
การแฮ็กกราฟหัวข้อด้วย Wikipedia และ Google Language API
เผยแพร่แล้ว: 2019-08-27หนึ่งในสไลด์เดอร์ที่ฉันโปรดปรานในช่วงสิบปีที่ผ่านมาทำโดย Mark Johnstone ในปี 2014 ในขณะที่เขายังคงอยู่กับ Distilled สำรับนี้มีชื่อว่า How to Produce Better Content Ideas และฉันใช้เป็นพระคัมภีร์ของฉันสองสามปีในขณะที่สร้างทีมเพื่อทำงานอย่างหนักในการโปรโมตเนื้อหา
แนวคิดหนึ่งที่เสนอคือการสร้างแผนที่ภาพของความเชื่อมโยงของคำที่เกี่ยวข้องกับผลิตภัณฑ์หรือแบรนด์ของคุณ เพื่อให้คุณสามารถยืนหยัดได้ และมองหาวิธีที่จะรวมความเชื่อมโยงเข้ากับสิ่งที่น่าสนใจ เป้าหมายคือการผลิตความคิด ซึ่งเขากำหนดให้เป็น " การผสมผสานที่แปลกใหม่ขององค์ประกอบที่ไม่เกี่ยวข้องก่อนหน้านี้ในลักษณะที่เพิ่มมูลค่า"
ในบทความนี้ เราใช้แนวทางสมองซีกซ้ายมากขึ้น โดยใช้ Python ซึ่งเป็น API ภาษาของ Google ร่วมกับ Wikipedia เพื่อสำรวจการเชื่อมโยงเอนทิตีที่มีอยู่จากหัวข้อตั้งต้น เป้าหมายคือมุมมองระดับสูงของความสัมพันธ์ของเอนทิตีตามกราฟหัวข้อ บทความนี้ไม่เหมาะสำหรับผู้อ่านทั่วไป ผู้อ่านที่คุ้นเคยกับ Python และมีความสามารถในการเขียนโค้ดขั้นพื้นฐานอย่างน้อยจะพบว่ามีประโยชน์มากกว่า
ความคิด
การติดตามแนวคิดการทำแผนที่ของ Mark Johnstone ฉันคิดว่ามันน่าสนใจที่จะให้ Google และ Wikipedia กำหนดโครงสร้างหัวข้อโดยเริ่มจากหัวข้อตั้งต้นหรือหน้าเว็บ เป้าหมายคือการสร้างแผนที่ของความสัมพันธ์กับหัวข้อหลักด้วยภาพ ในกราฟแบบต้นไม้ที่สามารถตรวจสอบได้เพื่อค้นหาคนรู้จักและอาจสร้างแนวคิดเกี่ยวกับเนื้อหา รูปภาพต่อไปนี้แสดงถึงแนวคิดการออกแบบเบื้องต้น
