
ความสำคัญของ Semantic Network สำหรับ SEO: การสร้าง Semantic Content Networks ด้วย Query และ Document Templates – กรณีศึกษา
เผยแพร่แล้ว: 2022-01-11เครือข่ายความหมายเชื่อมต่อกับแนวคิดของฐานความรู้ที่สามารถแสดงข้อมูลในโลกแห่งความเป็นจริงสำหรับสิ่งต่าง ๆ ที่มีความสัมพันธ์เชิงสัมพันธ์ ฐานความรู้สามารถมีความสัมพันธ์ได้หลายพันแบบโดยมีเอนทิตีหลายพันล้านรายการและมีข้อเท็จจริงหลายล้านรายการ เครือข่ายความหมายสามารถสร้างขึ้นจากการมีอยู่จริงในโลกด้วยคุณลักษณะร่วมกัน เช่น น้ำหนัก ขนาด ประเภท กลิ่น หรือสี ความสัมพันธ์ระหว่าง Semantic Networks และ Semantic Web ถูกสร้างขึ้นโดยเครื่องมือค้นหาเชิงความหมายและการเพิ่มประสิทธิภาพ
Semantic Networks ใช้ใน Semantic Parsing, Word-sense Disambiguation, WordNet Creation, ทฤษฎีกราฟ, การประมวลผลภาษาธรรมชาติ, ความเข้าใจ และการสร้าง มุมมองของ Semantic Network สามารถใช้ได้ภายใน Semantic Search Engine Optimization โดยการจัดหาเครือข่ายเนื้อหาที่มีความหมาย
ในกรณีศึกษา SEO นี้ เว็บไซต์สองแห่งที่มีวิธีการต่างกันสองวิธีในมุมมองเดียวกันจะได้รับการอธิบายโดยอิงจากแบบสอบถาม เอกสาร เทมเพลตเจตนา และคู่แอตทริบิวต์เอนทิตีที่อยู่เบื้องหลัง
การใช้ความเข้าใจว่าเสิร์ชเอ็นจิ้นแสดงความรู้อย่างไรและขยายการแสดงความรู้ได้อย่างไร ฉันสามารถใช้ประโยชน์จากสิ่งนั้นเพื่อสร้างผลลัพธ์การจัดอันดับที่น่าทึ่ง เมื่อคุณเข้าใจแนวคิดพื้นฐานแล้ว ฉันจะอธิบายวิธีที่ฉันนำไปใช้กับสองเว็บไซต์ที่แตกต่างกัน จากนั้นฉันจะให้รายละเอียดเกี่ยวกับวิธีการที่ฉันใช้
Semantic Networks ช่วยจัดอันดับเว็บไซต์ของคุณได้อย่างไร
ด้านล่างนี้ คุณจะพบผลลัพธ์ดิบโดยรวมสำหรับโครงการ I
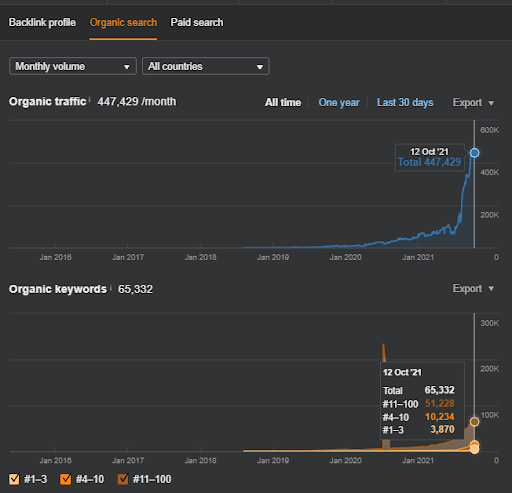
ผลลัพธ์สำหรับ Project One ซึ่งก็คือ IstanbulBogaziciEnstitu.com เพื่อพิสูจน์ว่า "เครือข่ายความหมาย" สามารถใช้สำหรับ SEO กับแบบสอบถามและเทมเพลตเอกสาร ฉันจะสาธิตเครือข่ายเนื้อหาสองเครือข่ายที่แตกต่างจากโครงการหนึ่ง Project One จะมีผลลัพธ์ที่ดีกว่ามากในอนาคตอันใกล้นี้ ขอบคุณ Semantic Content Network Two ลูกค้าจะต้องรับผิดชอบในการเปิดตัวเครือข่ายที่สองนี้ แต่ฉันจะอธิบายเหตุผลของมันด้วย
17 วันต่อมา นี่คือความคืบหน้าในโครงการ I: 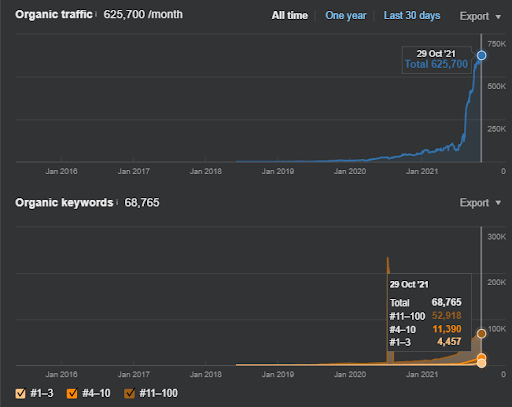
17 วันต่อมา กระบวนการจัดลำดับใหม่ของ Semantic Content Network มีความชัดเจนมากขึ้น
แนวคิดเกี่ยวกับเครือข่ายเนื้อหาเชิงความหมายช่วยให้เราเข้าใจคุณค่าของข้อความค้นหา ความตั้งใจในการค้นหา พฤติกรรม และเทมเพลตเอกสารสำหรับเอนทิตีจากประเภทเดียวกัน ในกรณีศึกษา SEO ที่เน้น Semantic Network ก่อนหน้านี้ Topical Authority และ Semantic SEO Case Study จะได้รับการเจาะลึกผ่านเว็บไซต์ใหม่สองแห่งที่ใช้เครือข่ายเนื้อหาที่สร้างขึ้นโดยมีความหมายเกี่ยวกับเอนทิตีประเภทเดียวกัน
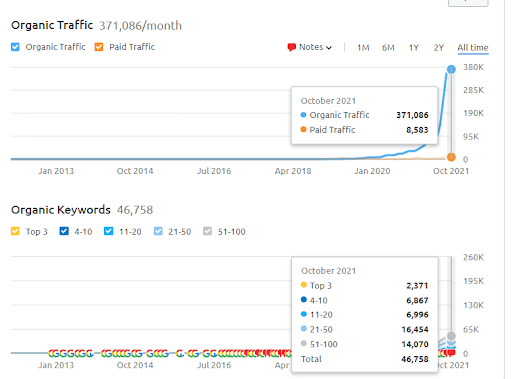
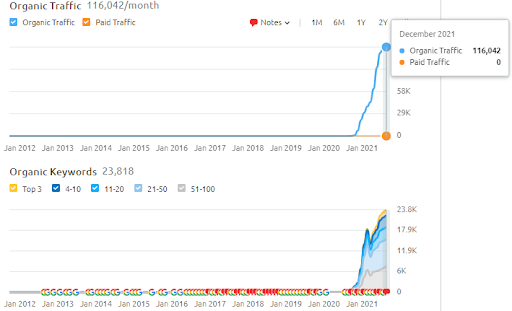
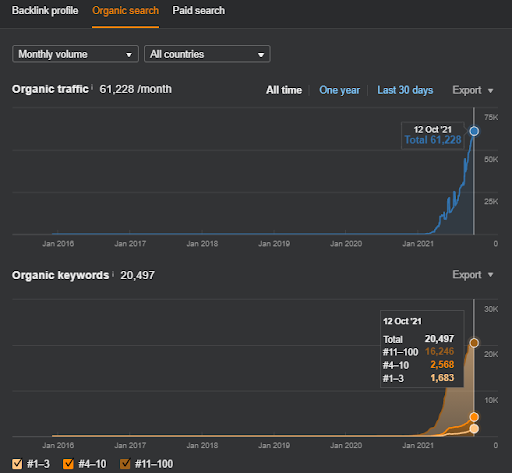
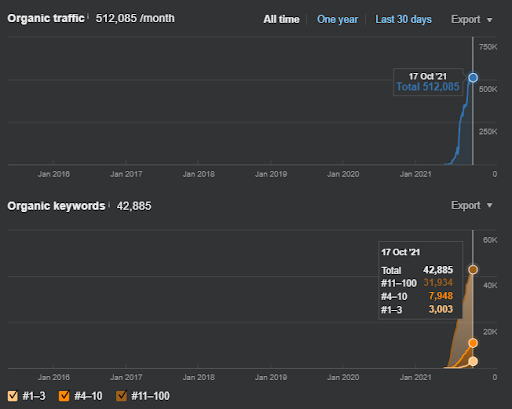
นี่คือกราฟิก SEMRush ของโครงการแรก ฉันต้องพูดถึงด้วยว่าเว็บไซต์นี้สูญเสียการอัปเดต Broad Core Algorithm ประจำเดือนมิถุนายน หากไม่สูญเสีย "อันดับ" ผลลัพธ์ก็จะดีขึ้น สำหรับ Broad Core Algorithm Update ครั้งต่อไปที่มีสิทธิ์เฉพาะหัวข้อ ความครอบคลุม และข้อมูลในอดีตที่ดีกว่า จึงสามารถกู้คืน “อันดับ” ได้อย่างง่ายดาย
ชื่อของโปรเจ็กต์ที่สองคือ Vizem.net แตกต่างจาก Project One คุณจะเห็นว่า Vizem.net มีการเพิ่มขึ้นช้ากว่าแต่สม่ำเสมอ เป็นเพราะพวกเขาใช้ Semantic Content Networks ด้วยมุมมองที่แตกต่างกันเล็กน้อย ด้านล่าง คุณสามารถดูผลลัพธ์ Ahrefs ของโครงการที่สอง
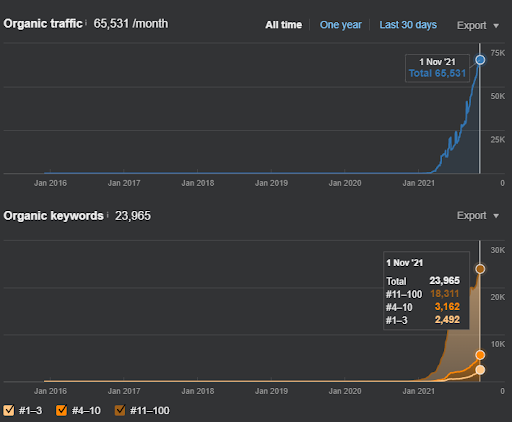
ผลลัพธ์ของโครงการที่สองแสดงถึง "กระบวนการจัดลำดับใหม่ช้า" โดยการปรับปรุงความครอบคลุมเฉพาะและอำนาจหน้าที่ทีละน้อย คำว่า "การจัดอันดับใหม่" และ "การจัดอันดับเริ่มต้น" จะอธิบายหลังจากแนวคิดที่เกี่ยวข้องกับเครือข่ายเนื้อหาเชิงความหมาย หากคุณตระหนักถึง “ความเสถียร” ภายในกราฟิก นั่นเป็นเพราะฉันหยุดเผยแพร่เนื้อหาใหม่ในแหล่งที่มา และส่งผลต่อกระบวนการจัดลำดับใหม่เมื่อคุณทราบจากการนับจำนวนคำค้นหา 3 อันดับแรก ความสัมพันธ์ "โมเมนตัม" และ "การจัดลำดับใหม่" สามารถพบได้หลังจากคำอธิบายของแนวคิดพื้นฐาน
คุณสามารถดูผลลัพธ์ SEMRush ของ Vizem.net ได้ที่ด้านล่างนี้
ปริมาณการใช้จริงของเว็บไซต์นี้มากกว่า 3 เท่าของจำนวนที่ระบุไว้ใน SEMRush คุณสามารถตระหนักถึง "เสถียรภาพ" เดียวกันและแนวคิด "โมเมนตัม" ภายในกราฟเหล่านี้ได้เช่นกัน
ขณะเขียนกรณีศึกษา SEO ของ Topical Authority ฉันขอบคุณ Bill Slawski ที่ให้ความรู้เกี่ยวกับมุมมองของฉัน ฉันทำซ้ำสำหรับกรณีศึกษา Semantic Content Network SEO ด้วย เพื่อให้เข้าใจแนวคิด "Re-rank" และ "Initial-rank" ควรอ่าน "วิธีที่เครื่องมือค้นหาอาจจัดลำดับผลการค้นหาใหม่"
เมื่อวันที่ 18 มีนาคม พ.ศ. 2564 Oncrawl, RankSense และ Holistic SEO & Digital ได้เผยแพร่ Python SEO and Data Science Webinar ในการสัมมนาผ่านเว็บนั้น SERP ได้รับการบันทึกไว้เพื่อสร้างความแตกต่างของผลลัพธ์ จะเห็นได้ว่าเสิร์ชเอ็นจิ้นเปลี่ยนอันดับของแหล่งข้อมูลบางแห่งกับแหล่งอื่นที่มีความถี่ใกล้เคียงกัน
ก่อนที่ฉันจะไปต่อ ฉันรู้ว่าบทความนี้ยาว แต่แท้จริงแล้ว นี่เป็นคำอธิบายสั้น ๆ เกี่ยวกับวิธีการทำ SEO ที่ซับซ้อนอย่างสูง เครือข่ายเนื้อหาเชิงความหมายต้องใช้การคิดมากเกินไปในขณะออกแบบ และการศึกษาหลายเดือนสำหรับลูกค้า ผู้เขียน และการปฐมนิเทศ ดังนั้น ในบทความนี้ ฉันต้องการเน้นที่คำจำกัดความของแนวคิดด้วยคำแนะนำสั้นๆ ที่สามารถดำเนินการได้ดีที่สุดและ Google ที่สำคัญ ตลอดจนสิทธิบัตร เอกสารการวิจัย เอกสารการวิจัยของเครื่องมือค้นหาอื่นๆ พร้อมด้วยแนวคิดของตนเอง ในเวอร์ชันยาว (โดยทั่วไปคือหนังสือ) ฉันได้เน้นที่ "การจัดอันดับเริ่มต้น" และ "การจัดลำดับใหม่" ของเครือข่ายเนื้อหาเชิงความหมาย
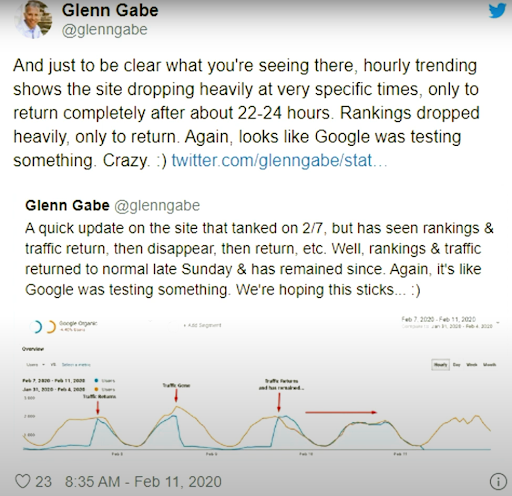
ตั้งแต่วันที่ 11 กุมภาพันธ์ 2020 Glenn Gabe มีตัวอย่างที่ดีสำหรับวิธีการจัดอันดับใหม่และการทดสอบของเครื่องมือค้นหาด้วยสายตา
หากคุณต้องการเรียนรู้เพิ่มเติม โปรดอ่าน "ความสำคัญของการจัดอันดับเริ่มต้นและการจัดอันดับใหม่สำหรับ SEO"
หากต้องการเจาะลึกข้อมูลในโลกแห่งความเป็นจริงสำหรับกรณีศึกษา SEO แนวคิดในการทำความเข้าใจเครือข่ายเนื้อหาเชิงความหมายควรได้รับการประมวลผลด้วยมุมมองความเข้าใจเกี่ยวกับการสื่อสารของเครื่องมือค้นหา
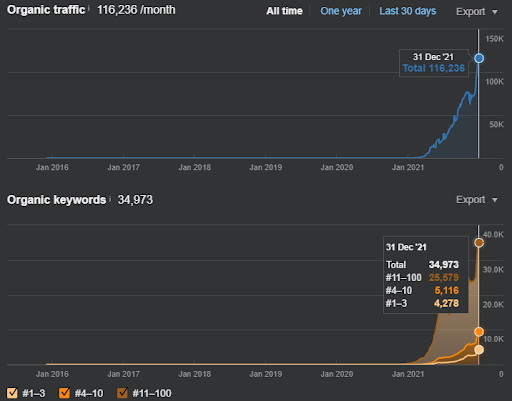
เป็นตัวอย่างการจัดอันดับใหม่ของ Vizem.net สถานการณ์ที่อัปเดตสามารถดูได้ที่ด้านบน ในส่วนต่อไปของกรณีศึกษา SEO จะมีคำอธิบายเพิ่มเติมเกี่ยวกับอัลกอริทึมการจัดลำดับใหม่ของ Google สำหรับ SEO
เครือข่ายความหมายคืออะไร?
