
7 SEO ล้มเหลวที่เห็นได้ทั่วไป (และคุณจะหลีกเลี่ยงได้อย่างไร)
เผยแพร่แล้ว: 2022-06-12
เรามักได้รับคำถามจากผู้ที่สงสัยว่าเหตุใดไซต์ของพวกเขาจึงไม่อยู่ในอันดับ หรือเหตุใดจึงไม่สร้างดัชนีโดยเครื่องมือค้นหา
เมื่อเร็วๆ นี้ ฉันพบไซต์หลายแห่งที่มีข้อผิดพลาดสำคัญซึ่งสามารถแก้ไขได้ง่าย หากมีเพียงเจ้าของเท่านั้นที่รู้ว่าจะมองดู แม้ว่าข้อผิดพลาด SEO บางอย่างจะค่อนข้างซับซ้อน แต่นี่คือข้อผิดพลาด "การกระแทกหัว" ที่มักถูกมองข้าม
ดังนั้นให้ตรวจสอบข้อผิดพลาด SEO เหล่านี้ - และวิธีที่คุณสามารถหลีกเลี่ยงการทำด้วยตัวเอง
SEO ล้มเหลว #1: ปัญหา Robots.txt
ไฟล์ robots.txt มีพลังมาก มันสั่งบอทของเครื่องมือค้นหาสิ่งที่จะแยกออกจากดัชนีของพวกเขา
ในอดีต ฉันเคยเห็นไซต์ต่างๆ ลืมลบโค้ดหนึ่งบรรทัดออกจากไฟล์นั้นหลังจากออกแบบไซต์ใหม่ และทำให้ไซต์ทั้งหมดของพวกเขาจมลงในผลการค้นหา
ดังนั้นเมื่อไซต์ดอกไม้เน้นปัญหา ฉันเริ่มต้นด้วยการตรวจสอบครั้งแรกที่ฉันทำในไซต์เสมอ ดูไฟล์ robots.txt
ฉันต้องการทราบว่า robots.txt ของไซต์บล็อกเครื่องมือค้นหาไม่ให้สร้างดัชนีเนื้อหาหรือไม่ แต่แทนที่จะเป็นไฟล์ข้อความที่คาดไว้ ฉันเห็นหน้าเสนอให้ส่งดอกไม้ไปยัง Robots.Txt
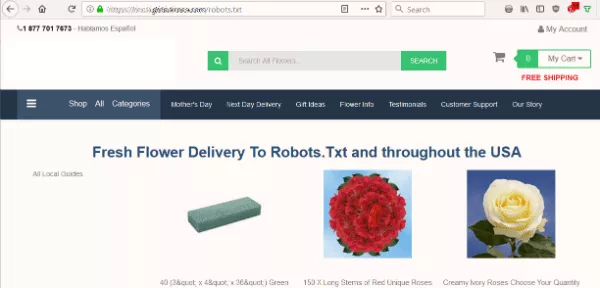
ไซต์ไม่มี robots.txt ซึ่งเป็นสิ่งแรกที่บอทมองหาเมื่อรวบรวมข้อมูลไซต์ นั่นเป็นความผิดพลาดครั้งแรกของพวกเขา แต่จะเอาไฟล์นั้นเป็นปลายทาง…จริงเหรอ?
