
เพิ่มขีดความสามารถด้านความปลอดภัยของธนาคาร: การเรียนรู้ของเครื่องสำหรับการตรวจจับการฉ้อโกง
เผยแพร่แล้ว: 2023-11-14ทุกโอกาสมาพร้อมกับภัยคุกคาม การเปลี่ยนแปลงสู่ดิจิทัลในอุตสาหกรรมการธนาคารช่วยปรับปรุงประสบการณ์ของลูกค้าและขยายฐานลูกค้าไปสู่ประชากรที่ก่อนหน้านี้ไม่มีบัญชีธนาคาร ข้อเสียคือธุรกรรมออนไลน์และโซลูชันการชำระเงินดิจิทัลเปิดช่องทางใหม่ให้ผู้ฉ้อโกงได้ใช้ประโยชน์
ข้อค้นพบจากการสำรวจการฉ้อโกงของ KMPG ระบุว่าการโจมตีทางไซเบอร์มีความถี่และความรุนแรงเพิ่มขึ้น ส่งผลให้สูญเสียมูลค่าหลายพันล้านดอลลาร์
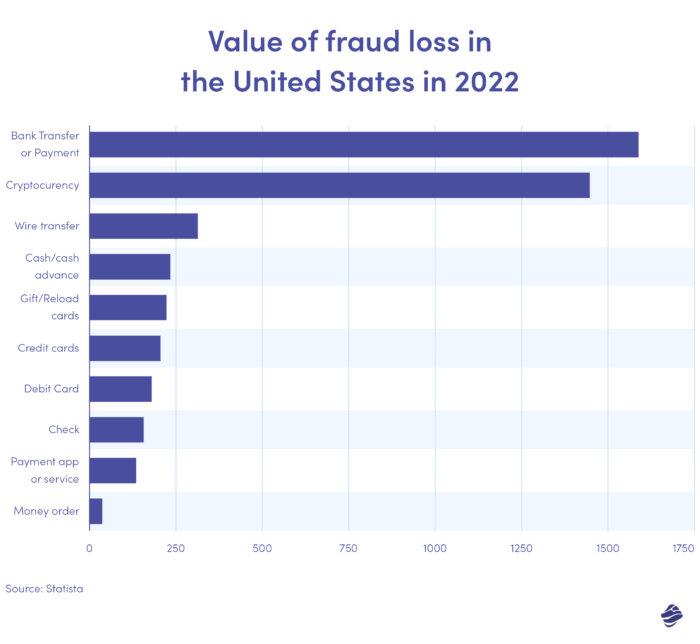
กราฟด้านบนแสดงมูลค่าการสูญเสียจากการฉ้อโกงโดยวิธีการชำระเงินในสหรัฐอเมริกาในปี 2022 การโอนเงินและการชำระเงินผ่านธนาคารมีปริมาณสูงสุด โดยขาดทุน 1.59 พันล้านดอลลาร์
ความสูญเสียเหล่านี้ทำให้สถาบันการธนาคารต้องนำโซลูชั่นใหม่ๆ มาใช้เพื่อตรวจจับ บรรเทา และป้องกันการฉ้อโกงทางการเงิน วิธีหนึ่งคือปัญญาประดิษฐ์ (AI) โดยเฉพาะการเรียนรู้ของเครื่อง
ในบทความนี้ เราจะพูดถึงทุกสิ่งที่คุณจำเป็นต้องรู้เกี่ยวกับ การเรียนรู้ของเครื่องเพื่อการตรวจจับการฉ้อโกง รวมถึงคุณประโยชน์และแอปพลิเคชันในชีวิตจริง
วิวัฒนาการของการตรวจจับการฉ้อโกง
การตรวจจับการฉ้อโกงแบบดั้งเดิมเป็นไปตามแนวทางตามกฎ ตามชื่อที่แนะนำ จะดำเนินการภายใต้ชุดของกฎหรือเงื่อนไขที่กำหนดว่าธุรกรรมนั้นเป็นของแท้หรือฉ้อโกง เงื่อนไขทั่วไป ได้แก่ สถานที่ (เป็นการซื้อนอกพื้นที่ปกติของผู้ใช้หรือไม่) และความถี่ (จำนวนและประเภทการซื้อเป็นเรื่องปกติสำหรับผู้ใช้หรือไม่)
การทำธุรกรรมจะต้องผ่านเมื่อตรงตามเงื่อนไขเท่านั้น ตัวอย่างเช่น ลูกค้าในโอไฮโอมีการเรียกเก็บเงิน POS ในนิวซีแลนด์อย่างกะทันหัน ตำแหน่งอยู่นอกรหัสพื้นที่ของผู้ใช้ ดังนั้นระบบจึงทำเครื่องหมายธุรกรรมว่าฉ้อโกง
ระบบตรวจจับการฉ้อโกงประเภทนี้มีข้อเสียหลายประการ
- มันก่อให้เกิดผลบวกลวงจำนวนมาก นี่คือที่ที่คุณบล็อกการชำระเงินจากลูกค้าจริง
- มันไม่ยืดหยุ่น แนวทางที่อิงกฎเกณฑ์ใช้ผลลัพธ์ที่ตายตัว ทำให้ยากต่อการปรับให้เข้ากับแนวโน้มในระบบธนาคารดิจิทัล คุณต้องเปลี่ยนกฎเกณฑ์เพื่อตรวจจับการฉ้อโกงรูปแบบใหม่
- มันไม่ปรับขนาด เมื่อข้อมูลเพิ่มขึ้น ความพยายามในการป้องกันก็เพิ่มขึ้นเช่นกัน การเปลี่ยนแปลงใดๆ ในระบบจะต้องดำเนินการด้วยตนเอง ซึ่งทำให้มีราคาแพงและใช้เวลานาน
การตรวจจับการฉ้อโกงตามกฎทำงาน อย่างไรก็ตาม ข้อเสียของมันทำให้ไม่เหมาะกับสภาพแวดล้อมดิจิทัลสมัยใหม่ ไม่สามารถจดจำรูปแบบและอาศัยการแทรกแซงของมนุษย์
