
วิธีคาดการณ์รายได้จากการเข้าชมแบบออร์แกนิกที่ไม่มีแบรนด์ตามตำแหน่ง URL ด้วย Python
เผยแพร่แล้ว: 2022-05-24การคาดการณ์ SEO คืออะไร?
การคาดการณ์ SEO หรือการประมาณการเข้าชมที่เกิดขึ้นเองเป็นกระบวนการของการใช้ข้อมูลของไซต์ของคุณเองหรือข้อมูลของบุคคลที่สามเพื่อประเมินการเข้าชมที่เกิดขึ้นเองในอนาคต รายได้ SEO และ SEO ROI ของไซต์ของคุณ การประมาณนี้สามารถคำนวณได้โดยใช้วิธีการต่างๆ มากมายตามข้อมูลของเรา
ในบทช่วยสอนนี้ เราต้องการคาดการณ์รายได้ออร์แกนิกที่ไม่มีแบรนด์และการเข้าชมออร์แกนิกที่ไม่มีแบรนด์ตามตำแหน่ง URL ของเราและรายได้ในปัจจุบัน สิ่งนี้สามารถช่วยให้เราในฐานะ SEO ได้รับการซื้อจากผู้มีส่วนได้ส่วนเสียอื่นๆ มากขึ้น: จากงบประมาณรายเดือน รายไตรมาส หรือรายปีที่เพิ่มขึ้น ไปจนถึงชั่วโมงการทำงานที่เพิ่มขึ้นจากผลิตภัณฑ์และทีมพัฒนา
โปรดทราบว่าบทช่วยสอนนี้ไม่ได้ใช้ได้กับการเข้าชมทั่วไปที่ไม่มีแบรนด์เท่านั้น ด้วยการเปลี่ยนแปลงเล็กน้อยและรู้จัก Python คุณสามารถใช้มันเพื่อประเมินการเข้าชมหน้าเป้าหมายของคุณ
ส่งผลให้เราสามารถจัดทำ Google ชีตได้ดังภาพด้านล่าง
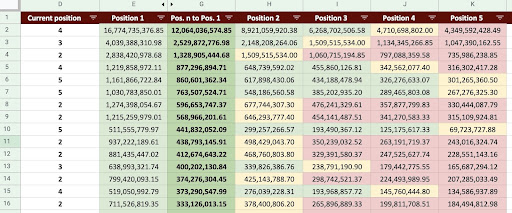
รูปภาพ Google ชีต
การคาดการณ์ปริมาณการใช้ SEO ที่ไม่มีแบรนด์
คำถามแรกที่คุณอาจถามหลังจากอ่านบทนำคือ "ทำไมต้องคำนวณการเข้าชมแบบออร์แกนิกที่ไม่มีแบรนด์"
ลองพิจารณาบริษัทอย่างอเมซอน เมื่อคุณต้องการซื้อหนังสือหรือหน้ากาก คุณเพียงแค่ค้นหา "ซื้อหน้ากาก amazon"
แบรนด์มักเป็นสิ่งที่สำคัญที่สุด และเมื่อคุณต้องการซื้อบางอย่าง คุณชอบซื้อสิ่งที่คุณต้องการจากบริษัทเหล่านี้ ในแต่ละอุตสาหกรรม มีบริษัทที่มีแบรนด์ที่ส่งผลต่อพฤติกรรมของผู้ใช้ในการค้นหาของ Google
หากเราต้องตรวจสอบข้อมูล Google Search Console (GSC) ของ Amazon เราน่าจะพบว่ามีการเข้าชมจำนวนมากจากข้อความค้นหาเกี่ยวกับแบรนด์ และโดยส่วนใหญ่ ผลลัพธ์แรกของการค้นหาเกี่ยวกับแบรนด์คือไซต์ของแบรนด์นั้น
ในฐานะ SEO เช่นเดียวกับฉัน คุณคงเคยได้ยินมาหลายครั้งแล้วว่า “แบรนด์ของเราเท่านั้นที่ช่วย SEO ของเรา!” เราจะพูดว่า "ไม่ เป็นเช่นนั้น" และแสดงการเข้าชมและรายได้ของการสืบค้นที่ไม่ใช่แบรนด์ได้อย่างไร
การพิสูจน์สิ่งนี้ซับซ้อนยิ่งขึ้นเพราะเรารู้ว่าอัลกอริทึมของ Google นั้นซับซ้อนมากและเป็นการยากที่จะแยกแบรนด์ออกจากการค้นหาที่ไม่มีแบรนด์อย่างชัดเจน แต่นี่คือสิ่งที่ทำให้เราทำ SEO มีความสำคัญมากขึ้น
ในบทช่วยสอนนี้ ฉันจะแสดงให้คุณเห็นถึงวิธีแยกแยะระหว่างสองแบรนด์ - แบบมีแบรนด์และแบบไม่มีแบรนด์ - และแสดงให้คุณเห็นว่า SEO มีประสิทธิภาพเพียงใด
แม้ว่าบริษัทของคุณจะไม่มีแบรนด์ คุณยังสามารถได้รับอะไรมากมายจากบทความนี้: คุณสามารถเรียนรู้วิธีประเมินข้อมูลทั่วไปของไซต์ของคุณได้
SEO ROI ตามการประเมินปริมาณการใช้งาน
ไม่ว่าคุณจะอยู่ที่ไหนหรือทำอะไร มีข้อจำกัดด้านทรัพยากร ไม่ว่าจะเป็นงบประมาณหรือเพียงแค่จำนวนชั่วโมงในวันทำงาน การรู้วิธีที่ดีที่สุดในการจัดสรรทรัพยากรของคุณมีบทบาทสำคัญในภาพรวมและผลตอบแทนจากการลงทุน (ROI) ของ SEO
