
การอัปเดตหลักของ Google: ผลกระทบ ปัญหา และวิธีแก้ไขสำหรับไซต์ YMYL
เผยแพร่แล้ว: 2019-12-04ในกรณีศึกษานี้ ฉันจะดูที่ Hangikredi.com ซึ่งเป็นหนึ่งในสินทรัพย์ทางการเงินและดิจิทัลที่ใหญ่ที่สุดของตุรกี เราจะเห็นหัวข้อย่อยทางเทคนิค SEO และกราฟิกบางส่วน
กรณีศึกษานี้นำเสนอเป็นสองบทความ บทความนี้กล่าวถึงการอัปเดตหลักของ Google ในวันที่ 12 มีนาคม ซึ่งส่งผลเสียอย่างร้ายแรงต่อเว็บไซต์ และสิ่งที่เราทำเพื่อแก้ไข เราจะพิจารณาปัญหาทางเทคนิคและวิธีแก้ไข 13 รายการ รวมถึงปัญหาแบบองค์รวม
อ่านงวดที่ 2 เพื่อดูว่าฉันนำการเรียนรู้จากการอัปเดตนี้ไปใช้อย่างไรเพื่อเป็นผู้ชนะจากการอัปเดต Google Core ทุกครั้ง
ปัญหาและแนวทางแก้ไข: การแก้ไขผลกระทบของการอัปเดต Google Core วันที่ 12 มีนาคม
จนถึงวันที่ 12 มีนาคม Core Algorithm Update ทุกอย่างเป็นไปอย่างราบรื่นสำหรับเว็บไซต์ โดยอิงจากข้อมูลการวิเคราะห์ ในหนึ่งวัน หลังจากที่ข่าวเกี่ยวกับ Core Algorithm Update ถูกเผยแพร่ออกมา การจัดอันดับและความยุ่งยากในสำนักงานก็ลดลงอย่างมาก โดยส่วนตัวแล้วฉันไม่ได้เห็นวันนั้นเพราะฉันเพิ่งมาถึงเมื่อพวกเขาจ้างฉันให้เริ่มโครงการ SEO ใหม่และดำเนินการ 14 วันต่อมา
[กรณีศึกษา] การปรับปรุงการจัดอันดับ การเข้าชมแบบออร์แกนิก และการขายด้วยการวิเคราะห์ไฟล์บันทึก
 อ่านกรณีศึกษา
อ่านกรณีศึกษารายงานความเสียหายสำหรับเว็บไซต์ของบริษัทหลังการอัปเดต Core Algorithm ในวันที่ 12 มีนาคม มีดังนี้:
- การสูญเสียเซสชันออร์แกนิก 36%
- 65% คลิกวาง
- การสูญเสีย CTR 30%
- การสูญเสียผู้ใช้ทั่วไป 33%
- เสียการแสดงผล 100,000 ครั้งต่อวัน
- 9.72% การสูญเสียการแสดงผล
- 8,000 คีย์เวิร์ดหายไป

ดังที่เราได้กล่าวไว้ตอนต้นของบทความกรณีศึกษา เราควรถามคำถามหนึ่งคำถาม เราไม่สามารถถามได้ว่า "การอัปเดต Core Algorithm ครั้งต่อไปจะเกิดขึ้นเมื่อใด" เพราะมันได้เกิดขึ้นแล้ว เหลือเพียงคำถามเดียว
“ Google พิจารณาเกณฑ์ที่แตกต่างกันอย่างไรระหว่างฉันกับคู่แข่งของฉัน”
ดังที่คุณเห็นจากแผนภูมิด้านบนและจากรายงานความเสียหาย เราได้สูญเสียการเข้าชมหลักและคำหลักของเราไปแล้ว
1. ปัญหา: การเชื่อมโยงภายใน
ฉันสังเกตว่าในครั้งแรกที่ฉันตรวจสอบจำนวนลิงก์ภายใน ข้อความแองเคอร์ และโฟลว์ลิงก์ คู่แข่งของฉันอยู่ข้างหน้าฉัน
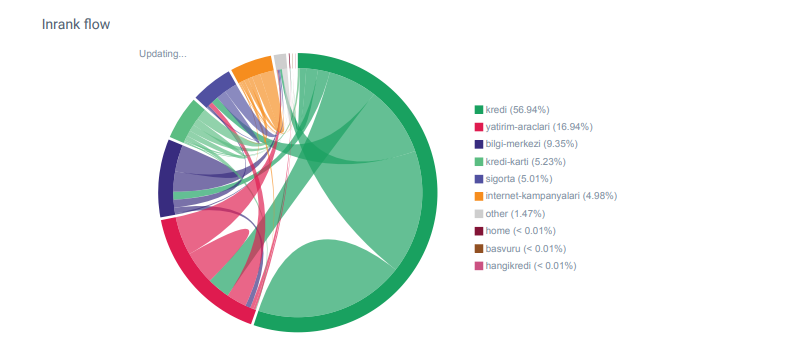
รายงาน Linkflow สำหรับหมวดหมู่ของ Hangikredi.com จาก OnCrawl
คู่แข่งหลักของฉันมีลิงก์ภายในมากกว่า 340,000 ลิงก์พร้อมข้อความยึดเหนี่ยวนับพัน ในปัจจุบัน เว็บไซต์ของเรามีเพียง 70,000 ลิงค์ภายในที่ไม่มี anchor text อันมีค่า นอกจากนี้ การขาดลิงก์ภายในยังส่งผลต่องบประมาณการรวบรวมข้อมูลและประสิทธิภาพการทำงานของเว็บไซต์อีกด้วย แม้ว่า 80% ของการเข้าชมของเราจะถูกรวบรวมในหน้าผลิตภัณฑ์เพียง 20 หน้า แต่ 90% ของไซต์ของเราประกอบด้วยหน้าคำแนะนำพร้อมข้อมูลที่เป็นประโยชน์สำหรับผู้ใช้ คำหลักและคะแนนความเกี่ยวข้องส่วนใหญ่ของเราสำหรับการสืบค้นข้อมูลทางการเงินมาจากหน้าเหล่านี้ นอกจากนี้ยังมีหน้าเด็กกำพร้ามากเกินไปนับไม่ถ้วน
เนื่องจากโครงสร้างการเชื่อมโยงภายในขาดหายไป เมื่อฉันทำการวิเคราะห์บันทึกด้วย Kibana ฉันสังเกตเห็นว่าหน้าที่รวบรวมข้อมูลมากที่สุดคือหน้าที่ได้รับการเข้าชมน้อยที่สุด นอกจากนี้ เมื่อฉันจับคู่สิ่งนี้กับเครือข่ายลิงก์ภายใน ฉันพบว่าหน้าองค์กรที่มีการเข้าชมต่ำที่สุด (หน้าความเป็นส่วนตัว คุกกี้ ความปลอดภัย หน้าเกี่ยวกับเรา) มีจำนวนลิงก์ภายในสูงสุด
ตามที่ฉันจะพูดถึงในหัวข้อถัดไป การทำเช่นนี้ทำให้ Googlebot ลบปัจจัยการเชื่อมโยงภายในออกจาก Pagerank เมื่อรวบรวมข้อมูลเว็บไซต์ โดยตระหนักว่าลิงก์ภายในไม่ได้ถูกสร้างขึ้นตามที่ตั้งใจไว้
2. ปัญหา: Site-Architecture, Inter²rnal Pagerank, Traffic and Crawl Efficiency
ตามคำแถลงของ Google ลิงก์ภายในและ anchor text ช่วยให้ Googlebot เข้าใจถึงความสำคัญและบริบทของหน้าเว็บ Pagerank ภายในหรือ Inrank คำนวณจากปัจจัยมากกว่าหนึ่งปัจจัย ตามคำกล่าวของ Bill Slawski ลิงก์ภายในหรือภายนอกนั้นไม่เท่ากันทั้งหมด ค่าของลิงก์สำหรับโฟลว์ Pagerank จะเปลี่ยนไปตามตำแหน่ง ชนิด สไตล์ และน้ำหนักแบบอักษร

หาก Googlebot เข้าใจว่าหน้าใดมีความสำคัญสำหรับเว็บไซต์ของคุณ Googlebot จะรวบรวมข้อมูลและจัดทำดัชนีเร็วขึ้น ลิงก์ภายในและการออกแบบแผนผังไซต์ที่ถูกต้องเป็นปัจจัยสำคัญสำหรับสิ่งนี้ ผู้เชี่ยวชาญคนอื่น ๆ ยังได้ให้ความเห็นเกี่ยวกับความสัมพันธ์นี้ในช่วงหลายปีที่ผ่านมา:
