
การประเมินคุณภาพของการคาดการณ์ผลกระทบเชิงสาเหตุ
เผยแพร่แล้ว: 2022-02-15CausalImpact เป็นหนึ่งในแพ็คเกจยอดนิยมที่ใช้ในการทดลอง SEO ความนิยมเป็นที่เข้าใจได้
การทดลอง SEO ให้ข้อมูลเชิงลึกที่น่าตื่นเต้นและวิธีรายงาน SEO เกี่ยวกับคุณค่าของงาน
กระนั้น ความแม่นยำของโมเดลการเรียนรู้ของเครื่องใดๆ ขึ้นอยู่กับข้อมูลที่ป้อนเข้ามา
พูดง่ายๆ ว่าอินพุตที่ไม่ถูกต้องอาจส่งคืนค่าประมาณที่ไม่ถูกต้อง
ในโพสต์นี้ เราจะแสดงให้เห็นว่า CausalImpact น่าเชื่อถือ (และไม่น่าเชื่อถือ) เพียงใด นอกจากนี้เรายังจะได้เรียนรู้วิธีเพิ่มความมั่นใจในผลการทดสอบของคุณอีกด้วย
ประการแรก เราจะให้ภาพรวมคร่าวๆ เกี่ยวกับวิธีการทำงานของ CausalImpact จากนั้น เราจะพูดถึงความน่าเชื่อถือของการประมาณค่า CausalImpact สุดท้าย เราจะได้เรียนรู้เกี่ยวกับวิธีการที่สามารถใช้ประเมินผลการทดสอบ SEO ของคุณเองได้
CausalImpact คืออะไรและทำงานอย่างไร?
CausalImpact เป็นแพ็คเกจที่ใช้สถิติแบบเบย์เพื่อประเมินผลกระทบของเหตุการณ์ในกรณีที่ไม่มีการทดสอบ การประมาณนี้เรียกว่าการอนุมานเชิงสาเหตุ
การอนุมานเชิงสาเหตุจะประมาณการว่าการเปลี่ยนแปลงที่สังเกตได้เกิดจากเหตุการณ์เฉพาะ
มักใช้ในการประเมินประสิทธิภาพของการทดลอง SEO
ตัวอย่างเช่น เมื่อระบุวันที่ของเหตุการณ์ CausalImpact (CI) จะใช้จุดข้อมูลก่อนการแทรกแซงเพื่อคาดการณ์จุดข้อมูลหลังการแทรกแซง จากนั้นจะเปรียบเทียบการคาดคะเนกับข้อมูลที่สังเกตได้และประเมินความแตกต่างด้วยเกณฑ์ความเชื่อมั่นที่แน่นอน
นอกจากนี้ยังสามารถใช้กลุ่มควบคุมเพื่อทำให้การคาดการณ์แม่นยำยิ่งขึ้น
พารามิเตอร์ต่างๆ จะส่งผลต่อความแม่นยำของการทำนายด้วยเช่นกัน:
- ขนาดของข้อมูลการทดสอบ
- ระยะเวลาก่อนการทดลอง