CMO, รองประธานฝ่ายการตลาด หรือนักการตลาดด้านประสิทธิภาพล้วนมี KPI ที่แตกต่างกันและต้องการทรัพยากรที่แตกต่างกันเพื่อให้บรรลุเป้าหมาย วิธีที่ดีที่สุดเพื่อให้แน่ใจว่าคุณได้รับสิ่งที่คุณต้องการคือการพิสูจน์ความจำเป็นโดยการแสดงผลตอบแทนที่จะนำมาสู่บริษัท SEO ROI ก็ไม่ต่างกัน เมื่อถึงเวลาจัดสรรงบประมาณของปีและทีมของคุณต้องการของบประมาณที่มากขึ้น การประมาณค่า SEO ROI ของคุณสามารถช่วยให้คุณเจรจาได้ดีกว่า เมื่อคุณคำนวณการประมาณการเข้าชมที่ไม่มีแบรนด์แล้ว คุณจะสามารถประเมินงบประมาณที่จำเป็นสำหรับการบรรลุผลลัพธ์ที่ต้องการได้ดีขึ้น
ผลของการคาดคะเน SEO ต่อกลยุทธ์ SEO
ดังที่เราทราบ ทุกๆ 3 หรือ 6 เดือน เราจะทบทวนกลยุทธ์ SEO ของเราและปรับเปลี่ยนเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด แต่จะเกิดอะไรขึ้นเมื่อคุณไม่รู้ว่าผลกำไรของบริษัทคุณอยู่ที่ใดมากที่สุด? คุณ สามารถ ตัดสินใจได้ แต่การตัดสินใจเหล่านั้นจะไม่ได้ผลเท่ากับการตัดสินใจเมื่อคุณมีมุมมองที่ครอบคลุมมากขึ้นเกี่ยวกับการเข้าชมไซต์
การประเมินรายได้จากการเข้าชมแบบออร์แกนิกที่ไม่มีแบรนด์สามารถใช้ร่วมกับหน้า Landing Page และการแบ่งส่วนข้อความค้นหาเพื่อให้เห็นภาพใหญ่ที่จะช่วยให้คุณพัฒนากลยุทธ์ที่ดีขึ้นในฐานะผู้จัดการ SEO หรือนักวางกลยุทธ์ SEO
วิธีต่างๆ ในการคาดการณ์การเข้าชมอินทรีย์
มีวิธีการและสคริปต์สาธารณะมากมายในชุมชน SEO เพื่อทำนายปริมาณการใช้ข้อมูลอินทรีย์ในอนาคต
วิธีการบางอย่างเหล่านี้รวมถึง:
- การคาดการณ์ปริมาณการใช้ข้อมูลอินทรีย์ทั่วทั้งไซต์
- การคาดการณ์การเข้าชมที่เกิดขึ้นเองในหน้าเฉพาะ (บล็อก ผลิตภัณฑ์ หมวดหมู่ ฯลฯ) หรือหน้าเดียว
- การคาดการณ์การเข้าชมที่เกิดขึ้นเองในข้อความค้นหาเฉพาะ (คำค้นหาประกอบด้วย "ซื้อ" "วิธีการ" ฯลฯ) หรือข้อความค้นหา
- การคาดการณ์การเข้าชมที่เกิดขึ้นเองในช่วงเวลาเฉพาะ (โดยเฉพาะสำหรับเหตุการณ์ตามฤดูกาล)
วิธีการของฉันใช้สำหรับหน้าใดหน้าหนึ่ง และกรอบเวลาคือหนึ่งเดือน
[กรณีศึกษา] ขับเคลื่อนการเติบโตในตลาดใหม่ด้วย SEO บนหน้าเว็บ
 อ่านกรณีศึกษา
อ่านกรณีศึกษาวิธีคำนวณรายได้จากการเข้าชมที่เกิดขึ้นเอง
วิธีที่ถูกต้องขึ้นอยู่กับข้อมูล Google Analytics (GA) ของคุณ หากเว็บไซต์ของคุณเป็นเว็บไซต์ใหม่ คุณจะต้องใช้เครื่องมือของบุคคลที่สาม ฉันชอบที่จะหลีกเลี่ยงการใช้เครื่องมือดังกล่าวเมื่อคุณมีข้อมูลของคุณเอง
โปรดจำไว้ว่า คุณจะต้องทดสอบข้อมูลของบุคคลที่สามที่คุณใช้กับข้อมูลจริงของหน้าเว็บเพื่อค้นหาข้อผิดพลาดที่เป็นไปได้ในข้อมูลของพวกเขา
วิธีคำนวณรายได้จากการเข้าชม SEO ที่ไม่มีแบรนด์ด้วย Python
จนถึงตอนนี้ เราได้ครอบคลุมแนวคิดทางทฤษฎีมากมายที่เราควรจะคุ้นเคย เพื่อให้เข้าใจแง่มุมต่างๆ ของการเข้าชมที่เกิดขึ้นเองและการคาดการณ์รายได้ของเราได้ดีขึ้น ตอนนี้ เราจะเจาะลึกในส่วนที่ใช้งานได้จริงของบทความนี้
อันดับแรก เราจะเริ่มต้นด้วยการคำนวณเส้นโค้ง CTR ของเรา ในบทความ เส้นโค้ง CTR ของฉันเกี่ยวกับ Oncrawl ฉันจะอธิบายสองวิธีที่แตกต่างกันและวิธีอื่นๆ ที่คุณสามารถใช้ได้โดยการเปลี่ยนแปลงเล็กน้อยในโค้ดของฉัน ฉันแนะนำให้คุณอ่านบทความเส้นโค้งการคลิกก่อน มันให้ข้อมูลเชิงลึกเกี่ยวกับบทความนี้แก่คุณ
ในบทความนี้ ฉันปรับแต่งโค้ดบางส่วนเพื่อให้ได้ผลลัพธ์เฉพาะที่เราต้องการในการประเมินปริมาณการใช้งาน จากนั้น เราจะรับข้อมูลจาก GA และใช้มิติรายได้ของ GA เพื่อประเมินรายได้ของเรา
การพยากรณ์รายรับจากการเข้าชมทั่วไปที่ไม่ใช่แบรนด์ด้วย Python: เริ่มต้นใช้งาน
