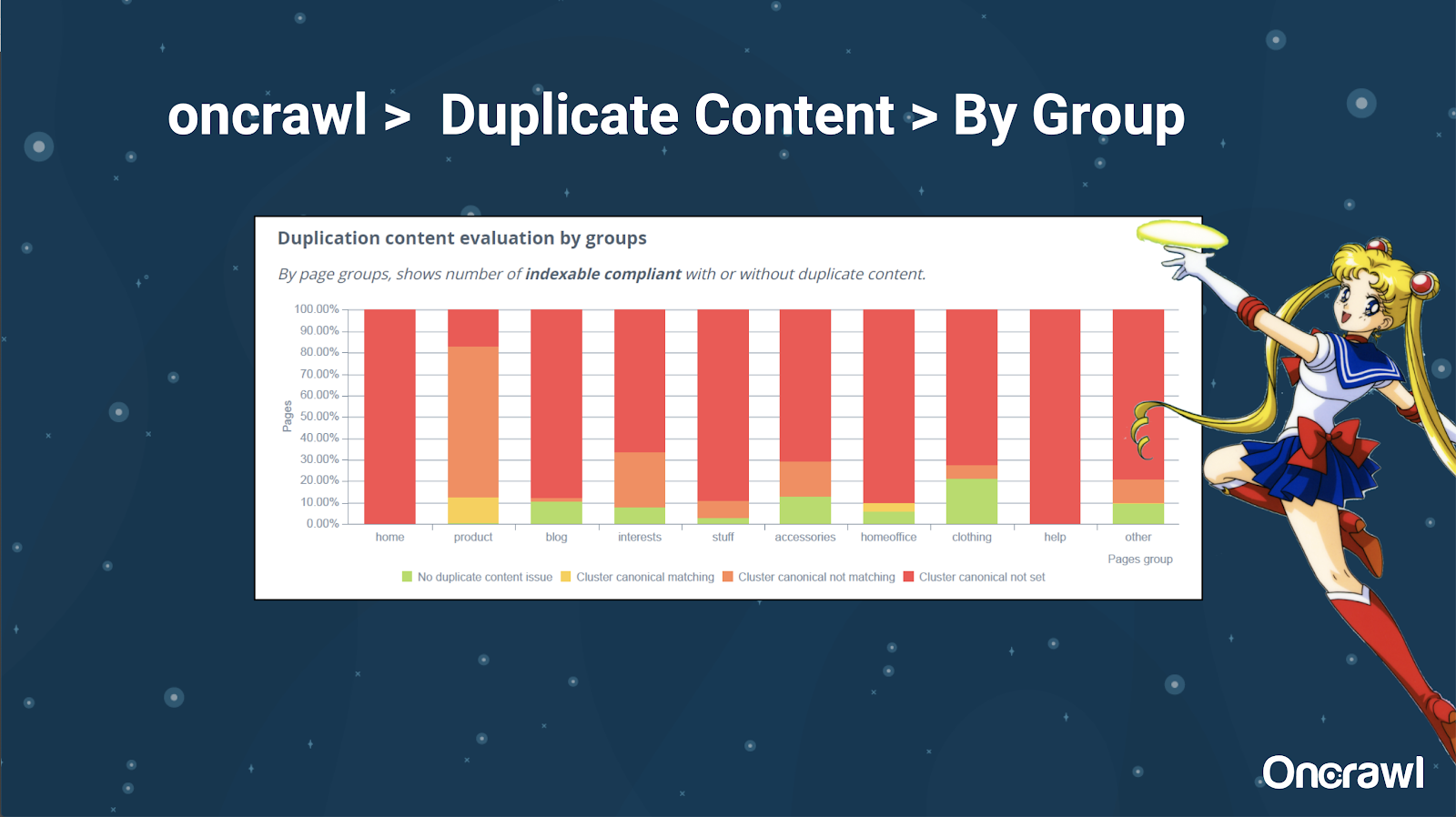
หน้าประเภทต่าง ๆ มีปริมาณการทำซ้ำต่างกัน ซึ่งช่วยให้สามารถดูส่วนต่างๆ ที่มีปัญหาได้มากที่สุด ในตัวอย่างข้างต้น ไซต์ต้องการความสนใจเป็นอย่างมาก
– เครื่องมือ: การค้นหาของ Google และ GSC
คุณยังสามารถตรวจสอบเนื้อหาที่ซ้ำกันโดยใช้เครื่องมือค้นหาเอง ใน Google คุณสามารถ:
- ใช้คำพูดโดยตรง
- ใช้ไซต์: ค้นหา
- การใช้ตัวดำเนินการเพิ่มเติม เช่น inurl:, intitle: หรือ filetype:

Google Search Console ได้เพิ่มรายงานเนื้อหาที่ซ้ำกัน ซึ่งมีประโยชน์มากในการระบุสิ่งที่ Google เชื่อว่าเป็นเนื้อหาที่ซ้ำกันจากด้านข้าง
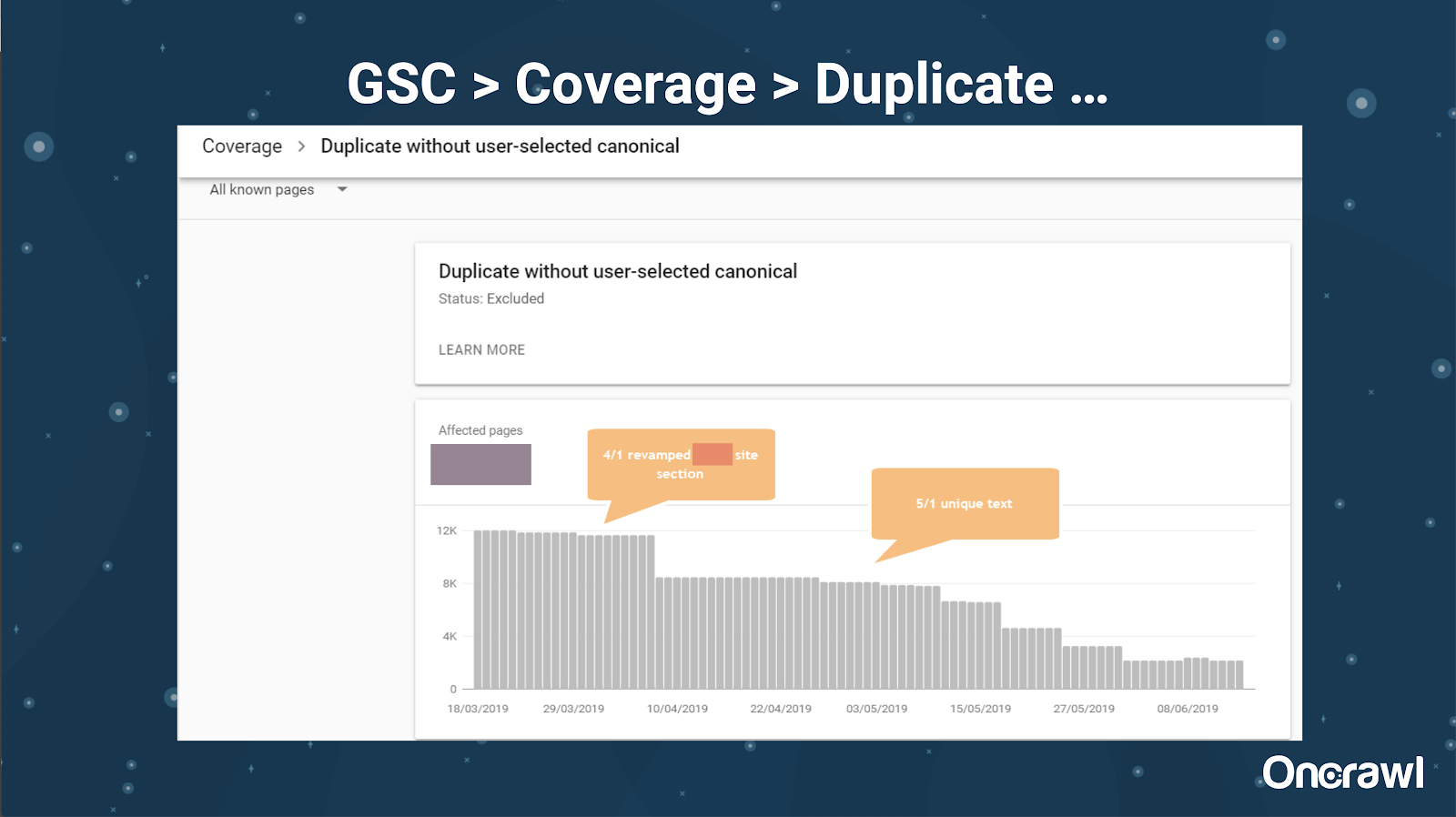
– เครื่องมือ: เครื่องมือลอกเลียนแบบ
เช่นเดียวกับ Omi อเล็กซิสยังใช้เครื่องมือลอกเลียนแบบที่แตกต่างกัน:
Quetext
Noplag
PaperRater
ไวยากรณ์
CopyScape
คุณต้องการให้แน่ใจว่าเนื้อหาของคุณไม่เพียงแค่เป็นต้นฉบับเท่านั้น แต่ยังรวมถึงจากมุมมองของบ็อตด้วยว่าจะไม่ถูกมองว่ามาจากแหล่งอื่น
สิ่งเหล่านี้ยังสามารถช่วยคุณค้นหาส่วนต่างๆ ในบทความที่อาจคล้ายกับเนื้อหาที่อื่นบนอินเทอร์เน็ต
อเล็กซิสชอบวิธีที่เรามีเครื่องมือเหล่านี้ที่ช่วยให้เรา “มีความเห็นอกเห็นใจต่อบอทของเครื่องมือค้นหา” เนื่องจากพวกเราไม่มีใครเป็นหุ่นยนต์ เมื่อเครื่องมือให้สัญญาณแก่เราว่าเนื้อหาคล้ายกันเกินไป แม้ว่าเราจะรู้ว่ามีความแตกต่างกัน นั่นเป็นสัญญาณที่ดีว่ามีบางสิ่งที่ต้องเจาะลึกลงไป