“ลิงก์ส่วนใหญ่จะให้บริบทเพิ่มเติมเล็กน้อยผ่าน anchor text อย่างน้อยก็ควรใช่ไหม”
–จอห์น มูลเลอร์, Google 2017“หากคุณมีเพจที่คุณคิดว่าสำคัญในเว็บไซต์ของคุณ อย่าฝัง 15 ลิงค์ไว้ในเว็บไซต์ของคุณ และผมไม่ได้หมายถึงความยาวของไดเร็กทอรี ผมหมายถึงคุณต้องคลิกผ่าน 15 ลิงค์ถึงจะเจอหน้านั้น หากมีหน้าที่สำคัญหรือมีอัตรากำไรสูงหรือแปลงจริงๆ – ดี – บานปลายที่ใส่ลิงก์ไปยังหน้านั้นจากหน้ารากของคุณ นั่นคือสิ่งที่สามารถเข้าใจได้มาก "
–Matt Cutts, Google 2011“หากหน้าหนึ่งเชื่อมโยงไปยังอีกหน้าหนึ่งด้วยคำว่า “ติดต่อ” หรือคำว่า “เกี่ยวกับ” และหน้าที่เชื่อมโยงเพื่อรวมที่อยู่ ตำแหน่งของที่อยู่นั้นอาจถือว่าเกี่ยวข้องกับหน้าที่เชื่อมโยงนั้น”
12 วิธีการวิเคราะห์ Google Link ที่อาจเปลี่ยนไป – Bill Slawski
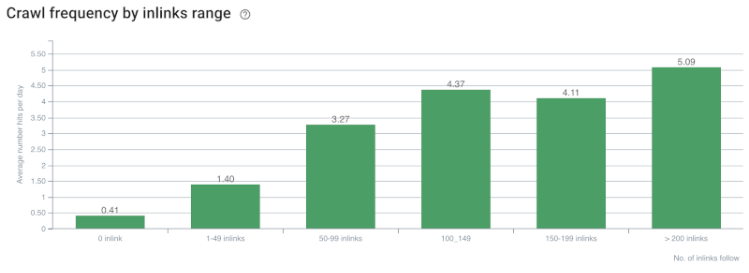
อัตราการรวบรวมข้อมูล/อุปสงค์และความสัมพันธ์ของจำนวนลิงก์ภายใน ที่มา: OnCrawl
จนถึงตอนนี้ เราอาจทำการอนุมานเหล่านี้:
- Google ให้ความสำคัญกับความลึกของการคลิก หากหน้าเว็บอยู่ใกล้กับโฮมเพจก็ควรมีความสำคัญมากกว่า สิ่งนี้ได้รับการยืนยันโดย John Mueller เมื่อวันที่ 1 กรกฎาคม 2018 ภาษาอังกฤษ Google Webmaster Hangout
- หากหน้าเว็บมีลิงก์ภายในจำนวนมากซึ่งชี้ไปที่ลิงก์นั้น ก็ควรมีความสำคัญ
- ข้อความ Anchor สามารถให้อำนาจตามบริบทแก่หน้าเว็บได้
- ลิงก์ภายในสามารถส่งจำนวน Pagerank ที่แตกต่างกันตามตำแหน่ง ประเภท น้ำหนักแบบอักษร หรือรูปแบบ
- Site-Tree ที่เป็นมิตรกับ UX ที่ให้ข้อความที่ชัดเจนเกี่ยวกับ Internal Page Authority แก่โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาเป็นทางเลือกที่ดีกว่าสำหรับการกระจาย Inrank และประสิทธิภาพการรวบรวมข้อมูล
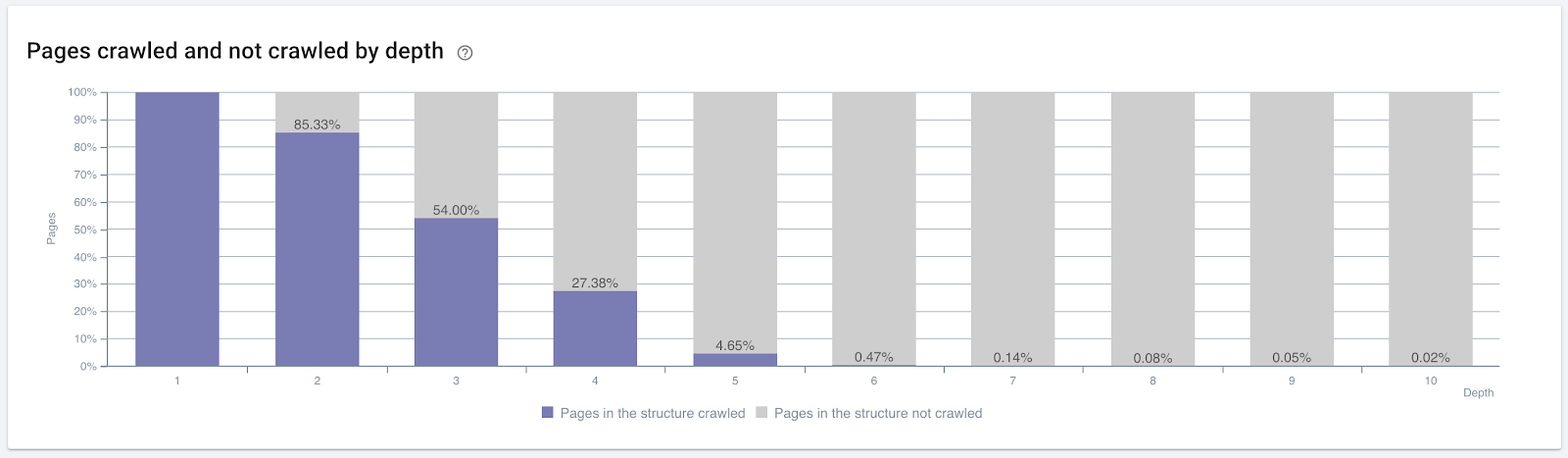
เปอร์เซ็นต์ของหน้าที่รวบรวมข้อมูลตามความลึกของการคลิก ที่มา: OnCrawl
แต่สิ่งเหล่านี้ไม่เพียงพอที่จะเข้าใจธรรมชาติของลิงก์ภายในและผลกระทบของการรวบรวมข้อมูล
โปรแกรมรวบรวมข้อมูล SEO Oncrawl
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมหากหน้าที่เชื่อมโยงภายในส่วนใหญ่ของคุณไม่สร้างการเข้าชมหรือได้รับการคลิก จะเป็นสัญญาณที่บ่งชี้ว่าแผนผังไซต์และโครงสร้างลิงก์ภายในของคุณไม่ได้สร้างขึ้นตามเจตนาของผู้ใช้ และ Google พยายามค้นหาหน้าที่เกี่ยวข้องมากที่สุดของคุณด้วยความตั้งใจของผู้ใช้หรือเอนทิตีการค้นหา เรามีการอ้างอิงอื่นจาก Bill Slawski ที่ทำให้เรื่องนี้ชัดเจนขึ้น:
“หากทรัพยากรเชื่อมโยงกับทรัพยากรจำนวนหนึ่งซึ่งไม่สมส่วนกับการรับส่งข้อมูลที่ได้รับจากการใช้ลิงก์เหล่านั้น ทรัพยากรนั้นอาจถูกลดระดับในกระบวนการจัดอันดับ”
การอัปเดต Groundhog เพิ่งเกิดขึ้นที่ Google หรือไม่ — บิล สลอว์สกี้“คะแนนคุณภาพการเลือกอาจสูงกว่าสำหรับการเลือกที่ส่งผลให้มีเวลาพักนาน (เช่น มากกว่าช่วงเวลาเกณฑ์) มากกว่าคะแนนคุณภาพการเลือกสำหรับการเลือกที่ส่งผลให้มีเวลาพักสั้น”
การอัปเดต Groundhog เพิ่งเกิดขึ้นที่ Google หรือไม่ — บิล สลอว์สกี้
ดังนั้นเราจึงมีปัจจัยอีกสองประการ:
- Dwell Time ในหน้าเชื่อมโยง
- ปริมาณการใช้งานของผู้ใช้ที่สร้างโดยลิงก์
จำนวนลิงก์ภายในและรูปแบบ/ตำแหน่งไม่ใช่ปัจจัยเดียว จำนวนผู้ใช้ที่ติดตามลิงก์เหล่านี้และตัวชี้วัดพฤติกรรมก็มีความสำคัญเช่นกัน นอกจากนี้ เราทราบดีว่าลิงก์และหน้าที่คลิก/เข้าชมนั้น Google รวบรวมข้อมูลมากกว่าลิงก์และหน้าที่ไม่ได้คลิกหรือเข้าชม
“เราได้ก้าวไปสู่การทำความเข้าใจส่วนต่างๆ ของไซต์มากขึ้นเรื่อยๆ เพื่อทำความเข้าใจคุณภาพของส่วนเหล่านั้น”
John Mueller 2 พฤษภาคม 2017 Google Webmasters Hangout ภาษาอังกฤษ
จากปัจจัยทั้งหมดเหล่านี้ ฉันจะแบ่งปันผลลัพธ์ Pagerank Simulator ที่แตกต่างกันสองรายการ:
การคำนวณ Pagerank เหล่านี้ใช้สมมติฐานว่าทุกหน้าเท่ากัน รวมถึงหน้าแรกด้วย ความแตกต่างที่แท้จริงถูกกำหนดโดยลำดับชั้นของลิงก์
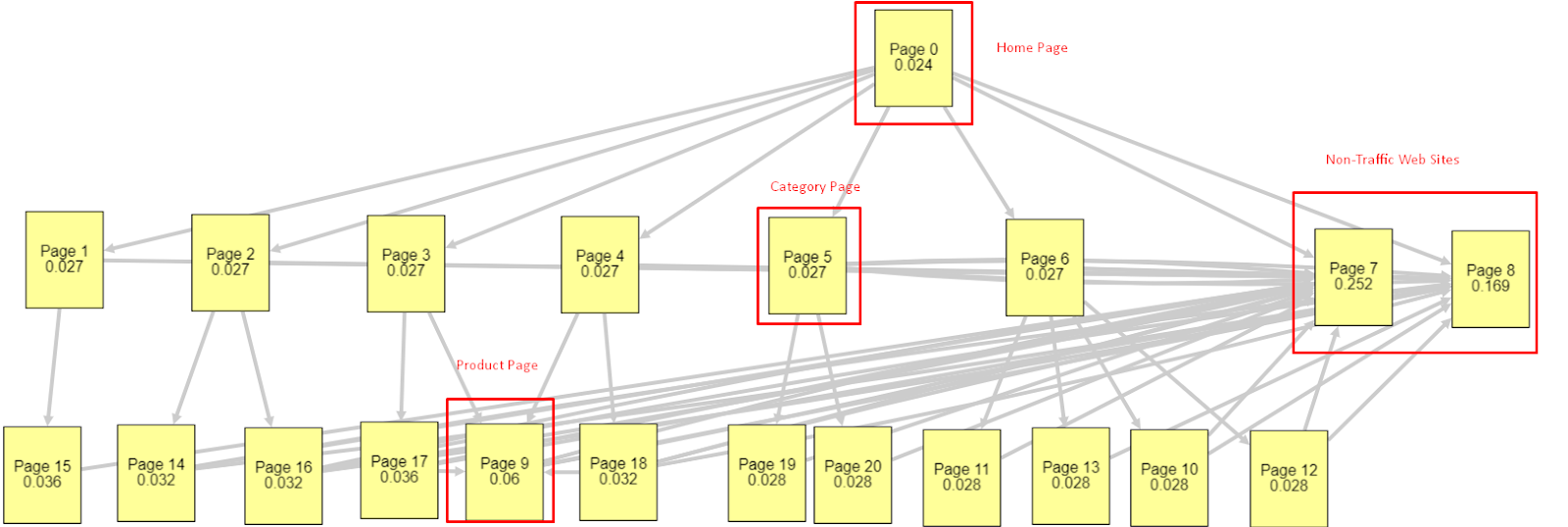
ตัวอย่างที่แสดงที่นี่อยู่ใกล้กับโครงสร้างลิงก์ภายในก่อนวันที่ 12 มีนาคม หน้าแรก PR: 0.024, หน้าหมวดหมู่ PR: 0.027, หน้าผลิตภัณฑ์ PR: 0.06, หน้าเว็บที่ไม่ใช่การเข้าชม PR: 0.252
ตามที่คุณอาจสังเกตเห็น Googlebot ไม่สามารถเชื่อถือโครงสร้างลิงก์ภายในนี้เพื่อคำนวณเพจแรงก์ภายในและความสำคัญของเพจภายใน เพจที่ไม่มีทราฟฟิกและปราศจากผลิตภัณฑ์มีอำนาจมากกว่าโฮมเพจ 12 เท่า มีมากกว่าหน้าสินค้า

