
วิธีสร้างแบบจำลองส่วนประสมการตลาดโดยอัตโนมัติด้วยสเปรดชีตฟีดข้อมูล MMM
เผยแพร่แล้ว: 2022-06-16การสร้างแบบจำลองส่วนประสมทางการตลาดหรือ MMM กำลังประสบกับยุคฟื้นฟูศิลปวิทยา กว่า 60 ปีนับตั้งแต่มีการใช้งานทั่วไป ต่างจากวิธีการระบุแหล่งที่มาทางการตลาดส่วนใหญ่ MMM ไม่ต้องการข้อมูลระดับผู้ใช้ แทนที่จะสร้างแบบจำลองว่าช่องทางใดสมควรได้รับเครดิตสำหรับการขายโดยการจับคู่การเพิ่มขึ้นอย่างรวดเร็วทางสถิติและการลดลงของการใช้จ่ายกับการกระทำและกิจกรรมในช่องทางการตลาดของคุณ การอัพเกรดจากการถดถอยเชิงเส้นอย่างง่ายเป็นเทคนิคต่างๆ เช่น การถดถอยแนวสันหรือวิธีเบย์เซียน การสร้างแบบจำลองส่วนประสมทางการตลาดกำลังถูกคิดค้นขึ้นใหม่สำหรับยุคใหม่

ต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ MMM หรือไม่
อ่านข้อดีและข้อเสียเกี่ยวกับการสร้างแบบจำลองส่วนประสมทางการตลาดเทียบกับการสร้างแบบจำลองการระบุแหล่งที่มา
อย่างไรก็ตาม มีอุปสรรคสำคัญที่ต้องเอาชนะ การสร้างแบบจำลองอาจใช้เวลา 3 ถึง 6 เดือนตามข้อมูลของ Meta/Facebook ซึ่งทำงานบนไลบรารี MMM แบบโอเพ่นซอร์สตั้งแต่เดือนตุลาคม พ.ศ. 2564 ตามการประมาณการ เวลาประมาณ 50% ถูกใช้ไปในการรวบรวมและทำความสะอาดข้อมูลก่อนเริ่มการสร้างแบบจำลอง . สิ่งนี้ตรงกับประสบการณ์ของฉันที่ Recast—และก่อนหน้านี้ของ Harry's— รวมถึงผลการศึกษา CrowdFlower ซึ่งพบว่า 60% ของเวลาวิทยาศาสตร์ข้อมูลถูกใช้ไปในการทำความสะอาดและจัดระเบียบข้อมูล
กรอไปข้างหน้า >>
- การล้างข้อมูล
- การสร้างแบบจำลองส่วนประสมทางการตลาด
- การสร้างแบบจำลองอัตโนมัติ
