
กุญแจสู่การสร้าง Robots.txt ที่ได้ผล
เผยแพร่แล้ว: 2020-02-18บอทหรือที่เรียกว่าโปรแกรมรวบรวมข้อมูลหรือแมงมุมเป็นโปรแกรมที่ "เดินทาง" ผ่านเว็บโดยอัตโนมัติจากเว็บไซต์หนึ่งไปอีกเว็บไซต์หนึ่งโดยใช้ลิงก์เป็นเส้นทาง แม้ว่าพวกเขาจะนำเสนอสิ่งที่น่าสนใจบางอย่างอยู่เสมอ แต่ไฟล์ robot.txt ก็สามารถเป็นเครื่องมือที่มีประสิทธิภาพมาก เครื่องมือค้นหาเช่น Google และ Bing ใช้บอทเพื่อรวบรวมข้อมูลเนื้อหาของเว็บ ไฟล์ robots.txt ให้คำแนะนำแก่บ็อตต่างๆ เกี่ยวกับหน้าที่ไม่ควรรวบรวมข้อมูลในไซต์ของคุณ คุณยังสามารถลิงก์ไปยังแผนผังเว็บไซต์ XML จาก robots.txt เพื่อให้บอทมีแผนที่ของทุกหน้าที่ควรรวบรวมข้อมูล
เหตุใด robots.txt จึงมีประโยชน์
robots.txt จำกัดจำนวนหน้าที่บอทต้องรวบรวมข้อมูลและจัดทำดัชนีในกรณีที่บอทของเครื่องมือค้นหา หากคุณต้องการหลีกเลี่ยง Google จากการรวบรวมข้อมูลหน้าผู้ดูแลระบบ คุณสามารถบล็อกหน้าเหล่านี้บน robots.txt ของคุณเพื่อพยายามไม่ให้หน้าเว็บออกจากเซิร์ฟเวอร์ของ Google