เครือข่ายความหมายสามารถใช้ในการเชื่อมต่อและวิเคราะห์อินเทอร์เน็ตของสิ่งต่างๆ อาจเป็นประโยชน์สำหรับการรับรู้ถึงผู้ซื้อที่มีศักยภาพในตลาดเทคโนโลยี หรือเพียงแค่การวิเคราะห์คำร่วมสำหรับการสร้างเครือข่ายคำหลักและการจัดกลุ่ม เครือข่ายความหมายสามารถใช้เพื่อสนับสนุนการนำทางและเปิดเผยโครงสร้างของความสัมพันธ์หรือความสำคัญสัมพัทธ์ของสิ่งของกับอีกสิ่งหนึ่ง Semantic Network มีองค์ประกอบด้านล่าง:
- Lexical Semantics: ทำความเข้าใจว่าคำและแนวคิดใดเชื่อมโยงกับคำอื่น มีความแตกต่างอย่างไร
- ส่วนประกอบโครงสร้าง: ทำความเข้าใจว่าโหนดใดเชื่อมต่อกับขอบใดกับข้อมูลใด
- องค์ประกอบทางความหมาย: ความหมายของข้อเท็จจริง
- ส่วนขั้นตอน: ช่วยสร้างการเชื่อมต่อเพิ่มเติมระหว่างส่วนประกอบต่างๆ
เนื่องจากเครือข่ายความหมายเป็นแบบอเนกประสงค์ จึงสามารถใช้อัลกอริทึม NLP เพื่อวัตถุประสงค์ที่หลากหลายได้ เช่น เพื่อช่วยในการระบุปัญหาสุขภาพที่ซับซ้อน โครงสร้างเครือข่ายความหมายเดียวกันสามารถนำไปใช้ในพื้นที่อื่นๆ ได้ ตราบใดที่ส่วนอื่นๆ เหล่านี้มีความสัมพันธ์เชิงความหมายระหว่างกัน
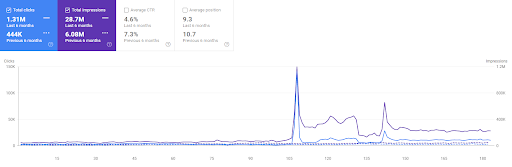
การเปรียบเทียบ 6 เดือนที่ผ่านมาของโครงการแรก
ฐานความรู้คืออะไร?
ฐานความรู้คือไลบรารีข้อมูลที่มีการจัดประเภทในรูปแบบที่เครื่องอ่านได้ ฐานความรู้สามารถใช้เป็นสารานุกรมที่สามารถจำกัดให้แคบลงและลึกซึ้งขึ้นตามแบบสอบถาม ฐานความรู้สามารถสร้างขึ้นตามข้อเสนอ การแยกข้อเท็จจริง และการดึงข้อมูล ความสัมพันธ์ระหว่างเครือข่ายความหมายและฐานความรู้คือทุกสิ่งที่อยู่ในเครือข่ายความหมายจะถูกจัดวางในฐานความรู้พร้อมๆ กับดึงข้อมูลข้อเท็จจริง
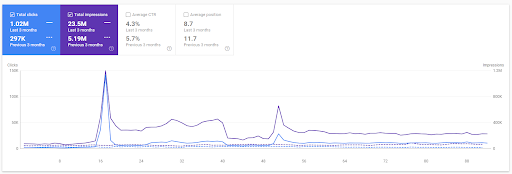
การเปรียบเทียบ 3 เดือนสุดท้ายของโครงการแรก
เครือข่ายเนื้อหาเชิงความหมายคืออะไร?
เครือข่ายเนื้อหาเชิงความหมายหมายถึงเครือข่ายเนื้อหาที่ได้รับการจัดเตรียมตามองค์ประกอบเครือข่ายความหมายและความเข้าใจ เครือข่ายเนื้อหาเชิงความหมายสามารถรวมแอตทริบิวต์หลายรายการจากเอนทิตีหรือเอนทิตีจากกลุ่มเดียวกัน เพื่อให้ฐานความรู้มีรายละเอียดมากขึ้น
ภายในเครือข่ายเนื้อหาเชิงความหมาย สามารถใช้ข้อกำหนดโดเมนความรู้ และ Triples เพื่อส่งสัญญาณถึงวัตถุประสงค์หลักของเอกสารและเนื้อหาในบริเวณใกล้เคียงที่เป็นไปได้
เครื่องมือค้นหาสามารถเปรียบเทียบฐานความรู้ของตนเองกับฐานความรู้ที่สามารถสร้างจากเนื้อหาของเว็บไซต์ได้ หากเว็บไซต์มีระดับความถูกต้องและความครอบคลุมในระดับสูงสำหรับชั้นบริบทต่างๆ เครื่องมือค้นหาสามารถปรับปรุงฐานความรู้ของตนเองจากเนื้อหาของเว็บไซต์ได้ หากเสิร์ชเอ็นจิ้นปรับปรุงและขยายฐานความรู้ของตนเองจากแหล่งอื่นในเว็บแบบเปิด แสดงว่าเป็นสัญญาณของความเชื่อถือบนฐานความรู้ระดับสูง
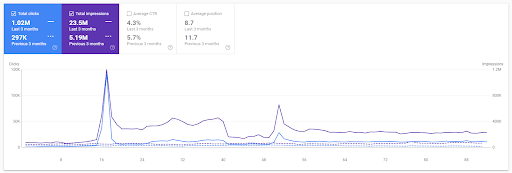
การเปรียบเทียบแบบปีต่อปีในช่วง 3 เดือนล่าสุดตามโครงการแรก
Knowledge Based-Trust คืออะไร?
Knowledge-based Trust มุ่งเน้นไปที่การเปิดเว็บแบบเปิดที่ “ความถูกต้องของข้อมูล” ไม่ใช่ “เพจแรงก์” เป็นอัลกอริทึมที่คล้ายกับ RankMerge ความเชื่อถือตามความรู้เกี่ยวข้องกับแฝดสาม การแยกข้อเท็จจริง การตรวจสอบความถูกต้อง และความเข้าใจข้อความโดยการขจัดความคลุมเครือของข้อความ สามารถรับความเชื่อถือตามความรู้ได้โดยการจัดหาเครือข่ายเนื้อหาเชิงความหมายที่มีองค์ประกอบที่เชื่อมโยงกันอย่างแน่นหนาภายในบทความ โดยอิงตามชั้นบริบทที่แตกต่างกันแต่มีความเกี่ยวข้อง
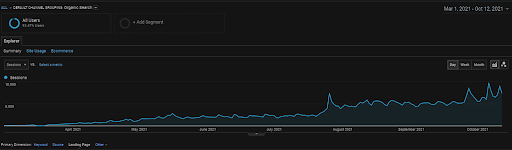
เซสชันทั่วไปของ Vizem.net จาก GA ในช่วง 6 เดือนที่ผ่านมา
ด้านล่างนี้ คุณจะเห็นตัวอย่างการนำเสนอของ Trust-based Trust จาก Luna Dong มันแสดงให้เห็นว่าเสิร์ชเอ็นจิ้นสามารถมุ่งเน้นไปที่ “ปัจจัยการจัดอันดับภายใน” แทนปัจจัยการจัดอันดับภายนอกได้อย่างไร มันอธิบายว่า PageRank ที่สูงนั้นไม่สามารถแสดงถึงคุณภาพและความแม่นยำในระดับสูงสำหรับเนื้อหาได้ด้วยตัวเอง ดังนั้นการมี KBT (Knowledge-based Trust) จึงมีความสำคัญ
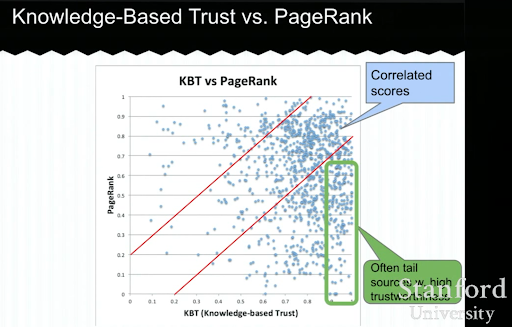
ขอบคุณมากสำหรับ Arnout Hellemans ที่แบ่งปันการบรรยายเพื่อการศึกษานี้กับฉันในระหว่างการแชท SEO ส่วนตัว หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับความเชื่อถือตามความรู้: สัมมนาสแตนฟอร์ด – Knowledge Vault และ Knowlege-Based Trust
ความครอบคลุมตามบริบทคืออะไร?
Contextual Coverage และ Topical Coverage ไม่เหมือนกับ Knowledge Domain และ Contextual Domain ไม่เหมือนกัน ความครอบคลุมตามบริบทแสดงถึงมุมการประมวลผลของแนวคิด แนวคิดสามารถประมวลผลโดยยึดตามจุดร่วมของมันกับสิ่งอื่น เช่นหากนิติบุคคลเป็นประเทศจุดยืนของตนเกี่ยวกับวิกฤตสิ่งแวดล้อมสามารถดำเนินการได้ หากประเทศอื่นๆ ได้รับการประมวลผลจากมุมมองเดียวกัน แสดงว่าเรากำลังครอบคลุมโดเมนตามบริบท

Google Search Engine สร้างเอกสารการวิจัยและสิทธิบัตรเมื่อเวลาผ่านไป คำพูดที่ถูกต้องจากส่วนด้านบนเป็นแอตทริบิวต์ของ "เวกเตอร์บริบท" ในขณะที่ส่วนด้านซ้ายเป็นแอตทริบิวต์ของ "อนุกรมวิธานแบบวลี" สิ่งที่น่าสนใจก็คือ แม้แต่ตัวอย่างก็เหมือนกัน นั่นคือ “กล้องดิจิตอล”
รายละเอียดเชิงลึกและส่วนย่อยของชุดค่าผสมเหล่านี้แสดงถึงเลเยอร์ตามบริบทภายในโดเมนตามบริบท ทุกเอนทิตีไม่ว่าจะตั้งชื่อหรือไม่ก็ตามมีโดเมนบริบทมากมาย ดังนั้น Google จึงแยกโดเมนตามบริบทและผู้ใช้ค้นหาข้อความค้นหาที่ยาวขึ้นทุกปี เมื่อมีการพัฒนาการประมวลผลภาษาธรรมชาติและความเข้าใจภาษาธรรมชาติ คำถามและเอกสารจะขยายไปพร้อมกันในแง่ของรายละเอียดและบริบท
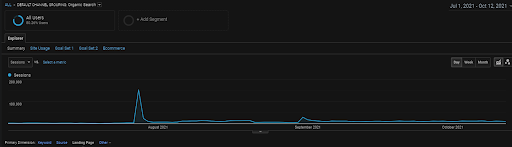
กราฟิก GA Organic Sessions ในช่วง 4 เดือนสุดท้ายของโครงการ BogaziciEnstitu เนื่องจาก "ขั้นตอนการรับข้อมูลทางประวัติศาสตร์" ของโครงการ รายละเอียดที่เพิ่มขึ้นไม่ชัดเจนที่จะถูกมองว่าเป็นเส้นตรง
ความครอบคลุมตามบริบทสามารถเข้าใจได้โดย "ตัวระบุบริบท" ตัวระบุบริบทอาจเป็นคำคุณศัพท์ คำวิเศษณ์ หรือคำบุพบทอื่นๆ เช่น วลีที่ขึ้นต้นด้วย “for, in, at, during, while” คำถามเกี่ยวกับเอนทิตีด้านล่างนี้ไม่เหมือนกันในแง่ของโดเมนตามบริบท:
- ผลไม้อะไรที่เป็นประโยชน์ที่สุดสำหรับเด็กที่นอนไม่หลับ?
- ผลไม้อะไรที่เป็นประโยชน์ที่สุดสำหรับเด็กที่มีความวิตกกังวล?
คำถามเกี่ยวกับเอนทิตีด้านล่างไม่เหมือนกันในแง่ของชั้นบริบท:
- ผลไม้อะไรที่เป็นประโยชน์มากที่สุดสำหรับเด็กที่มีอาการนอนไม่หลับรุนแรงเกิน 6 ปี?
- ผลไม้ที่มีประโยชน์มากที่สุดสำหรับเด็กที่มีความวิตกกังวลระดับต่ำอายุต่ำกว่า 6 ปีคืออะไร?
คำถามที่เกี่ยวข้องกับเอนทิตีด้านล่างไม่เหมือนกันในแง่ของโดเมนความรู้:
- หนังสือที่มีประโยชน์ที่สุดสำหรับเด็กที่มีอาการนอนไม่หลับรุนแรงเกิน 6 ปีคืออะไร?
- เกมที่มีประโยชน์มากที่สุดสำหรับเด็กที่มีความวิตกกังวลระดับต่ำอายุต่ำกว่า 6 ปีคืออะไร?
แต่คำถามเหล่านี้ทั้งหมดอาจอยู่ใน Semantic Content Network เดียวกัน เนื่องจากคำถามทั้งหมดเกี่ยวกับ "แนวคิด" และ "พื้นที่ความสนใจ" เดียวกันซึ่งมีกิจกรรมการค้นหาที่คล้ายกัน และกิจกรรมในโลกแห่งการค้นหาที่เกี่ยวข้องกับการค้นหา
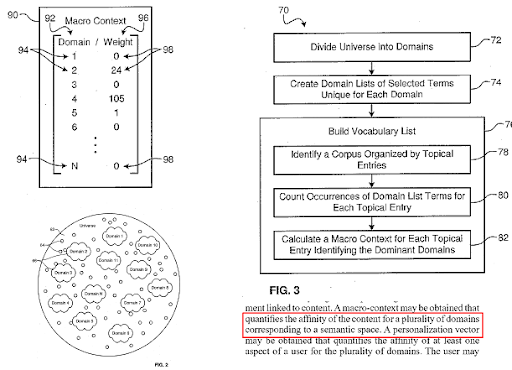
เครื่องมือค้นหาแบ่งเว็บออกเป็นโดเมนความรู้ที่แตกต่างกัน และคำนวณคะแนนบริบทของแมโครและไมโครสำหรับแหล่งที่มา หน้าเว็บ และส่วนของหน้าเว็บพร้อมกัน
ฉันรู้ว่าฉันมีแนวคิดใหม่ ๆ มากมายสำหรับคุณ และเนื่องจากบทความนี้เป็นบทความสั้น ๆ ฉันจึงไม่สามารถพูดถึงทุกสิ่งที่นี่ได้ แต่ในหลักสูตร Semantic SEO ในอนาคต ฉันจะดำเนินการสิ่งเหล่านี้ เช่น ความแตกต่างระหว่าง "กิจกรรมการค้นหา" และ "กิจกรรมในโลกแห่งความเป็นจริงที่เกี่ยวข้องกับการค้นหา"
มาต่อกันอีกหน่อยเพื่อสิ่งที่เป็นรูปธรรมมากขึ้น
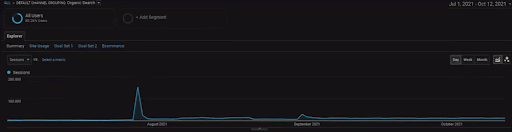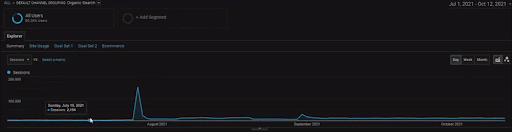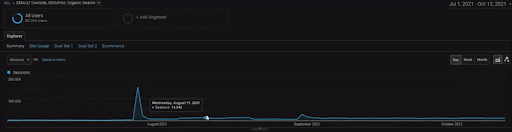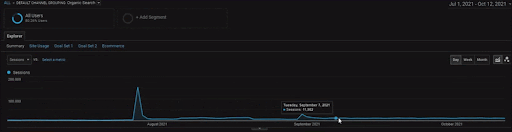
หากต้องการแสดงรายละเอียดของโครงการ BogaziciEnstitu คุณสามารถตรวจสอบเวอร์ชันของรูปภาพแบบโต้ตอบได้ ขั้นตอนการทดสอบและจัดลำดับใหม่ของเครื่องมือค้นหามีความชัดเจนมากขึ้นในโครงการนี้หลังจากเหตุการณ์แหล่งข้อมูลในอดีต
MuM เกี่ยวข้องกับเครือข่ายเนื้อหาเชิงความหมายอย่างไร
Multitask Learning ด้วย Unified Transformer หรือ Multitask Unified Model ฝึกโมเดลภาษาเพื่อประเมินอินพุตที่เป็นภาพ รวมถึงข้อความ สามารถสร้างข้อความควบคู่ไปกับความเข้าใจ นอกจากนี้ MuM เป็นภาษาที่ไม่เชื่อเรื่องพระเจ้า กล่าวอีกนัยหนึ่ง Semantic SEO ขึ้นอยู่กับทักษะทางภาษา แต่ไม่ได้จำกัดเฉพาะภาษา เนื่องจากเอนทิตีไม่มีภาษาและความหมายเป็นสากล MuM ใช้ประโยชน์จากข้อมูลจากหลายภาษาและหลายบริบทในฐานความรู้เดียว
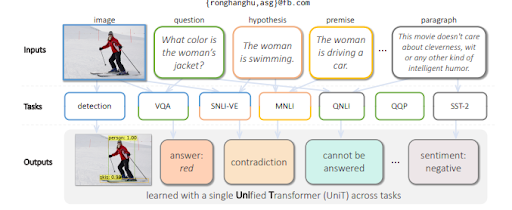
ในการตอบคำถามจากภาพ MuM จะสร้างคำถามตามวัตถุที่ตรวจพบภายในภาพ ในอนาคตอันใกล้ คำถามเกี่ยวกับเสียงและวิดีโอจะถูกสร้างขึ้นเช่นกัน
MuM ใช้โดเมนที่แตกต่างกันสำหรับการตรวจจับวัตถุและความเข้าใจภาษาธรรมชาติด้วยโครงสร้างตัวเข้ารหัส-ตัวถอดรหัสของหม้อแปลงไฟฟ้า อินพุตทั้งหมดมาจากพื้นที่ที่แตกต่างกันของเว็บเปิด ในขณะที่ข้อมูลทั้งหมดได้รับการประเมินจากตัวถอดรหัสที่ใช้ร่วมกันเพียงตัวเดียว ด้านล่างนี้ คุณจะสามารถดูตัวอย่างเพิ่มเติมจากรายงานการวิจัยได้
หมายเหตุ MuM แข็งแกร่งกว่า BERT ถึง 1,000 เท่า แต่ BERT ยังคงใช้อยู่ใน Text Encoder ของ MuM ข้อได้เปรียบหลักของ MuM คือสามารถใช้สำหรับภาพและเสียงได้โดยตรง จึงสามารถเรียกได้ว่าเป็นโมเดล "มัลติทาสก์" ข้อดีที่สองคือสามารถขจัดอุปสรรคด้านภาษาทั้งหมดได้โดยตรง ข้อได้เปรียบที่สามคือสามารถเชื่อมต่อทุกอย่างเข้ากับสิ่งอื่นได้โดยไม่ต้องมีคนกลางเพิ่มเติม ข้อได้เปรียบที่สี่คือ MuM สามารถสร้างข้อความได้เช่นกัน ไม่เหมือนกับ BERT
ความเชื่อมโยงระหว่าง MuM, ฐานความรู้, เครือข่ายความหมาย และความครอบคลุมตามบริบท คือ เสิร์ชเอ็นจิ้นสามารถค้นหาโดเมนตามบริบทได้มากขึ้นผ่านตัวระบุบริบทและการผสมผสานกับโดเมนความรู้ที่เป็นไปได้ ดังนั้น เครือข่ายเนื้อหาเชิงความหมายที่มีโครงสร้างเป็นอย่างดีซึ่งมีรูปร่างด้วยแผนที่เฉพาะและบริบทของแหล่งที่มาที่เหมาะสมสามารถปรับปรุงความน่าเชื่อถือของฐานความรู้พร้อมกับหน่วยงานเฉพาะ
บริบทของแหล่งที่มาคืออะไร?