การล้างข้อมูลคือ 60% ของงาน และทำอย่างไรให้เป็น 0%
ในการสร้างแบบจำลองที่แม่นยำ คุณต้องใช้ข้อมูลของคุณในรูปแบบเฉพาะ การเตรียมข้อมูลให้พร้อมใช้เวลานาน ดังนั้นโครงการ MMM จึงใช้เวลานานกว่าที่จำเป็น สิ่งนี้ทำให้ MMM เป็นทักษะเฉพาะทางและมีราคาแพง ดังนั้นบริษัทส่วนใหญ่จึงสามารถสร้างแบบจำลองได้หนึ่งถึงสองแบบต่อปีเท่านั้น หากคุณสามารถทำให้กระบวนการเป็นอัตโนมัติโดยใช้เครื่องมือเช่น Supermetrics เพื่อสร้างฟีดข้อมูล MMM คุณสามารถอัปเดตโมเดลของคุณเป็นประจำ ช่วยให้คุณเพิ่มประสิทธิภาพงบประมาณการตลาดของคุณได้ดียิ่งขึ้น
รูปแบบข้อมูลแบบตาราง
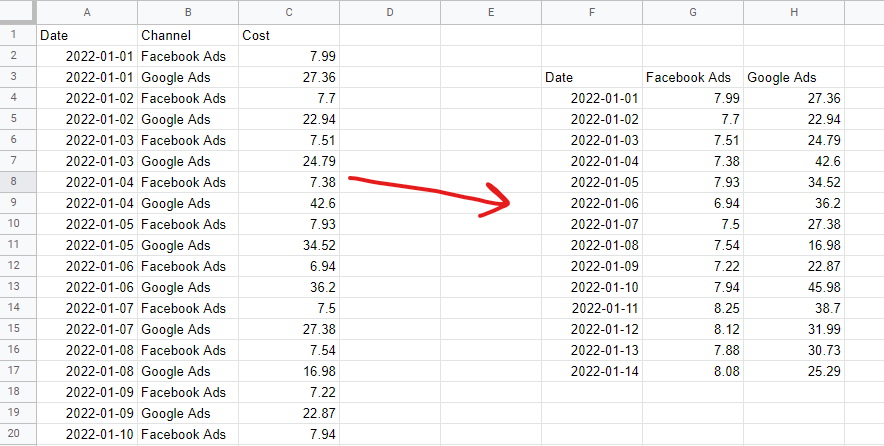
ในการสร้างแบบจำลองส่วนประสมทางการตลาด คุณต้องจัดวางข้อมูลของคุณในรูปแบบตารางที่ไม่ซ้อนกัน ซึ่งหมายความว่าหนึ่งแถวต่อการสังเกต—โดยปกติคือวันหรือสัปดาห์—และหนึ่งคอลัมน์ต่อ 'คุณลักษณะ' ของโมเดล—โดยทั่วไปคือการใช้จ่ายด้านสื่อและตัวแปรทั่วไปหรือตัวแปรภายนอก ข้อมูลตามหมวดหมู่ เช่น รายการวันหยุดประจำชาติ จำเป็นต้องเข้ารหัสเป็นตัวแปรจำลอง—1 เมื่อเป็นวันหยุดนั้น 0 เมื่อไม่ใช่
เข้าร่วมแหล่งข้อมูล
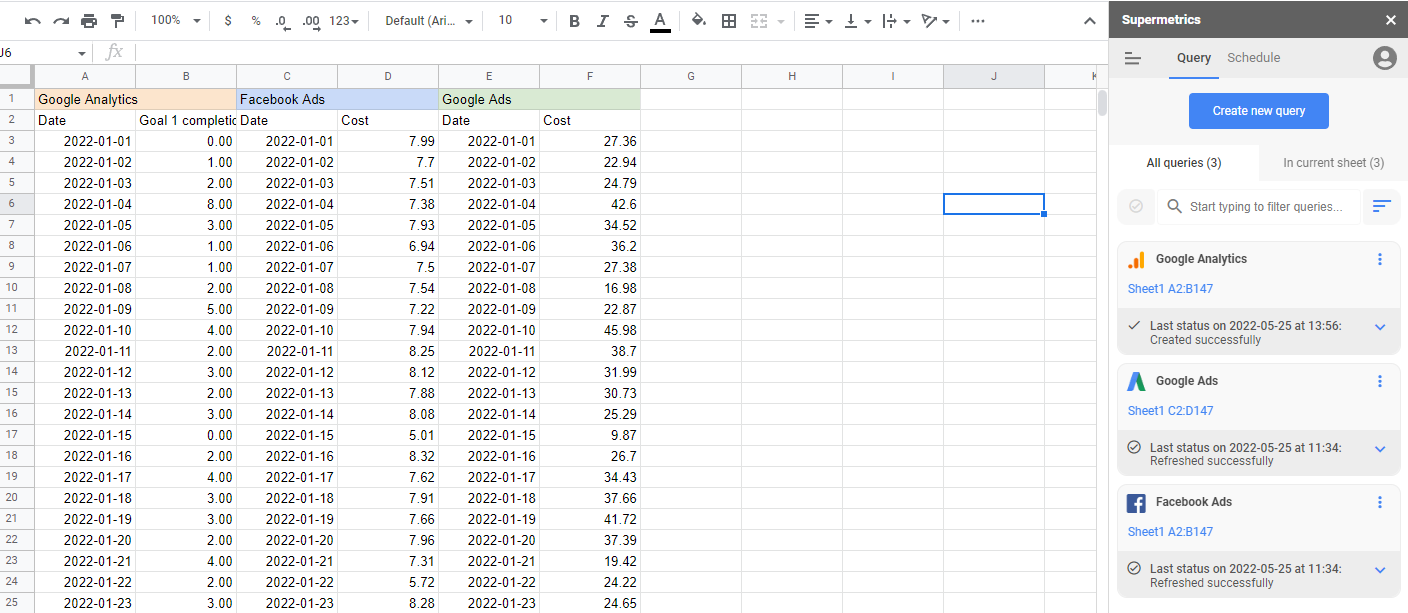
ในการสร้างรูปแบบการระบุแหล่งที่มาทางการตลาด คุณต้องมีข้อมูลการตลาดทั้งหมดของคุณในที่เดียว นี่คือสิ่งที่ Supermetrics จัดการให้คุณโดยอัตโนมัติ ด้วยตัวเชื่อมต่อกว่า 90 รายการ ค่าใช้จ่ายทางการตลาด กิจกรรม และกิจกรรมทั้งหมดของคุณจะถูกรวมเข้าไว้ในที่เดียว จัดการตามต้องการ แล้วส่งออกไปยังรูปแบบและตำแหน่งที่คุณต้องการ
กำลังส่งออกไปยัง Google ชีต