นอกจากนี้ แฮกเกอร์ไม่ปฏิบัติตามกำหนดการ 9-5 และสามารถปรับใช้วิธีการที่ซับซ้อน เช่น การปลอมแปลงตำแหน่งและการแอบอ้างพฤติกรรมของลูกค้า เพื่อหลอกระบบตรวจจับการฉ้อโกง ดังนั้น คุณจำเป็นต้องมีระบบที่ได้รับการพัฒนาอย่างสูงพอๆ กัน ซึ่งทำงานได้ตลอด 24 ชั่วโมงทุกวัน
เข้าสู่การเรียนรู้ของเครื่อง
การเรียนรู้ของเครื่องคือปัญญาประดิษฐ์ (AI) ที่ใช้ข้อมูลเพื่อฝึกอัลกอริธึมการตรวจจับการฉ้อโกงเพื่อเปิดเผยรูปแบบและความสัมพันธ์ของข้อมูล รับข้อมูลเชิงลึก และทำการคาดการณ์
คุณคุ้นเคยกับแมชชีนเลิร์นนิงอยู่แล้ว แม้ว่าคุณจะไม่รู้ก็ตาม ตัวอย่างเช่น เมื่อใดก็ตามที่คุณมีส่วนร่วมกับโพสต์ Instagram คุณจะป้อนข้อมูลอัลกอริทึมเกี่ยวกับประเภทเนื้อหาที่คุณต้องการ จากนั้นจะค้นหาเนื้อหาที่คล้ายกันในแอปเพื่อเพิ่มลงในฟีดของคุณ
การเรียนรู้ของเครื่องจะเปลี่ยนการตรวจจับการฉ้อโกงอย่างไร
การตรวจจับการฉ้อโกงในระบบธนาคารโดยใช้แมชชีนเลิร์นนิงกำลังเปลี่ยนแปลงอุตสาหกรรมไปแล้ว โดยมีการระบุและการตอบสนองต่อการฉ้อโกงที่รวดเร็ว ยืดหยุ่นมากขึ้น และแม่นยำยิ่งขึ้น
ระบบ AI วิเคราะห์รูปแบบในข้อมูลลูกค้าและเปลี่ยนแปลงกฎโดยอัตโนมัติตามภัยคุกคามในอดีตและที่เกิดขึ้นใหม่
โปรดจำไว้ว่าการเรียกเก็บเงิน POS ของนิวซีแลนด์ที่เรากล่าวถึงก่อนหน้านี้ การตรวจจับการฉ้อโกงโดยใช้การเรียนรู้ของเครื่อง จะพิจารณาว่าบัตรธนาคารใบเดียวกันนั้นมีการซื้อเที่ยวบินไปยังสถานที่นั้น ดังนั้นการเดบิตใหม่จึงน่าจะถูกต้องตามกฎหมาย
มีการใช้แบบจำลองสองแบบในการฝึกอัลกอริธึมเพื่อตรวจจับการฉ้อโกง: การเรียนรู้ของเครื่องภายใต้การดูแลและการเรียนรู้ของเครื่องแบบไม่ได้รับการดูแล
การเรียนรู้ของเครื่องภายใต้การดูแล
โมเดลการเรียนรู้ภายใต้การดูแลจะฟีดอัลกอริธึมข้อมูลจำนวนมากที่ถูกแท็กว่าเป็นการฉ้อโกงหรือไม่ฉ้อโกง อัลกอริทึมจะศึกษาตัวอย่างเหล่านี้และเรียนรู้ว่ารูปแบบและความสัมพันธ์ใดที่แยกธุรกรรมที่ถูกต้องออกจากธุรกรรมที่ฉ้อโกง
โมเดลการเรียนรู้นี้ใช้เวลานานเนื่องจากต้องมีการแท็กข้อมูลด้วยตนเอง นอกจากนี้ ชุดข้อมูลของคุณต้องมีป้ายกำกับอย่างถูกต้องและมีการจัดระเบียบอย่างดี ธุรกรรมที่ติดแท็กไม่ถูกต้องจะส่งผลต่อความแม่นยำของอัลกอริทึม
นอกจากนี้ยังเรียนรู้จากอินพุตที่รวมอยู่ในชุดการฝึกเท่านั้น ดังนั้น ธุรกรรมผ่านฟีเจอร์แอปธนาคารบนมือถือที่เพิ่งเปิดตัวซึ่งไม่ได้เป็นส่วนหนึ่งของข้อมูลในอดีตจะไม่ถูกตั้งค่าสถานะ ขณะนี้มีช่องโหว่สำหรับผู้ฉ้อโกงในการแสวงหาผลประโยชน์
การเรียนรู้ของเครื่องที่ไม่ได้รับการดูแล
โมเดลการเรียนรู้แบบไม่มีผู้ดูแลใช้ข้อมูลของมนุษย์น้อยที่สุด อัลกอริทึมเรียนรู้รูปแบบและความสัมพันธ์จากข้อมูลที่ไม่ได้แท็กจำนวนมาก โดยจัดกลุ่มชุดข้อมูลตามความเหมือนและความแตกต่าง