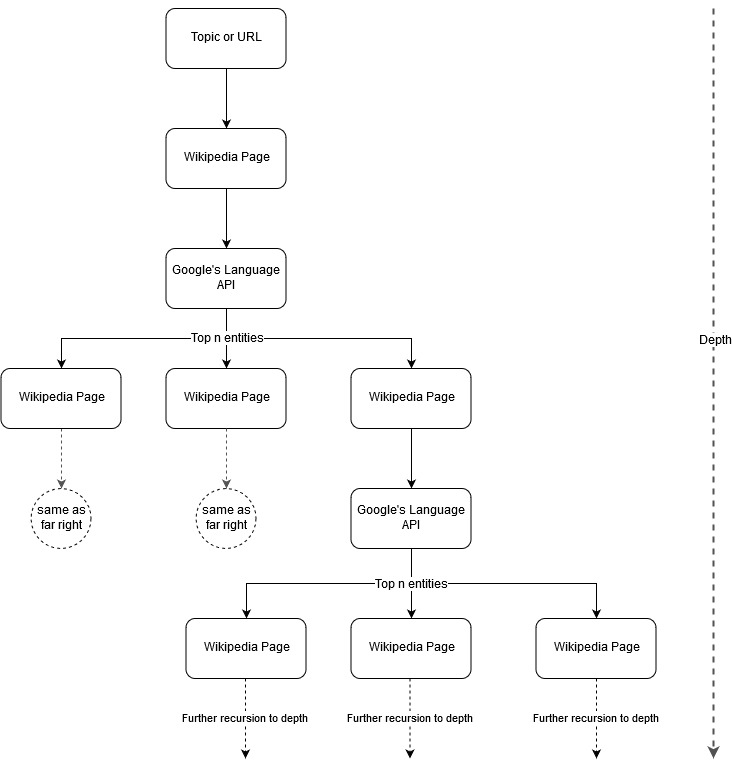
โดยพื้นฐานแล้ว เราให้หัวข้อหรือ URL แก่เครื่องมือ และให้ Language API ของ Google เลือกเอนทิตี n อันดับแรก (3 ในตัวอย่างของเรา) (ซึ่งรวมถึง Wikipedia URL) สำหรับแต่ละหน้าเอนทิตี และเรายังคงสร้างกราฟเครือข่ายสำหรับเอนทิตีที่พบแต่ละรายการซ้ำๆ จนถึงระดับความลึกสูงสุด
ความเป็นมาของเครื่องมือที่ใช้
Google ภาษา API
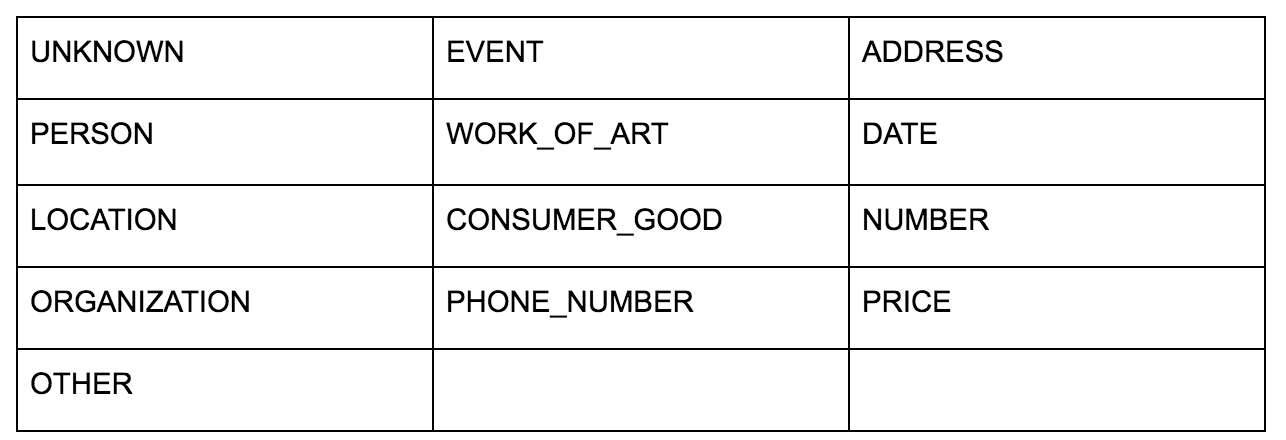
API ภาษาของ Google ช่วยให้คุณสามารถส่งผ่านข้อความธรรมดาหรือ HTML และส่งคืนเอนทิตีต่างๆ ทั้งหมดที่เกี่ยวข้องกับเนื้อหาได้อย่างน่าอัศจรรย์ API ทำได้มากกว่านี้ แต่สำหรับการวิเคราะห์นี้ เราจะเน้นเฉพาะส่วนนี้เท่านั้น นี่คือรายการประเภทของเอนทิตีที่ส่งคืน:
การระบุเอนทิตีเป็นส่วนพื้นฐานของการประมวลผลภาษาธรรมชาติ (NLP) มาเป็นเวลานาน และคำศัพท์ที่ถูกต้องสำหรับงานคือ Named Entity Recognition (NER) NER เป็นงานที่ยากเพราะคำหลายคำมีความหมายต่างกันตามบริบทที่ใช้ ดังนั้นเครื่องมือ NLP หรือ API ต้องเข้าใจบริบททั้งหมดที่อยู่รอบ ๆ คำเพื่อให้สามารถระบุได้อย่างถูกต้องว่าเป็นเอนทิตีเฉพาะ
ฉันได้ให้ภาพรวมโดยละเอียดของ API นี้ และโดยเฉพาะอย่างยิ่งเอนทิตีในบทความบน opensource.com หากคุณต้องการติดตามบริบทก่อนที่จะจบบทความนี้
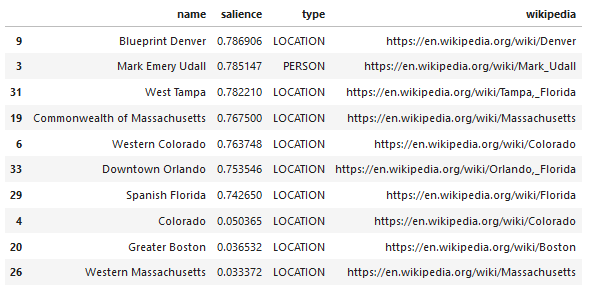
คุณลักษณะที่น่าสนใจอย่างหนึ่งของ API ภาษาของ Google คือนอกเหนือจากการค้นหาเอนทิตีที่เกี่ยวข้องแล้ว ยังทำเครื่องหมายว่าสัมพันธ์กับเอกสารโดยรวมอย่างไร (ความโดดเด่น) และสำหรับบางคน จะนำเสนอบทความ Wikipedia (กราฟความรู้) ที่เกี่ยวข้องซึ่งเป็นตัวแทนของเอนทิตี
นี่คือตัวอย่างผลลัพธ์ของสิ่งที่ API ส่งคืน (จัดเรียงตาม salience):
Oncrawl Developer
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมPython
Python เป็นภาษาซอฟต์แวร์ที่ได้รับความนิยมในพื้นที่วิทยาศาสตร์ข้อมูลเนื่องจากมีชุดไลบรารีขนาดใหญ่และกำลังเติบโตซึ่งทำให้ง่ายต่อการนำเข้า ล้าง จัดการ และวิเคราะห์ชุดข้อมูลขนาดใหญ่ นอกจากนี้ยังได้ประโยชน์จากสภาพแวดล้อมการทำงานร่วมกันที่เรียกว่าสมุดบันทึก Jupyter ซึ่งช่วยให้ผู้ใช้สามารถทดสอบและใส่คำอธิบายประกอบโค้ดได้อย่างง่ายดายด้วยวิธีที่ง่ายดาย
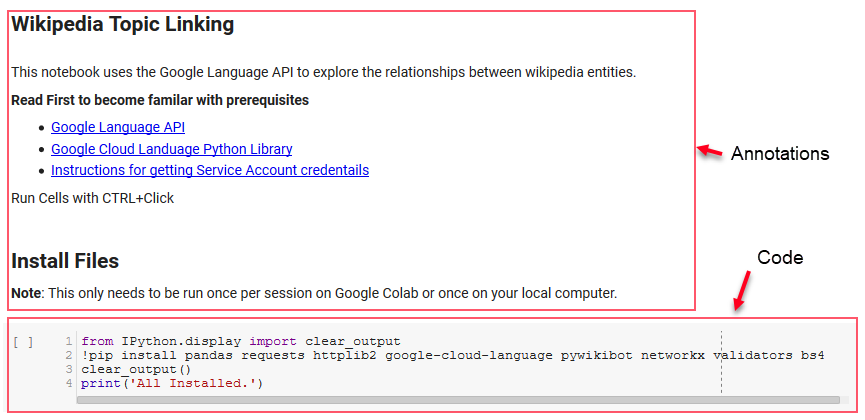
สำหรับรีวิวนี้ เราจะใช้ไลบรารีหลักสองสามแห่ง ซึ่งจะช่วยให้เราสามารถทำสิ่งที่น่าสนใจด้วยข้อมูล NLP ของ Google
- Pandas: ลองนึกถึงความสามารถในการเขียนสคริปต์ Microsoft Excel เพื่ออ่าน บันทึก แยกวิเคราะห์ หรือจัดเรียงสเปรดชีตใหม่ แล้วคุณก็จะเข้าใจว่า Pandas ทำอะไรได้บ้าง แพนด้าน่าทึ่งมาก (ลิงค์)
