
การควบคุมการรวบรวมข้อมูลและการจัดทำดัชนี: คู่มือ SEO สำหรับ Robots.txt & แท็ก
เผยแพร่แล้ว: 2019-02-19การเพิ่มประสิทธิภาพสำหรับงบประมาณการรวบรวมข้อมูลและการบล็อกบอทจากหน้าการจัดทำดัชนีเป็นแนวคิดที่ SEO หลายๆ คนคุ้นเคย แต่มารอยู่ในรายละเอียด โดยเฉพาะอย่างยิ่งเมื่อแนวทางปฏิบัติที่ดีที่สุดได้เปลี่ยนแปลงไปอย่างมากในช่วงหลายปีที่ผ่านมา
การเปลี่ยนแปลงเล็กน้อยในไฟล์ robots.txt หรือแท็ก robots อาจส่งผลกระทบอย่างมากต่อเว็บไซต์ของคุณ เพื่อให้แน่ใจว่าผลกระทบจะส่งผลดีต่อไซต์ของคุณเสมอ วันนี้เราจะมาเจาะลึกใน:
การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล
ไฟล์ Robots.txt คืออะไร
แท็ก Meta Robots คืออะไร
X-Robots-Tags คืออะไร
คำสั่งหุ่นยนต์ & SEO
รายการตรวจสอบหุ่นยนต์ฝึกหัดที่ดีที่สุด
การเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล
สไปเดอร์ของเครื่องมือค้นหามี "ค่าเผื่อ" สำหรับจำนวนหน้าที่สามารถและต้องการรวบรวมข้อมูลในไซต์ของคุณ สิ่งนี้เรียกว่า "งบประมาณการรวบรวมข้อมูล"
ค้นหางบประมาณการรวบรวมข้อมูลของไซต์ของคุณในรายงาน "สถิติการรวบรวมข้อมูล" ของ Google Search Console (GSC) โปรดทราบว่า GSC เป็นบอทรวม 12 ตัวซึ่งไม่ได้มีไว้สำหรับ SEO ทั้งหมด นอกจากนี้ยังรวบรวมบอท AdWords หรือ AdSense ซึ่งเป็นบอทของ SEA ดังนั้น เครื่องมือนี้จะช่วยให้คุณมีแนวคิดเกี่ยวกับงบประมาณการรวบรวมข้อมูลทั่วโลกของคุณ แต่ไม่ใช่การแบ่งพาร์ติชั่นที่แน่นอน
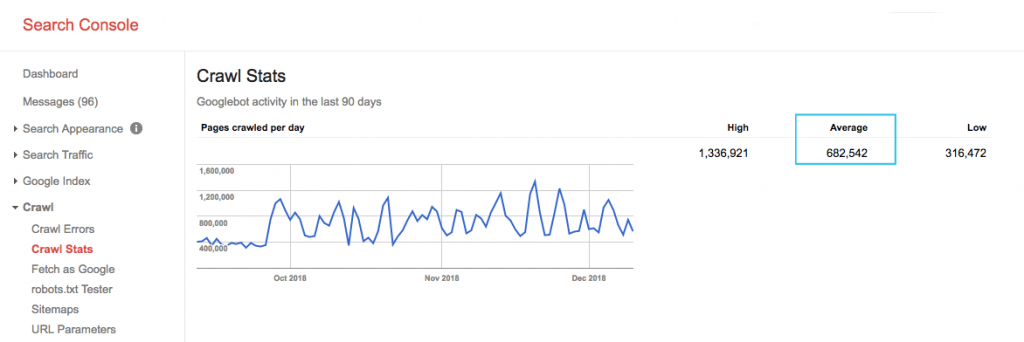
ในการทำให้ตัวเลขใช้งานได้จริงมากขึ้น ให้แบ่งหน้าเฉลี่ยที่รวบรวมข้อมูลต่อวันด้วยหน้าที่รวบรวมข้อมูลได้ทั้งหมดบนไซต์ของคุณ - คุณสามารถขอหมายเลขจากนักพัฒนาซอฟต์แวร์ของคุณ หรือเรียกใช้โปรแกรมรวบรวมข้อมูลเว็บไซต์แบบไม่จำกัด ซึ่งจะทำให้คุณมีอัตราส่วนการรวบรวมข้อมูลที่คาดไว้เพื่อให้คุณเริ่มเพิ่มประสิทธิภาพได้
ต้องการไปลึก? รับรายละเอียดเพิ่มเติมเกี่ยวกับกิจกรรมของ Googlebot เช่น หน้าที่กำลังเข้าชม ตลอดจนสถิติสำหรับโปรแกรมรวบรวมข้อมูลอื่นๆ โดยการวิเคราะห์ไฟล์บันทึกของเซิร์ฟเวอร์ในเว็บไซต์ของคุณ
มีหลายวิธีในการเพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล แต่จุดเริ่มต้นง่ายๆ คือการดูรายงาน "ความครอบคลุม" ของ GSC เพื่อทำความเข้าใจพฤติกรรมการรวบรวมข้อมูลและการจัดทำดัชนีของ Google ในปัจจุบัน
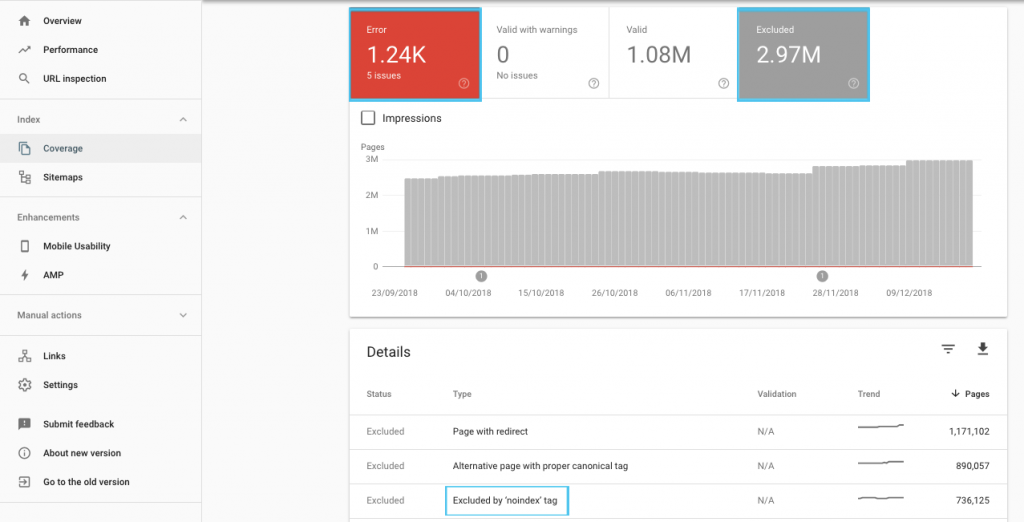
หากคุณพบข้อผิดพลาด เช่น “URL ที่ส่งที่ทำเครื่องหมาย 'noindex'” หรือ “URL ที่ส่งถูกบล็อกโดย robots.txt” ให้ทำงานร่วมกับนักพัฒนาของคุณเพื่อแก้ไขปัญหา สำหรับการยกเว้นโรบ็อตใดๆ ให้ตรวจสอบเพื่อทำความเข้าใจว่าหุ่นยนต์เหล่านี้เป็นกลยุทธ์จากมุมมองของ SEO หรือไม่
โดยทั่วไป SEO ควรมีจุดมุ่งหมายเพื่อลดข้อจำกัดในการรวบรวมข้อมูลหุ่นยนต์ให้น้อยที่สุด การปรับปรุงสถาปัตยกรรมเว็บไซต์ของคุณเพื่อให้ URL มีประโยชน์และเข้าถึงได้สำหรับเครื่องมือค้นหาเป็นกลยุทธ์ที่ดีที่สุด
Google เองทราบว่า "สถาปัตยกรรมข้อมูลที่มั่นคงมีแนวโน้มที่จะใช้ทรัพยากรอย่างมีประสิทธิผลมากกว่าการมุ่งเน้นไปที่การจัดลำดับความสำคัญของการรวบรวมข้อมูล"
ดังที่กล่าวไปแล้ว การทำความเข้าใจสิ่งที่สามารถทำได้ด้วยไฟล์ robots.txt และแท็กโรบ็อตนั้นมีประโยชน์ เพื่อเป็นแนวทางในการรวบรวมข้อมูล การจัดทำดัชนี และการส่งผ่านส่วนของลิงก์ และที่สำคัญกว่านั้น เมื่อใดและอย่างไรจึงจะใช้ประโยชน์จาก SEO สมัยใหม่ได้ดีที่สุด
[กรณีศึกษา] การจัดการการรวบรวมข้อมูลบอทของ Google
 อ่านกรณีศึกษา
อ่านกรณีศึกษาไฟล์ Robots.txt คืออะไร
ก่อนที่เครื่องมือค้นหาจะทำการแมงมุมหน้าใดๆ มันจะตรวจสอบ robots.txt ไฟล์นี้บอกบอทว่าเส้นทาง URL ใดที่พวกเขาได้รับอนุญาตให้เยี่ยมชม แต่รายการเหล่านี้เป็นเพียงคำสั่ง ไม่ใช่อาณัติ
Robots.txt ไม่สามารถป้องกันการรวบรวมข้อมูลอย่างไฟร์วอลล์หรือการป้องกันด้วยรหัสผ่านได้อย่างน่าเชื่อถือ ซึ่งเทียบเท่ากับป้าย “โปรดอย่าเข้า” ที่ประตูปลดล็อค
