
การใช้ Python และ Sitemaps เพื่อตรวจสอบกลยุทธ์เนื้อหา
เผยแพร่แล้ว: 2020-10-08ความสนใจในสิ่งที่สามารถทำได้ในนามของ SEO ด้วย Python Libraries นั้นไม่ใช่ความลับอีกต่อไป อย่างไรก็ตาม คนส่วนใหญ่ที่มีประสบการณ์การเขียนโปรแกรมน้อยมีปัญหาในการนำเข้าและใช้งานไลบรารีจำนวนมากหรือการพุช ผลลัพธ์ที่เกินกว่าที่โปรแกรมรวบรวมข้อมูลทั่วไปหรือเครื่องมือ SEO จะทำได้
นี่คือเหตุผลที่ไลบรารี Python ที่สร้างขึ้นโดยเฉพาะสำหรับ SEO, SEM, SMO, SERP check และการวิเคราะห์เนื้อหามีประโยชน์สำหรับทุกคน
ในบทความนี้ เราจะมาดูบางสิ่งที่สามารถทำได้ด้วย Advertools Python Library for SEO ที่สร้างและพัฒนาโดย Elias Dabbas ซึ่งผมเห็นว่ามีศักยภาพสูงในด้าน SEO, PPC และความสามารถในการเขียนโค้ด ในเวลาอันสั้น นอกจากนี้ เราจะใช้สคริปต์ Python แบบกำหนดเองร่วมกับไลบรารี Python อื่นๆ ในลักษณะที่ให้ความรู้และปรับเปลี่ยนได้
เราจะตรวจสอบสิ่งที่สามารถเรียนรู้สำหรับ SEO จากแผนผังเว็บไซต์ด้วยฟังก์ชัน sitemap_to_df ของ Elias Dabbas ซึ่งช่วยในการดาวน์โหลดและวิเคราะห์แผนผังเว็บไซต์ XML (แผนผังเว็บไซต์คือเอกสารในรูปแบบ XML ที่ใช้ในการรายงาน URL ที่รวบรวมข้อมูลและจัดทำดัชนีได้ไปยังเครื่องมือค้นหา)
บทความนี้จะแสดงให้คุณเห็นว่าคุณสามารถเขียนโค้ด Python แบบกำหนดเองเพื่อวิเคราะห์เว็บไซต์ต่างๆ ตามโครงสร้างที่แตกต่างกันได้อย่างไร วิธีตีความข้อมูลในแง่ของ SEO และวิธีคิดเหมือนเสิร์ชเอ็นจิ้นเมื่อกล่าวถึงโปรไฟล์เนื้อหา URL และโครงสร้างเว็บไซต์ .
การวิเคราะห์ขนาดเนื้อหาและกลยุทธ์ของเว็บไซต์ตามแผนผังเว็บไซต์
แผนผังเว็บไซต์เป็นส่วนประกอบของเว็บไซต์ที่สามารถเก็บข้อมูลได้หลายประเภท เช่น ความถี่ที่เว็บไซต์เผยแพร่เนื้อหา หมวดหมู่ของเนื้อหา วันที่เผยแพร่ ข้อมูลผู้เขียน หัวเรื่องเนื้อหา...
ภายใต้สภาวะปกติ คุณสามารถขูดแผนผังไซต์ด้วย scrapy แปลงเป็น DataFrame กับ Pandas และตีความมันด้วยไลบรารีเสริมต่างๆ มากมายหากต้องการ
แต่ในบทความนี้ เราจะใช้เฉพาะวิธีการและแอตทริบิวต์ของห้องสมุด Advertools และ Pandas เท่านั้น ห้องสมุดบางแห่งจะเปิดใช้งานเพื่อให้เห็นภาพข้อมูลที่เราได้รับ
มาเจาะลึกและเลือกเว็บไซต์เพื่อใช้แผนผังเว็บไซต์เพื่อสรุปข้อมูลเชิงลึก SEO ที่สำคัญ
การแยกและสร้างกรอบข้อมูลจากแผนผังเว็บไซต์ด้วย Advertools
ใน Advertools คุณสามารถค้นพบ เรียกดู และรวมแผนผังเว็บไซต์ทั้งหมดของเว็บไซต์ด้วยโค้ดเพียงบรรทัดเดียว
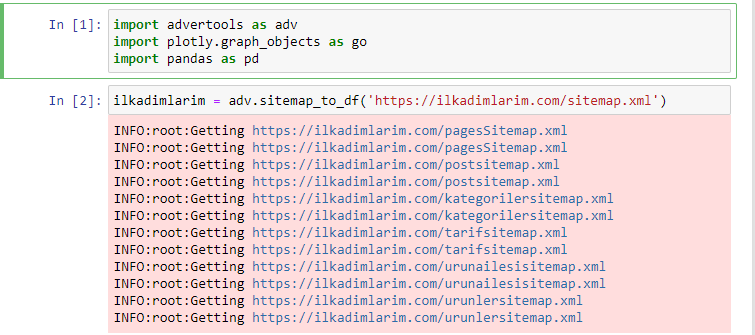
ฉันชอบใช้ Jupyter Notebook แทนตัวแก้ไขโค้ดปกติหรือ IDE
ในเซลล์แรก เราได้นำเข้า Pandas และ Advertools เพื่อรวบรวมและจัดระเบียบข้อมูล และ Plotly.graph_objects สำหรับการแสดงข้อมูล
คำสั่ง adv.sitemap_to_df('sitemap address') รวบรวมแผนผังเว็บไซต์ทั้งหมดและรวมเป็น DataFrame
หากคุณทำเช่นเดียวกันโดยใช้ Pandas และ Advertools คุณสามารถค้นหา URL ที่มีอยู่ในแผนผังเว็บไซต์ได้
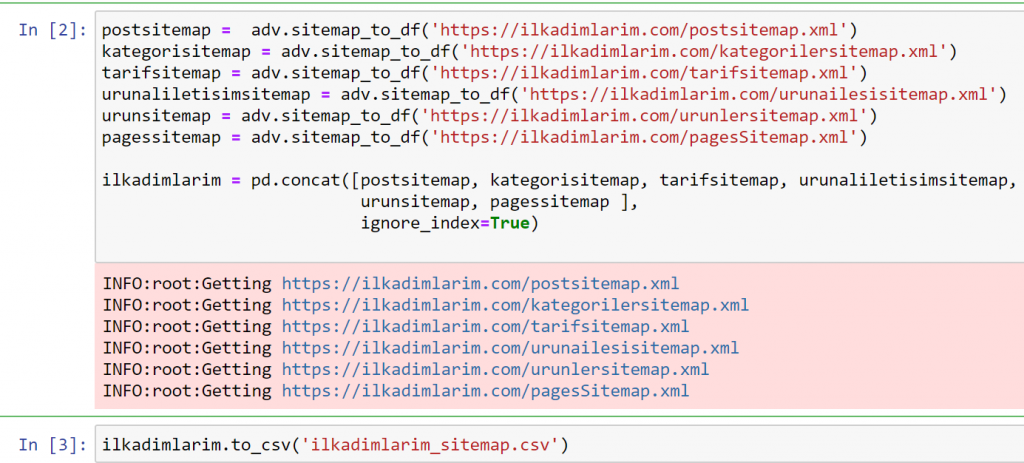
ในตัวอย่างข้างต้น เราดึงแผนผังเว็บไซต์เดียวกันแยกจากกัน แล้วรวมเข้ากับคำสั่ง pd.concat และโอนผลลัพธ์ไปยัง CSV ตัวอย่างก่อนหน้านี้ใช้ไฟล์ดัชนีแผนผังเว็บไซต์ ซึ่งในกรณีนี้ ฟังก์ชันจะไปดึงข้อมูลแผนผังเว็บไซต์อื่นๆ ทั้งหมด ดังนั้นคุณจึงมีตัวเลือกในการเลือกแผนผังเว็บไซต์เฉพาะอย่างที่เราทำที่นี่ หากคุณสนใจในส่วนใดส่วนหนึ่งของเว็บไซต์
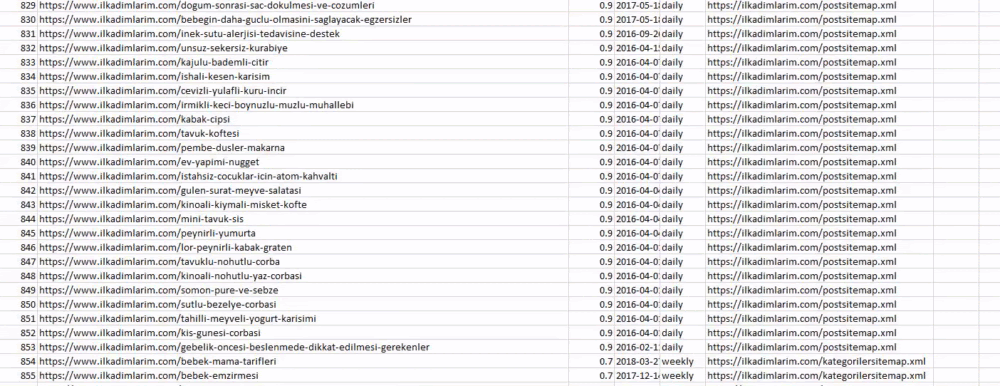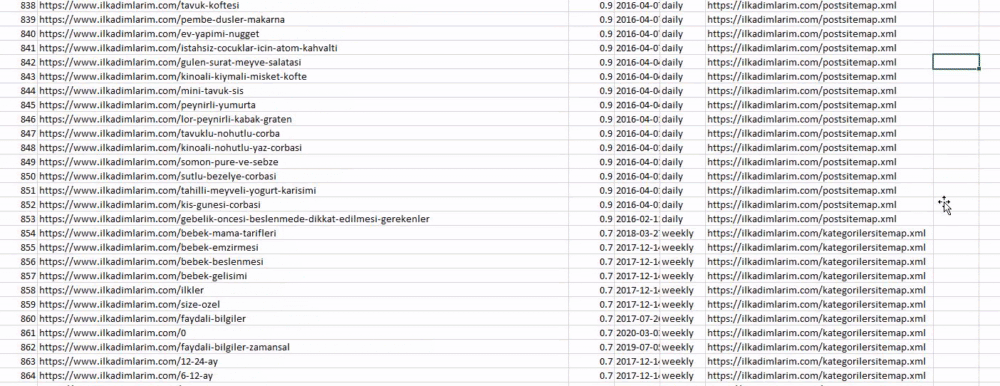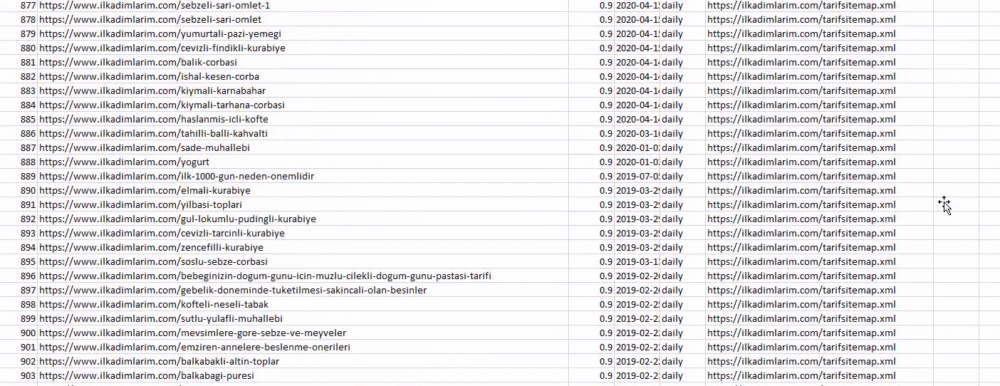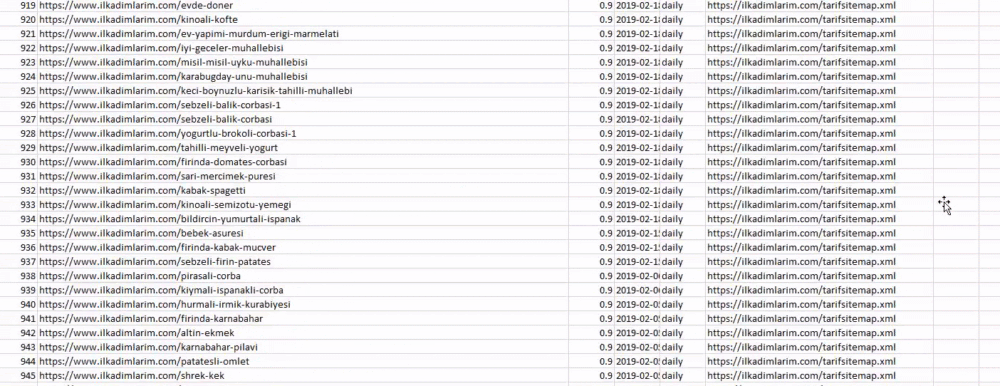
คุณสามารถดูคอลัมน์ที่มีชื่อแผนผังเว็บไซต์ต่างกันด้านบน forget_index=ส่วนจริงมีไว้สำหรับการเรียงลำดับหมายเลขดัชนีของ DataFrames ที่แตกต่างกันอย่างเป็นระเบียบ หากคุณรวมหลาย ๆ อันเข้าด้วยกัน
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมการทำความสะอาดและการเตรียมกรอบข้อมูลแผนผังเว็บไซต์สำหรับการวิเคราะห์เนื้อหาด้วย Python
