
วิธีสร้างตัวอย่างข้อมูลในยุคของ Google ในฐานะผู้เผยแพร่
เผยแพร่แล้ว: 2019-10-22Google มองว่าตัวเองเป็นผู้เผยแพร่เนื้อหามาเป็นเวลานานแล้ว แม้ว่าในช่วงไม่กี่ปีมานี้ แนวโน้มดังกล่าวได้กลายเป็นเรื่องยากที่จะเพิกเฉย ส่วนหนึ่งได้รับการอำนวยความสะดวกโดยความก้าวหน้าในการเรียนรู้ของเครื่องและโดยคุณลักษณะหน้าผลลัพธ์ของเครื่องมือค้นหา (SERP) ใหม่
“Google ในฐานะผู้เผยแพร่เนื้อหา” เป็นปัญหาที่อาจเกิดขึ้นสำหรับเจ้าของเว็บไซต์จำนวนมาก เนื่องจากเป็นตัวเลือกที่ยาก คุณควร:
- ปกป้องเนื้อหาของคุณและเสี่ยงต่อการถูกปิดไม่ให้ผลการค้นหาของ Google?
- ให้แหล่งที่มาของเนื้อหาฟรีแก่ Google โดยรู้ว่า Google อาจไม่ส่งผู้เยี่ยมชมไซต์ของคุณใช่หรือไม่
แท็กการจัดการข้อมูลโค้ดใหม่ที่มีผลบังคับใช้ปลายเดือนตุลาคม 2019 ถือได้ว่าเป็นการประกาศเจตนาโดย Google พวกเขายังเป็นขั้นตอนในทิศทางที่ถูกต้องในการให้เจ้าของเว็บไซต์มีวิธีการในการปกป้องเนื้อหาของพวกเขาและเพื่อควบคุมว่าหน้าของพวกเขาจะปรากฏใน SERP อย่างไร
ทำไมต้องกังวลเกี่ยวกับเนื้อหาที่มีคุณภาพ?
คุณสมบัติของ Google ยังคงให้ปริมาณการเข้าชมเว็บไซต์ประมาณ 60% ขึ้นอยู่กับประเภทธุรกิจ ดังนั้นการไม่เล่นเกมของ Google อาจส่งผลเสียอย่างใหญ่หลวงต่อการมองเห็นและการรับส่งข้อมูลของเว็บไซต์ แต่ในขณะเดียวกัน ทาง EAT และ Quality Rater Guidelines นั้น Google ได้กำหนดไว้อย่างชัดเจนว่าเนื้อหาที่มีคุณภาพคือสิ่งที่ผู้ใช้อินเทอร์เน็ตกำลังมองหา และเว็บไซต์นั้นต้องลงทุนเพื่อผลิตเนื้อหาดังกล่าวเพื่อความอยู่รอด
