
การทำความเข้าใจ AI: วิธีที่เราสอนคอมพิวเตอร์ด้วยภาษาธรรมชาติ
เผยแพร่แล้ว: 2023-11-28วลี "ปัญญาประดิษฐ์" ถูกนำมาใช้กับคอมพิวเตอร์มาตั้งแต่ปี 1950 แต่จนถึงปีที่ผ่านมา คนส่วนใหญ่อาจคิดว่า AI ยังคงเป็นไซไฟมากกว่าความเป็นจริงทางเทคโนโลยี
การมาถึงของ ChatGPT ของ OpenAI ในเดือนพฤศจิกายน 2022 จู่ๆ ก็เปลี่ยนการรับรู้ของผู้คนเกี่ยวกับความสามารถของแมชชีนเลิร์นนิง แต่ ChatGPT เป็นอย่างไรกันแน่ที่ทำให้โลกต้องตื่นตะลึงและตระหนักว่าปัญญาประดิษฐ์มาถึงจุดนี้อย่างยิ่งใหญ่
พูดง่ายๆ ก็คือภาษา เหตุผลที่ ChatGPT รู้สึกเหมือนก้าวกระโดดอย่างน่าทึ่งก็เนื่องมาจากการที่ ChatGPT ดูคล่องแคล่วในภาษาธรรมชาติในแบบที่ไม่เคยมีมาก่อน
นี่เป็นก้าวใหม่ที่น่าทึ่งของ "การประมวลผลภาษาธรรมชาติ" (NLP) ซึ่งเป็นความสามารถของคอมพิวเตอร์ในการตีความภาษาธรรมชาติและแสดงผลการตอบสนองที่น่าเชื่อ ChatGPT สร้างขึ้นจาก "โมเดลภาษาขนาดใหญ่" (LLM) ซึ่งเป็นโครงข่ายประสาทเทียมประเภทหนึ่งที่ใช้การเรียนรู้เชิงลึกที่ได้รับการฝึกบนชุดข้อมูลขนาดใหญ่ที่สามารถประมวลผลและสร้างเนื้อหาได้
“โปรแกรมคอมพิวเตอร์มีความคล่องทางภาษาได้อย่างไร”
แต่เรามาที่นี่ได้อย่างไร? โปรแกรมคอมพิวเตอร์สามารถบรรลุความคล่องแคล่วทางภาษาได้อย่างไร? มันฟังดูเป็นมนุษย์อย่างไม่มีข้อผิดพลาดได้อย่างไร?
ChatGPT ไม่ได้ถูกสร้างขึ้นในสุญญากาศ แต่สร้างขึ้นจากนวัตกรรมและการค้นพบต่างๆ มากมายในช่วงหลายทศวรรษที่ผ่านมา ความก้าวหน้าอย่างต่อเนื่องที่นำไปสู่ ChatGPT ล้วนเป็นเหตุการณ์สำคัญในวิทยาการคอมพิวเตอร์ แต่ก็เป็นไปได้ที่จะมองว่าสิ่งเหล่านี้เป็นการเลียนแบบขั้นตอนที่มนุษย์เรียนรู้ภาษา
เราเรียนภาษาอย่างไร?
เพื่อให้เข้าใจว่า AI มาถึงขั้นตอนนี้ได้อย่างไร การพิจารณาธรรมชาติของการเรียนรู้ภาษานั้นคุ้มค่า โดยเราเริ่มต้นด้วยคำเดียว จากนั้นจึงเริ่มรวมคำเหล่านั้นเข้าด้วยกันเป็นลำดับที่ยาวขึ้น จนกว่าเราจะสามารถสื่อสารแนวคิด แนวคิด และคำแนะนำที่ซับซ้อนได้
ตัวอย่างเช่น ขั้นตอนทั่วไปบางประการของการเรียนรู้ภาษาในเด็ก ได้แก่:
- ระยะโฮโลแฟรสติก: ระหว่าง 9-18 เดือน เด็กเรียนรู้ที่จะใช้คำเดี่ยวๆ ที่อธิบายความต้องการหรือความต้องการพื้นฐานของพวกเขา การสื่อสารด้วยคำเพียงคำเดียวหมายถึงการเน้นความชัดเจนมากกว่าความสมบูรณ์ของแนวคิด หากเด็กหิว พวกเขาจะไม่พูดว่า “ฉันต้องการอาหาร” หรือ “ฉันหิว” แต่พวกเขาจะพูดว่า “อาหาร” หรือ “นม” แทน
- เวทีสองคำ: ในช่วงอายุ 18-24 เดือน เด็กๆ เริ่มใช้การจัดกลุ่มคำสองคำง่ายๆ เพื่อพัฒนาทักษะการสื่อสาร ตอนนี้พวกเขาสามารถสื่อสารความรู้สึกและความต้องการด้วยสำนวนต่างๆ เช่น "กินมากขึ้น" หรือ "อ่านหนังสือ"
- ระยะโทรเลข: เด็กอายุระหว่าง 24-30 เดือนจะเริ่มร้อยคำหลายคำเข้าด้วยกันเพื่อสร้างวลีและประโยคที่ซับซ้อนมากขึ้น จำนวนคำที่ใช้ยังมีน้อยแต่การเรียงลำดับคำถูกต้องและความซับซ้อนเริ่มปรากฏให้เห็น เด็กๆ เริ่มเรียนรู้การสร้างประโยคพื้นฐาน เช่น “ฉันอยากให้แม่ดู”
