
ดึงข้อมูลจาก Google Search Console API สำหรับการวิเคราะห์ข้อมูลใน Python
เผยแพร่แล้ว: 2022-03-01Google Search Console (GSC) เป็นหนึ่งในเครื่องมือที่มีประโยชน์ที่สุดสำหรับผู้เชี่ยวชาญด้าน SEO เนื่องจากช่วยให้คุณได้รับข้อมูลเกี่ยวกับความครอบคลุมของดัชนีและโดยเฉพาะอย่างยิ่งคำค้นหาที่คุณกำลังจัดอันดับอยู่ เมื่อทราบสิ่งนี้แล้ว ผู้คนจำนวนมากวิเคราะห์ข้อมูล GSC โดยใช้สเปรดชีตและเป็นเรื่องปกติ ตราบใดที่คุณเข้าใจว่ายังมีช่องว่างให้ปรับปรุงได้อีกมากด้วยเครื่องมือ เช่น ภาษาการเขียนโปรแกรม
น่าเสียดายที่อินเทอร์เฟซ GSC ค่อนข้างจำกัดทั้งในแง่ของแถวที่แสดง (เพียง 5000) และช่วงเวลาที่ใช้ได้เพียง 16 เดือน เป็นที่ชัดเจนว่าการดำเนินการนี้อาจจำกัดความสามารถของคุณในการรับข้อมูลเชิงลึกอย่างรุนแรง และไม่เหมาะสำหรับเว็บไซต์ขนาดใหญ่
Python ช่วยให้คุณรับข้อมูล GSC ได้อย่างง่ายดายและทำการคำนวณที่ซับซ้อนมากขึ้นโดยอัตโนมัติ ซึ่งจะใช้ความพยายามมากขึ้นในซอฟต์แวร์สเปรดชีตแบบเดิม
นี่เป็นวิธีแก้ปัญหาหนึ่งในปัญหาใหญ่ที่สุดใน Excel กล่าวคือ ขีดจำกัดของแถวและความเร็ว ทุกวันนี้ คุณมีทางเลือกอื่นในการวิเคราะห์ข้อมูลมากกว่าเมื่อก่อน และนั่นคือที่มาของ Python
คุณไม่จำเป็นต้องมีความรู้ด้านการเขียนโค้ดขั้นสูงเพื่อทำตามบทช่วยสอนนี้ เพียงแค่ทำความเข้าใจแนวคิดพื้นฐานและแนวทางปฏิบัติบางอย่างกับ Google Colab
เริ่มต้นใช้งาน Google Search Console API
ก่อนที่เราจะเริ่มต้น ตั้งค่า Google Search Console API ก่อน กระบวนการนี้ค่อนข้างง่าย เพียงคุณมีบัญชี Google ขั้นตอนมีดังนี้:
- สร้างโครงการใหม่บน Google Cloud Platform คุณควรมีบัญชี Google และฉันค่อนข้างแน่ใจว่าคุณมีบัญชีนี้ ไปที่คอนโซลแล้วคุณจะพบตัวเลือกที่ด้านบนสุดสำหรับการสร้างโครงการใหม่
- คลิกที่เมนูด้านซ้ายและเลือก "API and services" คุณจะไปที่หน้าจออื่น
- จากแถบค้นหาที่ด้านบน ให้มองหา “Google Search Console API” และเปิดใช้งาน
- จากนั้นไปที่แท็บ "ข้อมูลประจำตัว" คุณต้องมีการอนุญาตบางอย่างเพื่อใช้ API
- กำหนดค่าหน้าจอ "ยินยอม" เนื่องจากเป็นข้อบังคับ ไม่สำคัญสำหรับการใช้งานที่เราจะเปิดเผยต่อสาธารณะหรือไม่
- คุณสามารถเลือก "แอปเดสก์ท็อป" สำหรับประเภทแอปพลิเคชัน
- เราจะใช้ OAuth 2.0 สำหรับบทช่วยสอนนี้ คุณควรดาวน์โหลดไฟล์ json และตอนนี้คุณก็ทำเสร็จแล้ว
นี่เป็นส่วนที่ยากที่สุดสำหรับคนส่วนใหญ่ โดยเฉพาะอย่างยิ่งผู้ที่ไม่คุ้นเคยกับ Google API ไม่ต้องกังวล ขั้นตอนต่อไปจะง่ายขึ้นและมีปัญหาน้อยลง
รับข้อมูลจาก Google Search Console API ด้วย Python
คำแนะนำของฉันคือคุณใช้สมุดบันทึกเช่น Jupyter Notebook หรือ Google Colab อย่างหลังจะดีกว่าเพราะคุณไม่ต้องกังวลกับความต้องการ ดังนั้น สิ่งที่ฉันจะอธิบายจะขึ้นอยู่กับ Google Colab
ก่อนที่เราจะเริ่ม ให้อัปเดตไฟล์ json ของคุณเป็น Google Colab ด้วยรหัสต่อไปนี้:
จากไฟล์นำเข้า google.colab ไฟล์.อัพโหลด()
จากนั้น มาติดตั้งไลบรารีทั้งหมดที่เราต้องการสำหรับการวิเคราะห์ของเรา และสร้างการแสดงภาพตารางที่ดีขึ้นด้วยข้อมูลโค้ดนี้:
%%การจับกุม #โหลดเท่าที่จำเป็น !pip ติดตั้ง git+https://github.com/joshcarty/google-searchconsole นำเข้าแพนด้าเป็น pd นำเข้า numpy เป็น np นำเข้า matplotlib.pyplot เป็น plt จาก google.colab นำเข้า data_table !git โคลน https://github.com/jroakes/querycat.git !pip ติดตั้ง -r querycat/requirements_colab.txt !pip ติดตั้ง umap-learn data_table.enable_dataframe_formatter() #สำหรับการแสดงตารางที่ดีขึ้น