การลงทุนในเนื้อหาที่ไม่ซ้ำใครและมีคุณภาพสูงนั้นเป็นสิ่งที่เจ้าของเว็บไซต์ควรปกป้องโดยธรรมชาติ ในการแจกเนื้อหา เว็บไซต์อนุญาตให้ผู้ให้บริการรายอื่น (ในกรณีนี้คือ เสิร์ชเอ็นจิ้น) ทำกำไรจากเวลา เงิน และความเชี่ยวชาญของพวกเขา
Google ใช้เนื้อหาอย่างไร
Google ใช้ รีมิกซ์ และเขียนเนื้อหาใหม่เพื่อตอบคำถามของผู้ใช้เครื่องมือค้นหา คำตอบเหล่านี้แสดงอยู่ใน SERP หลายรูปแบบ
รายการผลการค้นหาหรือ "ตัวอย่าง"
Google จัดทำข้อมูลโค้ดสำหรับหน้าเว็บที่ระบุในผลการค้นหาโดยใช้องค์ประกอบต่างๆ ที่แต่เดิมมาจากหน้าเว็บเอง:
- <title> แท็ก
- <meta description=”Snippet text”> tag
- มาร์กอัป Schema.org สำหรับข้อมูลที่มีโครงสร้างที่รองรับ
- URL
- Favicon (ในผลการค้นหาบนมือถือในบางภูมิภาค)
ทุกวันนี้ มีเพียงไม่กี่รายการที่ใช้ตามที่เป็นอยู่ Google ขอสงวนสิทธิ์ในการเปลี่ยนไอคอน Fav Google ระบุอย่างชัดเจนว่า “การสร้างชื่อและคำอธิบายของหน้านั้นเป็นไปโดยอัตโนมัติอย่างสมบูรณ์ และ … [Google ใช้] แหล่งข้อมูลที่แตกต่างกันจำนวนหนึ่งสำหรับข้อมูลนี้ รวมถึงข้อมูลอธิบายในชื่อและเมตาแท็กสำหรับแต่ละหน้า” ในที่สุด Google ได้เริ่มระงับ URL ใน SERP ตามที่เห็นในการทดสอบล่าสุด
Google การลบ URL ใน SERP อาจช่วย TLD ที่ "ไม่ดี" ได้เล็กน้อย
หากคุณไม่สามารถบอกได้ว่ามันเป็น .io, .org, .net, .ie ฯลฯ หรือไม่ คุณไม่สามารถอคติกับพวกเขาและคลิก .com ที่ดูถูกกฎหมายมากกว่า อาจไม่ใช่ผลกระทบที่ยิ่งใหญ่ แต่อาจเป็นผลกระทบที่ละเอียดอ่อนซึ่งจะยิ่งใหญ่ขึ้นเมื่อเวลาผ่านไป pic.twitter.com/CcQ2E0lVtZ
– Ross Hudgens (@RossHudgens) วันที่ 21 ตุลาคม 2019
ตัวอย่างแนะนำ