โปรแกรมรวบรวมข้อมูลที่สุภาพ เช่น เครื่องมือค้นหาสำคัญๆ มักจะปฏิบัติตามคำแนะนำ โปรแกรมรวบรวมข้อมูลที่ไม่เป็นมิตร เช่น แครปเปอร์อีเมล สแปมบอท มัลแวร์และสไปเดอร์ที่สแกนหาช่องโหว่ของไซต์ มักจะไม่สนใจ
ยิ่งไปกว่านั้น ยังเป็น ไฟล์ที่เปิดเผยต่อสาธารณะ ทุกคนสามารถดูคำสั่งของคุณได้
อย่าใช้ไฟล์ robots.txt ของคุณเพื่อ:
- เพื่อซ่อนข้อมูลที่ละเอียดอ่อน ใช้การป้องกันด้วยรหัสผ่าน
- เพื่อบล็อกการเข้าถึงไซต์การแสดงละครและ/หรือการพัฒนาของคุณ ใช้การรับรองความถูกต้องฝั่งเซิร์ฟเวอร์
- เพื่อบล็อกโปรแกรมรวบรวมข้อมูลที่ไม่เป็นมิตรอย่างชัดเจน ใช้การบล็อก IP หรือการบล็อก user-agent (หรือที่รู้จักว่าห้ามการเข้าถึงของโปรแกรมรวบรวมข้อมูลเฉพาะด้วยกฎในไฟล์ .htaccess หรือเครื่องมือ เช่น CloudFlare)
ทุกเว็บไซต์ควรมีไฟล์ robots.txt ที่ถูกต้องพร้อมการจัดกลุ่มคำสั่งอย่างน้อยหนึ่งรายการ หากไม่มีบอททั้งหมดจะมีสิทธิ์เข้าถึงแบบเต็มตามค่าเริ่มต้น ดังนั้นทุกหน้าจะถือว่ารวบรวมข้อมูลได้ แม้ว่านี่จะเป็นสิ่งที่คุณต้องการ แต่ควรทำให้ชัดเจนสำหรับผู้มีส่วนได้ส่วนเสียทั้งหมดด้วยไฟล์ robots.txt นอกจากนี้ หากไม่มี บันทึกเซิร์ฟเวอร์ของคุณจะเต็มไปด้วยคำขอที่ล้มเหลวสำหรับ robots.txt
โครงสร้างของไฟล์ robots.txt
เพื่อให้โปรแกรมรวบรวมข้อมูลได้รับการยอมรับ robots.txt ของคุณต้อง:
- เป็นไฟล์ข้อความชื่อ “robots.txt” ชื่อไฟล์ต้องตรงตามตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ “Robots.TXT” หรือรูปแบบอื่นๆ จะไม่ทำงาน
- อยู่ในไดเรกทอรีระดับบนสุดของโดเมนตามรูปแบบบัญญัติและโดเมนย่อยหากเกี่ยวข้อง ตัวอย่างเช่น หากต้องการควบคุมการรวบรวมข้อมูลใน URL ทั้งหมดด้านล่าง https://www.example.com ไฟล์ robots.txt จะต้องอยู่ที่ https://www.example.com/robots.txt และสำหรับ subdomain.example.com ที่ subdomain.example.com/robots.txt
- ส่งกลับสถานะ HTTP 200 OK
- ใช้ไวยากรณ์ robots.txt ที่ถูกต้อง – ตรวจสอบโดยใช้เครื่องมือทดสอบ robots.txt ของ Google Search Console
ไฟล์ robots.txt ประกอบด้วยการจัดกลุ่มคำสั่ง รายการส่วนใหญ่ประกอบด้วย:
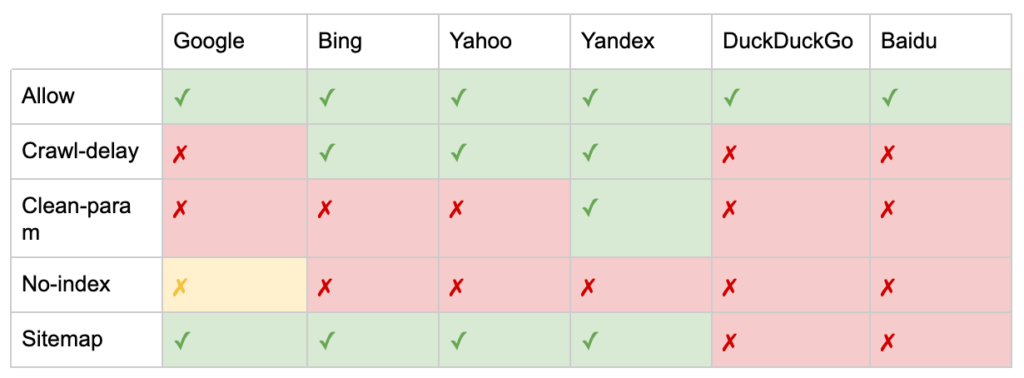
- 1. User-agent: จัดการกับโปรแกรมรวบรวมข้อมูลต่างๆ คุณสามารถมีกลุ่มเดียวสำหรับโรบ็อตทั้งหมดหรือใช้กลุ่มเพื่อตั้งชื่อเครื่องมือค้นหาเฉพาะ
- 2. ไม่อนุญาต: ระบุไฟล์หรือไดเร็กทอรีที่จะแยกออกจากการรวบรวมข้อมูลโดยตัวแทนผู้ใช้ด้านบน คุณสามารถมีบรรทัดเหล่านี้ได้หนึ่งบรรทัดหรือมากกว่าต่อบล็อก
สำหรับรายชื่อ User Agent ทั้งหมดและตัวอย่างคำสั่งเพิ่มเติม โปรดดูคู่มือ robots.txt ใน Yoast
นอกจากคำสั่ง "User-agent" และ "Disallow" แล้ว ยังมีคำสั่งที่ไม่ได้มาตรฐานอีกด้วย:
- อนุญาต: ระบุข้อยกเว้นสำหรับคำสั่ง disallow สำหรับไดเร็กทอรีหลัก
- ความล่าช้าในการรวบรวมข้อมูล: ควบคุม โปรแกรมรวบรวมข้อมูลจำนวนมากโดยบอกบอทว่าต้องรอกี่วินาทีก่อนที่จะไปที่หน้าเว็บ หากคุณได้รับเซสชันออร์แกนิกไม่กี่เซสชัน ความล่าช้าในการรวบรวมข้อมูลสามารถประหยัดแบนด์วิดท์ของเซิร์ฟเวอร์ได้ แต่ฉันจะใช้ความพยายามก็ต่อเมื่อโปรแกรมรวบรวมข้อมูลทำให้เกิดปัญหาในการโหลดเซิร์ฟเวอร์เท่านั้น Google ไม่รับทราบคำสั่งนี้ มีตัวเลือกในการจำกัดอัตราการรวบรวมข้อมูลใน Google Search Console
- Clean-param: หลีกเลี่ยงการตระเวนซ้ำเนื้อหาที่ซ้ำกันที่สร้างโดยพารามิเตอร์ไดนามิก
- ไม่มีดัชนี: ออกแบบมาเพื่อควบคุมการจัดทำดัชนีโดยไม่ต้องใช้งบประมาณการรวบรวมข้อมูล Google ไม่รองรับอย่างเป็นทางการแล้ว แม้ว่าจะมีหลักฐานว่าอาจมีผลกระทบ แต่ก็ไม่น่าเชื่อถือและไม่แนะนำโดยผู้เชี่ยวชาญเช่น John Mueller
@maxxeight @google @DeepCrawl ฉันจะหลีกเลี่ยงการใช้ noindex ที่นั่นจริงๆ
— ???? จอห์น ???? (@JohnMu) วันที่ 1 กันยายน 2558
- แผนผังเว็บไซต์: วิธีที่ดีที่สุดในการส่งแผนผังเว็บไซต์ XML ของคุณคือผ่าน Google Search Console และเครื่องมือของผู้ดูแลเว็บของเครื่องมือค้นหาอื่นๆ อย่างไรก็ตาม การเพิ่มคำสั่งแผนผังเว็บไซต์ที่ฐานของไฟล์ robots.txt จะช่วยโปรแกรมรวบรวมข้อมูลอื่นๆ ที่อาจไม่มีตัวเลือกในการส่ง
ข้อจำกัดของ robots.txt สำหรับ SEO