บริบทของแหล่งที่มาแสดงถึงสองสิ่ง อินเทอร์เน็ตการค้นหาส่วนกลางของแหล่งที่มา และกิจกรรมการค้นหาส่วนกลางที่สามารถทำได้ด้วยกิจกรรมการค้นหาที่เกี่ยวข้อง สำหรับเว็บไซต์อีคอมเมิร์ซ บริบทที่มาคือการซื้อผลิตภัณฑ์เฉพาะหรือผลิตภัณฑ์บางประเภท หากเป็นเว็บไซต์ท่องเที่ยว บริบทของแหล่งที่มาจะมาจากที่อื่นเพื่อหาอาหารประเภทต่างๆ ทิวทัศน์ หรือเพียงแค่ธุรกิจ ตามบริบทของแหล่งที่มา การออกแบบเครือข่ายเนื้อหาเชิงความหมาย และแผนที่เฉพาะ จะต้องได้รับการกำหนดค่าเพิ่มเติม จำเป็นต้องเลือกส่วนกลางภายในแผนที่เฉพาะ และส่วนเสริมภายในแผนที่เฉพาะ
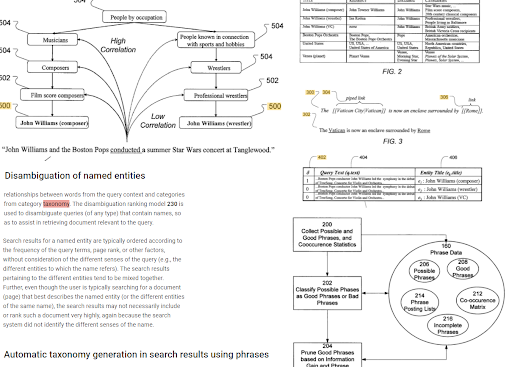
การจัดทำดัชนีแบบวลีและความเข้าใจในการค้นหาเชิงเอนทิตีจะเชื่อมต่อกันตามความหมาย ด้านบน สามารถเห็น "การแก้ความกำกวมที่มีชื่อ" และ "การสร้างอนุกรมวิธานอัตโนมัติในผลการค้นหาโดยใช้วลี" ร่วมกันเพื่อกำหนด "บริบท" วลีที่ดีและข้อมูลเฉพาะแต่มีความเกี่ยวข้องกันสำหรับหัวข้อหนึ่งๆ จะช่วยให้การเริ่มต้นและการจัดลำดับใหม่ดีขึ้น
อีกครั้ง แนวคิดบางส่วนเหล่านี้ "การกำหนดค่าแผนที่เฉพาะ" "การออกแบบเครือข่ายเนื้อหาเชิงความหมาย" ยังไม่ได้รับการกำหนด และนี่ไม่ใช่สถานที่ที่เหมาะสมสำหรับมัน แต่มีการอธิบายกิจกรรมการค้นหาที่เกี่ยวข้องพร้อมกับความตั้งใจในการค้นหาตามรูปแบบบัญญัติ และวลีที่เป็นตัวแทนสำหรับความตั้งใจในการค้นหาตามรูปแบบบัญญัติเหล่านี้
ความเป็นมาของกรณีศึกษา SEO ที่เน้นเครือข่ายความหมาย
จากแนวคิดข้างต้น ฉันใช้ Semantic Networks เพื่อสร้างกรณีศึกษา SEO เราจะดูโครงการเว็บไซต์สองโครงการที่ฉันกล่าวถึงในตอนต้นของบทความนี้ และตรวจสอบผลลัพธ์ และวิธีที่ฉันนำ Semantic Networks มาใช้ในการผลิต
เพื่อให้คุณได้ทราบว่าเครือข่ายเหล่านี้มีประสิทธิภาพเพียงใด ผลลัพธ์ที่เกี่ยวข้องกับ SEO สำหรับกรณีศึกษา SEO ที่เน้นเครือข่ายความหมายจะแสดงรายการด้านล่าง
- การทำความเข้าใจเครือข่ายความหมายเป็นสิ่งจำเป็นในการสร้างแผนที่เฉพาะที่เหมาะสม
- สำหรับทั้งสองโครงการ ไม่ได้ใช้เทคนิค SEO เพื่อแยกผลกระทบของ SEO เชิงความหมาย
- ไม่ได้ใช้ Page Speed Optimization ด้วยเหตุผลเดียวกัน
- ไม่ใช้การเพิ่มประสิทธิภาพการออกแบบและ WUX (ประสบการณ์ผู้ใช้เว็บไซต์)
- ไม่ใช้ลิงก์ย้อนกลับ (การอ้างอิงภายนอกและโฟลว์ PageRank)
- ทั้งสองแบรนด์ไม่มีข้อมูลในอดีต Vizem.net นั้นใหม่ทั้งหมด BogaziciEnstitusu มีประวัติที่เก่ากว่า แต่ต่ำกว่าบริษัทจริง
- ไม่ใช้ OnPage SEO หรือแนวดิ่งอื่นๆ ของ SEO
- ทั้งสองแบรนด์มีเซิร์ฟเวอร์ที่ดีกว่าตัวอย่างกรณีศึกษา Topical Authority ก่อนหน้านี้
กรณีศึกษา SEO ที่เน้นเครือข่ายความหมายนี้จะช่วยผู้ที่ต้องการปรับปรุงมุมมอง SEO เชิงความหมายด้วยวิธีการและแนวคิดที่แตกต่างกันสองแบบซึ่งมุ่งเน้นไปที่เว็บไซต์สองแห่งที่แตกต่างกัน
โครงการที่สอง: Vizem.net มุ่งเน้นไปที่ขั้นตอนการสมัครวีซ่า ก่อนเขียน เผยแพร่ หรือแม้แต่เปิดตัวโครงการเหล่านี้ ฉันได้แสดงเว็บไซต์ทั้งสองนี้หลายครั้งต่อลูกค้ารายอื่นๆ หรือพันธมิตรของฉัน และ Vizem.net ได้เริ่มต้นเส้นทาง "Topical Authority" เมื่อเร็วๆ นี้
SEO ตามกรณีศึกษา Semantic Networks ถูกเขียนขึ้นในสองเวอร์ชันที่แตกต่างกัน หากคุณต้องการอ่านสิทธิบัตรที่เกี่ยวข้อง เอกสารการวิจัย และการตรวจสอบอย่างละเอียด การตีความจากมุมมองของเครื่องมือค้นหาในขณะที่ทำความเข้าใจโครงสร้างการตัดสินใจของเครื่องมือค้นหาเพิ่มเติม คุณสามารถอ่านความสำคัญของ SEO การจัดอันดับเริ่มต้นและการจัดอันดับใหม่ บทความกรณีศึกษาที่มีความยาวมากกว่า 30,000 คำ หากคุณไม่มีความรู้ทางทฤษฎีเพียงพอสำหรับ SEO และภูมิหลังทางประวัติศาสตร์ คุณสามารถอ่านบทสรุปสำหรับผู้บริหารต่อไปได้
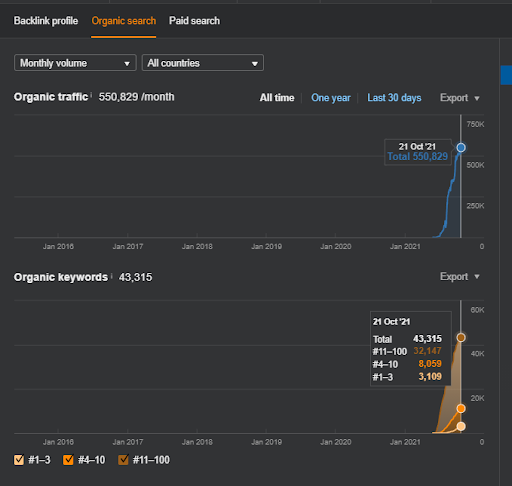
ด้านล่างนี้ คุณสามารถดูกราฟิกโครงการที่สอง (Vizem.net) จาก SEMRush
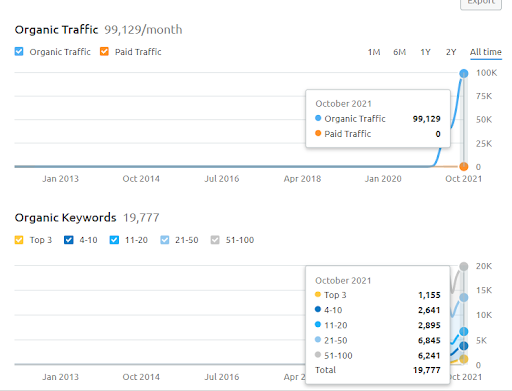
กราฟิก SEMRush ของเว็บไซต์ที่สอง Vizem.net เป็นแหล่งข้อมูลใหม่ที่กำหนดเป้าหมายไปยังอุตสาหกรรมที่มีคู่แข่งที่หยั่งรากในระดับสูง เช่น “การขอวีซ่า” โดยเฉพาะอย่างยิ่ง เนื่องจากเหตุการณ์ล่าสุดในตุรกี ระดับการแข่งขันของอุตสาหกรรมจึงเพิ่มขึ้น ดังนั้น การใช้มุมมองของ Semantic Network ในการสร้างเครือข่ายเนื้อหาจึงมีประโยชน์
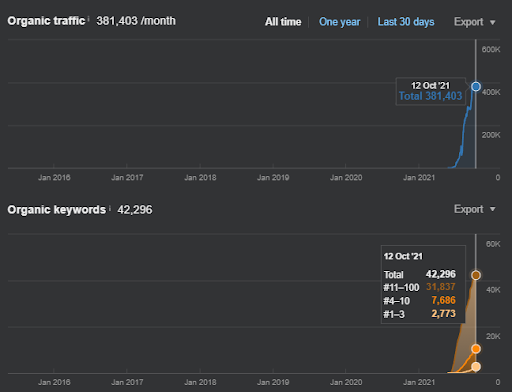
โปรเจ็กต์แรก: Istanbul Bogazici Enstitusu: คลิกออร์แกนิกเพิ่มขึ้น 600% ใน 3 เดือน – ใช้ประโยชน์จากข้อมูลย้อนหลังและอันดับเริ่มต้น
IstanbulBogazici Enstitusu เป็นหนึ่งในกรณีศึกษา SEO ที่ยากที่สุดที่ฉันเคยทำ ไม่ใช่เพราะเครื่องมือค้นหา แต่เป็นเพราะผู้คนและปัญหาสุขภาพของฉัน ดังนั้นฉันจึงออกจากโครงการและไม่ได้เผยแพร่เครือข่ายเนื้อหาที่มีความหมายที่สามซึ่งได้รับการออกแบบมาเพื่อให้ความสัมพันธ์ทางความหมายสมบูรณ์ตามบริบทของแหล่งที่มา แม้ว่าจะไม่มีคำศัพท์ของโดเมนความรู้และมีการใช้วลีตามบริบทอย่างเหมาะสม แต่ก็มีการกำหนดค่าด้วยระดับการเชื่อมต่อทางความหมายและความแม่นยำที่เพียงพอ เพื่อให้มีประสิทธิภาพการค้นหาทั่วไปโดยรวมมากกว่าสามล้านเซสชันต่อเดือนหากเครือข่ายเนื้อหาที่สาม เผยแพร่ในอนาคตโดยคำนึงถึงผลกระทบที่เพิ่มขึ้นของเครือข่ายเนื้อหาที่มีความหมายที่สองเช่นกัน
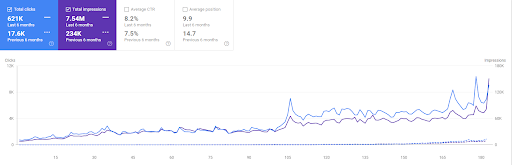
ด้านล่างนี้ คุณจะเห็นกราฟิกที่เปลี่ยนแปลงของ IstanbulBogazici Enstitusu บน GSC ในช่วง 12 เดือนที่ผ่านมา โปรเจ็กต์นี้เปิดตัวในเดือนพฤษภาคม 2564 ด้วยวิธีที่เหมาะสม และสิ้นสุดในเดือนกันยายน 2564 ด้วยการเผยแพร่ Semantic Content Networks สองรายการ
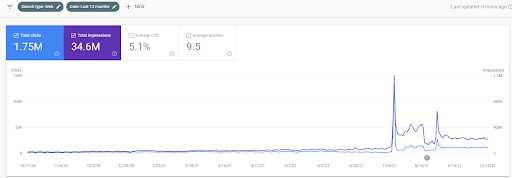
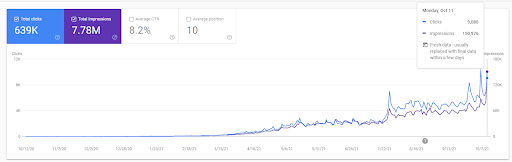
ด้านล่างนี้ คุณสามารถดูเวอร์ชันโดยละเอียดเพิ่มเติมได้ จาก 1,400 คลิกต่อวันเป็น 140000 คลิก จากนั้นคลิกปกติ 10,000+ คลิกต่อวันในประสิทธิภาพการค้นหาทั่วไป
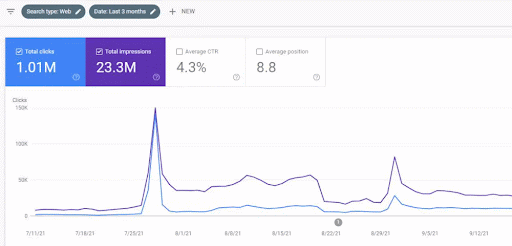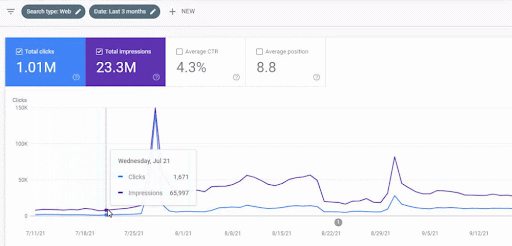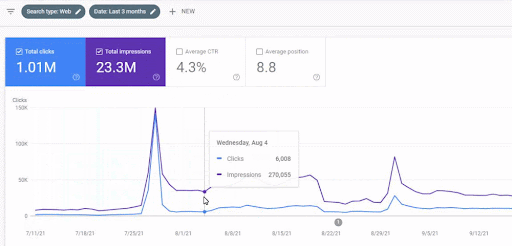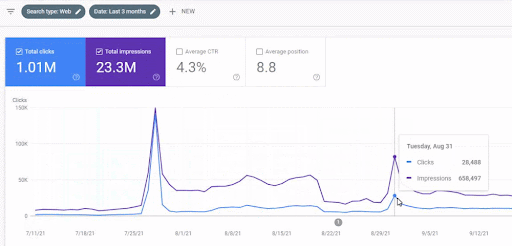
การเข้าชมที่เพิ่มขึ้นของเครือข่ายเนื้อหาแรกหลังการเปิดตัวสามารถดูได้ที่ด้านล่าง
ภาพหน้าจอนี้แสดงเดือนที่ 4 ของ First Semantic Content Network
ดังที่คุณเห็นจากภาพกราฟิก การเข้าชมโดยรวมของเว็บไซต์ทั้งหมดถูกครอบงำและได้รับผลกระทบจาก First Semantic Content Network ซึ่งมุ่งเน้นไปที่ "สาขาการศึกษา" เครือข่ายเนื้อหาที่สองที่ฉันเปิดตัวกับเว็บไซต์นี้สามารถดูได้ที่ด้านล่างจาก Google Search Console ภาพหน้าจอด้านล่างมาจากวันที่ 16 ของเครือข่ายเนื้อหาที่มีความหมายที่สอง
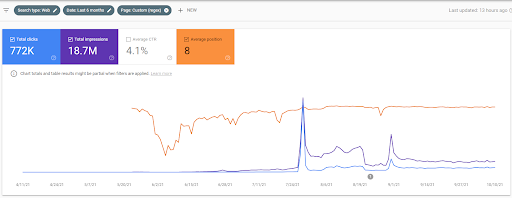
มีการใช้การจัดอันดับเริ่มต้นและการจัดอันดับใหม่ภายในบทความเนื่องจากกำหนดขั้นตอนของอัลกอริทึมการจัดอันดับพร้อมกับประเภทและวัตถุประสงค์ก่อนที่จะทดสอบแหล่งที่มาและหน้าเว็บจากแหล่งที่มาภายใน SERP สำหรับข้อความค้นหาที่สำคัญกว่าที่ได้รับความนิยม .