Google สร้างตัวอย่างข้อมูลแนะนำ ซึ่งปรากฏก่อนรายการผลการค้นหา โดยแยกเนื้อหาจากหน้าเว็บที่ดูเหมือนจะตอบคำถามของผู้ค้นหา ตัวอย่างข้อมูลแนะนำมีหลายตอนปรากฏขึ้นโดยไม่มีการระบุแหล่งที่มา (หรือไม่มีการแสดงที่มาที่มองเห็นได้หรือเข้าถึงได้ง่าย) ในเดือนกุมภาพันธ์และมิถุนายน 2019 ในแต่ละกรณี Google ได้ประณามความตั้งใจที่จะข้ามสิทธิ์ของผู้จัดพิมพ์และอ้างว่าไม่มีการระบุแหล่งที่มา ข้อผิดพลาด
คำจำกัดความ สภาพอากาศ และอาหาร
การค้นหาคำจำกัดความของพจนานุกรมหรือสภาพอากาศในสถานที่เฉพาะจะให้คำตอบในช่องเติมข้อความอัตโนมัติ โดยไม่มีการระบุแหล่งที่มา และไม่จำเป็นต้องดำเนินการค้นหา
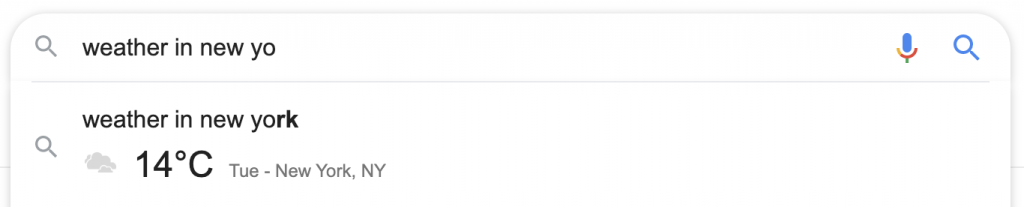
ในกรณีของคำจำกัดความ หากกดปุ่มค้นหา คำจำกัดความแบบเต็มพร้อมเสียง คำพ้องความหมาย และคุณสมบัติอื่นๆ ใน SERP จะพร้อมใช้งาน ผู้ค้นหาไม่จำเป็นต้องไปที่ไซต์พจนานุกรมของ Oxford และการระบุแหล่งที่มาของ Oxford จะปรากฏเป็นข้อความสีเทาขนาดเล็กด้านล่างช่องคำจำกัดความ
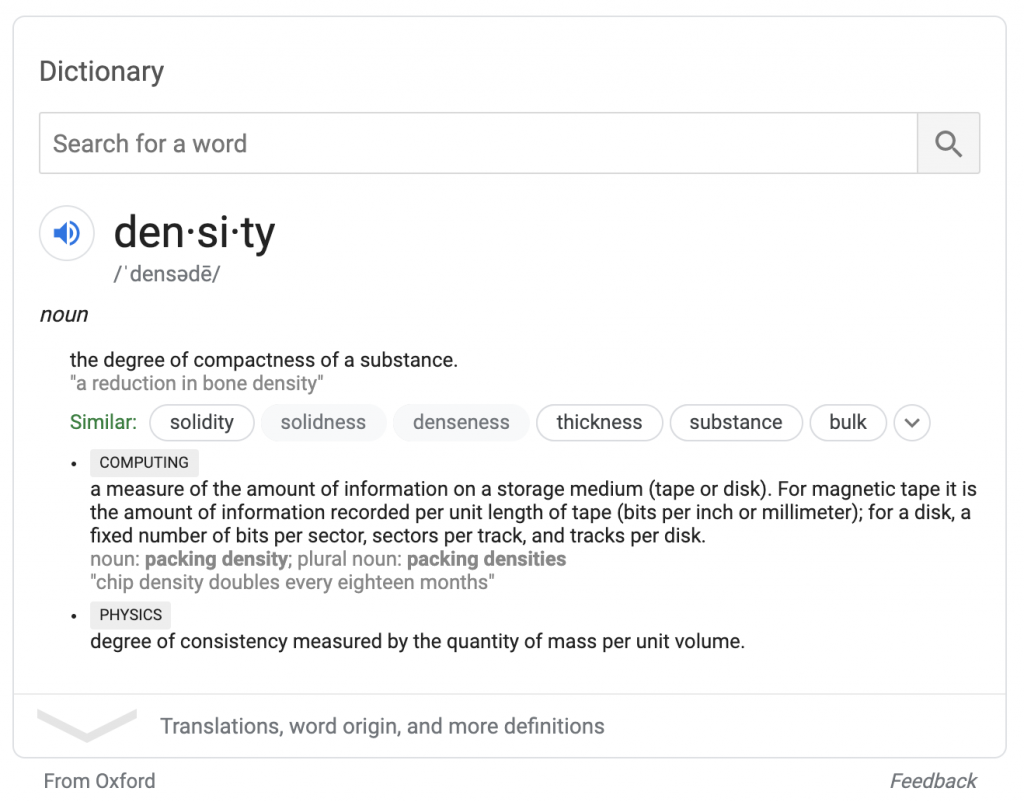
การค้นหาสภาพอากาศที่สมบูรณ์จะมีช่องพยากรณ์อากาศที่คล้ายกันตามข้อมูลจาก weather.com เช่นเดียวกับการระบุแหล่งที่มาของ Oxford การระบุแหล่งที่มาของ weather.com จะปรากฏด้านล่างช่อง ผู้ค้นหาสามารถโต้ตอบกับข้อมูลในกล่องโดยไม่ต้องไปที่ weather.com
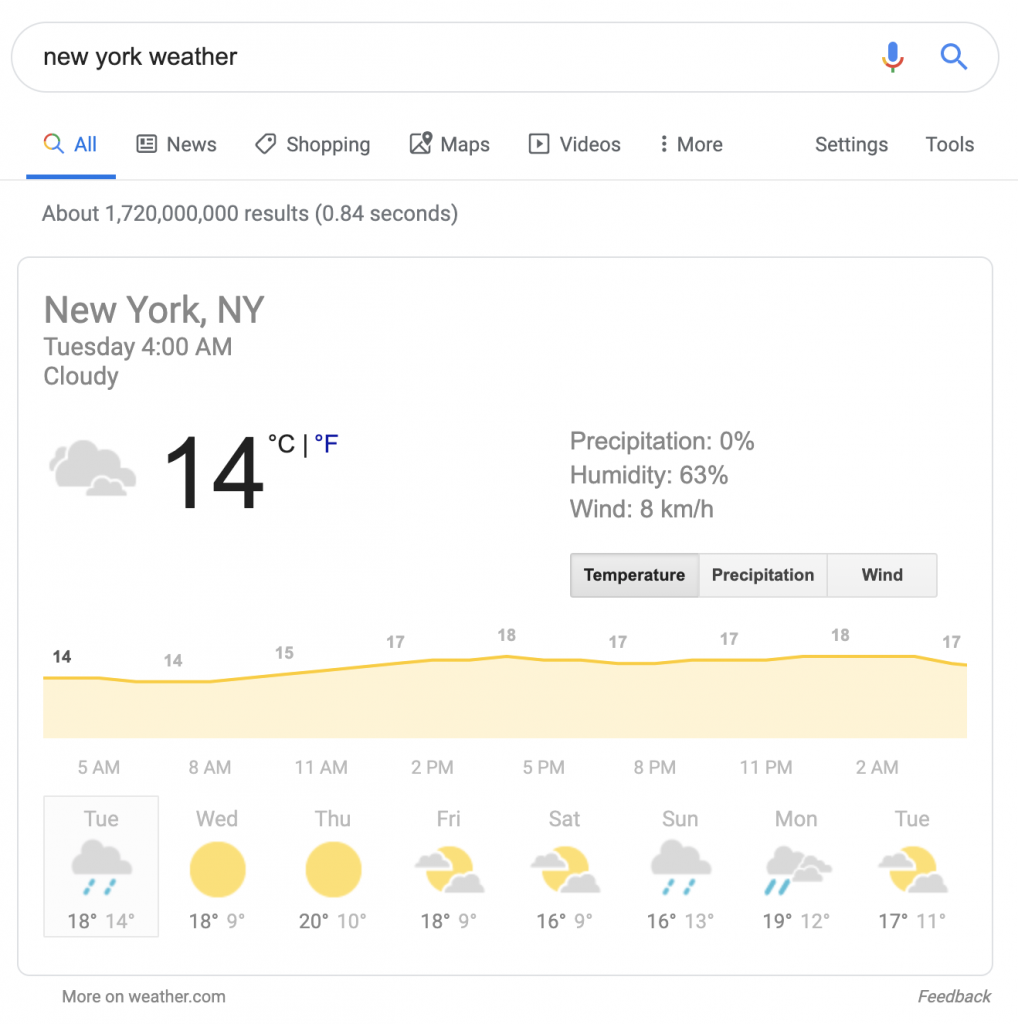
ผลการค้นหาที่คล้ายกันอีกรายการคือข้อมูลทางโภชนาการและองค์ประกอบอาหาร:
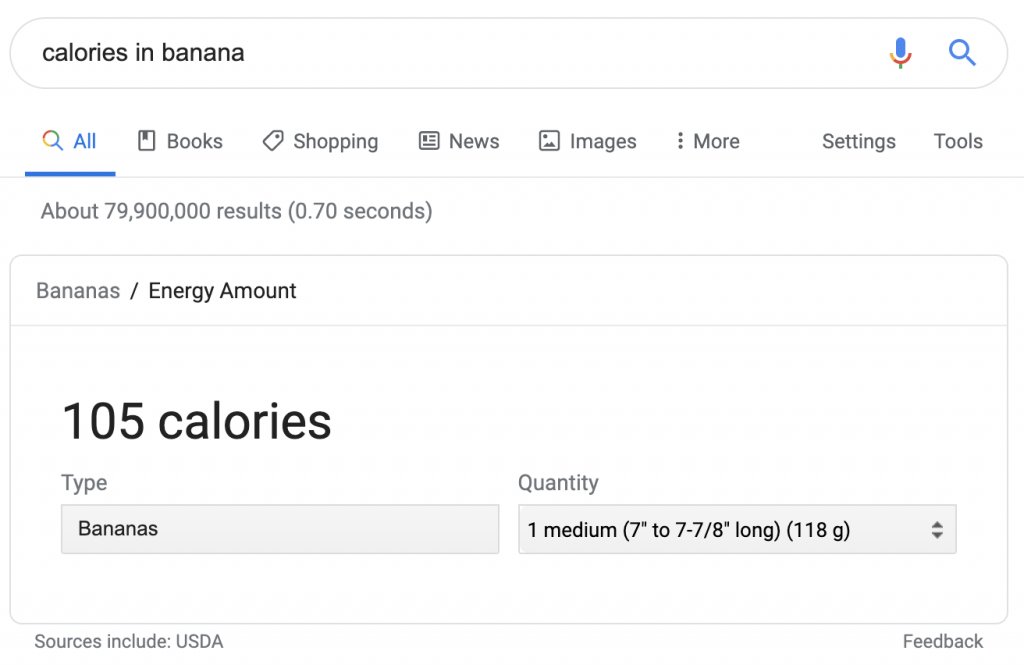
อย่างไรก็ตาม ในกรณีนี้ การระบุแหล่งที่มาจะแสดงเป็น "แหล่งที่มารวมถึง" หากใช้แหล่งข้อมูลอื่นจะไม่ปรากฏหรือเข้าถึงได้
ผลลัพธ์เชิงท้องถิ่น