สุดท้าย คุณสามารถโหลดไลบรารี่คอนโซลการค้นหา ซึ่งมีวิธีที่ง่ายที่สุดในการทำเช่นนั้นโดยไม่ต้องอาศัยฟังก์ชันยาวๆ เรียกใช้โค้ดต่อไปนี้ด้วยอาร์กิวเมนต์ที่ฉันใช้ และต้องแน่ใจว่า client_config มีชื่อเดียวกันกับไฟล์ json ที่อัปโหลด
นำเข้าคอนโซลการค้นหา บัญชี = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
คุณจะถูกเปลี่ยนเส้นทางไปยังหน้า Google เพื่ออนุญาตแอปพลิเคชัน เลือกบัญชี Google ของคุณ จากนั้นคัดลอกและวางรหัสที่คุณจะได้รับในแถบ Google Colab
เรายังไม่เสร็จสิ้น คุณต้องเลือกคุณสมบัติที่คุณต้องการข้อมูล คุณสามารถตรวจสอบคุณสมบัติของคุณได้อย่างง่ายดายผ่าน account.webproperties เพื่อดูว่าคุณควรเลือกอะไร
property_name = input('ใส่ชื่อเว็บไซต์ของคุณตามรายการใน GSC: ')
คุณสมบัติเว็บ=บัญชี[str(property_name)]
เมื่อคุณทำเสร็จแล้ว คุณจะเรียกใช้ฟังก์ชันที่กำหนดเองเพื่อสร้างวัตถุที่มีข้อมูลของเรา
def extract_gsc_data(คุณสมบัติเว็บ, เริ่ม, หยุด, *args):
หากคุณสมบัติเว็บไม่ใช่ไม่มี:
print(f'Extracting data for {webproperty}')
gsc_data = webproperty.query.range(เริ่ม, หยุด).dimension(*args).get()
ส่งคืน gsc_data
อื่น:
print('ไม่พบเว็บพร็อพเพอร์ตี้ โปรดเลือกรายการที่ถูกต้อง')
กลับไม่มี
แนวคิดของฟังก์ชันคือการนำคุณสมบัติที่คุณกำหนดไว้ก่อนหน้านี้และกรอบเวลา ในรูปแบบของวันที่เริ่มต้นและสิ้นสุด ไปพร้อมกับมิติข้อมูล
ทางเลือกในการเลือกมิติข้อมูลเป็นสิ่งสำคัญสำหรับผู้เชี่ยวชาญด้าน SEO เนื่องจากจะช่วยให้คุณเข้าใจว่าคุณต้องการความละเอียดในระดับหนึ่งหรือไม่ ตัวอย่างเช่น คุณอาจไม่สนใจรับมิติวันที่ ในบางกรณี
คำแนะนำของฉันคือให้เลือกคำค้นหาและหน้าเสมอ เนื่องจากอินเทอร์เฟซของ Google Search Console สามารถส่งออกแยกกันได้ และมันน่ารำคาญมากที่จะรวมมันทุกครั้ง นี่เป็นข้อดีอีกอย่างของ Search Console API
ในกรณีของเรา เราสามารถรับมิติวันที่ได้โดยตรงเช่นกัน เพื่อแสดงสถานการณ์ที่น่าสนใจซึ่งคุณต้องคำนึงถึงเวลาด้วย
อดีต = extract_gsc_data (เว็บพร็อพเพอร์ตี้ '2021-09-01', '2021-12-31', 'แบบสอบถาม', 'หน้า', 'วันที่')
เลือกกรอบเวลาที่เหมาะสม โดยพิจารณาว่าสำหรับคุณสมบัติขนาดใหญ่ คุณจะต้องรอเป็นเวลานาน สำหรับตัวอย่างนี้ ฉันแค่พิจารณาช่วงเวลา 3 เดือนซึ่งเพียงพอที่จะรับข้อมูลเชิงลึกอันมีค่าจากชุดข้อมูลส่วนใหญ่โดยเฉลี่ย
คุณสามารถเลือกได้แม้กระทั่งหนึ่งสัปดาห์หากคุณต้องรับมือกับข้อมูลจำนวนมาก สิ่งที่เราสนใจคือกระบวนการ
สิ่งที่ฉันจะแสดงให้คุณเห็นที่นี่ขึ้นอยู่กับข้อมูลสังเคราะห์หรือข้อมูลจริงที่แก้ไขเพื่อความเหมาะสมสำหรับตัวอย่าง ด้วยเหตุนี้ สิ่งที่คุณเห็นจึงเป็นเรื่องจริงและสามารถสะท้อนสถานการณ์ในโลกแห่งความเป็นจริงได้
การล้างข้อมูล
สำหรับผู้ที่ไม่ทราบ เราไม่สามารถใช้ข้อมูลของเราตามที่เป็นอยู่ มีขั้นตอนเพิ่มเติมบางอย่างเพื่อให้แน่ใจว่าเราทำงานอย่างถูกต้อง ก่อนอื่น เราต้องแปลงอ็อบเจกต์ของเราเป็น Pandas dataframe ซึ่งเป็นโครงสร้างข้อมูลที่คุณต้องคุ้นเคย เนื่องจากเป็นพื้นฐานของการวิเคราะห์ข้อมูลใน Python
df = pd.DataFrame (ข้อมูล = อดีต) df.head()