ตัวอย่างนี้ใกล้เคียงกับสถานการณ์ของเรามากขึ้นก่อนการอัปเดต Core Algorithm ในวันที่ 5 มิถุนายน.. หน้าแรก PR: 0.033 หน้าหมวดหมู่: 0,037 หน้าผลิตภัณฑ์: 0,148 และ PR ของหน้าที่ไม่ใช่การจราจร: 0,037
ตามที่คุณอาจสังเกตเห็น โครงสร้างลิงก์ภายในยังไม่ถูกต้อง แต่อย่างน้อยหน้าเว็บที่ไม่ใช่การเข้าชมไม่มีการประชาสัมพันธ์มากกว่าหน้าหมวดหมู่และหน้าผลิตภัณฑ์
อะไรคือข้อพิสูจน์เพิ่มเติมว่า Google ได้นำลิงก์ภายในและโครงสร้างเว็บไซต์ออกจากขอบเขต Pagerank ตามกระแสของผู้ใช้ คำขอ และความตั้งใจ แน่นอนว่าพฤติกรรมของ Googlebot และ Inlink Pagerank และ Ranking Correlations:
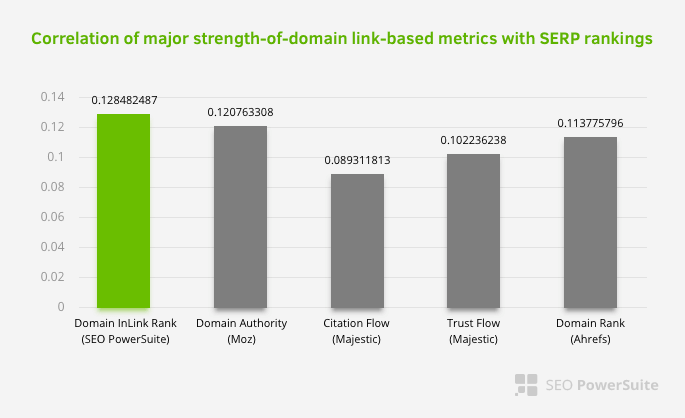
ไม่ได้หมายความว่าเครือข่ายลิงก์ภายในมีความสำคัญมากกว่าปัจจัยอื่นๆ มุมมอง SEO ที่เน้นที่จุดเดียวไม่สามารถประสบความสำเร็จได้ ในการเปรียบเทียบระหว่างเครื่องมือของบริษัทอื่น แสดงว่าค่า Pagerank ภายในมีความคืบหน้าเมื่อเทียบกับเกณฑ์อื่นๆ
จากการวิจัยของ Inlink Rank และอันดับสหสัมพันธ์โดย Aleh Barysevich หน้าที่มีลิงก์ภายในมากที่สุดจะมีอันดับที่สูงกว่าหน้าอื่นๆ ของเว็บไซต์ จากการสำรวจที่ดำเนินการในวันที่ 4-6 มีนาคม 2019 มีการวิเคราะห์เพจ 1,000,000 หน้าตามตัวชี้วัด Pagerank ภายในสำหรับคำหลัก 33,500 คำ ผลการวิจัยที่ดำเนินการโดย SEO PowerSuite ถูกนำมาเปรียบเทียบกับเมตริกต่างๆ ของ Moz, Majestic และ Ahrefs และให้ผลลัพธ์ที่แม่นยำยิ่งขึ้น
ต่อไปนี้คือหมายเลขลิงก์ภายในบางส่วนจากเว็บไซต์ของเราก่อนการอัปเดต Core Algorithm ในวันที่ 12 มีนาคม:
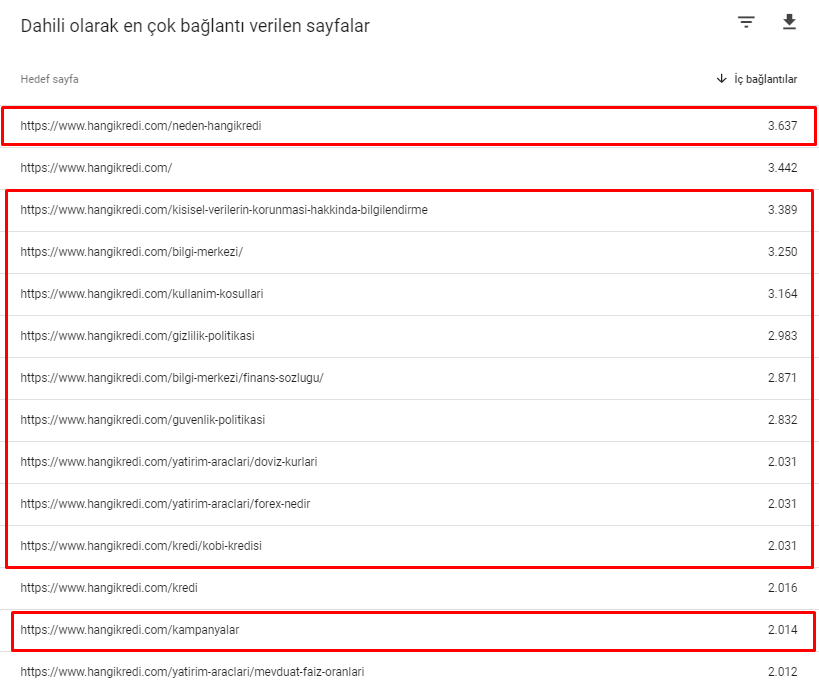
อย่างที่คุณเห็น รูปแบบการเชื่อมต่อภายในของเราไม่ได้สะท้อนถึงความตั้งใจและโฟลว์ของผู้ใช้ หน้าที่ได้รับการเข้าชมน้อยที่สุด (หน้าผลิตภัณฑ์รอง) หรือที่ไม่เคยได้รับการเข้าชม (สีแดง) อยู่ในความลึกของการคลิกครั้งแรกโดยตรงและได้รับการประชาสัมพันธ์จากหน้าแรก และบางอันก็มีลิงค์ภายในมากกว่าโฮมเพจเสียอีก
ในแง่ของทั้งหมดนี้ มีเพียงสองจุดสุดท้ายที่เราสามารถแสดงเกี่ยวกับเรื่องนี้ได้
- อัตราการรวบรวมข้อมูล / ความต้องการสำหรับหน้าที่เชื่อมโยงภายในมากที่สุด
- ลิงค์ Sculpting และ Pagerank
ระหว่างวันที่ 1 กุมภาพันธ์ถึง 31 มีนาคม ต่อไปนี้คือหน้าเว็บที่ Googlebot รวบรวมข้อมูลบ่อยที่สุด:
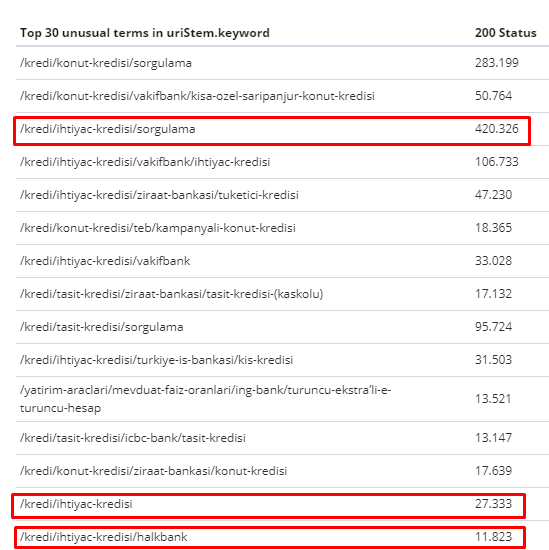
ดังที่คุณอาจสังเกตเห็น หน้าที่รวบรวมข้อมูลและหน้าที่มีลิงก์ภายในมากที่สุดจะแตกต่างกันโดยสิ้นเชิง หน้าที่มีลิงก์ภายในมากที่สุดไม่สะดวกสำหรับความตั้งใจของผู้ใช้ พวกเขาไม่มีคำหลักทั่วไปหรือมูลค่า SEO โดยตรงใดๆ (
URL ในช่องสีแดงคือหมวดหมู่หน้าผลิตภัณฑ์ที่เข้าชมบ่อยที่สุดและสำคัญของเรา หน้าอื่นๆ ในรายการนี้เป็นหมวดหมู่ที่มีผู้เข้าชมมากที่สุดเป็นอันดับสองหรือสาม)
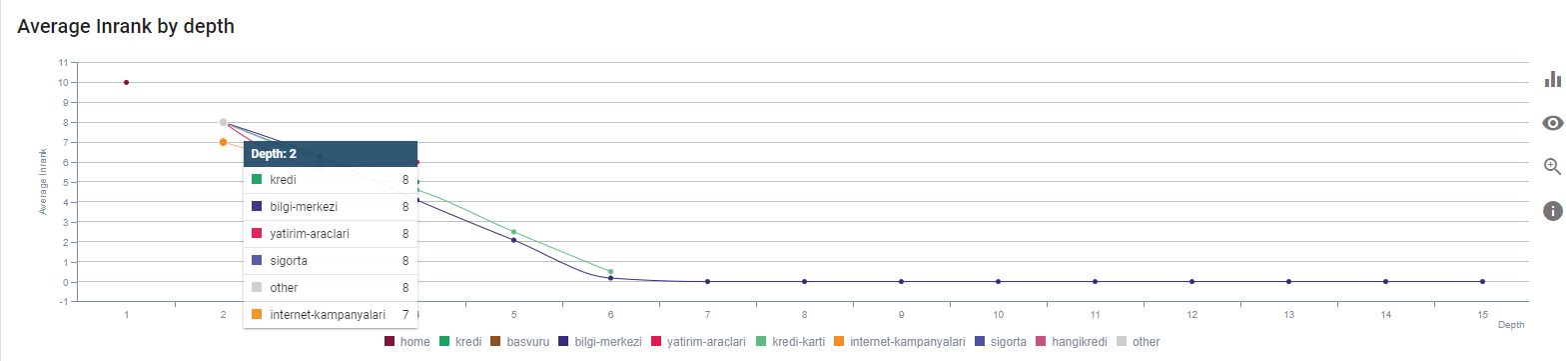
อันดับปัจจุบันของเราตามความลึกของหน้า ที่มา: Oncrawl
Link Sculpting คืออะไรและจะทำอย่างไรกับลิงก์ Nofollowed ภายใน
ตรงกันข้ามกับสิ่งที่ SEO ส่วนใหญ่เชื่อ ลิงก์ที่มีแท็ก "nofollow" ยังคงส่งค่า Pagerank ภายใน สำหรับฉัน หลังจากหลายปีที่ผ่านมานี้ ไม่มีใครบรรยายองค์ประกอบ SEO นี้ได้ดีไปกว่า Matt Cutts ในบทความ Pagerank Sculpting ของเขาตั้งแต่วันที่ 15 มิถุนายน 2552
ส่วนที่เป็นประโยชน์สำหรับ Link Sculpting ซึ่งแสดงจุดประสงค์ที่แท้จริงของ Pagerank Sculpting
“ฉันขอแนะนำว่าอย่า ใช้ nofollow สำหรับประเภทของ PageRank แกะสลักภายในเว็บไซต์ เพราะอาจไม่เป็นไปตามที่คุณคิด”
–จอห์น มูลเลอร์, Google 2017
หากคุณมีหน้าเว็บที่ไร้ค่าในแง่ของ Google และผู้ใช้ คุณไม่ควรแท็กพวกเขาด้วย "nofollow" มันจะไม่หยุดโฟลว์ Pagerank คุณควรไม่อนุญาตให้ใช้ไฟล์ robots.txt ด้วยวิธีนี้ Googlebot จะไม่รวบรวมข้อมูล แต่จะไม่ส่งเพจแรงก์ภายในให้พวกเขาด้วย แต่คุณควรใช้เฉพาะกับหน้าเว็บที่ไร้ค่าจริงๆ ตามที่ Matt Cutts กล่าวเมื่อสิบปีก่อน เพจที่ทำการเปลี่ยนเส้นทางอัตโนมัติสำหรับการตลาดแบบพันธมิตรหรือเพจที่ส่วนใหญ่ไม่มีเนื้อหาเป็นตัวอย่างที่สะดวกบางส่วนที่นี่
วิธีแก้ปัญหา: โครงสร้างการเชื่อมโยงภายในที่ดีขึ้นและเป็นธรรมชาติมากขึ้น