นอกเหนือจากการป้องกันไม่ให้หน้าเว็บได้รับการจัดทำดัชนีแล้ว robots.txt ยังเหมาะสำหรับการเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล งบประมาณการรวบรวมข้อมูลคือจำนวนหน้าที่ Google กำหนดว่าจะรวบรวมข้อมูลในเว็บไซต์ของคุณ โดยปกติ เว็บไซต์ที่มีอำนาจหน้าที่มากกว่าและจำนวนหน้ามากกว่าจะมีงบประมาณในการรวบรวมข้อมูลมากกว่าเว็บไซต์ที่มีจำนวนหน้าน้อยและมีอำนาจต่ำ เนื่องจากเราไม่ทราบว่ามีการกำหนดงบประมาณการรวบรวมข้อมูลให้กับไซต์ของเราเป็นจำนวนเท่าใด เราจึงต้องการใช้เวลานี้ให้เกิดประโยชน์สูงสุดโดยอนุญาตให้ Googlebot ไปที่หน้าที่สำคัญที่สุดแทนการรวบรวมข้อมูลหน้าที่เราไม่ต้องการให้จัดทำดัชนี
รายละเอียดที่สำคัญมากที่คุณต้องรู้เกี่ยวกับ robots.txt คือ แม้ว่า Google จะไม่รวบรวมข้อมูลหน้าเว็บที่ถูกบล็อกโดย robots.txt แต่ยังสามารถจัดทำดัชนีได้หากหน้านั้นเชื่อมโยงจากเว็บไซต์อื่น เพื่อป้องกันไม่ให้หน้าเว็บของคุณได้รับการจัดทำดัชนีและปรากฏในผลการค้นหาของ Google Search คุณต้องใช้รหัสผ่านป้องกันไฟล์บนเซิร์ฟเวอร์ของคุณ ใช้เมตาแท็ก noindex หรือส่วนหัวการตอบกลับ หรือลบหน้าเว็บทั้งหมด (ตอบกลับด้วย 404 หรือ 410) สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการรวบรวมข้อมูลและการควบคุมการสร้างดัชนี คุณสามารถอ่านคู่มือ robots.txt ของ OnCrawl
[กรณีศึกษา] การจัดการการรวบรวมข้อมูลบอทของ Google
 อ่านกรณีศึกษา
อ่านกรณีศึกษาแก้ไขไวยากรณ์ Robots.txt
ไวยากรณ์ของ robots.txt ในบางครั้งอาจมีความยุ่งยากเล็กน้อย เนื่องจากโปรแกรมรวบรวมข้อมูลต่างๆ ตีความไวยากรณ์ต่างกัน นอกจากนี้ โปรแกรมรวบรวมข้อมูลที่ไม่น่าเชื่อถือบางโปรแกรมยังมองว่าคำสั่งของ robots.txt เป็นคำแนะนำ ไม่ใช่กฎที่ชัดเจนว่าจำเป็นต้องปฏิบัติตาม หากคุณมีข้อมูลลับในเว็บไซต์ของคุณ สิ่งสำคัญคือต้องใช้การป้องกันด้วยรหัสผ่านนอกเหนือจากการบล็อกโปรแกรมรวบรวมข้อมูลโดยใช้ robots.txt
ด้านล่างนี้ ฉันได้ระบุบางสิ่งที่คุณต้องจำไว้เมื่อทำงานกับ robots.txt ของคุณ:
- ไฟล์ robots.txt ต้องอยู่ภายใต้โดเมนและไม่อยู่ภายใต้ไดเรกทอรีย่อย โปรแกรมรวบรวมข้อมูลไม่ตรวจสอบไฟล์ robots.txt ในไดเรกทอรีย่อย
- แต่ละโดเมนย่อยต้องมีไฟล์ robots.txt ของตัวเอง:
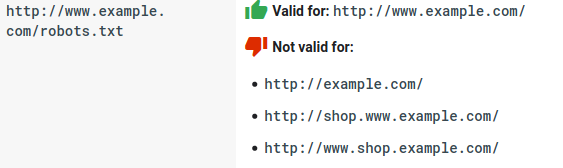
- Robots.txt คำนึงถึงขนาดตัวพิมพ์:
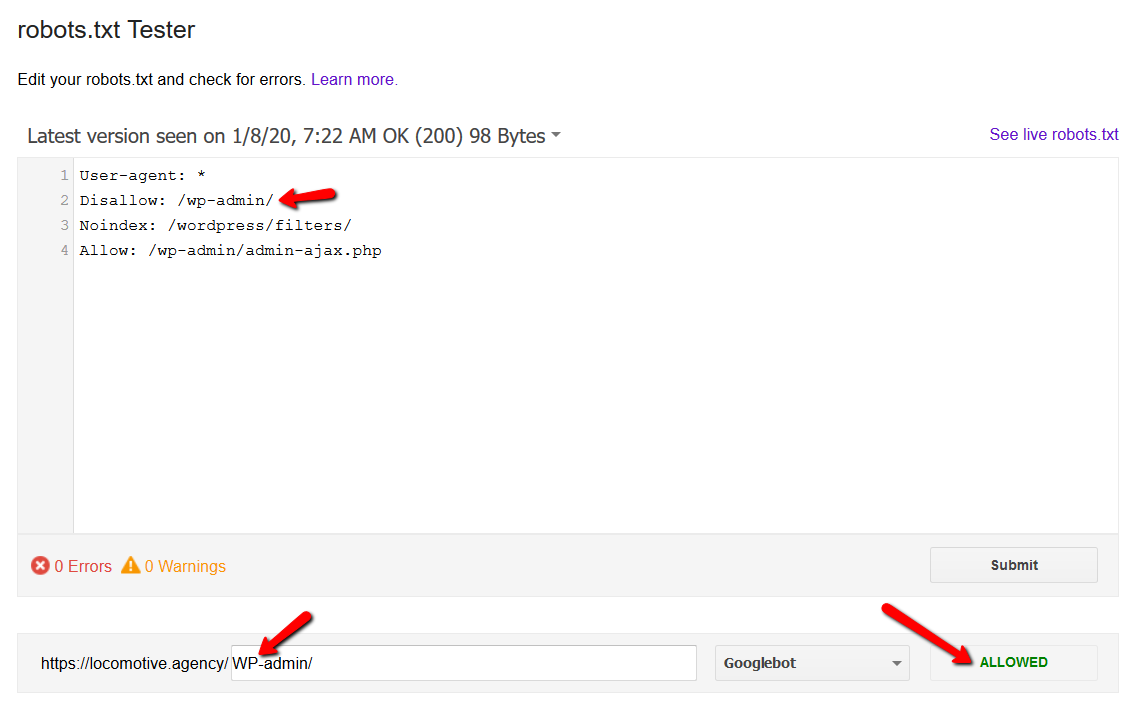
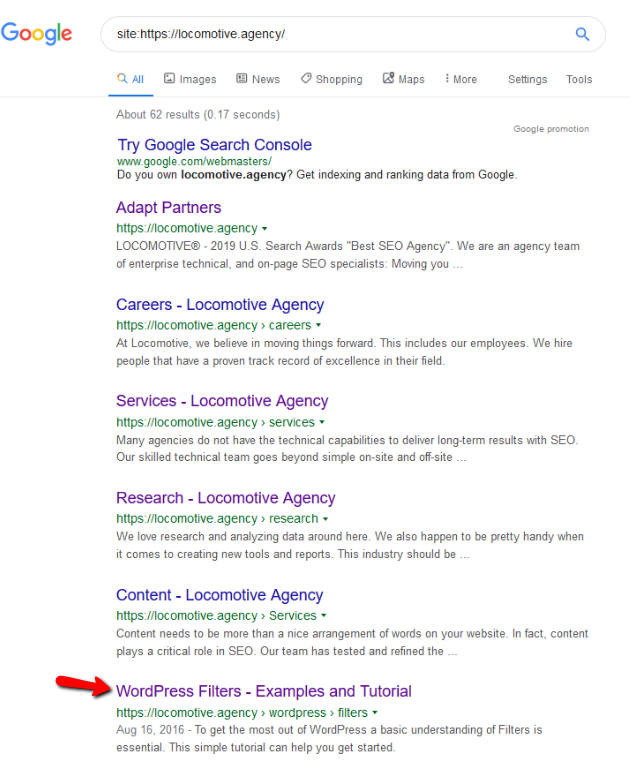
- คำสั่ง noindex: เมื่อคุณใช้ noindex ใน robots.txt คำสั่งจะทำงานในลักษณะเดียวกับที่ไม่อนุญาต Google จะหยุดรวบรวมข้อมูลหน้า แต่จะเก็บไว้ในดัชนี @jroakes และฉันสร้างการทดสอบโดยที่เราใช้คำสั่ง Noindex ในบทความ /wordpress/filters/ และส่งหน้าใน Google คุณสามารถดูได้จากภาพหน้าจอด้านล่างซึ่งแสดงว่า URL ถูกบล็อก:
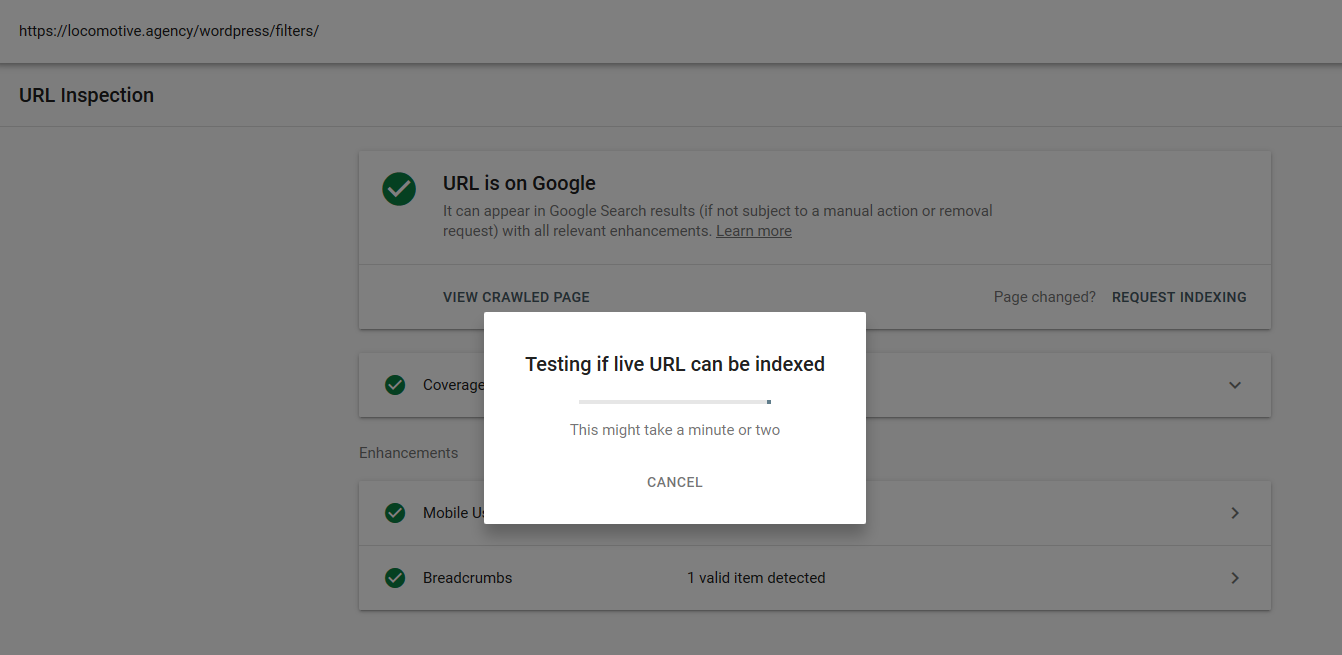
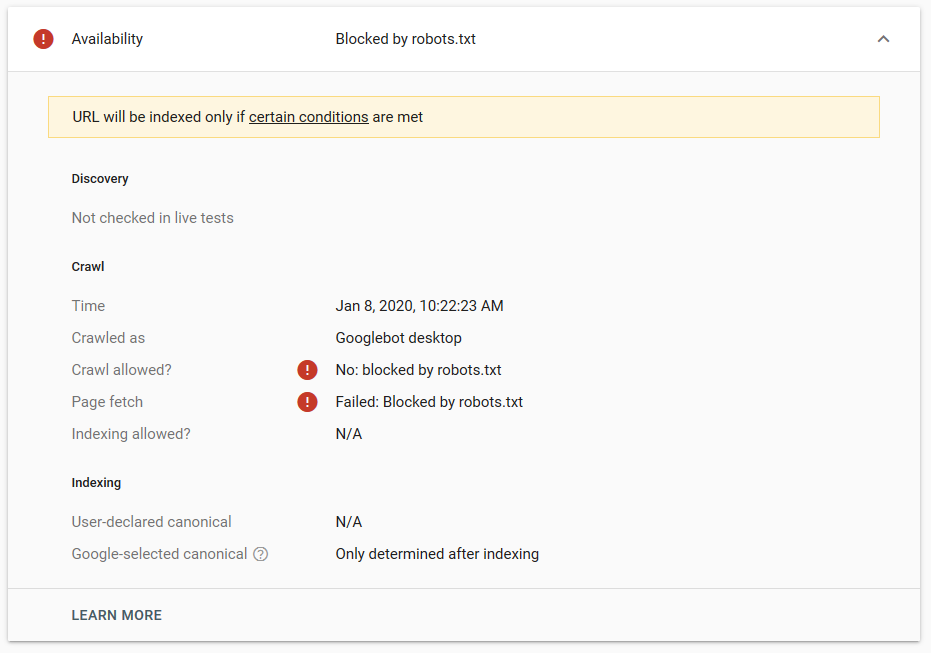
เราทำการทดสอบหลายครั้งใน Google และหน้านี้ไม่เคยถูกลบออกจากดัชนี:

ปีที่แล้วมีการพูดคุยกันเกี่ยวกับคำสั่ง noindex ที่ทำงานใน robots.txt โดยนำหน้าออกยกเว้น Google นี่คือกระทู้ที่ Gary Illyes บอกว่ามันกำลังจะจากไป ในการทดสอบนี้ เราจะเห็นได้ว่าโซลูชันของ Google ใช้งานได้แล้ว เนื่องจากคำสั่ง noindex ไม่ได้ลบหน้าออกจากผลการค้นหา