วิธี head สามารถแสดง 5 แถวแรกของชุดข้อมูลของคุณได้ ซึ่งมีประโยชน์มากในการดูข้อมูลคร่าวๆ ว่าข้อมูลของคุณเป็นอย่างไร เราสามารถนับจำนวนหน้าที่เรามีโดยใช้ฟังก์ชันง่ายๆ
วิธีที่ดีในการลบรายการที่ซ้ำกันคือการแปลงออบเจ็กต์เป็นชุด เนื่องจากชุดต้องไม่มีองค์ประกอบที่ซ้ำกัน
ข้อมูลโค้ดบางส่วนได้รับแรงบันดาลใจจากสมุดบันทึกของ Hamlet Batista และอีกอันจาก Masaki Okazawa
การลบคำที่เป็นแบรนด์
สิ่งแรกที่ต้องทำคือลบคำหลักที่มีตราสินค้า เรากำลังมองหาคำค้นหาที่ไม่มีคำที่เป็นแบรนด์ของเรา การดำเนินการนี้ค่อนข้างตรงไปตรงมากับฟังก์ชันแบบกำหนดเอง และคุณมักจะมีชุดคำที่เป็นแบรนด์
เพื่อจุดประสงค์ในการสาธิต คุณไม่จำเป็นต้องกรองข้อมูลทั้งหมดออก แต่โปรดทำเพื่อการวิเคราะห์อย่างแท้จริง เป็นหนึ่งในขั้นตอนการล้างข้อมูลที่สำคัญที่สุดใน SEO มิฉะนั้น คุณอาจเสี่ยงที่จะนำเสนอผลลัพธ์ที่ทำให้เข้าใจผิด
domain_name = str(input('ใส่คำแบรนด์โดยคั่นด้วยเครื่องหมายจุลภาค: ')).replace(',', '|')
นำเข้าอีกครั้ง
domain_name = re.sub(r"\s+", "", domain_name)
print('ลบช่องว่างทั้งหมดโดยใช้ RegEx:\n')
df['ยี่ห้อ/ไม่มีตราสินค้า'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Non-branded'
)
เราจะเพิ่มคอลัมน์ใหม่ในชุดข้อมูลของเราเพื่อรับรู้ความแตกต่างระหว่างสองคลาส เราสามารถเห็นภาพผ่านตารางหรือแผนภูมิแท่งได้ว่าพวกเขาคิดอย่างไรกับจำนวนข้อความค้นหาทั้งหมด
ฉันจะไม่แสดงแผนภาพให้คุณเห็นเพราะมันง่ายมาก และฉันคิดว่าตารางจะดีกว่าสำหรับกรณีนี้
brand_count_df = df['Brand/Non-branded'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Percentage'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
คุณสามารถดูอัตราส่วนระหว่างคำหลักของแบรนด์และคำหลักที่ไม่มีแบรนด์ได้อย่างรวดเร็วเพื่อดูว่าคุณจะลบออกจากชุดข้อมูลของคุณเป็นจำนวนเท่าใด ไม่มีอัตราส่วนที่เหมาะสมที่นี่ แม้ว่าคุณต้องการมีคำหลักที่ไม่มีแบรนด์ในเปอร์เซ็นต์ที่สูงกว่า
จากนั้น เราสามารถวางแถวทั้งหมดที่ทำเครื่องหมายเป็นตราสินค้า และดำเนินการขั้นตอนอื่น ๆ
#เลือกเฉพาะคำหลักที่ไม่มีตราสินค้า df = df.loc[df['Brand/Non-branded'] == 'ไม่มีตราสินค้า']
การกรอกค่าที่หายไปและขั้นตอนอื่นๆ
หากชุดข้อมูลของคุณมีค่าที่ขาดหายไป (หรือ NA ในศัพท์แสง) คุณมีหลายทางเลือก โดยทั่วไปแล้วจะปล่อยทั้งหมดหรือเติมด้วยค่าตัวยึดตำแหน่ง เช่น 0 หรือค่าเฉลี่ยของคอลัมน์นั้น
ไม่มีคำตอบที่ถูกต้อง และทั้งสองวิธีก็มีข้อดีและข้อเสีย เช่นเดียวกับความเสี่ยง สำหรับข้อมูล Google Search Console คำแนะนำที่ดีที่สุดของฉันคือใส่ค่าตัวยึดตำแหน่งเช่น 0 เพื่อประเมินผลกระทบของบางเมตริกต่ำไป
df.fillna(0, แทนที่ = จริง)
ก่อนที่เราจะไปยังการวิเคราะห์ข้อมูลจริง เราต้องปรับคุณลักษณะของเรา นั่นคือคอลัมน์ของชุดข้อมูลของเรา ตำแหน่งนี้น่าสนใจเป็นพิเศษ เนื่องจากเราต้องการใช้สำหรับตารางสรุปข้อมูลที่น่าสนใจ
เราสามารถปัดเศษตำแหน่งให้เป็นจำนวนเต็มซึ่งเป็นไปตามจุดประสงค์ของเรา
df['position'] = df['position'].round(0).astype('int64')
คุณควรทำตามขั้นตอนการทำความสะอาดอื่นๆ ทั้งหมดที่อธิบายไว้ข้างต้น แล้วปรับคอลัมน์วันที่
เรากำลังแยกเดือนและปีด้วยความช่วยเหลือจากแพนด้า คุณไม่จำเป็นต้องเจาะจงเรื่องนี้หากต้องทำงานในกรอบเวลาที่สั้นกว่า นี่เป็นตัวอย่างที่คำนึงถึงครึ่งปี