คู่แข่งของเรามีข้อเสีย เว็บไซต์ของพวกเขามี anchor text มากกว่า มีลิงก์ภายในมากกว่า แต่โครงสร้างไม่เป็นธรรมชาติและมีประโยชน์ มีการใช้ anchor text เดียวกันกับประโยคเดียวกันในแต่ละหน้าในเว็บไซต์ของตน ย่อหน้ารายการสำหรับแต่ละหน้ามีเนื้อหาซ้ำซากนี้ ผู้ใช้และเสิร์ชเอ็นจิ้นทุกคนสามารถทราบได้โดยง่ายว่านี่ไม่ใช่โครงสร้างธรรมชาติที่คำนึงถึงประโยชน์ของผู้ใช้
ดังนั้นฉันจึงตัดสินใจสามสิ่งที่ต้องทำเพื่อแก้ไขโครงสร้างลิงก์ภายใน:
- สถาปัตยกรรมข้อมูลไซต์หรือแผนผังไซต์ควรไปตามเส้นทางที่แตกต่างจากลิงก์ที่อยู่ในเนื้อหา ควรติดตามจิตใจของผู้ใช้และเครือข่ายประสาทคำหลักอย่างใกล้ชิด
- ในเนื้อหาแต่ละส่วน ควรใช้คำหลักด้านข้างร่วมกับคำหลักของหน้าเป้าหมาย
- Anchor text ควรมีความเป็นธรรมชาติ ปรับให้เข้ากับเนื้อหา และควรใช้จุดต่างๆ ในแต่ละหน้าโดยให้ความสนใจกับการรับรู้ของผู้ใช้
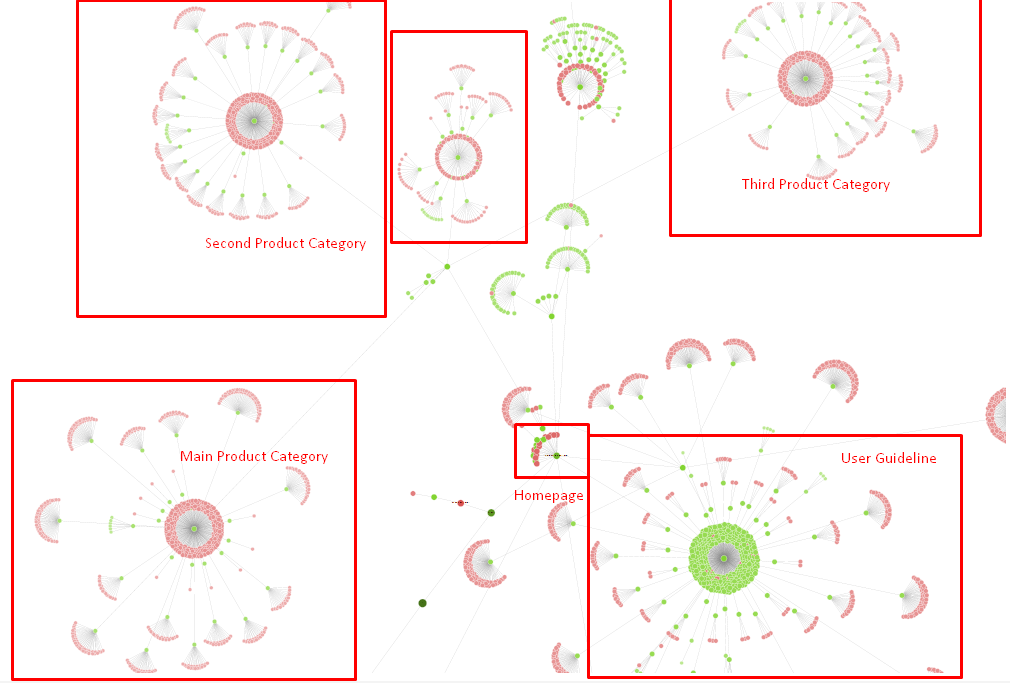
โครงสร้างแผนผังไซต์ของเราและส่วนหนึ่งของโครงสร้างลิงก์สำหรับตอนนี้
ในแผนภาพด้านบน คุณจะเห็นลิงก์ภายในปัจจุบันและแผนผังไซต์ของเรา
สิ่งที่เราทำเพื่อแก้ไขปัญหานี้มีดังนี้:
- เราสร้างลิงก์ภายในอีก 30,000 ลิงก์พร้อมจุดยึดที่มีประโยชน์
- เราใช้จุดที่เป็นธรรมชาติและคำหลักสำหรับผู้ใช้
- เราไม่ได้ใช้ประโยคและรูปแบบที่ซ้ำกันในการเชื่อมโยงภายใน
- เราให้สัญญาณที่ถูกต้องแก่ Googlebot เกี่ยวกับ Inrank ของหน้าเว็บ
- เราตรวจสอบผลกระทบของโครงสร้างลิงก์ภายในที่ถูกต้องต่อประสิทธิภาพการรวบรวมข้อมูลผ่านการวิเคราะห์บันทึก และพบว่าหน้าผลิตภัณฑ์หลักของเรามีการรวบรวมข้อมูลมากกว่าสถิติก่อนหน้า
- สร้างลิงก์ภายในมากกว่า 50,000 ลิงก์สำหรับเพจที่ไม่มีผู้ดูแล
- ใช้ลิงก์ภายในของโฮมเพจสำหรับเปิดเพจย่อยและสร้างแหล่งลิงก์ภายในเพิ่มเติมในโฮมเพจ
- สำหรับการปกป้อง Pagerank Power เราใช้แท็ก nofollow สำหรับลิงก์ภายนอกที่ไม่จำเป็น (สิ่งนี้ไม่เกี่ยวกับลิงก์ภายใน แต่มีเป้าหมายเดียวกัน)
3. ปัญหา: โครงสร้างเนื้อหา
Google กล่าวว่าสำหรับเว็บไซต์ YMYL ความน่าเชื่อถือและอำนาจมีความสำคัญมากกว่าเว็บไซต์ประเภทอื่นๆ

ในสมัยก่อน คีย์เวิร์ดเป็นเพียงคีย์เวิร์ด แต่ตอนนี้ สิ่งเหล่านี้ยังเป็น เอนทิตี ที่มีการกำหนดไว้อย่างชัดเจน เป็นเอกพจน์ มีความหมาย และแยกแยะได้ ในเนื้อหาของเรามีปัญหาหลักสี่ประการ:
- เนื้อหาของเราสั้น (โดยปกติ ความยาวของเนื้อหาไม่สำคัญ แต่ในกรณีนี้ มีข้อมูลไม่เพียงพอเกี่ยวกับหัวข้อ)
- ชื่อนักเขียนของเราไม่ใช่เอกพจน์ มีความหมาย หรือแยกความแตกต่างได้ในฐานะเอนทิตี
- เนื้อหาของเราไม่เป็นมิตรกับสายตา กล่าวคือไม่ใช่เนื้อหา "ฟาสต์ฟู้ด" เป็นเนื้อหาที่ไม่มีหัวข้อย่อย
- เราใช้ภาษาการตลาด ในวรรคหนึ่ง เราสามารถระบุชื่อแบรนด์และโฆษณาสำหรับผู้ใช้ได้
- มีปุ่มมากมายที่ส่งผู้ใช้ไปยังหน้าผลิตภัณฑ์จากหน้าข้อมูล
- ในเนื้อหาของหน้าผลิตภัณฑ์ของเรา มีข้อมูลไม่เพียงพอหรือแนวทางปฏิบัติที่ครอบคลุม
- การออกแบบไม่เป็นมิตรกับผู้ใช้ โดยพื้นฐานแล้วเราใช้สีเดียวกันสำหรับแบบอักษรและพื้นหลัง (ส่วนใหญ่ยังคงเป็นกรณีนี้เนื่องจากปัญหาโครงสร้างพื้นฐาน)
- รูปภาพและวิดีโอไม่ได้ถูกมองว่าเป็นส่วนหนึ่งของเนื้อหา
- ความตั้งใจของผู้ใช้และความตั้งใจในการค้นหาสำหรับคำหลักหนึ่งๆ ไม่เคยถูกมองว่ามีความสำคัญมาก่อน
- มีเนื้อหาที่ซ้ำกัน ไม่จำเป็น และซ้ำซากมากมายสำหรับหัวข้อเดียวกัน
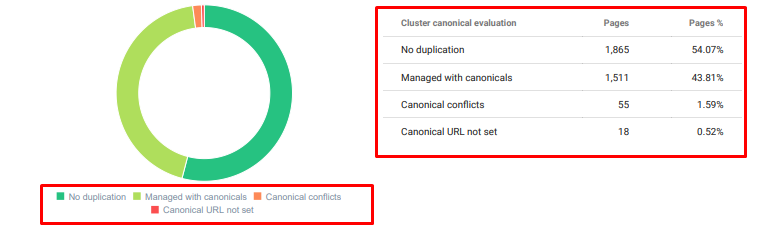
Oncrawl การตรวจสอบเนื้อหาที่ซ้ำกันตั้งแต่วันนี้
วิธีแก้ไข: โครงสร้างเนื้อหาที่ดีขึ้นสำหรับความน่าเชื่อถือของผู้ใช้
เมื่อตรวจสอบปัญหาทั่วทั้งไซต์ การใช้โปรแกรมตรวจสอบทั่วทั้งไซต์เป็นผู้ช่วยเป็นวิธีที่ดีกว่าในการจัดระเบียบเวลาที่ใช้ในโครงการ SEO เช่นเดียวกับในส่วนลิงก์ภายใน ฉันใช้ Oncrawl Site Audit ร่วมกับเครื่องมืออื่นๆ และการตรวจสอบ Xpath
ประการแรก การแก้ไขปัญหาในส่วนเนื้อหาทั้งหมดจะใช้เวลามากเกินไป ในวันวิกฤตที่พังทลายนั้น เวลาเป็นสิ่งฟุ่มเฟือย ดังนั้นฉันจึงตัดสินใจแก้ไขปัญหาการชนะอย่างรวดเร็ว เช่น:
- การลบเนื้อหาที่ซ้ำ ไม่จำเป็น และซ้ำซาก
- Unifying Short and Thin Content ขาดข้อมูลที่ครอบคลุม
- เผยแพร่ซ้ำเนื้อหาที่ไม่มีหัวเรื่องย่อยและโครงสร้างที่ติดตามได้
- แก้ไขโทนการตลาดแบบเร่งรัดในเนื้อหา
- การลบปุ่มเรียกร้องให้ดำเนินการออกจากเนื้อหา
- การสื่อสารด้วยภาพที่ดีขึ้นด้วยรูปภาพและวิดีโอ
- ทำให้เนื้อหาและคีย์เวิร์ดเป้าหมายเข้ากันได้กับผู้ใช้และความตั้งใจในการค้นหา
- การใช้และแสดงหน่วยงานทางการเงินและการศึกษาในเนื้อหาเพื่อความไว้วางใจ