วัตถุประสงค์คือเพื่อตรวจหากิจกรรมที่ผิดปกติที่ไม่รวมอยู่ในชุดข้อมูลการฝึกอบรม ดังนั้น การเรียนรู้แบบไม่มีผู้ดูแลจึงเริ่มต้นจากจุดที่การเรียนรู้แบบมีผู้สอนหลุดออกไปและตรวจพบการฉ้อโกงครั้งใหม่
โปรดจำไว้ว่าคุณไม่จำเป็นต้องเลือกระหว่างโมเดลแมชชีนเลิร์นนิงแบบมีผู้ดูแลหรือไม่มีผู้ดูแล คุณสามารถใช้ร่วมกันได้ (โมเดลการเรียนรู้แบบกึ่งมีผู้สอน) หรือแยกอิสระก็ได้
ประโยชน์ของการใช้ ML ในการตรวจจับการฉ้อโกง
เราได้บอกเป็นนัยถึงประโยชน์ของการตรวจจับการฉ้อโกงโดยใช้แมชชีนเลิร์นนิงในระบบธนาคาร แต่เราจะพูดคุยกันต่อไป
- ความเร็ว
การคำนวณของแมชชีนเลิร์นนิงเกิดขึ้นอย่างรวดเร็วและให้การตัดสินใจเรื่องการฉ้อโกงแบบเรียลไทม์ แม้ว่าอัลกอริธึมที่อิงกฎจะตัดสินใจแบบเรียลไทม์ แต่ก็อาศัยกฎที่เป็นลายลักษณ์อักษรเพื่อแจ้งการฉ้อโกง
จะเกิดอะไรขึ้นในสถานการณ์ใหม่ที่ไม่มีกฎที่กำหนดไว้ล่วงหน้า มันนำไปสู่การบวกลวงหรือผลลบลวง
แมชชีนเลิร์นนิงตรวจจับรูปแบบใหม่ๆ โดยอัตโนมัติ วิเคราะห์กิจกรรมปกติของลูกค้า และคำนวณผลลัพธ์ที่เหมาะสมภายในเสี้ยววินาที
- ความแม่นยำ
ระบบการตรวจจับตามกฎจะบล็อกธุรกรรมจริงหรืออนุญาตธุรกรรมที่เป็นการฉ้อโกง เนื่องจากไม่ตรวจจับความแตกต่างในพฤติกรรมของลูกค้า
ระบบการเรียนรู้ของเครื่องจักรจะพิจารณาตัวแปรที่อยู่นอกเหนือกฎเกณฑ์ที่เขียนไว้ เช่น พฤติกรรมการฉ้อโกงที่ทราบ ตัวแปรเหล่านี้ช่วยให้บริบทของธุรกรรมลดอัตราการเกิดผลบวกลวงลง
- ความยืดหยุ่น
แมชชีนเลิร์นนิงมีความยืดหยุ่นและตอบสนองได้ ความสามารถในการเรียนรู้ด้วยตนเองทำให้ระบบนี้สามารถปรับให้เข้ากับสถานการณ์ใหม่และตรวจจับภัยคุกคามใหม่ๆ ระบบที่อิงกฎเกณฑ์เข้มงวดและไม่มีความสามารถในการเรียนรู้ ดังนั้นจึงสามารถตอบสนองกิจกรรมการฉ้อโกงตามกฎที่กำหนดไว้ล่วงหน้าเท่านั้น
- ประสิทธิภาพ
อัลกอริธึมการเรียนรู้ของเครื่องสามารถวิเคราะห์ข้อมูลธุรกรรมหลายพันรายการต่อวินาที แทนที่จะต้องใช้แรงงานและต้นทุนค่าใช้จ่ายในการสืบสวนคดีฉ้อโกงระดับต่ำถึงปานกลาง แมชชีนเลิร์นนิงสามารถประมวลผลการฉ้อโกงซ้ำๆ หรือชัดเจนได้ ช่วยให้ผู้เชี่ยวชาญด้านการฉ้อโกงมุ่งเน้นไปที่รูปแบบที่ซับซ้อนซึ่งต้องการข้อมูลเชิงลึกของมนุษย์
- ความสามารถในการขยายขนาด
ปริมาณข้อมูลที่เพิ่มขึ้นสร้างแรงกดดันต่อระบบที่อิงกฎเกณฑ์ กฎใหม่เพิ่มความซับซ้อนให้กับระบบ ทำให้ยากต่อการรักษา ข้อผิดพลาดหรือข้อขัดแย้งใดๆ อาจทำให้ทั้งโมเดลไม่มีประสิทธิภาพ
ระบบการเรียนรู้ของเครื่องเป็นสิ่งที่ตรงกันข้าม พวกเขาไม่เพียงแต่ดูดซับข้อมูลใหม่จำนวนมากเท่านั้น แต่ยังปรับปรุงอีกด้วย