เมื่อคุณมีบัญชี Supermetrics แล้ว คุณต้องไปที่ส่วนขยาย > ส่วนเสริม > รับส่วนเสริมและติดตั้ง ระบบจะขอให้คุณตรวจสอบสิทธิ์ด้วยบัญชี Google ที่เชื่อมโยงกับบัญชี Supermetrics จากนั้นแถบด้านข้างจะปรากฏในเมนูส่วนขยาย
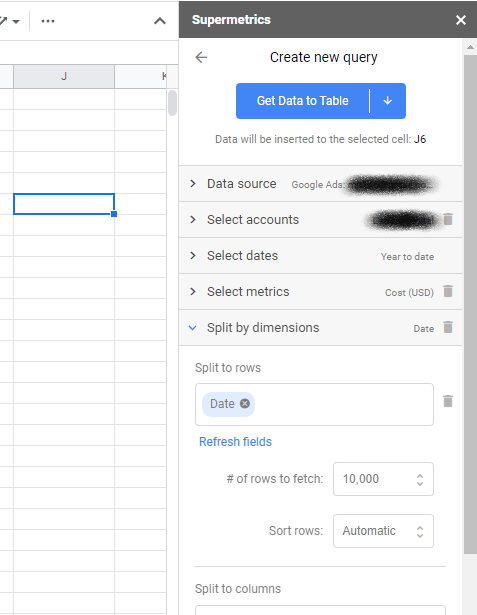
เมื่อดำเนินการเสร็จแล้ว คุณสามารถเปิดแถบด้านข้างได้ หากยังไม่ได้เปิดใช้ แล้วคลิกเพื่อสร้างคิวรีใหม่ การสืบค้นข้อมูลเป็นวิธีที่คุณตัดสินใจว่าจะดึงข้อมูลใดและจากบัญชีใด เมื่อคุณเลือกหนึ่งในแพลตฟอร์มโฆษณา เช่น โฆษณาบน Facebook และ Google Ads ระบบจะแจ้งให้คุณตรวจสอบสิทธิ์และให้สิทธิ์การเข้าถึง Supermetrics
จากนั้น คุณจะต้องเลือกบัญชีที่คุณต้องการดึงข้อมูลและช่วงวันที่ สุดท้าย เลือกเมตริกของคุณ—โดยปกติคือค่าใช้จ่ายหรือการแสดงผลสำหรับ MMM—และมิติข้อมูล—เลือกเฉพาะวันที่เพื่อให้สอดคล้องกับรูปแบบตารางเท่านั้น
หรือคุณอาจต้องการเพิ่มตัวกรองหากต้องการเลือกชุดแคมเปญเฉพาะ ตัวอย่างเช่น หากคุณมี 'YT: ' ในชื่อแคมเปญ YouTube ของคุณ คุณอาจต้องการเลือกแหล่งที่มาเหล่านั้นเป็นแหล่งที่มาที่แยกจากกัน จากนั้นทำซ้ำข้อความค้นหาและตัวกรองสำหรับแคมเปญประเภทอื่นๆ แต่ละประเภท
เมื่อคุณทำแบบสอบถามเสร็จแล้ว ตรวจสอบให้แน่ใจว่าคุณได้เลือกเซลล์ที่คุณต้องการดึงข้อมูลเข้าไป แล้วคลิก 'รับข้อมูลไปยังตาราง' หากคุณทำผิดพลาด เพียงทำซ้ำแบบสอบถามและวางไว้ในตำแหน่งที่ถูกต้อง ลบอีกอันหนึ่ง
ฉันพบว่าการใส่ชื่อของแต่ละแหล่งที่มาในเซลล์เหนือตารางนั้นมีประโยชน์ ดังนั้นฉันจึงรู้ว่าฉันกำลังดึงข้อมูลมาจากไหน ผลลัพธ์ควรมีลักษณะดังนี้:
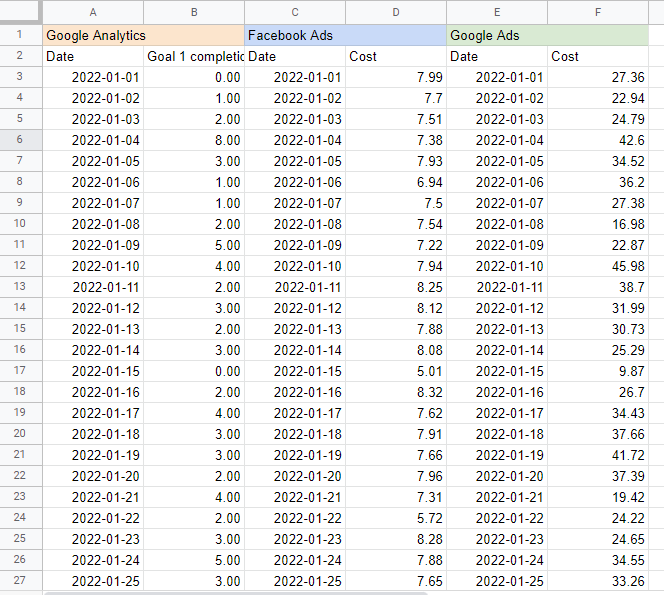