#แปลงวันที่เป็นรูปแบบที่เหมาะสม df['date'] = pd.to_datetime(df['date']) #สารสกัดเดือน df['month'] = df['date'].dt.เดือน #สารสกัดปี df['ปี'] = df['date'].dt.year
[Ebook] Data SEO: การผจญภัยครั้งยิ่งใหญ่ครั้งต่อไป
 อ่านอีบุ๊ก
อ่านอีบุ๊กการวิเคราะห์ข้อมูลเชิงสำรวจ
ข้อได้เปรียบหลักเกี่ยวกับ Python คือคุณสามารถทำสิ่งเดียวกันกับที่คุณทำใน Excel แต่มีตัวเลือกมากมายและง่ายกว่า มาเริ่มกันที่สิ่งที่นักวิเคราะห์ทุกคนรู้จักเป็นอย่างดี นั่นคือ pivot table
การวิเคราะห์ CTR เฉลี่ยต่อกลุ่มตำแหน่ง
กำลังวิเคราะห์เฉลี่ย CTR ต่อกลุ่มตำแหน่งเป็นหนึ่งในกิจกรรมที่ชาญฉลาดที่สุด เนื่องจากช่วยให้คุณเข้าใจสถานการณ์ทั่วไปของเว็บไซต์ ใช้เดือยแล้วลองพล็อตมัน
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
ขวาน = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('ตำแหน่งเฉลี่ย')
ax.set_ylabel('CTR')
ax.set_title('CTR โดยตำแหน่งเฉลี่ย')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(การหมุน=0)
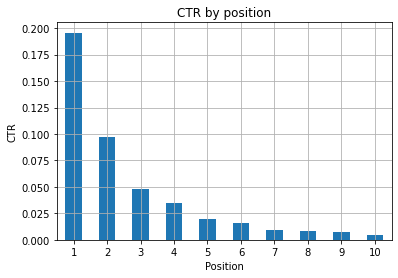
รูปที่ 1: แสดง CTR ตามตำแหน่งเพื่อระบุความผิดปกติ
สถานการณ์ในอุดมคติที่นี่คือการมี CTR ที่ดีกว่าทางด้านซ้ายของกราฟ ซึ่งตามปกติแล้วผลลัพธ์ในตำแหน่งที่ 1 ควรมี CTR ที่สูงกว่ามาก ระวังด้วย คุณอาจเห็นบางกรณีที่ 3 จุดแรกมี CTR ต่ำกว่าที่คาดไว้ และคุณต้องตรวจสอบ
โปรดพิจารณากรณีที่มีขอบเช่นกัน เช่น ตำแหน่งที่ 11 ดีกว่าที่หนึ่ง ตามที่อธิบายไว้ในเอกสารประกอบของ Google สำหรับ Search Console เมตริกนี้ไม่เป็นไปตามลำดับที่คุณคิดในตอนแรก
นอกจากนี้ ยังเสริมว่าตัวชี้วัดนี้เป็นค่าเฉลี่ย เนื่องจากตำแหน่งของลิงก์เปลี่ยนแปลงทุกครั้ง และเป็นไปไม่ได้ที่จะมีความแม่นยำ 100%
บางครั้งหน้าเว็บของคุณมีอันดับสูงแต่ไม่น่าเชื่อถือเพียงพอ ดังนั้น คุณจึงสามารถลองแก้ไขชื่อได้ เนื่องจากนี่เป็นภาพรวมระดับสูง คุณจะไม่เห็นความแตกต่างที่ละเอียด ดังนั้นควรดำเนินการอย่างรวดเร็วหากปัญหานี้มีขนาดใหญ่
พึงระวังด้วยว่าเมื่อกลุ่มของหน้าในตำแหน่งที่ต่ำกว่ามี CTR เฉลี่ยที่สูงกว่ากลุ่มของหน้าในตำแหน่งที่ดีกว่า
ด้วยเหตุนี้ คุณอาจต้องการขยายการวิเคราะห์ของคุณจนถึงตำแหน่งที่ 15 หรือมากกว่า เพื่อดูรูปแบบที่แปลก
จำนวนคำค้นหาต่อตำแหน่งและการวัดความพยายาม SEO
การเพิ่มขึ้นของคำค้นหาที่คุณอยู่ในอันดับนั้นเป็นสัญญาณที่ดี แต่ก็ไม่ได้หมายความว่าจะมีอันดับที่ดีขึ้นในอนาคตเสมอไป การนับคำค้นหาเป็นกระบวนการนับจำนวนคำค้นหาที่คุณจัดลำดับ และเป็นหนึ่งในงานที่สำคัญที่สุดที่คุณสามารถทำได้ด้วยข้อมูล GSC
ตาราง Pivot ช่วยได้มากอีกครั้ง และเราสามารถพล็อตผลลัพธ์ได้
Rank_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) Rank_queries.sort_values(by=['position']).head(10)
สิ่งที่คุณต้องการในฐานะผู้เชี่ยวชาญด้าน SEO คือการมีจำนวนคำค้นหาที่สูงกว่าทางด้านซ้ายสุด ซึ่งเป็นจุดสูงสุด เหตุผลค่อนข้างเป็นธรรมชาติ ตำแหน่งที่สูงจะได้รับ CTR ที่ดีขึ้นโดยเฉลี่ย ซึ่งสามารถแปลให้มีคนคลิกบนเพจของคุณมากขึ้น
ขวาน = Rank_queries.head(10).plot(kind='bar')
ax.set_ylabel('จำนวนคำค้นหา')
ax.set_xlabel('ตำแหน่ง')
ax.set_title('การกระจายอันดับ')
ax.grid('on')
ax.get_legend().remove()
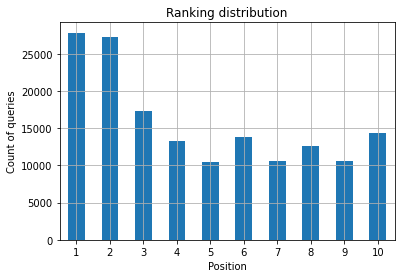
รูปที่ 2: ฉันมีคำถามกี่ข้อตามตำแหน่ง?