– เครื่องมือ: เครื่องมือความหนาแน่นของคำหลัก
สองตัวอย่างของเครื่องมือวัดความหนาแน่นของคำหลักที่ Alexis ใช้ ได้แก่:
แท็กCrowd
SEObook
ปัญหาขึ้นอยู่กับประเภทของเว็บไซต์
การแก้ไขเนื้อหาที่ซ้ำกันนั้นขึ้นอยู่กับประเภทของเนื้อหาที่คุณกำลังเผยแพร่และประเภทของปัญหาที่คุณกำลังเผชิญอยู่ บล็อกไม่ต้องเผชิญกับกรณีเดียวกันของเนื้อหาที่ซ้ำกันเป็นไซต์อีคอมเมิร์ซเป็นต้น
กรณีที่น่าจดจำ
อเล็กซิสแบ่งปันกรณีลูกค้าล่าสุดที่เธอพบปัญหาเนื้อหาซ้ำซ้อนที่น่าจดจำ
– ไซต์ขนาดใหญ่: ผลลัพธ์หลังจากเพิ่มเนื้อหาที่ไม่ซ้ำกัน
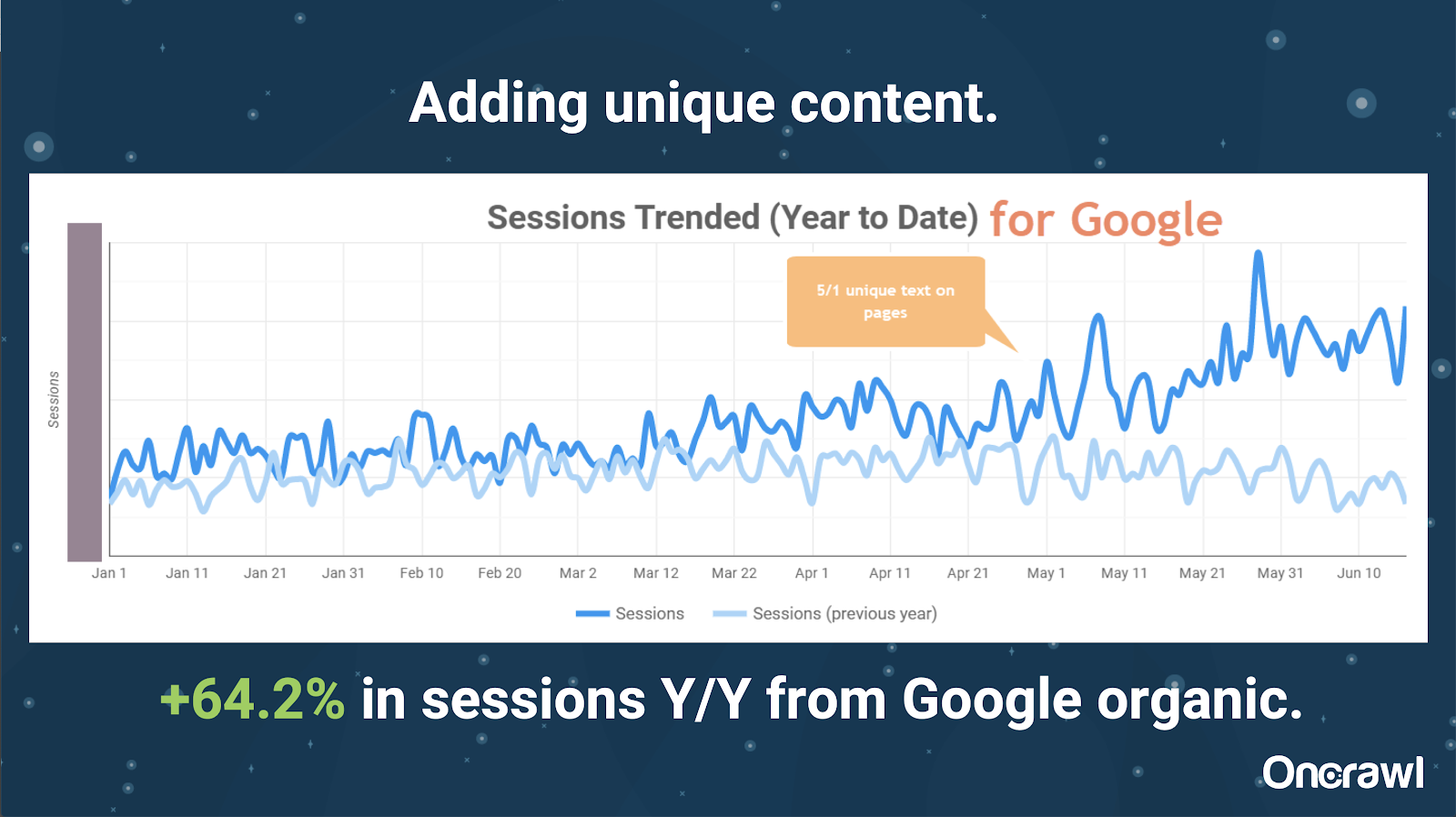
ไซต์นี้มีขนาดใหญ่มาก และประสบปัญหาด้านงบประมาณในการรวบรวมข้อมูล มี 86 ล้านหน้าที่ยังไม่ได้จัดทำดัชนี และมีเพียง 1% ของหน้าที่ได้รับการจัดทำดัชนีแล้ว
นี่คือไซต์อสังหาริมทรัพย์ เนื้อหาส่วนใหญ่ไม่ได้มีลักษณะเฉพาะเป็นพิเศษ และหน้าเว็บจำนวนมากมีความคล้ายคลึงกันมาก อเล็กซิสลงเอยด้วยการเพิ่มเนื้อหาในหน้าเพื่อเพิ่มข้อมูลเฉพาะสถานที่เพื่อสร้างความแตกต่างของหน้า น่าแปลกใจที่สิ่งนี้ให้ผลลัพธ์ได้เร็วเพียงใด (นี่เป็นเพียงข้อมูลทั่วไปของ Google)