การสร้างแบบจำลองส่วนประสมทางการตลาดใน Google ชีต
การสร้างแบบจำลองส่วนประสมทางการตลาดเป็นเครื่องมือที่มีประสิทธิภาพสำหรับการระบุแหล่งที่มา แต่จริงๆ แล้วเข้าถึงได้ง่ายกว่าที่คุณคิด ผู้ปฏิบัติงานส่วนใหญ่ใช้โค้ดที่กำหนดเองและสถิติขั้นสูง แต่คุณสามารถทำพื้นฐานในช่วงบ่ายได้โดยไม่ต้องใช้ Excel หรือ Google ชีต
การถดถอยเชิงเส้นด้วยฟังก์ชัน LINEST
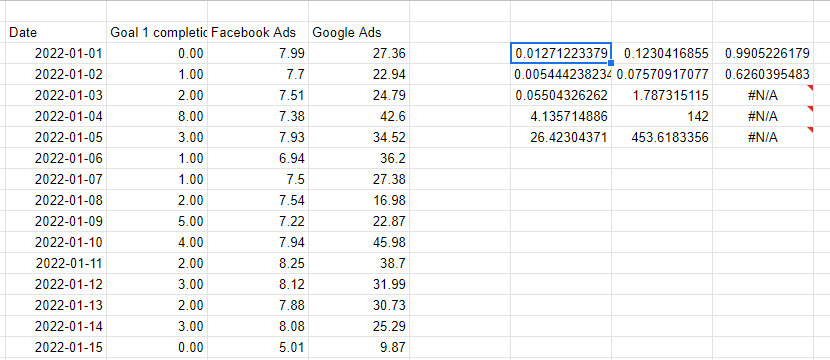
ทั้ง Excel และ Google ชีตต่างก็มีวิธีการง่ายๆ อย่างฟังก์ชัน LINEST สำหรับการถดถอยเชิงเส้นแบบหลายตัวแปร LINEST ทำงานโดยส่งผ่านคอลัมน์ที่เรากำลังพยายามทำนาย จากนั้นหลายคอลัมน์ที่แสดงตัวแปรที่เราใช้ทำนาย พารามิเตอร์สองตัวสุดท้ายคือว่าเราต้องการเส้นสกัดกั้นหรือไม่—โดยปกติคือ 1 สำหรับใช่—และไม่ว่าเราต้องการให้ผลลัพธ์เป็นรายละเอียดหรือไม่—ซึ่งประกอบด้วยสถิติทั้งหมดสำหรับแบบจำลอง ไม่ใช่แค่ค่าสัมประสิทธิ์
โปรดทราบว่าตัวแปร X ที่เราใช้เพื่อทำให้การคาดคะเนต้องต่อเนื่องกัน ดังนั้นฉันจึงอ้างอิงคอลัมน์ทางด้านซ้ายเพื่อทำซ้ำค่าที่อยู่ติดกัน
พยากรณ์ใหม่ด้วยสัมประสิทธิ์แบบจำลอง
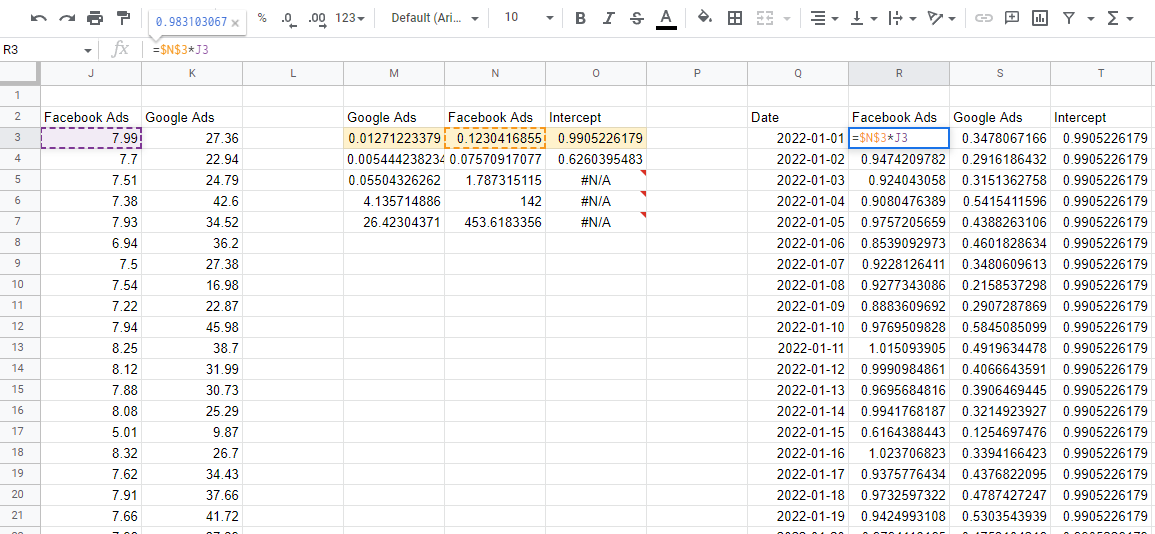
ตอนนี้เรามีแบบจำลองแล้ว เราจำเป็นต้องใช้สัมประสิทธิ์ในการประมาณผลกระทบของแต่ละช่องสัญญาณ ถ้าเรานำตัวเลขแถวบนสุด นั่นคือสัมประสิทธิ์ และคูณด้วยค่าอินพุตที่สัมพันธ์กันจากข้อมูลของเรา เราจะได้รับส่วนแบ่งของตัวแปรแต่ละตัวในการขายทั้งหมด