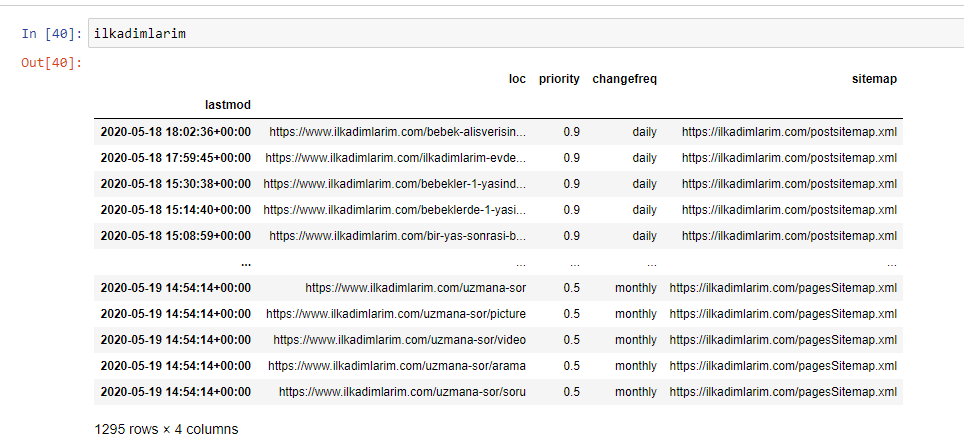
เพื่อให้เข้าใจโปรไฟล์เนื้อหาของเว็บไซต์ผ่านแผนผังเว็บไซต์ เราต้องเตรียมมันเพื่อตรวจทาน DataFrame ที่เราได้รับจาก Advertools
เราจะใช้คำสั่งพื้นฐานจากไลบรารี Pandas เพื่อกำหนดข้อมูลของเรา:
อิลคาดิมลาริม = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(คอลัมน์ = 'ไม่มีชื่อ: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
“อิลคาดิมลาริม” หมายถึง “ก้าวแรกของฉัน” ในภาษาตุรกี และอย่างที่คุณจินตนาการได้ มันคือไซต์สำหรับทารก การตั้งครรภ์ และการเลี้ยงลูกด้วยนมแม่
เราได้ดำเนินการสามครั้งด้วยบรรทัดเหล่านี้
- ไม่มีชื่อ: เราลบคอลัมน์ว่างที่ชื่อ 0 ออกจาก DataFrame นอกจากนี้ หากคุณใช้ 'index = False “ พร้อม ฟังก์ชัน pd.to_csv() คุณจะไม่เห็นคอลัมน์ 'Unnamed 0' นี้ที่จุดเริ่มต้น
- เราแปลงข้อมูลในคอลัมน์ Last Modification เป็น Date Time
- เรานำคอลัมน์ "lastmod" มาไว้ที่ตำแหน่งดัชนี
ด้านล่างนี้ คุณสามารถดู DataFrame เวอร์ชันสุดท้ายได้
เราทราบดีว่า Google ไม่ได้ใช้ลำดับความสำคัญและเปลี่ยนแปลงข้อมูลความถี่จากแผนผังเว็บไซต์ พวกเขาเรียกมันว่า "ถุงหูหนวก" แต่ถ้าคุณให้ความสำคัญกับประสิทธิภาพของเว็บไซต์ของคุณสำหรับเครื่องมือค้นหาอื่นๆ คุณอาจพบว่ามีประโยชน์ในการตรวจสอบเช่นกัน โดยส่วนตัวแล้ว ฉันไม่สนใจข้อมูลนี้มากนัก แต่ก็ยังไม่จำเป็นต้องลบออกจาก DataFrame
เราต้องการโค้ดอีกหนึ่งบรรทัดเพื่อจัดหมวดหมู่แผนผังเว็บไซต์ในอีกคอลัมน์หนึ่ง
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
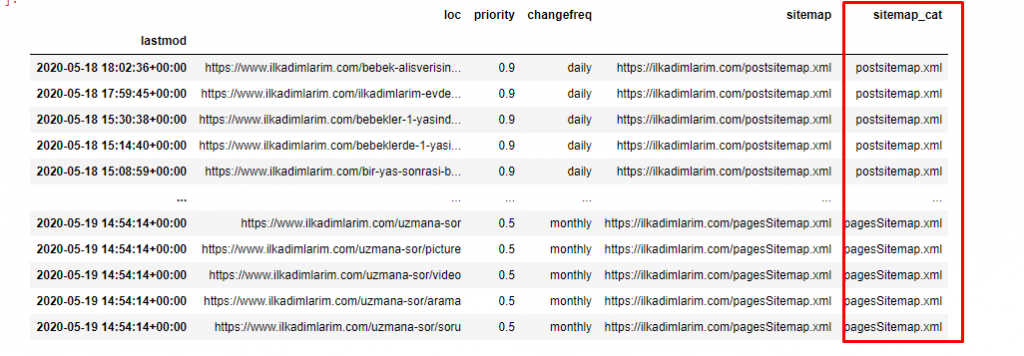
ใน Pandas คุณสามารถเพิ่มคอลัมน์หรือแถวใหม่ลงใน DataFrame หรือคุณสามารถอัปเดตได้อย่างง่ายดาย เราได้สร้างคอลัมน์ใหม่ด้วยข้อมูลโค้ด DataFrame['new_columns'] DataFrame['column_name'].str ช่วยให้เราดำเนินการต่างๆ ได้โดยเปลี่ยนประเภทของข้อมูลในคอลัมน์ เราแบ่งข้อมูลสตริงในคอลัมน์ที่เกี่ยวข้องกับ .split ('/') ด้วยอักขระ / และใส่ลงในรายการ ด้วย .str [number] เราสร้างเนื้อหาของคอลัมน์ใหม่โดยเลือกองค์ประกอบเฉพาะในรายการนั้น
การวิเคราะห์โปรไฟล์เนื้อหาตามจำนวนและประเภทของแผนผังเว็บไซต์
หลังจากวางแผนผังเว็บไซต์ในคอลัมน์ต่างๆ ตามประเภทแล้ว เราสามารถตรวจสอบว่ามีเนื้อหากี่% ในแต่ละแผนผังเว็บไซต์ ดังนั้นเราจึงสามารถอนุมานได้ว่าส่วนใดของเว็บไซต์มีความสำคัญมากกว่า
ilkadimlarim['sitemap_cat'].value_counts (ทำให้ปกติ = True) * 100
- DataFrame['column_name'] กำลังเลือกคอลัมน์ที่เราต้องการสร้างกระบวนการ
- value_counts() นับความถี่ของค่าในคอลัมน์
- normalize=True ใช้อัตราส่วนของค่าเป็นทศนิยม
- เราทำให้อ่านง่ายขึ้นโดยทำให้ตัวเลขทศนิยมใหญ่ขึ้นด้วย *100
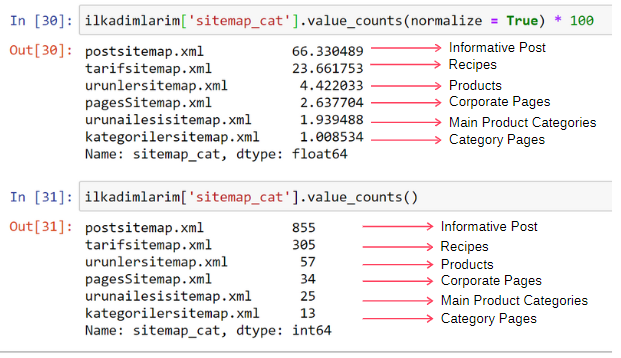
เราพบว่า 65% ของเนื้อหาอยู่ใน Post Sitemap และ 23% อยู่ใน Recipe Sitemap Product Sitemap มีเนื้อหาเพียง 2%
นี่แสดงให้เห็นว่าเรามีเว็บไซต์ที่ต้องสร้างเนื้อหาข้อมูลสำหรับผู้ชมจำนวนมากเพื่อทำการตลาดผลิตภัณฑ์ของตนเอง ลองดูว่าวิทยานิพนธ์ของเราถูกต้องหรือไม่
ก่อนดำเนินการต่อ เราต้องเปลี่ยนชื่อคอลัมน์ ilkadimlarim['sitemap_cat'] เป็น 'URL_Count' ด้วยรหัสด้านล่าง:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- ฟังก์ชัน rename() มีประโยชน์ในการแก้ไขชื่อคอลัมน์หรือดัชนีของคุณสำหรับการเชื่อมต่อข้อมูลและความหมายในระดับที่ลึกกว่า
- เราได้เปลี่ยนชื่อคอลัมน์เป็นแบบถาวรด้วยแอตทริบิวต์ 'inplace=True'
- คุณยังเปลี่ยนรูปแบบตัวอักษรของคอลัมน์และดัชนีได้ด้วย ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) สิ่งนี้จะเขียนเฉพาะตัวอักษรตัวแรกเป็นตัวพิมพ์ใหญ่ของทุกคอลัมน์ในภาษาอิลคาดิมลาริม

ตอนนี้เราอาจจะดำเนินการต่อ
หากต้องการดูข้อมูลนี้ในเฟรมเดียว คุณสามารถใช้รหัสด้านล่าง:
(ilkadimlarim['sitemap_cat']