สิ่งที่คุณสนใจคือการเพิ่มจำนวนการสืบค้นในตำแหน่งบนสุดเมื่อเวลาผ่านไป
เล่นกับมิติวันที่
มาดูกันว่าจำนวนคลิกแตกต่างกันอย่างไรในช่วงเวลาที่พิจารณา มาดูผลรวมของการคลิกกันก่อน:
clicks_sum = df.groupby('วันที่')['clicks'].sum()
เรากำลังจัดกลุ่มข้อมูลตามมิติข้อมูลวันที่และรับผลรวมของการคลิกสำหรับแต่ละรายการ ซึ่งเป็นประเภทการสรุป
ตอนนี้เราพร้อมที่จะพล็อตสิ่งที่เราได้รับแล้ว โค้ดจะค่อนข้างยาวเพื่อปรับปรุงการแสดงภาพ อย่ากลัวไปเลย
# ยอดรวมของการคลิกข้ามช่วงเวลา
%config InlineBackend.figure_format = 'เรตินา'
จากรูปนำเข้า matplotlib.pyplot
ตัวเลข(figsize=(8, 6), dpi=80)
ขวาน = clicks_sum.plot(color='red')
ax.grid('on')
ax.set_ylabel('ผลรวมของการคลิก')
ax.set_xlabel('เดือน')
ax.set_title('จำนวนคลิกในแต่ละเดือนแตกต่างกันอย่างไร')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('ตัวเอียง')
xlab.set_size(10)
ylab.set_style('ตัวเอียง')
ylab.set_size(10)
ttl = ax.title
ttl.set_weight('ตัวหนา')
ax.spines['right'].set_color((.8,.8,.8)) ขวาน
ขวาน.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
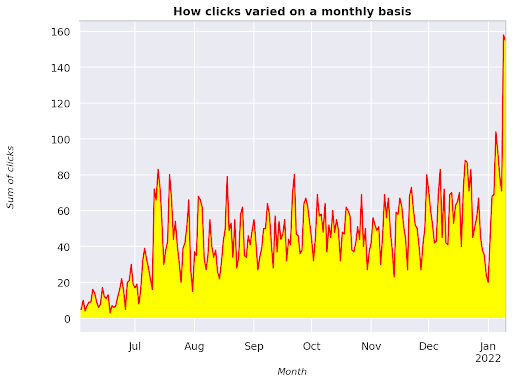

รูปที่ 3: การพล็อตผลรวมของการคลิกที่สัมพันธ์กับตัวแปรเดือน
นี่คือตัวอย่างตั้งแต่มิถุนายน 2564 ไปจนถึงครึ่งมกราคม 2565 ทุกบรรทัดที่คุณเห็นด้านบนมีบทบาทในการทำให้การแสดงภาพนี้สวยขึ้น คุณสามารถลองเล่นกับมันเพื่อดูว่าจะเกิดอะไรขึ้น
จำนวนคำค้นหาต่อตำแหน่ง สแนปชอตรายเดือน
การสร้างภาพข้อมูลที่ยอดเยี่ยมอีกอย่างหนึ่งที่เราสามารถพล็อตใน Python ได้ก็คือแผนที่ความหนาแน่น ซึ่งมองเห็นได้ชัดเจนมากกว่ากราฟแท่งธรรมดา ฉันจะแสดงวิธีแสดงจำนวนการสืบค้นตามเวลาและตามตำแหน่ง
นำเข้า seaborn เป็น sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # โหลดชุดข้อมูลเที่ยวบินตัวอย่างและแปลงเป็นรูปแบบยาว df_heat = df_new.pivot_table (ดัชนี = "ตำแหน่ง", คอลัมน์ = "เดือน", ค่า = "ข้อความค้นหา", aggfunc='นับ') # วาดแผนที่ความร้อนด้วยค่าตัวเลขในแต่ละเซลล์ f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["กันยายน", "ตุลาคม", "พฤศจิกายน", "ธันวาคม"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax_ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'เดือน', ylabel='Position', title = 'จำนวนคำค้นหาต่อตำแหน่งเปลี่ยนแปลงตามเวลา') #rotate ป้ายตำแหน่งเพื่อให้อ่านง่ายขึ้น plt.yticks(การหมุน=0)
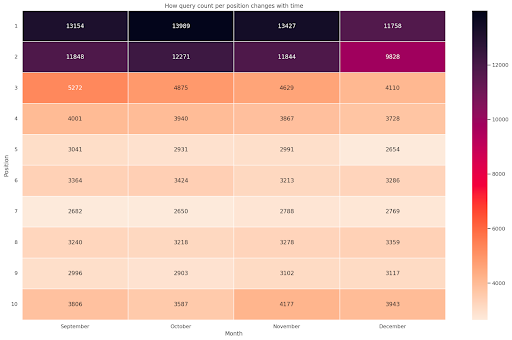
รูปที่ 4: Heatmap แสดงความคืบหน้าของการนับการสืบค้นตามตำแหน่งและเดือน
นี่เป็นหนึ่งในแผนที่ความร้อนที่ฉันโปรดปราน ซึ่งค่อนข้างมีประสิทธิภาพในการแสดงตารางสาระสำคัญ เช่น ในตัวอย่างนี้ ระยะเวลานี้กินเวลานานกว่า 4 เดือน และหากคุณอ่านในแนวนอน คุณจะเห็นว่าการนับข้อความค้นหาเปลี่ยนแปลงไปอย่างไรเมื่อเวลาผ่านไป สำหรับตำแหน่ง 10 คุณมีการเพิ่มขึ้นเล็กน้อยตั้งแต่เดือนกันยายนถึงธันวาคม แต่สำหรับตำแหน่งที่ 2 คุณมีการลดลงอย่างน่าทึ่ง ดังที่แสดงด้วยสีม่วง
ในสถานการณ์ต่อไปนี้ คุณมีคำถามส่วนใหญ่อยู่ในอันดับต้นๆ ซึ่งอาจเป็นเรื่องที่ไม่ปกติอย่างน่าทึ่ง หากเป็นเช่นนั้น คุณอาจต้องกลับไปวิเคราะห์ dataframe โดยมองหาคำที่เป็นแบรนด์ที่เป็นไปได้ หากมี