เมื่อเร็วๆ นี้ มีอีกกระทู้ที่น่าสนใจบนทวิตเตอร์จาก Christian Oliveira ซึ่งเขาได้แบ่งปันรายละเอียดหลายประการที่ควรพิจารณาเมื่อทำงานกับ robots.txt ของคุณ
- หากเราต้องการให้มีกฎและกฎทั่วไปสำหรับ Googlebot เท่านั้น เราจำเป็นต้องทำซ้ำกฎทั่วไปทั้งหมดภายใต้ User-agent: ชุดกฎของบ็อต Google หากไม่รวมอยู่ในนี้ Googlebot จะไม่สนใจกฎทั้งหมด:

- พฤติกรรมที่สับสนอีกประการหนึ่งคือลำดับความสำคัญของกฎ (ภายในกลุ่ม User-agent เดียวกัน) ไม่ได้ถูกกำหนดโดยลำดับ แต่ตามความยาวของกฎ
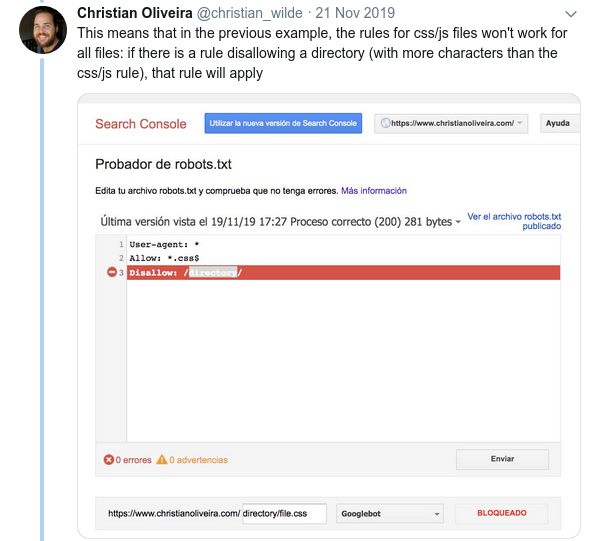
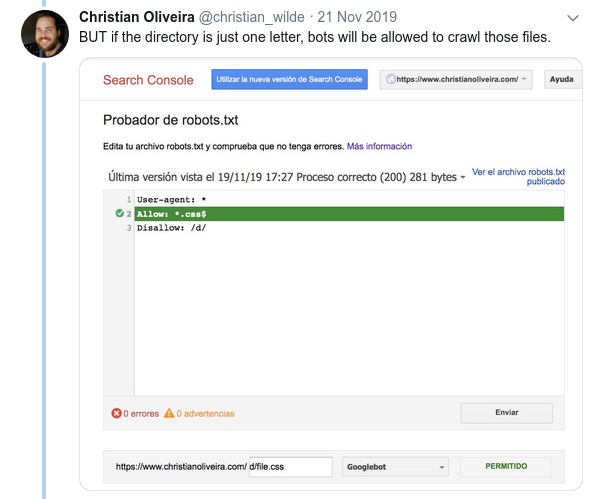
- ตอนนี้ เมื่อคุณมีกฎสองข้อที่มีความยาวเท่ากันและมีพฤติกรรมตรงกันข้าม (อันหนึ่งอนุญาตให้รวบรวมข้อมูลและอีกกฎหนึ่งไม่อนุญาต) กฎที่จำกัดน้อยกว่าจะมีผลบังคับใช้:
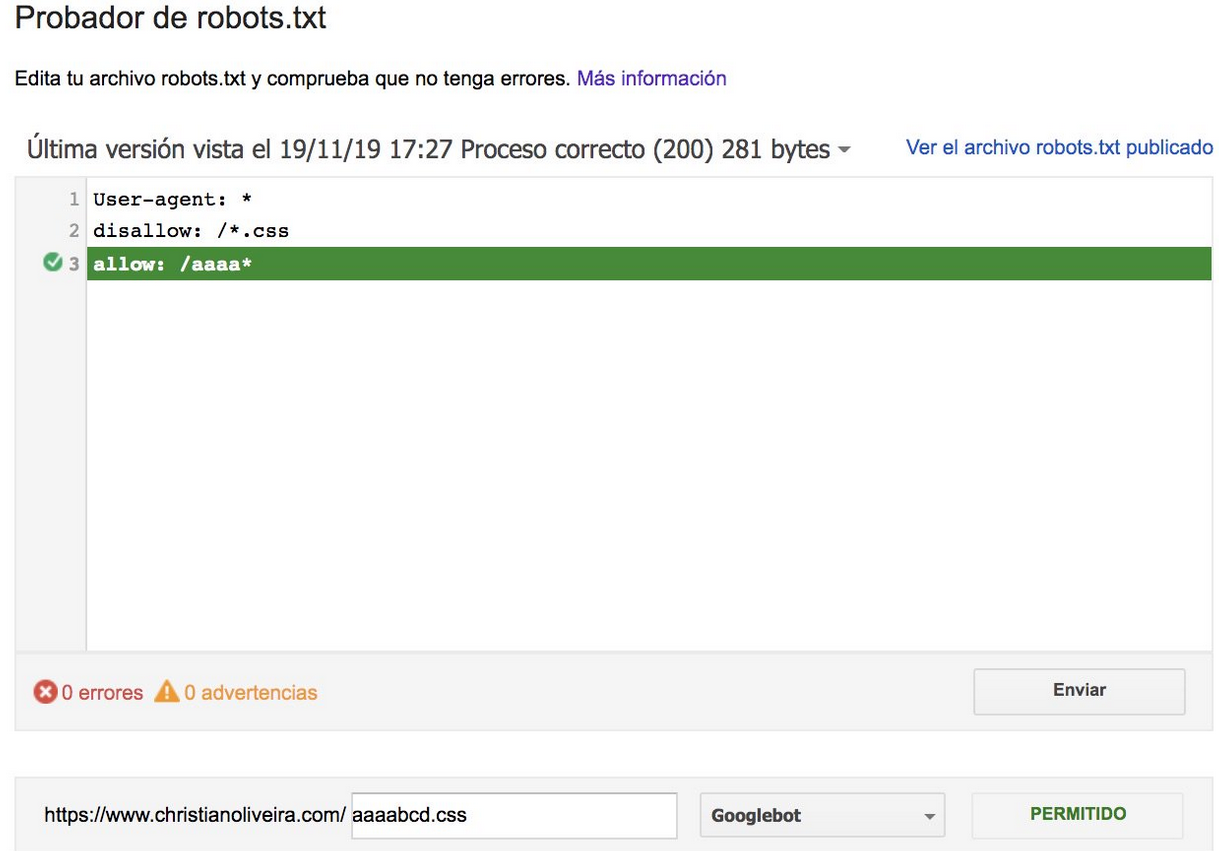
สำหรับตัวอย่างเพิ่มเติม โปรดอ่านข้อกำหนดของ robots.txt ที่ Google ให้มา
เครื่องมือสำหรับทดสอบ Robots.txt . ของคุณ
หากคุณต้องการทดสอบไฟล์ robots.txt มีเครื่องมือหลายอย่างที่สามารถช่วยคุณได้ และยังมีที่เก็บ github อีกสองสามแห่ง หากคุณต้องการสร้างไฟล์ของคุณเอง:
- กลั่น
- Google ได้ออกจากเครื่องมือทดสอบ robots.txt จาก Google Search Console เก่าที่นี่
- บน Python
- บน C++
ผลลัพธ์ตัวอย่าง: การใช้ Robots.txt สำหรับอีคอมเมิร์ซอย่างมีประสิทธิภาพ
ด้านล่างนี้ ฉันได้รวมกรณีที่เรากำลังทำงานกับไซต์ Magento ที่ไม่มีไฟล์ robots.txt Magento และ CMS อื่นๆ มีหน้าผู้ดูแลระบบและไดเรกทอรีที่มีไฟล์ที่เราไม่ต้องการให้ Google รวบรวมข้อมูล ด้านล่างนี้ เราได้รวมตัวอย่างของไดเร็กทอรีบางส่วนที่เรารวมไว้ใน robots.txt:
# # ไดเรกทอรีวีโอไอพีทั่วไป ไม่อนุญาต: / แอพ / ไม่อนุญาต: / ผู้ดาวน์โหลด / ไม่อนุญาต: / ข้อผิดพลาด / ไม่อนุญาต: / รวมถึง / ไม่อนุญาต: / lib / ไม่อนุญาต: / pkginfo / ไม่อนุญาต: / เปลือก / ไม่อนุญาต: / var / # # อย่าสร้างดัชนีหน้าการค้นหาและหมวดหมู่ลิงก์ที่ไม่ได้รับการปรับให้เหมาะสม ไม่อนุญาต: /catalog/product_compare/ ไม่อนุญาต: /catalog/category/view/ ไม่อนุญาต: /catalog/product/view/ ไม่อนุญาต: /catalog/product/gallery/ ไม่อนุญาต: /catalogsearch/
หน้าเว็บจำนวนมากที่ไม่ได้ตั้งใจให้รวบรวมข้อมูลมีผลกระทบต่องบประมาณการรวบรวมข้อมูล และ Googlebot ไม่ได้รวบรวมข้อมูลหน้าผลิตภัณฑ์ทั้งหมดบนไซต์
คุณสามารถดูได้จากภาพด้านล่างว่าหน้าที่จัดทำดัชนีเพิ่มขึ้นหลังจากวันที่ 25 ตุลาคม ซึ่งเป็นช่วงที่มีการนำ robots.txt ไปใช้อย่างไร:
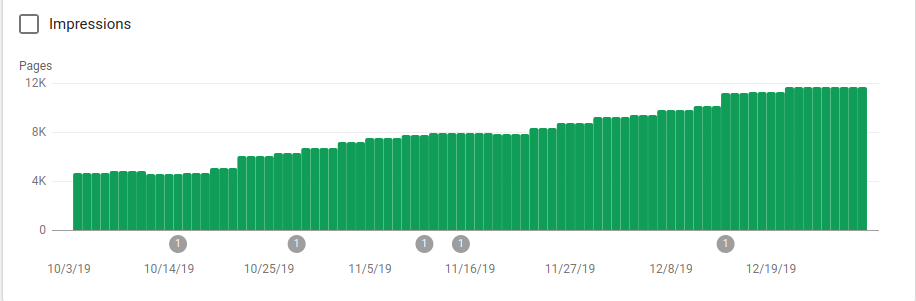
นอกจากการบล็อกไดเร็กทอรีหลายอันที่ไม่ได้ตั้งใจให้รวบรวมข้อมูลแล้ว โรบ็อตยังรวมลิงก์ไปยังแผนผังเว็บไซต์ด้วย ในภาพหน้าจอด้านล่าง คุณสามารถดูจำนวนหน้าที่จัดทำดัชนีเพิ่มขึ้นเมื่อเปรียบเทียบกับหน้าที่แยกออก:
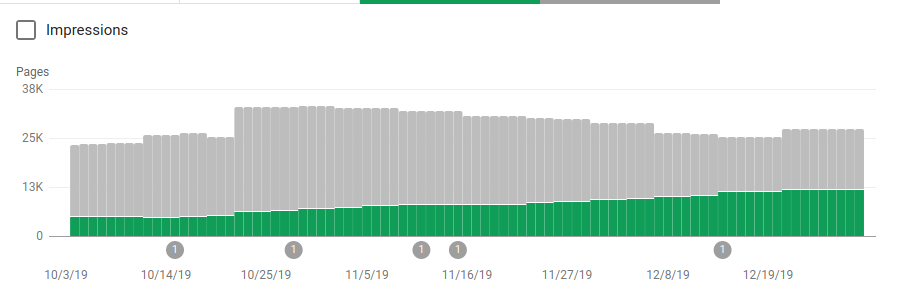
มีแนวโน้มเชิงบวกในหน้าที่ถูกต้องที่จัดทำดัชนีตามที่แสดงโดยแถบสีเขียวและแนวโน้มเชิงลบในหน้าที่ถูกยกเว้นซึ่งแสดงโดยแถบสีเทา
ห่อ
ความสำคัญของ robots.txt ในบางครั้งอาจถูกมองข้ามไป และอย่างที่คุณเห็นจากโพสต์นี้มีรายละเอียดมากมายที่ต้องพิจารณาเมื่อสร้าง แต่งานก็ออกมาดี: ฉันได้แสดงผลลัพธ์เชิงบวกบางประการที่คุณจะได้รับจากการตั้งค่า robots.txt อย่างถูกต้อง