
CTR Curve คืออะไรและจะคำนวณด้วย Python ได้อย่างไร
เผยแพร่แล้ว: 2022-03-22เส้นโค้ง CTR หรืออีกนัยหนึ่งคืออัตราการคลิกผ่านแบบออร์แกนิกตามตำแหน่ง คือข้อมูลที่แสดงจำนวนลิงก์สีน้ำเงินบนหน้าผลลัพธ์ของเครื่องมือค้นหา (SERP) ที่ได้รับ CTR ตามตำแหน่ง ตัวอย่างเช่น โดยส่วนใหญ่ ลิงก์สีน้ำเงินแรกใน SERP จะได้รับ CTR มากที่สุด
ในตอนท้ายของบทช่วยสอนนี้ คุณจะสามารถคำนวณเส้นโค้ง CTR ของไซต์ของคุณตามไดเร็กทอรีของไซต์ หรือคำนวณ CTR ทั่วไปตามข้อความค้นหา CTR ผลลัพธ์ของโค้ด Python ของฉันคือพล็อตแบบกล่องและแท่งที่อธิบายกราฟ CTR ของไซต์
หากคุณเป็นมือใหม่และไม่ทราบคำจำกัดความ CTR ฉันจะอธิบายเพิ่มเติมในหัวข้อถัดไป
CTR ทั่วไปหรืออัตราการคลิกผ่านแบบอินทรีย์คืออะไร
CTR มาจากการแบ่งคลิกทั่วไปออกเป็นการแสดงผล ตัวอย่างเช่น ถ้ามีคน 100 คนค้นหาคำว่า “apple” และ 30 คนคลิกที่ผลลัพธ์แรก CTR ของผลลัพธ์แรกคือ 30/100 * 100 = 30%
ซึ่งหมายความว่าจากการค้นหาทุกๆ 100 ครั้ง คุณจะได้รับ 30% สิ่งสำคัญคือต้องจำไว้ว่าการแสดงผลใน Google Search Console (GSC) ไม่ได้ขึ้นอยู่กับลักษณะที่ปรากฏของลิงก์เว็บไซต์ของคุณในวิวพอร์ตของผู้ค้นหา หากผลการค้นหาปรากฏใน SERP ของผู้ค้นหา คุณจะได้รับการแสดงผลหนึ่งครั้งสำหรับการค้นหาแต่ละครั้ง
กราฟ CTR มีประโยชน์อย่างไร?
หนึ่งในหัวข้อที่สำคัญใน SEO คือการคาดคะเนปริมาณการเข้าชมแบบออร์แกนิก เพื่อปรับปรุงการจัดอันดับในชุดคำหลักบางชุด เราต้องจัดสรรเงินหลายพันดอลลาร์เพื่อให้ได้ส่วนแบ่งเพิ่มขึ้น แต่คำถามในระดับการตลาดของบริษัทมักคือ "การจัดสรรงบประมาณนี้คุ้มหรือไม่"
นอกจากนี้ นอกจากหัวข้อของการจัดสรรงบประมาณสำหรับโครงการ SEO แล้ว เราจำเป็นต้องได้รับค่าประมาณของการเข้าชมที่เกิดขึ้นเองของเราที่เพิ่มขึ้นหรือลดลงในอนาคต ตัวอย่างเช่น หากเราเห็นคู่แข่งรายหนึ่งพยายามอย่างหนักที่จะแทนที่เราในตำแหน่งอันดับ SERP ของเรา สิ่งนี้จะเสียค่าใช้จ่ายเท่าไร?
