
ข้อมูลเบื้องต้นเกี่ยวกับโปรแกรมรวบรวมข้อมูลเว็บ
เผยแพร่แล้ว: 2016-03-08เมื่อฉันพูดคุยกับผู้คนเกี่ยวกับสิ่งที่ฉันทำและสิ่งที่ SEO คืออะไร พวกเขามักจะได้มันมาอย่างรวดเร็วหรือพวกเขาทำเหมือนที่ทำ โครงสร้างเว็บไซต์ที่ดี เนื้อหาดี ลิงก์ย้อนกลับที่ดี แต่บางครั้ง มันก็มีเทคนิคนิดหน่อย และฉันก็จบลงด้วยการพูดถึงเครื่องมือค้นหาที่รวบรวมข้อมูลเว็บไซต์ของคุณ และฉันก็มักจะทำหาย...
ทำไมต้องรวบรวมข้อมูลเว็บไซต์ ?
การรวบรวมข้อมูลเว็บเริ่มต้นจากการทำแผนที่อินเทอร์เน็ตและวิธีที่แต่ละเว็บไซต์เชื่อมต่อถึงกัน มันยังถูกใช้โดยเสิร์ชเอ็นจิ้นเพื่อค้นหาและจัดทำดัชนีหน้าออนไลน์ใหม่ โปรแกรมรวบรวมข้อมูลเว็บยังใช้เพื่อทดสอบช่องโหว่ของเว็บไซต์ด้วยการทดสอบเว็บไซต์และวิเคราะห์ว่าพบปัญหาใดๆ หรือไม่
ตอนนี้ คุณสามารถค้นหาเครื่องมือที่รวบรวมข้อมูลเว็บไซต์ของคุณเพื่อให้ข้อมูลเชิงลึกแก่คุณได้ ตัวอย่างเช่น OnCrawl ให้ข้อมูลเกี่ยวกับเนื้อหาของคุณและ SEO ในสถานที่หรือ Majestic ซึ่งให้ข้อมูลเชิงลึกเกี่ยวกับลิงก์ทั้งหมดที่ชี้ไปยังหน้า
โปรแกรมรวบรวมข้อมูลใช้เพื่อรวบรวมข้อมูลซึ่งสามารถใช้และประมวลผลเพื่อจัดประเภทเอกสารและให้ข้อมูลเชิงลึกเกี่ยวกับข้อมูลที่รวบรวมได้
การสร้างโปรแกรมรวบรวมข้อมูลสามารถเข้าถึงได้โดยทุกคนที่รู้รหัส อย่างไรก็ตาม การสร้างโปรแกรมรวบรวมข้อมูลที่มีประสิทธิภาพนั้นยากกว่าและต้องใช้เวลา
มันทำงานอย่างไร ?
ในการรวบรวมข้อมูลเว็บไซต์หรือเว็บ คุณต้องมีจุดเริ่มต้นก่อน หุ่นยนต์จำเป็นต้องรู้ว่าเว็บไซต์ของคุณมีอยู่จริงเพื่อที่พวกเขาจะได้เข้ามาดู ย้อนกลับไปในสมัยก่อน คุณจะส่งเว็บไซต์ของคุณไปยังเครื่องมือค้นหาเพื่อบอกว่าเว็บไซต์ของคุณออนไลน์อยู่ ตอนนี้คุณสามารถสร้างลิงค์สองสามลิงค์ไปยังเว็บไซต์ของคุณได้อย่างง่ายดายและ Voila คุณก็อยู่ในวง!