- Networkx: Networkx เป็นเครื่องมือสำหรับสร้างกราฟของโหนดและขอบที่กำหนดความสัมพันธ์ระหว่างโหนด นอกจากนี้ยังมีการสนับสนุนในตัวสำหรับการพล็อตกราฟเพื่อให้มองเห็นได้ง่าย (ลิงค์)
- Pywikibot: Pywikibot เป็นห้องสมุดที่ให้คุณโต้ตอบกับ Wikipedia เพื่อค้นหา แก้ไข ค้นหาความสัมพันธ์ ฯลฯ กับเนื้อหาทั้งหมดสำหรับแต่ละไซต์ Wikipedia (ลิงค์)
กระบวนการ
เรากำลังแชร์โน้ตบุ๊ก Google Colab ที่สามารถใช้ติดตามได้ (ขอขอบคุณเป็นพิเศษกับ Tyler Reardon สำหรับการตรวจสุขภาพจิตในบทความและสมุดบันทึกนี้)
การตั้งค่า
เซลล์สองสามเซลล์แรกในโน้ตบุ๊กจะจัดการกับการติดตั้งไลบรารี่ ทำให้ไลบรารีเหล่านั้นพร้อมใช้งานใน Python และการจัดเตรียมข้อมูลประจำตัวและไฟล์กำหนดค่าสำหรับ Language API และ Pywikibot ของ Google ตามลำดับ นี่คือไลบรารีทั้งหมดที่เราต้องติดตั้งเพื่อให้แน่ใจว่าเครื่องมือสามารถทำงานได้:
- หมีแพนด้า
- คำขอ
- httplib2
- google-cloud-language
- pywikibot
- เครือข่ายx
- ผู้ตรวจสอบความถูกต้อง
- Bs4
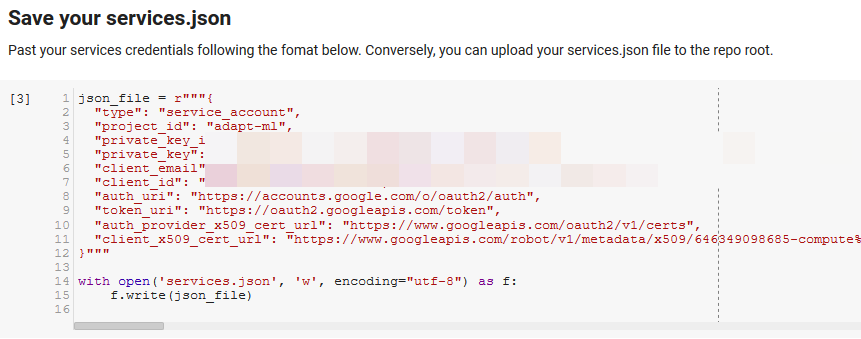
หมายเหตุ: ส่วนที่ยากที่สุดในการเรียกใช้สมุดบันทึกนี้คือการขอรับข้อมูลรับรองจาก Google เพื่อเข้าถึง API ของพวกเขา สำหรับผู้ที่ไม่มีประสบการณ์กับสิ่งนี้ จะใช้เวลาหนึ่งชั่วโมงหรือมากกว่านั้นในการคิดออก เราเชื่อมโยงคำแนะนำในการรับข้อมูลประจำตัวของบัญชีบริการที่ด้านบนของสมุดบันทึกเพื่อช่วยเหลือคุณ ด้านล่างนี้คือตัวอย่างวิธีที่เรารวมข้อมูลของเรา
ฟังก์ชันสำหรับ Win