ในสถานการณ์นี้หรือสถานการณ์อื่นๆ เราต้องการเส้นโค้ง CTR ของไซต์ของเรา
ทำไมเราไม่ใช้การศึกษาเส้นโค้ง CTR และใช้ข้อมูลของเรา
ตอบง่ายๆ ว่าไม่มีเว็บไซต์อื่นใดที่มีลักษณะเว็บไซต์ของคุณใน SERP
มีงานวิจัยมากมายสำหรับเส้นโค้ง CTR ในอุตสาหกรรมต่างๆ และคุณลักษณะ SERP ที่แตกต่างกัน แต่เมื่อคุณมีข้อมูลแล้ว เหตุใดไซต์ของคุณจึงไม่คำนวณ CTR แทนที่จะอาศัยแหล่งข้อมูลของบุคคลที่สาม
มาเริ่มทำสิ่งนี้กันเถอะ
การคำนวณ CTR Curve ด้วย Python: เริ่มต้น
ก่อนที่เราจะพูดถึงขั้นตอนการคำนวณอัตราการคลิกผ่านของ Google ตามตำแหน่ง คุณจำเป็นต้องรู้ไวยากรณ์พื้นฐานของ Python และมีความเข้าใจพื้นฐานเกี่ยวกับไลบรารี Python ทั่วไป เช่น Pandas วิธีนี้จะช่วยให้คุณเข้าใจโค้ดได้ดีขึ้นและปรับแต่งในแบบของคุณ
นอกจากนี้ สำหรับขั้นตอนนี้ ฉันชอบใช้สมุดบันทึก Jupyter
สำหรับการคำนวณ CTR แบบออร์แกนิกตามตำแหน่ง เราจำเป็นต้องใช้ไลบรารี Python เหล่านี้:
- แพนด้า
- พล็อตเรื่อง
- คาเลโด
นอกจากนี้ เราจะใช้ไลบรารีมาตรฐาน Python เหล่านี้:
- os
- json
ดังที่ฉันได้กล่าวไปแล้ว เราจะสำรวจสองวิธีในการคำนวณเส้นโค้ง CTR ที่แตกต่างกัน บางขั้นตอนจะเหมือนกันในทั้งสองวิธี: การนำเข้าแพ็คเกจ Python การสร้างโฟลเดอร์เอาต์พุตรูปภาพพล็อต และการตั้งค่าขนาดการลงจุดเอาต์พุต
# การนำเข้าไลบรารีที่จำเป็นสำหรับกระบวนการของเรา นำเข้าระบบปฏิบัติการ นำเข้า json นำเข้าแพนด้าเป็น pd นำเข้า plotly.express เป็น px นำเข้า plotly.io เป็น pio นำเข้าคาไลโด
ที่นี่เราสร้างโฟลเดอร์เอาต์พุตสำหรับบันทึกภาพพล็อตของเรา
# การสร้างโฟลเดอร์เอาต์พุตภาพพล็อต
ถ้าไม่ใช่ os.path.exists('./output plot images'):
os.mkdir('./ภาพพล็อตเอาต์พุต')
คุณสามารถเปลี่ยนความสูงและความกว้างของรูปภาพพล็อตผลลัพธ์ด้านล่าง
# การตั้งค่าความกว้างและความสูงของภาพพล็อตเอาต์พุต pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
เริ่มต้นด้วยวิธีแรกที่ยึดตาม CTR ของข้อความค้นหา
วิธีแรก: คำนวณเส้นโค้ง CTR สำหรับทั้งเว็บไซต์หรือคุณสมบัติ URL เฉพาะตามการสืบค้น CTR
ก่อนอื่น เราต้องได้รับคำถามทั้งหมดของเราด้วย CTR อันดับเฉลี่ย และการแสดงผล ฉันชอบใช้ข้อมูลหนึ่งเดือนเต็มจากเดือนที่ผ่านมา
ในการดำเนินการนี้ ฉันได้รับข้อมูลการสืบค้นจากแหล่งข้อมูลการแสดงผลไซต์ GSC ใน Google Data Studio หรือคุณอาจรับข้อมูลนี้ด้วยวิธีใดก็ได้ที่ต้องการ เช่น GSC API หรือส่วนเสริม Google ชีต "Search Analytics for Sheets" เป็นต้น ด้วยวิธีนี้ หากบล็อกหรือหน้าผลิตภัณฑ์ของคุณมีคุณสมบัติ URL เฉพาะ คุณจะใช้เป็นแหล่งข้อมูลใน GDS ได้
1. รับข้อมูลการสืบค้นจาก Google Data Studio (GDS)
เพื่อทำสิ่งนี้:
- สร้างรายงานและเพิ่มแผนภูมิตารางเข้าไป
- เพิ่มแหล่งข้อมูล "การแสดงผลไซต์" ของไซต์ของคุณในรายงาน