ผลลัพธ์ที่เกี่ยวข้องกับกิจกรรมในท้องถิ่นจำนวนมากยังดึงมาจากแหล่งที่หลากหลายเพื่อสร้าง SERP ที่ให้ข้อมูลที่รวบรวมและรวบรวมที่หลากหลาย แทนที่จะไปที่เว็บไซต์ต่างๆ ผู้ค้นหาสามารถตัวอย่างเช่น ดูรายชื่อภาพยนตร์ที่ฉายใกล้ ๆ กัน ค้นหารอบฉายในโรงภาพยนตร์ต่างๆ และค้นหารายละเอียด เช่น บทวิจารณ์ เรื่องย่อ และอื่นๆ เกี่ยวกับภาพยนตร์แต่ละเรื่อง ผู้ค้นหาไม่จำเป็นต้องออกจาก SERP ที่ Google ดูแล
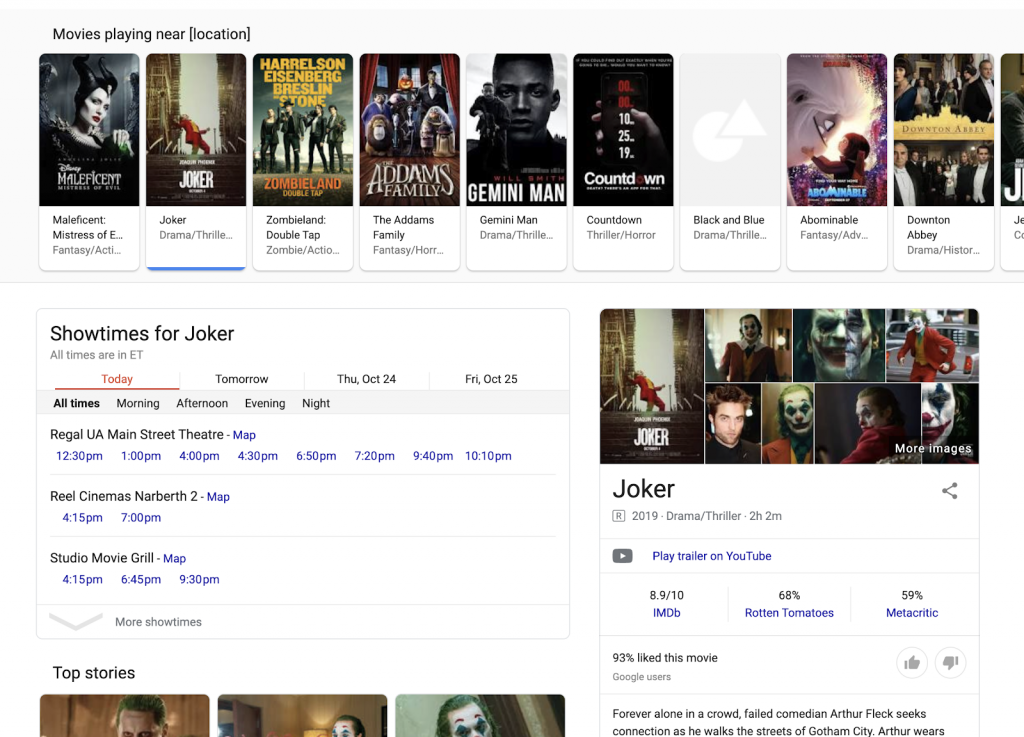
SERP ประเภทนี้กำลังขยายไปสู่พื้นที่ต่างๆ รวมถึงการเดินทาง
เรื่อง AMP
เรื่องราว AMP ให้โหมด "เน้นเรื่องราว" สำหรับ "การใช้ข่าวบนมือถือ" นี่เป็นตัวอย่างว่าการจัดทำดัชนีตามเอนทิตีได้ปรับปรุงความสามารถของ Google ในการดึงเนื้อหาจากแหล่งต่างๆ และรีมิกซ์เนื้อหาดังกล่าวได้อย่างไร ในเรื่องราวที่ Google สร้างขึ้นสำหรับการปรากฏตัวของคนดัง Google ได้จับคู่รูปภาพจากแหล่งหนึ่งกับข้อความจากอีกแหล่งหนึ่ง เป็นต้น
แผงความรู้
แผงความรู้คือ "กล่องข้อมูลที่ปรากฏใน Google เมื่อคุณค้นหาเอนทิตี" ซึ่งเป็นส่วนหนึ่งของกราฟความรู้ของ Google ข้อมูลที่แสดงในแผงเหล่านี้มาจากหลายแหล่ง ซึ่ง Google แสดงรายการดังนี้:
- พันธมิตรด้านข้อมูลซึ่งให้ข้อมูลที่เชื่อถือได้ในหัวข้อเฉพาะ เช่น ภาพยนตร์หรือเพลง
- เปิดแหล่งที่มาของเว็บ
- หน่วยงานที่ตรวจสอบแล้วซึ่งได้แนะนำให้แก้ไขข้อเท็จจริงในแผงความรู้ของตนเอง
- การแสดงตัวอย่างผลลัพธ์ของ Google รูปภาพสำหรับเอนทิตี
ก่อนหน้านี้ Google ได้ระบุว่ากราฟความรู้ของพวกเขาอาศัยแหล่งข้อมูลต่างๆ เช่น Wikipedia/Wikidata, CIA World Factbook, ข้อมูลที่มีโครงสร้างในเว็บสาธารณะ, Google My Business และอื่นๆ
นอกจากนี้ยังอาจแสดงหน่วยงานที่เกี่ยวข้อง ทำให้ผู้ใช้การค้นหาสามารถนำทางผ่านกราฟความรู้โดยไม่ต้องออกจากเว็บไซต์ของเครื่องมือค้นหา