สิ่งหนึ่งที่ต้องระวังคือ LINEST จะแสดงผลค่าสัมประสิทธิ์ย้อนหลัง ค่าแรกที่เริ่มต้นจากด้านซ้ายจะเป็นตัวแปรสุดท้ายที่คุณป้อนเสมอ จากนั้นจะดำเนินต่อไปในลำดับที่กลับกันจนกว่าคุณจะได้ค่าสุดท้าย ซึ่งก็คือค่าสกัดกั้น หากคุณรวมค่าการมีส่วนร่วมเหล่านี้ทั้งหมดเข้าด้วยกัน ก็จะให้การคาดคะเนจากแบบจำลอง ซึ่งคุณสามารถเปรียบเทียบกับค่าจริงเพื่อให้แน่ใจว่าแบบจำลองนั้นถูกต้อง
การตรวจสอบเมตริกความถูกต้องของแบบจำลอง
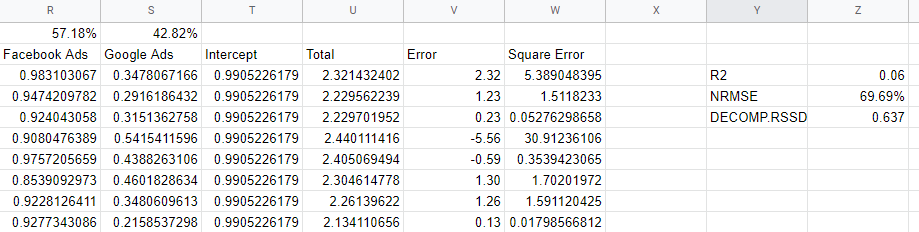
เราจะทราบได้อย่างไรว่าแบบจำลองของเราเชื่อถือได้หรือไม่ ตัวแบบควรเข้ากับข้อมูลได้ดี ควรจะสามารถทำนายข้อมูลใหม่ที่ยังไม่ได้ดู และควรมีค่าสัมประสิทธิ์ที่สมเหตุสมผล เมตริกการตรวจสอบความถูกต้องหลายตัวระบุข้อกำหนดเหล่านี้
ตรวจสอบฟังก์ชันในเทมเพลตเพื่อดูวิธีคำนวณเมตริกเหล่านี้
ในการใช้เทมเพลต ไปที่ 'ไฟล์' > 'ทำสำเนา' > 'เปิดใช้ Supermetrics' จากรายการส่วนเสริม > ทำซ้ำไฟล์นี้สำหรับบัญชีอื่น จากนั้นดำเนินการเลือกบัญชี
R2 หรือ R-Squared เป็นการวัดว่าแบบจำลองอธิบายความแปรปรวนของข้อมูลมากน้อยเพียงใด และอยู่ระหว่าง 0 ถึง 1: แบบจำลองที่ดีจะสูงกว่า 0.7 แต่สิ่งใดที่เข้าใกล้ 1 อาจน่าสงสัย เกือบ 0 เช่นเดียวกับแบบจำลองของเรา เป็นสัญญาณว่าเราไม่ได้รวมตัวแปรที่เพียงพอในแบบจำลองของเรา และจำเป็นต้องรวมสิ่งต่าง ๆ เช่น ช่องทางอินทรีย์ วันหยุด และปัจจัยเศรษฐกิจมหภาค
'Normalized Root Mean Square Error' คือวิธีที่เราวัดความแม่นยำ และพบโดยนำความแตกต่างระหว่างการคาดคะเนแบบจำลองกับค่าจริง จากนั้นหารากของค่ากำลังสองเป็นเปอร์เซ็นต์ของมูลค่าจริง ตามหลักการแล้ว วิธีนี้ใช้ข้อมูลที่มองไม่เห็น ซึ่งเป็นกลุ่มที่ระงับ แต่ในรูปแบบง่ายๆ ของเรา เราเพิ่งคำนวณข้อผิดพลาดกับข้อมูลในตัวอย่าง