SEO ล้มเหลว #2: การสร้างอัตโนมัติ Gone Wild
ประการที่สอง ไซต์สร้างเนื้อหาไร้สาระโดยอัตโนมัติ มันอาจจะส่งถึงซานตาคลอสหรือข้อความใดก็ตามที่ฉันใส่ใน URL
ฉันเรียกใช้เครื่องมือตรวจสอบหน้าเซิร์ฟเวอร์เพื่อดูว่าหน้าที่สร้างอัตโนมัติแสดงสถานะใด หากเป็น 404 (ไม่พบ) บอทจะละเว้นหน้าตามที่ควรจะเป็น อย่างไรก็ตาม ส่วนหัวของเซิร์ฟเวอร์ของเพจมีสถานะ 200 (ตกลง) ด้วยเหตุนี้ เพจปลอมจึงทำให้เสิร์ชเอ็นจิ้นได้รับไฟเขียวให้จัดทำดัชนี
เครื่องมือค้นหาต้องการดูเนื้อหาที่ไม่ซ้ำกันและมีความหมายต่อหน้า ดังนั้นการจัดทำดัชนีหน้าที่ไม่ใช่หน้าเหล่านี้อาจส่งผลเสียต่อ SEO ของพวกเขา
SEO ล้มเหลว #3: ข้อผิดพลาดที่ยอมรับได้
ต่อไป ฉันตรวจสอบเพื่อดูว่าเครื่องมือค้นหาคิดอย่างไรกับไซต์นี้ พวกเขาสามารถรวบรวมข้อมูลและจัดทำดัชนีหน้าเว็บได้หรือไม่
เมื่อดูซอร์สโค้ดของหน้าต่างๆ ฉันสังเกตเห็นข้อผิดพลาดที่สำคัญอีกอย่างหนึ่ง
ทุกหน้ามีองค์ประกอบลิงก์ตามรูปแบบบัญญัติที่ชี้กลับไปที่หน้าแรก:
<link rel=”canonical” href=”https://www.domain.com/” />
กล่าวอีกนัยหนึ่ง เสิร์ชเอ็นจิ้นบอกว่าทุกหน้าเป็นสำเนาของโฮมเพจจริงๆ ตามแท็กนี้ บ็อตควรละเว้นหน้าที่เหลือในโดเมนนั้น
โชคดีที่ Google ฉลาดพอที่จะรู้ว่าแท็กเหล่านี้มีแนวโน้มที่จะใช้โดยผิดพลาดเมื่อใด ดังนั้นมันจึงยังคงสร้างดัชนีหน้าบางหน้าของเว็บไซต์ แต่คำขอมาตรฐานสากลนั้นไม่ได้ช่วย SEO ของไซต์
วิธีหลีกเลี่ยงข้อผิดพลาด SEO เหล่านี้
สำหรับข้อผิดพลาดหลายประการของไซต์ดอกไม้ นี่คือการแก้ไข:
- มีไฟล์ robots.txt ที่ถูกต้อง เพื่อบอกให้เครื่องมือค้นหาทราบถึงวิธีการรวบรวมข้อมูลและจัดทำดัชนีเว็บไซต์ แม้ว่าจะเป็นไฟล์เปล่า แต่ก็ควรอยู่ที่รูทของโดเมนของคุณ
- สร้างองค์ประกอบลิงก์ตามรูปแบบบัญญัติที่เหมาะสมสำหรับแต่ละหน้า และอย่าชี้ไปที่หน้าที่คุณต้องการจัดทำดัชนี
- แสดงหน้า 404 ที่กำหนดเอง เมื่อไม่มี URL ของหน้า ตรวจสอบให้แน่ใจว่าส่งคืนรหัสเซิร์ฟเวอร์ 404 เพื่อให้เครื่องมือค้นหามีข้อความที่ชัดเจน
- ระวังหน้าที่สร้างอัตโนมัติ หลีกเลี่ยงการสร้างเรื่องไร้สาระหรือหน้าที่ซ้ำกันสำหรับเครื่องมือค้นหาและผู้ใช้
แม้ว่าคุณจะไม่ได้ประสบปัญหาเกี่ยวกับไซต์ แต่สิ่งเหล่านี้เป็นประเด็นที่ดีที่คุณควรตรวจสอบเป็นระยะ เพื่อความปลอดภัย
อ้อ และ อย่าใส่ Canonical tag ในหน้า 404 ของคุณ โดยเฉพาะอย่างยิ่งการชี้ไปที่หน้าแรกของคุณ … อย่าเลย
SEO ล้มเหลว #4: อันดับค้างคืน Freefall
บางครั้งการเปลี่ยนแปลงง่ายๆ อาจเป็นความผิดพลาดที่มีค่าใช้จ่ายสูง เรื่องราวนี้มาจากประสบการณ์กับลูกค้า SEO รายหนึ่งของเรา
เมื่อนามสกุล .org ของชื่อโดเมนใช้งานได้ พวกเขาก็เร่งพัฒนา จนถึงตอนนี้ดีมาก แต่การเคลื่อนไหวครั้งต่อไปของพวกเขานำไปสู่หายนะ