- เลือก "คำค้นหา" สำหรับมิติข้อมูลและ "ctr" "ตำแหน่งเฉลี่ย" และ"'การแสดงผล" สำหรับเมตริก
- กรองคำค้นหาที่มีชื่อแบรนด์โดยการสร้างตัวกรอง (คำค้นหาที่มีแบรนด์จะมีอัตราการคลิกผ่านสูงกว่า ซึ่งจะลดความถูกต้องของข้อมูลของเรา)
- คลิกขวาที่ตารางแล้วคลิกส่งออก
- บันทึกผลลัพธ์เป็น CSV
2. กำลังโหลดข้อมูลของเราและติดป้ายกำกับข้อความค้นหาตามตำแหน่ง
สำหรับการจัดการ CSV ที่ดาวน์โหลด เราจะใช้ Pandas
แนวทางปฏิบัติที่ดีที่สุดสำหรับโครงสร้างโฟลเดอร์ของโครงการคือการมีโฟลเดอร์ 'ข้อมูล' ที่เราบันทึกข้อมูลทั้งหมดของเรา
ฉันไม่ได้ทำสิ่งนี้ เพื่อความลื่นไหลในบทช่วยสอน
query_df = pd.read_csv('./downloaded_data.csv')
จากนั้นเราจะติดป้ายกำกับคำค้นหาของเราตามตำแหน่งของพวกเขา ฉันสร้างลูป 'for' สำหรับการติดป้ายกำกับตำแหน่ง 1 ถึง 10
ตัวอย่างเช่น หากอันดับเฉลี่ยของข้อความค้นหาคือ 2.2 หรือ 2.9 รายการนั้นจะมีข้อความกำกับว่า "2" ด้วยการจัดการช่วงตำแหน่งเฉลี่ย คุณสามารถบรรลุความแม่นยำที่คุณต้องการ
สำหรับฉันอยู่ในช่วง (1, 11):
query_df.loc[(query_df['Average Position'] >= i) & (
query_df['ตำแหน่งเฉลี่ย'] < i + 1), 'ป้ายกำกับตำแหน่ง'] = i
ตอนนี้ เราจะจัดกลุ่มคำค้นหาตามตำแหน่งของพวกเขา ซึ่งช่วยให้เราจัดการข้อมูลการสืบค้นแต่ละตำแหน่งได้ดีขึ้นในขั้นตอนต่อไป
query_grouped_df = query_df.groupby(['position label'])
3. การกรองข้อความค้นหาตามข้อมูลสำหรับการคำนวณเส้นโค้ง CTR
วิธีที่ง่ายที่สุดในการคำนวณเส้นโค้ง CTR คือการใช้ข้อมูลการสืบค้นทั้งหมดและทำการคำนวณ อย่างไรก็ตาม; อย่าลืมนึกถึงข้อความค้นหาเหล่านั้นด้วยการแสดงผลหนึ่งครั้งในตำแหน่งที่สองในข้อมูลของคุณ
คำค้นหาเหล่านี้จากประสบการณ์ของฉัน ทำให้เกิดความแตกต่างอย่างมากในผลลัพธ์สุดท้าย แต่วิธีที่ดีที่สุดคือลองด้วยตัวเอง ขึ้นอยู่กับชุดข้อมูล นี้อาจมีการเปลี่ยนแปลง
ก่อนที่เราจะเริ่มขั้นตอนนี้ เราจำเป็นต้องสร้างรายการสำหรับผลลัพธ์การพล็อตแท่งและ DataFrame สำหรับจัดเก็บการสืบค้นที่ถูกจัดการของเรา
# การสร้าง DataFrame สำหรับจัดเก็บ 'query_df' ข้อมูลที่จัดการ modified_df = pd.DataFrame() # รายการบันทึกแต่ละตำแหน่งหมายถึงแผนภูมิแท่งของเรา mean_ctr_list = []
จากนั้น เราวนรอบกลุ่ม query_grouped_df และผนวกข้อความค้นหา 20% อันดับแรกตามการแสดงผลไปยัง DataFrame ที่ modified_df แล้ว
หากการคำนวณ CTR ตาม 20% อันดับแรกของข้อความค้นหาที่มีการแสดงผลมากที่สุดนั้นไม่ดีที่สุดสำหรับคุณ คุณสามารถเปลี่ยนได้
ในการทำเช่นนั้น คุณสามารถเพิ่มหรือลดได้โดยจัดการ .quantile(q=your_optimal_number, interpolation='lower')] และ your_optimal_number ต้องอยู่ระหว่าง 0 ถึง 1
ตัวอย่างเช่น หากคุณต้องการได้รับ 30% แรกของข้อความค้นหา your_optimal_num คือผลต่างระหว่าง 1 และ 0.3 (0.7)