- ระยะหลายคำ: หลังจาก 30 เดือน เด็ก ๆ จะเริ่มเข้าสู่ระยะหลายคำ ในขั้นตอนนี้ เด็ก ๆ จะเริ่มใช้ประโยคที่ถูกต้องตามหลักไวยากรณ์ ซับซ้อน และมีหลายประโยคมากขึ้น นี่เป็นขั้นตอนสุดท้ายของการเรียนรู้ภาษา และเด็กๆ จะสื่อสารด้วยประโยคที่ซับซ้อนในที่สุด เช่น “ถ้าฝนตก ฉันอยากจะอยู่ในเกมและเล่นเกมต่อไป”
ขั้นตอนสำคัญขั้นแรกในการเรียนรู้ภาษาคือความสามารถในการเริ่มใช้คำเดี่ยวๆ ด้วยวิธีง่ายๆ ดังนั้นอุปสรรคแรกที่นักวิจัย AI จำเป็นต้องเอาชนะคือวิธีฝึกแบบจำลองเพื่อเรียนรู้การเชื่อมโยงคำง่ายๆ
รุ่น 1 – การเรียนรู้คำเดี่ยวด้วย Word2Vec (กระดาษ 1 และกระดาษ 2)
หนึ่งในโมเดลโครงข่ายประสาทเทียมในยุคแรกๆ ที่พยายามเรียนรู้การเชื่อมโยงคำในลักษณะนี้คือ Word2Vec ซึ่งพัฒนาโดย Tomaš Mikolov และกลุ่มนักวิจัยของ Google มีการตีพิมพ์ในเอกสารสองฉบับในปี 2013 (ซึ่งแสดงให้เห็นว่าสิ่งต่าง ๆ พัฒนาไปเร็วแค่ไหนในสาขานี้)
แบบจำลองเหล่านี้ได้รับการฝึกอบรมโดยการเรียนรู้การเชื่อมโยงคำที่ใช้กันทั่วไป แนวทางนี้สร้างขึ้นจากสัญชาตญาณของผู้บุกเบิกด้านภาษาในยุคแรกๆ เช่น จอห์น อาร์. เฟิร์ธ ซึ่งตั้งข้อสังเกตว่าความหมายอาจมาจากการเชื่อมโยงคำ: “คุณจะรู้คำศัพท์จากบริษัทที่มันเก็บไว้”
แนวคิดก็คือคำที่มีความหมายทางความหมายคล้ายกันมักจะเกิดขึ้นพร้อมกันบ่อยกว่า โดยทั่วไปคำว่า "แมว" และ "สุนัข" มักจะเกิดขึ้นพร้อมกันมากกว่าคำว่า "แอปเปิ้ล" หรือ "คอมพิวเตอร์" กล่าวอีกนัยหนึ่ง คำว่า "แมว" ควรคล้ายกับคำว่า "สุนัข" มากกว่า "แมว" จะเป็น "แอปเปิ้ล" หรือ "คอมพิวเตอร์"
สิ่งที่น่าสนใจเกี่ยวกับ Word2Vec คือวิธีการฝึกให้เรียนรู้การเชื่อมโยงคำเหล่านี้:
- เดาคำเป้าหมาย: โมเดลจะได้รับจำนวนคำคงที่เป็นอินพุต โดยที่คำเป้าหมายหายไป และจะต้องเดาคำเป้าหมายที่หายไป สิ่งนี้เรียกว่า ถุงคำต่อเนื่อง (CBOW)
- เดาคำที่อยู่รอบๆ: แบบจำลองจะได้รับคำเดียว จากนั้นจึงมอบหมายให้เดาคำที่อยู่รอบๆ สิ่งนี้เรียกว่า Skip-Gram และเป็นแนวทางตรงกันข้ามกับ CBOW เนื่องจากเรากำลังทำนายคำที่อยู่รอบๆ
ข้อดีอย่างหนึ่งของแนวทางเหล่านี้คือ คุณไม่จำเป็นต้องมีข้อมูลที่ติดป้ายกำกับเพื่อฝึกโมเดล ข้อมูลการติดป้ายกำกับ เช่น การอธิบายข้อความว่าเป็น "เชิงบวก" หรือ "เชิงลบ" เพื่อสอนการวิเคราะห์ความรู้สึก เป็นงานที่ช้าและลำบากในท้ายที่สุด
หนึ่งในสิ่งที่น่าประหลาดใจที่สุดเกี่ยวกับ Word2Vec คือความสัมพันธ์ทางความหมายที่ซับซ้อนที่บันทึกไว้ด้วยวิธีการฝึกอบรมที่ค่อนข้างง่าย Word2Vec ส่งออกเวกเตอร์ซึ่งเป็นตัวแทนของคำที่ป้อน ด้วยการดำเนินการทางคณิตศาสตร์กับเวกเตอร์เหล่านี้ ผู้เขียนสามารถแสดงคำว่าเวกเตอร์ได้ไม่เพียงแต่จับองค์ประกอบที่คล้ายกันทางวากยสัมพันธ์ แต่ยังรวมถึงความสัมพันธ์เชิงความหมายที่ซับซ้อนด้วย
ความสัมพันธ์เหล่านี้เกี่ยวข้องกับวิธีการใช้คำต่างๆ ตัวอย่างที่ผู้เขียนตั้งข้อสังเกตคือความสัมพันธ์ระหว่างคำเช่น "King" และ "Queen" และ "Man" และ "Woman"
แต่ในขณะที่มันก้าวไปข้างหน้า Word2Vec ก็มีข้อจำกัด มันมีคำจำกัดความเดียวต่อคำ ตัวอย่างเช่น เราทุกคนรู้ว่า "ธนาคาร" อาจหมายถึงสิ่งที่แตกต่างกัน ขึ้นอยู่กับว่าคุณวางแผนที่จะถือธนาคารหรือตกปลาจากที่หนึ่ง Word2Vec ไม่สนใจ มีเพียงคำจำกัดความเดียวของคำว่า "ธนาคาร" และจะใช้คำนั้นในทุกบริบท