- การใช้ชุมชนทางสังคมเพื่อสร้างหลักฐานทางสังคมของการอนุมัติ
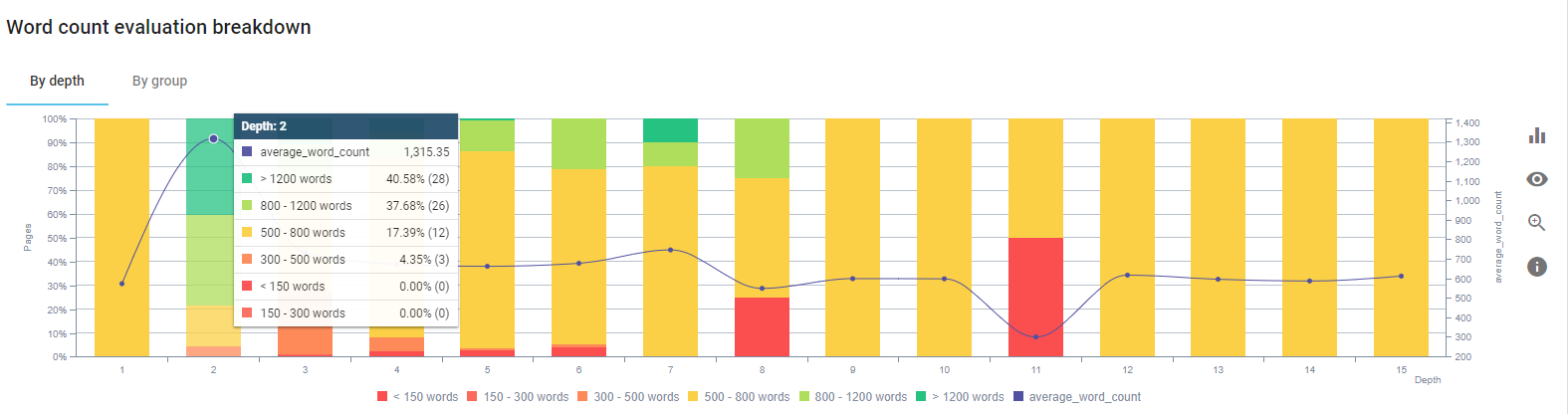

เรามุ่งเน้นที่การแก้ไขเนื้อหาของหน้าผลิตภัณฑ์และหน้าคำแนะนำที่ใกล้เคียงที่สุด
ในช่วงเริ่มต้นของกระบวนการนี้ ผลิตภัณฑ์ส่วนใหญ่และหน้า Landing Page/แนวทางการทำธุรกรรมของเรามีคำน้อยกว่า 500 คำโดยไม่มีข้อมูลที่ครอบคลุม
ใน 25 วัน การดำเนินการของเรามีดังนี้:
- ลบ 228 หน้าที่มีเนื้อหาซ้ำ ไม่จำเป็น และซ้ำซาก (โปรไฟล์ลิงก์ย้อนกลับของ Ccontent ได้รับการตรวจสอบก่อนดำเนินการลบ และเราใช้รหัสสถานะ 301 หรือ 410 เพื่อการสื่อสารที่ดียิ่งขึ้นกับ Googlebot)
- รวมกว่า 123 หน้า ขาดข้อมูลที่ครอบคลุม
- ใช้หัวข้อย่อยตามความสำคัญและความต้องการของผู้ใช้ในเนื้อหา
- ลบชื่อแบรนด์และปุ่ม CTA ด้วยภาษาสไตล์การตลาด
- รวมข้อความในภาพเพื่อเน้นหัวข้อหลัก
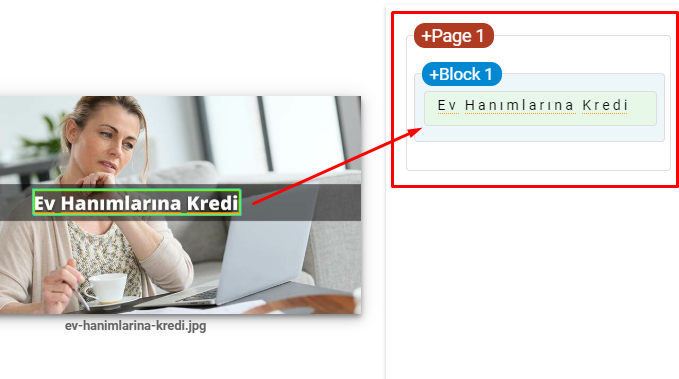
นี่คือภาพหน้าจอจาก Vision AI ของ Google Google สามารถอ่านข้อความในรูปภาพและตรวจจับความรู้สึกและตัวตนภายในหน่วยงานได้
- เปิดใช้งานเครือข่ายโซเชียลของเราเพื่อดึงดูดผู้ใช้มากขึ้น
- ตรวจสอบช่องว่างของเนื้อหาระหว่างคู่แข่งและเรา และสร้างเนื้อหาใหม่มากกว่า 80 ชิ้น
- ใช้ Google Analytics, Search Console และ Google Data Studio เพื่อระบุหน้าที่มีประสิทธิภาพต่ำซึ่งมีอัตราตีกลับสูงและปริมาณการใช้ข้อมูลต่ำ
- ได้ค้นคว้าข้อมูลโค้ดเด่นและคีย์เวิร์ดและโครงสร้างเนื้อหาแล้ว เราได้เพิ่มหัวเรื่องและโครงสร้างเนื้อหาเดียวกันลงในเนื้อหาที่เกี่ยวข้อง ซึ่งได้เพิ่มส่วนย่อยเด่นของเรา
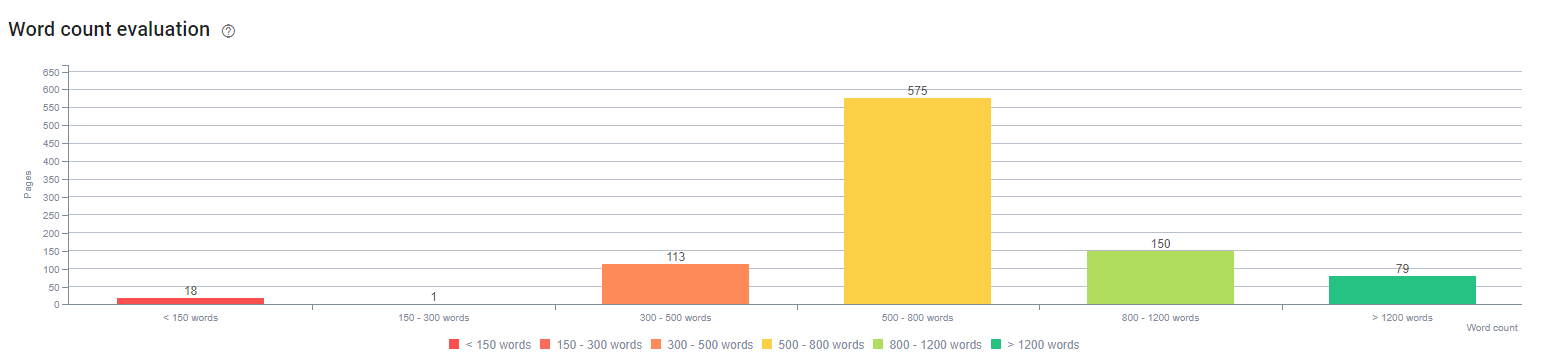
ในช่วงเริ่มต้นของกระบวนการนี้ เนื้อหาของเราจะประกอบด้วยคำส่วนใหญ่ระหว่าง 150 ถึง 300 คำ ความยาวเนื้อหาโดยเฉลี่ยของเราเพิ่มขึ้น 350 คำสำหรับทั้งไซต์
4. ปัญหา: ดัชนีมลพิษ บวม และ Canonical Tags
Google ไม่เคยออกแถลงการณ์เกี่ยวกับ Index Pollution และอันที่จริงฉันไม่แน่ใจว่ามีใครเคยใช้คำนี้เป็นคำ SEO มาก่อนหรือไม่ หน้าทั้งหมดที่ไม่เหมาะสมสำหรับ Google สำหรับคะแนนดัชนีที่มีประสิทธิภาพมากขึ้นควรลบออกจากหน้าดัชนีของ Google หน้าที่ก่อให้เกิดมลพิษต่อดัชนีคือหน้าที่ไม่ได้สร้างการเข้าชมเป็นเวลาหลายเดือน พวกเขามีศูนย์ CTR และศูนย์คำหลักทั่วไปเป็นศูนย์ ในกรณีที่มีคำหลักทั่วไปสองสามคำ พวกเขาจะต้องกลายเป็นคู่แข่งของหน้าอื่นๆ ในไซต์ของคุณสำหรับคำหลักเดียวกัน
นอกจากนี้ เราได้ทำการวิจัยเกี่ยวกับการขยายดัชนี และพบหน้าที่จัดทำดัชนีที่ไม่จำเป็นยิ่งขึ้นไปอีก หน้าเหล่านี้มีอยู่เนื่องจากโครงสร้างข้อมูลเว็บไซต์ผิดพลาด หรือเนื่องจากโครงสร้าง URL ที่ไม่ถูกต้อง
อีกสาเหตุหนึ่งของปัญหานี้คือการใช้แท็กบัญญัติอย่างไม่ถูกต้อง เป็นเวลานานกว่าสองปีแล้วที่แท็ก Canonical เป็นเพียงคำใบ้สำหรับ Googlebot หากใช้อย่างไม่ถูกต้อง Googlebot จะไม่คำนวณหรือให้ความสนใจขณะประเมินค่าไซต์ และสำหรับการคำนวณนี้ คุณอาจใช้งบประมาณการรวบรวมข้อมูลของคุณอย่างไม่มีประสิทธิภาพ เนื่องจากการใช้แท็กบัญญัติที่ไม่ถูกต้อง เราจึงมีหน้าความคิดเห็นมากกว่า 300 หน้าที่มีเนื้อหาที่ซ้ำกันได้รับการจัดทำดัชนี
ทฤษฎีของฉันมีจุดมุ่งหมายเพื่อแสดง Google เฉพาะหน้าเว็บที่มีคุณภาพและจำเป็นเท่านั้น ซึ่งมีโอกาสที่จะได้รับการคลิกและสร้างมูลค่าให้กับผู้ใช้
วิธีแก้ไข: แก้ไขดัชนีมลพิษและบวม
อันดับแรก ฉันรับคำแนะนำจาก John Mueller แห่ง Google ฉันถามเขาว่าฉันใช้แท็ก noindex สำหรับหน้าเหล่านี้หรือไม่ แต่ยังคงปล่อยให้ Googlebot ติดตาม "ฉันจะสูญเสียส่วนของลิงก์และประสิทธิภาพในการรวบรวมข้อมูลหรือไม่"
อย่างที่คุณเดาได้ เขาพูดใช่ในตอนแรก แต่จากนั้นเขาแนะนำว่าการใช้ลิงก์ภายในสามารถเอาชนะอุปสรรคนี้ได้
ฉันยังพบว่าการใช้แท็ก noindex ในเวลาเดียวกันกับ dofollow ลดอัตราการรวบรวมข้อมูลโดย Googlebot ในหน้าเหล่านี้ กลยุทธ์เหล่านี้ช่วยให้ Googlebot รวบรวมข้อมูลผลิตภัณฑ์และหน้าหลักเกณฑ์ที่สำคัญได้บ่อยขึ้น ฉันยังแก้ไขโครงสร้างลิงก์ภายในของฉันตามที่ John Mueller แนะนำ
ในเวลาอันสั้น:
- พบหน้าที่จัดทำดัชนีที่ไม่จำเป็น
- มากกว่า 300 หน้าถูกลบออกจากดัชนี
- แท็ก Noindex ถูกนำมาใช้
- โครงสร้างลิงก์ภายในได้รับการแก้ไขสำหรับเพจที่ได้รับลิงก์จากเพจที่ถูกลบออกจากดัชนี
- มีการตรวจสอบประสิทธิภาพและคุณภาพของการรวบรวมข้อมูลเมื่อเวลาผ่านไป
5. ปัญหา: รหัสสถานะไม่ถูกต้อง