- การเลือกกลุ่มควบคุมที่จะเปรียบเทียบ
- ไฮเปอร์พารามิเตอร์ตามฤดูกาล
- จำนวนการทำซ้ำ
พารามิเตอร์ทั้งหมดเหล่านี้ช่วยให้บริบทเพิ่มเติมแก่โมเดลและเพิ่มความน่าเชื่อถือ
Oncrawl BI
 ค้นพบ
ค้นพบเหตุใดการประเมินความถูกต้องของการทดสอบ SEO จึงมีความสำคัญ
ในหลายปีที่ผ่านมา ฉันได้วิเคราะห์การทดลอง SEO หลายครั้งและบางอย่างก็ทำให้ฉันประทับใจ
หลายครั้ง การใช้กลุ่มควบคุมและกรอบเวลาที่แตกต่างกันในชุดการทดสอบและวันที่ดำเนินการที่เหมือนกันทำให้เกิดผลลัพธ์ที่แตกต่างกัน
สำหรับภาพประกอบ ด้านล่างนี้เป็นผลลัพธ์สองรายการจากเหตุการณ์เดียวกัน
ครั้งแรกกลับลดลงอย่างมีนัยสำคัญทางสถิติ 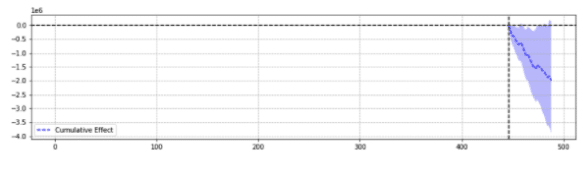
ประการที่สองไม่มีนัยสำคัญทางสถิติ 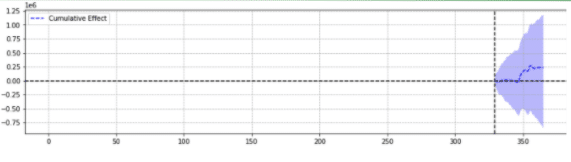
พูดง่ายๆ ก็คือ สำหรับเหตุการณ์เดียวกัน ผลลัพธ์ที่แตกต่างกันถูกส่งกลับตามพารามิเตอร์ที่เลือก
เราต้องสงสัยว่าคำทำนายใดถูกต้อง
ในท้ายที่สุด “นัยสำคัญทางสถิติ” ไม่ควรจะเพิ่มความมั่นใจในการประมาณการของเราใช่หรือไม่
คำจำกัดความ
เพื่อให้เข้าใจโลกของการทดลอง SEO มากขึ้น ผู้อ่านควรตระหนักถึงแนวคิดพื้นฐานของการทดลอง SEO:
- การ ทดลอง : ขั้นตอนการทดสอบสมมติฐาน ในกรณีของการอนุมานเชิงสาเหตุ มันมีวันที่เริ่มต้นเฉพาะ
- กลุ่มทดสอบ : ชุดย่อยของข้อมูลที่ใช้การเปลี่ยนแปลง อาจเป็นทั้งเว็บไซต์หรือบางส่วนของเว็บไซต์ก็ได้
- กลุ่มควบคุม : ชุดย่อยของข้อมูลที่ไม่มีการเปลี่ยนแปลงใดๆ คุณสามารถมีกลุ่มควบคุมได้หนึ่งกลุ่มหรือหลายกลุ่ม นี่อาจเป็นไซต์ที่แยกจากกันในอุตสาหกรรมเดียวกันหรือส่วนอื่นของไซต์เดียวกัน
ตัวอย่างด้านล่างจะช่วยอธิบายแนวคิดเหล่านี้:
การแก้ไขชื่อ (การทดสอบ) ควรเพิ่ม CTR ทั่วไป 1% (สมมติฐาน) ของหน้าผลิตภัณฑ์ในห้าเมือง (กลุ่มทดสอบ) การประมาณการจะได้รับการปรับปรุงโดยใช้ชื่อที่ไม่เปลี่ยนแปลงในเมืองอื่นๆ ทั้งหมด (กลุ่มควบคุม)
เสาหลักในการทำนายการทดสอบ SEO ที่แม่นยำ
- เพื่อความง่าย ฉันได้รวบรวมข้อมูลเชิงลึกที่น่าสนใจสองสามข้อสำหรับมืออาชีพด้าน SEO ที่เรียนรู้วิธีปรับปรุงความแม่นยำของการทดลอง:
- ข้อมูลบางอย่างใน CausalImpact จะส่งกลับค่าประมาณที่ไม่ถูกต้อง แม้ว่าจะมีนัยสำคัญทางสถิติก็ตาม นี่คือสิ่งที่เราเรียกว่า "ผลบวกเท็จ" และ "ผลลบเท็จ"
- ไม่มีกฎทั่วไปที่ควบคุมว่าจะใช้การควบคุมใดกับชุดทดสอบ จำเป็นต้องมีการทดสอบเพื่อกำหนดข้อมูลการควบคุมที่ดีที่สุดเพื่อใช้สำหรับชุดการทดสอบเฉพาะ
- การใช้ CausalImpact ด้วยการควบคุมที่ถูกต้องและความยาวของข้อมูลก่อนช่วงเวลาที่เหมาะสมนั้นแม่นยำมาก โดยข้อผิดพลาดเฉลี่ยจะต่ำเพียง 0.1%
- อีกทางหนึ่ง การใช้ CausalImpact กับการควบคุมที่ไม่ถูกต้อง อาจทำให้เกิดอัตราความผิดพลาดที่รุนแรงได้ การทดลองส่วนตัวแสดงให้เห็นความผันแปรที่มีนัยสำคัญทางสถิติถึง 20% โดยที่แท้จริงแล้วไม่มีการเปลี่ยนแปลงใดๆ
- ไม่สามารถทดสอบทุกอย่างได้ กลุ่มทดสอบบางกลุ่มแทบไม่เคยส่งคืนการประมาณที่แม่นยำ
- การทดลองที่มีหรือไม่มีกลุ่มควบคุมต้องการข้อมูลที่มีความยาวต่างกันก่อนการแทรกแซง
ไม่ใช่ทุกกลุ่มการทดสอบที่จะคืนค่าประมาณการที่แม่นยำ
กลุ่มทดสอบบางกลุ่มจะแสดงการคาดคะเนที่ไม่ถูกต้องเสมอ ไม่ควรใช้ในการทดลอง
กลุ่มทดสอบที่มีรูปแบบการรับส่งข้อมูลที่ผิดปกติมากมักจะให้ผลลัพธ์ที่ไม่น่าเชื่อถือ
ตัวอย่างเช่น ในปีเดียวกัน เว็บไซต์มีการโยกย้ายไซต์ ได้รับผลกระทบจากการระบาดใหญ่ของ covid และส่วนหนึ่งของไซต์ถูก "noindexed" เป็นเวลา 2 สัปดาห์เนื่องจากข้อผิดพลาดทางเทคนิค การทำการทดลองบนไซต์นั้นจะให้ผลลัพธ์ที่ไม่น่าเชื่อถือ