เหนือสิ่งอื่นใด Word2Vec ไม่สามารถประมวลผลคำสั่งหรือประโยคได้ อาจใช้เพียงคำเป็นอินพุตและเอาต์พุต "การฝังคำ" หรือการแทนเวกเตอร์ซึ่งได้เรียนรู้จากคำนั้น ในการสร้างรากฐานคำเดียวนี้ นักวิจัยจำเป็นต้องค้นหาวิธีรวมคำตั้งแต่สองคำขึ้นไปเข้าด้วยกันตามลำดับ เราสามารถจินตนาการได้ว่าสิ่งนี้จะคล้ายกับขั้นตอนการเรียนรู้ภาษาสองคำ
รุ่น 2 – การเรียนรู้ลำดับคำด้วย RNN และลำดับข้อความ
เมื่อเด็กๆ เริ่มเชี่ยวชาญการใช้คำเดี่ยวๆ แล้ว พวกเขาจะพยายามรวบรวมคำต่างๆ เพื่อแสดงความคิดและความรู้สึกที่ซับซ้อนมากขึ้น ในทำนองเดียวกัน ขั้นตอนต่อไปในการพัฒนา NLP คือการพัฒนาความสามารถในการประมวลผลลำดับคำ ปัญหาเกี่ยวกับลำดับการประมวลผลข้อความคือไม่มีความยาวคงที่ ประโยคสามารถมีความยาวแตกต่างกันไปตั้งแต่คำไม่กี่คำไปจนถึงย่อหน้าที่ยาว ไม่ใช่ลำดับทั้งหมดที่จะมีความสำคัญต่อความหมายและบริบทโดยรวม แต่เราจำเป็นต้องสามารถประมวลผลลำดับทั้งหมดได้จึงจะรู้ว่าส่วนใดที่เกี่ยวข้องมากที่สุด
นั่นคือที่มาของ Recurrent Neural Networks (RNN)
RNN พัฒนาขึ้นในปี 1990 โดยทำงานโดยประมวลผลอินพุตในลูป โดยที่เอาต์พุตจากขั้นตอนก่อนหน้าจะถูกส่งผ่านเครือข่ายในขณะที่วนซ้ำแต่ละขั้นตอนในลำดับ
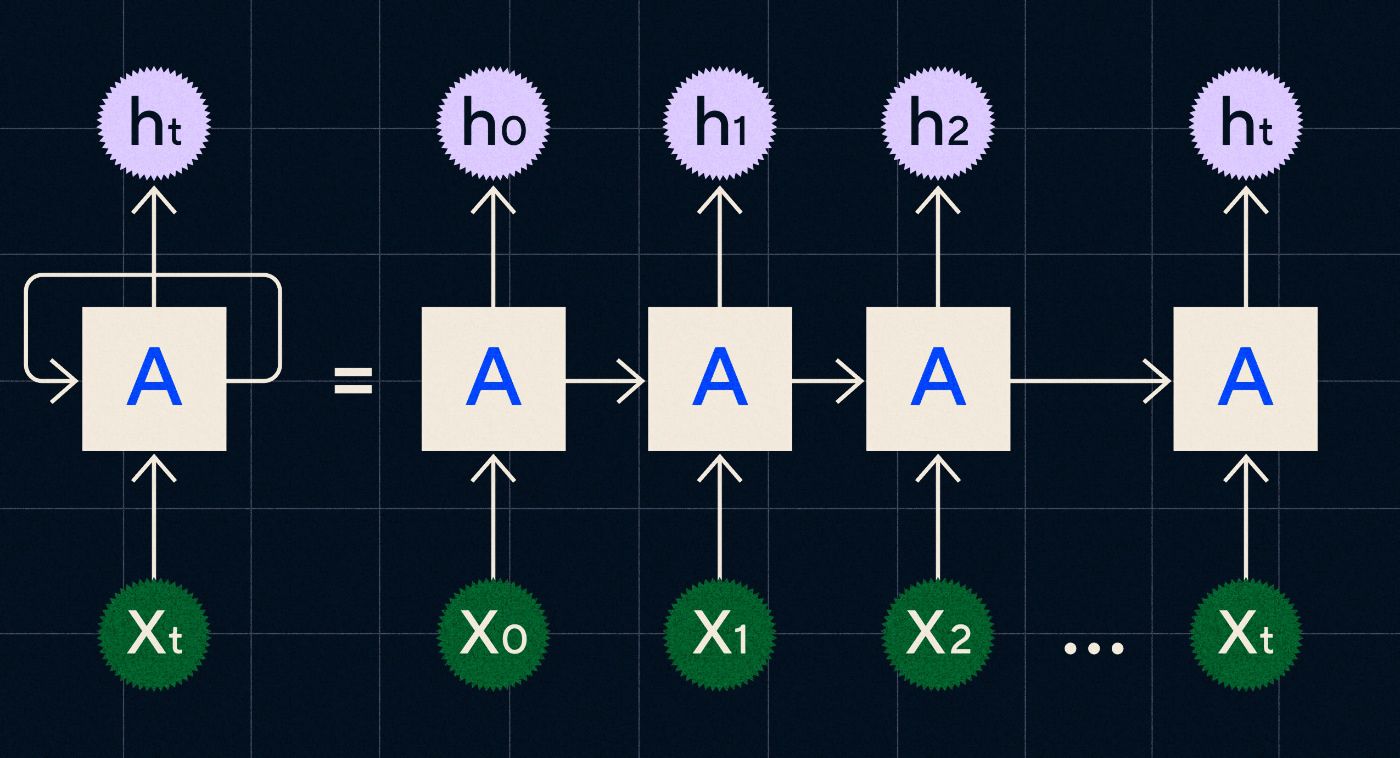
ที่มา: โพสต์บล็อกของ Christopher Olah ใน RNN
แผนภาพด้านบนแสดงวิธีนึกภาพ RNN เป็นชุดของโครงข่ายประสาทเทียม (A) โดยที่เอาต์พุตของขั้นตอนก่อนหน้า (h0, h1, h2…ht) จะถูกส่งผ่านไปยังขั้นตอนถัดไป ในแต่ละขั้นตอน อินพุตใหม่ (X0, X1, X2 … Xt) จะถูกประมวลผลโดยเครือข่ายด้วย
RNN (และโดยเฉพาะเครือข่าย Long Short Term Memory หรือ LSTM ซึ่งเป็น RNN ประเภทพิเศษที่ Sepp Hochreiter และ Jurgen Schmidhuber นำมาใช้ในปี 1997) ช่วยให้เราสามารถสร้างสถาปัตยกรรมเครือข่ายประสาทเทียมซึ่งสามารถทำงานที่ซับซ้อนมากขึ้น เช่น การแปลได้
ในปี 2014 บทความตีพิมพ์โดย Ilya Sutskever (ผู้ร่วมก่อตั้ง OpenAI), Oriol Vinyals และ Quoc V Le ที่ Google ซึ่งอธิบายโมเดล Sequence to Sequence (Seq2Seq) บทความนี้แสดงให้เห็นว่าคุณสามารถฝึกโครงข่ายประสาทเทียมให้รับข้อความที่ป้อนและส่งกลับคำแปลของข้อความนั้นได้อย่างไร คุณสามารถคิดว่านี่เป็นตัวอย่างแรกๆ ของโครงข่ายประสาทเทียมโดยที่คุณแจ้งและส่งคืนการตอบกลับ อย่างไรก็ตาม งานดังกล่าวได้รับการแก้ไขแล้ว ดังนั้น หากได้รับการฝึกอบรมเกี่ยวกับการแปล คุณจะไม่สามารถ “สั่ง” ให้ดำเนินการอย่างอื่นได้
โปรดจำไว้ว่า Word2Vec รุ่นก่อนหน้านี้สามารถประมวลผลได้เพียงคำเดียวเท่านั้น ดังนั้นหากคุณผ่านประโยคเช่น “ทันตแพทย์ดึงฟันของฉัน” มันก็จะสร้างเวกเตอร์สำหรับแต่ละคำราวกับว่ามันไม่เกี่ยวข้องกัน
อย่างไรก็ตาม ลำดับและบริบทมีความสำคัญสำหรับงานต่างๆ เช่น การแปล คุณไม่สามารถแปลเพียงคำเดียวได้ คุณต้องแยกวิเคราะห์ลำดับของคำแล้วจึงแสดงผลลัพธ์ออกมา นี่คือจุดที่ RNN เปิดใช้งานโมเดล Seq2Seq เพื่อประมวลผลคำในลักษณะนี้
กุญแจสำคัญของโมเดล Seq2Seq คือการออกแบบโครงข่ายประสาทเทียม ซึ่งใช้ RNN สองตัวเรียงกัน ตัวหนึ่งคือตัวเข้ารหัสซึ่งเปลี่ยนอินพุตจากข้อความเป็นการฝัง และอีกอันคือตัวถอดรหัสซึ่งรับการฝังที่ส่งออกโดยตัวเข้ารหัสเป็นอินพุต:
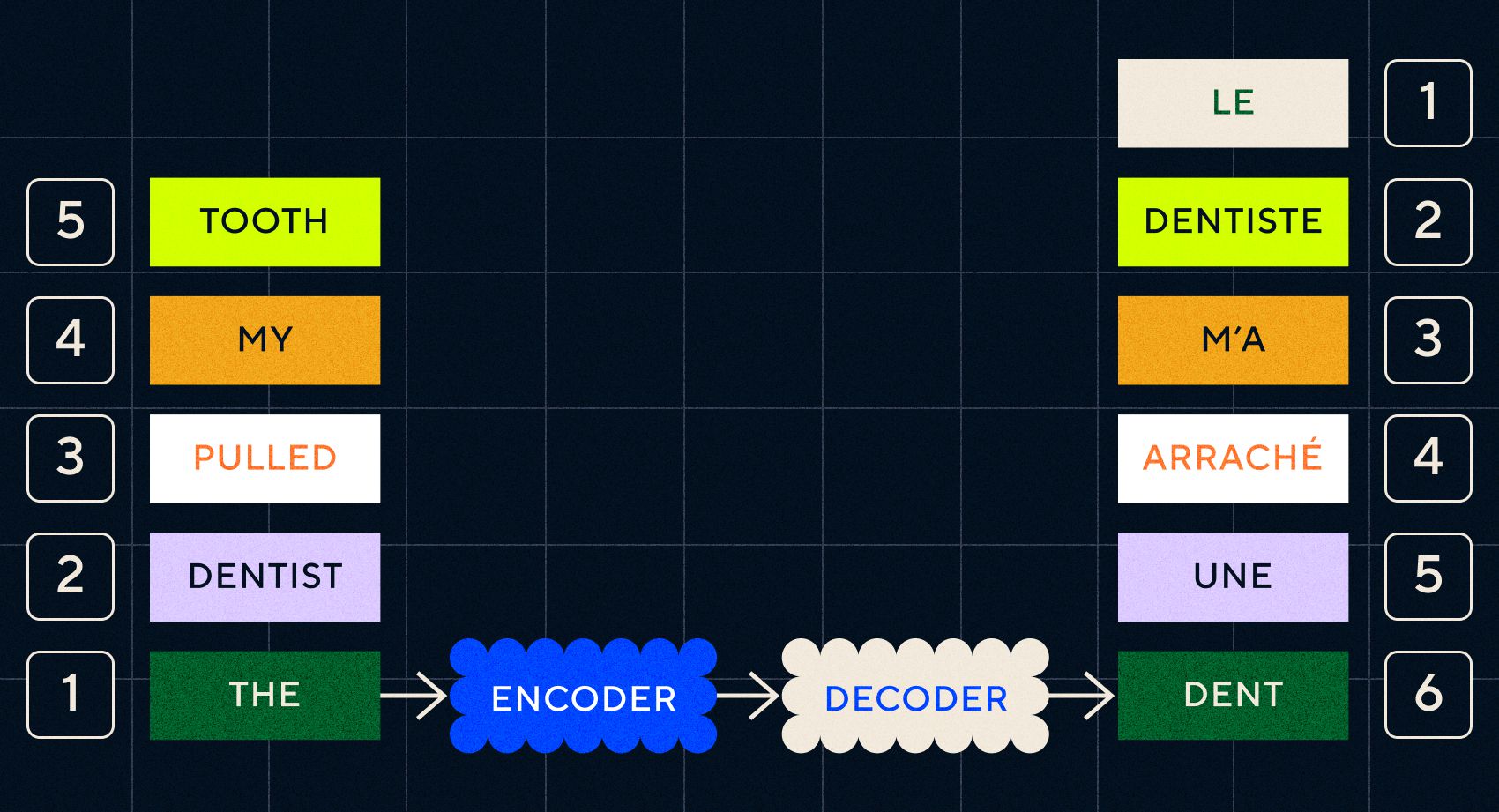
เมื่อตัวเข้ารหัสประมวลผลอินพุตในแต่ละขั้นตอนแล้ว ตัวเข้ารหัสจะเริ่มส่งเอาต์พุตไปยังตัวถอดรหัส ซึ่งจะเปลี่ยนการฝังให้เป็นข้อความที่แปล
ด้วยวิวัฒนาการของโมเดลเหล่านี้ เราจะเห็นว่าโมเดลเหล่านี้เริ่มมีลักษณะคล้ายคลึงกันในรูปแบบง่ายๆ เหมือนกับที่เราเห็นใน ChatGPT ในปัจจุบัน อย่างไรก็ตาม เรายังเห็นว่าโมเดลเหล่านี้มีข้อจำกัดเพียงใดเมื่อเปรียบเทียบกัน เช่นเดียวกับการพัฒนาภาษาของเราเอง เพื่อปรับปรุงความสามารถทางภาษาอย่างแท้จริง เราจำเป็นต้องรู้อย่างชัดเจนถึงสิ่งที่ต้องใส่ใจเพื่อสร้างวลีและประโยคที่ซับซ้อนมากขึ้น
โมเดล 3 – การเรียนรู้โดยความสนใจและการปรับขนาดด้วย Transformers
เราสังเกตไว้ก่อนหน้านี้ว่าขั้นตอนโทรเลขเป็นที่ที่เด็ก ๆ เริ่มสร้างประโยคสั้น ๆ ที่มีคำตั้งแต่สองคำขึ้นไป สิ่งสำคัญอย่างหนึ่งของขั้นตอนการเรียนรู้ภาษานี้คือ เด็ก ๆ กำลังเริ่มเรียนรู้วิธีสร้างประโยคที่เหมาะสม
โมเดล RNN และ Seq2Seq ช่วยให้โมเดลภาษาประมวลผลคำหลายลำดับ แต่ยังคงจำกัดความยาวของประโยคที่สามารถประมวลผลได้ เมื่อความยาวของประโยคเพิ่มขึ้น เราจำเป็นต้องให้ความสนใจกับสิ่งส่วนใหญ่ในประโยค
ตัวอย่างเช่น ประโยคต่อไปนี้ “ในห้องมีความตึงเครียดมากจนคุณสามารถใช้มีดตัดมันได้” มีเรื่องมากมายเกิดขึ้นที่นั่น หากต้องการทราบว่าเราไม่ได้กำลังตัดบางสิ่งบางอย่างด้วยมีดในที่นี้ เราจำเป็นต้องเชื่อมโยง "cut" กับ "tension" ในช่วงต้นประโยค
เมื่อความยาวของประโยคเพิ่มขึ้น การจะรู้ว่าคำใดหมายถึงคำใดจึงจะอนุมานความหมายที่ถูกต้องได้ยากขึ้น นี่คือจุดที่ RNN เริ่มเผชิญกับขีดจำกัด และเราต้องการโมเดลใหม่เพื่อก้าวไปสู่ขั้นต่อไปของการเรียนรู้ภาษา
“ลองนึกถึงการพยายามสรุปบทสนทนาที่ยาวขึ้นเรื่อยๆ โดยมีจำนวนคำจำกัด ทุกขั้นตอนคุณเริ่มสูญเสียข้อมูลมากขึ้นเรื่อยๆ”
ในปี 2017 กลุ่มนักวิจัยของ Google ตีพิมพ์บทความซึ่งเสนอเทคนิคที่ช่วยให้แบบจำลองสามารถให้ความสนใจกับบริบทที่สำคัญในข้อความได้ดียิ่งขึ้น
สิ่งที่พวกเขาพัฒนาขึ้นคือวิธีที่โมเดลภาษาสามารถค้นหาบริบทที่ต้องการได้ง่ายขึ้นในขณะที่ประมวลผลลำดับการป้อนข้อความ พวกเขาเรียกแนวทางนี้ว่า "สถาปัตยกรรมหม้อแปลงไฟฟ้า" และแสดงถึงการก้าวกระโดดครั้งใหญ่ที่สุดในการประมวลผลภาษาธรรมชาติจนถึงปัจจุบัน
กลไกการค้นหานี้ทำให้โมเดลสามารถระบุคำก่อนหน้านี้ได้ง่ายขึ้นซึ่งให้บริบทกับคำปัจจุบันที่กำลังประมวลผลมากขึ้น RNN พยายามจัดเตรียมบริบทโดยผ่านสถานะรวมของคำทั้งหมดที่ได้รับการประมวลผลแล้วในแต่ละขั้นตอน ลองนึกถึงการพยายามสรุปบทสนทนาที่ยาวขึ้นเรื่อยๆ โดยมีจำนวนคำจำกัด ในทุกขั้นตอนคุณเริ่มสูญเสียข้อมูลมากขึ้นเรื่อยๆ ในทางกลับกัน หม้อแปลงจะถ่วงน้ำหนักคำ (หรือโทเค็น ซึ่งไม่ใช่ทั้งคำ แต่เป็นส่วนหนึ่งของคำ) โดยพิจารณาจากความสำคัญของคำในปัจจุบันในแง่ของบริบท ทำให้ง่ายต่อการประมวลผลลำดับคำที่ยาวขึ้นเรื่อยๆ โดยปราศจากปัญหาคอขวดใน RNN กลไกความสนใจใหม่นี้ยังอนุญาตให้ประมวลผลข้อความแบบคู่ขนานแทนการประมวลผลตามลำดับเหมือน RNN