สำหรับอเล็กซิส นี่เป็นกรณีศึกษาที่ค่อนข้างธรรมดา เท่าที่เราพูดถึง EAT และสิ่งที่คล้ายคลึงกันในปัจจุบันนี้ แสดงให้เห็นว่าทันทีที่เสิร์ชเอ็นจิ้นเห็นว่าเนื้อหามีเอกลักษณ์และมีคุณค่า สิ่งนั้นก็ยังคงได้รับการตอบแทน

ในไซต์นี้ ปัญหาแท็ก Canonical โดยไม่ได้ตั้งใจทำให้หน้าเว็บประมาณ 250 หน้าถูกส่งไปยังโปรโตคอลที่ไม่ถูกต้อง
นี่เป็นกรณีหนึ่งที่ Canonical tags ระบุหน้าหลักที่ไม่ถูกต้อง โดยผลักหน้า HTTP มาแทนที่หน้า HTTPS
การเปลี่ยนแปลงในช่วง 18 เดือนที่ผ่านมา
อเล็กซิสเขียนบทความที่สมบูรณ์มาก เนื้อหาที่ซ้ำกันและการแก้ปัญหาเชิงกลยุทธ์ ประมาณ 18 เดือนก่อนการสัมมนาผ่านเว็บนี้ SEO เปลี่ยนแปลงอย่างรวดเร็ว และคุณจำเป็นต้องต่ออายุและประเมินความรู้ของคุณใหม่อยู่เสมอ
สำหรับอเล็กซิส สิ่งที่กล่าวถึงในบทความส่วนใหญ่ยังคงมีความเกี่ยวข้องในปัจจุบัน ยกเว้น rel=next/prev เธอหวังว่าจะยุติความเกี่ยวข้องภายในห้าถึงสิบปีข้างหน้าแม้ว่า
ปัญหาทางเทคนิคที่นักพัฒนาจัดการ: ด้วยตนเองเกินไป
ปัญหามากมายที่เกี่ยวข้องกับเนื้อหาที่ซ้ำกันซึ่งจัดการโดยนักพัฒนานั้นเป็นเรื่องที่ทำด้วยตนเองมากเกินไป อเล็กซิสเชื่อว่า CMS และ Adobe ควรจัดการพวกเขาแทน ตัวอย่างเช่น คุณไม่จำเป็นต้องดำเนินการด้วยตนเอง และตรวจสอบให้แน่ใจว่าได้ตั้งค่า Canonical ทั้งหมดและสอดคล้องกัน
– โอกาสในการทำงานอัตโนมัติ/การแจ้งเตือน