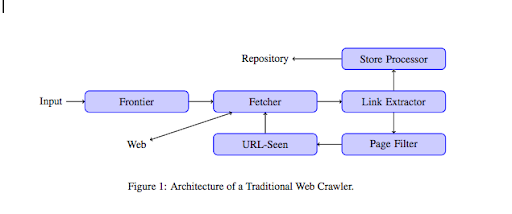
เมื่อโปรแกรมรวบรวมข้อมูลเข้าสู่เว็บไซต์ของคุณ โปรแกรมจะวิเคราะห์เนื้อหาทั้งหมดของคุณทีละบรรทัด และติดตามลิงก์แต่ละลิงก์ที่คุณมี ไม่ว่าจะเป็นลิงก์ภายในหรือภายนอก และอื่นๆ จนกว่าจะถึงหน้าที่ไม่มีลิงก์หรือพบข้อผิดพลาดเช่น 404, 403, 500, 503
จากมุมมองทางเทคนิคที่มากขึ้น โปรแกรมรวบรวมข้อมูลจะทำงานกับเมล็ดพันธุ์ (หรือรายการ) ของ URL สิ่งนี้จะถูกส่งต่อไปยัง Fetcher ซึ่งจะดึงเนื้อหาของเพจ เนื้อหานี้จะถูกย้ายไปยังตัวแยกลิงก์ ซึ่งจะแยกวิเคราะห์ HTML และแยกลิงก์ทั้งหมด ลิงก์เหล่านี้จะถูกส่งไปยังโปรเซสเซอร์ของ Store ซึ่งจะจัดเก็บตามชื่อ URL เหล่านี้จะผ่านตัวกรองหน้าซึ่งจะส่งลิงก์ที่น่าสนใจทั้งหมดไปยังโมดูลที่มองเห็น URL โมดูลนี้จะตรวจสอบว่า URL นั้นถูกมองเห็นแล้วหรือไม่ ถ้าไม่เช่นนั้นจะถูกส่งไปยัง Fetcher ซึ่งจะดึงเนื้อหาของเพจเป็นต้น
โปรดทราบว่าเนื้อหาบางอย่างเป็นไปไม่ได้ที่สไปเดอร์จะรวบรวมข้อมูล เช่น Flash ขณะนี้ GoogleBot รวบรวมข้อมูล Javascript อย่างถูกต้องแล้ว แต่ในบางครั้งกลับไม่มีการรวบรวมข้อมูลใดๆ ของ Javascript รูปภาพไม่ใช่เนื้อหาที่ Google สามารถรวบรวมข้อมูลในทางเทคนิคได้ แต่ก็ฉลาดพอที่จะเริ่มทำความเข้าใจได้ !
ถ้าหุ่นยนต์ไม่บอกตรงกันข้าม พวกมันจะคลานทุกอย่าง นี่คือจุดที่ไฟล์ robots.txt มีประโยชน์มาก มันบอกโปรแกรมรวบรวมข้อมูล (สามารถเจาะจงต่อโปรแกรมรวบรวมข้อมูลเช่น GoogleBot หรือ MSN Bot – ดูข้อมูลเพิ่มเติมเกี่ยวกับบอทที่นี่) ว่าหน้าใดที่พวกเขาไม่สามารถรวบรวมข้อมูลได้ สมมติว่าคุณมีการนำทางโดยใช้แง่มุมต่างๆ คุณอาจไม่ต้องการให้โรบ็อตรวบรวมข้อมูลทั้งหมดเนื่องจากมีมูลค่าเพิ่มเพียงเล็กน้อยและจะใช้งบประมาณในการรวบรวมข้อมูล การใช้บรรทัดง่ายๆ นี้จะช่วยป้องกันไม่ให้หุ่นยนต์คลานไปมา
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /folder-a/
สิ่งนี้บอกหุ่นยนต์ทั้งหมดไม่ให้รวบรวมข้อมูลโฟลเดอร์ A
ตัวแทนผู้ใช้: GoogleBot
ไม่อนุญาต: /repertoire-b/
ในทางกลับกันระบุว่ามีเพียง Google Bot เท่านั้นที่ไม่สามารถรวบรวมข้อมูลโฟลเดอร์ B
คุณยังสามารถใช้การบ่งชี้ใน HTML ซึ่งบอกโรบ็อตไม่ให้ติดตามลิงก์เฉพาะโดยใช้แท็ก rel=”nofollow” การทดสอบบางรายการแสดงให้เห็นแม้กระทั่งการใช้แท็ก rel=”nofollow” บนลิงก์จะไม่บล็อก Googlebot ไม่ให้ติดตาม สิ่งนี้ขัดแย้งกับจุดประสงค์ แต่จะมีประโยชน์ในกรณีอื่น
