
พยากรณ์ปริมาณการใช้ SEO ด้วย Prophet และ Python
เผยแพร่แล้ว: 2021-03-16การตั้งเป้าหมายและการประเมินความสำเร็จเมื่อเวลาผ่านไปเป็นแบบฝึกหัดที่น่าสนใจมาก เพื่อให้เข้าใจว่าเราสามารถทำอะไรได้บ้าง และกลยุทธ์ที่เราใช้ได้ผลหรือไม่ อย่างไรก็ตาม การกำหนดเป้าหมายเหล่านี้มักไม่ง่ายนัก เนื่องจากเราจะต้องคาดการณ์ล่วงหน้า
การสร้างการคาดการณ์ไม่ใช่เรื่องง่าย แต่ต้องขอบคุณขั้นตอนการคาดการณ์ที่มีอยู่ CPU ของเราและทักษะการเขียนโปรแกรมบางอย่าง เราสามารถลดความซับซ้อนได้ค่อนข้างมาก ในโพสต์นี้ ฉันจะแสดงให้คุณเห็นว่าเราสามารถคาดการณ์ได้อย่างแม่นยำได้อย่างไร และคุณจะนำไปใช้กับ SEO ได้อย่างไรโดยใช้ Python และ Library Prophet โดยไม่ต้องมีพลังพิเศษของหมอดู
หากคุณไม่เคยได้ยินเกี่ยวกับศาสดา คุณอาจสงสัยว่ามันคืออะไร กล่าวโดยย่อ ศาสดาเป็นขั้นตอนสำหรับการคาดการณ์ซึ่งเผยแพร่โดยทีม Core Data Science ของ Facebook ซึ่งมีอยู่ใน Python และ R และเกี่ยวข้องกับค่าผิดปกติและเอฟเฟกต์ตามฤดูกาลได้เป็นอย่างดี
ให้การคาดการณ์ที่แม่นยำและรวดเร็ว
เมื่อเราพูดถึงการคาดการณ์ เราต้องคำนึงถึงสองสิ่ง:
- ยิ่งเรามีข้อมูลในอดีตมากเท่าไร แบบจำลองของเราก็จะยิ่งแม่นยำมากขึ้นเท่านั้น ดังนั้นการคาดการณ์ของเราก็จะยิ่งแม่นยำมากขึ้นเท่านั้น
- แบบจำลองการคาดการณ์จะมีผลก็ต่อเมื่อปัจจัยภายในยังคงเหมือนเดิมและไม่มีปัจจัยภายนอกที่ส่งผลต่อรูปแบบดังกล่าว ซึ่งหมายความว่า ตัวอย่างเช่น หากเราเผยแพร่หนึ่งโพสต์ต่อสัปดาห์ และเราเริ่มเผยแพร่สองโพสต์ต่อสัปดาห์ โมเดลนี้อาจไม่ถูกต้องในการทำนายว่าผลลัพธ์จากการเปลี่ยนแปลงกลยุทธ์นี้จะเป็นอย่างไร ในทางกลับกัน หากมีการอัพเดตอัลกอริธึม โมเดลก็อาจไม่ถูกต้องเช่นกัน โปรดทราบว่าแบบจำลองนี้สร้างขึ้นจากข้อมูลในอดีต
เพื่อนำไปใช้กับ SEO สิ่งที่เราจะทำคือคาดการณ์เซสชัน SEO สำหรับเดือนที่จะมาถึงตามขั้นตอนต่อไป:
- รับข้อมูลจาก Google Analytics เกี่ยวกับเซสชันทั่วไปในช่วงเวลาหนึ่ง
- การฝึกโมเดลของเรา
- การพยากรณ์การเข้าชม SEO ในเดือนหน้า
- การประเมินว่าแบบจำลองของเราดีเพียงใดด้วยค่าคลาดเคลื่อนสัมบูรณ์เฉลี่ย
คุณต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับวิธีการทำงานของขั้นตอนการคาดการณ์นี้หรือไม่? มาเริ่มกันเลยดีกว่า!
