
การจัดกลุ่มคำหลักเชิงความหมายใน Python
เผยแพร่แล้ว: 2021-04-19ในโลกที่เต็มไปด้วยตำนานการตลาดดิจิทัล เราเชื่อว่าการแก้ปัญหาในชีวิตประจำวันเป็นสิ่งที่เราต้องการ
ที่ PEMAVOR เราแบ่งปันความเชี่ยวชาญและความรู้ของเราเสมอเพื่อตอบสนองความต้องการของผู้ที่ชื่นชอบการตลาดดิจิทัล ดังนั้น เรามักจะโพสต์สคริปต์ Python ฟรีเพื่อช่วยให้คุณเพิ่ม ROI ของคุณ
การทำคลัสเตอร์คำหลัก SEO ของเราด้วย Python ปูทางไปสู่การรับข้อมูลเชิงลึกใหม่ๆ สำหรับโครงการ SEO ขนาดใหญ่ ด้วยโค้ด Python น้อยกว่า 50 บรรทัด
แนวคิดเบื้องหลังสคริปต์นี้คืออนุญาตให้คุณจัดกลุ่มคีย์เวิร์ดโดยไม่ต้องจ่าย 'ค่าธรรมเนียมเกินจริง' ให้กับ... เรารู้ว่าใคร...
แต่เราตระหนักดีว่าสคริปต์นี้ไม่เพียงพอในตัวเอง จำเป็นต้องมีสคริปต์อื่น ดังนั้น พวกคุณจึงสามารถเข้าใจคีย์เวิร์ดของคุณได้มากขึ้น: คุณต้องสามารถ " จัดกลุ่มคีย์เวิร์ดตามความหมายและความสัมพันธ์เชิงความหมายได้ ”
ตอนนี้ได้เวลานำ Python สำหรับ SEO ไปอีกขั้นหนึ่งแล้ว
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมวิธีดั้งเดิมของการจัดกลุ่มความหมาย
ดังที่คุณทราบ วิธีการดั้งเดิมสำหรับความหมายคือการสร้าง word2vec models จากนั้นจัดกลุ่มคำหลักด้วย Word Mover's Distance
แต่โมเดลเหล่านี้ต้องใช้เวลาและความพยายามอย่างมากในการสร้างและฝึกฝน ดังนั้น เราขอเสนอวิธีแก้ปัญหาที่ตรงไปตรงมากว่านี้ 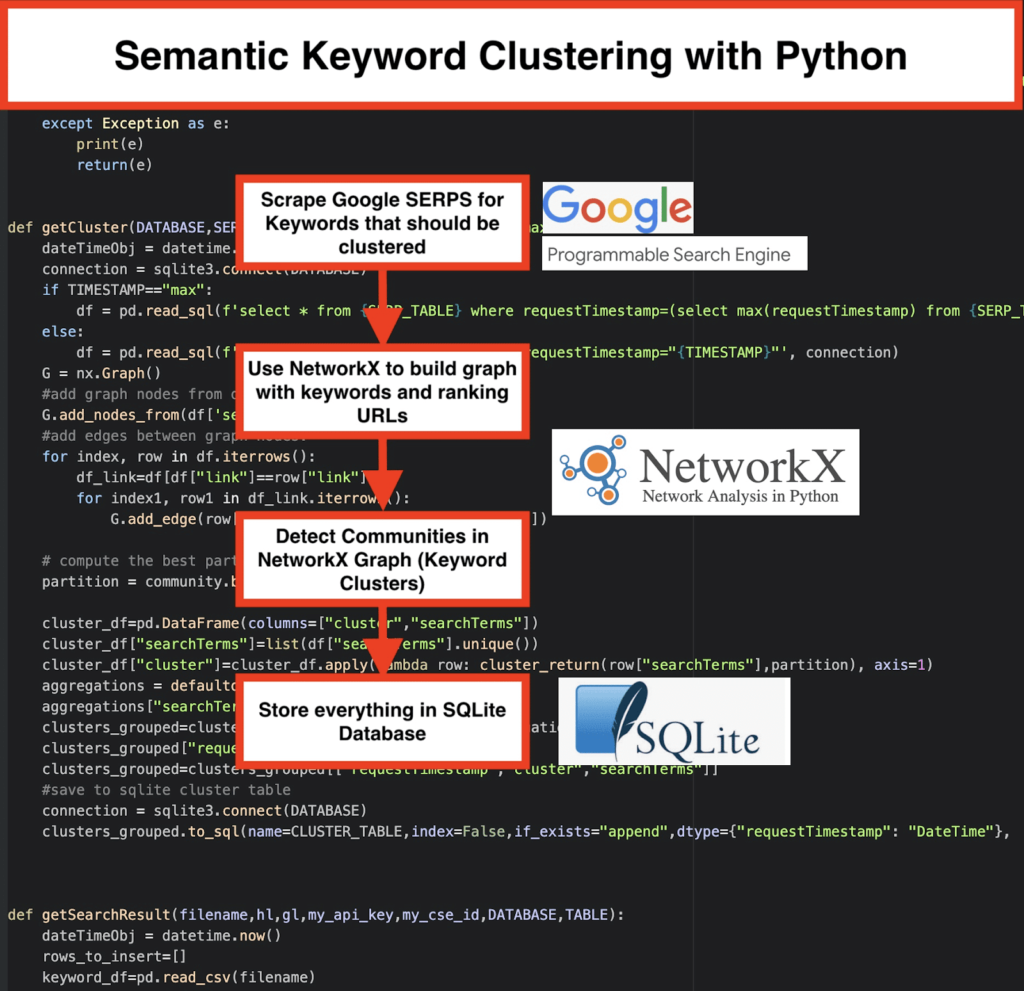
ผลลัพธ์ของ Google SERP และการค้นพบความหมาย
Google ใช้ประโยชน์จากโมเดล NLP เพื่อเสนอผลการค้นหาที่ดีที่สุด มันเหมือนกับการเปิดกล่องแพนโดร่า และเราไม่รู้แน่ชัด
อย่างไรก็ตาม แทนที่จะสร้างแบบจำลองของเรา เราสามารถใช้ช่องนี้เพื่อจัดกลุ่มคำหลักตามความหมายและความหมาย
นี่คือวิธีที่เราทำ:
️ อันดับแรก ให้ สร้างรายการคำหลัก สำหรับหัวข้อ
️ จากนั้น ขูดข้อมูล SERP สำหรับคำหลักแต่ละคำ
️ ถัดไป กราฟจะถูกสร้างขึ้น โดยมีความสัมพันธ์ระหว่างหน้าการจัดอันดับและคำหลัก
️ ตราบใดที่เพจเดียวกันมีอันดับสำหรับคีย์เวิร์ดต่างกัน แสดงว่ามีความเกี่ยวข้องกัน นี่คือ หลักการสำคัญที่ อยู่เบื้องหลังการสร้างคลัสเตอร์คีย์เวิร์ดเชิงความหมาย
ถึงเวลารวมทุกอย่างเข้าด้วยกันใน Python
สคริปต์ Python นำเสนอฟังก์ชันด้านล่าง:
- โดยใช้เครื่องมือค้นหาที่กำหนดเองของ Google ดาวน์โหลด SERP สำหรับรายการคำหลัก ข้อมูลจะถูกบันทึกลงใน ฐานข้อมูล SQLite ที่นี่ คุณควรตั้งค่า API การค้นหาแบบกำหนดเอง
- จากนั้นใช้โควต้าฟรี 100 คำขอต่อวัน แต่พวกเขายังเสนอแผนชำระเงินในราคา $5 ต่อ 1,000 เควส หากคุณไม่ต้องการรอหรือถ้าคุณมีชุดข้อมูลขนาดใหญ่
- ควรใช้ โซลูชัน SQLite ดีกว่าถ้าคุณไม่รีบ – ผลลัพธ์ SERP จะถูกผนวกเข้ากับตารางในการรันแต่ละครั้ง (ใช้ชุดคำหลักใหม่ 100 คำเมื่อคุณมีโควต้าอีกครั้งในวันถัดไป)