ในเซลล์ที่ระบุโดย "กำหนดฟังก์ชันบางอย่างสำหรับ Google NLP" เราพัฒนาฟังก์ชันแปดฟังก์ชันที่จัดการสิ่งต่างๆ เช่น การสืบค้น API ของภาษา การโต้ตอบกับ Wikipedia การดึงข้อความของหน้าเว็บ การสร้างและการพล็อตกราฟ ฟังก์ชันคือหน่วยโค้ดขนาดเล็กโดยพื้นฐานแล้วซึ่งรับข้อมูลการตั้งค่าบางอย่าง ทำงานบางอย่าง และสร้างบางสิ่ง ฟังก์ชันทั้งหมดได้รับการแสดงความคิดเห็นเพื่อบอกตัวแปรที่พวกเขารับเข้ามา และสิ่งที่พวกเขาสร้างขึ้น

การทดสอบ API
สองเซลล์ต่อไปนี้ใช้ URL แยกข้อความออกจาก URL และดึงเอนทิตีจาก API ภาษาของ Google หนึ่งดึงเฉพาะเอนทิตีที่มี URL ของ Wikipedia และอีกอันหนึ่งดึงเอนทิตีทั้งหมดจากหน้านั้น
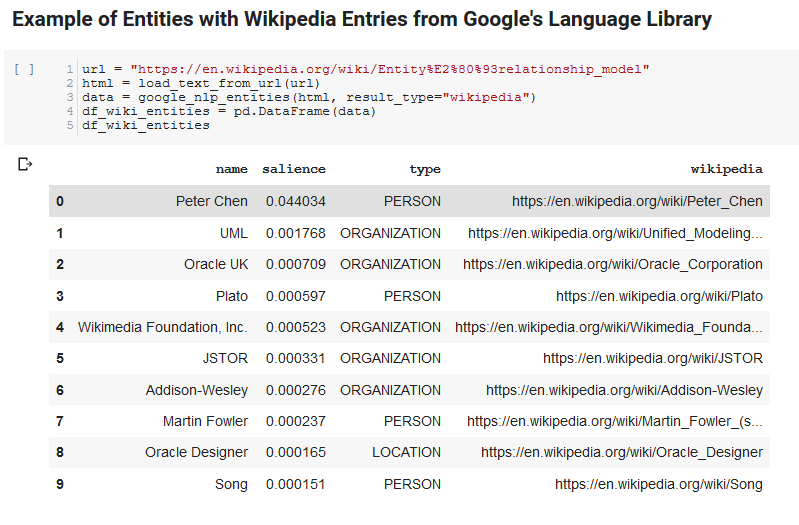
นี่เป็นขั้นตอนแรกที่สำคัญเพียงเพื่อให้ส่วนการแยกเนื้อหาถูกต้องและเข้าใจว่า API ของภาษาทำงานและส่งคืนข้อมูลอย่างไร
เครือข่ายx
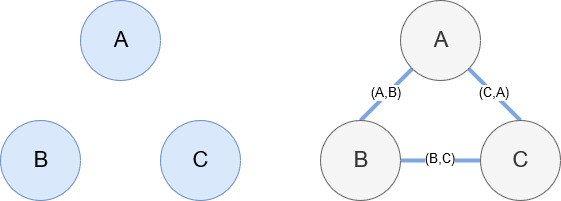
Networkx ดังที่กล่าวไว้ก่อนหน้านี้เป็นไลบรารีที่ยอดเยี่ยมที่ใช้งานง่ายพอสมควร โดยพื้นฐานแล้ว คุณต้องบอกว่าโหนดของคุณคืออะไร และเชื่อมต่อโหนดอย่างไร ตัวอย่างเช่น ในภาพด้านล่าง เราให้ Networkx สามโหนด (A,B,C) จากนั้นเราบอก Networkx ว่าพวกเขาเชื่อมต่อกันด้วยขอบ (A,B), (B,C), (C,A) ที่กำหนดความสัมพันธ์ระหว่างโหนด สำหรับการใช้งานของเรา เอนทิตีที่มี URL ของ Wikipedia จะเป็นโหนดและขอบถูกกำหนดโดยเอนทิตีใหม่ที่พบในหน้าเอนทิตีปัจจุบัน ดังนั้น หากเรากำลังตรวจสอบหน้า Wikipedia สำหรับ Entity A และในหน้านั้น Entity B จะถูกค้นพบ นั่นคือขอบระหว่าง Entity A และ Entity B