เครือข่ายเนื้อหาเชิงความหมายแรกของโครงการแรกที่มุ่งเน้นคืออะไร
“เครือข่ายเนื้อหาเชิงความหมาย” ใช้เครือข่ายความหมายจากฐานความรู้เพื่ออธิบายความสัมพันธ์หลัก รอง และตติยภูมิระหว่างสิ่งต่าง ๆ ภายในฐานความรู้ ดังนั้น การสร้างเครือข่ายเนื้อหาเชิงความหมายจึงต้องออกแบบเครือข่ายเนื้อหาเชิงความหมายถัดไปตามบริบทของแหล่งที่มาซึ่งเป็นหน้าที่หลักของเว็บไซต์ ในบริบทนี้ เครือข่ายเนื้อหาเชิงความหมายแรกมุ่งเน้นไปที่ “หน่วยงานของมหาวิทยาลัย สาขาการศึกษา และสิ่งจำเป็นสำหรับการศึกษาระดับมหาวิทยาลัยภายในองค์กรและสาขาเฉพาะ”
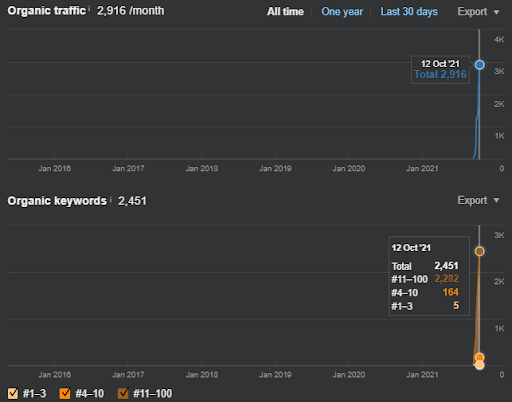
ด้านล่างนี้ คุณจะพบ Ahrefs Graphic ของ First Semantic Content Network
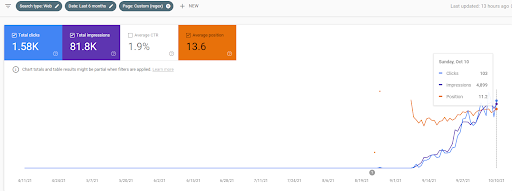
นี่คือห้าวันต่อมาจากภาพหน้าจอก่อนหน้า
“Root: istanbulbogazicienstitu.com/bolum” หลังจากระยะการจัดอันดับเริ่มต้นครั้งแรก กระบวนการจัดลำดับใหม่จะมีประสิทธิภาพและประสิทธิผลมากขึ้น
คุณสามารถดูเวอร์ชันสี่วันต่อมาด้านล่างเพื่อสนับสนุนลักษณะของ "การจัดลำดับใหม่"
เครือข่ายเนื้อหาเชิงความหมายที่สองของโครงการแรกที่มุ่งเน้นคืออะไร
เครือข่ายเนื้อหาที่มีความหมายที่สองมุ่งเน้นไปที่อาชีพ งาน ทักษะ และการศึกษาที่จำเป็นสำหรับทักษะเหล่านี้หรือกิจวัตร ตามเครือข่ายเนื้อหาเชิงความหมายแรก เครือข่ายเนื้อหาเชิงความหมายที่สองได้รับการสนับสนุน และตาม "เท็มเพลตเจตนาของเท็มเพลตแบบสอบถาม" เครือข่ายเนื้อหาย่อยความหมายที่แตกต่างกันอีกสองเครือข่ายถูกสร้างขึ้นและวางด้วย "การเชื่อมต่อเชิงสัมพันธ์" ในขณะที่เชื่อมต่อกับระดับลำดับชั้นที่คล้ายคลึงกัน
เราทราบดีว่าหัวข้อเหล่านี้ซับซ้อนสำหรับคุณ เนื่องจากคุณยังไม่เห็นคำจำกัดความของสิ่งต่างๆ ด้านล่าง
- เครือข่ายเนื้อหาความหมาย
- บริบทที่มา
- เครือข่ายเนื้อหาย่อยความหมาย
- ฐานความรู้
- การเชื่อมต่อเชิงสัมพันธ์
- อันดับเริ่มต้น
- จัดอันดับใหม่
- ความครอบคลุมตามบริบท
- อันดับเปรียบเทียบ
- การสกัดข้อเท็จจริง
หลังจากอธิบายเว็บไซต์ที่สองแล้ว จะเข้าใจแนวคิดและประโยคเหล่านี้ได้ง่ายขึ้น
Vizem.net: จาก 0 ถึง 9.000+ คลิกต่อวันต่อวันใน 6 เดือน – จัดอันดับเปรียบเทียบโดยใช้เลเวอเรจพร้อมความครอบคลุมตามบริบท
คุณสามารถดูกราฟของ Vizem.net ในช่วง 12 เดือนที่ผ่านมา สำหรับโครงการนี้ เนื่องจากสถานการณ์ Covid-19 เราประสบปัญหาทางเศรษฐกิจมากมาย เนื่องจากนักลงทุนมาจากอุตสาหกรรมยิม ดังนั้น ฉันสามารถบอกได้ว่าปัญหาทางเศรษฐกิจทำให้โครงการช้าลง และทำให้มีเวลาแฝงสำหรับ "กระบวนการจัดลำดับใหม่"
เพื่อให้เข้าใจการจัดอันดับเริ่มต้นและจัดอันดับใหม่อีกเล็กน้อย คุณสามารถใช้กราฟด้านล่าง
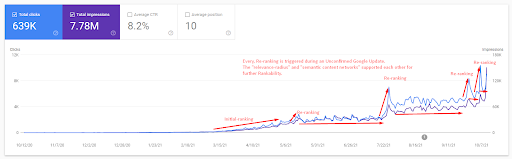
คำจำกัดความบางส่วนที่เกี่ยวข้องกับการจัดอันดับเริ่มต้นและการจัดอันดับใหม่จากภาพด้านบนสามารถดูได้ที่ด้านล่าง
- การจัดอันดับครั้งใหญ่เกิดขึ้นระหว่างการอัปเดตของ Google ที่ไม่ได้รับการยืนยัน การทดสอบบางรายการให้ตัวอย่างข้อมูลเด่นบางส่วน และผู้คนยังถามคำถามด้วย
- การทดสอบบางอย่างจาก Google ได้ลบรายได้ FS และ PAA
- ทุกครั้ง ไทม์ไลน์ระหว่างกระบวนการจัดลำดับใหม่ทั้งสองจะสั้นลง
- กระบวนการจัดลำดับใหม่ปรับปรุงความสามารถในการจัดอันดับของแหล่งที่มาทุกครั้ง
- แหล่งที่มาปรับปรุงรัศมีความเกี่ยวข้องเสมอในขณะที่ขยายคลัสเตอร์การสืบค้น
ฉันสามารถฝากประโยคไว้ด้านล่าง
หากเครื่องมือค้นหาจัดทำดัชนีหน้าเว็บของคุณ ไม่ได้หมายความว่าเครื่องมือค้นหาจะเข้าใจหน้าเว็บ การจัดทำดัชนีเกิดขึ้นเร็วกว่าการทำความเข้าใจ และโดยส่วนใหญ่แล้ว เครื่องมือค้นหาจะจัดอันดับหน้าเว็บด้วยการคาดคะเน "ในขั้นต้น" หลังจากทำความเข้าใจแล้ว "การจัดลำดับใหม่" ก็จะเกิดขึ้น 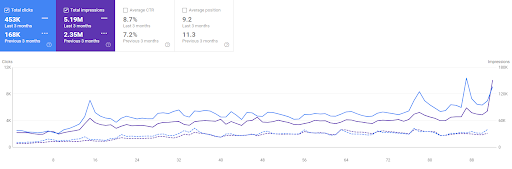
การเปรียบเทียบ 3 เดือนที่ผ่านมาของ Vizem.net
เครือข่ายเนื้อหาเชิงความหมายของ Vizem.net เป็นอย่างไร
ฉันจำได้ว่าสำหรับลูกค้าของฉัน เพื่อน หรือกลุ่ม SEO ลับๆ ของฉัน ในระหว่างการประชุม ฉันได้แสดงเว็บไซต์ทั้งสองนี้โดยพูดว่า "พวกเขาจะระเบิด" และในขณะที่เขียนบทความนี้ ฉันกำลังบอกคุณว่า:
ดู "istanbulbogazicienstitu.com/meslek" Semantic Content Network เพราะจะระเบิด และคุณสามารถค้นหาวิดีโอที่ฉันเผยแพร่ก่อนเขียนบทความนี้พร้อมทั้งแสดง "ข้อมูลย้อนหลัง" จากเหตุการณ์ตามฤดูกาลและผลกระทบต่อกระบวนการเริ่มต้นและการจัดลำดับใหม่ คุณสามารถดูได้ด้านล่าง
จากสิ่งนี้ Semantic Content Network ของ Vizem.net นั้นไม่เหมือนกับ IstanbulBogazici Enstitusu ดังนั้นฉันจึงไม่ได้ใช้ "ระดับความครอบคลุมเฉพาะที่เข้มข้นและข้อมูลทางประวัติศาสตร์ที่เพิ่มขึ้น" ฉันต้องสร้างอำนาจที่เกี่ยวข้องกับบางอย่าง ประเภทของเอนทิตี คุณลักษณะของเอนทิตี และการดำเนินการที่เป็นไปได้เบื้องหลังการสืบค้นสำหรับคู่เอนทิตี-แอตทริบิวต์เหล่านี้ Vizem.net ไม่ได้มีเพียง "สาขามหาวิทยาลัยการศึกษา" หรือ "อาชีพและหลักสูตรออนไลน์" อยู่ภายในเท่านั้น มี "ประเทศสำหรับการยื่นขอวีซ่า" ดังนั้น การสร้างระดับผู้มีอำนาจเฉพาะที่เพียงพอจึงต้องมีความสม่ำเสมอเมื่อเวลาผ่านไปกับเครือข่ายเนื้อหาที่มีความหมายต่างกันอย่างน้อย 190 เครือข่าย
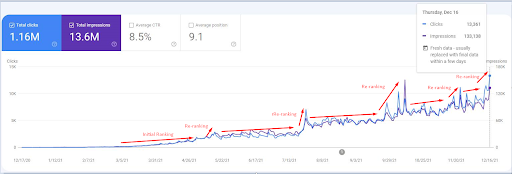
ภาพหน้าจอจากวันที่ 18 ธันวาคม 2021 คุณสามารถดูการเรียงลำดับใหม่อย่างต่อเนื่องและการเพิ่มขึ้นของการแสดงผลและการคลิก นี่คือ 4 สัปดาห์ต่อมาจากภาพหน้าจอก่อนหน้า
หากต้องการดูเหตุการณ์การจัดลำดับใหม่ คุณสามารถเปรียบเทียบเวอร์ชันเปล่าของกราฟิกประสิทธิภาพการค้นหาทั่วไปที่แสดงให้เห็นผลของ Semantic SEO 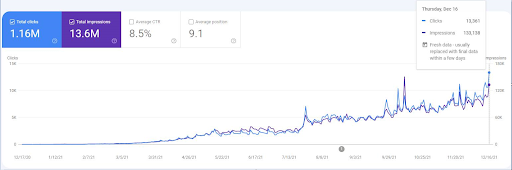
เครือข่ายเนื้อหาความหมายที่แตกต่างกัน 190 เครือข่ายเหล่านี้มีรูปแบบตาม "ประเทศ" เอง และประเทศต่างๆ จะถูกจัดวางไว้ตรงกลางของแผนที่เฉพาะที่มีทุกเลเยอร์ตามบริบทที่เป็นไปได้ เพื่อปรับปรุงความครอบคลุมของกิจกรรมการค้นหา
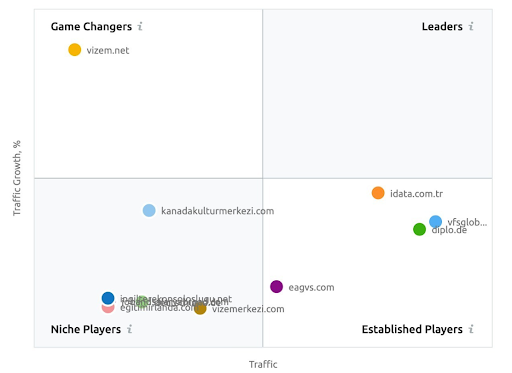
ภาพหน้าจอจาก SEMRush แสดงการรับรู้ของพวกเขาสำหรับ Vizem.net ซึ่งแตกต่างจากผู้เล่นในอุตสาหกรรมรายอื่น
ฉันยังเผยแพร่วิดีโออื่นสำหรับ Vizem.net เท่านั้น ในวิดีโอนี้ สถานการณ์สุดท้ายของเว็บไซต์ไม่มีอยู่จริง ดังนั้นฉันจึงเชื่อว่ายังมีการเปรียบเทียบที่ดีระหว่างวันนี้กับวันนั้น
สุดท้าย การเผยแพร่สิ่งที่ไม่เกี่ยวข้องภายในบทความ ส่วนเว็บไซต์ หรือแหล่งที่มาที่ไม่เกี่ยวข้องสามารถลดความเกี่ยวข้องโดยรวมของเอนทิตีเว็บกับโดเมนความรู้เฉพาะ Vizem.net จะแสดงมูลค่าที่แท้จริง และความสามารถในการจัดอันดับในอนาคตจะดีขึ้นมาก
การเปรียบเทียบ 6 เดือนที่ผ่านมาของ Vizem.net
ก่อนที่ฉันจะไปต่อ ฉันรู้ว่าบทความนี้ยาว แต่แท้จริงแล้ว นี่เป็นคำอธิบายสั้น ๆ เกี่ยวกับวิธีการทำ SEO ที่ซับซ้อนอย่างสูง เครือข่ายเนื้อหาเชิงความหมายต้องใช้การคิดมากเกินไปในขณะออกแบบ และการศึกษาหลายเดือนสำหรับลูกค้า ผู้เขียน และการปฐมนิเทศ ดังนั้น ในบทความนี้ ฉันต้องการเน้นที่คำจำกัดความของแนวคิดด้วยคำแนะนำสั้นๆ ที่สามารถดำเนินการได้ดีที่สุดและ Google ที่สำคัญ ตลอดจนสิทธิบัตร เอกสารการวิจัย เอกสารการวิจัยของเครื่องมือค้นหาอื่นๆ พร้อมด้วยแนวคิดของตนเอง ในเวอร์ชันยาว (โดยทั่วไปคือหนังสือ) ฉันได้เน้นที่ "การจัดอันดับเริ่มต้น" และ "การจัดลำดับใหม่" ของเครือข่ายเนื้อหาเชิงความหมาย
หากคุณต้องการเรียนรู้เพิ่มเติม โปรดอ่าน "ความสำคัญของการจัดอันดับเริ่มต้นและการจัดอันดับใหม่สำหรับ SEO"
จนถึงขณะนี้ เราได้ดำเนินการดังต่อไปนี้
- เครือข่ายความหมาย
- ฐานความรู้
- เครือข่ายเนื้อหาความหมาย
- ความรู้-ความเชื่อถือ
- ความครอบคลุมตามบริบท
- โดเมนบริบทและเลเยอร์
- ความเกี่ยวข้องของ MuM กับเครือข่ายเนื้อหาเชิงความหมาย
- บริบทของแหล่งที่มา
แนวคิดเหล่านี้คือการทำความเข้าใจว่า Semantic Content Networks ทำงานอย่างไร และสามารถใช้กับแผนที่เฉพาะได้อย่างไร ส่วนต่อไปจะเกี่ยวกับวิธีที่เครื่องมือค้นหาจัดอันดับ Semantic Content Networks ในขั้นต้นและภายหลัง การปรับเปลี่ยน ในบริบทนี้ สิ่งต่างๆ ด้านล่างนี้จะได้รับการประมวลผล
- อันดับเริ่มต้น
- จัดอันดับใหม่
- เทมเพลตแบบสอบถาม
- แม่แบบเอกสาร
- เทมเพลตความตั้งใจในการค้นหา
- สิ่งที่คุณควรทำเพื่อใช้ประโยชน์จาก Semantic Content Networks
การจัดอันดับเริ่มต้นสำหรับ SEO คืออะไร?