[กรณีศึกษา] เพิ่มการมองเห็นโดยการปรับปรุงความสามารถในการรวบรวมข้อมูลเว็บไซต์สำหรับ Googlebot
 อ่านกรณีศึกษา
อ่านกรณีศึกษา
คุณพูดถึงงบประมาณการรวบรวมข้อมูล แต่มันคืออะไร
สมมติว่าคุณมีเว็บไซต์ที่เครื่องมือค้นหาค้นพบ พวกเขามาดูว่าคุณได้ทำการอัปเดตบนเว็บไซต์ของคุณและสร้างหน้าใหม่เป็นประจำหรือไม่
แต่ละเว็บไซต์มีงบประมาณในการรวบรวมข้อมูลของตัวเอง ขึ้นอยู่กับปัจจัยหลายประการ เช่น จำนวนหน้าที่เว็บไซต์ของคุณมีและความเหมาะสมของเว็บไซต์ (หากมีข้อผิดพลาดจำนวนมาก เป็นต้น) คุณสามารถทราบแนวคิดสั้นๆ เกี่ยวกับงบประมาณการรวบรวมข้อมูลได้ง่ายๆ โดยเข้าสู่ระบบใน Search Console
งบประมาณการรวบรวมข้อมูลของคุณจะกำหนดจำนวนหน้าที่หุ่นยนต์รวบรวมข้อมูลในเว็บไซต์ของคุณทุกครั้งที่มีการเข้าชม มีการเชื่อมโยงตามสัดส่วนกับจำนวนหน้าที่คุณมีบนเว็บไซต์ของคุณและมีการรวบรวมข้อมูลแล้ว บางหน้ามีการรวบรวมข้อมูลบ่อยกว่าหน้าอื่นๆ โดยเฉพาะหากมีการอัปเดตเป็นประจำหรือหากมีการเชื่อมโยงจากหน้าที่สำคัญ
ตัวอย่างเช่น บ้านของคุณเป็นทางเข้าหลักซึ่งจะถูกรวบรวมข้อมูลบ่อยมาก หากคุณมีบล็อกหรือหน้าหมวดหมู่ พวกเขาจะถูกรวบรวมข้อมูลบ่อยครั้งหากมีการเชื่อมโยงไปยังการนำทางหลัก บล็อกจะถูกรวบรวมข้อมูลบ่อยครั้งเมื่อมีการอัปเดตเป็นประจำ โพสต์บล็อกอาจได้รับการรวบรวมข้อมูลบ่อยครั้งเมื่อเผยแพร่ครั้งแรก แต่หลังจากนั้นสองสามเดือนก็อาจจะไม่ได้รับการอัปเดต
ยิ่งมีการรวบรวมข้อมูลหน้าเว็บบ่อยเท่าใด โรบ็อตก็ถือว่ามีความสำคัญมากกว่าเมื่อเทียบกับหน้าอื่นๆ นี่คือเวลาที่คุณต้องเริ่มทำงานเพื่อเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลของคุณ
การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูลของคุณ
เพื่อที่จะเพิ่มประสิทธิภาพงบประมาณของคุณและตรวจสอบให้แน่ใจว่าหน้าที่สำคัญที่สุดของคุณได้รับความสนใจตามสมควร คุณสามารถวิเคราะห์บันทึกของเซิร์ฟเวอร์และดูว่าเว็บไซต์ของคุณถูกรวบรวมข้อมูลอย่างไร:
- หน้าเว็บยอดนิยมของคุณถูกรวบรวมข้อมูลบ่อยเพียงใด
- คุณเห็นหน้าเว็บที่มีความสำคัญน้อยกว่าที่มีการรวบรวมข้อมูลมากกว่าหน้าอื่นๆ ที่มีความสำคัญมากกว่าหรือไม่
- หุ่นยนต์มักได้รับข้อผิดพลาด 4xx หรือ 5xx เมื่อรวบรวมข้อมูลเว็บไซต์ของคุณหรือไม่?