ขั้นตอนการรูทและการยกกำลังสองจะจัดการกับค่าลบสำหรับเราและทำหน้าที่ลงโทษข้อผิดพลาดที่ใหญ่มาก ค่านี้สามารถตีความได้ว่าเป็นเปอร์เซ็นต์ของแบบจำลองที่ปิดในวันที่กำหนด จึงเป็นการวัดที่มีประโยชน์และใช้งานง่าย
ความน่าเชื่อถือเป็นหัวข้อใหญ่ และมักเป็นสิ่งที่นักวิเคราะห์ควรพูดในขั้นสุดท้าย อย่างไรก็ตาม การมีตัววัดที่คุณสามารถคำนวณทางโปรแกรมได้จะเป็นประโยชน์ เพื่อให้คุณเข้าใจว่าแบบจำลองนั้นเบี่ยงเบนไปในแง่ของสิ่งที่ค้นพบจากการผสมผสานช่องทางปัจจุบันของคุณมากน้อยเพียงใด
Demp RSSD เป็นตัวชี้วัดที่คิดค้นโดยทีมงาน Robyn ที่ Facebook ซึ่งวัดความแตกต่างระหว่างการจัดสรรการใช้จ่ายในปัจจุบันของคุณ และช่องทางใดที่ผลักดันให้เกิดผลกระทบที่ใหญ่ที่สุด ตามที่คาดการณ์โดยแบบจำลอง หากโมเดลดังกล่าวบอกว่าช่องทางที่ใหญ่ที่สุดของคุณไม่ได้กระตุ้นยอดขายได้มากขนาดนั้น แสดงว่าคุณมี Demp RSSD สูง
ในกรณีของเรา เรามีมูลค่าสูง 0.6 เนื่องจากโมเดลให้เครดิต Facebook มากเกินไป ซึ่งแสดงถึงการใช้จ่ายเพียงเล็กน้อย
นำเสนอ MMM โดยอัตโนมัติและทุกขนาด
การสร้างแบบจำลองส่วนประสมทางการตลาดเป็นหนึ่งในกิจกรรมที่สามารถปรับขนาดได้ไม่จำกัด คุณสามารถได้ผลลัพธ์ที่ดีในช่วงบ่ายด้วย Excel หรือ Google ชีต และ Supermetrics อย่างที่เราทำที่นี่ แต่คุณสามารถใช้เวลา 3 เดือนกับทีมนักวิทยาศาสตร์ข้อมูล 6 คนในการเขียนโค้ดที่กำหนดเองด้วยอัลกอริธึมที่ซับซ้อน เช่น Bayesian MCMC เพื่อสร้างอะไรเพิ่มเติม แข็งแกร่งและแม่นยำ