นี่เป็นคำศัพท์และแนวคิดใหม่สำหรับ SEO แต่เป็นคำเก่าสำหรับเครื่องมือค้นหา รุ่นยาวของ "กรณีศึกษา SEO ที่เน้นเครือข่ายความหมาย" มุ่งเน้นไปที่อัลกอริธึมการจัดอันดับตามการสืบค้นขึ้นอยู่กับอัลกอริธึมขึ้นอยู่กับแหล่งที่มาและสิทธิบัตรหลายฉบับ อัลกอริธึมการสืบค้นข้อมูลเชิงทำนายหรือการจัดลำดับเชิงคาดการณ์พยายามลดต้นทุนในการคำนวณ และแม้ว่าการจัดทำดัชนีจะเกิดขึ้นในวันเดียว การทำความเข้าใจเอกสารอาจใช้เวลาเป็นเดือนหรือเป็นปี การคำนวณการจัดอันดับเริ่มต้นเป็นวิธีหนึ่งในการปรับปรุงคุณภาพ SERP ในขณะที่ลดต้นทุน งานที่เกี่ยวข้องกับ Search Engine บางงานมีลำดับความสำคัญสูงกว่างานอื่นๆ ในการรักษาดัชนีให้คงอยู่ สดใหม่ และมีคุณภาพสูงเพียงพอ

คำว่าการจัดอันดับเริ่มต้นปรากฏในสิทธิบัตรและเอกสารการวิจัยของ Google หลายหมื่นฉบับ เนื่องจากเป็นมุมมองที่คลาสสิกในหมู่ผู้สร้างเครื่องมือค้นหา ดังนั้น ข้างต้น คุณสามารถดูเอกสารสิทธิบัตรที่แตกต่างกันโดยมีความต่อเนื่องของย่อหน้าเดียวกัน และข้อกำหนดที่มีการเปลี่ยนแปลงเล็กน้อยเกี่ยวกับระยะการจัดอันดับเริ่มต้น
การจัดอันดับเริ่มต้นแสดงถึงอันดับของเอกสารใน SERP ทันทีหลังจากจัดทำดัชนี การจัดอันดับเริ่มต้นของเอกสารแสดงถึงอำนาจโดยรวม และความเกี่ยวข้องของแหล่งที่มากับหัวข้อเฉพาะ เทมเพลตคิวรี และจุดประสงค์ในการค้นหา เนื้อหาเดียวกันสามารถจัดอันดับต่างกันในแง่ของการจัดอันดับเริ่มต้นระหว่างแหล่งที่มาต่างๆ การจัดอันดับเริ่มต้นมีความสำคัญในขณะที่ใช้ Semantic Content Networks เพื่อดูคุณภาพโดยรวมและอำนาจที่เพิ่มขึ้นของแหล่งที่มา เอกสารใหม่ทุกฉบับจะเพิ่มอันดับเริ่มต้นในขณะที่ลดความล่าช้าในการจัดทำดัชนี หากการออกแบบเครือข่ายเนื้อหาเชิงความหมายมีโครงสร้างที่ถูกต้อง
การจัดอันดับเริ่มต้นสนับสนุนกระบวนการจัดลำดับใหม่และประสิทธิภาพของแหล่งที่มา และ "ความสามารถในการจัดอันดับของแหล่งที่มา" ควรได้รับการประมวลผลด้วยคำสองคำนี้ ได้แก่ ค่าเริ่มต้นและการจัดลำดับใหม่
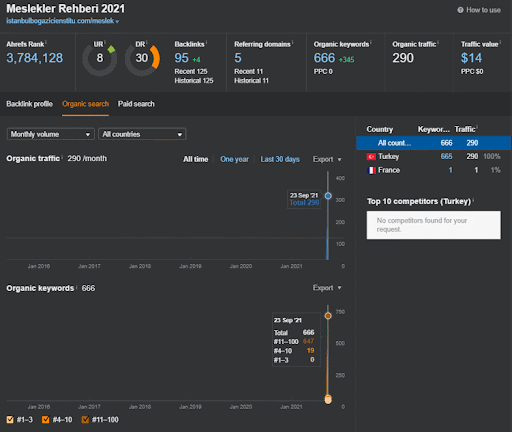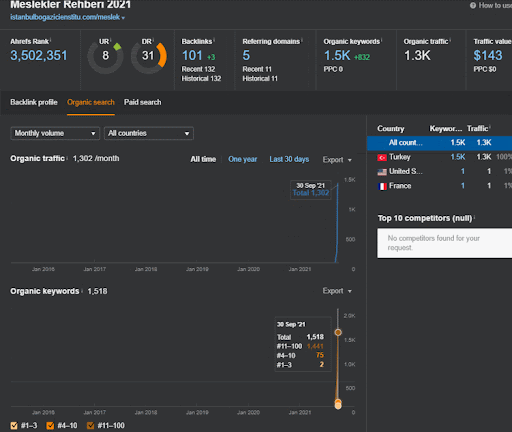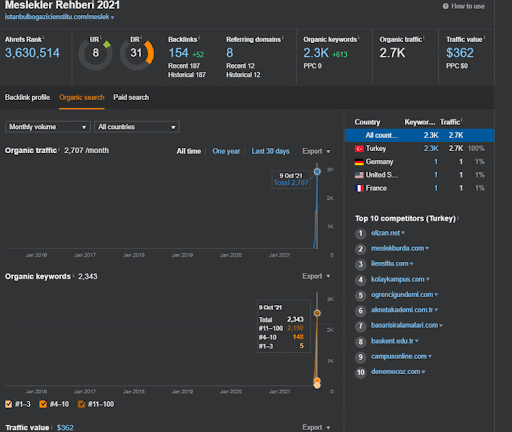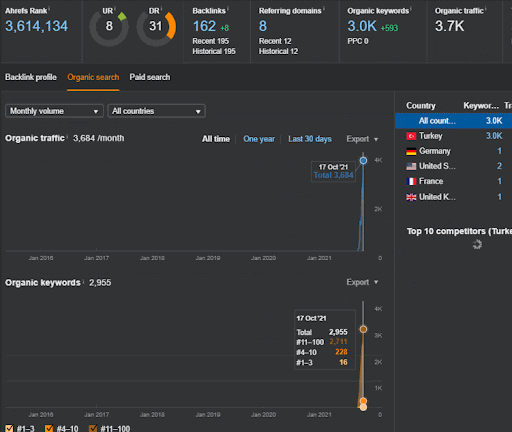
คุณสามารถรับชมการเปลี่ยนแปลงประสิทธิภาพทั่วไปของเครือข่ายเนื้อหาที่สองในช่วง 20 วันแรกได้จากโครงการ I
ในบริบทนี้ เมื่อใดก็ตามที่ Vizem.net เผยแพร่เอกสารใหม่ หรือเมื่อใดก็ตามที่ IstanbulBogazici Enstitu เผยแพร่เครือข่ายเนื้อหาที่มีความหมายใหม่ การจัดอันดับเริ่มต้นจะดีกว่าเมื่อก่อนในขณะที่เนื้อหาได้รับการจัดทำดัชนีเร็วขึ้น
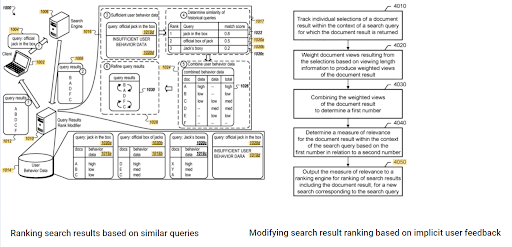
ความโดดเด่นของการจัดอันดับเริ่มต้นและข้อมูลในอดีตสามารถเห็นได้ระหว่างสองสิทธิบัตรเสริมของ Google หนึ่งคือสำหรับเอกสารเริ่มต้นและจัดลำดับใหม่ตามความคิดเห็นของผู้ใช้โดยนัย The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 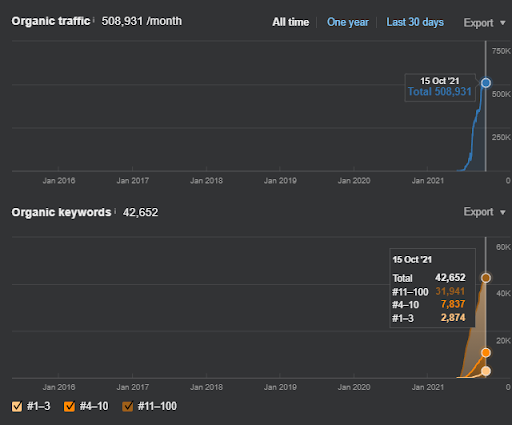
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 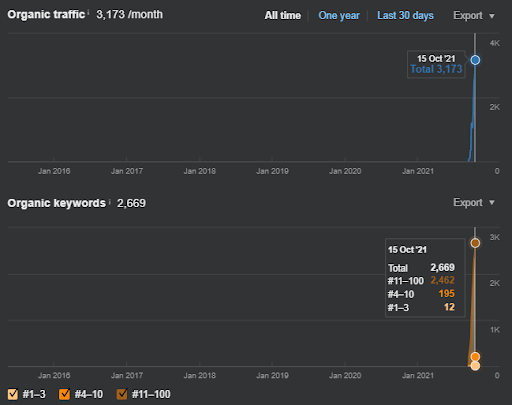
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 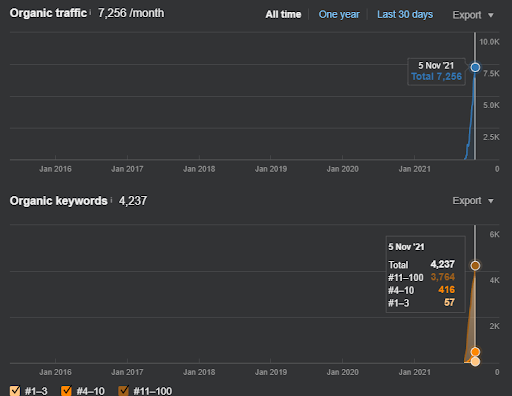
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 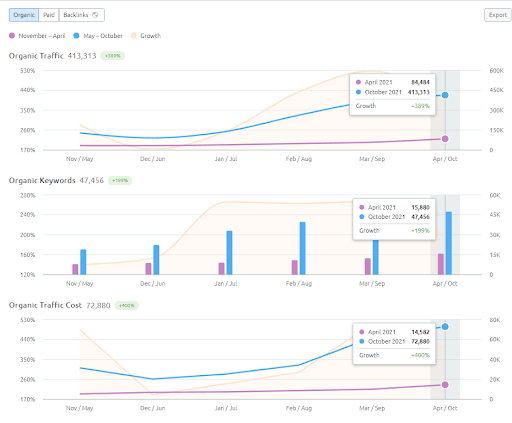
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.

Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.
The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Oncrawl Data³
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 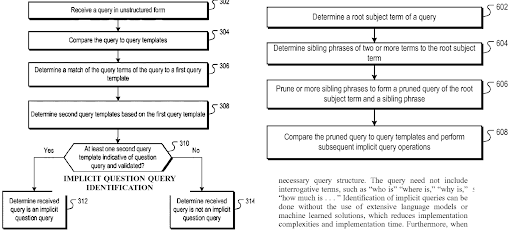
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
ใช่พวกเขาเป็น การจัดอันดับความน่าจะเป็นและการจัดอันดับความเกี่ยวข้องที่เสื่อมโทรมเป็นคอลัมน์หลักของเครื่องมือค้นหาเชิงความหมายเพื่อทำความเข้าใจผู้ใช้ และสร้าง SERP ที่มีคุณภาพดีที่สุดเท่าที่จะเป็นไปได้ซึ่งเตรียมไว้สำหรับสถานะของความเป็นไปได้ 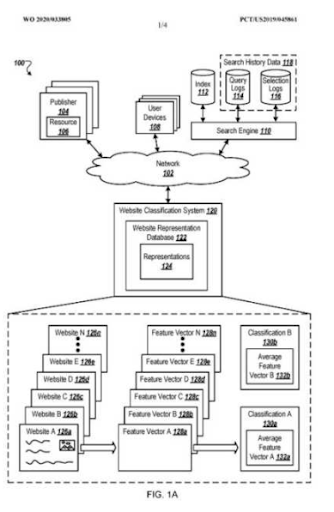
ก่อนหน้านี้ เพื่อให้ “การออกแบบเว็บไซต์ รูปลักษณ์ หรือโทนสี” เป็นข้อโต้แย้งสำหรับการเรียนรู้ตัวแทนสำหรับเว็บไซต์ Bill Slawski ได้เขียน “เวกเตอร์ตัวแทนเว็บไซต์”
เทมเพลตความตั้งใจในการค้นหาคืออะไร
เทมเพลตความตั้งใจในการค้นหาสามารถแสดงได้ด้วยความต้องการเบื้องหลังเทมเพลตคิวรี เท็มเพลตเอกสารการสืบค้นสามารถรวมกันโดยยึดตามเท็มเพลตเจตนา การมีเทมเพลตความตั้งใจในการค้นหาที่มีความเข้าใจ "อันดับความเกี่ยวข้องที่ลดลง" และ "อันดับความน่าจะเป็น" ที่เป็นไปได้จะช่วยในการสร้างกิจกรรมการค้นหาที่ดีที่สุดและครอบคลุมความตั้งใจในการค้นหาด้วยลำดับที่ถูกต้อง ขณะสร้าง Semantic Content Network สิ่งที่สำคัญที่สุดคือการปรับเทมเพลตการสืบค้นเอกสารตามบริบทของแหล่งที่มาสำหรับการเติมเครือข่ายความหมายตามโดเมนความรู้โดยปรับปรุงการครอบคลุมตามบริบทเพื่อปรับปรุงความน่าเชื่อถือตามความรู้และอำนาจเฉพาะ . 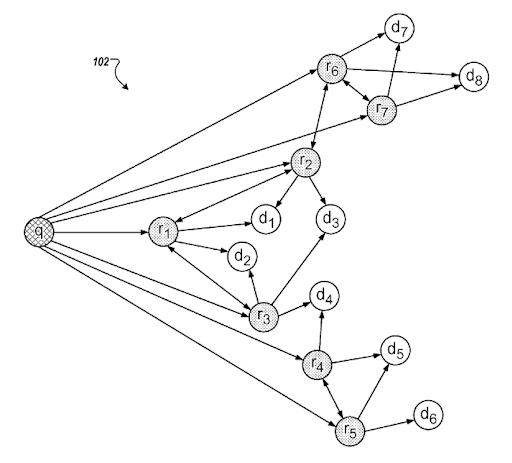
ส่วนจาก "การปรับแต่งการค้นหาตามเจตนาที่สรุป" ของ Google มันทำงานผ่านคลัสเตอร์การสืบค้นและเทมเพลตความตั้งใจที่มีการเชื่อมต่อทางความหมาย คุณสามารถสัมผัสมันได้ในระดับอนุกรมวิธานระดับต่างๆ
ก่อนที่จะไปยังตัวอย่างที่เป็นรูปธรรมและคำแนะนำในการช่วยคุณสร้างเครือข่ายเนื้อหาที่มีความหมายที่ดีขึ้น ฉันต้องบอกคุณว่าแม้แต่กรณีศึกษา SEO รุ่นธรรมดานี้ก็ยังต้องการความเข้าใจในเครื่องมือค้นหาและทักษะในการสื่อสารในระดับสูง ดังนั้น แม้ว่าฉันจะรู้สึกว่าได้ให้ข้อมูลในระดับสูง แต่ฉันก็รู้ว่าหลักสูตร Semantic SEO ที่ฉันจะสร้างจะแสดงตัวอย่างที่เป็นรูปธรรมมากขึ้นเรื่อยๆ ให้คุณเห็น 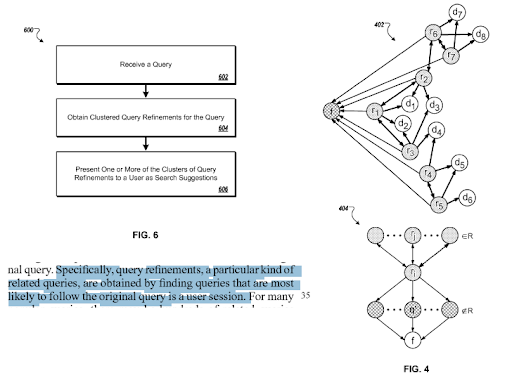
สิทธิบัตรเดียวกันอธิบายการเชื่อมต่อที่เหมาะสมระหว่าง "เส้นทางการสืบค้น" และ "การเปลี่ยนแปลงบริบท" ที่แตกต่างกัน
สิ่งที่คุณควรรู้เกี่ยวกับการใช้ประโยชน์จาก Semantic Content Networks?