รับข้อมูลจาก Google Analytics
เราสามารถเข้าถึงการแยกข้อมูลจาก Google Analytics ได้สองวิธี: การส่งออกไฟล์ Excel จากอินเทอร์เฟซปกติหรือการใช้ API เพื่อดึงข้อมูลนี้
การนำเข้าข้อมูลจากไฟล์ Excel
วิธีที่ง่ายที่สุดในการรับข้อมูลนี้จาก Google Analytics คือไปที่ส่วนช่องที่แถบด้านข้าง คลิกออร์แกนิกและส่งออกข้อมูลด้วยปุ่มที่อยู่ด้านบนของหน้า ตรวจสอบให้แน่ใจว่าคุณได้เลือกตัวแปรที่คุณต้องการวิเคราะห์ในเมนูดรอปดาวน์ที่ด้านบนของกราฟ ในกรณีนี้คือเซสชัน
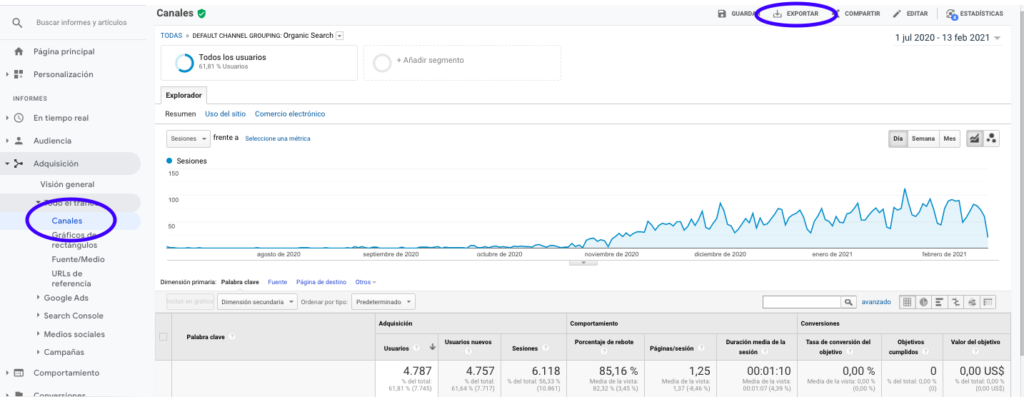
หลังจากส่งออกข้อมูลเป็นไฟล์ Excel แล้ว เราสามารถนำเข้าไปยังสมุดบันทึกของเราด้วย Pandas โปรดทราบว่าไฟล์ Excel ที่มีข้อมูลดังกล่าวจะมีแท็บต่างกัน ดังนั้นจึงต้องระบุแท็บที่มีการรับส่งข้อมูลรายเดือนเป็นอาร์กิวเมนต์ในส่วนของโค้ดที่อยู่ด้านล่าง นอกจากนี้เรายังลบแถวสุดท้ายเนื่องจากมีจำนวนเซสชันทั้งหมด ซึ่งจะทำให้แบบจำลองของเราบิดเบี้ยว
นำเข้าแพนด้าเป็น pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(เลน(df) - 1)
เราสามารถวาดด้วย Matplotlib ว่าข้อมูลมีลักษณะอย่างไร:
จาก matplotlib นำเข้า pyplot
df["เซสชัน"].plot(ชื่อ = "เซสชัน")
pyplot.show() 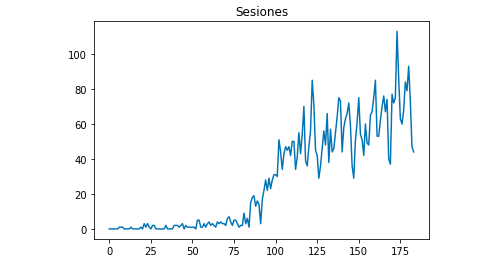
การใช้ Google Analytics API
ก่อนอื่น เพื่อใช้งาน Google Analytics API เราจำเป็นต้องสร้างโครงการบนคอนโซลนักพัฒนาซอฟต์แวร์ของ Google เปิดใช้งานบริการรายงานของ Google Analytics และรับข้อมูลประจำตัว Jean-Christophe Chouinard อธิบายวิธีตั้งค่านี้เป็นอย่างดีในบทความนี้
เมื่อได้รับข้อมูลประจำตัวแล้ว เราจำเป็นต้องตรวจสอบสิทธิ์ก่อนส่งคำขอ การตรวจสอบสิทธิ์ต้องทำด้วยไฟล์ข้อมูลรับรองที่ได้รับในขั้นต้นจากคอนโซลนักพัฒนาซอฟต์แวร์ของ Google เราจะต้องจดรหัส GA View จากพร็อพเพอร์ตี้ที่เราต้องการใช้ลงในโค้ดของเรา
จาก apiclient.discovery อิมพอร์ตบิวด์
จาก oauth2client.service_account นำเข้า ServiceAccountCredentials