คุณสามารถรันโค้ดนี้ได้ด้วยตัวเองโดยไม่ต้องรู้จัก Python อย่างไรก็ตาม ฉันต้องการให้คุณรู้เพียงเล็กน้อยเกี่ยวกับไวยากรณ์ Python และความรู้พื้นฐานเกี่ยวกับไลบรารี Python ที่ฉันจะใช้ในโค้ดการพยากรณ์นี้ วิธีนี้จะช่วยให้คุณเข้าใจโค้ดของฉันได้ดีขึ้นและปรับแต่งโค้ดในลักษณะที่เป็นประโยชน์สำหรับคุณ
ในการเรียกใช้โค้ดนี้ ฉันจะใช้ Visual Studio Code กับส่วนขยาย Python จาก Microsoft ซึ่งรวมถึงส่วนขยาย "Jupyter" แต่คุณสามารถใช้สมุดบันทึก Jupyter ได้
สำหรับกระบวนการทั้งหมด เราจำเป็นต้องใช้ไลบรารี Python เหล่านี้:
- นัมปี้
- แพนด้า
- พล็อตเรื่อง
นอกจากนี้ เราจะนำเข้าไลบรารีมาตรฐาน Python บางส่วน:
- JSON
- pprint
# การนำเข้าไลบรารีที่เราต้องการสำหรับกระบวนการของเรา นำเข้า json จาก pprint นำเข้า pprint นำเข้า numpy เป็น np นำเข้าแพนด้าเป็น pd นำเข้า plotly.express เป็น px
ขั้นตอนที่ 1: การคำนวณเส้นโค้ง CTR สัมพัทธ์ (เส้นโค้งการคลิกสัมพัทธ์)
ในขั้นตอนแรก เราต้องการคำนวณเส้นโค้ง CTR สัมพัทธ์ของเรา แต่เส้นโค้ง CTR สัมพัทธ์คืออะไร?
กราฟ CTR สัมพัทธ์คืออะไร?
มาเริ่มกันก่อนโดยพูดถึง 'เส้นโค้ง CTR สัมบูรณ์' เมื่อเราคำนวณเส้นโค้ง CTR สัมบูรณ์ เราบอกว่า CTR มัธยฐาน (หรือ CTR เฉลี่ย) ของตำแหน่งแรกคือ 36% และตำแหน่งที่สองคือ 20% เป็นต้น
ในกราฟ CTR สัมพัทธ์ ช่วงเวลาของเปอร์เซ็นต์ เราจะหารค่ามัธยฐานแต่ละตำแหน่งด้วย CTR ของตำแหน่งแรก ตัวอย่างเช่น กราฟ CTR สัมพัทธ์ของตำแหน่งแรกจะเป็น 0.36 / 0.36 = 1 ส่วนที่สองจะเป็น 0.20 / 0.36 = 0.55 เป็นต้น
บางทีคุณอาจสงสัยว่าทำไมการคำนวณนี้จึงมีประโยชน์ ลองนึกถึงหน้าที่ติดอันดับหนึ่งซึ่งมี CTR 44% หากหน้านี้ไปที่ตำแหน่งที่สอง เส้น CTR จะไม่ลดลงถึง 20% มีแนวโน้มว่า CTR จะลดลงเป็น 44% * 0.55 = 24.2%
1. รับข้อมูลการเข้าชมอินทรีย์ของแบรนด์และไม่ใช่แบรนด์จาก GSC
สำหรับขั้นตอนการคำนวณของเรา เราต้องรับข้อมูลจาก GSC ในครั้งแรก ข้อมูลทั้งหมดจะอิงตามคำค้นหาที่มีแบรนด์ และในครั้งต่อไป ข้อมูลทั้งหมดจะอิงตามข้อความค้นหาที่ไม่มีแบรนด์
ในการรับข้อมูลนี้ คุณสามารถใช้วิธีการต่างๆ: จากสคริปต์ Python หรือจากส่วนเสริม Google ชีต "Search Analytics for Sheets" ฉันจะใช้ตัวสำรวจ GSC API
ผลลัพธ์ของข้อมูลนี้คือไฟล์ JSON สองไฟล์ที่แสดงประสิทธิภาพของแต่ละหน้า ไฟล์ JSON หนึ่งไฟล์ที่แสดงประสิทธิภาพของหน้า Landing Page ตามคำค้นหาที่มีแบรนด์ และอีกไฟล์หนึ่งแสดงประสิทธิภาพของหน้า Landing Page ตามการสืบค้นที่ไม่มีแบรนด์
หากต้องการรับข้อมูลจากตัวสำรวจ GSC API ให้ทำตามขั้นตอนเหล่านี้:
- ไปที่ https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- เพิ่มตัวสำรวจ API ที่มุมบนขวาของหน้าให้ใหญ่สุด
- ในช่อง “
siteUrl” ให้ใส่ชื่อโดเมนของคุณ ตัวอย่างเช่น “https://www.example.com” หรือ “http://your-domain.com” - ในเนื้อหาคำขอ อันดับแรก เราต้องกำหนดพารามิเตอร์ "
startDate" และ "endDate" ความชอบของฉันคือ 30 วันที่ผ่านมา - จากนั้นเราเพิ่ม "
dimensions" และเลือก "page" สำหรับรายการนี้ - ตอนนี้เราเพิ่ม “
dimensionFilterGroups” เพื่อกรองการสืบค้นของเรา หนึ่งครั้งสำหรับรายการที่มีตราสินค้า และครั้งที่สองสำหรับข้อความค้นหาที่ไม่มีตราสินค้า - ในตอนท้าย เราตั้งค่า “
rowLimit” เป็น 25,000 หากหน้าเว็บไซต์ของคุณที่มีการเข้าชมแบบออร์แกนิกในแต่ละเดือนมากกว่า 25,000 คุณต้องแก้ไขเนื้อหาคำขอของคุณ - หลังจากสร้างคำขอแต่ละรายการแล้ว ให้บันทึกการตอบกลับ JSON สำหรับประสิทธิภาพของแบรนด์ ให้บันทึกไฟล์ JSON เป็น “
