
จะแยกเนื้อหาข้อความที่เกี่ยวข้องออกจากหน้า HTML ได้อย่างไร
เผยแพร่แล้ว: 2021-10-13บริบท
ในแผนก R&D ของ Oncrawl เราต้องการเพิ่มมูลค่าให้กับเนื้อหาเชิงความหมายของหน้าเว็บของคุณมากขึ้น การใช้โมเดลการเรียนรู้ของเครื่องสำหรับการประมวลผลภาษาธรรมชาติ (NLP) ทำให้สามารถทำงานที่มีมูลค่าเพิ่มอย่างแท้จริงสำหรับ SEO ได้
งานเหล่านี้รวมถึงกิจกรรมเช่น:
- ปรับแต่งเนื้อหาของเพจของคุณ
- ทำการสรุปอัตโนมัติ
- การเพิ่มแท็กใหม่ให้กับบทความของคุณหรือแก้ไขแท็กที่มีอยู่
- การเพิ่มประสิทธิภาพเนื้อหาตามข้อมูล Google Search Console ของคุณ
- ฯลฯ
ขั้นตอนแรกในการผจญภัยครั้งนี้คือการดึงเนื้อหาข้อความของหน้าเว็บที่โมเดลการเรียนรู้ของเครื่องเหล่านี้จะใช้ เมื่อเราพูดถึงหน้าเว็บ ซึ่งรวมถึง HTML, JavaScript, เมนู, สื่อ, ส่วนหัว, ส่วนท้าย, ... การแยกเนื้อหาโดยอัตโนมัติและถูกต้องไม่ใช่เรื่องง่าย จากบทความนี้ ฉันเสนอให้สำรวจปัญหาและหารือเกี่ยวกับเครื่องมือและคำแนะนำบางอย่างเพื่อให้บรรลุงานนี้
ปัญหา
การแยกเนื้อหาข้อความจากหน้าเว็บอาจดูเหมือนง่าย ด้วย Python สองสามบรรทัด ตัวอย่างเช่น นิพจน์ทั่วไปสองสามตัว (regexp) ไลบรารีการแยกวิเคราะห์ เช่น BeautifulSoup4 และมันก็เสร็จสิ้น
หากคุณเพิกเฉยสักสองสามนาทีว่าไซต์ต่างๆ ใช้เอ็นจินการเรนเดอร์ JavaScript เช่น Vue.js หรือ React มากขึ้นเรื่อยๆ การแยกวิเคราะห์ HTML นั้นไม่ซับซ้อนมากนัก หากคุณต้องการกำหนดกรอบปัญหานี้โดยใช้ประโยชน์จากโปรแกรมรวบรวมข้อมูล JS ของเราในการรวบรวมข้อมูล เราขอแนะนำให้คุณอ่าน “วิธีรวบรวมข้อมูลเว็บไซต์ใน JavaScript”
อย่างไรก็ตาม เราต้องการแยกข้อความที่เหมาะสม ซึ่งเป็นข้อมูลให้มากที่สุด ตัวอย่างเช่น เมื่อคุณอ่านบทความเกี่ยวกับอัลบั้มมรณกรรมสุดท้ายของ John Coltrane คุณละเลยเมนู ส่วนท้าย … และแน่นอนว่าคุณไม่ได้ดูเนื้อหา HTML ทั้งหมด องค์ประกอบ HTML เหล่านี้ที่ปรากฏบนหน้าเว็บเกือบทั้งหมดของคุณเรียกว่าสำเร็จรูป เราต้องการกำจัดมันและเก็บไว้เพียงบางส่วน: ข้อความที่มีข้อมูลที่เกี่ยวข้อง
ดังนั้นจึงเป็นเพียงข้อความนี้เท่านั้นที่เราต้องการส่งต่อไปยังโมเดลการเรียนรู้ของเครื่องเพื่อการประมวลผล ดังนั้นจึงจำเป็นที่การสกัดจะต้องมีคุณภาพมากที่สุด
โซลูชั่น
โดยรวมแล้ว เราต้องการกำจัดทุกสิ่งที่ "ค้างอยู่รอบๆ" ข้อความหลัก: เมนูและแถบด้านข้างอื่นๆ องค์ประกอบการติดต่อ ลิงก์ส่วนท้าย ฯลฯ มีหลายวิธีในการทำเช่นนี้ เราสนใจโครงการโอเพ่นซอร์สเป็นส่วนใหญ่ใน Python หรือ JavaScript
justText
jusText เป็นการนำเสนอใน Python จากวิทยานิพนธ์ระดับปริญญาเอก: "การลบ Boilerplate และ Duplicate Content จาก Web Corpora" วิธีนี้ช่วยให้บล็อกข้อความจาก HTML สามารถจัดประเภทเป็น "ดี" "ไม่ดี" "สั้นเกินไป" ตามการวิเคราะห์พฤติกรรมที่แตกต่างกัน การวิเคราะห์พฤติกรรมเหล่านี้ส่วนใหญ่ขึ้นอยู่กับจำนวนคำ อัตราส่วนข้อความ/โค้ด การมีอยู่หรือไม่มีลิงก์ ฯลฯ คุณสามารถอ่านเพิ่มเติมเกี่ยวกับอัลกอริทึมได้ในเอกสารประกอบ