.value_counts()
.to_frame()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}')))
- to_frame() ใช้เพื่อเฟรมค่าที่วัดโดย value_counts() ในคอลัมน์ที่เลือก
- assign() ใช้เพื่อเพิ่มค่าบางอย่างให้กับเฟรม
- lambda หมายถึงฟังก์ชันที่ไม่ระบุชื่อใน Python
- ในที่นี้ ฟังก์ชันแลมบ์ดาและประเภทแผนผังเว็บไซต์จะถูกหารด้วยจำนวนแผนผังเว็บไซต์ทั้งหมดโดยวิธี Pandas div()
- style() กำหนดวิธีการเขียนค่าสุดท้ายที่ระบุ
- ในที่นี้ เรากำหนดจำนวนหลักที่เขียนหลังจุดด้วยเมธอด format()
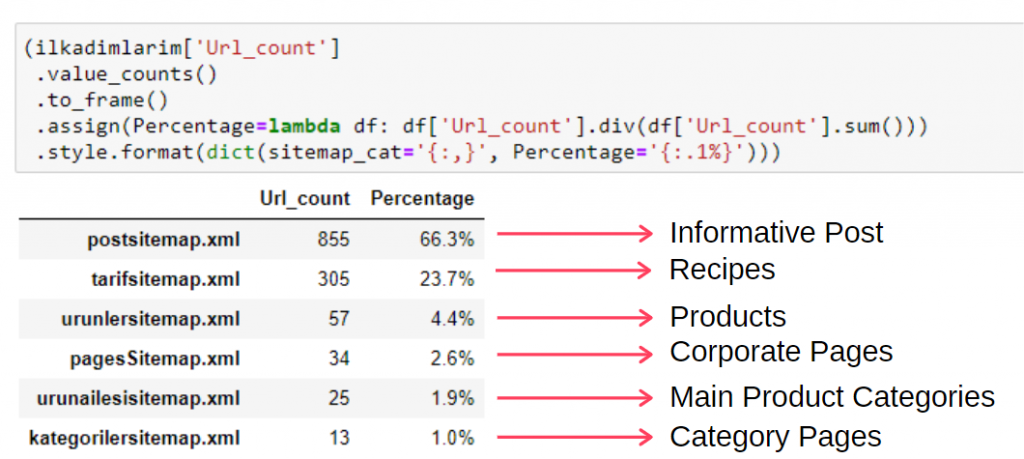
ดังนั้นเราจึงเห็นความสำคัญของการตลาดเนื้อหาสำหรับเว็บไซต์นี้ นอกจากนี้เรายังสามารถตรวจสอบแนวโน้มการตีพิมพ์บทความได้ทุกปีด้วยโค้ดสองบรรทัดเดียว เพื่อตรวจสอบสถานการณ์ของพวกเขาอย่างลึกซึ้งยิ่งขึ้น
ตรวจสอบและแสดงภาพแนวโน้มการเผยแพร่เนื้อหาตามปีผ่านแผนผังเว็บไซต์และ Python
เราทำเนื้อหาและการจับคู่ความตั้งใจของเว็บไซต์ที่ตรวจสอบตามหมวดหมู่แผนผังเว็บไซต์ แต่เรายังไม่ได้จัดประเภทตามเวลา เราจะใช้วิธี resample() เพื่อทำสิ่งนี้ให้สำเร็จ
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample เป็นวิธีการในไลบรารี Pandas resample('A') ตรวจสอบชุดข้อมูลสำหรับ DataFrame ประจำปี สำหรับสัปดาห์ คุณสามารถใช้ 'W' สำหรับเดือน คุณสามารถใช้ 'M'
Loc ที่นี่เป็นสัญลักษณ์ของดัชนี count หมายความว่าคุณต้องการนับผลรวมของตัวอย่างข้อมูล
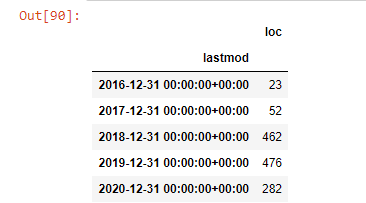
เราพบว่าพวกเขาเริ่มเผยแพร่บทความในปี 2016 แต่แนวโน้มการเผยแพร่หลักของพวกเขาเพิ่มขึ้นหลังจากปี 2017 นอกจากนี้เรายังสามารถใส่สิ่งนี้ลงในกราฟิกด้วยความช่วยเหลือของ Plotly Graph Objects
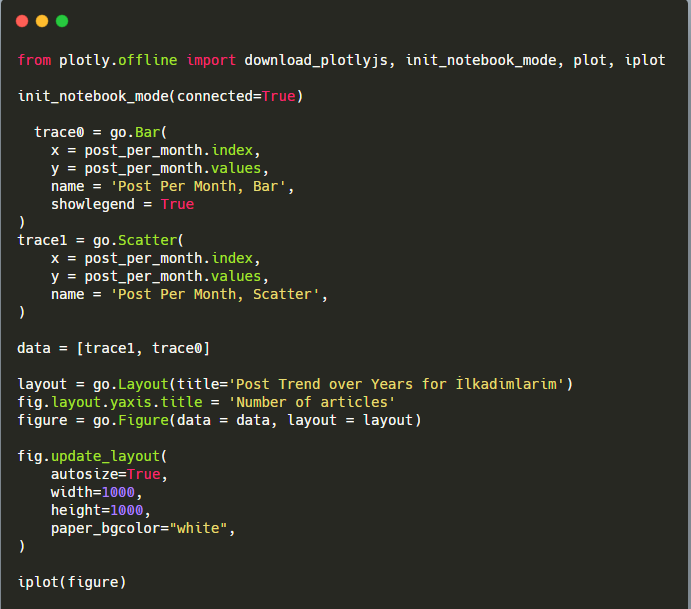
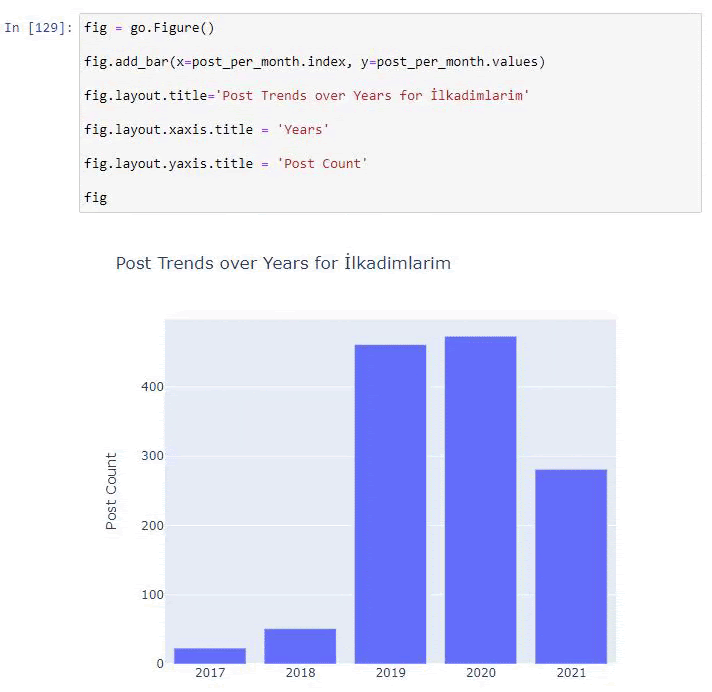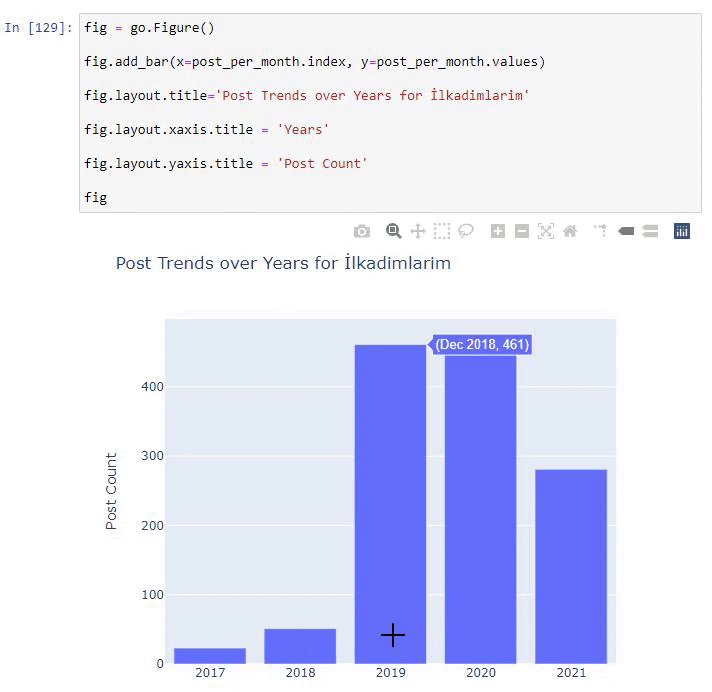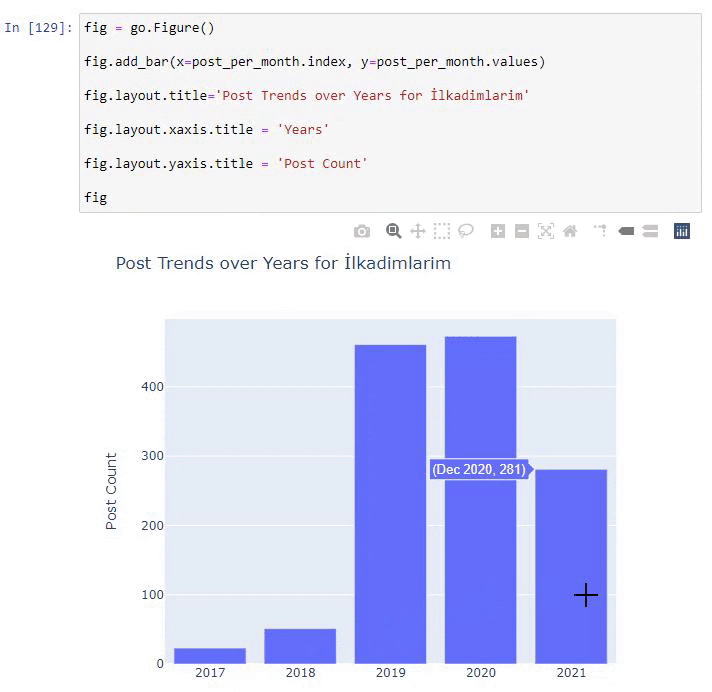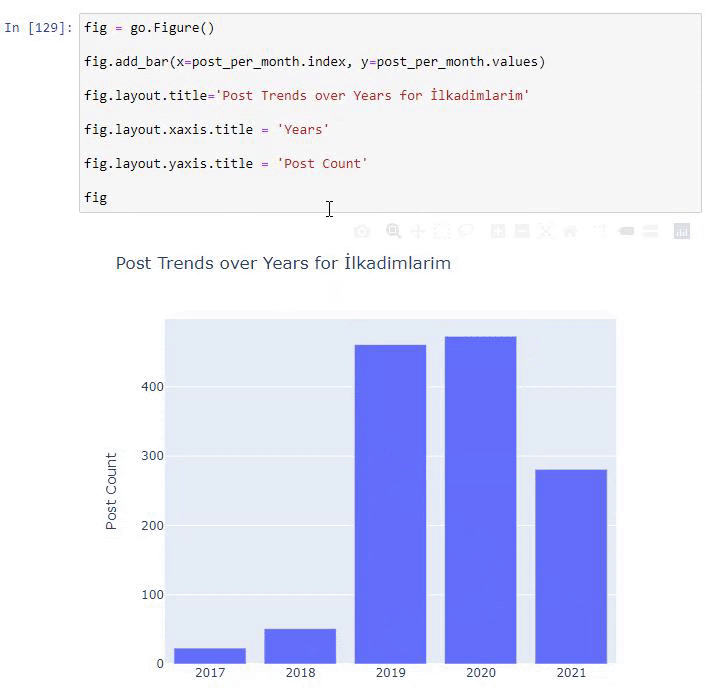
คำอธิบายของข้อมูลโค้ดบาร์โค้ดพล็อตนี้:
- fig = go.Figure() ใช้สำหรับสร้างตัวเลข
- fig.add_bar() ใช้สำหรับเพิ่ม barplot ลงในรูป นอกจากนี้เรายังกำหนดแกน X และ Y ที่จะอยู่ภายในวงเล็บ
- Fig.layout ใช้สำหรับสร้างชื่อทั่วไปสำหรับฟิกเกอร์และแกน
- ที่บรรทัดสุดท้าย เรากำลังเรียกใช้พล็อตที่เราสร้างขึ้นด้วยคำสั่ง fig ซึ่งเท่ากับ go.Figure()
ด้านล่างนี้ คุณจะพบข้อมูลเดียวกันตามเดือน โดยมี scatterplot และ barplot:
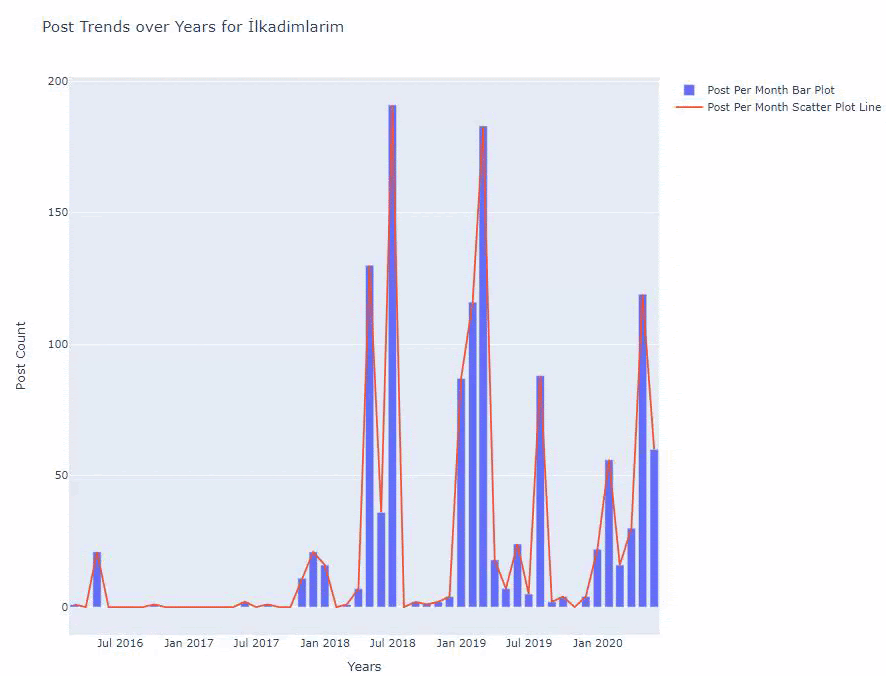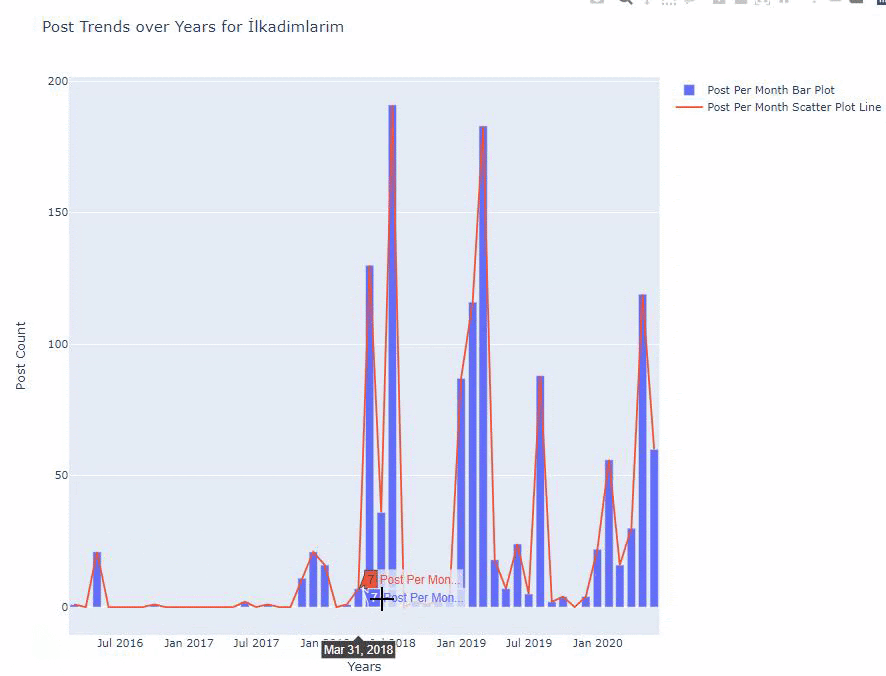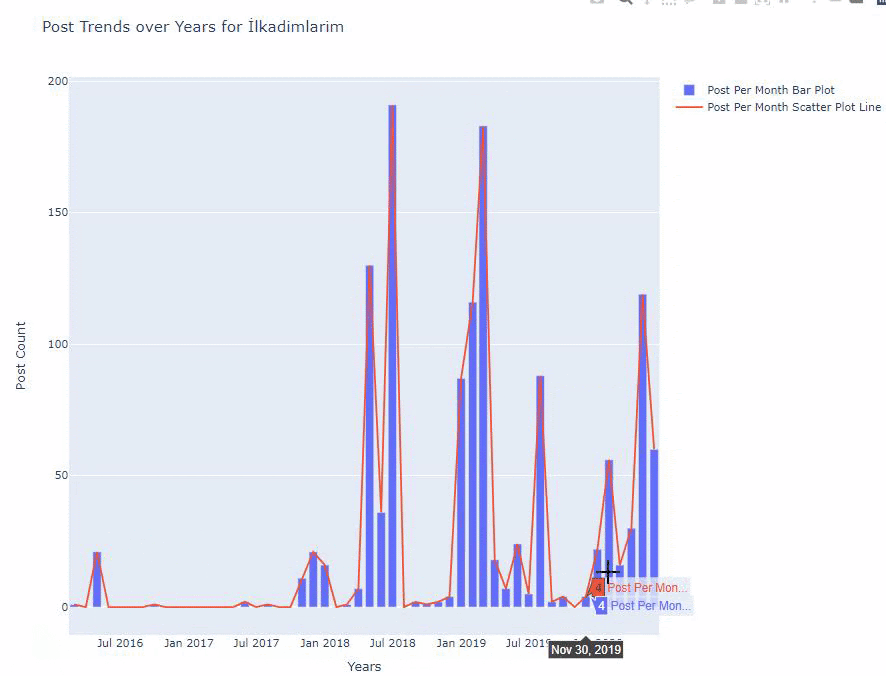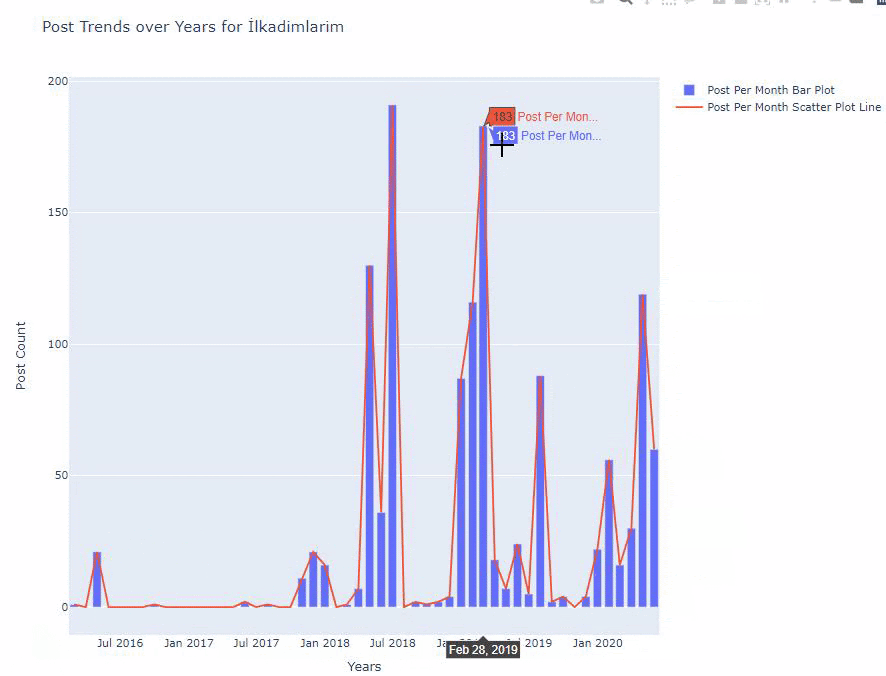
นี่คือรหัสสำหรับสร้างรูปนี้:
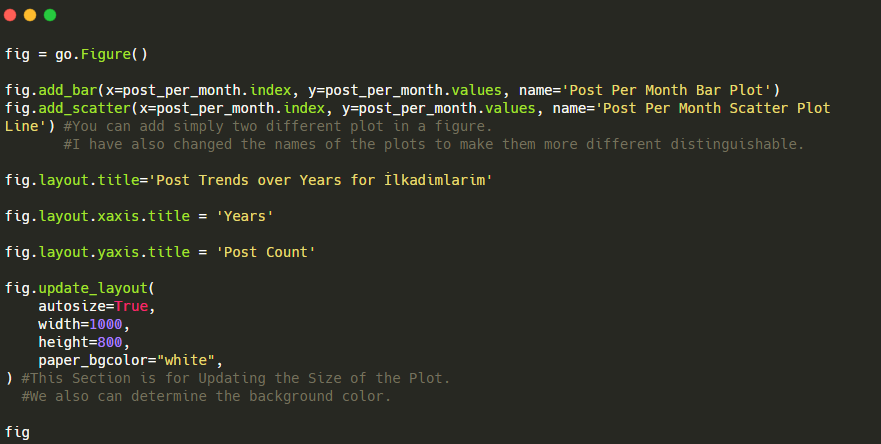
เราได้เพิ่มพล็อตที่สองด้วย fig.add_scatter() และเราได้เปลี่ยนชื่อโดยใช้แอตทริบิวต์ชื่อด้วย fig.update_layout() ใช้สำหรับเปลี่ยนขนาดและสีพื้นหลังของพล็อต
คุณยังสามารถเปลี่ยนโหมดโฮเวอร์ ระยะห่างระหว่างแท่งกราฟ และอื่นๆ ได้อีกด้วย ฉันคิดว่ามันเพียงพอแล้วที่จะแบ่งปันรหัสเท่านั้น เนื่องจากการอธิบายแต่ละรหัสที่นี่แยกกันอาจทำให้เราย้ายออกจากหัวข้อหลัก
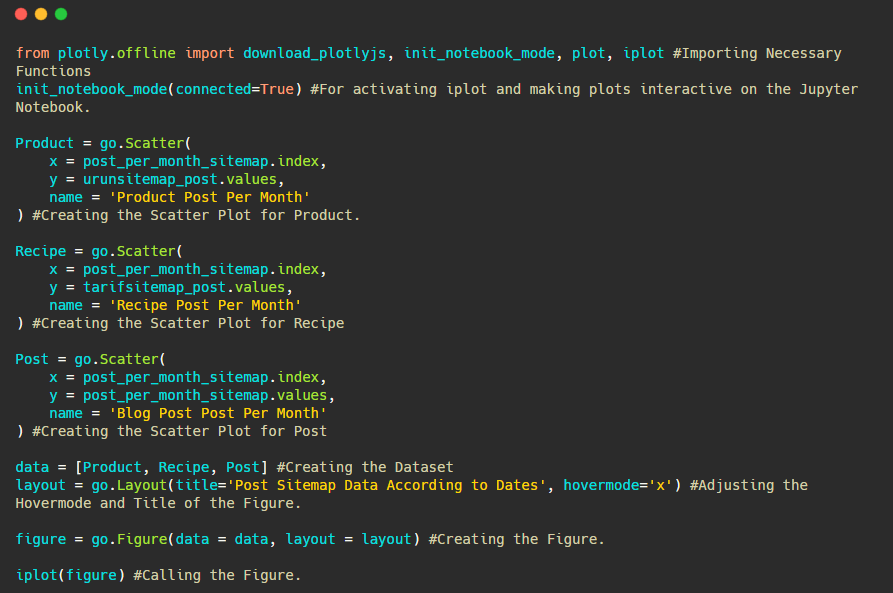
นอกจากนี้เรายังสามารถเปรียบเทียบแนวโน้มการเผยแพร่เนื้อหาของคู่แข่งตามหมวดหมู่ดังต่อไปนี้:
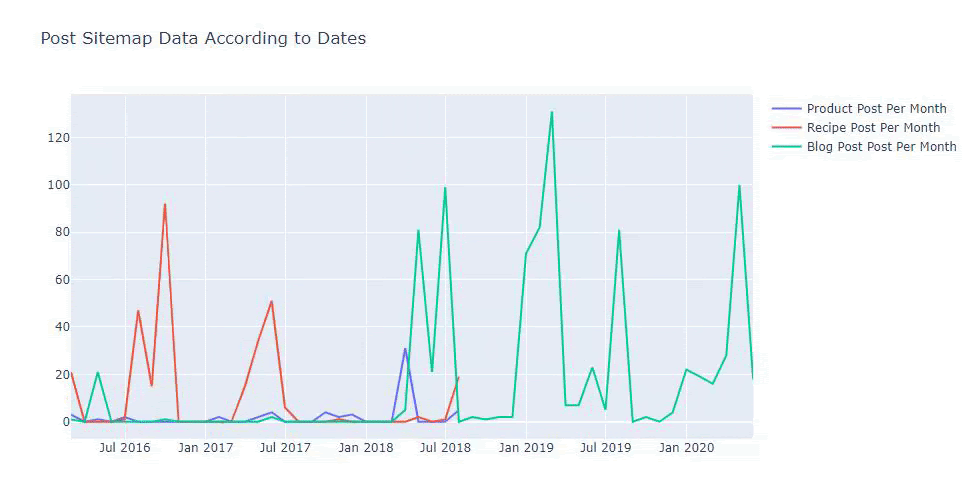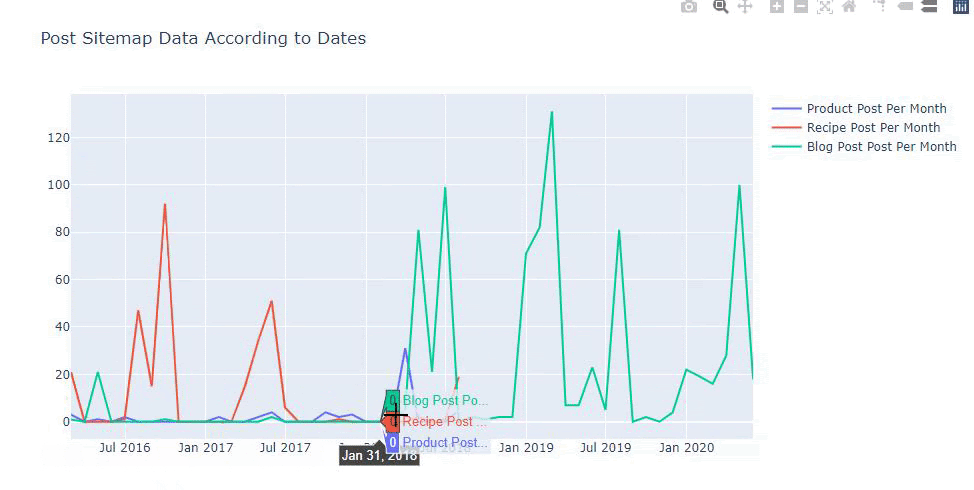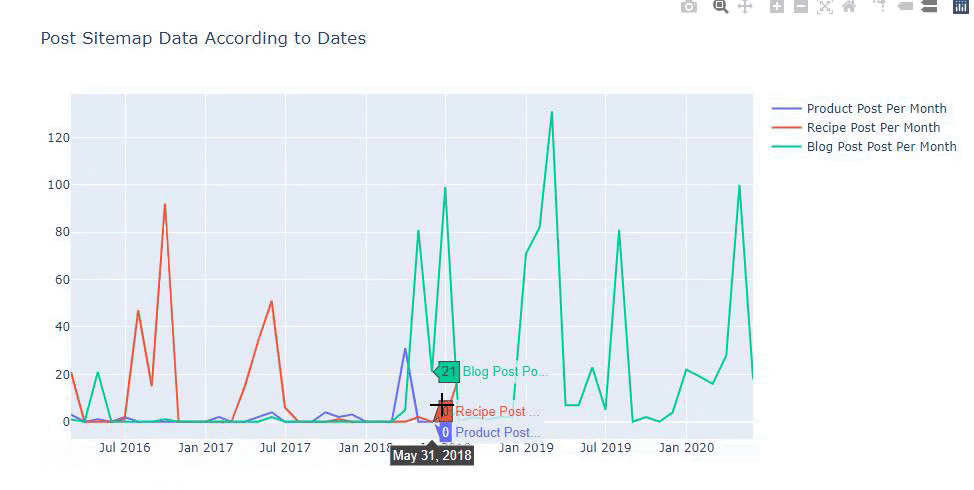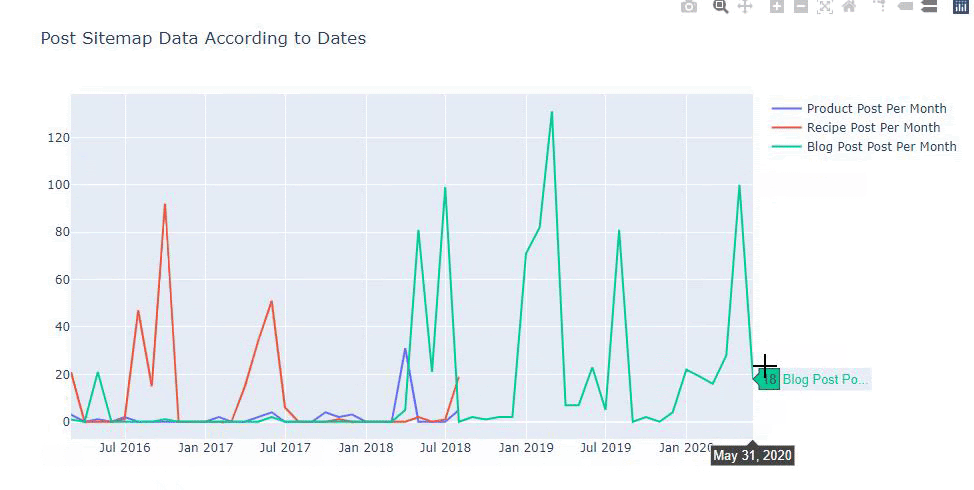
แผนภูมินี้สร้างขึ้นด้วยวิธีที่สอง เนื่องจากคุณอาจเห็นว่าไม่มีความแตกต่าง แต่วิธีหนึ่งค่อนข้างง่าย
ในการสร้างแผนภูมิความถี่และแนวโน้มของการเผยแพร่เนื้อหาจากแผนผังไซต์ที่แยกจากกันสามแผนผัง เราต้องวางแผนผังไซต์ซึ่งมีช่วงที่ยาวที่สุดบนแกน X ดังนั้น เราสามารถเปรียบเทียบความถี่ที่เว็บไซต์ที่เรากำลังตรวจสอบเผยแพร่เนื้อหาแต่ละประเภทที่แตกต่างกันสำหรับจุดประสงค์ในการค้นหาที่แตกต่างกัน