- ในขณะเดียวกัน คุณต้องตั้งค่าตัวแปรเหล่านี้ใน Python Script
- CSV_FILE=”keywords.csv” => เก็บคำหลักของคุณที่นี่
- ภาษา = “th”
- ประเทศ = “th”
- API_KEY=” xxxxxxx”
- CSE_ID=”xxxxxxx”
- การรัน
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)จะเขียนผลลัพธ์ SERP ไปยังฐานข้อมูล - การทำคลัสเตอร์ทำได้โดย networkx และโมดูลการตรวจหาชุมชน ข้อมูลถูกดึงมาจาก ฐานข้อมูล SQLite – คลัสเตอร์ถูกเรียกด้วย
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - ผลลัพธ์การจัดกลุ่มสามารถพบได้ใน ตาราง SQLite ตราบใดที่คุณไม่เปลี่ยนแปลง ชื่อจะเป็น “keyword_clusters” โดยค่าเริ่มต้น
ด้านล่าง คุณจะเห็นรหัสเต็ม:
# การจัดกลุ่มคำหลักเชิงความหมายโดย Pemavor.com # ผู้แต่ง: Stefan Neefischer ([email protected]) จาก googleapiclient.discovery import build นำเข้าแพนด้าเป็น pd นำเข้า Levenshtein จากวันที่และเวลานำเข้า วันที่เวลา จาก fuzzywuzzy นำเข้า fuzz จาก urllib.parse นำเข้า urlparse จาก tld นำเข้า get_tld นำเข้า นำเข้า json นำเข้าแพนด้าเป็น pd นำเข้า numpy เป็น np นำเข้า networkx เป็น nx นำเข้าชุมชน นำเข้า sqlite3 นำเข้าคณิตศาสตร์ นำเข้า io จากคอลเลกชันนำเข้า defaultdict def cluster_return (searchTerm พาร์ทิชัน): กลับพาร์ทิชัน[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) กลับเลน[0] def extract_domain(url, remove_http=จริง): uri = urlparse(url) ถ้า remove_http: domain_name = f"{uri.netloc}" อื่น: domain_name = f"{uri.netloc}://{uri.netloc}" ส่งคืน domain_name def extract_mainDomain (url): res = get_tld(url, as_object=จริง) ส่งคืน res.fld def fuzzy_ratio(str1,str2): คืนค่า fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): ส่งคืน fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): ลอง: บริการ = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() ผลตอบแทน ยกเว้นข้อยกเว้นเป็น e: พิมพ์ (จ) ผลตอบแทน (จ) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): ลอง: บริการ = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',จำนวน=10 , cx=cse_id, **kwargs).execute() ผลตอบแทน ยกเว้นข้อยกเว้นเป็น e: พิมพ์ (จ) ผลตอบแทน (จ) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="สูงสุด"): dateTimeObj = datetime.now () การเชื่อมต่อ = sqlite3.connect (ฐานข้อมูล) ถ้า TIMESTAMP=="max": df = pd.read_sql(f'select * จาก {SERP_TABLE} โดยที่ requestTimestamp=(select max(requestTimestamp) จาก {SERP_TABLE})', การเชื่อมต่อ) อื่น: df = pd.read_sql(f'select * จาก {SERP_TABLE} โดยที่ requestTimestamp="{TIMESTAMP}"', การเชื่อมต่อ) G = nx.