เทคนิคการเรียนรู้ของเครื่องที่ใช้ในการตรวจจับการฉ้อโกง
ก่อนที่เราจะตรวจสอบอัลกอริธึมต่างๆ ที่ใช้ในการตรวจจับการฉ้อโกงของ AI เรามาดูภาพรวมวิธีการทำงานของระบบกันก่อน
ขั้นตอนแรกคือการป้อนข้อมูล ความแม่นยำของแบบจำลองขึ้นอยู่กับปริมาณและคุณภาพของข้อมูล ยิ่งคุณเพิ่มข้อมูลคุณภาพสูงเท่าใด โมเดลก็จะยิ่งมีความแม่นยำมากขึ้นเท่านั้น
จากนั้น แบบจำลองจะวิเคราะห์ข้อมูลและแยกคุณลักษณะหลัก ที่อธิบายพฤติกรรมปกติเทียบกับพฤติกรรมที่ฉ้อโกง คุณสมบัติเหล่านี้รวมถึงข้อมูลประจำตัวของลูกค้า (อีเมลหรือหมายเลขโทรศัพท์) สถานที่ (IP หรือที่อยู่สำหรับจัดส่ง) วิธีการชำระเงิน (ชื่อผู้ถือบัตรและประเทศต้นทาง) และอื่นๆ
ขั้นตอนที่สามคือ การฝึกอบรมอัลกอริธึม (ที่มีข้อมูลมากขึ้น) เพื่อแยกแยะระหว่างธุรกรรมของแท้และธุรกรรมที่ฉ้อโกง แบบจำลองจะได้รับชุดข้อมูลการฝึกอบรมและคาดการณ์ความน่าจะเป็นของการฉ้อโกงในกรณีต่างๆ เมื่ออัลกอริทึมได้รับการฝึกฝนเพียงพอแล้ว คุณก็พร้อมที่จะเปิดใช้งาน
ตอนนี้เรามาดูอัลกอริธึมต่างๆ ที่คุณสามารถใช้ได้
1. การถดถอยโลจิสติก
การถดถอยโลจิสติกเป็นอัลกอริทึมการเรียนรู้แบบมีผู้สอน โดยจะคำนวณความน่าจะเป็นของการฉ้อโกงในระดับไบนารี ทั้งการฉ้อโกงหรือไม่ฉ้อโกง ตามพารามิเตอร์ของแบบจำลอง
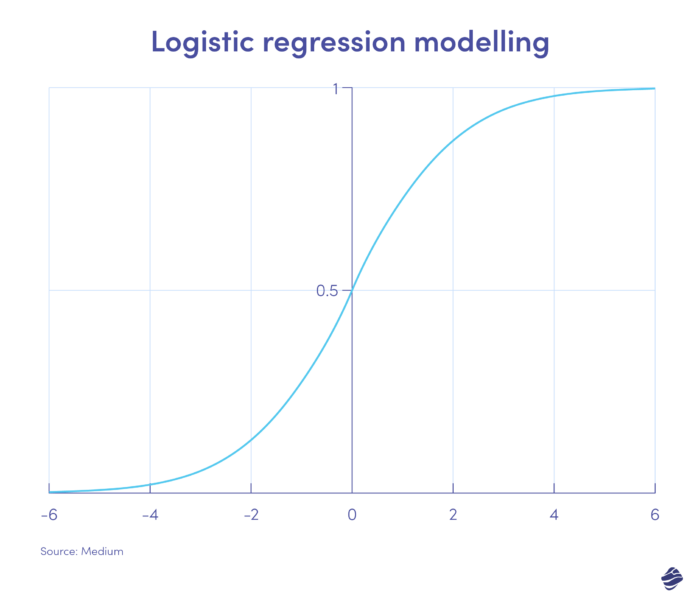
ธุรกรรมที่อยู่ด้านบวกของกราฟมีแนวโน้มว่าจะเป็นการฉ้อโกงมากที่สุด ในขณะที่ธุรกรรมที่อยู่ด้านลบมีแนวโน้มว่าจะถูกต้องตามกฎหมาย
2. แผนผังการตัดสินใจ
แผนผังการตัดสินใจเป็นอัลกอริธึมการเรียนรู้แบบมีผู้สอน แต่ไปไกลกว่าอัลกอริธึมการถดถอยลอจิสติก เป็นโครงสร้างการตัดสินใจแบบลำดับชั้นที่วิเคราะห์ข้อมูลในระดับต่างๆ เพื่อพิจารณาว่าธุรกรรมนั้นเป็นของแท้หรือเป็นการฉ้อโกง
ด้านล่างนี้คือภาพประกอบของแผนผังการตัดสินใจสำหรับการตรวจจับการฉ้อโกงบัตรเครดิต
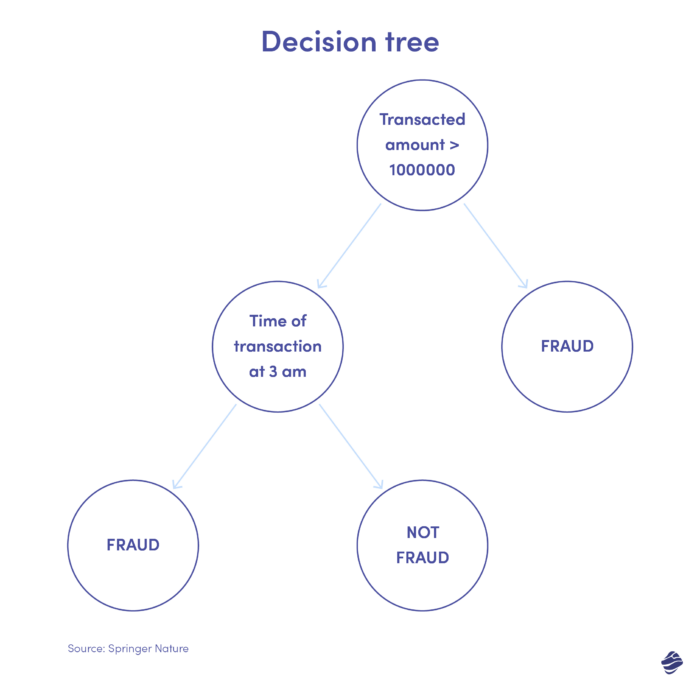
เงื่อนไขในการระบุว่าธุรกรรมเป็นการฉ้อโกงหรือไม่คือจำนวนเงินของธุรกรรม หากมูลค่าของธุรกรรมเกินเกณฑ์ที่กำหนด อัลกอริธึมจะพิจารณาว่าเป็นการฉ้อโกง ถ้าไม่เช่นนั้น ทรีจะตรวจสอบเงื่อนไขอื่น – เวลาธุรกรรม หากเวลาไม่ปกติ (ที่นี่ตี 3) ก็มีแนวโน้มว่าจะเป็นการฉ้อโกง ถ้าไม่เช่นนั้นจะตรวจสอบเงื่อนไขอื่น มันดำเนินต่อไป
3. ป่าสุ่ม
ฟอเรสต์สุ่มคือการรวมกันของแผนผังการตัดสินใจจำนวนมาก โดยแต่ละแผนผังการตัดสินใจจะตรวจสอบเงื่อนไขที่แตกต่างกัน เช่น ตัวตน สถานที่ ฯลฯ
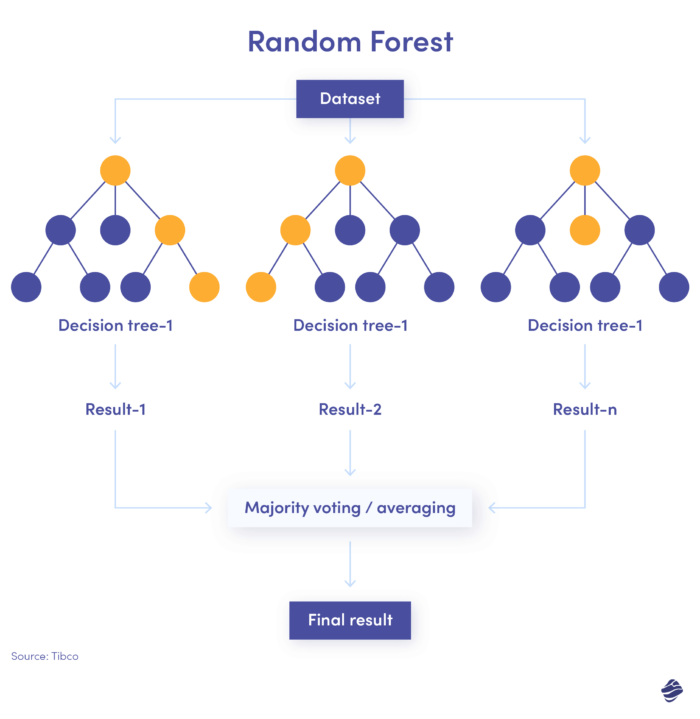
หลังจากตรวจสอบพารามิเตอร์ทั้งหมดแล้ว แผนผังย่อยทุกรายการจะเสนอการตัดสินใจ ยอดรวมทั้งหมดจะตัดสินว่าธุรกรรมนั้นเป็นของแท้หรือฉ้อโกง

4. โครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมเป็นอัลกอริธึมที่ซับซ้อนและไม่ได้รับการดูแล โครงข่ายประสาทเทียมได้รับแรงบันดาลใจจากสมองมนุษย์ในการประมวลผลข้อมูลในหลายเลเยอร์เพื่อดึงคุณสมบัติระดับสูงออกมา อัลกอริธึมนี้ทำงานร่วมกับการเรียนรู้เชิงลึกซึ่งสามารถจดจำรูปแบบในรูปภาพ ข้อความ เสียง และข้อมูลอื่น ๆ ได้
นี่คือโครงข่ายประสาทเทียมเวอร์ชันที่เรียบง่าย
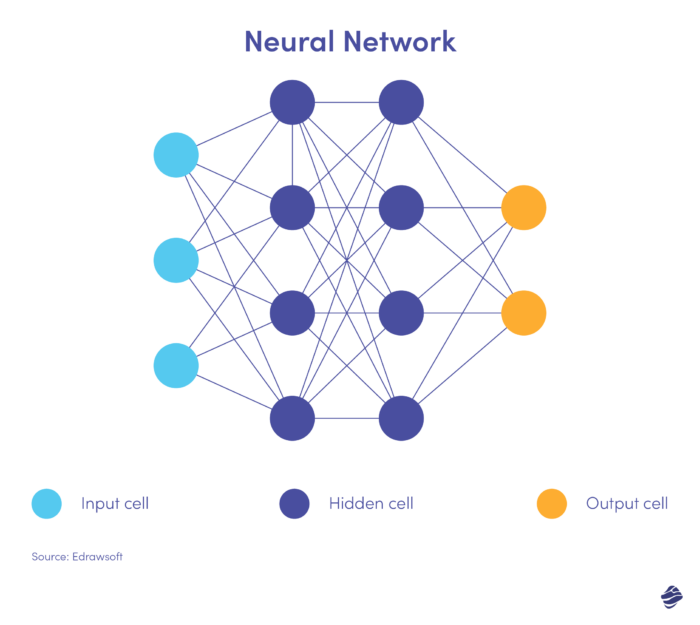
โครงข่ายประสาทเทียมมีสามชั้น: อินพุต ซ่อนเร้น และเอาต์พุต เลเยอร์อินพุตประมวลผลข้อมูล เลเยอร์ที่ซ่อนอยู่จะวิเคราะห์ข้อมูลจากเลเยอร์อินพุตเพื่อระบุรูปแบบที่ซ่อนอยู่ และเลเยอร์เอาต์พุตจะจัดประเภทข้อมูล
โครงข่ายประสาทเทียมระดับลึกมีหลายชั้นที่ซ่อนอยู่ เหมาะอย่างยิ่งสำหรับการระบุความสัมพันธ์แบบไม่เชิงเส้นและตรวจจับสถานการณ์การฉ้อโกงที่ไม่เคยเกิดขึ้นมาก่อน
5. รองรับเครื่องเวกเตอร์
Support vector machines (SVM) เป็นอัลกอริธึมการเรียนรู้ภายใต้การดูแลที่คาดการณ์ จำแนก และตรวจจับค่าผิดปกติ
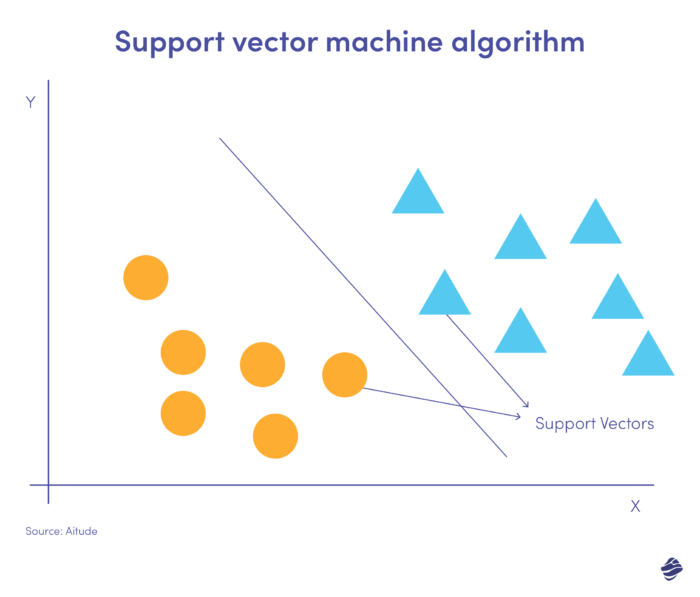
ภาพประกอบ SVM เชิงเส้นนี้แสดงชุดข้อมูลสองชุดที่คั่นด้วยเส้นตรงที่เรียกว่าไฮเปอร์เพลน เป็นขอบเขตการตัดสินใจที่จัดประเภทข้อมูลเป็นการฉ้อโกงและการไม่ฉ้อโกง
จุดข้อมูลที่อยู่ห่างจากไฮเปอร์เพลนสามารถจำแนกได้ง่าย เวกเตอร์รองรับ (ใกล้กับไฮเปอร์เพลนมากที่สุด) นั้นยากต่อการจัดหมวดหมู่ ค่าผิดปกติเหล่านี้อาจส่งผลต่อตำแหน่งของไฮเปอร์เพลนหากถูกถอดออก
6. K-เพื่อนบ้านที่ใกล้ที่สุด
K-เพื่อนบ้านที่ใกล้ที่สุด (KNN) เป็นอัลกอริธึมการเรียนรู้แบบมีผู้สอน มันทำงานบนสมมติฐานว่ามีสิ่งที่คล้ายกันอยู่ใกล้กัน
ด้านล่างนี้เป็นภาพประกอบง่ายๆ
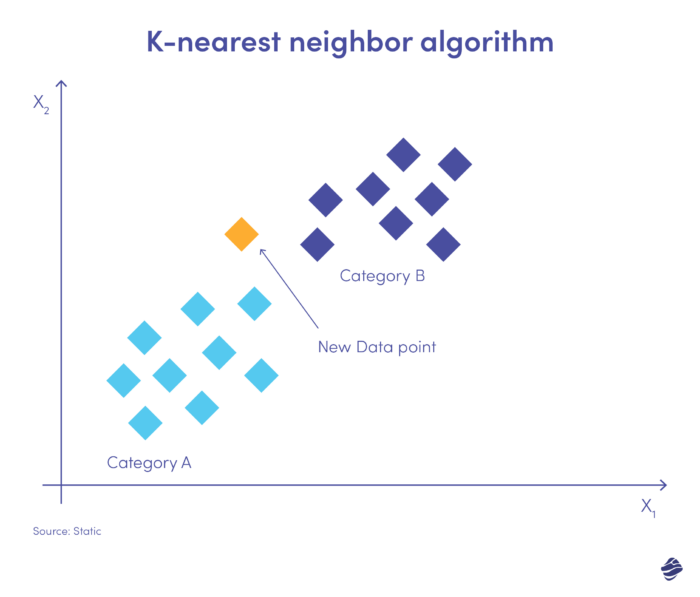
การป้อนข้อมูลใหม่จะต้องอยู่ในหมวดหมู่ A หรือ B อัลกอริธึมจะคำนวณระยะห่างระหว่างจุดข้อมูลโดยใช้สมการทางคณิตศาสตร์ที่เรียกว่าระยะทางแบบยุคลิด จุดข้อมูลใหม่จัดอยู่ในกลุ่มที่มีเพื่อนบ้านมากที่สุด หากชุดข้อมูลที่ใกล้เคียงที่สุดติดแท็ก 'การฉ้อโกง' ธุรกรรมนั้นจะถูกจัดประเภทเป็นการฉ้อโกง
การนำทางความท้าทายและการพิจารณาเชิงกลยุทธ์
เช่นเดียวกับเทคโนโลยีอื่นๆ มีความเจ็บปวดเพิ่มมากขึ้นที่เกี่ยวข้องกับการบูรณาการการเรียนรู้ของเครื่องเพื่อการตรวจจับการฉ้อโกง ต่อไปนี้เป็นความท้าทายทั่วไปที่คุณอาจเผชิญ
โครงสร้างพื้นฐานไม่เพียงพอ
ระบบธนาคารหลายแห่งไม่สามารถวิเคราะห์ข้อมูลที่ซับซ้อนในปริมาณมากได้ นอกจากนี้ ข้อมูลส่วนใหญ่จะถูกเก็บแยกไว้และจัดเก็บไว้ในพื้นที่จัดเก็บข้อมูลที่แยกจากกัน