ในการสร้างเครือข่ายเนื้อหาเชิงความหมาย บางครั้งแม้แต่การออกแบบและสรุปเนื้อหาเชิงความหมายง่ายๆ อาจใช้เวลาหนึ่งชั่วโมง หากคุณใส่รายละเอียดที่เกี่ยวข้องทั้งหมดตามความหมายคำศัพท์ หรือประเภทความสัมพันธ์ระหว่างเอนทิตีและวลี การใช้หลายมุมพร้อมกัน เช่น การสร้างดัชนีแบบวลี และเวกเตอร์ของคำ หรือเวกเตอร์บริบทเพื่อคำนวณความเกี่ยวข้องเชิงบริบทของเนื้อหาโดยรวมกับโดเมนตามบริบท หรือความเกี่ยวข้องตามประเภทเนื้อหาย่อยแต่ละรายการ ต้องใช้ความเข้าใจเครื่องมือค้นหาเชิงความหมายในระดับสูง
ดังนั้น การใช้วิธีการกำเนิดจะทำให้ทุกอย่างง่ายขึ้นด้วยแนวคิดที่ฉันได้อธิบายให้คุณฟังข้างต้น เพราะแม้ว่าคุณจะเตรียมทุกส่วนของเครือข่ายเนื้อหาที่มีความหมายอย่างสมบูรณ์แล้ว ผู้เขียนและผู้เขียนก็จะไม่สามารถเขียนมันได้ หรือผู้จัดการเนื้อหา จะไม่สามารถทำตามวิสัยทัศน์ของคุณได้ ดังนั้น อาจทำให้คุณเหนื่อยโดยเปล่าประโยชน์ และทำให้คุณออกจากโครงการเหมือนที่ฉันทำสำหรับโครงการกรณีศึกษา SEO เหล่านี้ หลังจากที่ฉันพิสูจน์แนวคิดด้วยวิธีที่เพียงพอ มีชีวิตชีวา และตรวจสอบได้
คำแนะนำด้านล่างนี้จะใช้ได้เฉพาะสำหรับขั้นตอนการทำงานที่ง่ายและสั้นซึ่งจะช่วยคุณได้
1. อย่าใช้ลิงก์แถบด้านข้างแบบตายตัวจากทุกเครือข่ายเนื้อหาที่มีความหมาย
ทุกลิงก์ควรมีคำอธิบายการเชื่อมต่อระหว่างเอกสารไฮเปอร์เท็กซ์สองฉบับ เช่นเดียวกับทุกคำในหน้าเว็บ การใช้ HTML เชิงความหมายสามารถช่วยระบุตำแหน่งและหน้าที่ของเอกสารบนหน้าเว็บ ในขณะที่ช่วยให้เครื่องมือค้นหากำหนดน้ำหนักส่วนต่างๆ ให้แตกต่างกันในแง่ของบริบท
ในตัวอย่าง Vizem.net ฉันไม่ได้ใช้การออกแบบแถบด้านข้างแบบเดียวกัน แถบด้านข้างไม่แสดงโพสต์ล่าสุดหรือโพสต์ที่สำคัญที่สุด แถบด้านข้างแสดงเฉพาะแอตทริบิวต์ของเอนทิตีส่วนกลาง และไม่ได้รับการแก้ไข แต่เป็นแบบไดนามิก กล่าวอีกนัยหนึ่ง ตามลำดับชั้นภายในแผนที่เฉพาะ เครือข่ายเนื้อหาเชิงความหมายจะเปลี่ยนแม้ว่าจะอยู่ในแถบด้านข้างก็ตาม 
การคิดถึงโมเดลนักท่องเว็บที่สมเหตุสมผลและนักท่องเว็บที่ระมัดระวังสามารถช่วย SEO เพื่อสร้างความเกี่ยวข้องที่ดีขึ้นระหว่างเอกสารไฮเปอร์เท็กซ์ต่างๆ
นอกจากนี้ ลิงก์ยังไหลในแง่ของความโดดเด่น และความนิยมควรเป็นไปตามบริบทของแหล่งที่มาจากการเชื่อมต่อที่ดีที่สุด ด้านล่างนี้ คุณสามารถดูส่วนของแถบด้านข้างพร้อมโค้ด HTML เชิงความหมายที่ปรับแล้ว 
ตามลำดับชั้นของบทความที่ใช้งานในเซสชันของผู้ใช้ แท็บ ลำดับของแท็บ ลิงก์ภายในแท็บจะเปลี่ยนไป ตัวอย่างข้างต้นมาจากลำดับชั้นการแสดงเส้นทางด้านล่าง ![]()
2. สนับสนุนเครือข่ายเนื้อหาเชิงความหมายด้วย PageRank
แม้ว่า PageRank ภายนอกจะไม่จำเป็นจากแหล่งข้อมูลภายนอก แต่หากคุณสามารถใช้ PageRank ได้ คุณจะรู้ว่าการจัดอันดับเริ่มต้นและการจัดอันดับใหม่นั้นจะดีกว่า สำหรับทั้งสองโครงการนี้ ฉันไม่ได้ใช้มัน แต่คราวนี้ มันไม่ใช่จุดประสงค์ สำหรับ Vizem.net มีปัญหาด้านเศรษฐกิจ และฉันไม่ต้องการใช้งบประมาณในการประชาสัมพันธ์และการประชาสัมพันธ์ดิจิทัล สำหรับ Istanbul BogaziciEnstitusu ฉันได้จัดเตรียม "แหล่งข้อมูลที่เชื่อมโยงถึงกันในพื้นที่" สองสามแห่งเพื่อสนับสนุนความถูกต้องของแหล่งที่มาสำหรับหัวข้อเฉพาะ แต่อีกครั้ง บริษัทไม่สามารถดำเนินการนี้ได้เนื่องจากปัญหาด้านงบประมาณและระเบียบวินัยขององค์กร 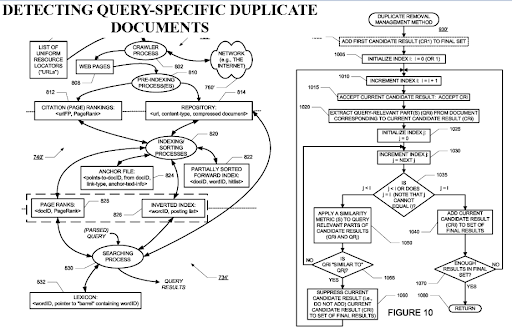
การตรวจจับเอกสารที่ซ้ำกันเฉพาะคำค้นหาเป็นมุมมองที่สำคัญจากเครื่องมือค้นหา เนื่องจาก PageRank สามารถช่วยให้เอกสารถูกกรองว่ามีค่าแม้ว่าจะซ้ำกันก็ตาม เนื่องจากเครือข่ายเนื้อหาเชิงความหมายที่มีการจัดระเบียบสูงอาจมีความคล้ายคลึงกัน โฟลว์ PageRank และข้อมูลในอดีตจึงมีประโยชน์
เมื่อต้องเลือกโฟลว์พอยต์เพจแรงก์ภายนอกสำหรับเครือข่ายเนื้อหาเชิงความหมายประเภทนี้ ให้ใช้แหล่งข้อมูลที่มีข้อมูลในอดีต ในกรณีของฉัน ฉันได้จัดเตรียมตำแหน่งข้อมูล PageRank เหล่านี้ไว้ก่อนหน้านี้ ก่อนที่ฉันจะเปิดตัวและเผยแพร่เครือข่ายเนื้อหาที่มีความหมายเครือข่ายแรก ด้วยวิธีนี้ ฉันสามารถดึงข้อมูลอ้างอิงภายนอกจากคู่แข่งโดยตรงได้ แต่เมื่อฉันเผยแพร่เครือข่ายเนื้อหาที่มีความหมาย คู่แข่งก็เลิกลิงก์แหล่งที่มาเพราะพวกเขาเห็นว่าแหล่งที่มาเพิ่มขึ้นจำนวนมากในฐานะคู่แข่ง
สถานการณ์นี้นำเราไปสู่ข้อเสนอแนะที่สาม หากเราสามารถใช้โฟลว์ PageRank จากการอ้างอิงภายนอก กระบวนการจัดลำดับใหม่จะเร็วขึ้น และการจัดอันดับเริ่มต้นจะสูงขึ้น
3. ใช้ Anchor Texts ที่แตกต่างจาก Footer, Header และ Main Content สำหรับเนื้อหาเครือข่าย Semantic Content ที่โดดเด่น
ข้อความยึดหรือ "ข้อความลิงก์" จากมุมมองของเครื่องมือค้นหาจะส่งสัญญาณถึงความเกี่ยวข้องของเอกสารไฮเปอร์เท็กซ์กับอีกเอกสารหนึ่ง ตามเอกสารต้นฉบับของ PageRank จำนวนลิงก์เป็นสัดส่วนกับโฟลว์ PageRank แต่ภายหลัง Google ได้เปลี่ยนแปลงสิ่งนี้เพื่อป้องกัน "การบรรจุลิงก์" และจำกัดลิงก์ที่สามารถส่งเพจแรงก์ได้จริง จากสิ่งนี้ จึงมีการพัฒนา TrustRank, Cautious Surfer, Hilltop Algorithm หรือ Models Surfer ที่สมเหตุสมผล 
นี่คือลิงก์สองลิงก์ไปยังเครือข่ายเนื้อหาที่มีความหมายต่างกันสำหรับ BogaziciEnstitusu แต่เนื่องจากฉันไม่ได้ใช้ SEO ด้านเทคนิคหรือการปรับปรุง UX คุณจึงสามารถรับรู้ถึง "ราคาถูก" ของการออกแบบปุ่มได้
ตาม Google ลิงก์เดียวกันไม่สามารถส่ง PageRank เป็นครั้งที่สองไปยังหน้าเว็บอื่นได้ ในขณะที่ PageRank จะถูกส่งต่อจากลิงก์แรกเท่านั้น และในรูปแบบดั้งเดิมของอัลกอริธึม PageRank เอกสารไฮเปอร์เท็กซ์สามารถเชื่อมโยงตัวเองเพื่อปรับปรุง PageRank หรือสามารถใช้การเปลี่ยนเส้นทาง 301 เพื่อนำ PageRank ของเอกสารเป้าหมายลิงก์ สถานการณ์ทั้งสองนี้ได้สร้างเทคนิค Black Hat แบบเก่า เช่น การเปลี่ยนเส้นทางหน้าเว็บไปยังอีกหน้าเว็บหนึ่งเป็นการชั่วคราวเพื่อใช้ PageRank นับตั้งแต่วันที่ SEO สามารถดู PageRank ของหน้าเว็บจาก Google Search Console หรือ SERP ต่อมา Google เริ่มลดอันดับ PageRank ด้วยการเปลี่ยนเส้นทางทุกครั้ง ในขณะที่ Danny Sullivan อธิบายว่าการเปลี่ยนเส้นทาง 301 ครั้งจะส่ง PageRank ทั้งหมด นอกจากการเปลี่ยนแปลงทั้งหมดเหล่านี้แล้ว สิ่งสำคัญในที่นี้คือแม้ว่าลิงก์ที่สองจะไม่ผ่านเพจแรงก์ แต่ก็ยังส่งผ่านความเกี่ยวข้องของข้อความลิงก์ 
ส่วนที่โดดเด่นของเครือข่ายเนื้อหาเชิงความหมายได้รับการเชื่อมโยงจากโฮมเพจตาม "การปรับแต่งข้อความค้นหาระดับกลาง" ซึ่งรวมถึง "กริยา เพรดิเคต" หรือ "กิจกรรมของผู้ค้นหา"
ดังนั้น ส่วนที่โดดเด่นของเครือข่ายเนื้อหาเชิงความหมายควรเชื่อมโยงจากเมนูส่วนหัวและส่วนท้ายที่มีส่วนการจัดหมวดหมู่ที่สูงกว่า และข้อความลิงก์ควรแตกต่างกัน ในตัวอย่างเหล่านี้ ฉันได้ใช้ลิงก์ส่วนหัวที่มีข้อความลิงก์สั้นๆ ที่เห็นได้ชัดเจน ขณะที่ฉันเก็บตัวอย่างส่วนท้ายให้ยาวขึ้น 
ส่วนหนึ่งของ "การจัดทำดัชนีแท็ก Anchor ในระบบรวบรวมข้อมูลเว็บ" จะสรุปความสำคัญของข้อความ Anchor และข้อความหมายเหตุเพื่อวางตำแหน่งหน้าเว็บภายในคลัสเตอร์การค้นหาและคลัสเตอร์ของหน้าเว็บ
หากส่วน Semantic Content Network โดดเด่นเกินไป ในการส่ง PageRank และลำดับความสำคัญของการรวบรวมข้อมูลอย่างเหมาะสม ฉันได้เชื่อมโยงส่วนที่สำคัญที่สุดกับข้อความลิงก์ที่เหมาะสม และย่อหน้าที่อธิบายที่มีแอตทริบิวต์ที่โดดเด่นพร้อมรูปแบบ N-Gram ที่แตกต่างกัน 
นี่เป็นพื้นที่เชื่อมโยงที่สองจากหน้าแรกของ Vizem.net ซึ่งอยู่หลังหีบเพลง และเน้นที่ประเทศต่างๆ ภายในข้อความค้นหา และเชื่อมโยงส่วนตรงกลางของเครือข่ายเนื้อหาเชิงความหมาย
หมายเหตุ: มีการใช้ "ข้อความคำอธิบายประกอบ" ที่วางแผนไว้รอบๆ Anchor Text เพื่อปรับปรุงความแม่นยำของจุดประสงค์ของลิงก์
4. จำกัดการจำกัดจำนวนลิงก์และจับคู่ลิงก์เดสก์ท็อปและมือถือและเนื้อหาหลัก
ทั้งสองโครงการถูกจำกัดให้มีลิงก์ภายในน้อยกว่า 150 ต่อหน้าเว็บ ด้วยความช่วยเหลือของ Semantic HTML ตำแหน่งของลิงก์และฟังก์ชันของลิงก์จะถูกทำให้ชัดเจนต่อโปรแกรมรวบรวมข้อมูล IstanbulBogazici Enstitusu มีลิงก์มากกว่า 450 ลิงก์ต่อหน้าเว็บ และบางส่วนเป็นลิงก์ด้วยตนเอง (ลิงก์จากหน้าเดียวกันไปยังหน้าเดียวกัน) ส่วนที่แย่ที่สุดคือลิงก์ครึ่งหนึ่งไม่มีอยู่ในเนื้อหาเวอร์ชันมือถือ 
URL Keep Score, Crawl Score และคะแนนประเภทอื่นๆ สามารถใช้เพื่อกำหนดความโดดเด่นของลิงก์ภายในแมป URL ภายใน และใช้แท็กระบุเอกสารภายในระดับต่างๆ เพื่อจัดเรียงดัชนีตามคะแนนความเกี่ยวข้องที่ไม่ขึ้นกับข้อความค้นหา
เนื่องจาก Google ใช้การจัดทำดัชนีเฉพาะอุปกรณ์เคลื่อนที่ หากไม่มีเนื้อหาอยู่ในเวอร์ชันสำหรับมือถือ เนื้อหานั้นจะถูกละเว้น และจะไม่ใช้เพื่อการประเมินความเกี่ยวข้องและการจัดอันดับ ดังนั้น เนื้อหาบนมือถือและเดสก์ท็อปจึงได้รับการกำหนดค่าให้จับคู่กันได้ แม้ว่า Google จะยอมให้เนื้อหาไม่ตรงกันระหว่างเวอร์ชันเดสก์ท็อปและมือถือ แต่ก็ยังทำให้การทำความเข้าใจและจัดอันดับหน้าเว็บยากขึ้นสำหรับเครื่องมือค้นหา 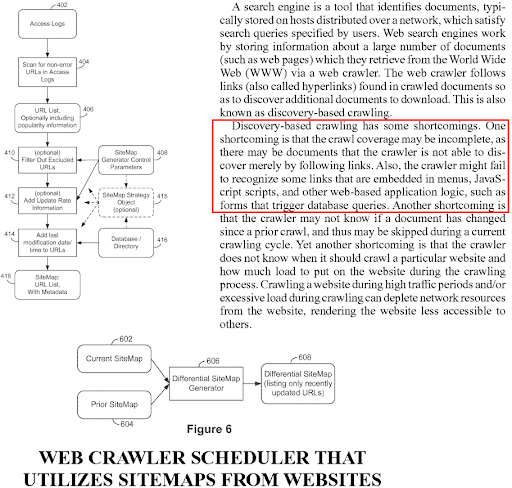
เสิร์ชเอ็นจิ้นสามารถสร้างแผนผังเว็บไซต์สำหรับเว็บไซต์ และแผนผังเว็บไซต์นี้สามารถสร้างใหม่ได้แบบวนซ้ำ หากลิงก์และข้อมูลเมตาของ URL ไม่ตรงกันระหว่าง user-agent หรือไทม์ไลน์ ดังนั้น การรักษาเส้นทางการรวบรวมข้อมูลให้สั้น บทสรุปของคิวการรวบรวมข้อมูล และการเชื่อมโยงภายในที่สอดคล้องกันจึงเป็นสิ่งสำคัญ
นอกจากลิงก์ระหว่างหน้าเว็บต่างๆ แล้ว ลิงก์สำหรับส่วนย่อยของหน้าเว็บยังใช้กับ "สารบัญ" และ "ส่วนย่อยของ URL" ด้วย ส่วนต่างๆ ของ URL เหล่านี้กำหนดเป้าหมายไปยังส่วนย่อยเฉพาะของหน้าเว็บในขณะที่ตั้งชื่ออย่างถูกต้อง และส่วนนั้นได้ถูกใส่ลงในแท็กส่วนที่มี h2 แล้ว ด้วยความช่วยเหลือของส่วนย่อยของ URL ที่มี "ลิงก์การนำทางในหน้า" การเชื่อมโยงผู้ใช้จาก SERP ไปยังส่วนเฉพาะของหน้าเว็บทำได้ง่ายขึ้น ในขณะที่ส่วนล่างของเนื้อหามีความโดดเด่นมากขึ้นเพื่อตอบสนองความต้องการที่อยู่เบื้องหลัง แบบสอบถาม
5. มีวินัยระดับทหารสำหรับโครงการ SEO ของคุณ
นี่เป็นอีกหัวข้อหนึ่งทั้งหมดและสามารถเขียนบทความอื่นเพื่อกำหนดความหมายของระเบียบวินัยระดับทหาร หรือเหตุใดจึงมีประโยชน์สำหรับโครงการ SEO แต่ฉันต้องบอกคุณว่าในช่วง 2 เดือนที่ผ่านมา ฉันได้ฝึกอบรม CEO และ SEO จำนวนมากจากเอเจนซี่อื่นพร้อมกับทีมของพวกเขา เพื่อดูว่าการออกแบบหลักสูตรของฉันจะทำงานได้ดีหรือไม่