ลองนึกภาพประโยคเช่น “สัตว์ไม่ได้ข้ามถนนเพราะมันเหนื่อยเกินไป” สำหรับ RNN จะต้องแสดงคำก่อนหน้าทั้งหมดในแต่ละขั้นตอน เมื่อจำนวนคำระหว่าง "it" และ "animal" เพิ่มขึ้น RNN จะระบุบริบทที่เหมาะสมได้ยากขึ้น

ด้วยสถาปัตยกรรมหม้อแปลงไฟฟ้า โมเดลจึงสามารถค้นหาคำที่น่าจะหมายถึง "มัน" มากที่สุด แผนภาพด้านล่างแสดงให้เห็นว่าโมเดลหม้อแปลงไฟฟ้าสามารถเน้นไปที่ส่วน "สัตว์" ของข้อความได้อย่างไรในขณะที่พยายามประมวลผลประโยค
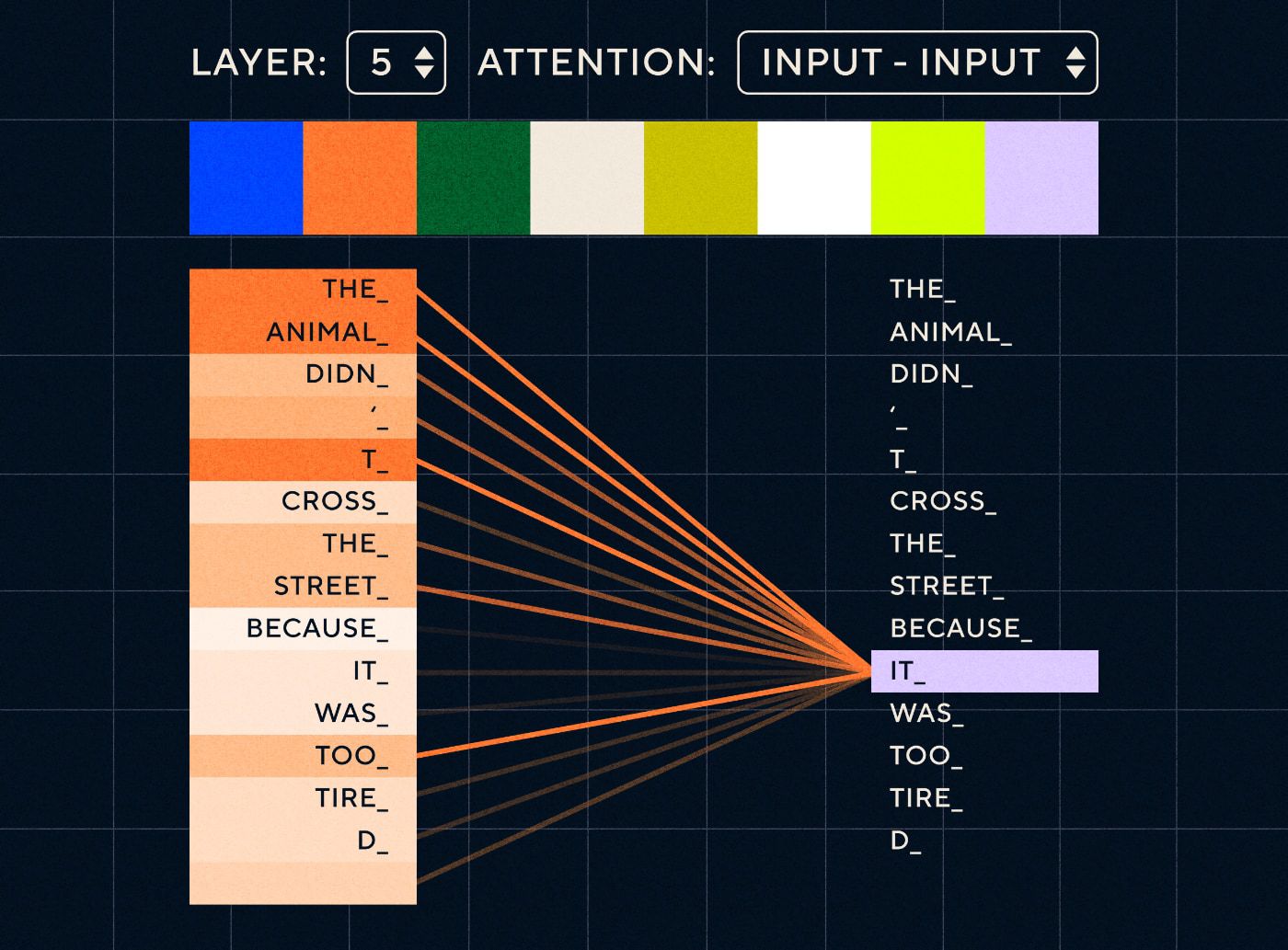
ที่มา: ดิ อิลลัสเตรเต็ด ทรานส์ฟอร์มเมอร์
แผนภาพด้านบนแสดงความสนใจที่เลเยอร์ 5 ของเครือข่าย ในแต่ละชั้น โมเดลกำลังสร้างความเข้าใจในประโยคและ "ให้ความสนใจ" ส่วนหนึ่งของข้อมูลนำเข้าซึ่งคิดว่าเกี่ยวข้องกับขั้นตอนที่กำลังประมวลผลในขณะนั้นมากกว่า กล่าวคือ ให้ความสนใจกับ " สัตว์” สำหรับ “มัน” ในเลเยอร์นี้ ที่มา: ภาพประกอบ Transformer
ให้คิดว่ามันเหมือนกับฐานข้อมูลที่สามารถดึงคำที่มีคะแนนสูงสุดซึ่งน่าจะเกี่ยวข้องกับคำว่า "มัน" มากที่สุด
ด้วยการพัฒนานี้ โมเดลภาษาไม่ได้จำกัดอยู่เพียงการแยกวิเคราะห์ลำดับข้อความสั้นๆ เท่านั้น คุณสามารถใช้ลำดับข้อความที่ยาวกว่าเป็นอินพุตแทนได้ เรารู้ว่าการให้เด็กๆ ได้คำศัพท์มากขึ้นผ่าน "การสนทนาอย่างมีส่วนร่วม" ช่วยปรับปรุงพัฒนาการทางภาษาของพวกเขา
ในทำนองเดียวกัน ด้วยกลไกความสนใจใหม่ โมเดลภาษาสามารถแยกวิเคราะห์ข้อมูลการฝึกแบบข้อความประเภทต่างๆ ได้มากขึ้น ซึ่งรวมถึงบทความ Wikipedia ฟอรัมออนไลน์ Twitter และข้อมูลข้อความอื่น ๆ ที่คุณสามารถแยกวิเคราะห์ได้ เช่นเดียวกับพัฒนาการในวัยเด็ก การได้สัมผัสกับคำเหล่านี้และการใช้งานในบริบทที่แตกต่างกันช่วยให้แบบจำลองภาษาพัฒนาความสามารถทางภาษาใหม่ๆ ที่ซับซ้อนมากขึ้น
ในช่วงนี้เองที่เราเริ่มเห็นการแข่งขันในขนาดที่ผู้คนทุ่มข้อมูลไปที่โมเดลเหล่านี้มากขึ้นเรื่อยๆ เพื่อดูว่าพวกเขาสามารถเรียนรู้อะไรได้บ้าง ข้อมูลนี้ไม่จำเป็นต้องติดป้ายกำกับโดยมนุษย์ นักวิจัยสามารถคัดลอกอินเทอร์เน็ตแล้วป้อนให้กับโมเดลและดูว่าได้เรียนรู้อะไรบ้าง
“แบบจำลองอย่าง BERT ทำลายสถิติการประมวลผลภาษาธรรมชาติทั้งหมดที่มีอยู่ ในความเป็นจริง ชุดข้อมูลการทดสอบที่ใช้สำหรับงานเหล่านี้ง่ายเกินไปสำหรับหม้อแปลงรุ่นเหล่านี้”
โมเดล BERT (BiDirectional Encoder Representations from Transformers) สมควรได้รับการกล่าวถึงเป็นพิเศษด้วยเหตุผลบางประการ เป็นหนึ่งในโมเดลแรกๆ ที่ใช้คุณลักษณะความสนใจซึ่งเป็นแกนหลักของสถาปัตยกรรม Transformer ประการแรก BERT เป็นแบบสองทิศทางโดยสามารถดูข้อความทั้งทางซ้ายและขวาของอินพุตปัจจุบัน สิ่งนี้แตกต่างจาก RNN ที่สามารถประมวลผลข้อความตามลำดับจากซ้ายไปขวาเท่านั้น ประการที่สอง BERT ยังใช้เทคนิคการฝึกอบรมใหม่ที่เรียกว่า "การมาสก์" ซึ่งในทางหนึ่ง บังคับให้โมเดลเรียนรู้ความหมายของอินพุตต่างๆ โดยการ "ซ่อน" หรือ "มาสก์" โทเค็นแบบสุ่ม เพื่อให้แน่ใจว่าโมเดลไม่สามารถ "โกง" และ มุ่งเน้นไปที่โทเค็นเดียวในการวนซ้ำแต่ละครั้ง และสุดท้าย BERT สามารถปรับแต่งให้ทำงาน NLP ที่แตกต่างกันได้ ไม่จำเป็นต้องได้รับการฝึกอบรมตั้งแต่เริ่มต้นสำหรับงานเหล่านี้