ขออภัย ไม่มีการแก้ไขปัญหานี้อย่างรวดเร็ว คุณต้องลงทุนในฮาร์ดแวร์และซอฟต์แวร์ที่เหมาะสม
คุณจะต้องร่วมมือกับหน่วยงานพัฒนาแอป Fintech ที่มีประสบการณ์ และตั้งค่าโครงสร้างพื้นฐานเพื่อเลือกอัลกอริทึมที่เหมาะสมสำหรับชุดข้อมูลเฉพาะโดยอัตโนมัติ นำเข้าข้อมูลดิบและเตรียมพร้อมสำหรับการเรียนรู้ของเครื่อง แสดงภาพข้อมูล ทดสอบอัลกอริทึม และอื่นๆ
คุณภาพข้อมูลและความปลอดภัย
คุณภาพของข้อมูลถือเป็นปัญหาสำคัญสำหรับสถาบันการเงินที่ต้องการใช้การเรียนรู้ของเครื่องเพื่อการตรวจจับการฉ้อโกง โมเดลการเรียนรู้ของเครื่องไม่ได้แยกแยะระหว่างข้อมูลที่ดีและไม่ดี ดังนั้น หากอัลกอริทึมมีข้อมูลที่ไม่เกี่ยวข้องหรือไม่สมบูรณ์ ความถูกต้องของแบบจำลองของคุณจะไม่ถูกต้อง
โซลูชันการนำเข้าข้อมูล เช่น Amazon Kinesis รวบรวม ทำความสะอาด และแปลงข้อมูลดิบ ทำให้เหมาะสำหรับโมเดล Machine Learning เมื่อข้อมูลได้รับการทำความสะอาดและจัดระเบียบแล้ว คุณต้องแยกข้อมูลที่ละเอียดอ่อนและที่ไม่ละเอียดอ่อน เข้ารหัสข้อมูลที่เป็นความลับและจัดเก็บไว้ในสถานที่ที่ปลอดภัย คุณควรจำกัดการเข้าถึงข้อมูลนี้ด้วย
ขาดความสามารถ
แม้ว่าผู้คนจะกลัว แต่การเรียนรู้ของเครื่องไม่ได้ขโมยงาน มันค่อนข้างตรงกันข้าม เรายังต้องการนักวิเคราะห์การฉ้อโกงเพื่อจัดการกรณีที่ซับซ้อนซึ่งต้องใช้ข้อมูลเชิงลึกและประสบการณ์ของมนุษย์ นอกจากนี้ แมชชีนเลิร์นนิงยังเป็นเทคโนโลยีใหม่ และมีผู้เชี่ยวชาญในสาขานี้ไม่เพียงพอ
นี่เป็นข่าวดีสำหรับผู้หางาน แต่ไม่ใช่สำหรับสถาบันที่ไม่สามารถใช้ประโยชน์จาก Machine Learning ได้อย่างเต็มศักยภาพ คุณสามารถเอาชนะความเร่งรีบนี้ได้ด้วยการร่วมมือกับธุรกิจต่างๆ ที่มีทักษะในการใช้แมชชีนเลิร์นนิง
กรณีศึกษาการตรวจจับการฉ้อโกงในระบบธนาคารโดยใช้การเรียนรู้ของเครื่อง
ตอนนี้เรามาดูตัวอย่างในชีวิตจริงของการตรวจจับการฉ้อโกงในระบบธนาคารโดยใช้การเรียนรู้ของเครื่อง
การตรวจจับการฉ้อโกง
Danske Bank เป็นบริษัททางการเงินข้ามชาติของเดนมาร์ก เป็นธนาคารที่ใหญ่ที่สุดในเดนมาร์กและเป็นธนาคารรายย่อยชั้นนำในยุโรปเหนือ ภายใต้ระบบการตรวจจับตามกฎ ธนาคารประสบปัญหาในการลดการฉ้อโกง มีอัตราการตรวจจับการฉ้อโกง 40% และอัตราผลบวกลวง 99.5%
Danske ทำงานร่วมกับ Teradata ซึ่งเป็นบริษัทซอฟต์แวร์ข้อมูล โดยผสานรวมซอฟต์แวร์การเรียนรู้เชิงลึกเพื่อช่วยระบุกิจกรรมที่อาจเกิดการฉ้อโกง ผลลัพธ์ที่ได้คือผลบวกลวงลดลง 60% และผลบวกลวงเพิ่มขึ้น 50%
ป้องกันการฟอกเงิน
OakNorth เป็นธนาคารที่ให้กู้ยืมเชิงพาณิชย์ในสหราชอาณาจักร ให้บริการด้านธุรกิจและการเงินส่วนบุคคลแก่บริษัทที่กำลังขยายขนาด ธนาคารมีกระบวนการคัดกรองที่แตกหัก โดยมีผู้ให้บริการรายหนึ่งสำหรับการตรวจสอบป้องกันการฟอกเงิน และอีกรายสำหรับลูกค้า นอกจากนี้ การคัดกรองบุคคลที่มีความเสี่ยงทางการเมือง (PEP) ยังก่อให้เกิดผลบวกลวงจำนวนมาก