branded_data.json” และสำหรับประสิทธิภาพที่ไม่ใช่แบรนด์ ให้บันทึกไฟล์ JSON เป็น “non_branded_data.json”
หลังจากที่เราเข้าใจพารามิเตอร์ในเนื้อหาคำขอแล้ว สิ่งเดียวที่คุณต้องทำคือคัดลอกและวางด้านล่างเนื้อหาคำขอ ลองเปลี่ยนชื่อแบรนด์ของคุณด้วย " brand variation names "
คุณต้องแยกชื่อแบรนด์ด้วยไปป์ไลน์หรือ “ | ” ตัวอย่างเช่น “ amazon|amazon.com|amazn ”
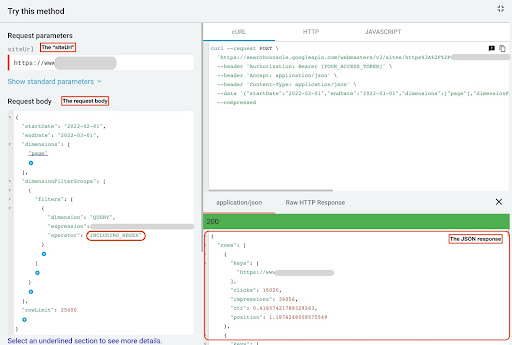
GSC API Explorer
เนื้อหาคำขอที่มีตราสินค้า:
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"ขนาด": [
"หน้าหนังสือ"
],
"dimensionFilterGroups": [
{
"ตัวกรอง": [
{
"มิติ": "QUERY",
"expression": "ชื่อรูปแบบแบรนด์",
"ตัวดำเนินการ": "INCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
เนื้อหาคำขอที่ไม่มีแบรนด์:
{
"startDate": "2022-02-01",
"endDate": "2022-03-01",
"ขนาด": [
"หน้าหนังสือ"
],
"dimensionFilterGroups": [
{
"ตัวกรอง": [
{
"มิติ": "QUERY",
"expression": "ชื่อรูปแบบแบรนด์",
"ตัวดำเนินการ": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
2. การนำเข้าข้อมูลลงในสมุดบันทึก Jupyter ของเราและการแยกไดเรกทอรีไซต์
ตอนนี้ เราต้องโหลดข้อมูลของเราลงในสมุดบันทึก Jupyter เพื่อให้สามารถแก้ไขและดึงสิ่งที่เราต้องการได้ มาต่อจากที่เราค้างไว้ด้านบนกัน
ในการโหลดข้อมูลแบรนด์ คุณต้องรันบล็อกของโค้ดนี้:
# การสร้าง DataFrame สำหรับประสิทธิภาพของ URL ของเว็บไซต์ในแบรนด์และข้อความค้นหาที่มีตราสินค้า
ด้วย open("./branded_data.json") เป็น json_file:
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame (branded_data)
# เปลี่ยนชื่อคอลัมน์ 'คีย์' เป็นคอลัมน์ 'แลนดิ้งเพจ' และแปลงรายการ 'แลนดิ้งเพจ' เป็น URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["หน้า Landing Page"] = branded_df["หน้า Landing Page"].apply(แลมบ์ดา x: x[0])
สำหรับประสิทธิภาพที่ไม่มีตราสินค้าของหน้า Landing Page คุณจะต้องรันบล็อกของโค้ดนี้:
# การสร้าง DataFrame สำหรับประสิทธิภาพของ URL ของเว็บไซต์ในการสืบค้นที่ไม่ใช่แบรนด์
ด้วย open("./non_branded_data.json") เป็น json_file:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame (ไม่ใช่_branded_data)
# เปลี่ยนชื่อคอลัมน์ 'คีย์' เป็นคอลัมน์ 'แลนดิ้งเพจ' และแปลงรายการ 'แลนดิ้งเพจ' เป็น URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["landing page"] = non_branded_df["landing page"].apply(แลมบ์ดา x: x[0])
เราโหลดข้อมูลของเรา จากนั้นเราต้องกำหนดชื่อไซต์ของเราเพื่อแยกไดเรกทอรี
# การกำหนดชื่อเว็บไซต์ของคุณระหว่างคำพูด ตัวอย่างเช่น 'https://www.example.com/' หรือ 'http://mydomain.com/' SITE_NAME = "https://www.your_domain.com/"
เราจำเป็นต้องแยกไดเร็กทอรีออกจากประสิทธิภาพที่ไม่มีตราสินค้าเท่านั้น
# รับไดเรกทอรีหน้า Landing Page (URL) แต่ละรายการ
non_branded_df["directory"] = non_branded_df["หน้า Landing Page"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
จากนั้นเราพิมพ์ไดเร็กทอรีเพื่อเลือกไดเร็กทอรีที่สำคัญสำหรับกระบวนการนี้ คุณอาจต้องการเลือกไดเร็กทอรีทั้งหมดเพื่อให้เข้าใจไซต์ของคุณได้ดีขึ้น