ขอบเขต = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
ดู_
หนังสือรับรอง = ServiceAccountCredentials.from_json_keyfile_name (KEY_FILE_LOCATION, ขอบเขต)
การวิเคราะห์ = บิลด์ ('analyticsreporting', 'v4', credentials=credentials)หลังจากตรวจสอบสิทธิ์แล้ว เราต้องส่งคำขอ สิ่งที่เราต้องใช้เพื่อรับข้อมูลเกี่ยวกับเซสชันออร์แกนิกในแต่ละวันคือ:
ตอบกลับ = analytics.reports().batchGet(body={
'คำขอรายงาน': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'เมตริก': [
{"นิพจน์": "ga:เซสชัน"}
], "ขนาด": [
{"name": "ga:date"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "จริง"
}]}).execute()โปรดทราบว่าเราเลือกช่วงเวลาใน dateRange ในกรณีของฉัน ฉันจะดึงข้อมูลตั้งแต่วันที่ 1 กันยายนถึง 31 มกราคม: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
หลังจากนี้ เราเพียงดึงไฟล์ตอบกลับเพื่อผนวกเข้ากับรายการวันด้วยเซสชันแบบออร์แกนิก:
list_values = [] สำหรับ x ในการตอบกลับ["reports"][0]["data"]["rows"]: list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])
อย่างที่คุณเห็น การใช้ Google Analytics API นั้นค่อนข้างง่ายและใช้ได้กับวัตถุประสงค์หลายอย่าง ในบทความนี้ ฉันได้อธิบายวิธีที่คุณสามารถใช้ Google Analytics API เพื่อสร้างการแจ้งเตือนเพื่อตรวจหาหน้าที่มีประสิทธิภาพต่ำ

การปรับรายการเป็น Dataframes
เพื่อใช้ประโยชน์จากพระศาสดา เราจำเป็นต้องใส่ Dataframe ที่มีสองคอลัมน์ที่ต้องตั้งชื่อ: “ds” และ “y” หากคุณนำเข้าข้อมูลจากไฟล์ Excel เราก็มีข้อมูลดังกล่าวเป็น Dataframe ดังนั้นคุณจะต้องตั้งชื่อคอลัมน์ว่า "ds" และ "y" เท่านั้น:
df.columns = ['ds', 'y']
ในกรณีที่คุณใช้ API เพื่อดึงข้อมูล เราจำเป็นต้องแปลงรายการเป็น dataframe และตั้งชื่อคอลัมน์ตามต้องการ:
จากแพนด้านำเข้า DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
ฝึกโมเดล