ประเด็นข้างต้นถูกรวบรวมผ่านชุดการทดสอบที่ครอบคลุมโดยใช้วิธีการที่อธิบายไว้ด้านล่าง
เมื่อไม่ได้ใช้กลุ่มควบคุม
- การใช้ตัวควบคุมแทนการโพสต์ล่วงหน้าแบบธรรมดาสามารถเพิ่มความแม่นยำในการประมาณการได้ถึง 18 เท่า
- การใช้ข้อมูล 16 เดือนก่อนหน้านั้นแม่นยำเท่ากับการใช้ 3 ปี
เมื่อใช้กลุ่มควบคุม
- การใช้การควบคุมที่ถูกต้องมักจะดีกว่าการใช้การควบคุมหลายตัว อย่างไรก็ตาม การควบคุมแบบเดียวจะเพิ่มความเสี่ยงของการคาดคะเนที่ผิดพลาดในกรณีที่ปริมาณข้อมูลของการควบคุมแตกต่างกันมาก
- การเลือกการควบคุมที่เหมาะสมสามารถเพิ่มความแม่นยำได้ถึง 10 เท่า (เช่น อันหนึ่งรายงาน +3.1% และอีกอัน +4.1% เมื่อในความเป็นจริงคือ +3%)
- รูปแบบการรับส่งข้อมูลที่สัมพันธ์กันส่วนใหญ่ระหว่างข้อมูลทดสอบและข้อมูลควบคุมไม่ได้หมายถึงการประมาณที่ดีกว่าเสมอไป
- การใช้ข้อมูล 16 เดือนก่อนหน้านั้นไม่แม่นยำเท่ากับการใช้ 3 ปี
ระวังความยาวของข้อมูลก่อนการทดลอง
ที่น่าสนใจคือเมื่อทำการทดลองกับกลุ่มควบคุม การใช้ข้อมูลก่อนหน้า 16 เดือนอาจทำให้เกิดอัตราความผิดพลาดที่รุนแรงได้
อันที่จริง ข้อผิดพลาดอาจมีขนาดใหญ่เท่ากับการประเมินการเข้าชมที่เพิ่มขึ้น 3 เท่าเมื่อไม่มีการเปลี่ยนแปลงจริง
อย่างไรก็ตาม การใช้ข้อมูลเป็นเวลา 3 ปีได้ลบอัตราข้อผิดพลาดนั้นออกไป ซึ่งตรงกันข้ามกับการทดลองก่อนโพสต์ง่ายๆ โดยที่อัตราข้อผิดพลาดนั้นไม่เพิ่มขึ้นโดยการเพิ่มความยาวจาก 16 เป็น 36 เดือน
ไม่ได้หมายความว่าการใช้การควบคุมไม่ดี มันค่อนข้างตรงกันข้าม
มันแสดงให้เห็นว่าการเพิ่มการควบคุมส่งผลต่อการคาดการณ์อย่างไร
นี่เป็นกรณีที่มีการเปลี่ยนแปลงครั้งใหญ่ในกลุ่มควบคุม