มีโอกาสมากมายสำหรับการทำงานอัตโนมัติในด้านปัญหาทางเทคนิคที่มีเนื้อหาที่ซ้ำกัน เพื่อยกตัวอย่าง: เราควรจะสามารถตรวจพบได้ทันทีหากมีการเชื่อมโยงไปยัง HTTP เมื่อพวกเขาควรจะไปที่ HTTPS และแก้ไขให้ถูกต้อง
– อายุไซต์และโครงสร้างพื้นฐานแบบเดิมเป็นอุปสรรค
ระบบแบ็คเอนด์บางระบบเก่าเกินไปที่จะรองรับการเปลี่ยนแปลงและการทำงานอัตโนมัติบางอย่าง การย้าย CMS เก่าไปยังใหม่ทำได้ยากมาก Omi ให้ตัวอย่างการย้ายเว็บไซต์ของ Canon ไปยัง CMS ที่สร้างขึ้นเองแบบใหม่ มันไม่เพียงแต่มีราคาแพงเท่านั้น แต่ยังใช้เวลาถึง 12 เดือนอีกด้วย
Rel ก่อนหน้า/ถัดไปและการสื่อสารจาก Google
บางครั้งการสื่อสารจาก Google อาจทำให้สับสน Omi ยกตัวอย่างในการใช้ rel=prev/next ลูกค้าของเขาพบว่าประสิทธิภาพเพิ่มขึ้นอย่างมากในปี 2018 แม้ว่า Google จะประกาศในปี 2019 ว่าแท็กเหล่านี้ไม่ได้ใช้มาหลายปีแล้ว
– ขาดโซลูชันที่มีขนาดเดียวเหมาะกับทุกคน
ความยากของ SEO คือสิ่งที่คนคนหนึ่งสังเกตเห็นว่าเกิดขึ้นบนเว็บไซต์ไม่จำเป็นต้องเหมือนกับสิ่งที่ SEO คนอื่นเห็นในเว็บไซต์ของพวกเขาเอง ไม่มี SEO ใดที่เหมาะกับทุกคน
ความสามารถของ Google ในการประกาศที่เกี่ยวข้องกับ SEO ทั้งหมดควรได้รับการยอมรับว่าเป็นความสำเร็จที่สำคัญ แม้ว่าข้อความบางส่วนของพวกเขาจะพลาดไป เช่นในกรณีของ rel=next/prev
ความหวังสำหรับอนาคตของการจัดการเนื้อหาที่ซ้ำกัน
ความหวังของอเล็กซิสสำหรับอนาคต:
- เนื้อหาที่ซ้ำกันทางเทคนิคน้อยกว่า (ตามที่ CMS ฉลาดขึ้น)
- ระบบอัตโนมัติมากขึ้น (การทดสอบหน่วยและการทดสอบภายนอก) ตัวอย่างเช่น เครื่องมือต่างๆ เช่น OnCrawl อาจรวบรวมข้อมูลไซต์ของคุณเป็นประจำ และแจ้งให้คุณทราบทันทีที่สังเกตเห็นข้อผิดพลาดบางอย่าง
- ตรวจหาหน้าและประเภทหน้าที่มีความคล้ายคลึงกันสูงโดยอัตโนมัติสำหรับผู้เขียนและผู้จัดการเนื้อหา การดำเนินการนี้จะทำให้การตรวจสอบบางอย่างที่ทำด้วยตนเองในเครื่องมือเช่น Grammarly เป็นไปโดยอัตโนมัติ: เมื่อมีคนพยายามเผยแพร่ CMS ควรพูดว่า "สิ่งนี้คล้ายกัน คุณแน่ใจหรือไม่ว่าต้องการเผยแพร่สิ่งนี้" การดูเว็บไซต์เดียวและการเปรียบเทียบข้ามเว็บไซต์นั้นมีประโยชน์มากมาย
- Google ยังคงปรับปรุงระบบและการตรวจจับที่มีอยู่อย่างต่อเนื่อง
- อาจเป็นระบบแจ้งเตือนเพื่อแจ้งปัญหาของ Google โดยไม่ใช้ Canonical ที่ถูกต้อง จะเป็นประโยชน์หากสามารถแจ้งเตือน Google ถึงปัญหาและแก้ไขปัญหาได้
เราต้องการเครื่องมือที่ดีกว่า เครื่องมือภายในที่ดีกว่า แต่หวังว่าในขณะที่ Google พัฒนาระบบ พวกเขาจะเพิ่มองค์ประกอบเพื่อช่วยเราเล็กน้อย
เทคนิคสุดโปรดของอเล็กซิส
อเล็กซิสมีเทคนิคที่ชื่นชอบหลายประการ:
- อินสแตนซ์คอมพิวเตอร์ระยะไกล EC2 นี่เป็นวิธีที่ยอดเยี่ยมมากในการเข้าถึงคอมพิวเตอร์จริงสำหรับการรวบรวมข้อมูลขนาดใหญ่ หรืออะไรก็ได้ที่ต้องใช้พลังประมวลผลสูง มันเร็วมากเมื่อคุณได้รับการติดตั้ง เพียงให้แน่ใจว่าคุณยกเลิกมันเมื่อคุณทำเสร็จแล้ว เพราะมันจะต้องเสียเงิน