เมื่อเรามี Dataframe ที่มีรูปแบบที่ต้องการแล้ว เราสามารถกำหนดและฝึกโมเดลของเราได้อย่างง่ายดายด้วย:
นำเข้า fbprophet จาก fbprophet นำเข้าศาสดา รุ่น = ศาสดา () รุ่น fit(df_sessions)
การทำนายของเรา
ในที่สุด หลังจากฝึกโมเดลของเรา เราก็สามารถเริ่มต้นคาดการณ์ได้! เพื่อดำเนินการคาดการณ์ เราจะต้องสร้างรายการที่มีช่วงเวลาที่เราต้องการคาดการณ์และปรับรูปแบบวันที่และเวลาก่อน:
จากแพนด้านำเข้า to_datetime พยากรณ์_วัน = [] สำหรับ x ในช่วง (1, 28): วันที่ = "2021-02-" + str(x) พยากรณ์_days.append([วันที่]) พยากรณ์_วัน = DataFrame(พยากรณ์_วัน) พยากรณ์_days.columns = ['ds'] พยากรณ์_วัน['ds']= to_datetime(พยากรณ์_วัน['ds'])
ในตัวอย่างนี้ ฉันใช้การวนซ้ำซึ่งจะสร้าง dataframe ที่จะบรรจุวันทั้งหมดตั้งแต่เดือนกุมภาพันธ์ และตอนนี้ก็เป็นเพียงเรื่องของการใช้โมเดลที่ฝึกมาก่อนหน้านี้:
พยากรณ์ = model.predict(forecast_days)
เราสามารถวาดโครงเรื่องที่เน้นช่วงเวลาที่คาดการณ์ไว้ได้:
จาก matplotlib นำเข้า pyplot model.plot(พยากรณ์) pyplot.show()
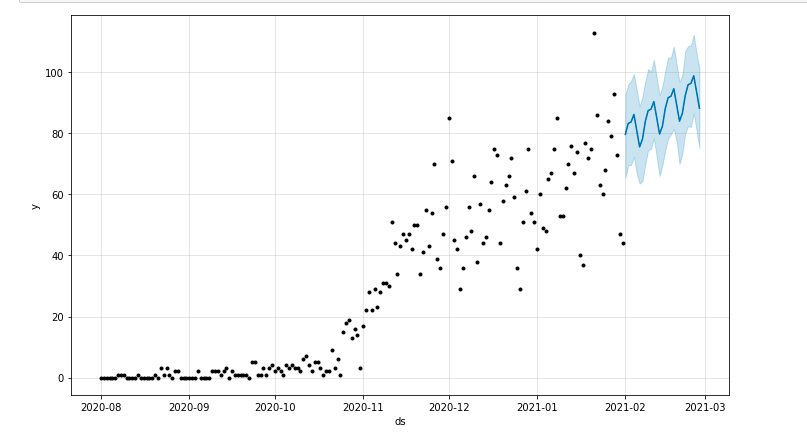
การประเมินแบบจำลอง
สุดท้าย เราสามารถประเมินว่าแบบจำลองของเรามีความแม่นยำเพียงใด โดยกำจัดข้อมูลบางวันจากข้อมูลที่ใช้ในการฝึกแบบจำลอง คาดการณ์เซสชันสำหรับวันเหล่านั้น และคำนวณค่าคลาดเคลื่อนสัมบูรณ์เฉลี่ย
ตัวอย่างเช่น สิ่งที่ฉันจะทำคือลบออกจาก dataframe เดิมในช่วง 12 วันที่ผ่านมาตั้งแต่เดือนมกราคม คาดการณ์เซสชันในแต่ละวัน และเปรียบเทียบการเข้าชมจริงกับเซสชันที่คาดการณ์ไว้
ขั้นแรก เราจะลบออกจาก dataframe ดั้งเดิม 12 วันสุดท้ายด้วย pop และเราสร้าง dataframe ใหม่ที่จะรวมเฉพาะ 12 วันเหล่านั้นซึ่งจะถูกใช้สำหรับการคาดการณ์:
รถไฟ = df_sessions.drop(df_sessions.index[-12:]) อนาคต = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
ตอนนี้เราฝึกแบบจำลอง ทำการพยากรณ์ และเราคำนวณค่าคลาดเคลื่อนสัมบูรณ์เฉลี่ย ในท้ายที่สุด เราสามารถวาดแผนภาพซึ่งจะแสดงความแตกต่างระหว่างค่าที่คาดการณ์ไว้จริงกับค่าจริง นี่คือสิ่งที่ฉันได้เรียนรู้จากบทความนี้ที่เขียนโดย Jason Brownlee