วางมันทั้งหมดเข้าด้วยกัน
ส่วนถัดไปของสมุดบันทึกนี้เรียกว่า Wikipedia Topic Branching โดย URL นี่คือที่ที่เวทมนตร์เกิดขึ้น เราได้กำหนดฟังก์ชันพิเศษ (recurse_entities) ไว้ก่อนหน้านี้ซึ่งเรียกซ้ำผ่านหน้าเว็บใน Wikipedia ตามเอนทิตีใหม่ที่กำหนดโดย API ภาษาของ Google นอกจากนี้เรายังได้เพิ่มฟังก์ชันที่เข้าใจยากจริงๆ (hierarchy_pos) ที่เรายกขึ้นจาก Stack Overflow ซึ่งนำเสนอกราฟที่เหมือนต้นไม้ที่มีโหนดจำนวนมากได้ดี ในเซลล์ด้านล่าง เรากำหนด อินพุต เป็น "Search Engine Optimization" และระบุ ความลึก 3 (นี่คือจำนวนหน้าที่ติดตามซ้ำ) และ ขีดจำกัด 3 (นี่คือจำนวนเอนทิตีที่ดึงต่อหน้า)
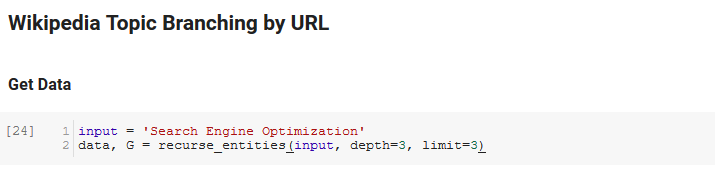
การเรียกใช้คำว่า "Search Engine Optimization" เราจะเห็นเส้นทางต่อไปนี้ที่เครื่องมือใช้ โดยเริ่มต้นที่หน้า Search Engine Optimization ของ Wikipedia (ระดับ 0) และตามด้วยหน้าซ้ำๆ จนถึงระดับความลึกสูงสุดที่ระบุ (3)

จากนั้นเราจะนำเอนทิตีที่พบทั้งหมดและเพิ่มลงใน Pandas DataFrame ซึ่งทำให้ง่ายต่อการบันทึกเป็น CSV เราจัดเรียงข้อมูลนี้ตามจุดสำคัญ (ซึ่งเป็นความสำคัญของเอนทิตีต่อหน้าเว็บที่พบ) แต่คะแนนนี้ทำให้เข้าใจผิดเล็กน้อยในบริบทนี้ เนื่องจากไม่ได้บอกคุณว่าเอนทิตีเกี่ยวข้องกับคำศัพท์เดิมของคุณอย่างไร (“ การเพิ่มประสิทธิภาพกลไกค้นหา”) เราจะทิ้งงานต่อไปให้ผู้อ่าน