- ตรวจสอบเครื่องมือทดสอบมือถือครั้งแรก Google ได้กล่าวว่านี่เป็นภาพที่ถูกต้องที่สุดสำหรับสิ่งที่พวกเขากำลังดู มันมองไปที่ DOM
- เปลี่ยน User Agent เป็น Googlebot ข้อมูลนี้จะช่วยให้คุณทราบว่า Googlebots กำลังเห็นอะไรจริงๆ
- การใช้เครื่องมือ robots.txt ของ TechnicalSEO.com นี่เป็นหนึ่งในเครื่องมือของ Merkle แต่ Alexis ชอบมากเพราะ robots.txt อาจทำให้สับสนในบางครั้ง
- ใช้ตัววิเคราะห์บันทึก
- ทำด้วยตัวตรวจสอบ htaccess ของ Love
- การใช้ Google Data Studio เพื่อรายงานการเปลี่ยนแปลง (การซิงค์ชีตกับการอัปเดต การกรองแต่ละหน้าตามการอัปเดตที่เกี่ยวข้อง)
ปัญหาทางเทคนิค SEO: robots.txt
Robots.txt นั้นน่าสับสนจริงๆ
เป็นไฟล์เก่าที่ดูเหมือนว่าจะรองรับ RegEx ได้ แต่ไม่รองรับ
มีกฎลำดับความสำคัญที่แตกต่างกันสำหรับการไม่อนุญาตและอนุญาตกฎ ซึ่งอาจทำให้เกิดความสับสน
บอทที่แตกต่างกันสามารถละเลยสิ่งต่าง ๆ ได้ แม้ว่าจะไม่ควรทำก็ตาม
สมมติฐานของคุณเกี่ยวกับสิ่งที่ถูกต้องอาจไม่ถูกต้องเสมอไป

ถาม-ตอบ
– HSTS: ต้องใช้โปรโตคอลแบบแยกส่วนหรือไม่
คุณต้องมี HTTPS ทั้งหมดสำหรับเนื้อหาที่ซ้ำกัน หากคุณมี HSTS
– เนื้อหาที่แปลเป็นเนื้อหาที่ซ้ำกันหรือไม่?