สำหรับฉันอยู่ในช่วง (1, 11):
# ข้อยกเว้นสำหรับการจัดการสถานการณ์ที่ไดเร็กทอรีไม่มีข้อมูลสำหรับบางตำแหน่ง
ลอง:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolation='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append (tmp_df, forget_index=จริง)
ยกเว้น KeyError:
mean_ctr_list.append(0)
# กำลังลบ DataFrame 'tmp_df' เพื่อลดการใช้หน่วยความจำ
เดล [tmp_df]
4. วาดโครงกล่อง
ขั้นตอนนี้คือสิ่งที่พวกเรารอคอย ในการวาดแผนผัง เราสามารถใช้ Matplotlib, seaborn เป็นเสื้อคลุมสำหรับ Matplotlib หรือ Plotly
โดยส่วนตัวแล้ว ฉันคิดว่าการใช้ Plotly เป็นหนึ่งในตัวเลือกที่เหมาะสมที่สุดสำหรับนักการตลาดที่รักการสำรวจข้อมูล
เมื่อเปรียบเทียบกับ Mathplotlib แล้ว Plotly นั้นใช้งานง่ายมาก และด้วยโค้ดเพียงไม่กี่บรรทัด คุณก็สามารถวาดโครงเรื่องที่สวยงามได้
# 1. โครงกล่อง
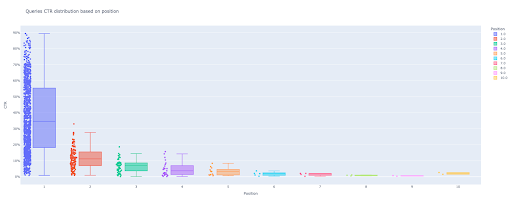
box_fig = px.box (modified_df, x='position label', y='Site CTR', title='สอบถามการกระจาย CTR ตามตำแหน่ง',
points='all', color='position label', labels={'position label': 'Position', 'Site CTR': 'CTR'})
# กำลังแสดงขีด x-axes ทั้งหมดสิบตัว
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# การเปลี่ยนรูปแบบขีดแกน y เป็นเปอร์เซ็นต์
box_fig.update_yaxes(tickformat=".0%")
# กำลังบันทึกพล็อตไปที่ไดเร็กทอรี 'เอาต์พุตพล็อตอิมเมจ'
box_fig.write_image('./output plot images/queries box plot CTR curve.png')
มีเพียงสี่บรรทัดนี้ คุณจะได้แผนภาพกล่องที่สวยงามและเริ่มสำรวจข้อมูลของคุณ
หากคุณต้องการโต้ตอบกับคอลัมน์นี้ ให้เรียกใช้เซลล์ใหม่:
box_fig.show()
ตอนนี้ คุณมีพล็อตกล่องที่น่าสนใจในเอาต์พุตที่โต้ตอบได้
เมื่อคุณวางเมาส์เหนือพล็อตแบบโต้ตอบในเซลล์ผลลัพธ์ ตัวเลขสำคัญที่คุณสนใจคือ "ผู้ชาย" ของแต่ละตำแหน่ง
นี่แสดง CTR เฉลี่ยสำหรับแต่ละตำแหน่ง เนื่องจากความสำคัญเฉลี่ย ดังที่คุณจำได้ เราจึงสร้างรายการที่มีค่าเฉลี่ยของแต่ละตำแหน่ง ต่อไป เราจะไปยังขั้นตอนถัดไปเพื่อวาดกราฟแท่งตามค่าเฉลี่ยของแต่ละตำแหน่ง
5. การวาดพล็อตแท่ง
เช่นเดียวกับพล็อตกล่อง การวาดพล็อตแท่งนั้นง่ายมาก คุณสามารถเปลี่ยน title ของแผนภูมิโดยแก้ไขอาร์กิวเมนต์ title px.bar()
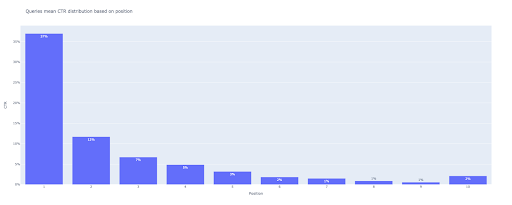
# 2. พล็อตบาร์
bar_fig = px.bar(x=[pos สำหรับ pos ในช่วง (1, 11)], y=mean_ctr_list, title='Queries หมายถึงการกระจาย CTR ตามตำแหน่ง',
labels={'x': 'Position', 'y': 'CTR'}, text_auto=True)
# กำลังแสดงขีด x-axes ทั้งหมดสิบตัว
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# การเปลี่ยนรูปแบบขีดแกน y เป็นเปอร์เซ็นต์
bar_fig.update_yaxes(tickformat='.0%')