# ในการรับไดเร็กทอรีทั้งหมดในเอาต์พุตเราต้องจัดการตัวเลือก Pandas
pd.set_option("display.max_rows", ไม่มี)
# ไดเรกทอรีเว็บไซต์
non_branded_df["ไดเรกทอรี"].value_counts()
ที่นี่ คุณสามารถแทรกไดเร็กทอรีใดก็ได้ที่สำคัญสำหรับคุณ

""" เลือกไดเร็กทอรีที่สำคัญสำหรับการรับ CTR Curve
แทรกไดเร็กทอรีลงในตัวแปร 'important_directories'
ตัวอย่างเช่น 'product,tag,product-category,mag' แยกค่าไดเรกทอรีด้วยเครื่องหมายจุลภาค
"""
IMPORTANT_DIRECTORIES = "your_important_directories"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. ติดป้ายกำกับหน้าตามตำแหน่งและคำนวณเส้น CTR สัมพัทธ์
ตอนนี้เราต้องติดป้ายกำกับหน้า Landing Page ตามตำแหน่ง เราทำเช่นนี้ เนื่องจากเราจำเป็นต้องคำนวณเส้นโค้ง CTR สัมพัทธ์สำหรับแต่ละไดเร็กทอรีตามตำแหน่งของหน้าที่เชื่อมโยงไปถึง
#การติดฉลากตำแหน่งที่ไม่มีตราสินค้า
สำหรับฉันอยู่ในช่วง (1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= i) & (non_branded_df["position"] < i + 1),
"ป้ายตำแหน่ง",
] = ฉัน
จากนั้น เราจัดกลุ่มหน้า Landing Page ตามไดเรกทอรี
# การจัดกลุ่มหน้า Landing Page ตามค่า 'ไดเรกทอรี' ของพวกเขา non_brand_grouped_df = non_branded_df.groupby (["ไดเรกทอรี"])
มากำหนดฟังก์ชันเพื่อคำนวณเส้นโค้ง CTR แบบสัมพัทธ์กัน
def each_dir_relative_ctr_curve(dir_df, คีย์):
"""ฟังก์ชันจะคำนวณเส้นโค้ง CTR ที่เกี่ยวข้อง IMPORTANT_DIRECTORIES เส้น
"""
# การจัดกลุ่ม "non_brand_grouped_df" ตามค่า "ป้ายกำกับตำแหน่ง"
dir_grouped_df = dir_df.groupby(["ป้ายกำกับตำแหน่ง"])
# รายการบันทึกแต่ละตำแหน่งค่ามัธยฐาน CTR
ค่ามัธยฐาน_ctr_list = []
# การจัดเก็บแต่ละไดเร็กทอรีเป็นคีย์ และมันคือ "median_ctr_list" เป็นค่า
ไดเร็กทอรี_median_ctr = {}
# วนซ้ำแต่ละกลุ่ม "dir_grouped_df"
สำหรับฉันอยู่ในช่วง (1, 11):
# ลองยกเว้นในการจัดการสถานการณ์เหล่านั้นที่ไดเรกทอรีเช่นไม่มีข้อมูลใด ๆ สำหรับตำแหน่ง 4
ลอง:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
ยกเว้น:
median_ctr_list.append(0)
# การคำนวณเส้นโค้ง CTR สัมพัทธ์
directory_median_ctr[คีย์] = np.array(median_ctr_list) / np.array(
[ค่ามัธยฐาน_ctr_list[0]] * 10
)
ส่งคืนไดเร็กทอรี_median_ctr
หลังจากที่เรากำหนดฟังก์ชันแล้ว เราก็รันมัน
# วนรอบไดเรกทอรีและเรียกใช้ฟังก์ชัน 'each_dir_relative_ctr_curve'
ไดเร็กทอรี_median_ctr_dict = dict()
สำหรับคีย์ รายการใน non_brand_grouped_df:
หากป้อน IMPORTANT_DIRECTORIES:
directory_median_ctr_dict.update(each_dir_relative_ctr_curve(รายการ, คีย์))
พิมพ์ (directories_median_ctr_dict)
ตอนนี้ เราจะโหลดหน้า Landing Page ประสิทธิภาพทั้งแบบมีแบรนด์และไม่ใช่แบรนด์ และคำนวณเส้นโค้ง CTR แบบสัมพัทธ์สำหรับข้อมูลที่ไม่ใช่แบรนด์ของเรา เหตุใดเราจึงทำเช่นนี้สำหรับข้อมูลที่ไม่ใช่แบรนด์เท่านั้น เพราะเราต้องการคาดการณ์การเข้าชมและรายได้ที่ไม่ใช่แบรนด์ทั่วไป
ขั้นตอนที่ 2: การคาดคะเนรายได้จากการเข้าชมทั่วไปที่ไม่มีแบรนด์
ในขั้นตอนที่ 2 เราจะมาดูวิธีการดึงข้อมูลรายได้และคาดการณ์รายได้ของเรา
1. การรวมข้อมูลอินทรีย์ที่มีตราสินค้าและไม่ใช่ตราสินค้า
ตอนนี้ เราจะรวมข้อมูลที่มีแบรนด์และไม่ใช่แบรนด์เข้าด้วยกัน ซึ่งจะช่วยให้เราคำนวณเปอร์เซ็นต์ของการเข้าชมแบบออร์แกนิกที่ไม่มีแบรนด์ในหน้า Landing Page แต่ละหน้าเมื่อเปรียบเทียบกับการเข้าชมทั้งหมด