สุดท้าย เราพล็อตกราฟที่สร้างโดยเครื่องมือเพื่อแสดงความเชื่อมโยงของเอนทิตีทั้งหมด ในเซลล์ด้านล่าง พารามิเตอร์ที่คุณส่งไปยังฟังก์ชันได้คือ: ( G : กราฟที่สร้างก่อนหน้าโดยฟังก์ชัน recurse_entities, w: ความกว้างของแผนภาพ h: ความสูงของแผนภาพ c: เปอร์เซ็นต์วงกลมของ พล็อตและ ชื่อไฟล์: ไฟล์ PNG ที่บันทึกลงในโฟลเดอร์รูปภาพ)

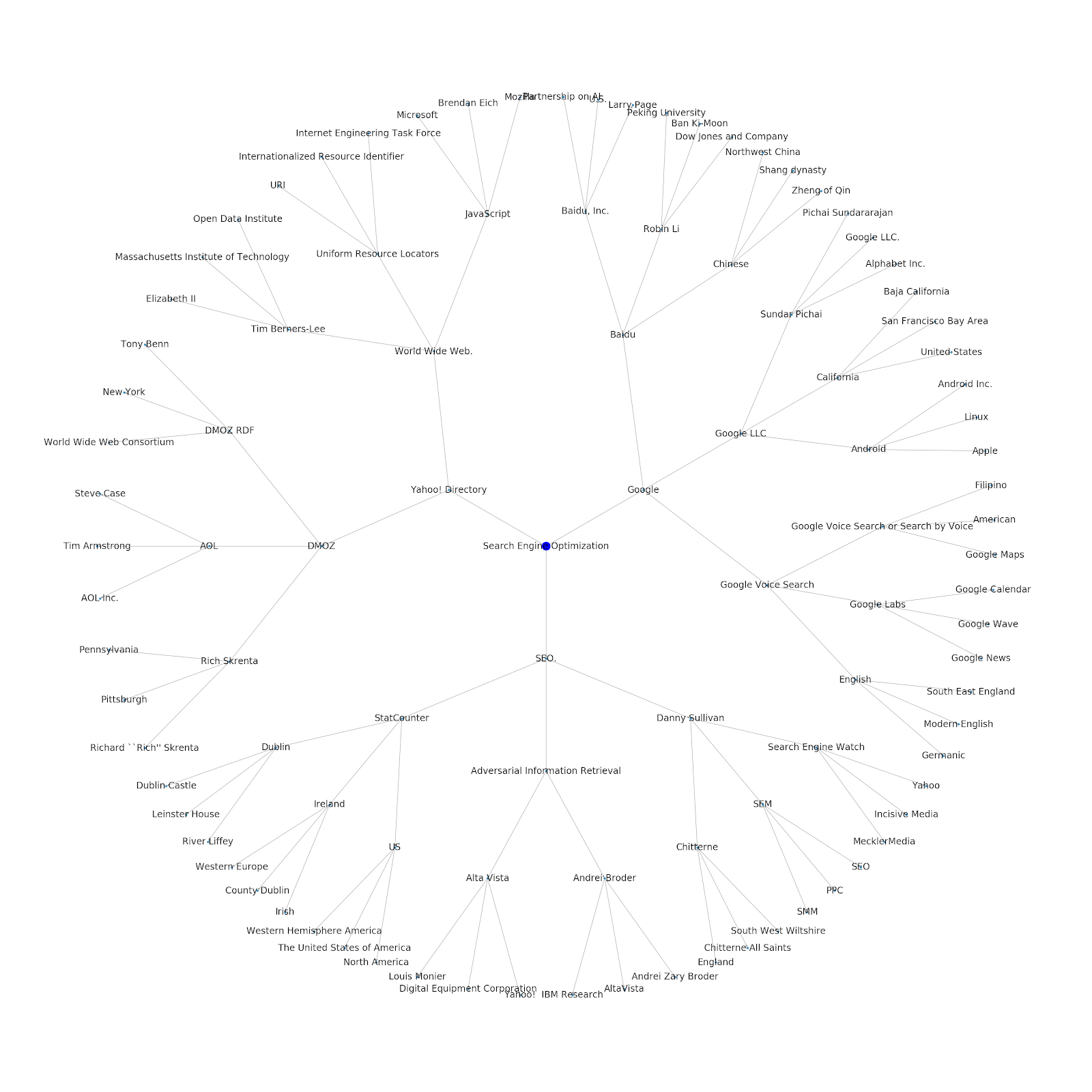
เราได้เพิ่มความสามารถในการกำหนดหัวข้อเริ่มต้นหรือ URL เมล็ดพันธุ์ ในกรณีนี้ เราจะดูเอนทิตีที่เกี่ยวข้องกับบทความ Google's Indexing Issues Continues Continue But This Is Different
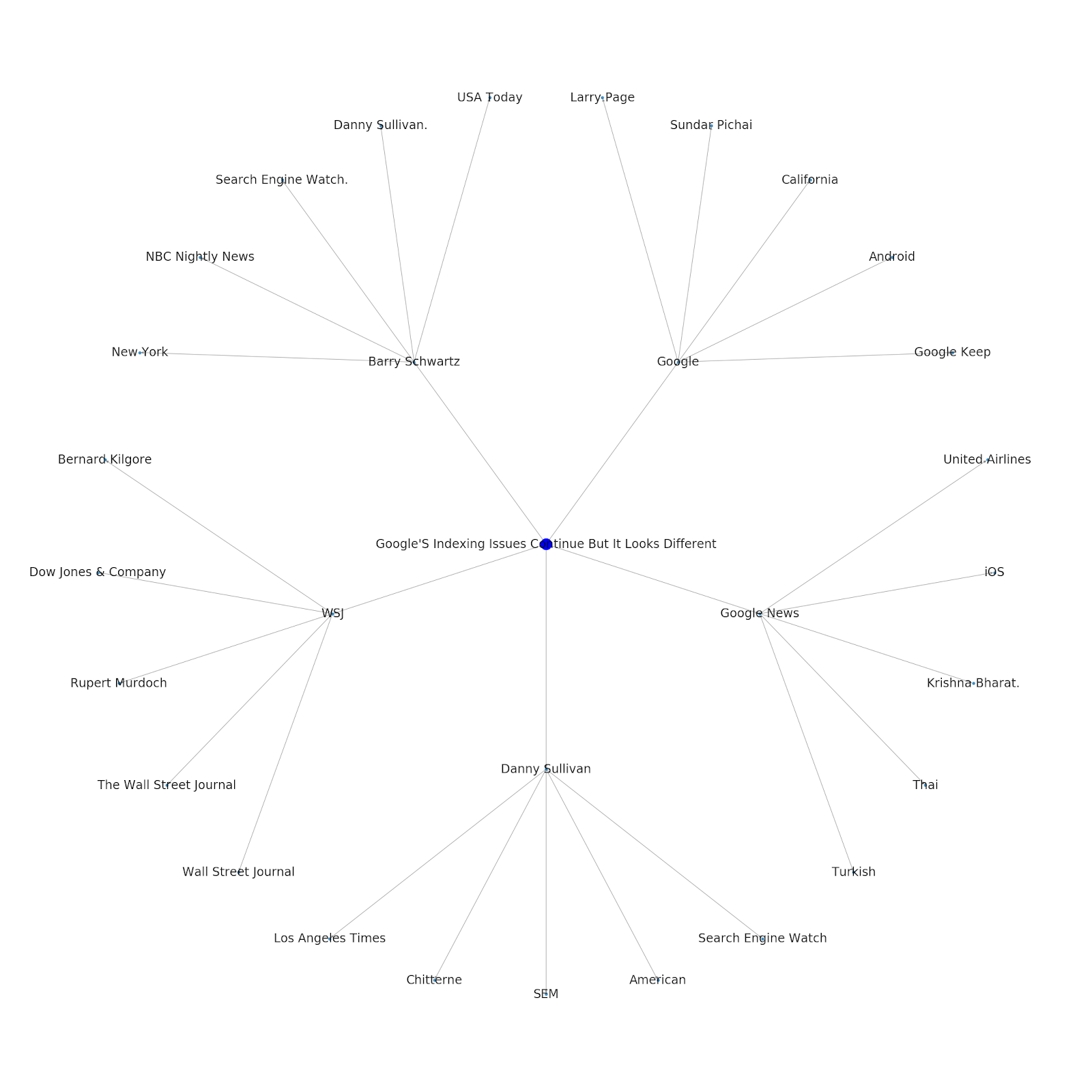
นี่คือกราฟเอนทิตี Google/Wikipedia สำหรับ Python
หมายความว่าอะไร
การทำความเข้าใจเกี่ยวกับชั้นหัวข้อของอินเทอร์เน็ตนั้นน่าสนใจจากมุมมองของ SEO เนื่องจากมันบังคับให้คุณคิดในแง่ของการเชื่อมต่อของสิ่งต่าง ๆ ไม่ใช่แค่การสืบค้นแต่ละรายการ เนื่องจาก Google ใช้เลเยอร์นี้เพื่อจับคู่กลุ่มความสนใจของผู้ใช้แต่ละรายกับหัวข้อ ดังที่กล่าวไว้ในการแนะนำ Google Discover อีกครั้ง จึงอาจกลายเป็นขั้นตอนการทำงานที่สำคัญมากขึ้นสำหรับ SEO ที่เน้นข้อมูล ในกราฟ "Python" ด้านบน อาจอนุมานได้ว่าความคุ้นเคยของผู้ใช้กับหัวข้อที่เกี่ยวข้องกับหัวข้อตั้งต้นอาจเป็นมาตรวัดระดับความเชี่ยวชาญของพวกเขาในหัวข้อตั้งต้นอย่างสมเหตุสมผล