trafilatura
trafilatura ซึ่งสร้างขึ้นใน Python เช่นกัน นำเสนอฮิวริสติกทั้งประเภทองค์ประกอบ HTML และเนื้อหา เช่น ความยาวของข้อความ ตำแหน่ง/ความลึกขององค์ประกอบใน HTML หรือการนับจำนวนคำ trafilatura ยังใช้ jusText เพื่อดำเนินการประมวลผลบางอย่าง
การอ่านง่าย
คุณเคยสังเกตปุ่มในแถบ URL ของ Firefox หรือไม่? เป็นมุมมองผู้อ่าน: ช่วยให้คุณสามารถลบต้นแบบออกจากหน้า HTML เพื่อเก็บเฉพาะเนื้อหาข้อความหลัก ค่อนข้างใช้งานได้จริงสำหรับเว็บไซต์ข่าว โค้ดที่อยู่เบื้องหลังคุณลักษณะนี้เขียนด้วย JavaScript และ Mozilla เรียกอ่านได้ มันขึ้นอยู่กับงานที่ริเริ่มโดยห้องปฏิบัติการ Arc90
ต่อไปนี้คือตัวอย่างวิธีการแสดงคุณลักษณะนี้สำหรับบทความจากเว็บไซต์ France Musique 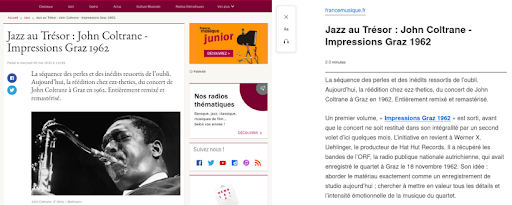
ด้านซ้ายเป็นข้อความที่ตัดตอนมาจากบทความต้นฉบับ ทางด้านขวาเป็นการแสดงผลของคุณลักษณะมุมมองผู้อ่านใน Firefox
คนอื่น
การวิจัยเกี่ยวกับเครื่องมือแยกเนื้อหา HTML ทำให้เราพิจารณาเครื่องมืออื่นๆ ด้วย:
- หนังสือพิมพ์: ห้องสมุดแยกเนื้อหาค่อนข้างเฉพาะสำหรับเว็บไซต์ข่าว (Python) ไลบรารีนี้ใช้เพื่อแยกเนื้อหาจากคลังข้อมูล OpenWebText2
- Boilerpy3 เป็นพอร์ต Python ของไลบรารี Boilerpipe
- ไลบรารี dragnet Python ยังได้รับแรงบันดาลใจจาก boilerpipe
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมการประเมินและข้อเสนอแนะ
ก่อนการประเมินและเปรียบเทียบเครื่องมือต่างๆ เราต้องการทราบว่าชุมชน NLP ใช้เครื่องมือเหล่านี้เพื่อเตรียมคลังข้อมูลหรือไม่ (เอกสารชุดใหญ่) ตัวอย่างเช่น ชุดข้อมูลที่เรียกว่า The Pile ที่ใช้ในการฝึก GPT-Neo มีข้อความภาษาอังกฤษมากกว่า 800 GB จาก Wikipedia, Openwebtext2, Github, CommonCrawl เป็นต้น เช่นเดียวกับ BERT GPT-Neo เป็นรูปแบบภาษาที่ใช้หม้อแปลงชนิด มีการใช้งานโอเพ่นซอร์สที่คล้ายกับสถาปัตยกรรม GPT-3

บทความ “The Pile: ชุดข้อมูล 800GB ของข้อความที่หลากหลายสำหรับการสร้างแบบจำลองภาษา” กล่าวถึงการใช้ jusText สำหรับส่วนใหญ่ของคลังข้อมูลจาก CommonCrawl นักวิจัยกลุ่มนี้ยังได้วางแผนที่จะทำเกณฑ์มาตรฐานของเครื่องมือสกัดต่างๆ น่าเสียดายที่พวกเขาไม่สามารถทำงานตามแผนได้เนื่องจากขาดทรัพยากร ในข้อสรุปของพวกเขาควรสังเกตว่า:
- บางครั้ง jusText ลบเนื้อหามากเกินไป แต่ยังให้คุณภาพดี ด้วยจำนวนข้อมูลที่พวกเขามี นี่ไม่ใช่ปัญหาสำหรับพวกเขา
- trafilatura รักษาโครงสร้างของหน้า HTML ไว้ได้ดีกว่าแต่เก็บต้นแบบไว้มากเกินไป
สำหรับวิธีการประเมินของเรา เราใช้เวลาประมาณสามสิบหน้า เราแยกเนื้อหาหลัก "ด้วยตนเอง" จากนั้นเราเปรียบเทียบการแยกข้อความของเครื่องมือต่างๆ กับเนื้อหาที่เรียกว่า "ข้อมูลอ้างอิง" เราใช้คะแนน ROUGE ซึ่งส่วนใหญ่ใช้ในการประเมินการสรุปข้อความอัตโนมัติเป็นตัวชี้วัด