# 'main_df' คือการรวมกันของ DataFrames 'ข้อมูลไซต์ทั้งหมด' และ 'ข้อมูลที่ไม่ใช่แบรนด์'
# เมื่อใช้ DataFrame นี้ คุณจะค้นหาได้ว่าการคลิกและการแสดงผลส่วนใหญ่ของเราอยู่ที่ใด
# มาจากคำค้นหาที่ไม่มีตราสินค้า
main_df = non_branded_df.merge (
branded_df, on="landing page", suffixes=("_non_brand", "_branded")
)
จากนั้นเราแก้ไขคอลัมน์เพื่อลบคอลัมน์ที่ไม่มีประโยชน์
# การปรับเปลี่ยนคอลัมน์ 'main_df' เป็นคอลัมน์ที่เราต้องการ
main_df = main_df[
[
"หน้า Landing Page",
"clicks_non_brand",
"ctr_non_brand",
"ไดเรกทอรี",
"ป้ายตำแหน่ง",
"clicks_branded",
]
]
ตอนนี้ มาคำนวณเปอร์เซ็นต์การคลิกที่ไม่มีแบรนด์กับจำนวนคลิกทั้งหมดของหน้า Landing Page
# การคำนวณเปอร์เซ็นต์การคลิกคำค้นหาที่ไม่มีแบรนด์โดยอิงจากหน้า Landing Page ไปจนถึงการคลิกหน้า Landing Page ทั้งหมด
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
แลมบ์ดา x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
แกน=1,
)
[Ebook] ทำ SEO อัตโนมัติด้วย Oncrawl
 อ่านอีบุ๊ก
อ่านอีบุ๊ก2. กำลังโหลดรายได้จากการเข้าชมอินทรีย์
เช่นเดียวกับการดึงข้อมูล GSC เรามีหลายวิธีในการรับข้อมูล GA: เราสามารถใช้ “ส่วนเสริม Google Analytics ชีต” หรือ GA API ในบทช่วยสอนนี้ ฉันชอบใช้ Google Data Studio (GDS) เนื่องจากความเรียบง่าย
ในการรับข้อมูล GA จาก GDS ให้ทำตามขั้นตอนเหล่านี้:
- ใน GDS ให้สร้างรายงานหรือตัวสำรวจและตารางใหม่
- สำหรับมิติข้อมูลเพิ่ม "หน้า Landing Page" และสำหรับเมตริก เราต้องเพิ่ม "รายได้"
- จากนั้น คุณจะต้องสร้างกลุ่มที่กำหนดเองใน GA ตามแหล่งที่มาและสื่อ กรองการเข้าชม "Google/ทั่วไป" หลังจากสร้างเซ็กเมนต์แล้ว ให้เพิ่มลงในส่วนเซ็กเมนต์ใน GDS
- ในขั้นตอนสุดท้าย ส่งออกตารางและบันทึกเป็น “
landing_pages_revenue.csv”
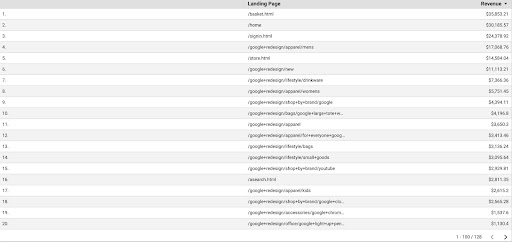
รายได้จากหน้า Landing Page การส่งออก csv
มาโหลดข้อมูลของเรากัน
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
ตอนนี้ เราต้องผนวกชื่อไซต์ของเราต่อท้าย URL ของหน้า Landing Page ของ GA
เมื่อเราส่งออกข้อมูลของเราจาก GA หน้า Landing Page จะอยู่ในรูปแบบที่เกี่ยวข้อง แต่ข้อมูล GSC จะอยู่ในรูปแบบสัมบูรณ์
อย่าลืมตรวจสอบข้อมูลหน้า Landing Page ของ GA ในชุดข้อมูลที่ฉันทำงานด้วย ฉันพบว่าข้อมูล GA ต้องการการล้างข้อมูลเล็กน้อยในแต่ละครั้ง
# กำลังเชื่อมโยง URL ของหน้า Landing Page ของ GA กับ SITE_NAME
# นอกจากนี้การเปลี่ยนชื่อคอลัมน์
organic_revenue_df.loc[:, "แลนดิ้งเพจ"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Landing Page": "landing Page", "Revenue": "revenue"}, inplace=True)
มารวมข้อมูล GSC ของเรากับข้อมูล GA กัน
# ในขั้นตอนนี้ ฉันรวม 'main_df' กับ 'dk_organic_revenue_df' DataFrame ที่มีเปอร์เซ็นต์ของข้อมูลการสืบค้นที่ไม่ใช่แบรนด์ main_df = main_df.merge (organic_revenue_df, on="หน้า Landing Page", วิธี = "ซ้าย")
ที่ส่วนท้ายของส่วนนี้ เราจะทำการล้างข้อมูลเล็กน้อยในคอลัมน์ DataFrame ของเรา
# ทำความสะอาด DataFrame 'main_df' เล็กน้อย
main_df = main_df[
[
"หน้า Landing Page",
"clicks_non_brand",
"ctr_non_brand",
"ไดเรกทอรี",