พวกเขาตั้งค่าการเปลี่ยนเส้นทาง 301 ทันทีโดยชี้ไปที่ .org ที่ได้มาใหม่ไปยังเว็บไซต์ .com หลักของพวกเขา เหตุผลของพวกเขาสมเหตุสมผล — เพื่อดึงดูดผู้เข้าชมที่เอาแต่ใจซึ่งอาจพิมพ์นามสกุลผิด
แต่วันรุ่งขึ้นพวกเขาโทรหาเราอย่างบ้าคลั่ง การเข้าชมไซต์ของพวกเขาไม่มีอยู่จริง พวกเขาไม่รู้ว่าทำไม
การตรวจสอบอย่างรวดเร็วบางส่วนเผยให้เห็นว่าอันดับการค้นหาของพวกเขาหายไปจาก Google ในชั่วข้ามคืน ไม่ต้องใช้ Q&A มากเกินไปเพื่อค้นหาว่าเกิดอะไรขึ้น

พวกเขาวางการเปลี่ยนเส้นทางโดยไม่พิจารณาถึงความเสี่ยง เราทำการขุดค้นและพบว่า .org มีอดีตที่เลวร้าย
เจ้าของไซต์ .org คนก่อนเคยใช้เพื่อส่งสแปม ด้วยการเปลี่ยนเส้นทาง Google ได้กำหนดพิษทั้งหมดนั้นให้กับเว็บไซต์หลักของบริษัท! เราใช้เวลาเพียงสองวันในการกู้คืนสถานะไซต์ใน Google
วิธีหลีกเลี่ยงความล้มเหลวในการทำ SEO นี้
ศึกษารายละเอียดลิงก์และประวัติของชื่อโดเมนที่คุณลงทะเบียนไว้ เสมอ
ที่ปรึกษา SEO ที่มีคุณสมบัติเหมาะสมสามารถทำได้ นอกจากนี้ยังมีเครื่องมือที่คุณสามารถเรียกใช้เพื่อดูว่าโครงกระดูกใดอาจอยู่ในตู้เสื้อผ้าของไซต์
เมื่อใดก็ตามที่ฉันเลือกโดเมนใหม่ ฉันชอบที่จะปล่อยให้มันอยู่เฉยๆ อย่างน้อยหกเดือนถึงหนึ่งปีก่อนที่จะพยายามทำอะไร ฉันต้องการให้เสิร์ชเอ็นจิ้นสร้างความแตกต่างให้กับไซต์ของฉันจากชาติที่แล้วอย่างชัดเจน เป็นข้อควรระวังพิเศษในการปกป้องการลงทุนของคุณ
SEO ล้มเหลว #5: หน้าที่จะไม่หายไป
บางครั้งไซต์อาจมีปัญหาที่แตกต่างกัน — มีหลายหน้าในดัชนีการค้นหามากเกินไป
บางครั้งเสิร์ชเอ็นจิ้นจะเก็บหน้าที่ใช้งานไม่ได้อีกต่อไป หากผู้คนไปที่หน้าแสดงข้อผิดพลาดเมื่อพวกเขามาจากผลการค้นหา แสดงว่าผู้ใช้ได้รับประสบการณ์ที่ไม่ดี
เจ้าของเว็บไซต์บางรายอาจแสดงรายการ URL แต่ละรายการในไฟล์ robots.txt ด้วยความหงุดหงิด พวกเขาหวังว่า Google จะใช้คำใบ้และหยุดสร้างดัชนี
แต่วิธีนี้ล้มเหลว! หาก Google ปฏิบัติตาม robots.txt จะไม่รวบรวมข้อมูลหน้าเหล่านั้น ดังนั้น Google จะไม่เห็นสถานะ 404 และไม่พบว่าหน้านั้นไม่ถูกต้อง
วิธีหลีกเลี่ยงข้อผิดพลาด SEO นี้
ส่วนแรกของการแก้ไขคือการ ไม่ อนุญาต URL เหล่านี้ใน robots.txt คุณต้องการให้บอทรวบรวมข้อมูลและรู้ว่า URL ใดควรถูกลบออกจากดัชนีการค้นหา
หลังจากนั้น ตั้งค่าการเปลี่ยนเส้นทาง 301 บน URL เก่า ส่งผู้เยี่ยมชม (และเครื่องมือค้นหา) ไปยังหน้าทดแทนที่ใกล้ที่สุดบนไซต์ การดำเนินการนี้จะดูแลผู้เยี่ยมชมของคุณไม่ว่าจะมาจากการค้นหาหรือจากลิงก์โดยตรง
SEO Fail #6: Missed Link Equity
ฉันตามลิงก์จากเว็บไซต์ของมหาวิทยาลัยและได้รับการต้อนรับด้วยข้อผิดพลาด 404 (ไม่พบ)