ผลลัพธ์ที่ได้นั้นน่าทึ่งมาก โมเดลอย่าง BERT ทำลายสถิติการประมวลผลภาษาธรรมชาติทั้งหมดที่มีอยู่ ในความเป็นจริง ชุดข้อมูลการทดสอบที่ใช้สำหรับงานเหล่านี้ง่ายเกินไปสำหรับโมเดลหม้อแปลงเหล่านี้
ตอนนี้เรามีความสามารถในการฝึกโมเดลภาษาขนาดใหญ่ซึ่งทำหน้าที่เป็นโมเดลพื้นฐานสำหรับงานการประมวลผลภาษาธรรมชาติใหม่ๆ ก่อนหน้านี้ผู้คนส่วนใหญ่ฝึกฝนโมเดลของตนตั้งแต่เริ่มต้น แต่ในปัจจุบัน โมเดลที่ผ่านการฝึกอบรมล่วงหน้าอย่าง BERT และรุ่น GPT ยุคแรกๆ นั้นดีมากจนไม่มีประโยชน์ที่จะทำด้วยตัวเอง ในความเป็นจริง โมเดลเหล่านี้เป็นคนดีมากที่ค้นพบว่าพวกเขาสามารถทำงานใหม่ได้ด้วยตัวอย่างที่ค่อนข้างน้อย ซึ่งถูกอธิบายว่าเป็น "ผู้เรียนเพียงไม่กี่คน" คล้ายกับที่คนส่วนใหญ่ไม่ต้องการตัวอย่างมากเกินไปเพื่อทำความเข้าใจแนวคิดใหม่
นี่เป็นจุดเปลี่ยนครั้งใหญ่ในการพัฒนาโมเดลเหล่านี้และความสามารถทางภาษา ตอนนี้เราแค่ต้องปรับปรุงคำแนะนำในการประดิษฐ์ให้ดียิ่งขึ้น
รุ่น 4 – คำแนะนำการเรียนรู้ด้วย InstructGPT
สิ่งหนึ่งที่เด็กเรียนรู้ในขั้นตอนสุดท้ายของการเรียนรู้ภาษา ระยะหลายคำ คือความสามารถในการใช้คำประกอบเพื่อเชื่อมโยงข้อมูลที่มีองค์ประกอบในประโยค คำประกอบบอกเราเกี่ยวกับความสัมพันธ์ระหว่างคำต่างๆ ในประโยค หากเราต้องการสร้างคำสั่ง โมเดลภาษาจะต้องสามารถสร้างประโยคที่มีคำในเนื้อหาและคำฟังก์ชันที่จับความสัมพันธ์ที่ซับซ้อนได้ ตัวอย่างเช่น คำสั่งต่อไปนี้มีคำที่ใช้เน้นเป็นตัวหนา:
- “ ฉัน อยากให้ คุณ เขียนจดหมาย…”
- “บอก ฉันว่า คุณ คิดอย่างไร เกี่ยวกับ ข้อความ ข้างต้น ”
แต่ก่อนที่เราจะลองฝึกโมเดลภาษาให้ทำตามคำแนะนำ เราต้องเข้าใจสิ่งที่พวกเขารู้เกี่ยวกับคำสั่งเสียก่อน
GPT-3 ของ OpenAI เปิดตัวในปี 2020 แม้ว่าโมเดลเหล่านี้จะมีข้อมูลคร่าวๆ แล้วว่าโมเดลเหล่านี้มีความสามารถอะไรบ้าง แต่เรายังจำเป็นต้องเข้าใจวิธีปลดล็อกความสามารถพื้นฐานของโมเดลเหล่านี้ เราจะโต้ตอบกับโมเดลเหล่านี้เพื่อให้ทำงานต่างๆ ได้อย่างไร
ตัวอย่างเช่น GPT-3 แสดงให้เห็นว่าการเพิ่มขนาดโมเดลและข้อมูลการฝึกอบรมทำให้เกิดสิ่งที่ผู้เขียนเรียกว่า "การเรียนรู้เมตา" ซึ่งเป็นจุดที่โมเดลภาษาพัฒนาชุดความสามารถทางภาษาในวงกว้าง ซึ่งหลายอย่างเป็นสิ่งที่ไม่คาดคิด และสามารถใช้สิ่งเหล่านั้นได้ ทักษะในการทำความเข้าใจงานที่ได้รับมอบหมาย
“แบบจำลองจะสามารถเข้าใจจุดประสงค์ในคำสั่งและดำเนินการงานได้ แทนที่จะเพียงแค่คาดเดาคำศัพท์ถัดไปหรือไม่”
โปรดจำไว้ว่า GPT-3 และโมเดลภาษารุ่นก่อนๆ ไม่ได้ออกแบบมาเพื่อพัฒนาทักษะเหล่านี้ แต่ส่วนใหญ่ได้รับการฝึกฝนให้คาดเดาคำถัดไปตามลำดับข้อความ แต่ด้วยความก้าวหน้าของ RNN, Seq2Seq และเครือข่ายความสนใจ โมเดลเหล่านี้จึงสามารถประมวลผลข้อความได้มากขึ้น ในลำดับที่ยาวขึ้น และมุ่งเน้นไปที่บริบทที่เกี่ยวข้องได้ดีขึ้น
คุณสามารถคิดว่า GPT-3 เป็นการทดสอบเพื่อดูว่าเราจะทำสิ่งนี้ได้ไกลแค่ไหน เราสามารถสร้างโมเดลได้ใหญ่แค่ไหน และเราสามารถป้อนข้อความได้มากแค่ไหน? หลังจากทำเช่นนั้น แทนที่จะป้อนข้อความอินพุตให้กับโมเดลเพื่อให้เสร็จสมบูรณ์ เราสามารถใช้ข้อความอินพุตเป็นคำสั่งได้ แบบจำลองจะสามารถเข้าใจจุดประสงค์ในคำสั่งและดำเนินการงานได้มากกว่าเพียงแค่คาดเดาคำถัดไปหรือไม่? ในลักษณะที่เหมือนกับการพยายามทำความเข้าใจว่าแบบจำลองเหล่านี้มาถึงขั้นตอนใดแล้ว