# กำลังบันทึกพล็อตไปที่ไดเร็กทอรี 'เอาต์พุตพล็อตอิมเมจ'
bar_fig.write_image('./output plot images/queries bar plot CTR curve.png')
ที่ผลลัพธ์เราได้รับพล็อตนี้:
เช่นเดียวกับพล็อตกล่อง คุณสามารถโต้ตอบกับพล็อตนี้ได้โดยเรียกใช้ bar_fig.show()
แค่นั้นแหละ! ด้วยโค้ดไม่กี่บรรทัด เราได้รับอัตราการคลิกผ่านแบบออร์แกนิกตามตำแหน่งด้วยข้อมูลการสืบค้นของเรา
หากคุณมีพร็อพเพอร์ตี้ URL สำหรับแต่ละโดเมนย่อยหรือไดเร็กทอรีของคุณ คุณสามารถรับเคียวรีคุณสมบัติ URL เหล่านี้และคำนวณเส้นโค้ง CTR สำหรับโดเมนย่อยหรือไดเร็กทอรีของคุณ
[กรณีศึกษา] การปรับปรุงการจัดอันดับ การเข้าชมแบบออร์แกนิก และการขายด้วยการวิเคราะห์ไฟล์บันทึก
 อ่านกรณีศึกษา
อ่านกรณีศึกษาวิธีที่สอง: การคำนวณเส้นโค้ง CTR ตาม URL ของหน้า Landing Page สำหรับแต่ละไดเรกทอรี
ในวิธีแรก เราคำนวณ CTR ทั่วไปตาม CTR ของข้อความค้นหา แต่ด้วยวิธีการนี้ เรารับข้อมูลหน้า Landing Page ทั้งหมด จากนั้นจึงคำนวณเส้นโค้ง CTR สำหรับไดเรกทอรีที่เลือก

ฉันรักวิธีนี้ ดังที่คุณทราบ CTR สำหรับหน้าผลิตภัณฑ์ของเรานั้นแตกต่างจากของบล็อกโพสต์หรือหน้าอื่นๆ มาก แต่ละไดเร็กทอรีมี CTR ของตัวเองตามตำแหน่ง
ในลักษณะขั้นสูงขึ้น คุณสามารถจัดหมวดหมู่หน้าไดเรกทอรีแต่ละหน้าและรับอัตราการคลิกผ่านทั่วไปของ Google ตามตำแหน่งของชุดของหน้า
1. รับข้อมูลหน้า Landing Page
เช่นเดียวกับวิธีแรก การรับข้อมูล Google Search Console (GSC) มีหลายวิธี ในวิธีนี้ ฉันชอบรับข้อมูลหน้า Landing Page จาก GSC API explorer ที่ https://developers.google.com/webmaster-tools/v1/searchanalytics/query
สำหรับสิ่งที่จำเป็นในแนวทางนี้ GDS ไม่ได้ให้ข้อมูลหน้าที่เชื่อมโยงไปถึงที่ชัดเจน นอกจากนี้ คุณยังใช้ส่วนเสริม Google ชีต "Search Analytics for Sheets" ได้อีกด้วย
โปรดทราบว่า Google API Explorer นั้นเหมาะสมกับไซต์เหล่านั้นที่มีข้อมูลน้อยกว่า 25,000 เพจ สำหรับไซต์ขนาดใหญ่ คุณสามารถรับข้อมูลหน้า Landing Page บางส่วนและเชื่อมโยงเข้าด้วยกัน เขียนสคริปต์ Python ด้วยลูป "for" เพื่อดึงข้อมูลทั้งหมดของคุณออกจาก GSC หรือใช้เครื่องมือของบุคคลที่สาม
ในการรับข้อมูลจาก Google API Explorer:
- ไปที่หน้าเอกสาร "Search Analytics: query" GSC API: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- ใช้ API Explorer ที่อยู่ทางด้านขวามือของหน้า
- ในช่อง “siteUrl” ให้ใส่ที่อยู่คุณสมบัติ URL ของคุณ เช่น
https://www.example.comนอกจากนี้ คุณสามารถแทรกคุณสมบัติโดเมนของคุณดังนี้sc-domain:example.com - ในช่อง "เนื้อหาคำขอ" ให้เพิ่ม
startDateและendDateฉันชอบรับข้อมูลของเดือนที่แล้ว รูปแบบของค่าเหล่านี้คือYYYY-MM-DD - เพิ่ม