เมื่อคุณตรวจสอบรหัสที่เกี่ยวข้องด้านล่าง คุณจะเห็นว่ารหัสดังกล่าวไม่แตกต่างจากรหัสด้านบนมากนัก
สำหรับการสร้างพล็อตกระจายที่มีแกน Y หลายแกน คุณสามารถใช้โค้ดด้านล่างนี้
มีวิธีการอื่นๆ เช่น การรวมแผนผังไซต์ที่แตกต่างกัน และการใช้ for loop สำหรับคอลัมน์เพื่อใช้แกน Y หลายอันในแผนภาพแบบกระจาย แต่สำหรับไซต์ขนาดเล็กดังกล่าว เราไม่ต้องการสิ่งนั้น โดยส่วนใหญ่ การใช้วิธีนี้กับเว็บไซต์ที่มีแผนผังเว็บไซต์หลายร้อยรายการจะมีเหตุผลมากกว่า
นอกจากนี้ เนื่องจากเว็บไซต์มีขนาดเล็ก ภาพอาจดูตื้น แต่คุณจะเห็นในภายหลังในบทความบนเว็บไซต์ที่มี URL นับล้านๆ รายการ กราฟิกดังกล่าวเป็นวิธีที่ดีในการเปรียบเทียบเว็บไซต์ต่างๆ รวมทั้งเปรียบเทียบหมวดหมู่ต่างๆ ของ เว็บไซต์เดียวกัน
การตรวจสอบและการแสดงภาพหมวดหมู่เนื้อหา ความตั้งใจและแนวโน้มการเผยแพร่ด้วยแผนผังเว็บไซต์และ Python
ในส่วนนี้ เราจะตรวจสอบว่าพวกเขาเขียนเนื้อหาจำนวนมากในโดเมนความรู้เฉพาะเพื่อทำการตลาดผลิตภัณฑ์จำนวนเล็กน้อย ซึ่งเราได้กล่าวไว้ในตอนต้นของบทความ ด้วยเหตุนี้ เราจึงอาจทราบได้ว่าพวกเขามีเนื้อหาที่เป็นพันธมิตรทางธุรกิจกับแบรนด์อื่นๆ หรือไม่
เพื่อแสดงสิ่งอื่นๆ ที่สามารถพบได้ในแผนผังเว็บไซต์ เราจะทำการขุดต่อไปอีกเล็กน้อย นอกจากนี้เรายังสามารถรับข้อมูลบางส่วนจากส่วน 'loc' ของแผนผังเว็บไซต์ เช่น อื่นๆ
ไม่มีการแบ่งหมวดหมู่ใน URL ของ Ilkadimlarim หากเว็บไซต์มีการแบ่งหมวดหมู่ใน URL เราสามารถเรียนรู้เพิ่มเติมเกี่ยวกับการกระจายเนื้อหาได้ หากไม่เป็นเช่นนั้น เราสามารถเข้าถึงข้อมูลเดียวกันได้โดยการเขียนโค้ดเพิ่มเติม แต่มีความแน่นอนน้อยกว่าเท่านั้น
ณ จุดนี้ คุณสามารถจินตนาการได้ว่าการแยกย่อย URL ที่มีต้นทุนน้อยกว่าทำให้เครื่องมือค้นหาที่รวบรวมข้อมูลไซต์หลายพันล้านไซต์เข้าใจเว็บไซต์ของคุณมากน้อยเพียงใด
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
เบ็ค: ที่รัก
ฮามิล ตั้งท้อง
Haftalik: รายสัปดาห์หรือ "สัปดาห์ที่ตั้งครรภ์"
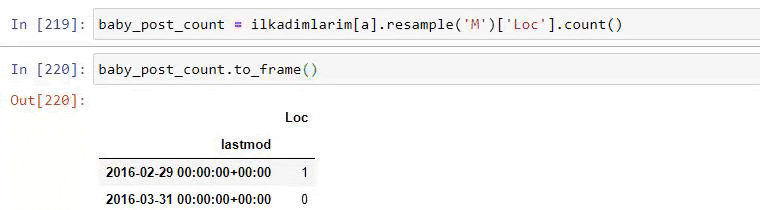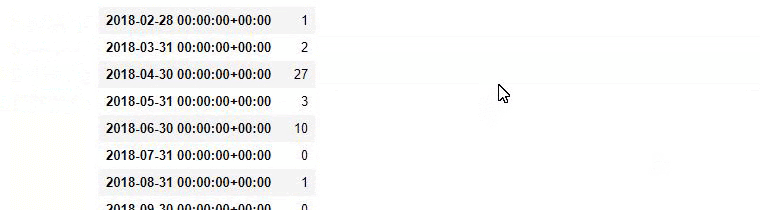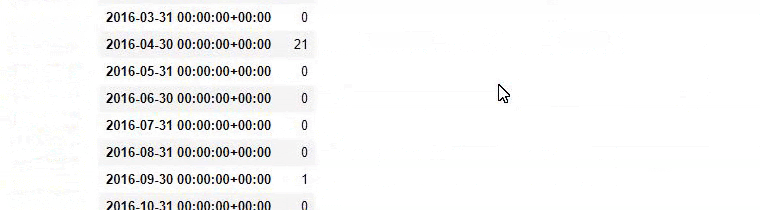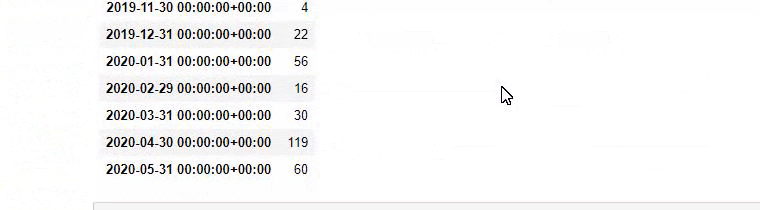
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
เมธอด str() ที่นี่อีกครั้งทำให้เราสามารถตั้งค่าคอลัมน์ที่เราเลือกการดำเนินการบางอย่างได้
ด้วยเมธอด contain () เราจะกำหนดข้อมูลเพื่อตรวจสอบว่าข้อมูลนั้นรวมอยู่ในข้อมูลที่แปลงเป็นสตริงหรือไม่
ที่นี่ “|” ระหว่างคำหมายถึง “หรือ”
จากนั้นเรากำหนดข้อมูลที่เรากรองให้กับตัวแปรและใช้วิธี resample() ที่เราใช้ก่อนหน้านี้
ในทางกลับกัน วิธีการ นับ จะวัดว่าข้อมูลใดถูกใช้และจำนวนครั้ง
ผลลัพธ์ที่ได้รับจาก count() จะถูกปิดด้วย to_frame() อีกครั้ง
นอกจากนี้ str.contains() รับค่า Regex เป็นค่าเริ่มต้น ซึ่งหมายความว่าคุณสามารถสร้างเงื่อนไขการกรองที่ซับซ้อนมากขึ้นโดยใช้โค้ดน้อยลง
กล่าวอีกนัยหนึ่ง ณ จุดนี้เรากำหนด URL ที่มีคำว่า "baby", "weekly", "pregnant" ให้กับตัวแปรใน ilkadimlarim จากนั้นเราใส่วันที่เผยแพร่ของ URL ในเงื่อนไขที่เหมาะสมสำหรับตัวกรองนี้ สร้างขึ้นในกรอบ
จากนั้นเราทำเช่นเดียวกันสำหรับ URL ที่มีคำว่า 'aptamil' Aptamil เป็นชื่อของผลิตภัณฑ์โภชนาการสำหรับทารกที่ Ilkadimlarim นำเสนอ ดังนั้นเราจึงสามารถให้ความสนใจกับความหนาแน่นของการออกอากาศของเนื้อหาข้อมูลและเชิงพาณิชย์
และคุณอาจเห็นกลุ่มเนื้อหาสองกลุ่มที่เผยแพร่กำหนดการในช่วงหลายปีที่ผ่านมาสำหรับจุดประสงค์ในการค้นหาที่แตกต่างกัน โดยมีข้อมูลที่แน่นอนและแม่นยำยิ่งขึ้นจาก URL
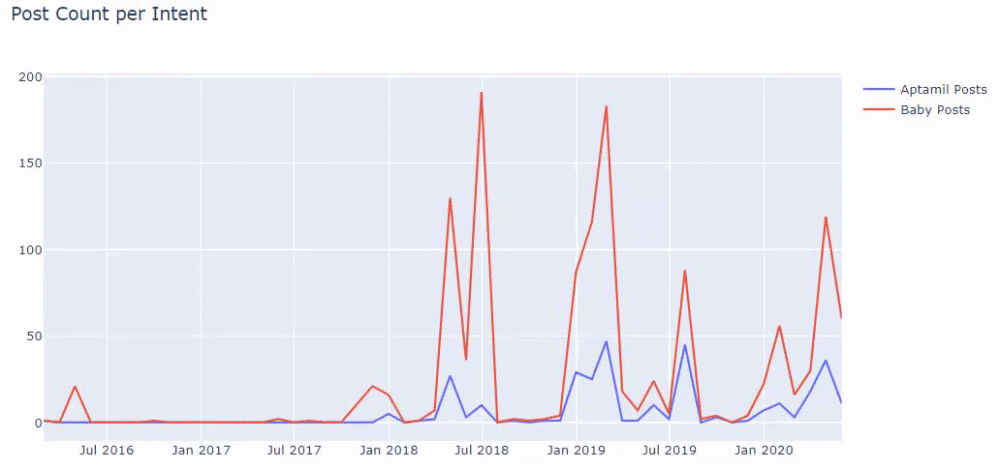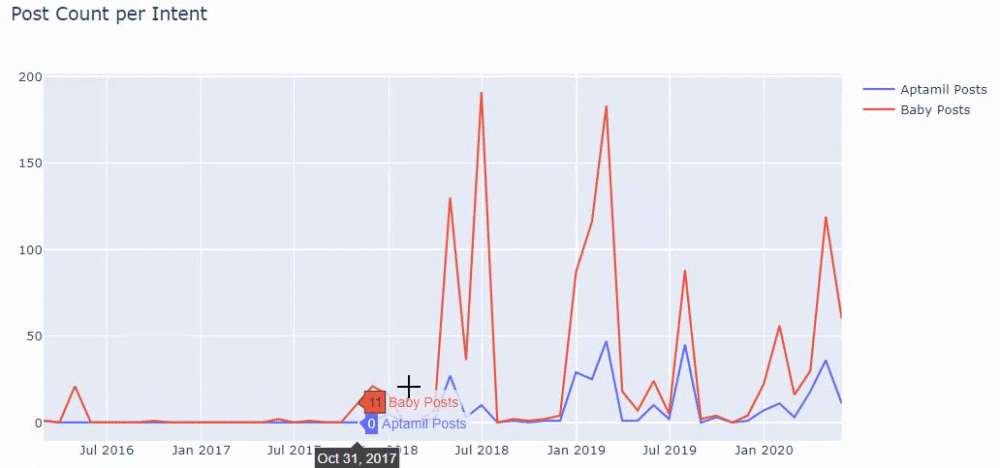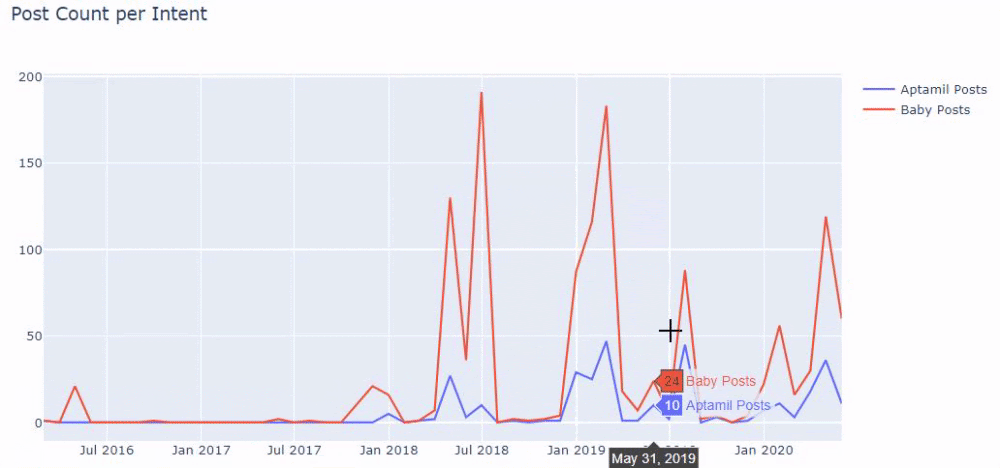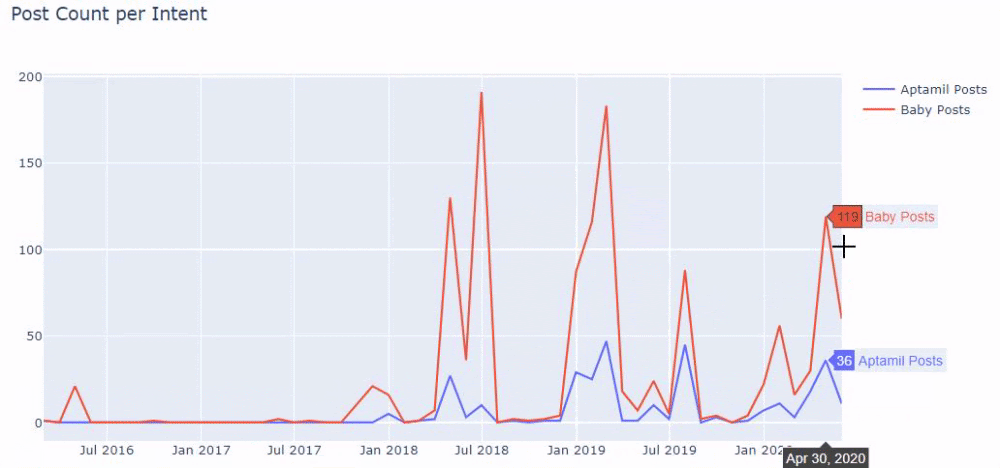
ไม่มีการแชร์รหัสสำหรับสร้างแผนภูมินี้เนื่องจากเป็นรหัสเดียวกับที่ใช้สำหรับแผนภูมิก่อนหน้า