คุณสมบัติ SERP อื่น ๆ
คุณสมบัติอื่นๆ ของ SERP รวมถึงองค์ประกอบการคาดคะเนข้อความค้นหาที่พยายามตอบหรือจัดกลุ่มกิจกรรมการค้นหาใหม่โดยไม่ส่งผู้ใช้การค้นหาไปยังเว็บไซต์อื่น ตัวอย่าง ได้แก่ คำตอบที่ไม่มีผลลัพธ์ในการค้นหาบนมือถือหรือการเติมข้อความอัตโนมัติ รวมถึงช่อง "ผู้คนยังถาม" (PAA)


ตัวอย่างการค้นหาที่ไม่มีผลลัพธ์ (มือถือ) ซึ่งแสดงเป็นคำตอบโดยตรงในช่องเติมข้อความอัตโนมัติบนเดสก์ท็อป
การจัดการเนื้อหาในผลการค้นหา
มาร์กอัป Schema.org
ด้วยการควบคุมโดยตรงเพียงเล็กน้อยเหนือองค์ประกอบอื่นๆ ที่สร้างรายชื่อการค้นหา SEO ได้พึ่งพาพลังของตัวอย่างข้อมูลอย่างหนาแน่นผ่านมาร์กอัป Schema.org เพื่อทำให้รายชื่อของพวกเขาโดดเด่นใน SERP
อย่างไรก็ตาม Google ได้ปราบปรามการใช้มาร์กอัปสื่อสมบูรณ์อย่างไม่เหมาะสม ซึ่งรวมถึงดาวรีวิวและมาร์กอัปคำถามที่พบบ่อย:
Google Review Stars ในผลการค้นหาลดลง 14% ตั้งแต่อัปเดต:
— ไซต์การเงินลดลง 46%
— ไซต์อสังหาริมทรัพย์ลดลง 46%
— เว็บไซต์กฎหมายและรัฐบาลลดลง 28%ข้อมูลใหม่โดย @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
– ไซรัส (@CyrusShepard) วันที่ 24 กันยายน 2019
เพื่อไม่ให้ SERP เต็มไปด้วยผลลัพธ์ #FAQ ดูเหมือนว่า #Google ได้กำหนดขีดจำกัดไว้ที่ 3 ผลลัพธ์คำถามที่พบบ่อย #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
– AJ Ghergich (@SEO) วันที่ 8 ตุลาคม 2019
สิ่งบ่งชี้ที่ชัดเจนว่าเนื้อหาใดไม่สามารถใช้ได้
สัปดาห์นี้ Google กำลังเปิดตัวแท็กการจัดการข้อมูลโค้ดที่สามารถใช้เพื่อระบุข้อจำกัดบางประการแก่ Google เกี่ยวกับสิ่งที่สามารถใช้เพื่อสร้างข้อมูลโค้ดของหน้าใน SERP