dimensionและตั้งค่าเป็นpage - สร้าง "dimensionFilterGroups" และกรองข้อความค้นหาด้วยชื่อรูปแบบแบรนด์ (แทนที่
brand_variation_namesด้วยชื่อแบรนด์ของคุณ RegExp) - เพิ่ม
rawLimitและตั้งค่าเป็น 25000 - ในตอนท้ายให้กดปุ่ม 'EXECUTE'
คุณยังสามารถคัดลอกและวางเนื้อหาคำขอด้านล่าง:
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"ขนาด": [
"หน้าหนังสือ"
],
"dimensionFilterGroups": [
{
"ตัวกรอง": [
{
"มิติ": "QUERY",
"expression": "brand_variation_names",
"ตัวดำเนินการ": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
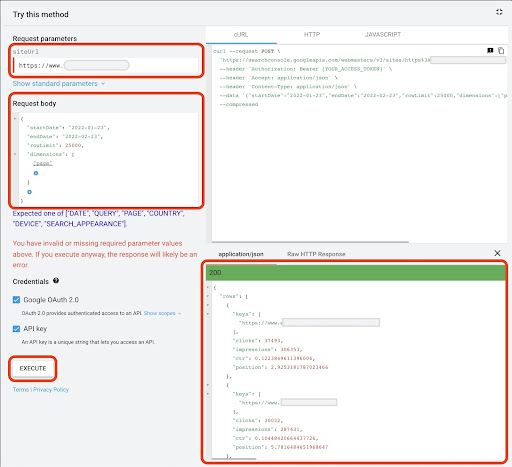
หลังจากดำเนินการตามคำขอแล้ว เราต้องบันทึก เนื่องจากรูปแบบการตอบกลับ เราจำเป็นต้องสร้างไฟล์ JSON คัดลอกการตอบกลับ JSON ทั้งหมด และบันทึกด้วยชื่อไฟล์ที่ downloaded_data.json _data.json
หากไซต์ของคุณมีขนาดเล็ก เช่น ไซต์ของบริษัท SASS และข้อมูลหน้า Landing Page ของคุณมีน้อยกว่า 1,000 หน้า คุณสามารถตั้งค่าวันที่ของคุณใน GSC และส่งออกข้อมูลหน้า Landing Page สำหรับแท็บ "PAGES" เป็นไฟล์ CSV ได้อย่างง่ายดาย
2. กำลังโหลดข้อมูลหน้า Landing Page
เพื่อประโยชน์ของบทช่วยสอนนี้ ฉันจะถือว่าคุณได้รับข้อมูลจาก Google API Explorer และบันทึกไว้ในไฟล์ JSON สำหรับการโหลดข้อมูลนี้ เราต้องรันโค้ดด้านล่าง:
# การสร้าง DataFrame สำหรับข้อมูลที่ดาวน์โหลด
ด้วย open('./downloaded_data.json') เป็น json_file:
Landings_data = json.loads(json_file.read())['rows']
Landings_df = pd.DataFrame (landings_data)
นอกจากนี้ เราจำเป็นต้องเปลี่ยนชื่อคอลัมน์เพื่อให้มีความหมายมากขึ้น และใช้ฟังก์ชันเพื่อรับ URL ของหน้า Landing Page โดยตรงในคอลัมน์ "หน้า Landing Page"
# เปลี่ยนชื่อคอลัมน์ 'คีย์' เป็นคอลัมน์ 'แลนดิ้งเพจ' และแปลงรายการ 'แลนดิ้งเพจ' เป็น URL
Landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
Landings_df['หน้า Landing Page'] = Landing Page ['หน้า Landing Page'].apply (แลมบ์ดา x: x[0])
3. รับไดเรกทอรีรากของหน้า Landing Page ทั้งหมด
ก่อนอื่น เราต้องกำหนดชื่อเว็บไซต์ของเรา
# การกำหนดชื่อเว็บไซต์ของคุณระหว่างคำพูด ตัวอย่างเช่น 'https://www.example.com/' หรือ 'http://mydomain.com/' site_name = ''
จากนั้นเราเรียกใช้ฟังก์ชันบน URL ของหน้า Landing Page เพื่อรับไดเรกทอรีรากและดูในผลลัพธ์เพื่อเลือก
# รับไดเรกทอรีหน้า Landing Page (URL) แต่ละรายการ
Landings_df['directory'] = landings_df['landing page'].str.extract(pat=f'((?<={site_name})[^/]+)')
# ในการรับไดเร็กทอรีทั้งหมดในเอาต์พุตเราต้องจัดการตัวเลือก Pandas
pd.set_option("display.max_rows", ไม่มี)
# ไดเรกทอรีเว็บไซต์
Landings_df['ไดเรกทอรี'].value_counts()
จากนั้น เราเลือกไดเร็กทอรีที่เราต้องการเพื่อให้ได้กราฟ CTR