ด้วยความช่วยเหลือของโอเปอเรเตอร์การค้นหาบน Google ฉันจึงได้ผลลัพธ์ 38 รายการเมื่อฉันต้องการหน้าเว็บที่มีการใช้คำว่า Aptamil ใน anchor text ที่ Ilkadimlarim.com หน้าเหล่านี้จำนวนมากให้ข้อมูลและเชื่อมโยงเนื้อหาเชิงพาณิชย์
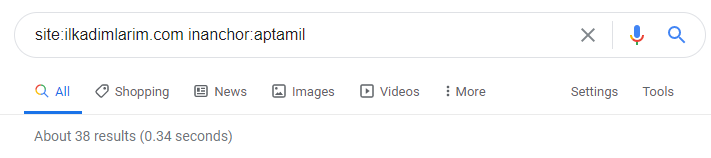
วิทยานิพนธ์ของเราได้รับการพิสูจน์แล้ว
“My First Steps” ใช้เนื้อหาที่ให้ข้อมูลนับร้อยเกี่ยวกับการเป็นแม่ การดูแลทารก และการตั้งครรภ์เพื่อเข้าถึงกลุ่มเป้าหมาย “Ilkadimlarim” เชื่อมโยงหน้าที่มีผลิตภัณฑ์ Aptamil จากเนื้อหานี้และนำผู้ใช้ไปที่นั่น

การทำโปรไฟล์เนื้อหาเปรียบเทียบและวิเคราะห์กลยุทธ์เนื้อหาผ่านแผนผังเว็บไซต์ด้วย Python
ถ้าคุณต้องการ ให้ทำแบบเดียวกันกับบริษัทจากอุตสาหกรรมเดียวกัน และทำการเปรียบเทียบเพื่อทำความเข้าใจลักษณะทั่วไปของอุตสาหกรรมนี้และความแตกต่างของกลยุทธ์ระหว่างสองแบรนด์นี้
ตัวอย่างที่สอง ฉันเลือก Prima.com.tr ซึ่งก็คือ Pampers แต่ใช้ชื่อแบรนด์ Prima ในตุรกี เนื่องจาก Prima มีแผนผังเว็บไซต์เดียว เราจึงไม่สามารถจำแนกตามแผนผังเว็บไซต์ได้ แต่อย่างน้อยก็มีตัวแบ่ง URL ที่แตกต่างกัน เราจึงโชคดีมาก: เราจะต้องเขียนโค้ดให้น้อยลง
ลองนึกภาพว่าอัลกอริธึมที่ Google ต้องใช้ให้คุณมีราคาแพงกว่ามากเพียงใดเมื่อคุณสร้างไซต์ที่เข้าใจยาก! วิธีนี้สามารถช่วยทำให้การคำนวณต้นทุนการรวบรวมข้อมูลมีความชัดเจนมากขึ้นในใจของคุณ แม้จะเกี่ยวข้องกับโครงสร้าง URL ก็ตาม
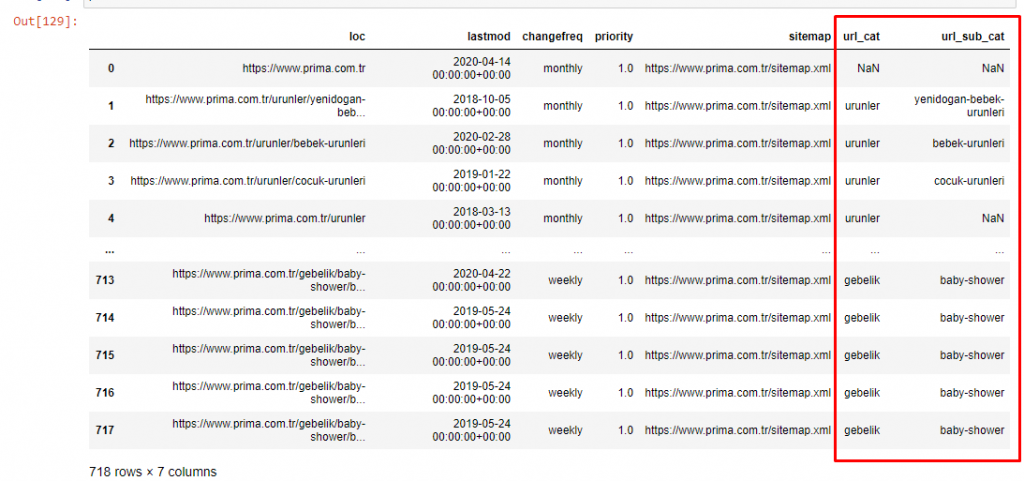
เพื่อไม่ให้มีปริมาณบทความเพิ่มขึ้น เราจะไม่วางรหัสของกระบวนการที่คล้ายกับที่เราได้ทำไปแล้ว
ตอนนี้ เราสามารถตรวจสอบการแจกแจงหมวดหมู่เนื้อหาตามหมวดหมู่ URL และหมวดหมู่ย่อยของ URL เราเห็นว่าพวกเขามีหน้าเว็บของบริษัทมากเกินไป หน้าเว็บของบริษัทเหล่านี้อยู่ในส่วน “prima-hakkinda” (“เกี่ยวกับ Prima”) แต่เมื่อฉันตรวจสอบพวกเขาด้วย Python ฉันเห็นว่าพวกเขาได้รวมผลิตภัณฑ์และหน้าเว็บขององค์กรไว้ในหมวดหมู่เดียว คุณสามารถดูการกระจายเนื้อหาด้านล่าง:

เราสามารถทำเช่นเดียวกันสำหรับหมวดหมู่ย่อยต่อไปนี้
เป็นที่น่าสนใจที่จะสังเกตว่า Prima ใช้คำว่า “gebelik” (การตั้งครรภ์ในภาษาตุรกี) ซึ่งเป็นอีกรูปแบบหนึ่งของคำว่า “hamilelik” (การตั้งครรภ์ในภาษาอาหรับ) และทั้งสองหมายถึงระยะเวลาการตั้งครรภ์

ตอนนี้เราเห็นการจัดหมวดหมู่เนื้อหาที่ลึกซึ้งยิ่งขึ้น 9.2% ของเนื้อหาเกี่ยวกับการตั้งครรภ์ที่มีสุขภาพดี 7.3% เกี่ยวกับกระบวนการเจริญเติบโตของทารก 8.3% ของเนื้อหาเกี่ยวกับกิจกรรมที่ทารกสามารถทำได้ 0.7% คือลำดับการนอนหลับของทารก มีแม้กระทั่งหัวข้อต่างๆ เช่น การงอกของฟัน 3.9% ความปลอดภัยของทารก 1.9% และการเปิดเผยการตั้งครรภ์กับครอบครัว 1.4% อย่างที่คุณเห็น คุณสามารถทำความรู้จักกับอุตสาหกรรมที่มีเพียงแค่ URL และเปอร์เซ็นต์การกระจาย
นี่ไม่ใช่การจัดหมวดหมู่ที่สมบูรณ์แบบ แต่อย่างน้อย เราก็สามารถเห็นแนวความคิดของคู่แข่งและแนวโน้มการตลาดเนื้อหา และเนื้อหาของเว็บไซต์ตามหมวดหมู่ ตอนนี้ มาตรวจสอบความถี่ในการเผยแพร่เนื้อหาตามเดือนกัน
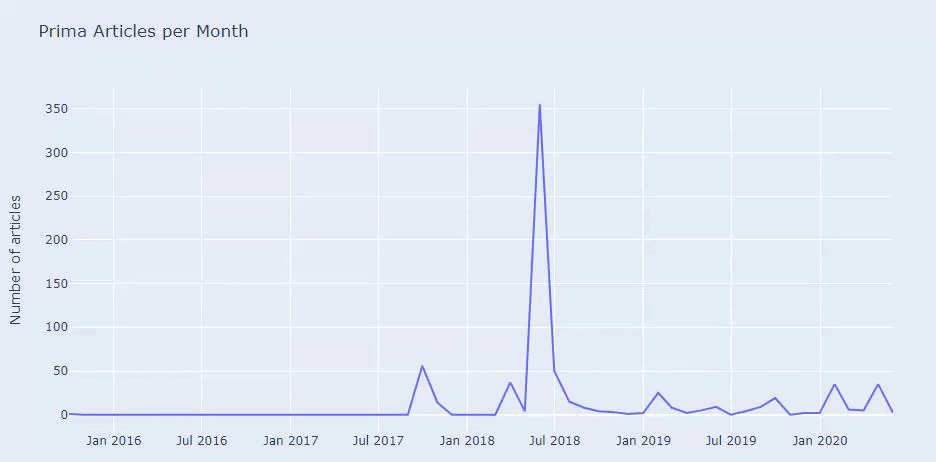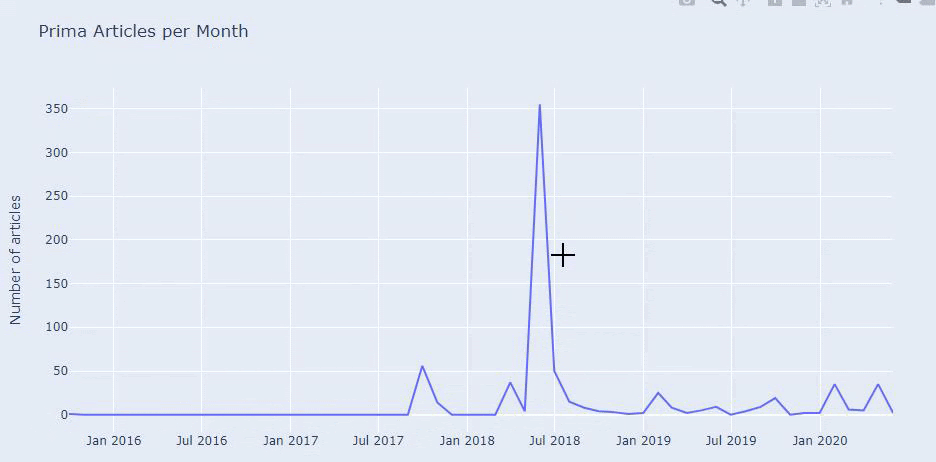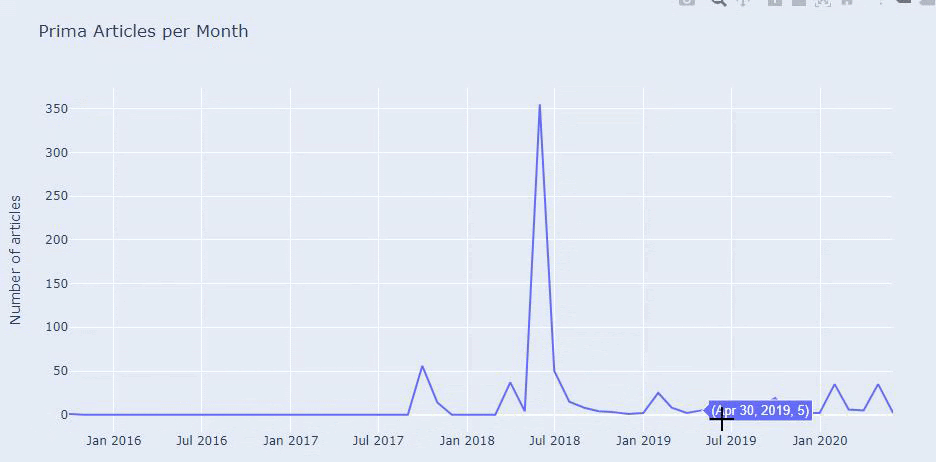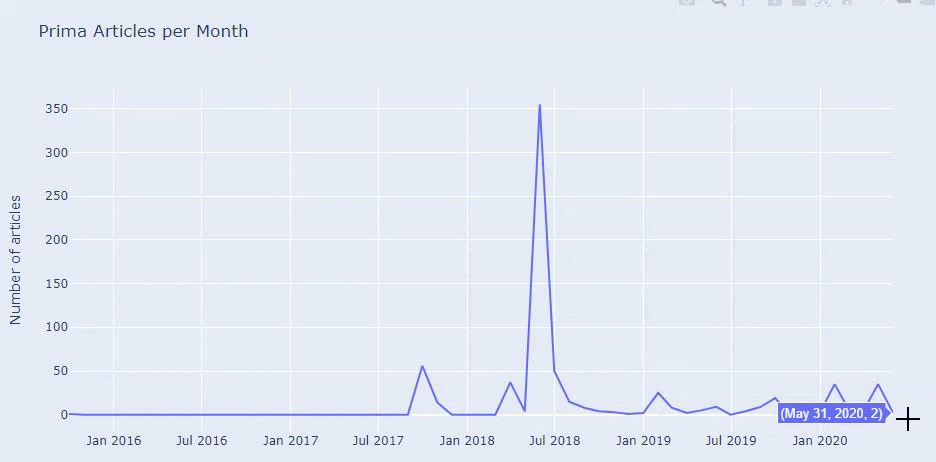
เราพบว่าพวกเขาได้ตีพิมพ์บทความ 355 ในเดือนกรกฎาคม 2018 และตาม Sitemap เนื้อหาของพวกเขาจะไม่ถูกรีเฟรชตั้งแต่นั้นมา นอกจากนี้เรายังสามารถเปรียบเทียบแนวโน้มการเผยแพร่เนื้อหาตามหมวดหมู่ในช่วงหลายปีที่ผ่านมา อย่างที่คุณเห็น เนื้อหาส่วนใหญ่อยู่ในสี่หมวดหมู่ที่แตกต่างกัน และส่วนใหญ่เผยแพร่ในเดือนเดียวกัน
ก่อนดำเนินการต่อ ฉันต้องบอกว่าข้อมูลแผนผังเว็บไซต์อาจไม่ถูกต้องเสมอไป ตัวอย่างเช่น ข้อมูล Lastmod อาจมีการอัปเดตสำหรับ URL ทั้งหมด เนื่องจากได้ต่ออายุแผนผังเว็บไซต์ทั้งหมดในวันที่นี้ เพื่อแก้ไขปัญหานี้ เราสามารถตรวจสอบว่าพวกเขาไม่ได้เปลี่ยนเนื้อหาตั้งแต่นั้นมาโดยใช้ Wayback Machine