ข้อเสนอนี้มีความสำคัญอย่างยิ่งสำหรับเว็บไซต์ที่มีรูปแบบการเข้าชมที่ผิดปกติในปีที่ผ่านมา (ข้อผิดพลาดทางเทคนิคที่สำคัญ การระบาดของโควิด เป็นต้น)
จะประเมินการคาดการณ์ผลกระทบเชิงสาเหตุได้อย่างไร
ตอนนี้ไม่มีคะแนนความแม่นยำในไลบรารี CausalImpact จึงต้องอนุมานเป็นอย่างอื่น
คุณสามารถดูวิธีที่โมเดลการเรียนรู้ของเครื่องอื่นๆ ประเมินความถูกต้องของการคาดคะเน และตระหนักว่าผลรวมของข้อผิดพลาดกำลังสอง (SSE) เป็นตัวชี้วัดทั่วไป
ผลรวมของข้อผิดพลาดกำลังสอง หรือผลรวมของกำลังสอง คำนวณผลรวมของความแตกต่างทั้งหมด (n) ระหว่างความคาดหวัง (yi) และผลลัพธ์จริง (f(xi)) กำลังสอง 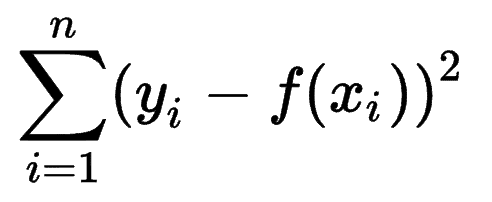
ยิ่ง SSE ต่ำเท่าไร ผลลัพธ์ก็จะยิ่งดีขึ้นเท่านั้น
ความท้าทายคือการทดลองก่อนโพสต์เกี่ยวกับการเข้าชม SEO นั้นไม่มีผลลัพธ์ที่แท้จริง
แม้ว่าจะไม่มีการเปลี่ยนแปลงในสถานที่ทำงาน แต่การเปลี่ยนแปลงบางอย่างอาจเกิดขึ้นนอกเหนือการควบคุมของคุณ (เช่น การอัปเดตอัลกอริทึมของ Google คู่แข่งรายใหม่ เป็นต้น) ปริมาณการใช้ SEO ไม่ได้แปรผันตามจำนวนที่แน่นอน แต่จะแตกต่างกันไปขึ้นและลง
ผู้เชี่ยวชาญ SEO อาจสงสัยว่าจะเอาชนะความท้าทายได้อย่างไร
แนะนำรูปแบบปลอม
เพื่อให้แน่ใจถึงขนาดของรูปแบบที่เกิดจากเหตุการณ์ ผู้ทดสอบสามารถแนะนำรูปแบบคงที่ ณ จุดต่างๆ ในเวลา และดูว่า CausalImpact ประมาณการการเปลี่ยนแปลงได้สำเร็จหรือไม่
ยิ่งไปกว่านั้น ผู้เชี่ยวชาญ SEO สามารถทำซ้ำขั้นตอนสำหรับการทดสอบและกลุ่มควบคุมต่างๆ
เมื่อใช้ Python จะมีการแนะนำรูปแบบคงที่ให้กับข้อมูลในวันที่มีการแทรกแซงที่แตกต่างกันสำหรับช่วงหลังช่วง
จากนั้นจึงประมาณผลรวมของข้อผิดพลาดกำลังสองระหว่างรูปแบบที่รายงานโดย CausalImpact และรูปแบบที่แนะนำ
ความคิดจะเป็นดังนี้:
- เลือกข้อมูลการทดสอบและควบคุม