แท็กการจัดการใหม่มีข้อจำกัดหลักสองประการ:
- ไม่ได้ใช้กับข้อมูลที่มีโครงสร้าง (มาร์กอัป Schema.org) บนหน้า ข้อมูลที่มีโครงสร้าง Schema.org ซึ่ง Google รองรับจะมีสิทธิ์แสดงในผลการค้นหาเสมอ
- สิ่งเหล่านี้อาจป้องกันไม่ให้เพจของคุณถูกใช้ใน “คุณสมบัติพิเศษ” บางอย่างใน SERP รวมถึงตัวอย่างข้อมูลเด่น หากมีความยาวไม่ตรงตามความยาวขั้นต่ำที่กำหนดโดยคุณสมบัติ SERP เนื่องจากความยาวแตกต่างกันไปตามภาษา Google จึงไม่เผยแพร่ความยาวขั้นต่ำสำหรับตัวอย่างข้อมูลเด่น Insead “[t]ท่อที่ไม่ต้องการให้เนื้อหาปรากฏเป็นตัวอย่างข้อมูลแนะนำสามารถทดลองด้วยความยาวสูงสุดของข้อมูลที่ต่ำกว่าได้”
เจ้าของเว็บไซต์มีสองตัวเลือกในการติดตั้งแท็กเหล่านี้:
1. แท็กโรบ็อต Meta
เริ่มตั้งแต่ปลายเดือนตุลาคม ทั่วโลก แท็ก meta robots เหล่านี้สามารถเพิ่มลงในหน้า <head> หรือในส่วนหัว x-robots HTTP
- <meta name=”robots” content=” nosnippet “> – ไม่ต้องแสดงข้อความตัวอย่างสำหรับหน้านี้ ยังคงใช้ภาพขนาดย่อได้
- <meta name=”robots” content=” max-snippet: 50″> – กำหนดความยาวสูงสุดในจำนวนอักขระสำหรับตัวอย่าง ความยาวของตัวอย่าง "0" เทียบเท่ากับ "nosnippet"; ความยาวตัวอย่าง "-1" ถูกตีความว่าไม่มีการจำกัดความยาวของตัวอย่าง
- <meta name=”robots” content=” max-video-preview: 3″> – ตั้งค่าความยาวสูงสุดเป็นวินาทีสำหรับการดูตัวอย่างวิดีโอ ความยาววิดีโอ "0" จะป้องกันไม่ให้แสดงตัวอย่างวิดีโอ ความยาววิดีโอ "-1" ถูกตีความว่าไม่มีการจำกัดความยาวของตัวอย่างวิดีโอ