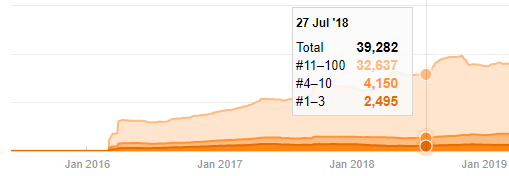
แม้ว่าจะดูน่าสงสัย แต่ข้อมูลนี้สามารถเป็นจริงได้ หลายบริษัทในตุรกีมีแนวโน้มที่จะออกคำสั่งซื้อจำนวนมากและเผยแพร่เนื้อหาในช่วงก่อนหน้านี้ เมื่อฉันตรวจสอบจำนวนคำหลัก ฉันเห็นการเพิ่มขึ้นในช่วงเวลานี้ ดังนั้น หากคุณกำลังดำเนินการเปรียบเทียบโปรไฟล์เนื้อหาและการวิเคราะห์กลยุทธ์ คุณควรคำนึงถึงปัญหาเหล่านี้ด้วย
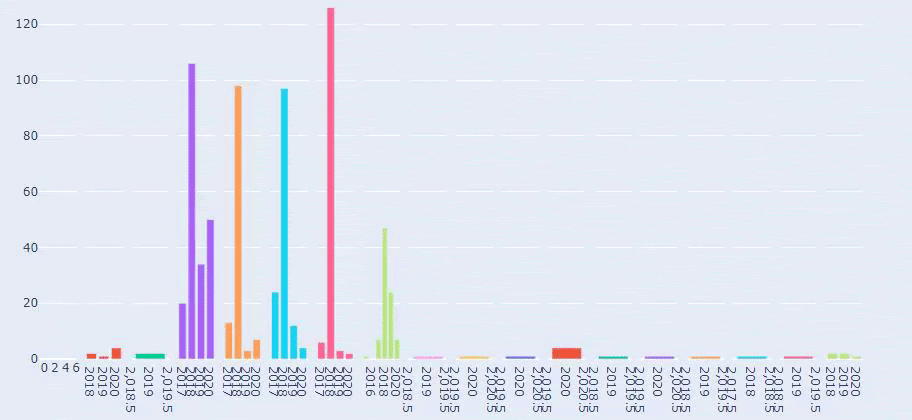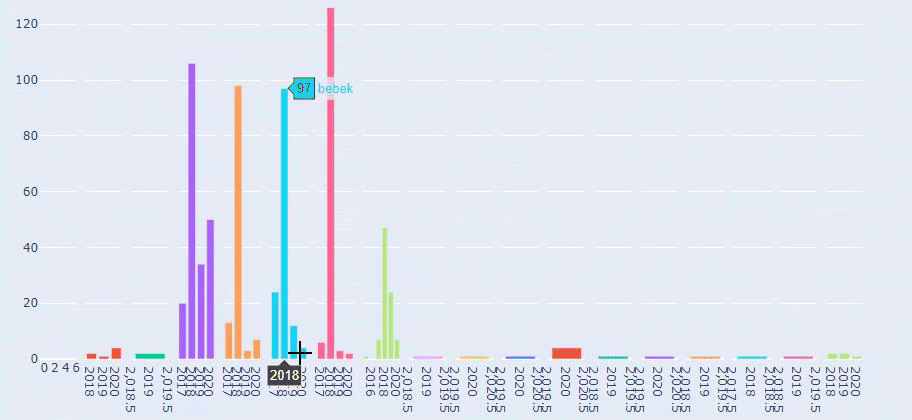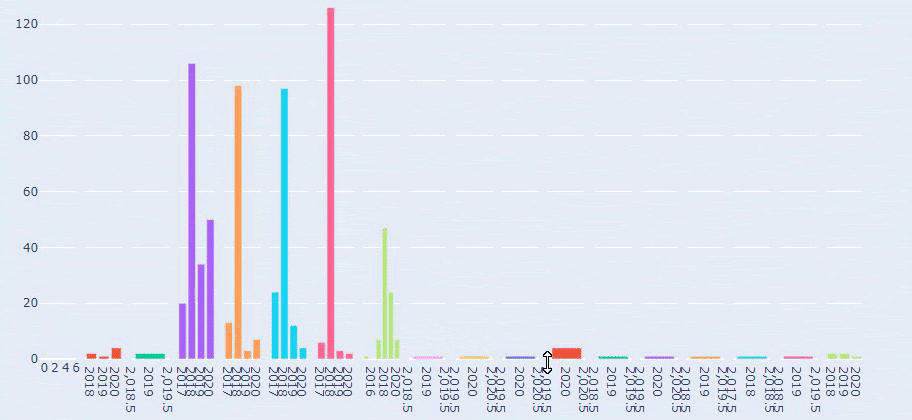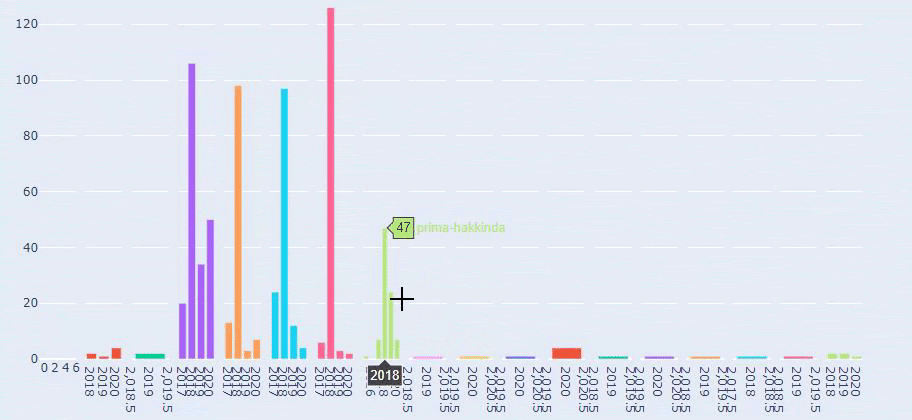
นี่คือการเปรียบเทียบระหว่างแนวโน้มการเผยแพร่เนื้อหาของทุกหมวดหมู่ตลอดหลายปีที่ผ่านมาสำหรับ Prima.com.tr
ตอนนี้ เราสามารถเปรียบเทียบหมวดหมู่เนื้อหาของเว็บไซต์สองประเภทและแนวโน้มการเผยแพร่ได้
เมื่อเราดูความถี่ของการเผยแพร่บทความเกี่ยวกับการเติบโตของทารก การตั้งครรภ์ และการเป็นแม่ของพรีมา เราเห็นความคล้ายคลึงกันกับอิลคาดิมลาริม:
- บทความส่วนใหญ่ตีพิมพ์ในช่วงเวลาหนึ่ง
- พวกเขาไม่ได้รับการอัพเดตเป็นเวลานาน
- จำนวนผลิตภัณฑ์และหน้าต่ำมากเมื่อเทียบกับจำนวนหน้าเนื้อหาที่ให้ข้อมูล
- เมื่อเร็ว ๆ นี้ พวกเขาเพิ่งเพิ่มผลิตภัณฑ์ใหม่ลงในไซต์ของตน
เราสามารถพิจารณาคุณลักษณะทั้งสี่นี้เป็นกรอบความคิดเริ่มต้นของอุตสาหกรรม และเราอาจใช้จุดอ่อนเหล่านี้เพื่อสนับสนุนแคมเปญของเรา ท้ายที่สุดแล้วคุณภาพต้องการความสดใหม่ (ตามที่ระบุไว้โดย Amit Singhal, Google Fellow)
ณ จุดนี้ เรายังเห็นว่าอุตสาหกรรมนี้ไม่คุ้นเคยกับพฤติกรรมของ Googlebot แทนที่จะอัปโหลดเนื้อหา 250 ชิ้นในหนึ่งวันแล้วไม่ทำการเปลี่ยนแปลงใดๆ เป็นเวลาหนึ่งปี เป็นการดีกว่าที่จะเพิ่มเนื้อหาใหม่เป็นระยะๆ และอัปเดตเนื้อหาเก่าเป็นประจำ ดังนั้น คุณสามารถรักษาคุณภาพของเนื้อหาได้ Googlebot สามารถเข้าใจไซต์ของคุณได้ง่ายขึ้น และค่าความถี่ของความต้องการรวบรวมข้อมูลของคุณจะสูงกว่าคู่แข่งของคุณ
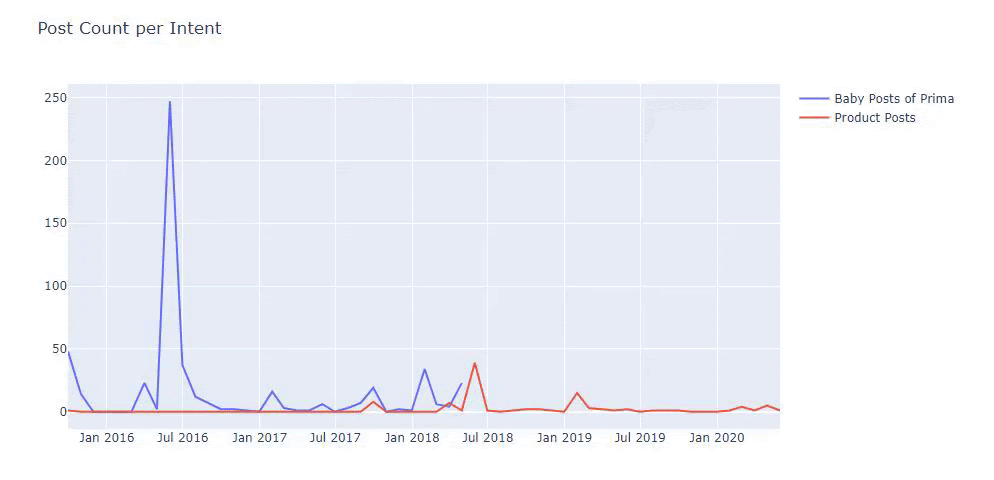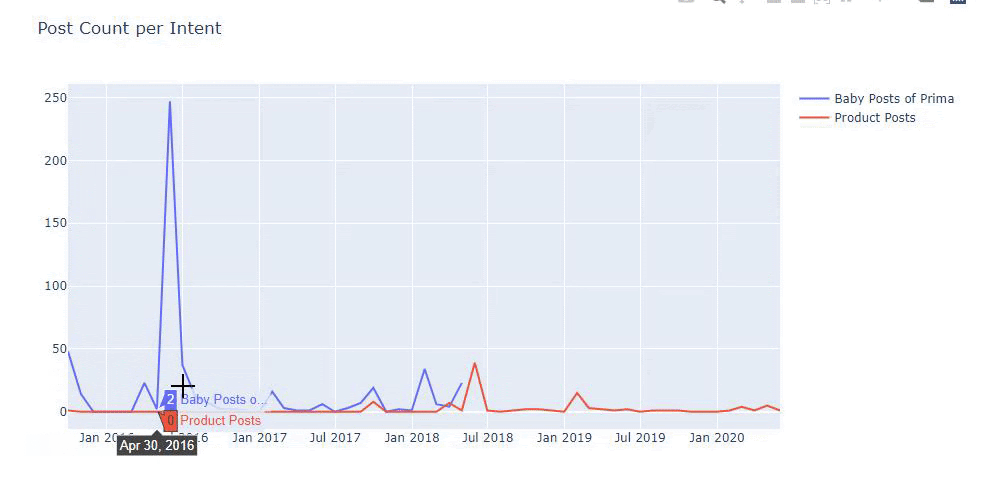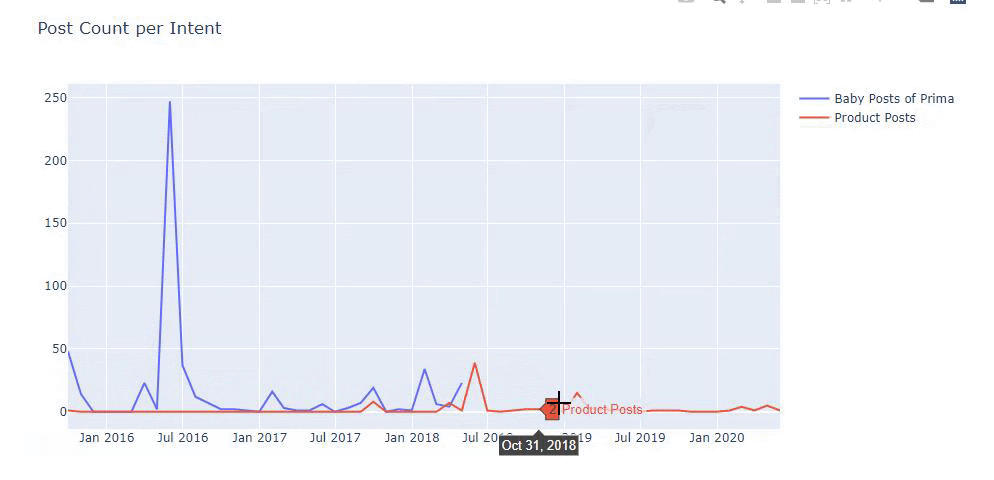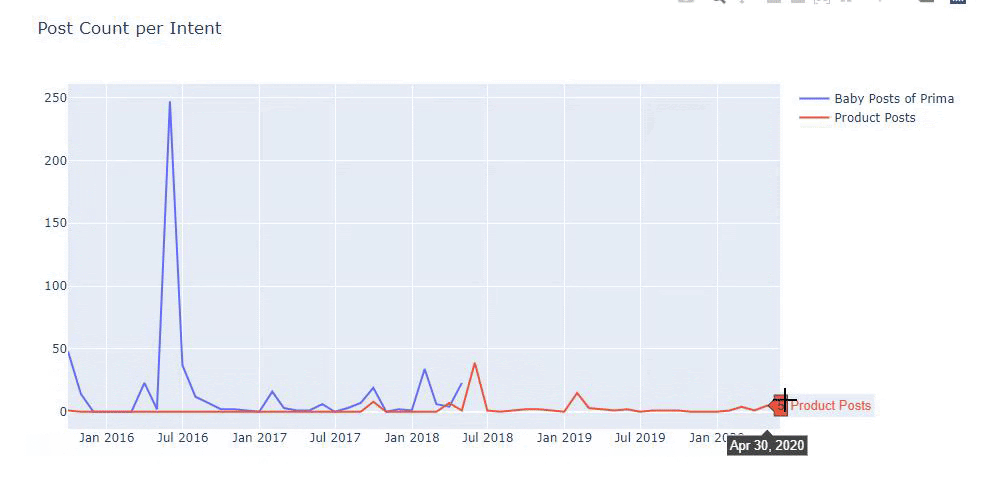
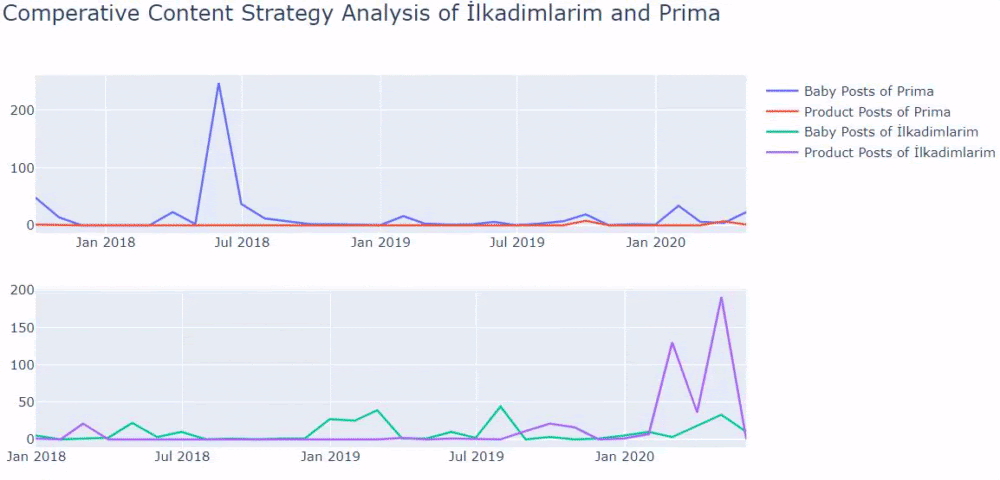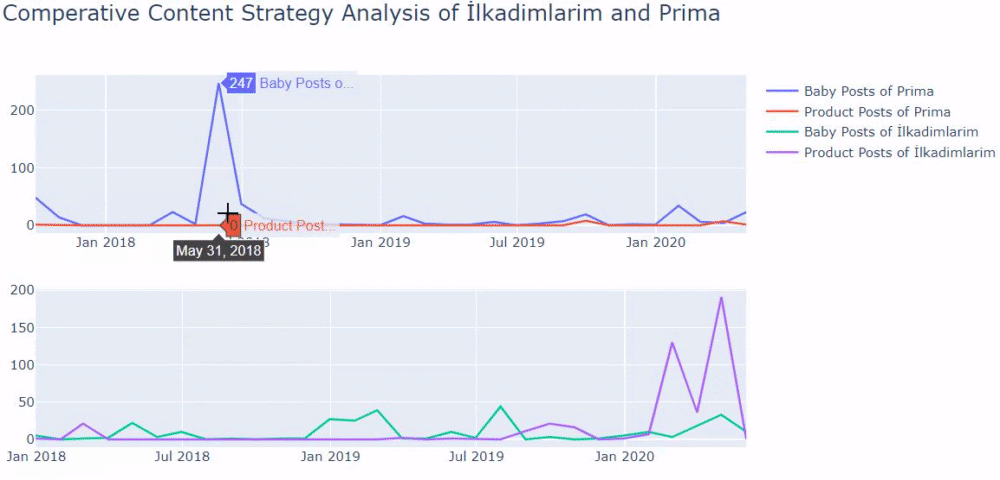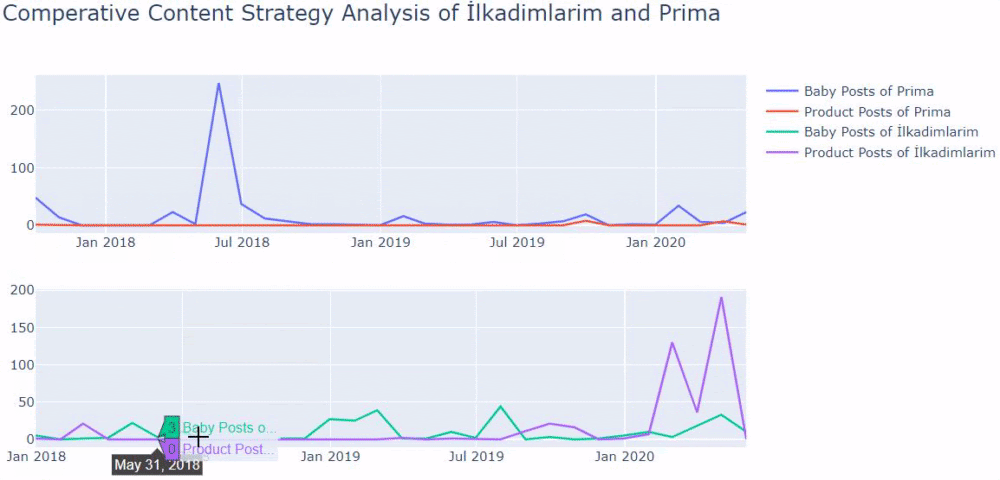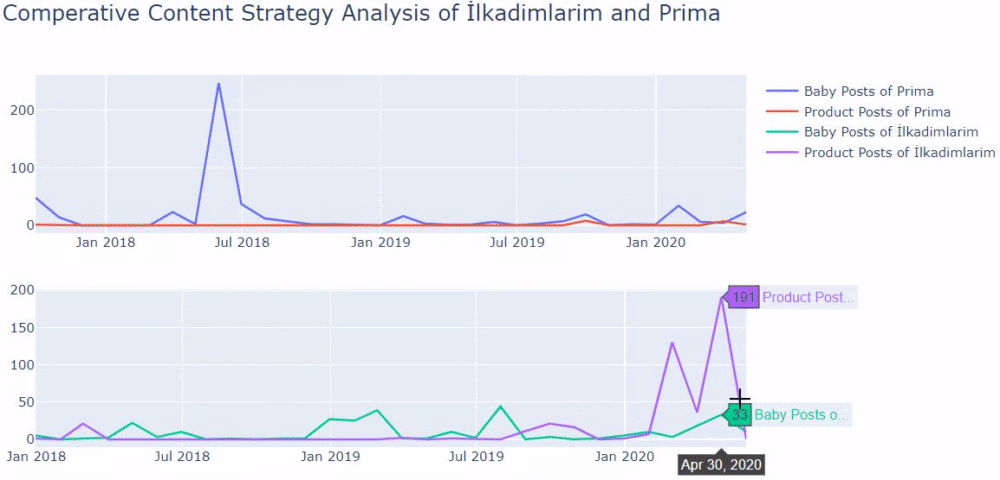
ฉันใช้วิธีก่อนหน้านี้เพื่อแยกความแตกต่างระหว่างหน้าผลิตภัณฑ์และเนื้อหาที่ให้ข้อมูล และสร้างโปรไฟล์ของคำที่ใช้บ่อยที่สุดใน URL Baby Posts ที่นี่หมายความว่าเนื้อหาเหล่านี้เป็นเนื้อหาที่ให้ข้อมูล
อย่างที่คุณเห็น พวกเขาได้เพิ่มเนื้อหา 247 รายการในหนึ่งวัน นอกจากนี้ พวกเขาไม่ได้เผยแพร่หรือรีเฟรชเนื้อหาที่ให้ข้อมูลเป็นเวลากว่าหนึ่งปี และพวกเขาเพียงแค่เพิ่มหน้าผลิตภัณฑ์ใหม่บางหน้าเป็นครั้งคราว
ตอนนี้ เรามาเปรียบเทียบแนวโน้มการตีพิมพ์ในรูปเดียวแต่มีสองแปลงที่แตกต่างกัน ฉันได้ใช้รหัสด้านล่างเพื่อสร้างรูปนี้:
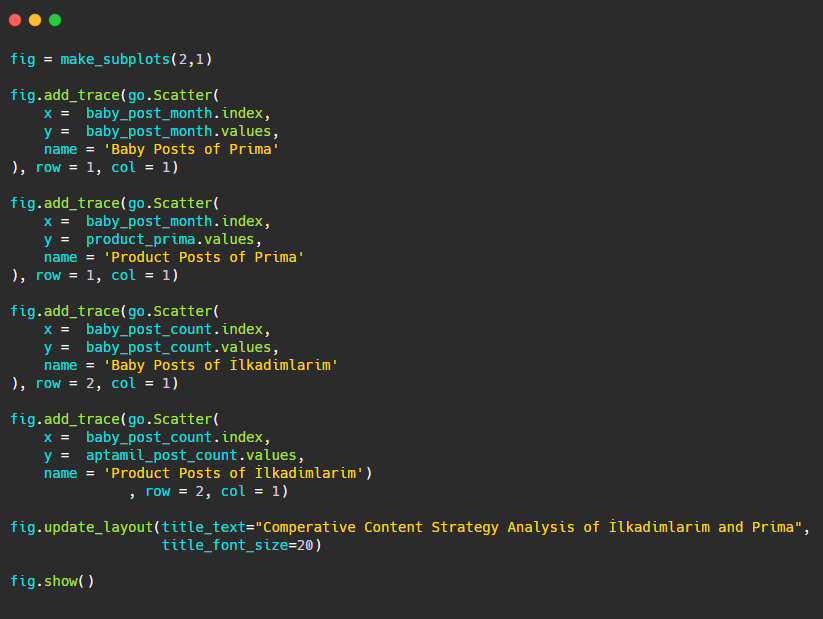
เนื่องจากกราฟิกนี้แตกต่างจากก่อนหน้านี้ ฉันต้องการแสดงรหัสให้คุณดู ที่นี่ สองแปลงแยกกันอยู่ในร่างเดียวกัน สำหรับสิ่งนี้ เมธอด make_subplots ถูกเรียกด้วยคำสั่งจาก plotly.subplots import make_subplots
มันถูกสร้างขึ้นเป็นรูปสองแถวและหนึ่งคอลัมน์ด้วย make_subplots (2,1)
ดังนั้น col และ row จะถูกเขียนที่ส่วนท้ายของการติดตามและตำแหน่งจะถูกระบุ เป็นระบบที่ใครก็ตามที่คุ้นเคยกับระบบกริดใน CSS สามารถจดจำได้ง่าย
หากคุณมีลูกค้าในภาคส่วนเดียวกัน คุณสามารถใช้ข้อมูลนี้เพื่อสร้างกลยุทธ์เนื้อหา เพื่อดูจุดอ่อนของคู่แข่งและเครือข่ายหน้า Landing Page ของพวกเขาผ่าน SERP นอกจากนี้ คุณสามารถทำความเข้าใจว่าควรเผยแพร่เนื้อหาจำนวนเท่าใดในโดเมนความรู้เดียวกันหรือเพื่อจุดประสงค์ของผู้ใช้เดียวกัน