ตอนนี้เราเรียกสิ่งนี้ว่า "กระตุ้น" แต่ในปี 2020 ในขณะที่รายงานเผยแพร่ นี่เป็นแนวคิดที่ใหม่มาก
ภาพหลอนและการจัดตำแหน่ง
ปัญหาของ GPT-3 อย่างที่เรารู้ตอนนี้ก็คือการยึดติดกับคำแนะนำในข้อความอินพุตได้ไม่ดีนัก GPT-3 สามารถปฏิบัติตามคำแนะนำได้แต่จะสูญเสียความสนใจได้ง่าย สามารถเข้าใจได้เฉพาะคำแนะนำง่ายๆ และมีแนวโน้มที่จะปรุงแต่งสิ่งต่างๆ กล่าวอีกนัยหนึ่ง โมเดลไม่ “สอดคล้อง” กับความตั้งใจของเรา ดังนั้นปัญหาตอนนี้ไม่ได้เกี่ยวกับการปรับปรุงความสามารถทางภาษาของโมเดลมากนัก แต่เป็นความสามารถในการปฏิบัติตามคำแนะนำ
เป็นที่น่าสังเกตว่า GPT-3 ไม่เคยได้รับการฝึกฝนตามคำแนะนำจริงๆ ไม่ได้บอกว่าคำสั่งคืออะไร หรือแตกต่างจากข้อความอื่นๆ อย่างไร หรือควรปฏิบัติตามคำแนะนำอย่างไร ในทางหนึ่ง มันถูก "หลอก" ให้ทำตามคำแนะนำโดยให้ "สมบูรณ์" พร้อมท์เหมือนกับลำดับข้อความอื่นๆ ด้วยเหตุนี้ OpenAI จึงจำเป็นต้องฝึกโมเดลที่สามารถปฏิบัติตามคำสั่งได้ดีกว่ามนุษย์ และพวกเขาก็ทำเช่นนั้นในรายงานที่มีชื่อเหมาะเจาะว่า โมเดลภาษาการฝึกอบรมเพื่อปฏิบัติตามคำสั่งพร้อมความคิดเห็นของมนุษย์ ที่เผยแพร่เมื่อต้นปี 2022 InstructGPT จะพิสูจน์ให้เห็นแล้วว่าเป็นผู้นำของ ChatGPT ในปีเดียวกันนั้นเอง
ขั้นตอนที่ระบุไว้ในรายงานดังกล่าวยังใช้ในการฝึก ChatGPT อีกด้วย การฝึกอบรมการสอนมี 3 ขั้นตอนหลัก:
- ขั้นตอนที่ 1 - ปรับแต่ง GPT-3: เนื่องจาก GPT-3 ดูเหมือนจะทำงานได้ดีกับการเรียนรู้แบบไม่กี่ช็อต ความคิดก็คือ จะดีกว่าหากปรับแต่งอย่างละเอียดด้วยตัวอย่างการสอนคุณภาพสูง เป้าหมายคือเพื่อให้ง่ายต่อการปรับเจตนาในการสอนให้สอดคล้องกับการตอบสนองที่สร้างขึ้น ในการดำเนินการนี้ OpenAI ได้ให้ผู้ติดป้ายกำกับที่เป็นมนุษย์สร้างการตอบสนองต่อข้อความแจ้งบางอย่างที่ส่งโดยผู้ที่ใช้ GPT-3 ผู้เขียนหวังว่าจะจับภาพ "การกระจาย" งานที่ผู้ใช้พยายามให้ GPT-3 ดำเนินการได้โดยใช้คำแนะนำจริง สิ่งเหล่านี้ใช้เพื่อปรับแต่ง GPT-3 อย่างละเอียด เพื่อช่วยปรับปรุงความสามารถในการตอบสนองทันที
- ขั้นตอนที่ 2 - ให้มนุษย์จัดอันดับ GPT-3 ใหม่ที่ได้รับการปรับปรุง: เพื่อประเมินคำสั่งใหม่ที่ได้รับการปรับแต่ง GPT-3 ขณะนี้ผู้ติดป้ายกำกับได้ให้คะแนนประสิทธิภาพของโมเดลตามพร้อมท์ที่แตกต่างกันโดยไม่มีการตอบสนองที่กำหนดไว้ล่วงหน้า การจัดอันดับเกี่ยวข้องกับปัจจัยการจัดตำแหน่งที่สำคัญ เช่น เป็นประโยชน์ เป็นจริง และไม่เป็นพิษ มีอคติ หรือเป็นอันตราย ดังนั้นให้มอบหมายงานให้กับโมเดลและให้คะแนนประสิทธิภาพตามเกณฑ์ชี้วัดเหล่านี้ จากนั้นผลลัพธ์ของแบบฝึกหัดการจัดอันดับนี้จะนำไปใช้ในการฝึกแบบจำลองที่แยกจากกันเพื่อคาดการณ์ว่าผลลัพธ์ใดที่ผู้ติดฉลากน่าจะชอบ โมเดลนี้เรียกว่าโมเดลรางวัล (RM)
- ขั้นตอนที่ 3 – ใช้ RM เพื่อฝึกฝนตัวอย่างเพิ่มเติม: สุดท้าย RM ถูกใช้เพื่อฝึกฝนโมเดลการสอนใหม่เพื่อสร้างการตอบสนองที่ดีขึ้นซึ่งสอดคล้องกับความชอบของมนุษย์