- <meta name=”robots” content=” max-image-preview: standard”> – กำหนดขนาดรูปภาพสูงสุดสำหรับรูปภาพจากหน้านี้ ตัวเลือกต่างๆ ได้แก่ "ไม่มี" "มาตรฐาน" หรือ "ใหญ่"
คุณสามารถใช้ตัวดำเนินการจัดการข้อมูลโค้ดมากกว่าหนึ่งตัวในแท็ก meta robots เดียวกันได้ คั่นแต่ละโอเปอเรเตอร์ด้วยเครื่องหมายจุลภาค
2. แอตทริบิวต์ HTML data-nosnippet
ในช่วงปลายปี 2019 Google จะรู้จักแอตทริบิวต์ HTML ใหม่: data-nosnippet สามารถใช้กับแท็ก <span>, <div> หรือ <selection>
แอตทริบิวต์ data-nosnippet ป้องกันไม่ให้ข้อความภายในแท็กที่ใช้แสดงในข้อมูลโค้ดสำหรับหน้า
การอนุญาตอย่างชัดแจ้งสำหรับการใช้เนื้อหาซ้ำสำหรับสื่อยุโรปในฝรั่งเศส
เนื้อหาข่าวที่รีมิกซ์และเผยแพร่ซ้ำของ Google ได้ขัดขืนข้อจำกัดของกฎหมายลิขสิทธิ์ในบางพื้นที่แล้ว ฝรั่งเศสเพิ่งได้รับความสนใจ:
เนื่องจากการเปลี่ยนแปลงในกฎหมายลิขสิทธิ์ในฝรั่งเศส Google Search จะไม่แสดงตัวอย่างข้อความหรือภาพขนาดย่อสำหรับสื่อสิ่งพิมพ์ของยุโรปที่ได้รับผลกระทบในฝรั่งเศส เว้นแต่เว็บไซต์จะใช้เมตาแท็กเพื่ออนุญาตให้ดูตัวอย่างการค้นหา (แหล่งที่มา)
กล่าวคือ Google จะไม่รวมสิ่งพิมพ์ในยุโรปใดๆ ที่ไม่อนุญาตให้เผยแพร่ซ้ำและรีมิกซ์เนื้อหาในท้ายที่สุดในฝรั่งเศสจากผลการค้นหา
แดกดัน วิธีการอนุญาตไม่ชัดเจนเป็นพิเศษ: แท็กโรบ็อตเมตาที่อนุญาตอย่างชัดเจนเท่านั้นคือ "ทั้งหมด" ซึ่ง "เป็นค่าเริ่มต้นและไม่มีผลหากมีการระบุไว้อย่างชัดเจน" ยกเว้นตอนนี้ใน SERP ของฝรั่งเศส
มิเช่นนั้น ผู้เผยแพร่โฆษณาสามารถระบุได้เฉพาะการจำกัดความยาวของการแสดงตัวอย่างข้อความและวิดีโอผ่านข้อตกลงที่ไม่รวมอยู่ในประกาศเกี่ยวกับการจัดการตัวอย่าง หรือพวกเขาสามารถกำหนดขีดจำกัดตามอำเภอใจเพื่อส่งสัญญาณว่าพวกเขาไม่ต้องการห้ามการแสดงตัวอย่างการค้นหา .