เมื่อใดก็ตามที่ฉันเห็นความสำเร็จและมีความโลภในระดับสูงสำหรับช่วงการศึกษาที่ฉันแสดง จะมีเจตจำนงที่เข้มแข็งและความอุตสาหะที่แข็งแกร่ง ปัญหาหลักคือ Semantic SEO นั้นยากกว่า SEO Verticals อื่นๆ มาก SEO ทางเทคนิคเป็นสากลและมีคำแนะนำเป็นลายลักษณ์อักษรสำหรับทุกขั้นตอน OnPage SEO หรือ WUX และ Layout Design สามารถติดตามได้โดยใช้การวัดเป็นตัวเลข เมื่อพูดถึง Semantics เป็นแนวปฏิบัติในการรวมมุมมองของเครื่องที่ทำงานโดยใช้ระบบการปรับตัวที่ซับซ้อนกับ Homo-sapiens ที่ไม่เข้าใจวิธีการทำงานของเครื่อง
ความแตกต่างนี้จำเป็นต้องมีฐานรากที่เป็นรูปธรรมซึ่งควรวางไว้ตั้งแต่วันแรกของโครงการ ส่วนใหญ่ฉันใช้กฎด้านล่าง
- การออกแบบเนื้อหาและเครือข่ายเนื้อหาที่มีความหมายไม่จำเป็นต้องมีเหตุผลสำหรับผู้เขียนหรือนักเขียน
- งานของผู้จัดการเนื้อหาคือการตรวจสอบความเข้ากันได้ของเนื้อหากับการออกแบบเนื้อหา
- งานของผู้เขียนคือการเขียนเนื้อหาที่มีข้อมูลที่เกี่ยวข้องซึ่งมีความแม่นยำและรายละเอียดสูง
- การเชื่อมโยง คำจำกัดความ หลักฐาน การเปรียบเทียบ ข้อเสนอ การอ้างอิง ควรทำด้วยตัวอย่างที่เป็นรูปธรรม ไม่ใช่ด้วยปุย
- คำที่ไม่จำเป็นทุกคำเป็นการเจือจางสำหรับบริบทและแนวคิด
เมื่อคุณอ่านอาจฟังดูง่ายในการนำไปใช้ แต่ก็ไม่ง่ายนัก ดังนั้น ฉันสามารถบอกได้ว่าฉันกำลังจะไล่พนักงานบางคนออก ฉันดีใจที่ฉันไม่ได้ทำ อย่างน้อยก็ในตอนนี้ ในสภาวะปกติจะมีคำถามมากมายที่จะถูกถาม ถ้าเจ้าของคำถามไม่ใช่ SEO หรือเจ้าของบริษัทอย่าตอบ ประหยัดพลังงานของคุณไปยังการจัดเก็บข้อมูลของเครื่องมือค้นหาที่จะเก็บความคิดเห็นในเชิงบวกของคุณ ไม่ใช่ความคิดเห็นที่ซ้ำซากและไม่เกี่ยวข้องกับการจัดอันดับ
6. ขยายแหล่งที่มาด้วยความเกี่ยวข้องตามบริบท
ส่วนนี้ทั้งหมดเกี่ยวกับการทำความเข้าใจความต้องการของ Google ในการสร้าง MuM เมื่อคุณออกแบบ Topical Map จะรวม Semantic Content Networks จำนวนมากซึ่งจะให้ฐานความรู้ระดับไซต์ที่ดีขึ้น ดังนั้น ขณะเผยแพร่ส่วนย่อยเหล่านี้ พวกเขาควรจะสามารถเชื่อมต่อกับบริบทของแหล่งที่มาได้ หรืออาจเปลี่ยนวิธีที่เครื่องมือค้นหามองเห็นแหล่งที่มา และธีมของเว็บไซต์สามารถสลับไปยังโดเมนความรู้อื่นได้ ตัวอย่างเช่น การเชื่อมโยงสิ่งต่าง ๆ รอบแนวคิดและพื้นที่ความสนใจกับการกระทำที่เป็นไปได้ จำเป็นต้องมีความเข้าใจในการเชื่อมต่อระหว่างความหมายที่ซับซ้อน การทำให้การเชื่อมต่อเหล่านี้ชัดเจนแก่ผู้ใช้ ผู้เขียน และเครื่องในเวลาเดียวกันคือกระบวนการของการสร้างเครือข่ายเนื้อหาเชิงความหมาย 
เพื่อให้บรรลุสิ่งนี้ ทุกส่วนใหม่สำหรับเว็บไซต์ควรจะสามารถเชื่อมต่อกับส่วนกลางของแผนที่เฉพาะ สะพานเชิงบริบทเหล่านี้สามารถเห็นได้จากการออกแบบและคำอธิบาย LaMDA ของ Google
ฉันพบคำถามมากมาย เช่น “ฉันควรเขียนเกี่ยวกับหัวข้ออื่นหรือไม่”, “ถ้าฉันมีสองประเด็นที่แตกต่างกัน มันจะเป็นอันตรายไหม” หากคุณเชื่อมโยงส่วนย่อยทั้งหมด ส่วนเว็บไซต์เป็นส่วนประกอบที่เชื่อมต่อกันอย่างแน่นหนา เครือข่ายเนื้อหาเชิงความหมายเหล่านี้จะสนับสนุนซึ่งกันและกันเพื่ออันดับที่ดีขึ้นแทนที่จะแบ่งเอกลักษณ์ของแบรนด์ และอำนาจเฉพาะสำหรับสองหัวข้อที่แตกต่างกันและไม่เกี่ยวข้อง
7. สร้างปริมาณการใช้งานจริงและการตรวจสอบด้วย Google Analytics Custom Segmentation
การรับส่งข้อมูลจริงเชื่อมต่อกับ RankMerge ในลักษณะเดียวกับที่ Trust ตามความรู้เชื่อมต่อกับ PageRank เร็วๆ นี้ ฉันกำลังคิดที่จะเขียนบทความอื่นในชื่อ “When the PageRank Lies…” เพื่ออธิบายว่าทำไมเสิร์ชเอ็นจิ้นจึงพยายามส่งผลกระทบกับเพจแรงก์ด้วยสัญญาณด้านข้าง อันที่จริง PageRank ไม่ใช่สัญญาณที่บ่งบอกถึงอำนาจ ความเชี่ยวชาญ และความน่าเชื่อถือของแหล่งที่มา อาจเป็นสัญญาณของการจัดอันดับและเป็นปัจจัยหนึ่ง แต่ไม่สามารถเชื่อถือได้เพียงลำพัง RankMerge เป็นกระบวนการของการรวมการเข้าชมเว็บไซต์และ PageRank เข้าด้วยกันในลักษณะที่เว็บไซต์สามารถทำความเข้าใจกับเครื่องมือค้นหาได้ PageRank สูงและปริมาณการใช้ข้อมูลต่ำสามารถบ่งบอกถึง "ปริมาณการใช้ข้อมูลที่ไม่เป็นที่นิยม" หรือ "การจัดการ PageRank"
ดังนั้น เพื่อปรับปรุงข้อมูลในอดีตของแหล่งที่มา ฉันจึงใช้เหตุการณ์ SEO ตามฤดูกาล และฉันได้เพิ่มข้อความค้นหา "แบรนด์ + คำทั่วไป" การเข้าชมโดยตรงและหน้าเว็บที่บุ๊กมาร์กไว้จะเพิ่มขึ้นตามปริมาณการใช้งานจริงและเป็นของแท้
ข้อมูลประเภทนี้ช่วยให้เสิร์ชเอ็นจิ้นไว้วางใจในการจัดอันดับให้สูงขึ้นและสูงขึ้นใน SERP
เพื่อให้สามารถตรวจสอบการเข้าชมจริงเหล่านี้ที่มาจากเครือข่ายเนื้อหาเชิงความหมาย SEO สามารถสร้างกลุ่มที่กำหนดเองจาก Google Analytics เพื่อดูว่าพวกเขามาในรูปแบบการเข้าชมโดยตรงได้อย่างไร นอกจากนี้ คุณสามารถสร้างเป้าหมายที่กำหนดเองได้ เช่น การสร้างเส้นทางการค้นหาที่เป็นไปได้จากเครือข่ายเนื้อหาเชิงความหมายแรกไปยังเครือข่ายเนื้อหาที่สอง นี่คือข้อพิสูจน์ของแนวคิดที่ว่าเครือข่ายความหมายถูกสร้างขึ้นจากความสนใจ แนวคิด และการดำเนินการที่เกี่ยวข้องกับการค้นหาที่เป็นไปได้
ด้านล่างนี้ คุณจะพบเพียงตัวอย่างเดียวสำหรับหน้าเว็บใดหน้าเว็บหนึ่งที่วางอยู่ภายในเครือข่ายเนื้อหาเชิงความหมายแรก เพื่อสาธิตการเข้าชมโดยตรงที่ได้รับผ่านการเข้าชมที่เกิดขึ้นเอง 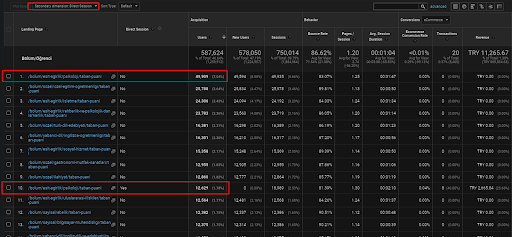
ในช่วง 3 เดือนที่ผ่านมา มีเพียงหน้าเว็บเดียวจากเครือข่ายเนื้อหาเชิงความหมายแรกที่มีผู้ใช้ทั่วไป 49.000 คนใช้ และผู้ใช้เพิ่มเติม 12.900 รายมาจากการเข้าชมโดยตรงซึ่งได้มาจากการค้นหาทั่วไปเป็นครั้งแรก และเมตริกเซสชัน/หน้าและระยะเวลาเซสชันเฉลี่ยก็สูงขึ้นสำหรับกลุ่มผู้ใช้เหล่านี้
ดังที่กล่าวไว้ก่อนหน้านี้ เสิร์ชเอ็นจิ้นสามารถจัดกลุ่มการสืบค้น เอกสาร ความตั้งใจ แนวคิด ความสนใจ การดำเนินการ แต่ก็สามารถจัดกลุ่มผู้ใช้ได้เช่นกัน หากกลุ่มผู้ใช้ให้ผลตอบรับเชิงบวกในขณะที่สร้างมูลค่าแบรนด์โดยเพิ่มหน้าเว็บเหล่านี้ในบุ๊กมาร์ก พิมพ์แถบที่อยู่โดยตรง และค้นหาคำทั่วไปพร้อมกับชื่อแบรนด์ ก็แสดงว่าแหล่งที่มาปรับปรุงอำนาจและเครื่องมือค้นหา สามารถรับรู้ทุกอย่างจาก SERP, Chrome และที่อยู่ DNS ของตัวเอง 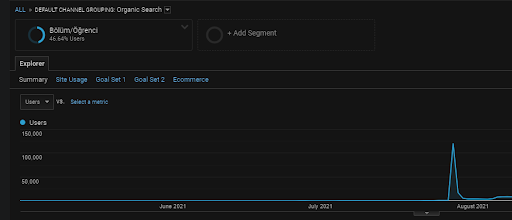
ด้านบน คุณสามารถดูกลุ่มผู้ใช้ของ First Content Network คุณสามารถสร้างกลุ่มผู้ใช้สำหรับทุกเครือข่ายเนื้อหาเชิงความหมายโดยมีเป้าหมายที่กำหนดเอง และคุณสามารถเพิ่มกลุ่มผู้ใช้ย่อยสำหรับเครือข่ายเนื้อหาย่อยเชิงความหมายได้เช่นกัน
8. รองรับเครือข่ายเนื้อหาเชิงความหมายด้วยส่วนย่อยตามกิจกรรมการค้นหา
ส่วนนี้ยังเกี่ยวกับการแก้ไขแอตทริบิวต์ของเอนทิตี และการวิเคราะห์ซึ่งเป็นอีกหัวข้อหนึ่ง แต่พูดง่ายๆ ก็คือ คุณลักษณะบางอย่างของเอนทิตีเหล่านี้ตามโดเมนบริบทควรอยู่ในลำดับชั้นที่ต่ำกว่า ไม่ใช่ในลำดับชั้นที่สูงกว่า ในกรณีนี้ “Vizem.net” สามารถให้ตัวอย่างที่ดีกว่า ในขณะที่ Bogazici Enstitusu นั้นสามารถแสดงให้เห็นได้ด้วย “เงินเดือนของอาชีพ” และ “คะแนนสอบของมหาวิทยาลัย” มีการวางแอตทริบิวต์ที่โดดเด่นทั้งสองนี้ตามการสืบค้นและเทมเพลตเอกสารในเครือข่ายเนื้อหาย่อยเชิงความหมาย 
การระบุหน่วยความหมายจากภายในคำค้นหาเป็นอีกสิทธิบัตรหนึ่งของ Google ที่แบ่งวลีออกเป็นหมวดหมู่ความหมายต่างๆ และรวบรวมความเกี่ยวข้องของเอกสารโดยพิจารณาจากความใกล้ชิดกับรูปแบบทั้งหมดของข้อความค้นหา
ในกรณีศึกษา SEO ครั้งก่อน ฉันไม่ได้ทำตามโครงสร้างประเภทนี้ ฉันสร้างเส้นทางการรวบรวมข้อมูลตาม "ลำดับเหตุการณ์" และลิงก์ภายในที่จำกัดอย่างเข้มงวด ในบทความเหล่านี้ เนื้อหาหลักที่วางจำนวนลิงก์ภายในจะสูงกว่าครั้งก่อน
9. ใช้คำเฉพาะภายใน URLs
หาก Google พบ URL ที่แตกต่างกัน 2 รายการซึ่งมีเนื้อหาเหมือนกันโดยไม่มีสัญญาณ Canonicalization จะเลือก URL แบบสั้นเป็น URL ตามรูปแบบบัญญัติ เนื่องจาก URL แบบสั้นนั้นง่ายต่อการแยกวิเคราะห์ แก้ไข และร้องขอ เมื่อคุณมีหน้าเว็บหลายล้านล้านหน้าที่คุณรีเฟรชหลายพันล้านครั้งทุกวัน แม้แต่ตัวอักษรใน URL ก็สามารถแสดง "ความสมดุลของต้นทุน/คุณภาพ" ของเว็บไซต์ได้ อย่างที่ฉันพูดไปก่อนหน้านี้ "ค่าใช้จ่ายในการดึงข้อมูล" ควรต่ำกว่า "ค่าใช้จ่ายในการไม่ดึงข้อมูล" หากคุณต้องการให้เครื่องมือค้นหาเข้าใจ คุณควรใส่ "สัญญาณบริบทที่สั่งและเสริม" ในทุกระดับ รวมทั้ง URL 
ส่วนจากการจัดอันดับ "ตามหลักฐาน" ผ่านการรวบรวมหลักฐาน อธิบายวิธีการจับคู่คำตอบกับคำถาม
ในบริบทนี้ ส่วนใหญ่ฉันใช้คำเดียวภายใน URL สิ่งเหล่านี้สามารถสะท้อนถึงลำดับชั้นและโครงสร้างของเครือข่ายเนื้อหาเชิงความหมาย บางคนยังคิดว่า “การนับเลเยอร์” ภายใน URL ส่งผลต่อความถี่ในการรวบรวมข้อมูล จริงอยู่ก่อนปี 2019 แต่ตราบใดที่เนื้อหามีความสมเหตุสมผล และทำให้ผู้ใช้พึงพอใจจากหัวข้อที่ได้รับความนิยมหรือโดดเด่น จะไม่ได้รับผลกระทบจากสถานการณ์ดังกล่าว
เพื่อสาธิต คุณสามารถทำตามตัวอย่างด้านล่าง
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
เครือข่ายเนื้อหาเชิงความหมายทั้งสองนี้สามารถเชื่อมโยงกันได้จากลำดับชั้นเดียวกัน และสามารถเชื่อมโยงตัวเองตามความเกี่ยวข้องได้เช่นกัน มีหลายสิ่งหลายอย่างที่เราพูดถึงได้ เช่น “Entity Grouper Contents – Hub Type Content” แต่เป็นหัวข้อของวันอื่น
หมายเหตุ: เครือข่ายเนื้อหาที่มีความหมายที่สามที่วางแผนไว้สามารถประมวลผลเป็น "เครือข่ายเนื้อหากลุ่มแนวคิด" ได้เช่นกัน และหากมีการเผยแพร่ด้วยผลกระทบของเครือข่ายเนื้อหาเชิงความหมายที่สอง การเข้าชมทั่วไปโดยรวมอาจมีมากกว่า 3 ล้านเซสชันต่อเดือน
10. ทำความเข้าใจความแตกต่างระหว่างการทำรังและการเชื่อมต่อ
เนื่องจากความแตกต่างของระเบียบวิธีปฏิบัติในทางปฏิบัติ การเชื่อมต่อคือการเชื่อมต่อสิ่งที่คล้ายคลึงกันโดยอิงตามโดเมนบริบท ในขณะที่การซ้อนเป็นการจัดกลุ่มเนื้อหาที่คล้ายกันโดยมีจุดประสงค์เดียวกันไว้ด้วยกัน การจัดกลุ่มนี้จะช่วยให้เสิร์ชเอ็นจิ้นค้นหาเนื้อหาที่คล้ายกันได้เร็วขึ้น และสร้างคะแนนคุณภาพแหล่งที่มาสำหรับกลุ่มเหล่านี้ หรือเนื้อหาที่ซ้อนกันเหล่านี้ตามเครือข่ายความหมายจะง่ายขึ้น 
ลองนึกภาพว่ามีเส้นทางการรวบรวมข้อมูลที่แตกต่างกันสองเส้นทางดังนี้
- เส้นทางการรวบรวมข้อมูล 1: พบ URL แบบสุ่ม โดยไม่มีเทมเพลต ความเหมือน และความเกี่ยวข้องตามบริบท