ดังที่คุณเห็นจากโค้ด การทำพล็อตที่ซับซ้อนไม่ใช่เรื่องยาก ตราบใดที่คุณมีตรรกะที่อยู่เบื้องหลัง
จำนวนคำค้นหาควรเพิ่มขึ้นตามเวลาหากคุณทำในสิ่งที่ "ถูกต้อง" และเราสามารถพล็อตความแตกต่างในกรอบเวลาที่แตกต่างกันสองแบบ ในตัวอย่างที่ฉันให้ไว้ เห็นได้ชัดว่าไม่ใช่กรณี โดยเฉพาะอย่างยิ่งสำหรับตำแหน่งบนสุด ซึ่งคุณควรมี CTR ที่สูงกว่า
แนะนำแนวคิด NLP พื้นฐานบางอย่าง
Natural Language Processing (NLP) มาจากสวรรค์สำหรับ SEO และคุณไม่จำเป็นต้องเป็นผู้เชี่ยวชาญเพื่อใช้อัลกอริธึมพื้นฐาน N-grams เป็นหนึ่งในแนวคิดที่เรียบง่ายแต่ทรงพลังที่สุดที่จะช่วยให้คุณได้รับข้อมูลเชิงลึกด้วยข้อมูล GSC
N-grams คือลำดับตัวอักษร พยางค์ หรือคำที่ต่อเนื่องกัน สำหรับคำวิเคราะห์ของเราจะเป็นหน่วยวัด n-gram เรียกว่า bigram เมื่อองค์ประกอบที่อยู่ติดกันเป็นสอง (คู่) และ trigram หากเป็นสามและอื่น ๆ ฉันแนะนำให้คุณทดสอบด้วยชุดค่าผสมต่างๆ และสูงสุดไม่เกิน 5 กรัม
ด้วยวิธีนี้ คุณจะสามารถมองเห็นประโยคที่พบบ่อยที่สุดในหน้าคู่แข่งของคุณหรือเพื่อประเมินประโยคของคุณเอง เนื่องจาก Google อาจใช้การจัดทำดัชนีแบบวลี จึงเป็นการดีกว่าที่จะเพิ่มประสิทธิภาพสำหรับประโยคมากกว่าการใช้คำหลักแต่ละคำ ดังที่แสดงโดยสิทธิบัตรของ Google ที่เกี่ยวข้องกับหัวข้อนี้
ตามที่ระบุไว้ในหน้าข้างต้นโดย Bill Slawski เอง คุณค่าของการทำความเข้าใจคำศัพท์ที่เกี่ยวข้องนั้นมีค่ามากสำหรับการเพิ่มประสิทธิภาพและสำหรับผู้ใช้ของคุณ
ไลบรารี nltk มีชื่อเสียงมากสำหรับแอปพลิเคชัน NLP และให้สิทธิ์เราในการลบคำหยุดในภาษาที่กำหนด เช่น ภาษาอังกฤษ คิดว่ามันเป็นเสียงรบกวนที่คุณต้องการลบ อันที่จริง บทความและคำที่ใช้บ่อยมากไม่ได้เพิ่มคุณค่าใดๆ ในการทำความเข้าใจข้อความ
นำเข้า nltk
nltk.download('คำหยุด')
จาก nltk.corpus นำเข้าคำหยุด
รายการหยุด = stopwords.words ('ภาษาอังกฤษ')
จาก sklearn.feature_extract.text นำเข้า CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
#เมทริกซ์ของ ngrams
ngrams = c_vec.fit_transform(df['query'])
#นับความถี่ ngrams
count_values = ngrams.toarray().sum(แกน=0)
#รายชื่อ ngrams
คำศัพท์ = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequency', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
เราใช้คอลัมน์การสืบค้นและนับความถี่ของ bi-grams เพื่อสร้าง dataframe ที่จัดเก็บ bi-grams และจำนวนครั้งที่เกิดขึ้น
ขั้นตอนนี้สำคัญมากจริง ๆ ในการวิเคราะห์เว็บไซต์ของคู่แข่งด้วย คุณสามารถขูดข้อความและตรวจดูว่า N-gram ทั่วไปคืออะไร โดยปรับ n ทุกครั้งเพื่อดูว่าคุณพบรูปแบบต่างๆ กันในหน้าระดับสูงหรือไม่
หากคุณลองคิดดูสักครู่ก็สมเหตุสมผลกว่ามาก เนื่องจากคีย์เวิร์ดแต่ละคำไม่ได้บอกอะไรเกี่ยวกับบริบทให้คุณทราบ
ผลไม้ห้อยต่ำ
หนึ่งในสิ่งที่น่ารักที่สุดที่ควรทำคือการตรวจสอบผลไม้ที่ห้อยต่ำ ซึ่งคุณสามารถปรับปรุงได้ง่าย ๆ เพื่อดูผลลัพธ์ที่ดีโดยเร็วที่สุด นี่เป็นสิ่งสำคัญในขั้นตอนแรกของทุกโครงการ SEO เพื่อโน้มน้าวผู้มีส่วนได้ส่วนเสียของคุณ ดังนั้น หากมีโอกาสที่จะใช้ประโยชน์จากหน้าดังกล่าว ก็แค่ทำมัน!