มีรายการตรวจสอบคุณลักษณะต่างๆ ที่นำไปสู่การสร้างแบบจำลองขั้นสูง ซึ่งบางรายการต้องใช้ความรู้ทางสถิติขั้นสูง เพิ่มวิศวกรข้อมูลราคาแพงหลายๆ คนเพื่อสร้างไปป์ไลน์ข้อมูล หากคุณไม่ได้ใช้ Supermetrics เพื่อทำให้ส่วนนั้นเป็นแบบอัตโนมัติ
ต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการสร้างแบบจำลองการผสมอัตโนมัติหรือไม่
ดูบทความการสร้างแบบจำลองส่วนประสมการตลาดอัตโนมัติของเรา
ถูกเตือน: MMM นั้นยาก คุณสามารถใช้เงิน $500, $5,000 หรือ $50k ในการสร้างแบบจำลอง และดูผลลัพธ์ที่แตกต่างกันอย่างมากในด้านความแม่นยำและความทนทาน สิ่งที่สำคัญจริงๆ คือ ค่าเสียโอกาสในการจัดสรรค่าใช้จ่ายทางการตลาดของคุณผิด
หากคุณใช้จ่ายเดือนละ $10ka โมเดลสเปรดชีตไตรมาสละครั้งก็ไม่เป็นไร อย่างไรก็ตาม หากคุณใช้จ่ายมากกว่า $100,000 ต่อเดือน แม้การถูกลด 5% ก็อาจทำให้คุณต้องเสียหลายหมื่นดอลลาร์ต่อปี
ไม่แน่ใจว่าคุณต้องการโมเดลการเข้าถึงข้อมูลแบบใดสำหรับฟีด MMM ของคุณ
ตรวจสอบบทความของเราเพื่อเลือกสิ่งที่เหมาะสมสำหรับธุรกิจของคุณ
นั่นคือเหตุผลที่ควรลงทุนในการสร้างแบบจำลองขั้นสูงขึ้น ดำเนินการวิเคราะห์บิลด์กับซื้อเพื่อตัดสินใจระหว่างโซลูชันแบบกำหนดเองที่สร้างบนไลบรารีโอเพนซอร์ซ เช่น Robyn ของ Facebook หรือซอฟต์แวร์การระบุแหล่งที่มาขั้นสูง เช่น สิ่งที่เราสร้างขึ้นที่ Recast
เกี่ยวกับผู้เขียน
Michael Kaminsky เป็นนักเศรษฐมิติที่ผ่านการฝึกอบรมมาแล้วซึ่งมีพื้นฐานด้านการดูแลสุขภาพและเศรษฐศาสตร์สิ่งแวดล้อม ก่อนหน้านี้เขาเคยสร้างทีมวิทยาศาสตร์การตลาดให้กับแบรนด์ผลิตภัณฑ์ดูแลผู้ชาย Harry's ก่อนที่จะร่วมก่อตั้ง Recast

ปรับปรุงประสิทธิภาพธุรกิจของคุณ
โดยการรวมการตลาดและธุรกิจอัจฉริยะในคลังข้อมูลของคุณ