เดินไต่เชือก
ทุกเว็บไซต์จะต้องค้นหาความสมดุลระหว่างการปกป้องเนื้อหาและการกำหนดสถานะบน SERP ของ Google
เนื่องจาก Google มีพฤติกรรมมากขึ้นในฐานะผู้เผยแพร่เนื้อหา เราสามารถคาดหวังคุณลักษณะ SERP เพิ่มเติมโดยมีการระบุแหล่งที่มาเพียงเล็กน้อย เช่นเดียวกับประเทศอื่นๆ ที่กฎหมายลิขสิทธิ์ซึ่งมีไว้เพื่อปกป้องเจ้าของและผู้สร้างเนื้อหา มีผลกระทบต่อสิ่งที่ Google สามารถและไม่สามารถแสดงได้
สิ่งที่ฉันคิดว่าน่าสนใจแม้ว่าจะเกี่ยวข้องกับลิขสิทธิ์ของสิ่งนี้… ผู้คนบ่นว่า G รับเนื้อหาโดยไม่ได้รับอนุญาต – แท็กตัวอย่างจะได้รับอนุญาตโดยปริยาย จะต้องใช้เวลาอีกนานไหม?
– Jenny Halasz (@jennyhalasz) วันที่ 15 ตุลาคม 2019
โชคดีที่เครื่องมือการจัดการข้อมูลโค้ดใหม่ช่วยให้เจ้าของเว็บไซต์สามารถเริ่มต้นกล่องเครื่องมือเพื่อกำหนดส่วนต่างๆ ของเนื้อหาและปริมาณเนื้อหาที่ Google สามารถนำกลับมาใช้ใหม่ได้ใน SERP
สำหรับตอนนี้ ฉันเชื่อว่าควรใช้แท็กการจัดการข้อมูลโค้ดตามความเหมาะสมบนเว็บไซต์ที่มีเนื้อหาต้นฉบับจำนวนมาก แม้ว่าฉันจะกังวลว่าแท็กที่มีข้อจำกัดเพียงอย่างเดียวจะไม่เป็นประโยชน์กับทุกเว็บไซต์ แม้จะมีข้อแม้นี้ แต่ก็ยังมีวิธีที่จะใช้เพื่อเพิ่มประสิทธิภาพประสบการณ์ใน SERP และเพิ่มปริมาณการใช้งาน
ฉันคิดว่าผู้คนจะใช้แท็กใหม่ ฉันคิดว่ามีโอกาสค่อนข้างมากที่จะ "กำหนด" ข้อมูลโค้ดด้วยแท็กเหล่านั้นเพื่อมอบประสบการณ์ที่ดีกว่าที่ Google ดึงโดยอัตโนมัติและเพิ่มประสิทธิภาพ CTR
— Kevin_Indig (@Kevin_Indig) วันที่ 16 ตุลาคม 2019
ฉันรอคอยที่จะได้เห็นการทดลองในแนวดิ่งต่างๆ เพื่อค้นหาสิ่งที่ดีที่สุด