เกณฑ์ของเราในการพิจารณาหน้าเว็บดังกล่าวเป็นปริมาณสำหรับการแสดงผลและ CTR กล่าวคือ เรากำลังกรองแถวที่อยู่ในการแสดงผล 80% แรกสุด แต่อยู่ใน 20% ที่ได้รับ CTR ต่ำที่สุด แถวเหล่านี้จะมี CTR ที่แย่กว่า 80% ของส่วนที่เหลือ
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascending = False))
ตอนนี้คุณมีรายการที่มีโอกาสทั้งหมดจัดเรียงตามการแสดงผล โดยเรียงลำดับจากมากไปน้อย
คุณสามารถนึกถึงเกณฑ์อื่นๆ เพื่อกำหนดว่าผลไม้ชนิดใดที่ห้อยต่ำ ตามความต้องการและขนาดของเว็บไซต์ของคุณ
สำหรับเว็บไซต์ขนาดเล็ก คุณอาจพิจารณามองหาเปอร์เซ็นต์ที่สูงกว่า ในขณะที่เว็บไซต์ขนาดใหญ่ คุณควรได้รับข้อมูลมากมายตามเกณฑ์ที่ฉันใช้อยู่
[Ebook] SEO เทคนิคสำหรับคนคิดไม่เก่ง
 อ่านอีบุ๊ก
อ่านอีบุ๊กขอแนะนำ querycat: การจำแนกประเภทและการเชื่อมโยง
Querycat เป็นไลบรารีที่เรียบง่ายแต่ทรงพลังซึ่งมีการทำเหมืองกฎการเชื่อมโยงสำหรับคีย์เวิร์ดที่ทำคลัสเตอร์และอีกมากมาย ฉันจะแสดงให้คุณเห็นเฉพาะการเชื่อมโยงเนื่องจากมีคุณค่ามากกว่าในการวิเคราะห์ประเภทนี้
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับไลบรารีที่ยอดเยี่ยมนี้ได้โดยดูที่ที่เก็บ querycat GitHub
แนะนำสั้นๆ เกี่ยวกับการเรียนรู้กฎสมาคม
การเรียนรู้กฎของสมาคมคือวิธีการค้นหากฎที่กำหนดความสัมพันธ์และการเกิดขึ้นร่วมระหว่างชุดของรายการ ซึ่งแตกต่างเล็กน้อยจากวิธีการเรียนรู้ของเครื่องอื่นที่ไม่มีการควบคุม ซึ่งเรียกว่าการจัดกลุ่ม
เป้าหมายสุดท้ายก็เหมือนกัน การรับกลุ่มของคำหลักเพื่อทำความเข้าใจว่าเว็บไซต์ของเรามีการดำเนินการอย่างไรสำหรับบางหัวข้อ
Querycat ให้คุณเลือกระหว่างสองอัลกอริทึม: Apriori และ FP-Growth เราจะเลือกอย่างหลังเพื่อการแสดงที่ดีขึ้น ดังนั้นคุณไม่ต้องสนใจอันแรก
FP-Growth เป็นเวอร์ชันปรับปรุงของ Apriori เพื่อค้นหารูปแบบที่พบบ่อยในชุดข้อมูล การเรียนรู้กฎของสมาคมมีประโยชน์มากสำหรับธุรกรรมอีคอมเมิร์ซเช่นกัน คุณอาจสนใจที่จะทำความเข้าใจว่าผู้คนซื้ออะไรร่วมกัน เป็นต้น
ในกรณีนี้ เรามุ่งเน้นที่การสืบค้นข้อมูลทั้งหมด แต่แอปพลิเคชันอื่นๆ ที่ฉันพูดถึงอาจเป็นแนวคิดที่มีประโยชน์อีกอย่างสำหรับข้อมูล Google Analytics
การอธิบายอัลกอริธึมเหล่านี้จากมุมมองของโครงสร้างข้อมูลนั้นค่อนข้างท้าทาย และในความเห็นของฉัน ไม่จำเป็นสำหรับงาน SEO ของคุณ ฉันจะอธิบายแนวคิดพื้นฐานบางอย่างเพื่อทำความเข้าใจความหมายของพารามิเตอร์
องค์ประกอบหลัก 3 ประการของ 2 อัลกอริธึมคือ:
- สนับสนุน – เป็นการแสดงออกถึงความนิยมของรายการหรือชุดรายการ ในเชิงเทคนิค คือจำนวนธุรกรรมที่ข้อความค้นหา X และข้อความค้นหา Y ปรากฏร่วมกันหารด้วยจำนวนธุรกรรมทั้งหมด
นอกจากนี้ยังสามารถใช้เป็นเกณฑ์ในการลบรายการที่ไม่บ่อยนัก มีประโยชน์มากสำหรับการเพิ่มนัยสำคัญทางสถิติและประสิทธิภาพ การตั้งค่าการสนับสนุนขั้นต่ำที่ดีนั้นดีมาก - ความมั่นใจ – คุณสามารถมองมันเป็นความน่าจะเป็นของการเกิดขึ้นร่วมกันสำหรับเงื่อนไข
- การยกระดับ – อัตราส่วนระหว่างการสนับสนุนสำหรับ (ระยะที่ 1 และระยะที่ 2) และการสนับสนุนระยะที่ 1 เราสามารถดูค่าของมันเพื่อรับข้อมูลเชิงลึกเกี่ยวกับความสัมพันธ์ระหว่างเงื่อนไขต่างๆ หากมากกว่า 1 เงื่อนไขจะสัมพันธ์กัน ถ้าน้อยกว่า 1 เงื่อนไขไม่น่าจะมีการเชื่อมโยง: ถ้าการเพิ่มเป็น 1 (หรือใกล้เคียงกัน) จะไม่มีความสัมพันธ์ที่สำคัญ
รายละเอียดเพิ่มเติมมีอยู่ในบทความนี้เกี่ยวกับ querycat ที่เขียนโดยผู้เขียนห้องสมุด
ตอนนี้เราพร้อมที่จะไปยังส่วนที่ใช้งานได้จริงแล้ว
นำเข้า querycat
query_cat = querycat.Categorize (df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#create กลุ่มเพื่อกรองหมวดหมู่ที่มีน้อยกว่า 15 คลิก (จำนวนโดยพลการ)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