ก่อนที่จะสรุปสิ่งที่เราเรียนรู้ได้จากแผนผังเว็บไซต์ซึ่งเป็นส่วนหนึ่งของการวิเคราะห์กลยุทธ์เนื้อหา เราสามารถตรวจสอบเว็บไซต์สุดท้ายที่มีจำนวน URL ที่สูงกว่ามากจากอุตสาหกรรมอื่น
การวิเคราะห์กลยุทธ์เนื้อหาของเว็บเอนทิตีข่าวเกี่ยวกับสกุลเงินด้วย Python และแผนผังเว็บไซต์
ในส่วนนี้เราจะใช้แผนภาพแผนที่ความร้อนของ Seaborn รวมถึงวิธีการจัดเฟรมและการแยกข้อมูลสำหรับนักเล่น

Elias Dabbas มี Kaggle Archive ที่น่าสนใจและมีประโยชน์มากในแง่ของ Data Science และ SEO ในเดือนนี้ เขาได้เปิดส่วนชุดข้อมูล Kaggle ใหม่สำหรับเว็บไซต์ข่าวของตุรกี ให้ฉันเขียนโค้ดที่จำเป็นและทำการวิเคราะห์กลยุทธ์เนื้อหาด้วย Advertools ผ่านแผนผังเว็บไซต์
ก่อนที่ฉันจะเริ่มใช้เทคนิคเหล่านี้ใน Kaggle ฉันต้องการแสดงตัวอย่างว่าจะเกิดอะไรขึ้นหากเราใช้เทคนิคเดียวกันกับเอนทิตีเว็บที่ใหญ่กว่าในบทความนี้
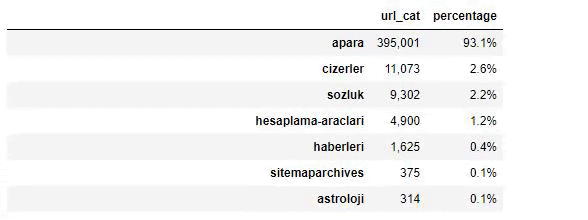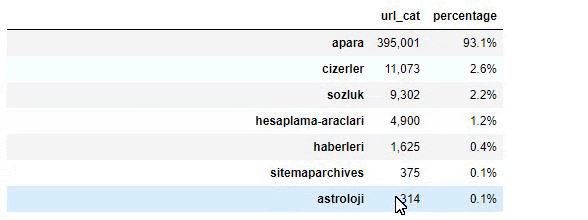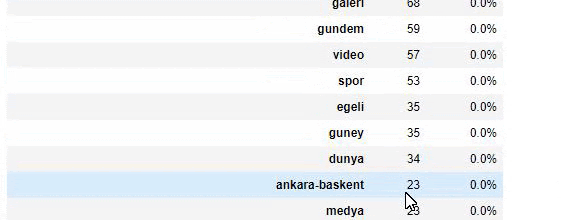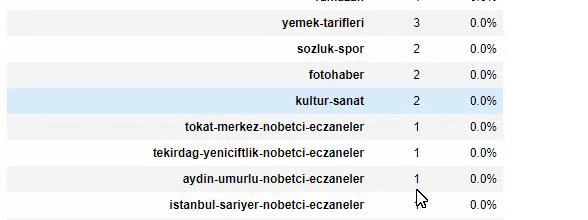
เมื่อเราวิเคราะห์เนื้อหาของหนังสือพิมพ์ซาบาห์ เราจะเห็นว่าส่วนสำคัญของเนื้อหา (81%) อยู่ในหมวดหมู่ที่เรียกว่า "อาปารา" นอกจากนี้ยังมีหมวดหมู่ใหญ่ ๆ สำหรับโหราศาสตร์ การคำนวณ พจนานุกรม สภาพอากาศ และข่าวโลก (Para แปลว่า เงิน ในภาษาตุรกี)
สำหรับหนังสือพิมพ์ซาบาห์ เราสามารถวิเคราะห์เนื้อหาด้วยแผนผังเว็บไซต์ที่เรารวบรวมไว้กับ Advertools เท่านั้น แต่เนื่องจากหนังสือพิมพ์ที่เป็นปัญหามีขนาดใหญ่มาก ฉันจึงไม่ชอบเพราะมีแผนผังเว็บไซต์จำนวนมากและเนื้อหาของแผนผังเว็บไซต์ต่างๆ ที่มี URL เดียวกัน หมวดหมู่.
ด้านล่างนี้ คุณสามารถดูแผนผังเว็บไซต์ส่วนเกินได้ด้วย Advertools
เราอาจเห็นว่ามีแผนผังเว็บไซต์ต่างกันสำหรับหมวดหมู่ URL เดียวกัน เช่น ทองคำ เครดิต สกุลเงิน แท็ก เวลาละหมาดและชั่วโมงทำงานของร้านขายยา ฯลฯ...
กล่าวโดยย่อ เราสามารถบรรลุรายละเอียดเหล่านี้โดยเน้นที่หมวดหมู่ย่อยของ URL แทนที่จะรวมแผนผังเว็บไซต์ต่างๆ เข้าด้วยกันโดยใช้ตัวแปร ดังนั้นฉันจึงรวมแผนผังไซต์ทั้งหมดด้วยวิธี sitemap_to_df() ของ Advertools เช่นเดียวกับตอนต้นของบทความ
เรายังสามารถใช้ชุดฟังก์ชันอื่นที่สร้างโดย Elias Dabbas เพื่อสร้างกรอบข้อมูลที่ดีขึ้น หากคุณตรวจสอบฟังก์ชัน dataset_utitilites คุณสามารถดูตัวอย่างได้ รหัสด้านล่างให้ผลรวมและเปอร์เซ็นต์ของ URL regex ที่ระบุพร้อมกับผลรวมสะสมโดยการจัดรูปแบบ
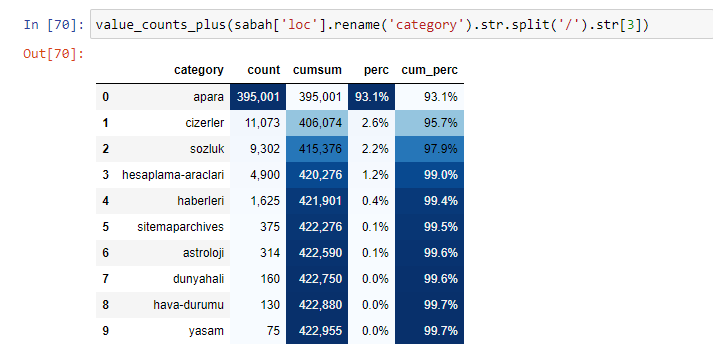
หากเราทำเช่นเดียวกันกับการแยกย่อย URL ของหนังสือพิมพ์ Sabah เราจะได้รับผลลัพธ์ดังต่อไปนี้
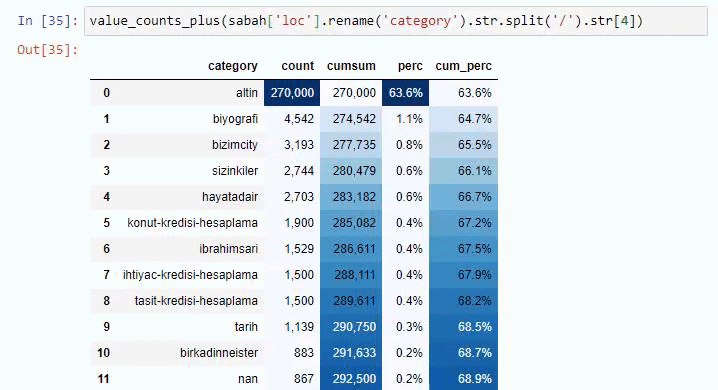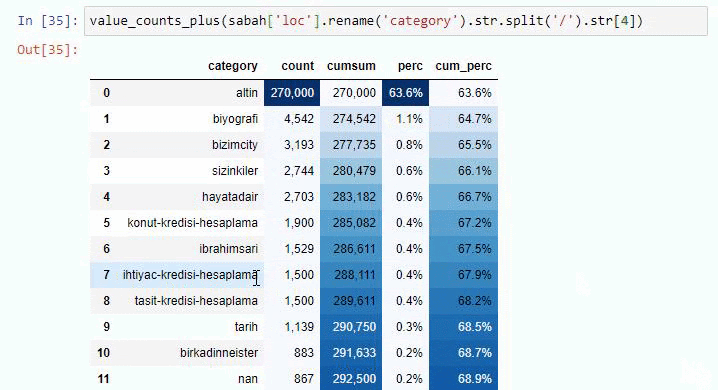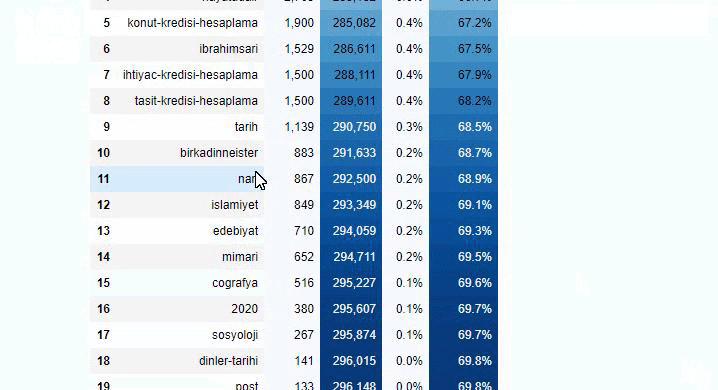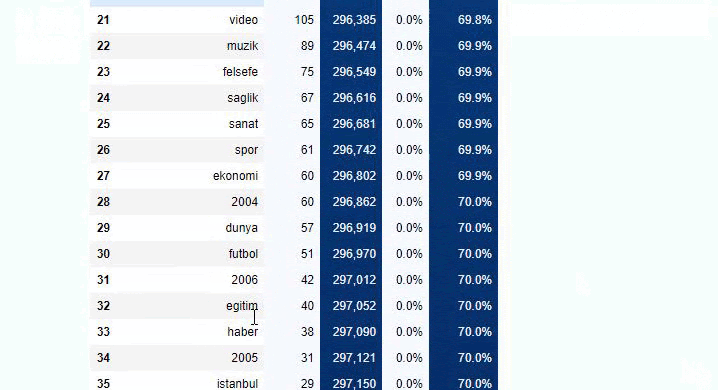
คุณสามารถเพิ่มจำนวนบรรทัดที่ฟังก์ชันดังกล่าวจะแสดงผลโดยเปลี่ยนบรรทัดด้านล่าง นอกจากนี้ หากคุณตรวจสอบเนื้อหาของฟังก์ชัน คุณจะเห็นว่ามันคล้ายกับที่เราเคยใช้มาก่อน
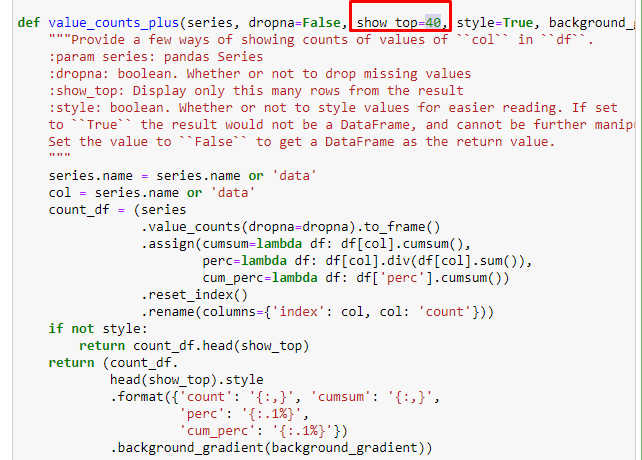
ในการแบ่งย่อย เราจะเห็นการแบ่งย่อยต่างๆ เช่น “ประวัติศาสตร์ศาสนา”, “ชีวประวัติ”, “ชื่อเมือง”, “ฟุตบอล”, “มหานคร (ล้อเลียน)”, “สินเชื่อที่อยู่อาศัย” รายละเอียดที่ใหญ่ที่สุดอยู่ในหมวด "ทอง"
หนังสือพิมพ์จะมี URL 295,000 รายการสำหรับราคาทองคำได้อย่างไร
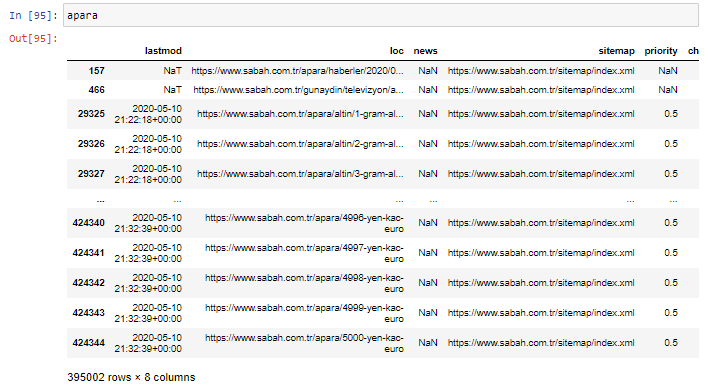
ก่อนอื่น ฉันโยน URL ทั้งหมดที่มี "apara" ในการแจกแจง URL แรกของหนังสือพิมพ์ Sabah ลงในตัวแปร
apara = sabah[sabah['loc'].str.contains('apara')] อะปารา
นี่คือผลลัพธ์:
นอกจากนี้เรายังสามารถกรองคอลัมน์ด้วยวิธีการ .filter() ได้:
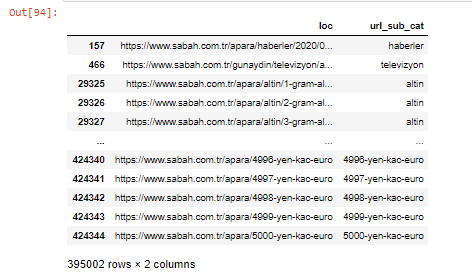
ตอนนี้ เราเห็นได้ที่ด้านล่างของ DataFrame ว่าทำไมหนังสือพิมพ์ Sabah ถึงมี Apara URL มากเกินไป เพราะพวกเขาได้เปิดหน้าเว็บที่แตกต่างกันสำหรับการคำนวณสกุลเงินทุกจำนวน เช่น 5,000 ยูโร 4999 ยูโร 4998 ยูโร และอื่นๆ...