บ่อยครั้งเมื่อคุณใช้ hreflang คุณกำลังใช้เพื่อแยกความกำกวมระหว่างเวอร์ชันที่แปลเป็นภาษาเดียวกัน เช่น หน้าภาษาอังกฤษของสหรัฐอเมริกาและไอริช อเล็กซิสจะไม่พิจารณาเนื้อหาที่ซ้ำกันนี้ แต่เธอขอแนะนำให้ตรวจสอบให้แน่ใจว่าคุณได้ตั้งค่าแท็ก hreflang อย่างถูกต้องเพื่อระบุว่านี่เป็นประสบการณ์เดียวกัน ซึ่งได้รับการปรับให้เหมาะสมสำหรับผู้ชมที่แตกต่างกัน
– คุณสามารถใช้ Canonical tags แทนการเปลี่ยนเส้นทาง 301 สำหรับการย้ายข้อมูล HTTP/HTTPS ได้หรือไม่
การตรวจสอบสิ่งที่เกิดขึ้นจริงใน SERP จะเป็นประโยชน์ สัญชาตญาณของอเล็กซิสคือการพูดว่าไม่เป็นไร แต่ขึ้นอยู่กับว่า Google มีพฤติกรรมอย่างไร ตามหลักการแล้ว หากเป็นหน้าเดียวกัน คุณจะต้องใช้ 301 แต่เธอเคยเห็น Canonical tag ที่ใช้งานได้ในอดีตสำหรับการย้ายข้อมูลประเภทนี้ เธอได้เห็นสิ่งนี้โดยบังเอิญ
จากประสบการณ์ของ Omi เขาขอแนะนำอย่างยิ่งให้ใช้ 301s เพื่อหลีกเลี่ยงปัญหา: หากคุณกำลังย้ายข้อมูลเว็บไซต์ คุณอาจย้ายข้อมูลอย่างถูกต้องเพื่อหลีกเลี่ยงข้อผิดพลาดในปัจจุบันและอนาคต
– ผลกระทบของชื่อหน้าที่ซ้ำกัน
สมมติว่าคุณมีชื่อที่คล้ายคลึงกันมากสำหรับสถานที่ต่างๆ แต่เนื้อหาแตกต่างกันมาก แม้ว่าเนื้อหาดังกล่าวจะไม่ซ้ำกับ Alexis แต่เธอมองว่าเครื่องมือค้นหาถือว่าสิ่งนี้เป็นประเภท "โดยรวม" และชื่อเป็นสิ่งที่สามารถใช้ระบุพื้นที่ที่อาจมีปัญหาได้
นี่คือที่ที่คุณอาจต้องการใช้การค้นหา [site: + intitle: ]
อย่างไรก็ตาม เพียงเพราะคุณมีแท็กชื่อเดียวกัน จะไม่ทำให้เกิดปัญหาเนื้อหาที่ซ้ำกัน
คุณควรยังคงตั้งเป้าไปที่ชื่อและคำอธิบายเมตาที่ไม่ซ้ำใคร แม้กระทั่งในหน้าที่มีเลขหน้าหรือหน้าอื่นๆ ที่คล้ายกันมาก นี่ไม่ใช่เพราะเนื้อหาที่ซ้ำกัน แต่เกี่ยวข้องกับวิธีการเพิ่มประสิทธิภาพวิธีนำเสนอหน้าเว็บของคุณใน SERP
เคล็ดลับยอดนิยม
“เนื้อหาที่ซ้ำกันเป็นทั้งความท้าทายทางเทคนิคและการตลาดเนื้อหา”
SEO ใน Orbit ไปสู่อวกาศ
หากคุณพลาดการเดินทางสู่อวกาศในวันที่ 27 มิถุนายน ติดตามได้ที่นี่และค้นพบเคล็ดลับทั้งหมดที่เราส่งไปในอวกาศ