กราฟ() #add โหนดกราฟจาก dataframe columun G.add_nodes_from(df['searchTerms']) #add ขอบระหว่างโหนดกราฟ: สำหรับดัชนี แถวใน df.iterrows(): df_link=df[df["link"]==row["link"]] สำหรับ index1, row1 ใน df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # คำนวณพาร์ติชั่นที่ดีที่สุดสำหรับชุมชน (คลัสเตอร์) พาร์ทิชัน = community.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(แถวแลมบ์ดา: cluster_return(แถว["searchTerms"], พาร์ติชัน), แกน=1) การรวม = defaultdict() การรวม["searchTerms"]=' | '.เข้าร่วม clusters_grouped=cluster_df.groupby("cluster").agg(การรวมกลุ่ม).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #save ไปยังตารางคลัสเตอร์ sqlite การเชื่อมต่อ = sqlite3.connect (ฐานข้อมูล) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(ชื่อไฟล์,hl,gl,my_api_key,my_cse_id,ฐานข้อมูล,ตาราง): dateTimeObj = datetime.now () rows_to_insert=[] คำสำคัญ_df=pd.read_csv(ชื่อไฟล์) คีย์เวิร์ด=keyword_df.iloc[:,0].tolist() สำหรับการค้นหาในคำหลัก: ถ้า hl=="default": ผลลัพธ์ = google_search_default_language(query, my_api_key, my_cse_id,gl) อื่น: ผลลัพธ์ = google_search(query, my_api_key, my_cse_id,hl,gl) ถ้า "items" เป็นผลลัพธ์และ "queries" ในผลลัพธ์: สำหรับตำแหน่งในช่วง(0,len(ผลลัพธ์["items"])): ผลลัพธ์["รายการ"][ตำแหน่ง]["ตำแหน่ง"]=ตำแหน่ง+1 ผลลัพธ์["items"][ตำแหน่ง]["main_domain"]= extract_mainDomain(ผลลัพธ์["items"][ตำแหน่ง]["ลิงก์"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(ผลลัพธ์["items"][position]["title"],query) ผลลัพธ์["รายการ"][ตำแหน่ง]["snippet_matchScore_token"]=fuzzy_token_set_ratio(ผลลัพธ์["รายการ"][ตำแหน่ง]["ตัวอย่างข้อมูล"],ข้อความค้นหา) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],แบบสอบถาม) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) ผลลัพธ์ ผลลัพธ์["items"][ตำแหน่ง]["snipped_language"]=language_detection(ผลลัพธ์["items"][ตำแหน่ง]["snippet"]) สำหรับตำแหน่งในช่วง(0,len(ผลลัพธ์["items"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "ตำแหน่ง":ผลลัพธ์["รายการ"][ตำแหน่ง]["ตำแหน่ง"],"ตัวอย่างข้อมูล":ผลลัพธ์["รายการ"][ตำแหน่ง]["ตัวอย่างข้อมูล"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":ผลลัพธ์["รายการ"][ตำแหน่ง]["title_matchScore_order"],"title_matchScore_token":ผลลัพธ์["รายการ"][ตำแหน่ง]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #save serp ผลลัพธ์ไปยังฐานข้อมูล sqlite การเชื่อมต่อ = sqlite3.connect (ฐานข้อมูล) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) #################################################### #################################################### ############################################# #อ่านฉัน: # #################################################### #################################################### ############################################# #1- คุณต้องตั้งค่า Google Custom Search Engine # # โปรดระบุคีย์ API และ SearchId # # ตั้งค่าประเทศและภาษาของคุณที่คุณต้องการติดตามผล SERP # # หากคุณยังไม่มีคีย์ API และรหัสการค้นหา # # คุณสามารถทำตามขั้นตอนในส่วนข้อกำหนดเบื้องต้นในหน้านี้ https://developers.google.com/custom-search/v1/overview#prerequisites # # # # 2- คุณต้องป้อนชื่อฐานข้อมูล ตาราง serp และตารางคลัสเตอร์เพื่อบันทึกผลลัพธ์ # # # #3- ป้อนชื่อไฟล์ csv หรือเส้นทางแบบเต็มที่มีคำหลักที่จะใช้สำหรับ serp # # # #4- สำหรับการจัดกลุ่มคำหลัก ให้ป้อนการประทับเวลาสำหรับผลลัพธ์ serp ที่จะใช้สำหรับการจัดกลุ่ม # # หากคุณต้องการจัดกลุ่มผลลัพธ์ serp ล่าสุด ให้ป้อน "max" สำหรับการประทับเวลา # # หรือป้อนเวลาเฉพาะ เช่น "2021-02-18 17:18:05.195321" # # # #5- เรียกดูผลลัพธ์ผ่านเบราว์เซอร์ DB สำหรับโปรแกรม Sqlite # #################################################### #################################################### ############################################# #csv ชื่อไฟล์ที่มีคีย์เวิร์ดสำหรับ serp CSV_FILE="คีย์เวิร์ด.csv" #กำหนดภาษา LANGUAGE = "th" #กำหนดเมือง ประเทศ = "th" #คีย์การค้นหาที่กำหนดเองของ Google json api API_KEY="ENTER KEY ที่นี่" #รหัสเครื่องมือค้นหา CSE_ #ชื่อฐานข้อมูล sqlite ฐานข้อมูล = "keywords.db" #ชื่อตารางเพื่อบันทึกผลการเซอร์ปไว้ SERP_TABLE="keywords_serps" # เรียกใช้เซิร์ฟเวอร์สำหรับคำหลัก getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #table ชื่อที่ผลลัพธ์ของคลัสเตอร์จะบันทึกไว้ CLUSTER_TABLE="keyword_clusters" #โปรดป้อนการประทับเวลา หากคุณต้องการสร้างคลัสเตอร์สำหรับการประทับเวลาที่เฉพาะเจาะจง #ถ้าคุณต้องการสร้างคลัสเตอร์สำหรับผลลัพธ์ serp ล่าสุด ให้ส่งด้วยค่า "max" #TIMESTAMP="2021-02-18 17:18:05.195321" เวลาประทับ = "สูงสุด" #run กลุ่มคีย์เวิร์ดตามเครือข่ายและอัลกอริทึมของชุมชน getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

ผลลัพธ์ของ Google SERP และการค้นพบความหมาย
เราหวังว่าคุณจะชอบสคริปต์นี้ที่มีทางลัดในการจัดกลุ่มคำหลักของคุณเป็นกลุ่มเชิงความหมายโดยไม่ต้องอาศัยแบบจำลองเชิงความหมาย เนื่องจากโมเดลเหล่านี้มักจะซับซ้อนและมีราคาแพง จึงต้องพิจารณาวิธีอื่นๆ ในการระบุคำหลักที่มีคุณสมบัติทางความหมายร่วมกัน
ด้วยการรักษาคำหลักที่เกี่ยวข้องกัน คุณจะสามารถครอบคลุมหัวข้อได้ดีขึ้น เชื่อมโยงบทความในไซต์ของคุณถึงกัน และเพิ่มอันดับของเว็บไซต์ของคุณสำหรับหัวข้อที่กำหนด