แต่ก่อนจะสรุปอะไร เราต้องแน่ใจว่า URL เหล่านี้มากกว่า 250,000 รายการอยู่ในหมวดหมู่ 'altin (ทอง)'
apara.filter(['loc', 'url_sub_cat' ]).tail(60) จะแสดง 60 บรรทัดสุดท้ายของ Data Frame นี้:

เราสามารถทำเช่นเดียวกันสำหรับรายละเอียด URL สีทองภายในกลุ่ม Apara
ทอง = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
ณ จุดนี้ เราเห็นว่าหนังสือพิมพ์ Sabah ได้เปิดหน้าต่างๆ 5,000 หน้าเพื่อแปลงแต่ละสกุลเงินเป็นดอลลาร์ ยูโร ทอง และ TL (ลีราตุรกี) มีหน้าการคำนวณแยกต่างหากสำหรับเงินแต่ละหน่วยระหว่าง 1 ถึง 5,000 คุณสามารถดูตัวอย่าง 85 บรรทัดแรกและ 85 บรรทัดสุดท้ายของกลุ่มทองคำด้านล่าง ได้เปิดหน้าแยกราคาทองคำแต่ละกรัม


เราไม่สงสัยเลยว่าหน้าเหล่านี้ไม่จำเป็น มีเนื้อหาที่ซ้ำกันจำนวนมาก และมีขนาดใหญ่เกินไป แต่หนังสือพิมพ์ Sabah เป็นเว็บไซต์ที่แข็งแกร่งของแบรนด์ ซึ่ง Google ยังคงแสดงหน้านี้ในเกือบทุกคำถาม การจัดอันดับสูงสุด
ณ จุดนี้ เรายังเห็นว่า Crawl Cost Tolerance นั้นสูงสำหรับเว็บไซต์ข่าวเก่าที่มีอำนาจสูง
อย่างไรก็ตาม สิ่งนี้ไม่ได้อธิบายว่าทำไมหมวดหมู่ระดับทองจึงมี URL มากกว่าประเภทอื่น
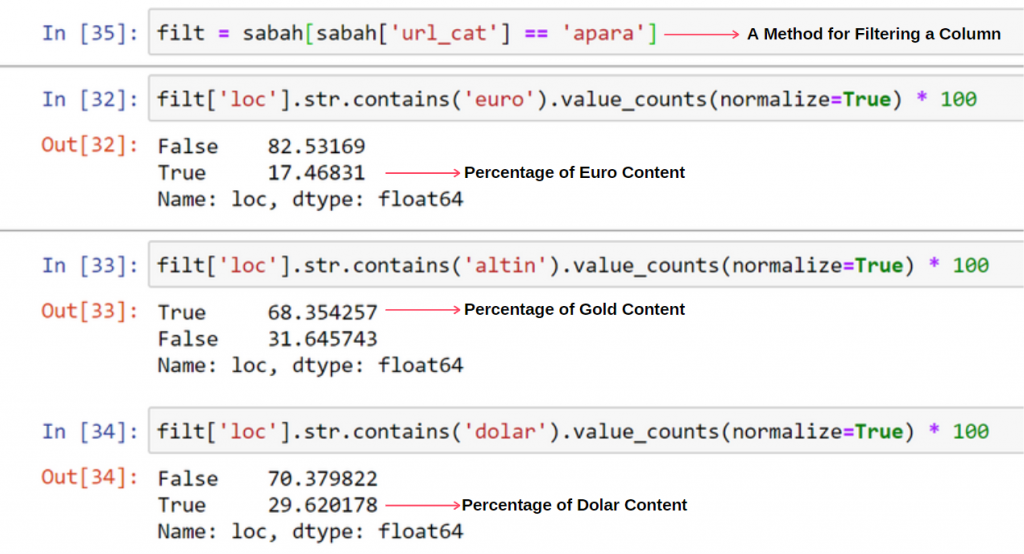
ฉันไม่เห็นอะไรแปลก ๆ เกี่ยวกับค่าที่ทับซ้อนกันซึ่งรวมกันได้เกิน 100%
เว้นแต่ว่าฉันพลาดอะไรไป?
อย่างที่คุณสังเกตเห็น เมื่อเราบวกค่า True ทั้งหมด เราจะได้ผลลัพธ์ 115.16% เหตุผลด้านล่างนี้
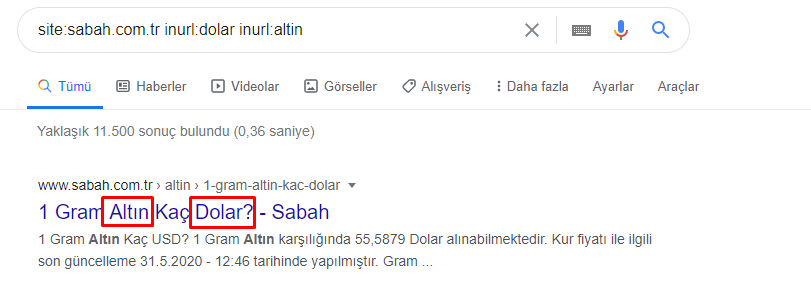
แม้แต่กลุ่มหลักก็มีทางแยกกันแบบนี้ เราสามารถวิเคราะห์ทางแยกเหล่านี้ได้เช่นกัน แต่อาจเป็นหัวข้อของบทความอื่น
เราพบว่า 68% ของเนื้อหาในกลุ่ม Apara URL เกี่ยวข้องกับ GOLD
เพื่อให้เข้าใจสถานการณ์นี้มากขึ้น สิ่งแรกที่เราต้องทำคือสแกน URL ในการหักเหของทองคำ
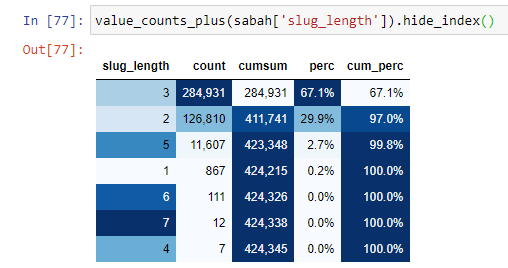
เมื่อเราจัดประเภท URL ตามจำนวน '/' ที่มีตั้งแต่ส่วนรูท เราจะพบว่าจำนวน URL ที่มีตัวแบ่งสูงสุด 3 ตัวนั้นสูง เมื่อเราวิเคราะห์ URL เหล่านี้ เราจะเห็นว่า 270.000 จาก 3 URL slug_length อยู่ในหมวด Gold
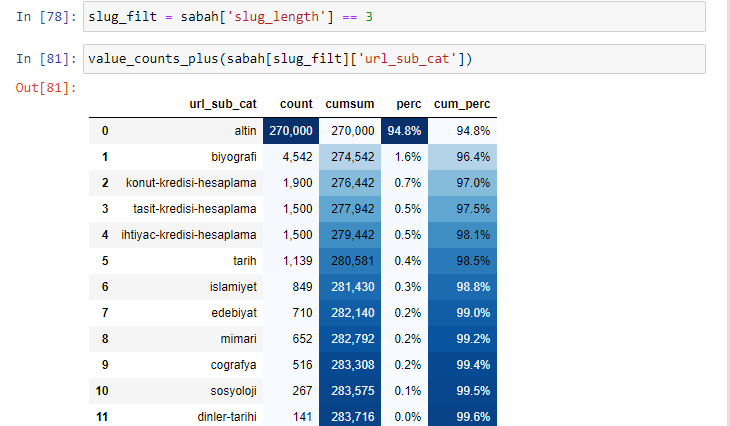
morning_filt = morning ['slug_length'] == 3 หมายความว่าคุณจะได้รับเฉพาะค่าที่เท่ากับ 3 จากกลุ่มข้อมูลของประเภทข้อมูล int ในคอลัมน์หนึ่งของกรอบข้อมูล จากนั้น ตามข้อมูลนี้ เราจะกำหนดกรอบ URL ที่สะดวกต่อเงื่อนไขด้วยการนับ ผลรวม และอัตราการรวมด้วยผลรวมสะสม
เมื่อเราแยกคำที่ใช้บ่อยที่สุดใน URL ทอง เราจะพบคำที่แสดงถึง "เต็ม", "สาธารณรัฐ", "ไตรมาส", "กรัม", "ครึ่ง", "บรรพบุรุษ" ทองคำประเภท Ata และ Republic มีเอกลักษณ์เฉพาะสำหรับตุรกี หนึ่งในนั้นเป็นตัวแทนของอธิปไตยของตุรกี และอีกคนหนึ่งคือ Kemal Ataturk ผู้ก่อตั้งสาธารณรัฐ นั่นเป็นสาเหตุที่ปริมาณการค้นหาคำค้นหาของพวกเขาสูง
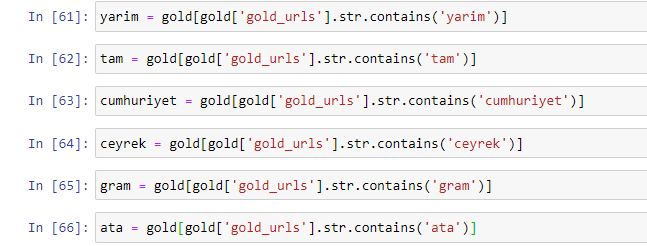
ก่อนอื่น เราได้ลบคำทั่วไปที่พบใน URL และกำหนดให้เป็นตัวแปรแยกกัน ต่อไป เราจะใช้ตัวแปรเหล่านี้ใน Gold DataFrame เพื่อสร้างคอลัมน์เฉพาะสำหรับประเภทของพวกมัน
หลังจากสร้างคอลัมน์ใหม่ผ่านตัวแปรแล้ว เราต้องกรองคอลัมน์เหล่านั้นด้วยค่าบูลีน
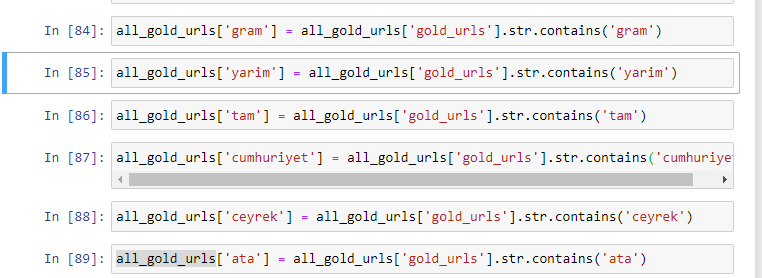
อย่างที่คุณเห็น เราสามารถจัดหมวดหมู่ gold URL ทั้งหมดได้ 270,000 แถวและ 6 คอลัมน์ สาเหตุหลักที่ทำให้หน้าเฉพาะทองคำมีจำนวนมากคือ ดอลลาร์หรือยูโรไม่มีประเภทแยกจากกัน ในขณะที่ทองคำมีประเภทแยกจากกัน ในเวลาเดียวกัน ความหลากหลายของหน้าข้ามระหว่างทองคำและสกุลเงินต่าง ๆ นั้นสูงกว่าสกุลเงินอื่นเนื่องจากความไว้วางใจดั้งเดิมในคนตุรกี
ในความคิดของผม หน้าทองคำทุกประเภทควรแบ่งเท่าๆ กัน จริงไหม?
เราสามารถทดสอบสิ่งนี้ได้อย่างง่ายดายด้วยคุณสมบัติ Heatmap ของ Seaborn
นำเข้า seaborn เป็น sns
นำเข้า matplotlib.pyplot เป็น plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
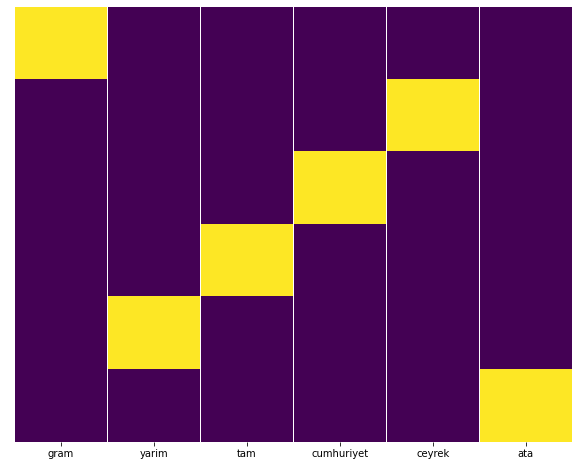
ที่นี่ในแผนที่ความร้อน ความจริงในแต่ละคอลัมน์จะถูกทำเครื่องหมายไว้อย่างเรียบง่าย อย่างที่เห็น ขนาดของแต่ละอันมีความสมมาตรและจัดเรียงไว้อย่างเป็นระเบียบบนแผนที่
ดังนั้นเราจึงมีมุมมองกว้างๆ เกี่ยวกับนโยบายเนื้อหาของหนังสือพิมพ์ Sabah.com.tr เกี่ยวกับสกุลเงินและการคำนวณสกุลเงิน
ในอนาคต ฉันจะเขียนเว็บไซต์ข่าวตุรกีและกลยุทธ์เนื้อหาตามแผนผังเว็บไซต์ Kaggle ซึ่งเปิดตัวโดย Elias Dabbas แต่ในบทความนี้ เราได้พูดถึงสิ่งที่สามารถค้นพบได้จากเว็บไซต์ทั้งขนาดใหญ่และขนาดเล็กที่มีแผนผังเว็บไซต์ .
บทสรุปและประเด็นสำคัญ
ฉันคิดว่าเราได้เห็นแล้วว่าการทำความเข้าใจเว็บไซต์นั้นง่ายเพียงใด ด้วยโครงสร้าง URL ที่ราบรื่นและมีความหมาย เราควรจำไว้ด้วยว่าโครงสร้าง URL ที่เหมาะสมสำหรับ Google มีคุณค่าเพียงใด
ในอนาคต เราจะเห็น SEO จำนวนมากที่คุ้นเคยกับวิทยาศาสตร์ข้อมูล การสร้างภาพข้อมูล การเขียนโปรแกรมส่วนหน้า และอื่นๆ มากขึ้น... ฉันเห็นว่ากระบวนการนี้เป็นจุดเริ่มต้นของการเปลี่ยนแปลงที่หลีกเลี่ยงไม่ได้: ช่องว่างระหว่าง SEO และนักพัฒนาจะถูกปิดอย่างสมบูรณ์ ในอีกไม่กี่ปี
ด้วย Python คุณสามารถทำการวิเคราะห์ประเภทนี้ให้ดียิ่งขึ้นไปอีก: เป็นไปได้ที่จะได้รับข้อมูลจากความเข้าใจมุมมองทางการเมืองของเว็บไซต์ข่าว ไปจนถึงผู้ที่เขียนเกี่ยวกับอะไร บ่อยแค่ไหน และด้วยความรู้สึกใด ฉันไม่ต้องการพูดถึงเรื่องนี้เนื่องจากกระบวนการเหล่านี้เกี่ยวกับวิทยาศาสตร์ข้อมูลล้วนๆ มากกว่า SEO (และบทความนี้ค่อนข้างยาว)
แต่ถ้าคุณสนใจ มีการตรวจสอบประเภทอื่นๆ อีกมากมายที่สามารถทำได้ผ่านแผนผังเว็บไซต์และ Python เช่น การตรวจสอบรหัสสถานะของ URL ในแผนผังเว็บไซต์
ฉันรอคอยที่จะทดลองและแบ่งปันงาน SEO อื่นๆ ที่คุณสามารถทำได้ด้วย Python และ Advertools