นอกจากนี้เรายังเปรียบเทียบเครื่องมือเหล่านี้กับเครื่องมือ "ทำเอง" ตามกฎการแยกวิเคราะห์ HTML ปรากฎว่า trafilatura, jusText และเครื่องมือทำเองของเรามีราคาดีกว่าเครื่องมืออื่นๆ ส่วนใหญ่สำหรับเมตริกนี้
นี่คือตารางค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของคะแนน ROUGE:
| เครื่องมือ | หมายถึง | มาตรฐาน |
|---|---|---|
| trafilatura | 0.783 | 0.28 |
| รวบรวมข้อมูล | 0.779 | 0.28 |
| justText | 0.735 | 0.33 |
| Boilpy3 | 0.698 | 0.36 |
| การอ่านง่าย | 0.681 | 0.34 |
| ตาข่ายดักแด้ | 0.672 | 0.37 |
สำหรับค่าเบี่ยงเบนมาตรฐาน โปรดทราบว่าคุณภาพของการสกัดอาจแตกต่างกันมาก วิธีการใช้งาน HTML ความสอดคล้องของแท็ก และการใช้ภาษาอย่างเหมาะสม อาจทำให้ผลลัพธ์ของการดึงข้อมูลมีความแตกต่างกันมาก
เครื่องมือสามอย่างที่มีประสิทธิภาพดีที่สุดคือ trafilatura ซึ่งเป็นเครื่องมือภายในของเราที่ชื่อว่า “oncrawl” สำหรับโอกาสนี้และ jusText เนื่องจาก trafilatura ใช้ jusText เป็นทางเลือกสำรอง เราจึงตัดสินใจใช้ trafilatura เป็นตัวเลือกแรกของเรา อย่างไรก็ตาม เมื่อคำหลังล้มเหลวและแยกคำเป็นศูนย์ เราใช้กฎของเราเอง
โปรดทราบว่าโค้ด trafilatura ยังมีการเปรียบเทียบในหน้าหลายร้อยหน้าอีกด้วย จะคำนวณคะแนนความแม่นยำ คะแนน f1 และความแม่นยำตามการมีอยู่หรือไม่มีองค์ประกอบบางอย่างในเนื้อหาที่แยกออกมา เครื่องมือสองอย่างโดดเด่น: trafilatura และ goose3. คุณอาจต้องการอ่าน:
- การเลือกเครื่องมือที่เหมาะสมในการดึงเนื้อหาจากเว็บ (2020)
- พื้นที่เก็บข้อมูล Github: เกณฑ์มาตรฐานในการแยกบทความ: ไลบรารีโอเพนซอร์ซและบริการเชิงพาณิชย์
บทสรุป
คุณภาพของโค้ด HTML และความแตกต่างของประเภทหน้าเว็บทำให้แยกเนื้อหาที่มีคุณภาพได้ยาก ตามที่นักวิจัย EleutherAI ซึ่งอยู่เบื้องหลัง The Pile และ GPT-Neo พบว่า ไม่มีเครื่องมือที่สมบูรณ์แบบ มีการประนีประนอมระหว่างเนื้อหาที่ถูกตัดทอนในบางครั้งและเสียงที่หลงเหลือในข้อความเมื่อไม่ได้เอาต้นแบบทั้งหมดออก
ข้อดีของเครื่องมือเหล่านี้คือไม่มีบริบท นั่นหมายความว่า พวกเขาไม่ต้องการข้อมูลอื่นใดนอกจาก HTML ของหน้าเพื่อแยกเนื้อหา เมื่อใช้ผลลัพธ์ของ Oncrawl เราสามารถจินตนาการถึงวิธีไฮบริดโดยใช้ความถี่ของการเกิดบล็อก HTML ที่แน่นอนในทุกหน้าของไซต์เพื่อจัดประเภทเป็นต้นแบบ
สำหรับชุดข้อมูลที่ใช้ในการวัดประสิทธิภาพที่เราพบบนเว็บ พวกเขามักจะเป็นหน้าประเภทเดียวกัน: บทความข่าวหรือโพสต์ในบล็อก ไม่จำเป็นต้องรวมเว็บไซต์ประกัน ตัวแทนท่องเที่ยว อีคอมเมิร์ซ ฯลฯ ที่เนื้อหาข้อความบางครั้งซับซ้อนกว่าในการดึงข้อมูล
เกี่ยวกับเกณฑ์มาตรฐานของเราและเนื่องจากขาดทรัพยากร เราทราบดีว่าหน้าสามสิบหน้าไม่เพียงพอสำหรับการดูคะแนนโดยละเอียดมากขึ้น ตามหลักการแล้ว เราต้องการให้มีหน้าเว็บต่างๆ จำนวนมากขึ้นเพื่อปรับแต่งค่าการเปรียบเทียบของเรา และเราต้องการรวมเครื่องมืออื่นๆ เช่น goose3, html_text หรือ inscriptis ด้วย