- แนะนำการแทรกแซงปลอมในข้อมูลจริงในวันที่ต่างกัน (เช่น เพิ่มขึ้น 5%)
- เปรียบเทียบการประมาณค่า CausalImpact กับรูปแบบต่างๆ ที่แนะนำ
- คำนวณผลรวมของข้อผิดพลาดกำลังสอง (SSE)
- ทำซ้ำขั้นตอนที่ 1 ด้วยตัวควบคุมหลายตัว
- เลือกการควบคุมด้วย SSE ที่เล็กที่สุดสำหรับการทดลองในโลกแห่งความเป็นจริง
ระเบียบวิธี
ด้วยวิธีการด้านล่าง ฉันได้สร้างตารางที่สามารถใช้เพื่อระบุว่าการควบคุมใดมีอัตราความผิดพลาดที่ดีที่สุดและแย่ที่สุด ณ จุดต่างๆ ในช่วงเวลาต่างๆ
ขั้นแรก เลือกข้อมูลการทดสอบและควบคุม และแนะนำรูปแบบต่างๆ ตั้งแต่ -50% ถึง 50%
จากนั้น เรียกใช้ CausalImpact (CI) และลบการเปลี่ยนแปลงที่รายงานโดย CI ไปยังรูปแบบที่คุณแนะนำ
หลังจากนั้น ให้คำนวณกำลังสองของผลต่างเหล่านี้และรวมค่าทั้งหมดเข้าด้วยกัน
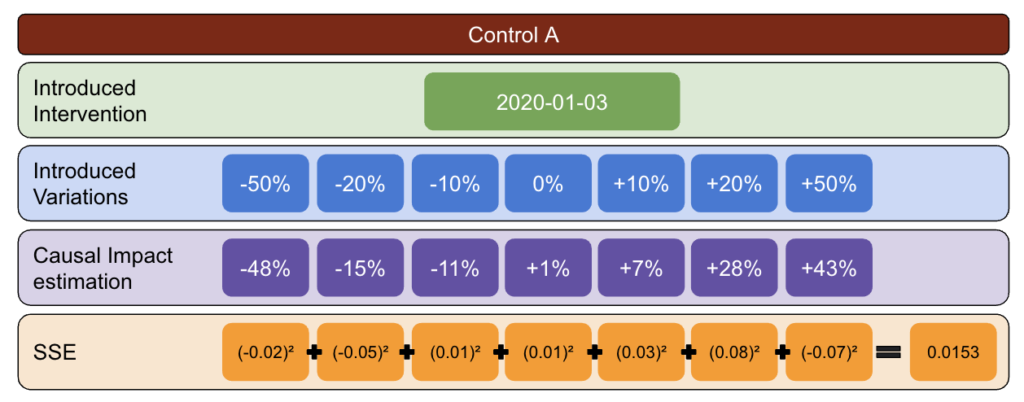
ถัดไป ทำขั้นตอนเดิมซ้ำในวันที่ต่างกันเพื่อลดความเสี่ยงของการเกิดอคติที่เกิดจากความผันแปรที่แท้จริง ณ วันที่ที่ระบุ
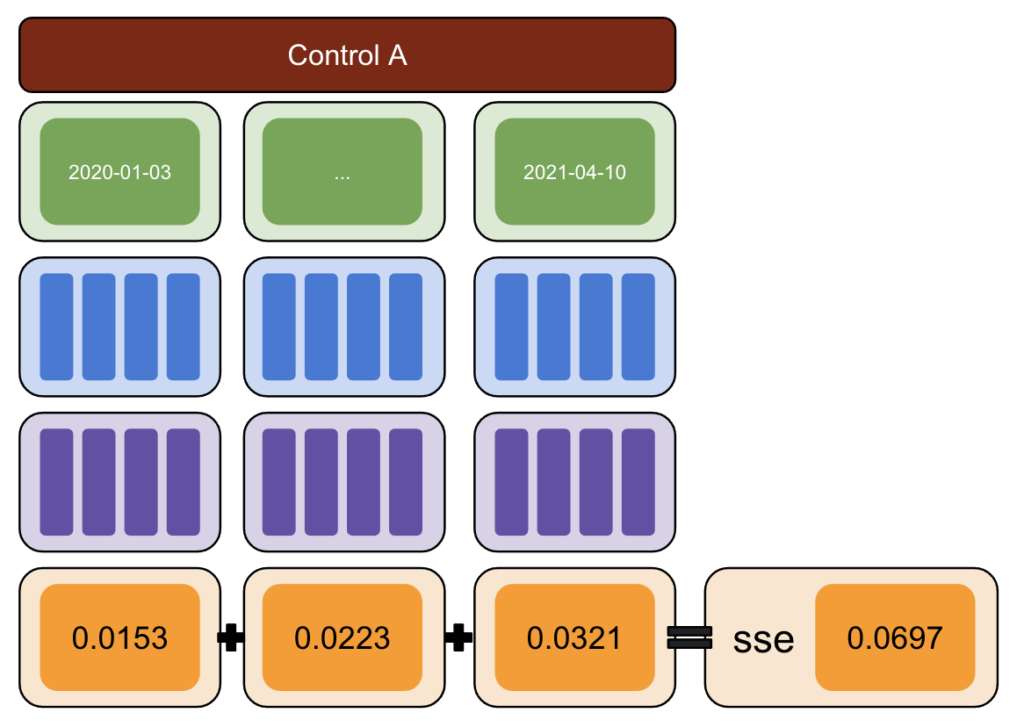
ทำซ้ำกับกลุ่มควบคุมหลายกลุ่มอีกครั้ง
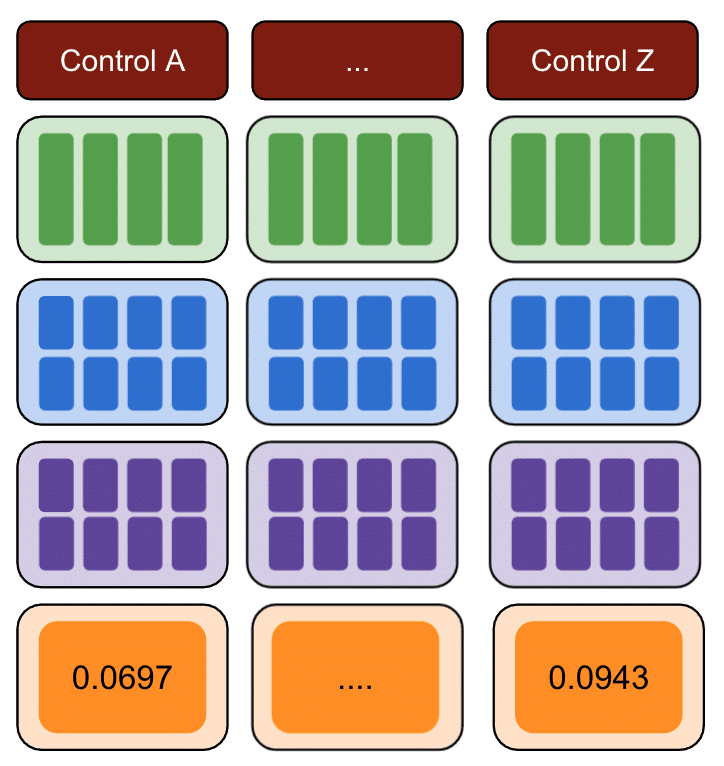
สุดท้าย การควบคุมที่มีจำนวนข้อผิดพลาดกำลังสองน้อยที่สุดคือกลุ่มควบคุมที่ดีที่สุดที่จะใช้สำหรับข้อมูลการทดสอบของคุณ
หากคุณทำซ้ำแต่ละขั้นตอนสำหรับข้อมูลการทดสอบแต่ละรายการ ผลลัพธ์จะแตกต่างกันไป
ในตารางผลลัพธ์ แต่ละแถวแสดงถึงกลุ่มควบคุม แต่ละคอลัมน์แสดงถึงกลุ่มทดสอบ ข้อมูลภายในคือ SSE
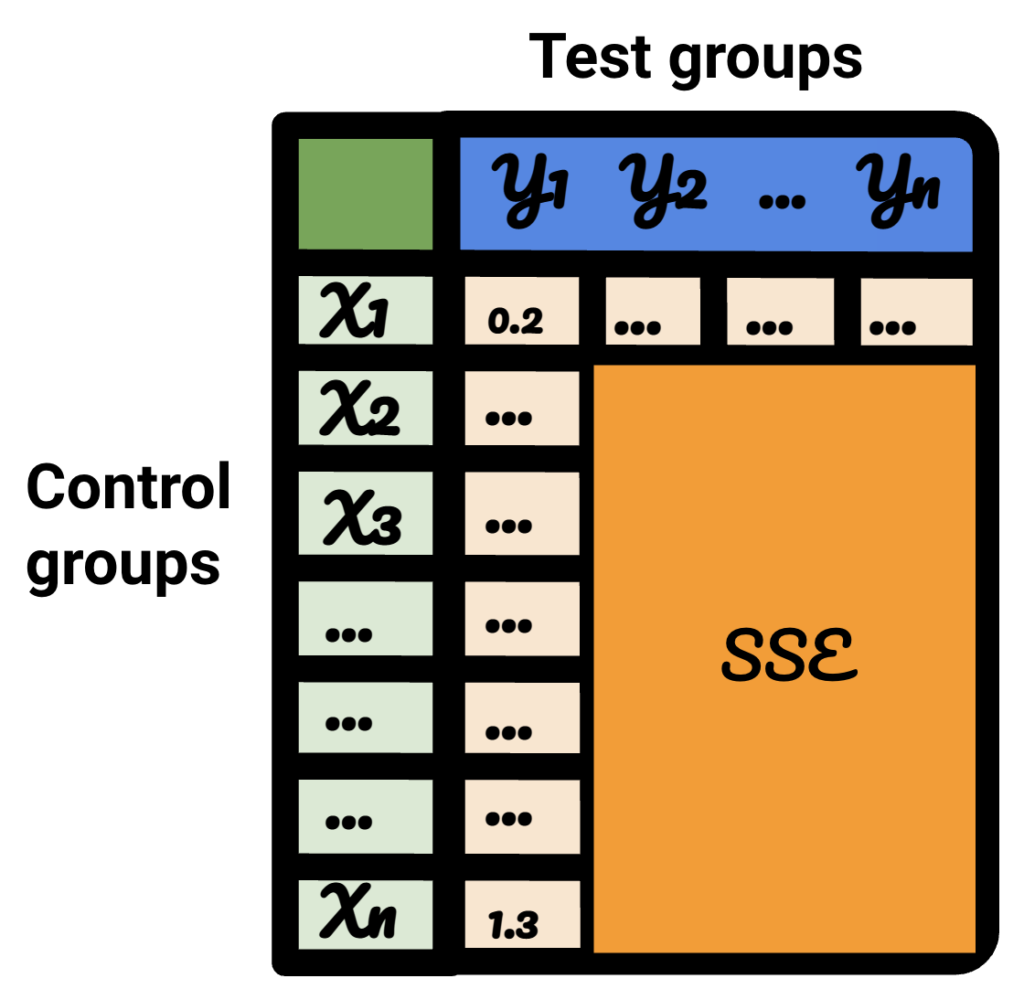
ในการจัดเรียงตารางนั้น ตอนนี้ฉันมั่นใจว่า สำหรับแต่ละกลุ่มการทดสอบ ฉันสามารถเลือกกลุ่มควบคุมที่ดีที่สุดสำหรับตารางนั้นได้
เราควรใช้กลุ่มควบคุมหรือไม่?