จาก sklearn.metrics นำเข้า mean_absolute_error
นำเข้า numpy เป็น np
จากอาร์เรย์นำเข้าจำนวนมาก
#เราเทรนโมเดล
รุ่น = ศาสดา ()
model.fit(รถไฟ)
#ปรับ dataframe ที่ใช้สำหรับวันที่คาดการณ์ให้อยู่ในรูปแบบที่ศาสดากำหนด
อนาคต = รายการ (อนาคต)
อนาคต = DataFrame (อนาคต)
อนาคต = future.rename(คอลัมน์={0: 'ds'})
#เราทำพยากรณ์
พยากรณ์ = model.predict (อนาคต)
# เราคำนวณ MAE ระหว่างค่าจริงและค่าที่คาดการณ์
y_true = df_sessions['y'][-12:].values
y_pred = พยากรณ์['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
# เราวางแผนผลลัพธ์สุดท้ายเพื่อความเข้าใจด้วยภาพ
y_true = np.stack(y_true).astype(ลอย)
pyplot.plot(y_true, label='Actual')
pyplot.plot(y_pred, label='Predicted')
pyplot.legend()
pyplot.show()
พิมพ์ (แม่) 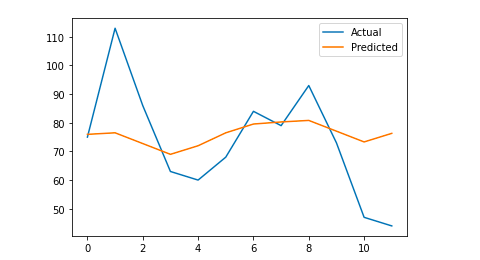
ข้อผิดพลาดสัมบูรณ์เฉลี่ยของฉันคือ 13 ซึ่งหมายความว่าแบบจำลองที่คาดการณ์ของฉันกำหนดเซสชันมากกว่าจริง 13 เซสชันในแต่ละวันซึ่งดูเหมือนจะเป็นข้อผิดพลาดที่ยอมรับได้
นั่นคือทั้งหมดที่! ฉันหวังว่าคุณจะพบว่าบทความนี้น่าสนใจ และคุณสามารถเริ่มคาดการณ์ SEO เพื่อกำหนดเป้าหมายได้
ก้าวต่อไป: OnCrawl Labs
หากคุณสนุกกับการคาดการณ์การเข้าชมด้วยวิธีนี้ คุณจะสนใจ OnCrawl Labs ซึ่งเป็นห้องปฏิบัติการวิทยาศาสตร์ข้อมูลของ OnCrawl และแมชชีนเลิร์นนิงที่นำเสนอโปรเจ็กต์ที่เข้ารหัสไว้ล่วงหน้าสำหรับเวิร์กโฟลว์ SEO ของคุณ
ในการพยากรณ์ SEO OnCrawl Labs จะช่วยคุณปรับแต่งการคาดการณ์ SEO ของคุณ:
- ทำความเข้าใจทฤษฎีและกระบวนการเบื้องหลังอัลกอริธึมของ Facebook Prophet
- วิเคราะห์กลุ่มของการเข้าชม เช่น การเข้าชมสำหรับคำหลักหางยาวเท่านั้น หรือคำหลักที่มีตราสินค้าเท่านั้น...
- ทำตามขั้นตอนทีละขั้นตอนเพื่อตั้งค่าเหตุการณ์ทางประวัติศาสตร์ ปรับอิทธิพลและแนวโน้มที่จะเกิดซ้ำ