"ป้ายตำแหน่ง",
"clicks_non_brand_percentage",
"รายได้",
]
]
3. การคำนวณรายได้ที่ไม่มีแบรนด์
ในส่วนนี้ เราจะประมวลผลข้อมูลเพื่อดึงข้อมูลที่เรากำลังมองหา
แต่ก่อนอื่น เรามากรองหน้า Landing Page ของเราตาม “ IMPORTANT_DIRECTORIES ”:
# การลบหน้า Landing Page ของไดเรกทอรีอื่น ๆ ที่ไม่รวมอยู่ใน "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["directory"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=["รายได้"])
.reset_index(drop=จริง)
)
ตอนนี้ มาคำนวณการเข้าชมของรายได้ทั่วไปที่ไม่มีแบรนด์กัน
ฉันกำหนดเมตริกที่เราไม่สามารถคำนวณได้ง่าย ๆ และมันเป็นสัญชาตญาณมากกว่าสิ่งอื่นใดที่ทำให้เรากำหนดตัวเลขให้กับมัน
ตัวชี้วัด “ brand_influence ” แสดงถึงความแข็งแกร่งของแบรนด์ของคุณ หากคุณเชื่อว่าการค้นหาที่ไม่ใช่แบรนด์ช่วยเพิ่มยอดขายให้กับธุรกิจของคุณ ลดจำนวนนี้ให้ต่ำลง เช่น 0.8 เป็นต้น
# หากแบรนด์ของคุณแข็งแกร่งมากจนการสืบค้นโดยไม่มีแบรนด์ของคุณสามารถขายได้มากเท่ากับการสอบถามแบรนด์ของคุณ ดังนั้น 1 ก็ดีสำหรับคุณ
# ลองนึกถึงการค้นหาหนังสือที่ไม่มีชื่อแบรนด์ในข้อความค้นหาของคุณ เมื่อคุณเห็น Amazon คุณซื้อจากตลาดหรือร้านค้าอื่นหรือไม่
brand_influence = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
แลมบ์ดา x: x["revenue"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
มาสร้างแผนภูมิวงกลมกันเพื่อรับข้อมูลเชิงลึกเกี่ยวกับรายได้ที่ไม่มีแบรนด์โดยอิงจากไดเรกทอรีที่สำคัญ
# ในเซลล์นี้ ฉันต้องการรับรายได้หน้า Landing Page ที่ไม่ใช่แบรนด์ทั้งหมดตามไดเรกทอรี
non_branded_directory_dist_revenue_df = pd.pivot_table (
main_df,
ดัชนี="ไดเรกทอรี",
ค่า=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
ค่านิยม = "ไม่ใช่แบรนด์_รายได้",
ชื่อ=non_branded_directory_dist_revenue_df.index,
title="รายได้ที่ไม่มีแบรนด์ตามไดเรกทอรีเว็บไซต์",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
pie_fig.show()
พล็อตนี้แสดงการกระจายข้อความค้นหาที่ไม่มีแบรนด์ใน IMPORTANT_DIRECTORIES ของคุณ
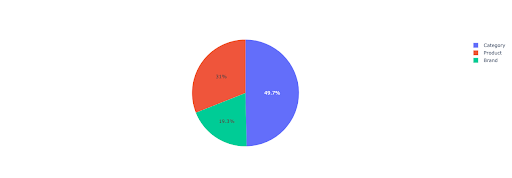
การกระจายข้อความค้นหาที่ไม่มีแบรนด์
จากข้อมูลเส้นโค้ง CTR ของฉัน ฉันเห็นว่าฉันไม่สามารถพึ่งพา CTR สำหรับตำแหน่งที่สูงกว่า 5 ได้ ด้วยเหตุนี้ ฉันจึงกรองข้อมูลตามตำแหน่ง
คุณสามารถแก้ไขบล็อคโค้ดด้านล่างตามข้อมูลของคุณ
# เนื่องจากความแม่นยำของ CTR ในกราฟ CTR ของเรา ฉันคิดว่าเราสามารถข้ามการลงจอดที่มีตำแหน่งมากกว่า 5 ได้ ด้วยเหตุนี้ ฉันจึงกรองหน้า Landing Page อื่นๆ main_df = main_df[main_df["ป้ายกำกับตำแหน่ง"] < 6].reset_index(drop=True)
4. การคำนวณ “รายได้ต่อคลิก” (RPC)
ที่นี่ ฉันสร้างเมตริกที่กำหนดเองและเรียกมันว่า "รายได้ต่อคลิก" หรือ RPC ข้อมูลนี้แสดงรายได้ที่เกิดจากการคลิกแบบไม่มีแบรนด์แต่ละครั้ง
คุณสามารถใช้เมตริกนี้ได้หลายวิธี ฉันพบหน้าที่มี RPC สูง แต่มีการคลิกต่ำ เมื่อฉันตรวจสอบหน้าเว็บ ฉันพบว่ามีการจัดทำดัชนีไว้ไม่ถึงหนึ่งสัปดาห์ที่แล้ว และเราสามารถใช้วิธีการต่างๆ เพื่อเพิ่มประสิทธิภาพหน้าเว็บได้
# การคำนวณรายได้ที่เกิดขึ้นในแต่ละคลิก (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
แลมบ์ดา x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. คาดการณ์รายได้!