หลักฐานแสดงให้เห็นว่าการใช้กลุ่มควบคุมช่วยให้มีการประมาณการได้ดีกว่าการโพสต์ล่วงหน้าแบบธรรมดา
อย่างไรก็ตาม สิ่งนี้เป็นจริงก็ต่อเมื่อเราเลือกกลุ่มควบคุมที่เหมาะสม
ระยะเวลาในการประมาณค่าควรนานแค่ไหน?
คำตอบนั้นขึ้นอยู่กับการควบคุมที่เรากำลังเลือก
เมื่อไม่ได้ใช้ตัวควบคุม การทดลองก่อนหน้า 16 เดือนก็เพียงพอแล้ว
เมื่อใช้ตัวควบคุม การใช้เพียง 16 เดือนอาจนำไปสู่อัตราข้อผิดพลาดจำนวนมาก การใช้ 3 ปีช่วยลดความเสี่ยงในการตีความผิด
เราควรใช้การควบคุม 1 รายการหรือการควบคุมหลายรายการ
คำตอบสำหรับคำถามนั้นขึ้นอยู่กับข้อมูลการทดสอบ
ข้อมูลการทดสอบที่เสถียรมากสามารถทำงานได้ดีเมื่อเปรียบเทียบกับตัวควบคุมหลายตัว ในกรณีนี้ นี่เป็นสิ่งที่ดีเพราะการใช้การควบคุมจำนวนมากทำให้โมเดลได้รับผลกระทบน้อยลงจากความผันผวนที่ไม่สงสัยในการควบคุมแบบใดแบบหนึ่ง
ในชุดข้อมูลอื่นๆ การใช้ตัวควบคุมหลายตัวอาจทำให้แบบจำลองมีความแม่นยำน้อยกว่าการใช้ตัวเดียว 10-20 เท่า
งานที่น่าสนใจในชุมชน SEO
CausalImpact ไม่ใช่ไลบรารีเดียวที่สามารถใช้สำหรับการทดสอบ SEO และวิธีข้างต้นก็ไม่ใช่โซลูชันเดียวในการทดสอบความถูกต้อง
หากต้องการเรียนรู้วิธีแก้ไขปัญหาอื่น อ่านบทความที่น่าทึ่งบางส่วนที่แบ่งปันโดยผู้คนในชุมชน SEO
ก่อนอื่น Andrea Volpini ได้เขียนบทความที่น่าสนใจเกี่ยวกับการวัดประสิทธิภาพของ SEO โดยใช้ CausalImpact Analysis
จากนั้น Daniel Heredia ได้กล่าวถึงแพ็คเกจ Prophet ของ Facebook เพื่อคาดการณ์ปริมาณการใช้ SEO ด้วย Prophet และ Python
แม้ว่าห้องสมุดของศาสดาจะเหมาะสำหรับการพยากรณ์มากกว่าการทดลอง แต่ก็คุ้มค่าที่จะเรียนรู้ห้องสมุดต่าง ๆ เพื่อทำความเข้าใจโลกแห่งการทำนาย