กลุ่มตัวกรอง
#ใส่ฟิลเตอร์
df = df.merge(กลุ่มตัวกรอง, on=['category','category'], how='inner')
เราได้กรองหมวดหมู่ที่ไม่ค่อยบ่อยในกระบวนการนี้ ฉันเลือก 15 หมวดหมู่เป็นเกณฑ์มาตรฐานในกรณีของฉัน เป็นเพียงตัวเลขตามอำเภอใจ ไม่มีเกณฑ์ใดอยู่เบื้องหลัง
มาตรวจสอบหมวดหมู่ของเราด้วยตัวอย่างต่อไปนี้:
df['หมวดหมู่'].value_counts()
แล้ว 10 หมวดหมู่ที่มีการคลิกมากที่สุดล่ะ? มาดูกันว่าเรามีคำถามกี่ข้อสำหรับคำถามแต่ละข้อ
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
จำนวนที่จะเลือกนั้นเป็นสิ่งที่ไม่แน่นอน อย่าลืมเลือกหมายเลขที่กรองกลุ่มเปอร์เซ็นต์ที่ดีออก แนวคิดที่เป็นไปได้ประการหนึ่งคือการได้ค่ามัธยฐานของการแสดงผลและลดลงต่ำสุด 50% โดยที่คุณต้องการยกเว้นกลุ่มเล็กๆ
รับคลัสเตอร์และจะทำอย่างไรกับเอาต์พุต
คำแนะนำของฉันคือส่งออก dataframe ใหม่ของคุณเพื่อหลีกเลี่ยงการเรียกใช้ FP-Growth อีกครั้ง โปรดทำเพื่อประหยัดเวลาที่มีประโยชน์
ทันทีที่คุณมีคลัสเตอร์ คุณต้องการทราบจำนวนคลิกและการแสดงผลสำหรับคลัสเตอร์แต่ละรายการ เพื่อประเมินว่าส่วนใดจำเป็นต้องได้รับการปรับปรุงมากที่สุด
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
ด้วยการจัดการข้อมูลบางอย่าง เราจึงสามารถปรับปรุงผลการเชื่อมโยงของเรา และมีการคลิกและการแสดงผลสำหรับแต่ละคลัสเตอร์
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#ลบข้อความค้นหาที่ซ้ำกัน แล้วจัดเรียงตามตัวอักษร
group_ex['query'] = group_ex['query'].apply(แลมบ์ดา x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
ตอนนี้คุณมีไฟล์ CSV ที่มีกลุ่มคีย์เวิร์ดทั้งหมดพร้อมทั้งการคลิกและการแสดงผล
#save ไฟล์ csv และดาวน์โหลดลงในเครื่องของคุณ หากคุณใช้ Safari โปรดลองเปลี่ยนไปใช้ Chrome เพื่อดาวน์โหลดไฟล์เหล่านี้เนื่องจากอาจไม่ทำงาน
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
จริงๆ แล้ว มีวิธีการที่ดีกว่าสำหรับการจัดกลุ่ม นี่เป็นเพียงตัวอย่างเกี่ยวกับวิธีที่คุณสามารถใช้ querycat เพื่อทำงานหลายอย่างเพื่อใช้งานได้ทันที เป้าหมายหลักที่นี่คือการรับข้อมูลเชิงลึกให้มากที่สุด โดยเฉพาะอย่างยิ่งสำหรับเว็บไซต์ใหม่ที่คุณไม่มีความรู้มากนัก
ในตอนนี้ แนวทางที่ดีที่สุดเกี่ยวข้องกับความหมาย ดังนั้น หากคุณต้องการเน้นที่การจัดกลุ่ม ฉันแนะนำให้คุณพิจารณาเรียนรู้กราฟหรือการฝัง
อย่างไรก็ตาม นี่เป็นหัวข้อขั้นสูง หากคุณเป็นมือใหม่ และคุณสามารถลองใช้แอพ Streamlit ที่สร้างไว้ล่วงหน้าบางตัวที่พร้อมใช้งานออนไลน์ได้
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมบทสรุปและจะเป็นอย่างไรต่อไป
Python สามารถให้ความช่วยเหลือที่สำคัญในการวิเคราะห์เว็บไซต์ของคุณ และช่วยให้คุณสามารถรวมการล้างข้อมูล การแสดงภาพ และการวิเคราะห์ไว้ในที่เดียว การดึงข้อมูลจาก GSC API เป็นสิ่งจำเป็นอย่างยิ่งสำหรับงานขั้นสูง และเป็นการแนะนำที่ "อ่อนโยน" เกี่ยวกับระบบอัตโนมัติของข้อมูล
ในขณะที่คุณสามารถทำการคำนวณขั้นสูงได้อีกมากมายด้วย Python คำแนะนำของฉันคือการตรวจสอบความเหมาะสมในแง่ของมูลค่า SEO
ตัวอย่างเช่น จำนวนการสืบค้นมีความสำคัญมากกว่าในระยะยาว เนื่องจากคุณต้องการให้เว็บไซต์ของคุณได้รับการพิจารณาสำหรับการสืบค้นเพิ่มเติม
การใช้โน้ตบุ๊กช่วยได้มากในการบรรจุโค้ดพร้อมความคิดเห็น และนี่คือเหตุผลหลักที่ฉันแนะนำให้คุณคุ้นเคยกับ Google Colab
นี่เป็นเพียงจุดเริ่มต้นของสิ่งที่การวิเคราะห์ข้อมูลสามารถนำเสนอให้กับคุณได้ เนื่องจากแนวคิดที่ดีที่สุดมาจากการรวมชุดข้อมูลต่างๆ
Google Search Console เป็นเครื่องมือที่ทรงพลังและฟรีทั้งหมด ปริมาณข้อมูลที่เป็นประโยชน์ที่คุณจะได้รับจากมันแทบจะไม่จำกัดอยู่ในมือที่ดี