เรากำลังถึงจุดสิ้นสุด เรารอจนถึงตอนนี้เพื่อคาดการณ์รายได้ออร์แกนิกที่ไม่มีแบรนด์ของเรา
มาเรียกใช้บล็อกโค้ดสุดท้ายกัน
# หน้าที่หลักในการคำนวณรายได้ตามตำแหน่งต่างๆ
สำหรับดัชนี row_values ใน main_df.iterrows():
# สลับระหว่างรายการ CTR ของไดเรกทอรี
ctr_curve = ไดเร็กทอรี_median_ctr_dict[row_values["directory"]]
# วนรอบตำแหน่ง 1 ถึง 5 และคำนวณรายได้ตามการเพิ่มขึ้นหรือลดลงของ CTR
สำหรับฉันอยู่ในช่วง (1, 6):
ถ้าฉัน == row_values["position label"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
อื่น:
# main_df.loc[ดัชนี ผม + 1] ==
main_df.loc[ดัชนี ผม] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["position label"] - 1)]
)
# การคำนวณเมตริก "N ถึง 1" สิ่งนี้แสดงรายได้ที่เพิ่มขึ้นเมื่ออันดับของคุณได้รับจาก "N" เป็น "1"
main_df.loc[ดัชนี, "N ถึง 1"] = main_df.loc[ดัชนี, 1] - main_df.loc[ดัชนี, row_values["ป้ายกำกับตำแหน่ง"]]
เมื่อดูผลลัพธ์สุดท้าย เรามีคอลัมน์ใหม่ ชื่อของคอลัมน์เหล่านี้คือ “1”, “2”, “3”, “4”, “5”
ชื่อเหล่านี้หมายถึงอะไร? ตัวอย่างเช่น เรามีหน้าอยู่ในอันดับที่ 3 และเราต้องการคาดการณ์รายได้ของหน้านั้นหากหน้านั้นเพิ่มอันดับ หรือเราต้องการทราบว่าเราจะสูญเสียเท่าใดหากเราตกอันดับ
คอลัมน์ "1" และ "2" แสดงรายได้ของหน้าเว็บเมื่ออันดับเฉลี่ยของหน้านี้ดีขึ้น และคอลัมน์ "4" และ "5" แสดงรายได้ของหน้านี้เมื่อเราจัดอันดับลดลง
คอลัมน์ “3” ในตัวอย่างนี้แสดงรายได้ปัจจุบันของหน้า
นอกจากนี้ ฉันยังได้สร้างเมตริกที่เรียกว่า "N ถึง 1" นี่แสดงให้เห็นว่าอันดับเฉลี่ยของหน้านี้เปลี่ยนจาก “3” (หรือ N) เป็น “1” หรือไม่ และการย้ายดังกล่าวจะส่งผลต่อรายได้มากน้อยเพียงใด
ห่อ
ฉันได้กล่าวถึงไปมากมายในบทความนี้ และตอนนี้ก็ถึงตาคุณแล้วที่จะทำให้มือของคุณสกปรกและคาดการณ์รายได้จากการเข้าชมแบบออร์แกนิกที่ไม่ใช่แบรนด์ของคุณ
นี่เป็นวิธีที่ง่ายที่สุดที่เราสามารถใช้การคาดคะเนนี้ได้ เราสามารถทำให้อัลกอริธึมนี้ซับซ้อนขึ้นและรวมเข้ากับโมเดล ML บางรุ่นได้ แต่นั่นจะทำให้บทความซับซ้อนขึ้น
ฉันต้องการบันทึกข้อมูลนี้เป็น CSV และอัปโหลดไปยัง Google ชีต หรือถ้าฉันวางแผนที่จะแชร์กับสมาชิกคนอื่นๆ ในทีมของฉันหรือองค์กร ฉันจะเปิดด้วย excel และจัดรูปแบบคอลัมน์โดยใช้สีเพื่อให้อ่านง่ายขึ้น
จากข้อมูลนี้ คุณสามารถคาดการณ์ ROI ของการเข้าชมที่เกิดขึ้นเองที่ไม่ใช่แบรนด์ของคุณ และใช้ในกระบวนการเจรจาของคุณ