ในตอนแรก ฉันสังเกตเห็นว่า Googlebot เข้าชมเนื้อหาที่ถูกลบไปจำนวนมากจากอดีต แม้แต่หน้าเมื่อแปดปีที่แล้วก็ยังถูกรวบรวมข้อมูล ทั้งนี้เนื่องมาจากการใช้รหัสสถานะที่ไม่ถูกต้องโดยเฉพาะอย่างยิ่งสำหรับเนื้อหาที่ถูกลบ
ฟังก์ชัน 404 และ 410 มีความแตกต่างกันอย่างมาก หนึ่งในนั้นมีไว้สำหรับหน้าข้อผิดพลาดที่ไม่มีเนื้อหาและอีกหน้าหนึ่งสำหรับเนื้อหาที่ถูกลบ นอกจากนี้ หน้าที่ถูกต้องยังอ้างอิง URL แหล่งที่มาและเนื้อหาที่ถูกลบจำนวนมาก รูปภาพที่ถูกลบบางส่วนและเนื้อหา CSS หรือ JS ยังถูกใช้บนหน้าที่เผยแพร่ที่ถูกต้องเป็นทรัพยากร สุดท้าย มีหน้า soft 404 จำนวนมาก และกลุ่มเปลี่ยนเส้นทางหลายสาย และ 302-307 เปลี่ยนเส้นทางชั่วคราวสำหรับหน้าที่เปลี่ยนเส้นทางอย่างถาวร
รหัสสถานะสำหรับเนื้อหาที่เปลี่ยนเส้นทางวันนี้
วิธีแก้ไข: แก้ไขรหัสสถานะไม่ถูกต้อง
- ทุกรหัสสถานะ 404 จะถูกแปลงเป็นรหัสสถานะ 410 (มากกว่า 30000)
- ทรัพยากรทุกรายการที่มีรหัสสถานะ 404 ถูกแทนที่ด้วยทรัพยากรใหม่ที่ถูกต้อง (มากกว่า 500)
- การเปลี่ยนเส้นทาง 302-307 ทุกครั้งจะถูกแปลงเป็นการเปลี่ยนเส้นทางถาวร 301 (มากกว่า 1500)
- โซ่เปลี่ยนเส้นทางถูกลบออกจากสินทรัพย์ที่ใช้งาน
- ทุกเดือน เราได้รับ Hit มากกว่า 25,000 ครั้งในหน้าและทรัพยากรที่มีรหัสสถานะ 404 ในการวิเคราะห์บันทึกของเรา ตอนนี้ น้อยกว่า 50 สำหรับรหัสสถานะ 404 ต่อเดือน และไม่มีการฮิตสำหรับรหัสสถานะ 410...
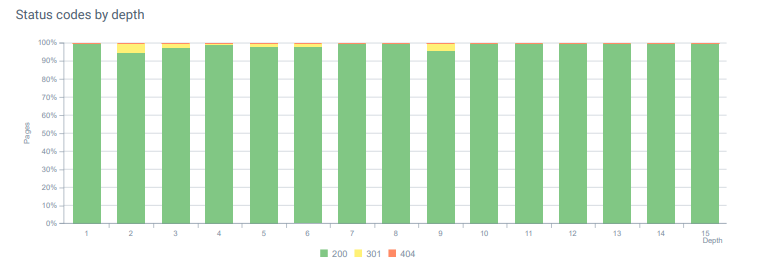
รหัสสถานะตลอดความลึกของหน้าวันนี้
6. ปัญหา: HTML เชิงความหมาย
ความหมายหมายถึงสิ่งที่หมายถึง HTML เชิงความหมายมีแท็กที่ให้ความหมายสำหรับองค์ประกอบของหน้าภายในลำดับชั้น ด้วยโครงสร้างรหัสแบบลำดับชั้นนี้ คุณสามารถบอก Google ว่าจุดประสงค์ของส่วนหนึ่งของเนื้อหาคืออะไร นอกจากนี้ ในกรณีที่ Googlebot ไม่สามารถรวบรวมข้อมูลทุกทรัพยากรที่จำเป็นในการแสดงผลหน้าเว็บของคุณโดยสมบูรณ์ อย่างน้อย คุณสามารถระบุการจัดวางหน้าเว็บของคุณและฟังก์ชันของส่วนเนื้อหาให้กับ Googlebot ได้
บน Hangikredi.com หลังจากอัปเดตอัลกอริทึมหลักของ Google ในวันที่ 12 มีนาคม ฉันรู้ว่ามีงบประมาณการรวบรวมข้อมูลไม่เพียงพอเนื่องจากโครงสร้างเว็บไซต์ที่ไม่เหมาะสม ดังนั้น เพื่อให้ Googlebot เข้าใจจุดมุ่งหมาย ฟังก์ชัน เนื้อหา และประโยชน์ของหน้าเว็บได้ง่ายขึ้น ฉันจึงตัดสินใจใช้ Semantic HTML
วิธีแก้ไข: การใช้ HTML เชิงความหมาย
ตามหลักเกณฑ์ผู้ประเมินคุณภาพของ Google ผู้ค้นหาทุกคนมีเจตนาและทุกหน้าเว็บมีฟังก์ชันตามเจตนานั้น เพื่อพิสูจน์ฟังก์ชันเหล่านี้ต่อ Googlebot เราได้ทำการปรับปรุงโครงสร้าง HTML ของเราสำหรับบางหน้าที่ Googlebot รวบรวมข้อมูลน้อยกว่า
- ใช้แท็ก <main> สำหรับแสดงเนื้อหาหลักและหน้าที่ของหน้า
- ใช้ <nav> สำหรับส่วนการนำทาง
- ใช้ <footer> สำหรับส่วนท้ายของไซต์
- ใช้ <article> สำหรับบทความ
- ใช้แท็ก <section> สำหรับทุกแท็กหัวเรื่อง
- ใช้แท็ก <picture>, <table>, <citation> สำหรับรูปภาพ ตาราง และเครื่องหมายคำพูดในเนื้อหา
- ใช้แล้ว <aside> แท็กสำหรับเนื้อหาเสริม
- แก้ไขปัญหาลำดับชั้นของ H1-H6 (แม้ว่าคำสั่ง "ใช้ H1 สองตัวไม่ใช่ปัญหา" ล่าสุดของ Google โดยใช้โครงสร้างที่ถูกต้องก็ช่วย Googlebot ได้)
- เช่นเดียวกับในส่วนโครงสร้างเนื้อหา เรายังใช้ HTML เชิงความหมายสำหรับตัวอย่างข้อมูลแนะนำ เราใช้ตารางและรายการสำหรับผลลัพธ์ตัวอย่างข้อมูลแนะนำเพิ่มเติม

สำหรับเรา นี่ไม่ใช่การพัฒนาที่นำไปปฏิบัติได้จริงสำหรับทั้งไซต์ ยังคงใช้แท็ก HTML เชิงความหมายสำหรับหน้าเว็บเพิ่มเติมในการอัปเดตการออกแบบทุกครั้ง
7. ปัญหา: การใช้ข้อมูลที่มีโครงสร้าง
เช่นเดียวกับการใช้ HTML เชิงความหมาย ข้อมูลที่มีโครงสร้างอาจใช้เพื่อแสดงฟังก์ชันและคำจำกัดความของส่วนต่างๆ ของหน้าเว็บต่อ Googlebot นอกจากนี้ ข้อมูลที่มีโครงสร้างยังเป็นสิ่งจำเป็นสำหรับผลลัพธ์ที่เป็นสื่อสมบูรณ์ บนเว็บไซต์ของเรา ไม่มีการใช้ข้อมูลที่มีโครงสร้าง หรือโดยปกติมีการใช้อย่างไม่ถูกต้องจนถึงสิ้นเดือนมีนาคม เพื่อสร้างความสัมพันธ์ที่ดียิ่งขึ้นกับเอนทิตีบนเว็บไซต์ของเราและบัญชีนอกเพจ เราจึงเริ่มใช้ข้อมูลที่มีโครงสร้าง
วิธีแก้ไข: การใช้ข้อมูลที่มีโครงสร้างที่ถูกต้องและทดสอบแล้ว
สำหรับสถาบันการเงินและเว็บไซต์ YMYL ข้อมูลที่มีโครงสร้างสามารถแก้ไขปัญหาได้มากมาย ตัวอย่างเช่น พวกเขาสามารถแสดงเอกลักษณ์ของแบรนด์ ประเภทของเนื้อหา และสร้างมุมมองตัวอย่างที่ดีขึ้น เราใช้ประเภทข้อมูลที่มีโครงสร้างต่อไปนี้สำหรับหน้าทั่วเว็บไซต์และแต่ละหน้า:
- คำถามที่พบบ่อย ข้อมูลที่มีโครงสร้างสำหรับหน้าผลิตภัณฑ์หลัก
- ข้อมูลที่มีโครงสร้างของหน้าเว็บ
- ข้อมูลโครงสร้างองค์กร
- ข้อมูลที่มีโครงสร้างเบรดครัมบ์
8. การเพิ่มประสิทธิภาพแผนผังเว็บไซต์และ Robots.txt
บน Hangikredi.com ไม่มี Dynamic Sitemap แผนผังเว็บไซต์ที่มีอยู่ในขณะนั้นไม่ได้รวมหน้าที่จำเป็นทั้งหมดและยังรวมเนื้อหาที่ถูกลบด้วย นอกจากนี้ ในไฟล์ Robots.txt หน้าอ้างอิงของ Affiliate บางหน้าที่มีลิงก์ภายนอกหลายพันลิงก์ไม่อนุญาต รวมถึงไฟล์ JS ของบุคคลที่สามบางไฟล์ที่ไม่เกี่ยวข้องกับเนื้อหาและทรัพยากรเพิ่มเติมอื่นๆ ที่ไม่จำเป็นสำหรับ Googlebot
มีการใช้ขั้นตอนต่อไปนี้:
- สร้าง sitemap_index.xml สำหรับแผนผังเว็บไซต์หลายรายการซึ่งสร้างขึ้นตามหมวดหมู่เว็บไซต์เพื่อให้มีสัญญาณการรวบรวมข้อมูลที่ดีขึ้นและการตรวจสอบความครอบคลุมที่ดีขึ้น
- ไฟล์ JS ของบริษัทอื่นบางไฟล์และไฟล์ JS ที่ไม่จำเป็นบางไฟล์ไม่ได้รับอนุญาตในไฟล์ robots.txt
- เพจในเครือที่มีลิงก์ภายนอกและไม่มีค่าหน้า Landing Page ไม่ได้รับอนุญาต ดังที่เรากล่าวถึงในส่วนของ Pagerank หรือ Internal Link Sculpting
- แก้ไขปัญหาความคุ้มครองมากกว่า 500 รายการ (ส่วนใหญ่เป็นหน้าที่จัดทำดัชนีแม้ว่าจะไม่ได้รับอนุญาตจาก Robots.txt)
คุณสามารถดูอัตราการรวบรวมข้อมูล โหลดและความต้องการของเราเพิ่มขึ้นจากแผนภูมิด้านล่าง:
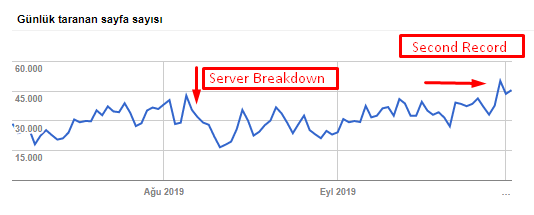
จำนวนหน้าที่รวบรวมข้อมูลต่อวันโดย Googlebot มีการเพิ่มขึ้นอย่างต่อเนื่องในหน้าที่รวบรวมข้อมูลต่อวันจนถึง 1 สิงหาคม หลังจากการโจมตีทำให้เซิร์ฟเวอร์ล้มเหลวในต้นเดือนสิงหาคม เซิร์ฟเวอร์ก็กลับมามีเสถียรภาพอีกครั้งในระยะเวลาหนึ่งเดือนกว่าๆ

การโหลดที่รวบรวมข้อมูลต่อวันโดย Googlebot มีการพัฒนาควบคู่ไปกับจำนวนหน้าที่รวบรวมข้อมูลต่อวัน
9. แก้ไขปัญหาแอมป์
บนเว็บไซต์ของบริษัท หน้าบล็อกทุกหน้ามีเวอร์ชัน AMP เนื่องจากการใช้โค้ดไม่ถูกต้องและไม่มี Canonical ของ AMP หน้า AMP ทั้งหมดจึงถูกลบออกจากดัชนีซ้ำแล้วซ้ำเล่า สิ่งนี้สร้างคะแนนดัชนีที่ไม่เสถียรและขาดความน่าเชื่อถือสำหรับเว็บไซต์ นอกจากนี้ หน้า AMP ยังมีคำศัพท์และคำภาษาอังกฤษโดยค่าเริ่มต้นในเนื้อหาภาษาตุรกี
- แท็ก Canonical ได้รับการแก้ไขแล้วสำหรับหน้า AMP มากกว่า 400 หน้า
- พบการใช้งานโค้ดที่ไม่ถูกต้องและแก้ไข (สาเหตุหลักมาจากการใช้งานแท็ก AMP-Analytics และ AMP-Canonical ที่ไม่ถูกต้อง)
- คำศัพท์ภาษาอังกฤษโดยค่าเริ่มต้นได้รับการแปลเป็นภาษาตุรกี
- ความมั่นคงของดัชนีและการจัดอันดับถูกสร้างขึ้นสำหรับด้านบล็อกของเว็บไซต์ของบริษัท
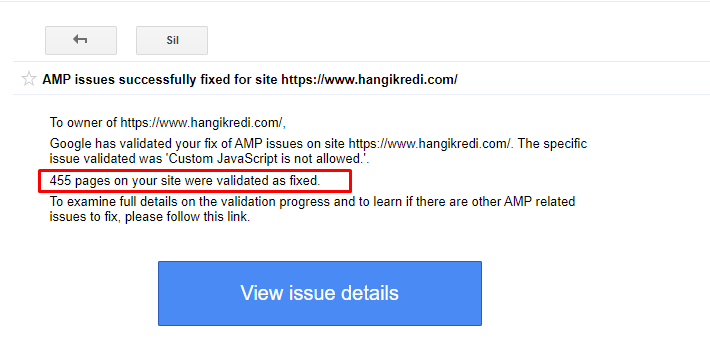
ตัวอย่างข้อความใน GSC เกี่ยวกับการปรับปรุง AMP
10. ปัญหาและแนวทางแก้ไขเมตาแท็ก
เนื่องจากปัญหางบประมาณในการรวบรวมข้อมูล บางครั้งในคำค้นหาที่สำคัญสำหรับหน้าผลิตภัณฑ์หลักที่สำคัญ Google ไม่ได้จัดทำดัชนีหรือแสดงเนื้อหาในเมตาแท็ก แทนที่จะเป็นชื่อเมตา รายการ SERP แสดงเฉพาะชื่อบริษัทที่สร้างจากคำสองคำเท่านั้น ไม่มีการแสดงคำอธิบายตัวอย่าง.. ซึ่งเป็นการลด CTR ของเราและส่งผลเสียต่อเอกลักษณ์ของแบรนด์ของเรา เราแก้ไขปัญหานี้โดยการย้ายเมตาแท็กไปที่ด้านบนของซอร์สโค้ดดังที่แสดงด้านล่าง
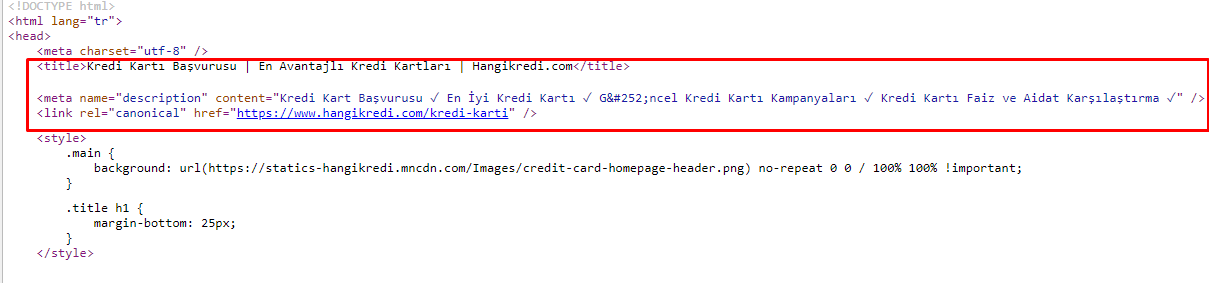
นอกจากงบประมาณในการรวบรวมข้อมูลแล้ว เรายังเพิ่มประสิทธิภาพเมตาแท็กมากกว่า 600 รายการสำหรับหน้าธุรกรรมและข้อมูล:
- ความยาวอักขระที่ปรับให้เหมาะสมสำหรับอุปกรณ์มือถือ
- ใช้คำหลักมากขึ้นในชื่อ
- ใช้เมตาแท็กรูปแบบต่างๆ และตรวจสอบ CTR ช่องว่างของคำหลัก และการเปลี่ยนแปลงอันดับ
- สร้างหน้าเว็บมากขึ้นด้วยโครงสร้างแผนผังไซต์ที่ถูกต้องสำหรับการกำหนดเป้าหมายคำหลักรองได้ดีขึ้นด้วยกระบวนการเพิ่มประสิทธิภาพเหล่านี้
- บนไซต์ของเรา เรายังคงมีชื่อ meta คำอธิบายและหัวข้อที่แตกต่างกันสำหรับการทดสอบอัลกอริทึมของ Google และ CTR ผู้ใช้ค้นหา
11. ปัญหาและแนวทางแก้ไขประสิทธิภาพของภาพ
ปัญหาเกี่ยวกับภาพสามารถแบ่งออกได้เป็น 2 ประเภท เพื่อความสะดวกของเนื้อหาและเพื่อความเร็วของหน้า สำหรับทั้งคู่ เว็บไซต์ของบริษัทยังมีสิ่งที่ต้องทำอีกมาก
ในเดือนมีนาคมและเมษายนหลังการอัปเดต Core Algorithm Update ในวันที่ 12 มีนาคม:
- รูปภาพไม่มีแท็ก alt หรือมีแท็ก alt ที่ไม่ถูกต้อง
- พวกเขาไม่มีชื่อ
- พวกเขาไม่มีโครงสร้าง URL ที่ถูกต้อง