ไม่ใช่เรื่องแปลก ยกเว้นว่าลิงก์ไปยัง /home.html — URL หน้าแรกของเว็บไซต์เดิม
เมื่อถึงจุดหนึ่ง พวกเขาต้องเปลี่ยนสถาปัตยกรรมเว็บไซต์และลบ /home.html แบบเก่า เสียการเปลี่ยนเส้นทางในการสับเปลี่ยน
น่าแปลกที่หน้า 404 ของพวกเขาบอกว่าคุณสามารถเริ่มต้นใหม่ได้จากหน้าแรก ซึ่งเป็นสิ่งที่ฉันพยายามจะเข้าถึงตั้งแต่แรก
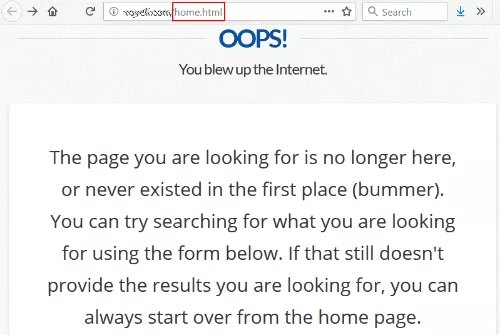
ค่อนข้างปลอดภัยที่ไซต์นี้ชอบที่จะมีลิงก์ที่ดีจากมหาวิทยาลัยที่เคารพนับถือไปยังหน้าแรกของพวกเขา และการบรรลุเป้าหมายนี้ทั้งหมดอยู่ในการควบคุมของพวกเขา พวกเขาไม่ต้องติดต่อไซต์ที่เชื่อมโยงด้วยซ้ำ
วิธีแก้ไขความล้มเหลวนี้
ในการแก้ไขลิงก์นี้ พวกเขาเพียงแค่ใส่ 301 redirect ที่ชี้ไปที่ /home.html ไปยังหน้าแรกปัจจุบัน (ดูบทความของเราเกี่ยวกับวิธีตั้งค่าการเปลี่ยนเส้นทาง 301 สำหรับคำแนะนำ)
สำหรับเครดิตเพิ่มเติม ไปที่ Google Search Console และตรวจสอบรายงานสถานะการครอบคลุมของดัชนี ดูหน้าทั้งหมดที่รายงานว่าส่งคืนข้อผิดพลาด 404 และดำเนินการแก้ไขข้อผิดพลาดที่นี่ให้ได้มากที่สุด
SEO Fail #7: การคัดลอก/วางล้มเหลว
เปิดตัวการออกแบบเว็บไซต์ใหม่ มีแท็กตามรูปแบบบัญญัติ และติดตั้ง Google Tag Manager ใหม่แล้ว ยังมีปัญหาการจัดอันดับ อันที่จริง หน้า Landing Page ใหม่หนึ่งหน้าไม่แสดงผู้เยี่ยมชมใน Google Analytics
ทีมพัฒนาตอบว่าได้ทำทุกอย่างตามหนังสือและได้ปฏิบัติตามตัวอย่างในจดหมาย
พวกเขาพูดถูก พวกเขาติดตามตัวอย่าง - รวมถึงการทิ้งไว้ในโค้ดตัวอย่าง! หลังจากคัดลอกและวางแล้ว นักพัฒนาซอฟต์แวร์ลืมป้อนข้อมูลไซต์เป้าหมายของตนเอง
ต่อไปนี้คือตัวอย่างสามตัวอย่างที่นักวิเคราะห์ของเราพบในโค้ดเว็บไซต์:
- <link rel=”canonical” href=”http://example.com/”>
- 'analyticsAccountNumber': 'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
วิธีหลีกเลี่ยงความล้มเหลวในการทำ SEO นี้
เมื่อสิ่งต่าง ๆ ใช้งานไม่ได้ ให้มองข้ามเพียงแค่ “องค์ประกอบนี้อยู่ในซอร์สโค้ดหรือไม่” อาจเป็นไปได้ว่าไม่มีการระบุรหัสตรวจสอบความถูกต้อง หมายเลขบัญชี และ URL ที่ถูกต้องในโค้ด HTML ของคุณ
ความผิดพลาดเกิดขึ้นและผู้คนเป็นเพียงมนุษย์ ฉันหวังว่าตัวอย่างเหล่านี้จะช่วยคุณหลีกเลี่ยงข้อผิดพลาด SEO ที่คล้ายกันของคุณเอง เพื่อประโยชน์ของคุณ เราได้สร้างคู่มือ SEO เชิงลึกที่สรุปเคล็ดลับ SEO และแนวทางปฏิบัติที่ดีที่สุด
แต่ปัญหา SEO บางอย่างซับซ้อนกว่าที่คุณคิด หากคุณมีปัญหาในการจัดทำดัชนี เรายินดีให้ความช่วยเหลือ โทรหาเราหรือกรอกแบบฟอร์มคำขอของเรา แล้วเราจะติดต่อกลับไป
ชอบโพสต์นี้? โปรดสมัครรับข้อมูลบล็อกของเราเพื่อให้โพสต์ใหม่ส่งถึงกล่องจดหมายของคุณ