- หุ่นยนต์พบกับดักแมงมุมหรือไม่? (Matthew Henry เขียนบทความที่ดีเกี่ยวกับพวกเขา)
ด้วยการวิเคราะห์บันทึกของคุณ คุณจะเห็นว่าหน้าใดที่คุณคิดว่ามีความสำคัญน้อยกว่าที่มีการรวบรวมข้อมูลเป็นจำนวนมาก จากนั้นคุณต้องเจาะลึกลงไปในโครงสร้างลิงก์ภายในของคุณ หากมีการรวบรวมข้อมูล จะต้องมีลิงก์จำนวนมากที่ชี้ไปยังข้อมูลดังกล่าว
คุณยังสามารถแก้ไขข้อผิดพลาดเหล่านี้ (4xx และ 5xx) ได้ด้วย OnCrawl มันจะปรับปรุงความสามารถในการรวบรวมข้อมูลรวมถึงประสบการณ์การใช้งานของผู้ใช้ ซึ่งเป็นกรณีที่มี win-win
คลาน VS ขูด ?
การรวบรวมข้อมูลและการขูดเป็นสองสิ่งที่แตกต่างกันซึ่งใช้เพื่อวัตถุประสงค์ที่ต่างกัน การรวบรวมข้อมูลเว็บไซต์เป็นการเชื่อมโยงไปถึงหน้าเว็บและติดตามลิงก์ที่คุณพบเมื่อสแกนเนื้อหา โปรแกรมรวบรวมข้อมูลจะย้ายไปที่หน้าอื่นเป็นต้น
ในทางกลับกัน การขูดคือการสแกนหน้าและรวบรวมข้อมูลเฉพาะจากหน้า: แท็กชื่อ คำอธิบายเมตา แท็ก h1 หรือพื้นที่เฉพาะของเว็บไซต์ของคุณ เช่น รายการราคา เครื่องขูดมักจะทำหน้าที่เป็น "มนุษย์" พวกเขาจะละเว้นกฎใด ๆ จากไฟล์ robots.txt ไฟล์ในแบบฟอร์ม และใช้เบราว์เซอร์ user-agent เพื่อไม่ให้ถูกตรวจพบ
โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหามักจะทำหน้าที่เป็นตัวทำลายข้อมูลและจำเป็นต้องรวบรวมข้อมูลเพื่อประมวลผลสำหรับอัลกอริทึมการจัดอันดับ พวกเขาไม่ได้มองหาข้อมูลเฉพาะเมื่อเปรียบเทียบกับ Scrapper พวกเขาเพียงแค่ใช้ข้อมูลที่มีอยู่ทั้งหมดบนหน้าและมากกว่านั้น (เวลาในการโหลดเป็นสิ่งที่คุณไม่สามารถรับได้จากหน้า) โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาจะระบุตัวเองว่าเป็นโปรแกรมรวบรวมข้อมูลเสมอเพื่อให้เจ้าของเว็บไซต์ทราบเมื่อเข้ามาเยี่ยมชมเว็บไซต์ครั้งล่าสุด ซึ่งจะมีประโยชน์มากเมื่อคุณติดตามกิจกรรมของผู้ใช้จริง
ตอนนี้คุณรู้มากขึ้นอีกเล็กน้อยเกี่ยวกับการรวบรวมข้อมูล วิธีการทำงาน และเหตุใดจึงสำคัญ ขั้นตอนต่อไปคือการเริ่มวิเคราะห์บันทึกของเซิร์ฟเวอร์ สิ่งนี้จะให้ข้อมูลเชิงลึกแก่คุณเกี่ยวกับวิธีที่โรบ็อตโต้ตอบกับเว็บไซต์ของคุณ หน้าที่พวกเขาเข้าชมบ่อย และจำนวนข้อผิดพลาดที่พวกเขาพบขณะเยี่ยมชมเว็บไซต์ของคุณ
สำหรับข้อมูลทางเทคนิคและประวัติเพิ่มเติมเกี่ยวกับโปรแกรมรวบรวมข้อมูลเว็บ คุณสามารถอ่าน "ประวัติโดยย่อของโปรแกรมรวบรวมข้อมูลเว็บ"