- พวกเขาไม่มีส่วนขยายรุ่นต่อไป
- พวกเขาไม่ได้ถูกบีบอัด
- ไม่มีความละเอียดที่เหมาะสมสำหรับทุกขนาดหน้าจอของอุปกรณ์
- พวกเขาไม่มีคำบรรยาย
เพื่อเตรียมพร้อมสำหรับการอัปเดต Google Core Algorithm ครั้งต่อไป:
- รูปภาพถูกบีบอัด
- ส่วนขยายของพวกเขามีการเปลี่ยนแปลงบางส่วน
- แท็ก Alt ถูกเขียนขึ้นสำหรับพวกเขาส่วนใหญ่
- ชื่อและคำอธิบายภาพได้รับการแก้ไขสำหรับผู้ใช้
- โครงสร้าง URL ได้รับการแก้ไขบางส่วนสำหรับผู้ใช้
- เราพบรูปภาพที่ไม่ได้ใช้ซึ่งยังคงโหลดโดยเบราว์เซอร์และลบออกจากระบบ
เนื่องจากโครงสร้างพื้นฐานของไซต์ เราจึงใช้การแก้ไข SEO ของรูปภาพบางส่วน
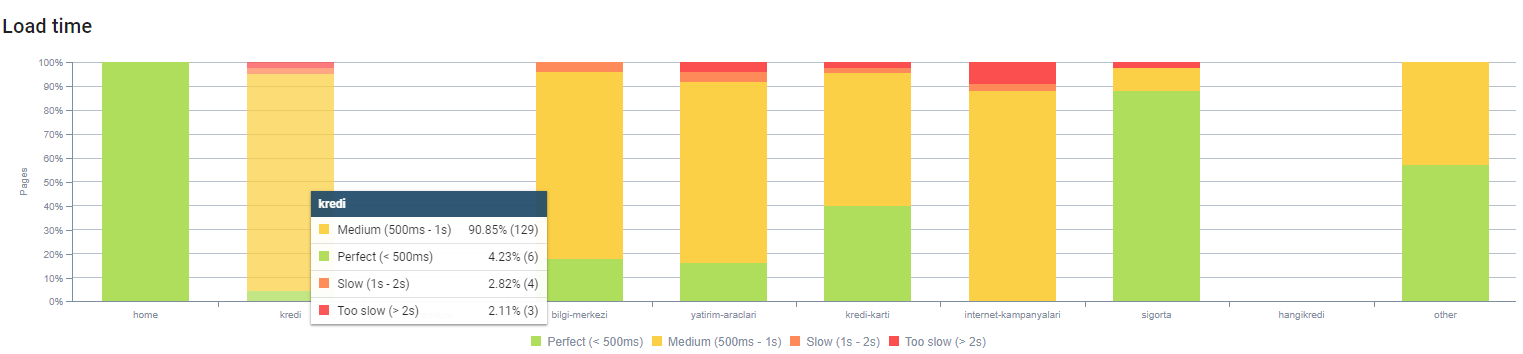
คุณสามารถสังเกตเวลาในการโหลดหน้าเว็บของเราตามความลึกของหน้าด้านบน อย่างที่คุณเห็น หน้าผลิตภัณฑ์ส่วนใหญ่ยังคงหนักอยู่
12. แคช ดึงข้อมูลล่วงหน้า และโหลดล่วงหน้าปัญหาและวิธีแก้ไข
ก่อนการอัปเดตอัลกอริธึมคอร์ 12 มีนาคม มีระบบแคชหลวมบนเว็บไซต์ของบริษัท เนื้อหาบางส่วนอยู่ในแคช แต่บางส่วนไม่ได้อยู่ในแคช นี่เป็นปัญหาโดยเฉพาะอย่างยิ่งสำหรับหน้าผลิตภัณฑ์เนื่องจากช้ากว่าหน้าผลิตภัณฑ์ของคู่แข่งถึง 2 เท่า ส่วนประกอบส่วนใหญ่ของหน้าเว็บของเราเป็นแหล่งที่มาแบบคงที่จริงๆ แต่ก็ยังไม่มี Etags สำหรับระบุช่วงแคช
เพื่อเตรียมพร้อมสำหรับการอัปเดต Google Core Algorithm ครั้งต่อไป:
- เราแคชส่วนประกอบบางอย่างสำหรับหน้าเว็บทุกหน้าและทำให้เป็นแบบคงที่
- หน้าเหล่านี้เป็นหน้าผลิตภัณฑ์ที่สำคัญ
- เรายังไม่ได้ใช้ E-Tag เนื่องจากโครงสร้างพื้นฐานของไซต์
- โดยเฉพาะอย่างยิ่งรูปภาพ ทรัพยากรแบบคงที่ และส่วนเนื้อหาที่สำคัญบางส่วนได้รับการแคชทั่วทั้งไซต์แล้ว
- เราได้เริ่มใช้โค้ด dns-prefetch สำหรับทรัพยากรเอาต์ซอร์ซที่ถูกลืมไปแล้วบางส่วน
- เรายังไม่ได้ใช้โค้ดโหลดล่วงหน้า แต่เรากำลังดำเนินการเกี่ยวกับการเดินทางของผู้ใช้บนไซต์เพื่อนำไปใช้ในอนาคต
13. การเพิ่มประสิทธิภาพและย่อขนาด HTML, CSS และ JS
เนื่องจากปัญหาด้านโครงสร้างพื้นฐานของไซต์ จึงไม่มีอะไรให้ทำมากมายสำหรับความเร็วของไซต์ ฉันพยายามปิดช่องว่างด้วยทุกวิธีที่ทำได้ รวมถึงการลบองค์ประกอบของหน้าบางส่วน สำหรับหน้าผลิตภัณฑ์ที่สำคัญ เราได้ทำความสะอาดโครงสร้างโค้ด HTML ย่อขนาดและบีบอัด
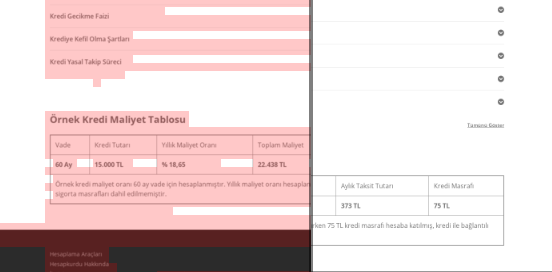
ภาพหน้าจอจากซอร์สโค้ดของหน้าผลิตภัณฑ์ตามฤดูกาลแต่มีความสำคัญ การใช้ข้อมูลที่มีโครงสร้างคำถามที่พบบ่อย, การลดขนาด HTML, การเพิ่มประสิทธิภาพรูปภาพ, การรีเฟรชเนื้อหา และการเชื่อมโยงภายในทำให้เรามีอันดับที่หนึ่งในเวลาที่เหมาะสม (คำสำคัญคือ “Bayram Kredisi” ในภาษาตุรกี แปลว่า “เครดิตวันหยุด”)
นอกจากนี้เรายังใช้ CSS Factoring, Refactoring และ JS Compression บางส่วนด้วยขั้นตอนเล็กๆ เมื่ออันดับลดลง เราได้ตรวจสอบช่องว่างความเร็วไซต์ระหว่างเพจของคู่แข่งกับเพจของเรา เราได้เลือกหน้าด่วนบางหน้าซึ่งเราสามารถเร่งความเร็วได้ นอกจากนี้ เรายังทำให้ไฟล์ CSS ที่สำคัญบริสุทธิ์และบีบอัดบางส่วนในหน้าเหล่านี้ เราเริ่มกระบวนการลบไฟล์ JS ของบุคคลที่สามบางไฟล์ที่ใช้โดยแผนกต่างๆ ของบริษัท แต่ยังไม่ได้ลบออก สำหรับหน้าผลิตภัณฑ์บางหน้า เรายังสามารถเปลี่ยนลำดับการโหลดทรัพยากรได้อีกด้วย
สอบผู้เข้าแข่งขัน
นอกเหนือจากการปรับปรุงทางเทคนิค SEO ทุกครั้ง การตรวจสอบคู่แข่งยังเป็นแนวทางที่ดีที่สุดของฉันในการทำความเข้าใจลักษณะและจุดมุ่งหมายของ Core Algorithm Update ฉันได้ใช้โปรแกรมที่มีประโยชน์และเป็นประโยชน์เพื่อติดตามการเปลี่ยนแปลงการออกแบบ เนื้อหา อันดับ และเทคโนโลยีของคู่แข่ง
- สำหรับการเปลี่ยนแปลงอันดับคำหลัก ฉันใช้ Wincher, Semrush และ Ahrefs
- สำหรับการกล่าวถึงแบรนด์ ฉันใช้ Google Alerts, BuzzSumo, Talkwalker
- สำหรับลิงก์ใหม่และรายงานการเพิ่มคำหลัก ฉันใช้ Ahrefs Alert
- สำหรับการเปลี่ยนแปลงเนื้อหาและการออกแบบ ฉันใช้ Visualping
- สำหรับการเปลี่ยนแปลงทางเทคโนโลยี ฉันใช้ SimilarTech
- สำหรับข่าวสารและการตรวจสอบของ Google Update ฉันใช้ Semrush Sensor, Algoroo และ CognitiveSEO Signals เป็นหลัก
- ในการตรวจสอบประวัติ URL ของคู่แข่ง ฉันใช้ Wayback Machine
- สำหรับความเร็วของเซิร์ฟเวอร์ของคู่แข่ง ฉันใช้ Chrome DevTools และ ByteCheck
- สำหรับค่าใช้จ่ายในการรวบรวมข้อมูลและการแสดงผล ฉันใช้ "ค่าใช้จ่ายไซต์ของฉันเท่าไหร่" (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.