- เส้นทางการรวบรวมข้อมูล 2: พบ URL ที่สมเหตุสมผลแม้จะมาจากตัว URL ด้วยเทมเพลตที่มีความคล้ายคลึงและความเกี่ยวข้องในระดับสูงตามบริบท
หากแม้แต่จากเส้นทางการรวบรวมข้อมูล เนื้อหาก็สมเหตุสมผล "การจัดอันดับเริ่มต้น" และ "การจัดลำดับใหม่" จะดีกว่าด้วย "การทริกเกอร์การจัดลำดับใหม่ตามความเข้าใจความครอบคลุมของเครื่องมือค้นหา"
หมายเหตุ: การใช้ลิงก์ภายในที่มีการจัดหมวดหมู่วลีอย่างเหมาะสมเป็นสิ่งสำคัญสำหรับการซ้อนและเชื่อมต่อ
สิ่งนี้นำเราไปสู่การแบ่งปันวิธีการเชิงปฏิบัติสองวิธีสุดท้ายโดยสังเขป และส่วนนี้เกี่ยวข้องกับวินัยระดับสูงและความเพียงพอขององค์กรอีกครั้ง 
สิทธิบัตรจาก Trystan Upstill และ Steven D. Baker สำหรับการระบุเงื่อนไขที่เกิดขึ้นร่วมกันภายในรายการ HTML ความโดดเด่นของสิทธิบัตรนี้คือมันแสดงให้เห็นคุณค่าของรายการ HTML เดียวเพื่อกำหนดรายการคำศัพท์ที่เกิดขึ้นร่วมกันสำหรับหัวข้อหรือส่วนหนึ่งของอนุกรมวิธานวลี
11. ทำความเข้าใจว่าเมื่อใดควรเผยแพร่เครือข่ายเนื้อหาเชิงความหมายด้วยความถี่ที่ปรับแล้ว
สิ่งนี้ได้รับการอธิบายมาก่อนแล้ว แต่ในโครงการกรณีศึกษา SEO เหล่านี้ ฉันได้เผยแพร่เนื้อหาเกือบ 400 ชิ้นในหนึ่งวัน อีกเรื่องหนึ่งผมเริ่มตีพิมพ์แค่ 10-15 เนื้อหากะทันหัน แล้วผมก็เพิ่มความเร็วไปเรื่อยๆ อย่างมั่นคง จนกระทั่งปัญหาเศรษฐกิจที่เกี่ยวข้องกับโควิดเริ่มต้นขึ้น
หากแหล่งข้อมูลใหม่สร้าง Semantic Content Network ใหม่ การเผยแพร่ในวันแรกอาจยากกว่าที่คุณคิดเล็กน้อย การตรวจสอบลิงก์ภายใน ไวยากรณ์ และข้อมูลบนหน้าเว็บทั้งหมดไม่ใช่เรื่องง่าย แต่ถ้าเนื้อหาทั้งหมดมาจากหัวข้อเดียวและเทมเพลตการสืบค้น และหากแหล่งที่มาไม่มีประวัติในหัวข้อนั้น การเผยแพร่ส่วนใหญ่ของเครือข่ายเนื้อหาเชิงความหมายก็มีข้อดี เช่น การทำดัชนีที่เร็วขึ้น ความเข้าใจ และ จัดอันดับใหม่
ในสถานการณ์ของฉัน ยังมีเหตุการณ์ทางประวัติศาสตร์ตามฤดูกาลอีกด้วย ดังนั้น จุดประสงค์ของฉันคือการมีอันดับเฉลี่ยเพียงพอจนกว่าฉันจะสามารถทดสอบโดยเครื่องมือค้นหาสำหรับเอนทิตีเฉพาะและกิจกรรมการค้นหากับแหล่งข้อมูลที่เก่ากว่า ดังนั้นฉันจึงได้เผยแพร่ Semantic Content Network แห่งแรกที่มีการเตรียมการระดับสูงก่อน 45 วันนับจากกิจกรรมตามฤดูกาล
จากนั้น คุณสามารถดูวิธีที่ Search Engine ทดสอบแหล่งที่มาซ้ำๆ ดังต่อไปนี้ 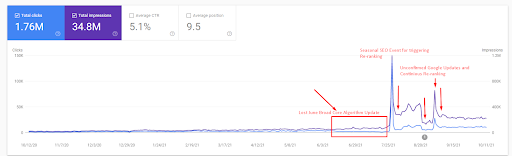
คำอธิบายโดยละเอียดเพิ่มเติมสามารถดูได้ที่ด้านล่าง 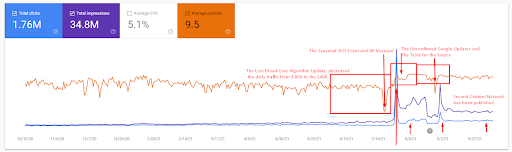
สามารถตรวจสอบข้อเท็จจริงอย่างรวดเร็วได้ที่ด้านล่างสำหรับคำอธิบายภาพหน้าจอด้านบน
- Broad Core Algorithm Update ได้ลดทราฟฟิกของเว็บไซต์ลงมากกว่า 200%
- เว็บไซต์ยังสูญเสียข้อความค้นหามากกว่า 15,000 รายการ
- สิ่งนี้ส่งผลต่อการจัดทำดัชนีโดยรวมของแหล่งที่มาสำหรับเครือข่ายเนื้อหาที่มีความหมายใหม่ ดังที่อธิบายไว้ในบทความกรณีศึกษา SEO โดยละเอียด
- ต้องขอบคุณกิจกรรม SEO ตามฤดูกาล การจัดลำดับใหม่จึงเกิดขึ้นก่อนหน้านี้ และหลังจากกิจกรรม SEO ตามฤดูกาล เครื่องมือค้นหาได้ปรับการจัดอันดับของแหล่งที่มาให้เป็นมาตรฐานตามปริมาณการใช้งานจริงระหว่างการอัปเดตที่ไม่ได้รับการยืนยัน
- ข้อความค้นหาและการจัดอันดับที่ได้รับจากเครือข่ายเนื้อหาที่มีความหมายแรกและกิจกรรมประจำฤดูกาลได้รับการคุ้มครองและปรับปรุงให้ดียิ่งขึ้น
- เครือข่ายเนื้อหาเชิงความหมายแรกยังรองรับเครือข่ายเนื้อหาเชิงความหมายใหม่และที่สองด้วย
การสูญเสียการสืบค้นและการสูญเสียอันดับเฉลี่ยสามารถดูได้จาก Ahrefs ดังต่อไปนี้ คุณตรวจสอบเอฟเฟกต์ Google Broad Core Algorithm Update (GBCAU) ในเดือนมิถุนายน 2021 ได้พร้อมกับเอฟเฟกต์ของการอัปเดตที่ยังไม่ยืนยัน 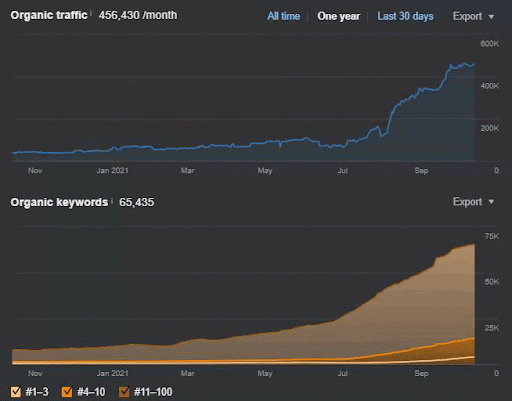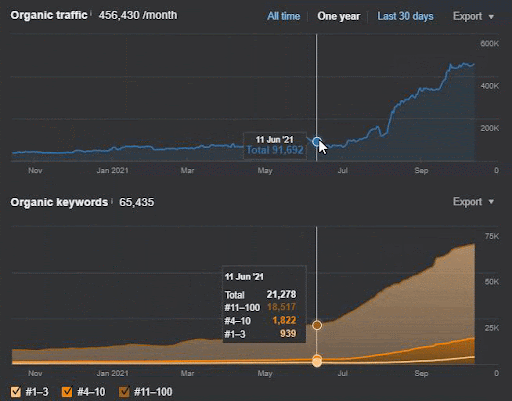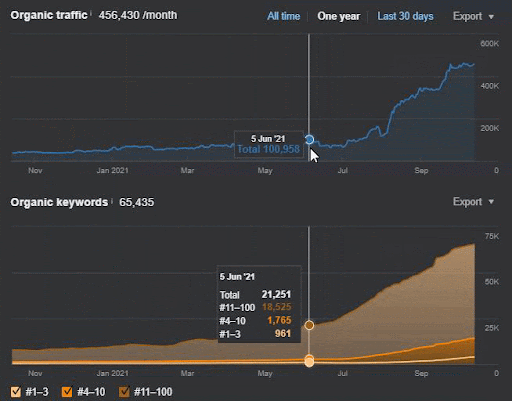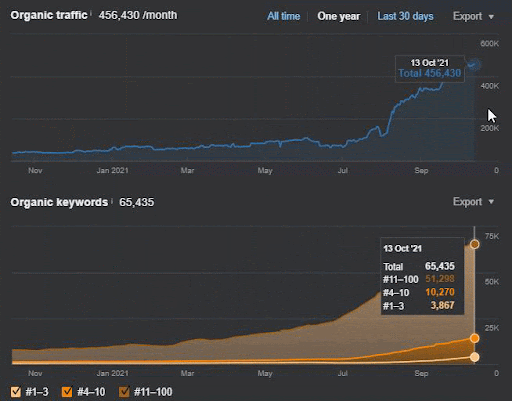
ดังนั้น การใช้เครือข่ายเนื้อหาเชิงความหมายที่มีกลยุทธ์ที่เป็นไปได้หลายอย่างจึงเป็นสิ่งจำเป็น แม้ว่า GCBAU จะสูญหาย แต่ต้องขอบคุณปัจจัยอื่นๆ ที่เกี่ยวข้องกับเนทูร่าของเครื่องมือค้นหาสามารถช่วย SEO ได้ ดังนั้น คุณอาจลองนึกดูว่าเหตุใดการอธิบายสิ่งเหล่านี้กับผู้เขียนหรือลูกค้าจึงยากกว่าเทคนิค SEO Semantic SEO ไม่ได้ใช้ค่าตัวเลข แต่ใช้ความรู้เชิงทฤษฎีที่มาจากความเข้าใจของเครื่องมือค้นหาผ่านสิทธิบัตร เอกสารการวิจัย ประสบการณ์ และการประกาศทางประวัติศาสตร์
12. ใช้การปรับประโยคให้เหมาะสมในหน้าเว็บเพื่อโครงสร้างข้อเท็จจริงที่ดีขึ้น
พูดตามตรง แม้แต่รายการที่ 10 ยังเป็นหัวข้อใหม่ทั้งหมด และอาจต้องใช้แม้แต่การเขียน 20,000 คำที่นี่ แต่ฉันจะเริ่มต้นด้วยตัวอย่างง่ายๆ
- X คือ Y
- Y คือ X
สำหรับประโยคตัวอย่างข้างต้น คุณสามารถเข้าใจสิ่งต่าง ๆ ด้านล่าง
- ประโยคข้างต้นไม่ใช่เนื้อหาที่ซ้ำกัน
- ข้อเสนอข้างต้นซ้ำกัน
- คำอธิบายเชิงสัมพันธ์ระหว่างสองประโยคเหมือนกัน
- ป้ายกำกับบทบาทความหมายแตกต่างกัน 100%
- เอาต์พุต Named Entity Recognition เหมือนกัน 100%
การเพิ่มประสิทธิภาพประโยคในหน้าเว็บเกี่ยวข้องกับอัลกอริทึมการสร้างคำถามและเทคโนโลยีการจับคู่คำถาม-คำตอบ รูปแบบคำถามต้องใช้ประโยคบางประเภท และคำถามบางประเภทควรตอบด้วยประโยคบางประเภท รูปแบบเนื้อหา NER และ Fact Extraction จะได้รับผลกระทบจากการปรับโครงสร้างประโยคให้เหมาะสม 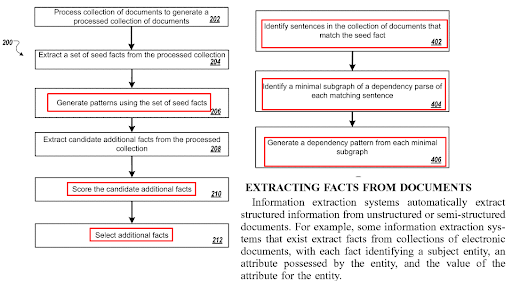
สามารถแยกและตรวจสอบแฝดสาม (หนึ่งวัตถุ สองวิชา) ในแง่ของความแม่นยำได้เร็วขึ้น ประโยคที่คล้ายกันสองประโยคไม่ได้หมายความว่าจะซ้ำกัน แต่หมายความว่าพวกเขาอยู่ใกล้กันในแง่ของโครงสร้างประโยค ตราบใดที่ข้อเสนอแตกต่างกัน การใช้ประโยคที่คล้ายกันระหว่างเทมเพลตเอกสารที่คล้ายคลึงกันสำหรับคู่การสืบค้นที่มีเจตนาต่างกันก็เป็นสิ่งจำเป็นสำหรับการสร้างเครือข่ายเนื้อหาเชิงความหมาย 
โครงสร้างประโยคที่ชัดเจนด้วยรูปแบบที่เหมาะสมมีประโยชน์ในการทำให้ข้อความมีความเกี่ยวข้องกันมากขึ้น ในขณะที่ช่วยให้เครื่องมือค้นหารู้จักเอนทิตีที่มีชื่อ หัวเรื่อง คุณลักษณะ ตลอดจนค่าของกันและกัน
นอกจากนี้ยังช่วยให้เห็นว่าส่วนใดของบทความสามารถปรับปรุงให้ดีขึ้นได้ และใน Topical Nets ที่เนื้อหาของคุณมีอันดับที่ดีขึ้นสำหรับประเภทของคู่คำ เวกเตอร์คำ และความตั้งใจ เพราะหากโครงสร้างประโยคบางประเภทสำหรับคำถามบางประเภทสามารถสังเกตได้จากหน้าเว็บหลายหน้า จะช่วยในการทดสอบ SEO A/B ขั้นสูงด้วยตัวอย่างข้อมูลจำนวนไม่รู้จบ และตัวอย่างทดสอบ คุณสามารถสร้างการออกแบบประโยคในหน้าได้หลายแบบเพื่อตรวจสอบว่าเครื่องมือค้นหาดึงข้อมูลข้อเท็จจริงมาเปรียบเทียบได้อย่างไร 
เมื่อพูดถึงการให้ข้อเท็จจริง ควรจดจำ “คลังความรู้” และ Luna Dong
13. ให้ข้อมูลโลกแห่งความจริงด้วยความแม่นยำและสม่ำเสมอ ไม่ใช่ความคิดเห็นกับ Fluff
ความแม่นยำในที่นี้หมายถึงความสามารถในการเปรียบเทียบกับค่าตัวเลข หรือความสัมพันธ์ที่เป็นรูปธรรมเชิงแนวคิด ความสม่ำเสมอหมายความว่าคุณปกป้องจุดยืนของคุณสำหรับข้อเสนอเฉพาะ ตัวอย่างเช่น อย่าพูดว่า "ผลิตภัณฑ์ X ดีที่สุดสำหรับ Y" สำหรับการตรวจสอบผลิตภัณฑ์ทั้งหมดที่เกี่ยวข้องกับ Y อย่าให้ข้อเสนอที่ขัดแย้งกันทั่วทั้งไซต์ และถ้าผลิตภัณฑ์นั้นดีที่สุด อะไรเป็นข้อพิสูจน์? วัสดุ ขนาด หรือสีและกลิ่น? ปุยในข้อความหมายความว่าคุณใช้คำเชื่อมที่ไม่จำเป็น หรือไม่บอกสิ่งที่ไม่สามารถพิสูจน์ได้ หรือขัดแย้งกับความจริง
ในบริบทของคำสั่งที่ไม่มีคำจำกัดความซึ่งได้รับการสนับสนุนโดยตัวอย่างบางส่วน คุณสามารถตรวจสอบหนึ่งในแบบจำลองภาษาของ Google ซึ่งก็คือ KeALM
ใช้สำหรับสร้างข้อความจากฐานข้อมูลด้วยโมเดลข้อมูลเป็นข้อความ และใช้สำหรับตรวจสอบความถูกต้องของเนื้อหา 
KELM เป็นตัวอย่างของการตรวจสอบความถูกต้องสำหรับข้อเสนอด้วยวิธีแปลงข้อความเป็นข้อมูล
นี่เป็นเพียงเล็กน้อยเกี่ยวกับคำจำกัดความของ "Triplet" และ "Open Information Extraction for Unknown Entities" แต่อย่างที่คุณทราบ นี่เป็นเวอร์ชันสั้น ๆ และฉันเดาว่าฉันได้บอกพอแล้ว โดยพื้นฐานแล้ว เมื่อคุณให้ข้อมูลที่ไม่ถูกต้องบนเว็บไซต์ของคุณ ต้องแน่ใจว่า Google สามารถเข้าใจข้อมูลดังกล่าว เพื่อลดความน่าเชื่อถือตามความรู้ของแหล่งที่มา ในที่นี้ คุณอาจจำเป็นต้องรู้ด้วยว่า เนื่องจากคุณสามารถขยายฐานความรู้ได้ เสิร์ชเอ็นจิ้นสามารถเปลี่ยนฐานความรู้ของตนเองตามข้อมูลของคุณ หากคุณมีแหล่งที่มาที่สัมพันธ์กับเพจแรงก์ และความน่าเชื่อถือในฐานความรู้ ด้วยความแม่นยำสูงและแฝดสามอันเป็นเอกลักษณ์
14. ทำความเข้าใจแผนผังการพึ่งพาความหมายสำหรับเอนทิตี
Semantic Dependency Tree หมายความว่าแอตทริบิวต์ที่ส่งสัญญาณความสัมพันธ์กับเอนทิตีอื่นมีการขึ้นต่อกันตามลำดับชั้นระหว่างพวกเขา แผนผังการพึ่งพาเชิงความหมายสามารถสังเกตได้โดยการตรวจสอบโปรไฟล์และมุมเอนทิตีหลายรายการ เช่น ประเทศหนึ่งสามารถเป็นสมาชิกขององค์กรได้ และในฐานะเอนทิตีอื่น องค์กรนี้สามารถมีแอตทริบิวต์อื่นๆ ที่สามารถนำมาประกอบกับประเทศที่เชื่อมต่อด้วยความสัมพันธ์ที่อนุมานได้
ด้านล่างนี้ คุณจะสามารถดูตัวอย่างง่ายๆ จากเครื่องมือค้นหาได้โดยตรง 
REALM เป็นวิธีการที่ใช้ Semantic Dependency Trees เพื่อดึงข้อมูลจากข้อความที่คลุมเครือ
บนเว็บแบบเปิด การดึงข้อมูลแบบเปิดสามารถรับรู้เอนทิตีที่มีชื่อใหม่ และแยกเอนทิตีเดียวกันนี้ว่าเกิดขึ้นร่วมกับเอนทิตีอื่นๆ การเกิดขึ้นร่วมและคุณลักษณะร่วมกันเหล่านี้ภายในบทความสามารถกำหนดบริบทและประเภทความสัมพันธ์ของผู้สมัครระหว่างเอนทิตี ขึ้นอยู่กับการเชื่อมต่อ และชนิดของเอนทิตี สามารถสร้างแผนผังการพึ่งพาทางความหมายได้ ตรรกะเดียวกันนี้เกิดขึ้นกับ Lexical Semantics เช่นกัน คำว่า "เด็กชาย" มีความหมายที่เป็นไปได้และความหมายอื่นที่แน่นอน เช่น เด็กชายเป็นชาย และอาจเป็นวัยรุ่นที่ยังไม่ได้แต่งงาน สามารถใช้ใกล้กับนักเรียนได้เป็นอย่างดี ในทางกลับกัน คำว่า "ราชินี" รวมถึงความหมายอื่นและความหมายที่แน่นอน เช่น "ผู้หญิง" และ "การเป็นผู้ว่าราชการ" ดังนั้น การมีบางสิ่งที่ควบคุมจึงเป็นลำดับชั้นของต้นไม้ที่อ้างอิงความหมายตามธรรมชาติ ซึ่งสามารถส่งสัญญาณถึงเทมเพลตการสืบค้นบางประเภท เช่น “ราชินีแห่ง…” หรือ “สำหรับ Quen” These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 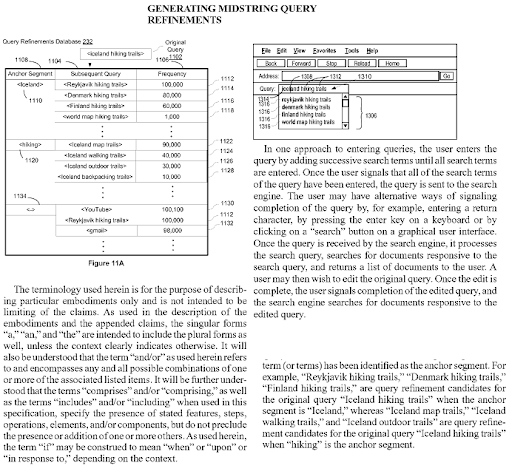
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.