ตัวอย่างด้านล่างแสดงผู้ใช้สองคนที่มีไฮไลท์สีเขียวซึ่งแสดงถึงความสนใจในอดีตหรือความเกี่ยวข้องกับหัวข้อที่เกี่ยวข้อง ผู้ใช้ทางด้านซ้าย การเข้าใจว่า IDE คืออะไร และเข้าใจว่า PyPy และ CPython หมายถึงอะไร จะเป็นผู้ใช้ที่มีประสบการณ์กับ Python มากกว่าคนที่รู้ว่ามันเป็นภาษา แต่ไม่มีอย่างอื่นมาก ซึ่งจะทำให้ง่ายต่อการเปลี่ยนเป็นคะแนนตัวเลขสำหรับแต่ละหัวข้อสำหรับผู้ใช้แต่ละคน

บทสรุป
เป้าหมายของฉันในวันนี้คือการแบ่งปันสิ่งที่เป็นกระบวนการมาตรฐานที่สวยงามที่ฉันทำเพื่อทดสอบและทบทวนประสิทธิภาพของเครื่องมือหรือ API ต่างๆ โดยใช้ Jupyter Notebooks การสำรวจกราฟหัวข้อนั้นน่าสนใจอย่างไม่น่าเชื่อ และเราหวังว่าคุณจะพบเครื่องมือที่แบ่งปันกันซึ่งจะช่วยให้คุณเริ่มต้นได้ตั้งแต่แรกเพื่อเริ่มสำรวจด้วยตัวคุณเอง ด้วยเครื่องมือเหล่านี้ คุณสามารถสร้างกราฟหัวข้อที่สำรวจความสัมพันธ์หลายระดับ โดยจำกัดแค่โควตาของ Google Language API เท่านั้น (ซึ่งก็คือ 800,000 ต่อวัน) (อัปเดต: ราคาขึ้นอยู่กับหน่วยของอักขระยูนิโค้ด 1,000 ตัวที่ส่งไปยัง API และให้ฟรีถึง 5,000 หน่วย เนื่องจากบทความ Wikipedia อาจมีความยาวได้ คุณจึงอยากดูการใช้จ่ายของคุณ คำแนะนำของ John Murch สำหรับการชี้ให้เห็นถึงสิ่งนี้) หากคุณปรับปรุงโน้ตบุ๊กหรือพบเคสที่น่าสนใจ ฉันหวังว่าคุณจะแจ้งให้เราทราบ คุณสามารถหาฉันได้ที่ @jroakes บน Twitter