แทรกไดเร็กทอรีลงในตัวแปร important_directories _ไดเร็กทอรี
ตัวอย่างเช่น product,tag,product-category,mag แยกค่าไดเรกทอรีด้วยเครื่องหมายจุลภาค
major_directories = ''
major_directories = major_directories.split(',')
4. การติดฉลากและการจัดกลุ่มหน้า Landing Page
เช่นเดียวกับข้อความค้นหา เรายังติดป้ายกำกับหน้า Landing Page ตามอันดับเฉลี่ย
# ติดฉลากตำแหน่งหน้าที่เชื่อมโยงไปถึง
สำหรับฉันอยู่ในช่วง (1, 11):
Landings_df.loc[(landings_df['position'] >= i) & (
Landings_df['position'] < i + 1), 'position label'] = i
จากนั้น เราจัดกลุ่มหน้า Landing Page ตาม "ไดเรกทอรี"
# การจัดกลุ่มหน้า Landing Page ตามค่า 'ไดเรกทอรี' ของพวกเขา Landings_grouped_df = Landings_df.groupby (['ไดเรกทอรี'])
5. การสร้างกล่องและแปลงแท่งสำหรับไดเร็กทอรีของเรา
ในวิธีก่อนหน้านี้ เราไม่ได้ใช้ฟังก์ชันเพื่อสร้างแปลง อย่างไรก็ตาม; สำหรับการคำนวณเส้นโค้ง CTR สำหรับหน้า Landing Page ต่างๆ โดยอัตโนมัติ เราจำเป็นต้องกำหนดฟังก์ชัน
# ฟังก์ชั่นสำหรับสร้างและบันทึกแต่ละไดเร็กทอรีชาร์ต
def each_dir_plot(dir_df, คีย์):
# การจัดกลุ่มหน้า Landing Page ของไดเรกทอรีตามค่า 'ป้ายตำแหน่ง'
dir_grouped_df = dir_df.groupby(['ป้ายกำกับตำแหน่ง'])
# การสร้าง DataFrame สำหรับจัดเก็บ 'dir_grouped_df' ที่จัดการข้อมูล
modified_df = pd.DataFrame()
# รายการบันทึกแต่ละตำแหน่งหมายถึงแผนภูมิแท่งของเรา
mean_ctr_list = []
'''
วนรอบกลุ่ม 'query_grouped_df' และต่อท้ายข้อความค้นหา 20% อันดับแรกโดยพิจารณาจากการแสดงผลไปยัง DataFrame 'modified_df'
หากการคำนวณ CTR ตาม 20% อันดับแรกของข้อความค้นหาที่มีการแสดงผลมากที่สุดนั้นไม่ดีที่สุดสำหรับคุณ คุณสามารถเปลี่ยนได้
สำหรับการเปลี่ยนแปลง คุณสามารถเพิ่มหรือลดได้โดยจัดการ '.quantile(q=your_optimal_number, interpolation='lower')]'
'you_optimal_number' ต้องอยู่ระหว่าง 0 ถึง 1
ตัวอย่างเช่น หากคุณต้องการได้รับ 30% แรกของข้อความค้นหาของคุณ 'your_optimal_num' คือความแตกต่างระหว่าง 1 และ 0.3 (0.7)
'''
สำหรับฉันอยู่ในช่วง (1, 11):
# ข้อยกเว้นสำหรับการจัดการสถานการณ์ที่ไดเร็กทอรีไม่มีข้อมูลสำหรับบางตำแหน่ง
ลอง:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolation='lower')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modified_df = modified_df.append (tmp_df, forget_index=จริง)
ยกเว้น KeyError:
mean_ctr_list.append(0)
# 1. โครงกล่อง
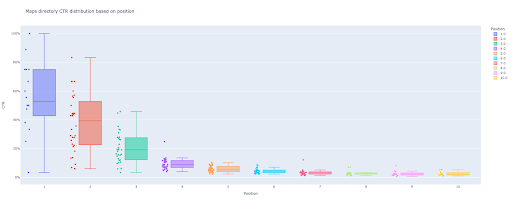
box_fig = px.box (modified_df, x='position label', y='ctr', title=f'{key} ไดเรกทอรี CTR การกระจายตามตำแหน่ง',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# กำลังแสดงขีด x-axes ทั้งหมดสิบตัว