ด้วยการทำงานร่วมกับ ComplyAdvantage ซึ่งเป็นบริษัทตรวจจับการฉ้อโกงและ AML ธนาคารได้รวมโซลูชันการคัดกรองและการตรวจสอบอย่างต่อเนื่องเพื่อปรับปรุงการปฏิบัติตามข้อกำหนดและรวบรวมข้อมูล สิ่งนี้อำนวยความสะดวกในการถ่ายโอนข้อมูลอย่างรวดเร็วระหว่างการดำเนินการให้กู้ยืมและการออมของธนาคาร
การพิจารณาสินเชื่อ
Hawaii USA Credit Union เป็นสหภาพเครดิตที่ใหญ่ที่สุดในฮาวาย และเป็นหนึ่งในสหภาพเครดิตที่ดีที่สุดของนิตยสาร Forbes ต้องการแข่งขันกับบริษัท Fintech และขยายพอร์ตสินเชื่อส่วนบุคคลโดยไม่เพิ่มความเสี่ยง
การทำงานร่วมกับ Zest AI สหภาพเครดิตทำให้กระบวนการตัดสินใจเป็นแบบอัตโนมัติโดยใช้โมเดลสินเชื่อส่วนบุคคลที่ขับเคลื่อนด้วย AI แบบจำลองนี้ใช้ตัวแปร 278 ตัวเพื่อให้ข้อมูลเชิงลึกที่ลึกกว่าระบบการให้คะแนนเครดิต VantageScore ผลลัพธ์คืออัตราการอนุมัติเพิ่มขึ้น 21% และอัตราการฉ้อโกงการสมัครผิดนัด/สินเชื่อ 0%
ข้อควรพิจารณาที่สำคัญเมื่อใช้ ML สำหรับการตรวจจับการฉ้อโกง
แม้ว่าการตรวจจับการฉ้อโกงในระบบธนาคารโดยใช้การเรียนรู้ของเครื่องจะมีประสิทธิภาพ แต่ก็เป็นเรื่องที่น่ากังวลเช่นกัน ระบบเหล่านี้ต้องการข้อมูลที่แม่นยำจำนวนมาก หรือแบบจำลองทำงานได้ไม่ดีเท่าที่ควร
ต่อไปนี้เป็นเคล็ดลับบางประการในการเพิ่มประสิทธิภาพกระบวนการเรียนรู้ของเครื่อง
1. จำกัดจำนวนตัวแปรอินพุต
ตลอดบทความนี้ เราได้กล่าวว่า more is more สิ่งนี้ยังคงเป็นจริงเกี่ยวกับปริมาณข้อมูล อย่างไรก็ตาม จำนวนตัวแปรการตรวจจับการฉ้อโกงมีจำนวนน้อยมาก
คุณสมบัติทั่วไปที่ควรพิจารณาเมื่อตรวจสอบการฉ้อโกง ได้แก่:
- ที่อยู่ IP
- ที่อยู่อีเมล
- ที่อยู่จัดส่ง
- มูลค่าการสั่งซื้อ/ธุรกรรมเฉลี่ย
ประโยชน์ของฟีเจอร์ที่น้อยลงคือเวลาฝึกฝนอัลกอริทึมที่สั้นลง คุณยังหลีกเลี่ยงปัญหาชุดข้อมูลที่ทับซ้อนกันหรือไม่เกี่ยวข้องอีกด้วย
2. ตรวจสอบการปฏิบัติตามกฎระเบียบ
การป้องกันการฉ้อโกงเป็นส่วนหนึ่งของการรักษาความปลอดภัยของข้อมูล อีกอย่างคือความเป็นส่วนตัวของข้อมูล หลายประเทศมีกฎหมายว่าสถาบันสามารถรวบรวม ใช้ และจัดเก็บข้อมูลลูกค้าได้อย่างไร มีกฎหมายคุ้มครองข้อมูลส่วนบุคคลของจีน (PIPL), พระราชบัญญัติความเป็นส่วนตัวของผู้บริโภคแห่งแคลิฟอร์เนีย (CCPA) และกฎระเบียบคุ้มครองข้อมูลทั่วไป (GDPR) ของสหภาพยุโรป เป็นต้น