สุดท้ายนี้ ฉันรู้สึกยินดีเป็นอย่างยิ่งกับการนำเสนอของแซนดี้ ลีที่ Brighton SEO ซึ่งเขาได้แบ่งปันข้อมูลเชิงลึกของ Data Science สำหรับการทดสอบ SEO และยกข้อผิดพลาดบางประการของการทดสอบ SEO
สิ่งที่ต้องพิจารณาเมื่อทำการทดลอง SEO
- เครื่องมือทดสอบแยก SEO ของบุคคลที่สามนั้นยอดเยี่ยม แต่ก็อาจไม่ถูกต้องเช่นกัน รอบคอบเมื่อเลือกโซลูชันของคุณ
- แม้ว่าฉันจะเขียนเกี่ยวกับเรื่องนี้ในอดีต แต่คุณไม่สามารถทำการทดสอบแยก SEO กับ Google Tag Manager เว้นแต่ฝั่งเซิร์ฟเวอร์ วิธีที่ดีที่สุดคือการปรับใช้ผ่าน CDN
- จงกล้าหาญเมื่อทำการทดสอบ CausalImpact มักจะไม่รับการเปลี่ยนแปลงเล็กน้อย
- การทดสอบ SEO ไม่ควรเป็นตัวเลือกแรกของคุณเสมอไป
- มีทางเลือกอื่นในการทดสอบการเปลี่ยนแปลงเล็กๆ น้อยๆ เช่น แท็กชื่อ การทดสอบ A/B ของ Google Ads หรือการทดสอบ A/B บนแพลตฟอร์ม การทดสอบ A/B จริงนั้นแม่นยำกว่าการทดสอบแยก SEO และมักจะให้ข้อมูลเชิงลึกเกี่ยวกับคุณภาพของชื่อของคุณมากกว่า
ผลลัพธ์ที่ทำซ้ำได้
ในบทช่วยสอนนี้ ฉันต้องการเน้นว่าสามารถปรับปรุงความแม่นยำของการทดลอง SEO ได้อย่างไรโดยไม่ต้องเป็นภาระในการรู้วิธีเขียนโค้ด นอกจากนี้ แหล่งที่มาของข้อมูลอาจแตกต่างกันและแต่ละไซต์ก็ต่างกัน
ดังนั้น โค้ด Python ที่ฉันใช้สร้างเนื้อหานี้จึงไม่ได้เป็นส่วนหนึ่งของขอบเขตของบทความนี้
อย่างไรก็ตาม ด้วยตรรกะ คุณสามารถทำซ้ำการทดลองข้างต้นได้
บทสรุป
หากคุณมีข้อเสนอเพียงข้อเดียวที่จะได้รับจากบทความนี้ การวิเคราะห์ CausalImpact นั้นอาจแม่นยำมาก แต่ก็อาจเป็นวิธีที่หลีกเลี่ยงได้เสมอ
เป็นสิ่งสำคัญมากสำหรับ SEO ที่ต้องการใช้แพ็คเกจนี้เพื่อทำความเข้าใจกับสิ่งที่พวกเขากำลังเผชิญอยู่ ผลลัพธ์ของการเดินทางของฉันคือ ฉันจะไม่เชื่อถือ CausalImpact หากไม่ได้ทดสอบความถูกต้องของแบบจำลองกับข้อมูลที่ป้อนก่อน