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# การเปลี่ยนรูปแบบขีดแกน y เป็นเปอร์เซ็นต์
box_fig.update_yaxes(tickformat=".0%")
# กำลังบันทึกพล็อตไปที่ไดเร็กทอรี 'เอาต์พุตพล็อตอิมเมจ'
box_fig.write_image(f'./output plot images/{key} ไดเร็กทอรี-พล็อตกล่อง CTR curve.png')
# 2. พล็อตบาร์
bar_fig = px.bar(x=[pos สำหรับ pos ในช่วง (1, 11)], y=mean_ctr_list, title=f'{key} ไดเรกทอรีหมายถึงการกระจาย CTR ตามตำแหน่ง',
labels={'x': 'Position', 'y': 'CTR'}, text_auto=True)
# กำลังแสดงขีด x-axes ทั้งหมดสิบตัว
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# การเปลี่ยนรูปแบบขีดแกน y เป็นเปอร์เซ็นต์
bar_fig.update_yaxes(tickformat='.0%')
# กำลังบันทึกพล็อตไปที่ไดเร็กทอรี 'เอาต์พุตพล็อตอิมเมจ'
bar_fig.write_image(f'./output plot images/{key} directory-Bar พล็อต CTR curve.png')
หลังจากกำหนดฟังก์ชันข้างต้นแล้ว เราจำเป็นต้องมีการวนซ้ำ 'for' เพื่อวนรอบข้อมูลไดเร็กทอรีที่เราอยากได้เส้นโค้ง CTR
# วนรอบไดเรกทอรีและเรียกใช้ฟังก์ชัน 'each_dir_plot'
สำหรับคีย์ รายการใน Landings_grouped_df:
ถ้าคีย์ใน important_directories:
each_dir_plot(รายการ คีย์)
ในผลลัพธ์ เราได้แปลงของเราในโฟลเดอร์ output plot images
เคล็ดลับขั้นสูง!
คุณยังสามารถคำนวณเส้นโค้ง CTR ของไดเร็กทอรีต่างๆ ได้โดยใช้หน้า Landing Page ของคิวรี ด้วยการเปลี่ยนแปลงเล็กน้อยในฟังก์ชัน คุณสามารถจัดกลุ่มการสืบค้นตามไดเร็กทอรีหน้า Landing Page
คุณสามารถใช้เนื้อหาคำขอด้านล่างเพื่อส่งคำขอ API ใน API Explorer (อย่าลืมจำกัดแถว 25,000 แถว):
{
"startDate": "2022-01-01",
"endDate": "2022-02-01",
"ขนาด": [
"แบบสอบถาม",
"หน้าหนังสือ"
],
"dimensionFilterGroups": [
{
"ตัวกรอง": [
{
"มิติ": "QUERY",
"expression": "brand_variation_names",
"ตัวดำเนินการ": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
เคล็ดลับสำหรับการปรับแต่งเส้นโค้ง CTR การคำนวณด้วย Python
เพื่อให้ได้ข้อมูลที่แม่นยำมากขึ้นสำหรับการคำนวณเส้น CTR เราจำเป็นต้องใช้เครื่องมือของบุคคลที่สาม
ตัวอย่างเช่น นอกเหนือจากการรู้ว่าข้อความค้นหาใดมีตัวอย่างข้อมูลเด่น คุณสามารถสำรวจคุณลักษณะ SERP เพิ่มเติมได้ นอกจากนี้ หากคุณใช้เครื่องมือของบุคคลที่สาม คุณจะได้รับการสืบค้นคู่กับอันดับของหน้า Landing Page สำหรับข้อความค้นหานั้น โดยพิจารณาจากคุณสมบัติ SERP
จากนั้น ติดป้ายกำกับหน้า Landing Page ด้วยไดเรกทอรีราก (หลัก) จัดกลุ่มข้อความค้นหาตามค่าไดเรกทอรี พิจารณาคุณลักษณะ SERP และสุดท้ายจัดกลุ่มข้อความค้นหาตามตำแหน่ง สำหรับข้อมูล CTR คุณสามารถรวมค่า CTR จาก GSC กับการสืบค้นข้อมูลที่คล้ายกันได้