เป็นเรื่องยากที่จะเข้าใจอย่างถ่องแท้ถึงสิ่งที่เกิดขึ้นที่นี่ด้วยการเรียนรู้แบบเสริมกำลังจากผลตอบรับของมนุษย์ (RLHF) โมเดลการให้รางวัล การอัปเดตนโยบาย และอื่นๆ
วิธีคิดง่ายๆ วิธีหนึ่งก็คือว่ามันเป็นเพียงวิธีที่ทำให้มนุษย์สามารถสร้างตัวอย่างที่ดีในการปฏิบัติตามคำแนะนำได้ ตัวอย่างเช่น ลองนึกถึงวิธีที่คุณจะพยายามสอนเด็กให้พูดคำขอบคุณ:
- ผู้ปกครอง: “เมื่อมีคนให้ X แก่คุณ คุณจะกล่าวขอบคุณ” นี่คือขั้นตอนที่ 1 ซึ่งเป็นชุดข้อมูลตัวอย่างของพร้อมท์และการตอบกลับที่เหมาะสม
- ผู้ปกครอง: “ตอนนี้คุณพูดอะไรกับ Y ที่นี่” นี่คือขั้นตอนที่ 2 ที่เราขอให้เด็กสร้างคำตอบ จากนั้นผู้ปกครองจะให้คะแนน “ใช่ นั่นเป็นสิ่งที่ดี”
- ในที่สุด ในการเผชิญหน้าครั้งต่อๆ ไป ผู้ปกครองจะให้รางวัลเด็กตามตัวอย่างการตอบสนองที่ดีและไม่ดีในสถานการณ์ที่คล้ายคลึงกันในอนาคต นี่คือขั้นตอนที่ 3 ซึ่งพฤติกรรมการเสริมกำลังเกิดขึ้น
ในส่วนของ OpenAI อ้างว่าสิ่งที่ทำคือเพียงปลดล็อกความสามารถที่มีอยู่แล้วในรุ่นเช่น GPT-3 "แต่ยากที่จะล้วงออกมาผ่านวิศวกรรมที่รวดเร็วเพียงอย่างเดียว" ตามที่รายงานระบุไว้
กล่าวอีกนัยหนึ่ง ChatGPT ไม่ได้เรียนรู้ความสามารถ " ใหม่ " จริงๆ แต่เป็นเพียงการเรียนรู้ " อินเทอร์เฟซ " ทางภาษาที่ดีกว่าเพื่อใช้งาน
ความมหัศจรรย์ของภาษา
ChatGPT ให้ความรู้สึกเหมือนก้าวกระโดดอย่างมหัศจรรย์ แต่จริงๆ แล้วเป็นผลมาจากความก้าวหน้าทางเทคโนโลยีอย่างอุตสาหะตลอดหลายทศวรรษ
เมื่อดูการพัฒนาที่สำคัญบางประการในด้าน AI และ NLP ในทศวรรษที่ผ่านมา เราจะเห็นได้ว่า ChatGPT "ยืนอยู่บนไหล่ของยักษ์ใหญ่" อย่างไร รุ่นก่อนๆ เรียนรู้ที่จะระบุความหมายของคำก่อน จากนั้นโมเดลต่อมาก็รวมคำเหล่านี้เข้าด้วยกัน และเราสามารถฝึกให้พวกเขาทำงานต่างๆ เช่น การแปลได้ เมื่อพวกเขาสามารถประมวลผลประโยคได้แล้ว เราก็ได้พัฒนาเทคนิคที่ทำให้โมเดลภาษาเหล่านี้สามารถประมวลผลข้อความได้มากขึ้นเรื่อยๆ และพัฒนาความสามารถในการนำการเรียนรู้เหล่านี้ไปใช้กับงานใหม่ๆ ที่ไม่คาดคิด จากนั้น ในที่สุดด้วย ChatGPT เราก็ได้พัฒนาความสามารถในการโต้ตอบกับโมเดลเหล่านี้ได้ดีขึ้นโดยระบุคำสั่งของเราในรูปแบบภาษาที่เป็นธรรมชาติ
“เนื่องจากภาษาเป็นพาหนะสำหรับความคิดของเรา การสอนคอมพิวเตอร์ด้วยพลังทางภาษาที่สมบูรณ์จะนำไปสู่ปัญญาประดิษฐ์ที่เป็นอิสระหรือไม่”
อย่างไรก็ตาม วิวัฒนาการของ NLP ได้เผยให้เห็นเวทมนตร์ที่ลึกซึ้งยิ่งขึ้นซึ่งเรามักจะมองไม่เห็น นั่นคือความมหัศจรรย์ของภาษาเอง และวิธีที่เราในฐานะมนุษย์ได้รับมันมา
ยังคงมีคำถามปลายเปิดและข้อโต้แย้งมากมายเกี่ยวกับวิธีการเรียนรู้ภาษาของเด็กตั้งแต่แรก นอกจากนี้ยังมีคำถามว่าทุกภาษามีโครงสร้างพื้นฐานร่วมกันหรือไม่ มนุษย์มีวิวัฒนาการในการใช้ภาษาหรือเป็นอย่างอื่น?
สิ่งที่น่าสงสัยก็คือ ขณะที่ ChatGPT และรุ่นต่อๆ ไปปรับปรุงการพัฒนาทางภาษา โมเดลเหล่านี้อาจช่วยตอบคำถามสำคัญบางข้อเหล่านี้ได้
ในที่สุด เนื่องจากภาษาเป็นพาหนะสำหรับความคิดของเรา การสอนคอมพิวเตอร์ด้วยพลังเต็มของภาษาจะนำไปสู่ปัญญาประดิษฐ์ที่เป็นอิสระหรือไม่ เช่นเคยในชีวิต ยังมีอะไรให้เรียนรู้อีกมาก