กฎหมายเหล่านี้มีผลกระทบต่อข้อมูลที่ใช้ในการเรียนรู้ของเครื่อง หลักการหลักในกฎระเบียบการปฏิบัติตามความเป็นส่วนตัวของข้อมูลส่วนใหญ่คือการแจ้งให้ทราบ/การยินยอม คุณต้องแจ้งและได้รับอนุญาตให้ใช้ข้อมูลลูกค้าเพื่อวัตถุประสงค์อื่นนอกเหนือจากคำขอของผู้ใช้ รวมถึงข้อมูลสำหรับการฝึกอบรมอัลกอริธึมการเรียนรู้ของเครื่อง
วิธีที่ง่ายที่สุดในการรับรองการปฏิบัติตามมาตรฐานความเป็นส่วนตัวคือการใช้พันธมิตรทางเทคนิคที่มีคุณสมบัติที่สอดคล้องกับกฎระเบียบ ตัวอย่างเช่น คุณควรร่วมมือกับบริษัทพัฒนาแอปธนาคารที่เข้าใจวิธีรักษาความเป็นส่วนตัวและความปลอดภัยของข้อมูล
3. กำหนดเกณฑ์ที่เหมาะสม
กฎมูลค่าธุรกรรมมีข้อกำหนดขั้นต่ำเพื่อทริกเกอร์การยอมรับหรือปฏิเสธการตอบสนอง คุณต้องการเกณฑ์ที่สร้างความสมดุลระหว่างความปลอดภัยและประสบการณ์ผู้ใช้ หากเกณฑ์เข้มงวดเกินไป คุณจะเสี่ยงต่อการบล็อกธุรกรรมที่ถูกต้องตามกฎหมาย หากเกณฑ์ไม่เข้มงวดเกินไป คุณจะเพิ่มอัตราการฉ้อโกงที่สำเร็จ
คำนวณความเสี่ยงที่ยอมรับได้ของคุณเพื่อค้นหาสมดุลที่เหมาะสม ระดับความเสี่ยงแตกต่างกันไปในแต่ละสถาบันการเงินหรือผลิตภัณฑ์ ตัวอย่างเช่น ข้อเสนอของธนาคารที่ให้สินเชื่อรายย่อยสามารถกำหนดเกณฑ์ที่สูงสำหรับสินเชื่อที่มีมูลค่าต่ำได้ ธนาคารพาณิชย์ไม่สามารถมีน้ำใจกับสินเชื่อจำนองได้
คาดการณ์อนาคต
อนาคตอยู่ในขณะนี้ แต่มีเพียง 17% ขององค์กรที่ใช้การเรียนรู้ของเครื่องในโปรแกรมต่อต้านการฉ้อโกง อย่าถูกทิ้งไว้ข้างหลัง
ต่อไปนี้เป็นความก้าวหน้าบางส่วนที่คุณคาดหวังได้ในความปลอดภัยของธนาคารผ่านการเรียนรู้ของเครื่อง
- การทำโปรไฟล์อุปกรณ์ : ระบุอุปกรณ์ต่างๆ ที่เชื่อมต่อกับเครือข่ายธนาคารของคุณ วิเคราะห์คุณสมบัติและพฤติกรรมของอุปกรณ์ที่กำหนด
- การตรวจจับและตอบสนองความผิดปกติอัตโนมัติ : ระบุพฤติกรรมการฉ้อโกงจากอุปกรณ์ที่รู้จักและแยกระบบที่ได้รับผลกระทบ
- การตรวจจับซีโรเดย์ : ระบุช่องโหว่และมัลแวร์ที่ไม่รู้จักก่อนหน้านี้เพื่อปกป้ององค์กรจากการโจมตีทางไซเบอร์
- การปกปิดข้อมูล : ตรวจจับและไม่ระบุชื่อข้อมูลที่เป็นความลับโดยอัตโนมัติ
- ข้อมูลเชิงลึกที่ปรับขนาดได้ : ระบุแนวโน้มของการฉ้อโกงในอุปกรณ์และสถานที่หลายแห่ง
- นโยบายที่เป็นนวัตกรรม : ใช้ข้อมูลเชิงลึกของการเรียนรู้ของเครื่องเพื่อขับเคลื่อนนโยบายความปลอดภัยที่เกี่ยวข้อง
ไม่ว่าคุณจะเป็นสถาบันการบริหารความมั่งคั่งหรือสหภาพเครดิต AI และการเรียนรู้ของเครื่องก็มีโอกาสมหาศาลในการตรวจจับการฉ้อโกง
อย่างไรก็ตาม จำเป็นอย่างยิ่งที่ต้องจำไว้ว่าแฮกเกอร์ยังใช้เทคโนโลยีเหล่านี้เพื่อหลีกเลี่ยงมาตรการป้องกันด้วย อัปเดตโมเดลแมชชีนเลิร์นนิงของคุณเพื่อก้าวนำหน้าการโจมตีเหล่านี้ คุณยังสามารถเสริมความปลอดภัยบนพื้นฐาน AI ของคุณด้วยความฉลาดของมนุษย์แบบเก่าได้