เราทราบแล้วว่า robots.txt ไม่สามารถป้องกันการรวบรวมข้อมูลสำหรับบ็อตทั้งหมดได้ ในทำนองเดียวกัน การไม่อนุญาตโปรแกรมรวบรวมข้อมูลจากหน้าเว็บ ไม่ได้ป้องกันไม่ให้รวมอยู่ในหน้าผลลัพธ์ของเครื่องมือค้นหา (SERP)
หากหน้าที่ถูกบล็อกมีสัญญาณการจัดอันดับที่แข็งแกร่งอื่นๆ Google อาจเห็นว่ามีความเกี่ยวข้องที่จะแสดงในผลการค้นหา ทั้งๆ ที่ยังไม่ได้รวบรวมข้อมูลหน้าเพจ
เนื่องจาก Google ไม่รู้จักเนื้อหาของ URL นั้น ผลการค้นหาจึงมีลักษณะดังนี้:

หากต้องการบล็อกหน้าเว็บไม่ให้ปรากฏใน SERP อย่างเด็ดขาด คุณต้องใช้เมตาแท็กโรบ็อต “noindex” หรือส่วนหัว HTTP X-Robots-Tag
ในกรณีนี้ อย่าไม่อนุญาตให้ ใช้หน้าใน robots.txt เพราะต้องรวบรวมข้อมูลหน้าเพื่อให้แท็ก "noindex" มองเห็นและปฏิบัติตามได้ หาก URL ถูกบล็อก แท็กโรบ็อตทั้งหมดจะไม่ได้ผล
ยิ่งไปกว่านั้น หากหน้าเว็บมีลิงก์ขาเข้าจำนวนมาก แต่ Google ถูกบล็อกไม่ให้รวบรวมข้อมูลหน้าเหล่านั้นโดย robots.txt ในขณะที่ Google รู้จัก ลิงก์ ส่วนของลิงก์ ก็จะสูญหายไป
แท็ก Meta Robots คืออะไร
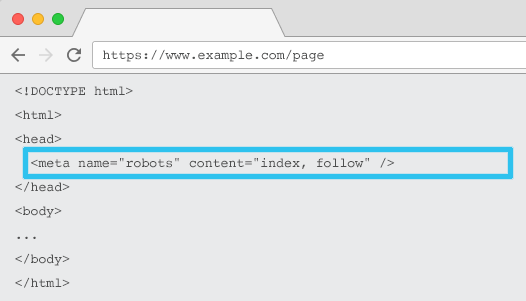
วางใน HTML ของแต่ละ URL meta name=”robots” บอกโปรแกรมรวบรวมข้อมูลว่าควร “จัดทำดัชนี” เนื้อหาอย่างไรและอย่างไร และจะ “ติดตาม” (เช่น รวบรวมข้อมูล) ลิงก์ในหน้าทั้งหมด ส่งต่อตามส่วนของลิงก์หรือไม่
การใช้ชื่อเมตาทั่วไป = “หุ่นยนต์” คำสั่งนี้ใช้กับโปรแกรมรวบรวมข้อมูลทั้งหมด คุณยังสามารถระบุตัวแทนผู้ใช้เฉพาะได้ ตัวอย่างเช่น ชื่อเมตา=”googlebot” แต่ไม่ค่อยต้องใช้เมตาแท็กโรบ็อตหลายแท็กเพื่อตั้งค่าคำแนะนำสำหรับสไปเดอร์เฉพาะ
มีข้อควรพิจารณาที่สำคัญสองประการเมื่อใช้แท็ก meta robots:
- เช่นเดียวกับ robots.txt เมตาแท็กคือคำสั่ง ไม่ใช่คำสั่ง ดังนั้นบ็อตบางตัวจึงอาจมองข้ามไป
- คำสั่ง nofollow ของโรบ็อตใช้กับลิงก์ในหน้านั้นเท่านั้น เป็นไปได้ที่โปรแกรมรวบรวมข้อมูลอาจติดตามลิงก์จากหน้าหรือเว็บไซต์อื่นโดยไม่มี nofollow ดังนั้นบอทอาจยังมาถึงและจัดทำดัชนีหน้าที่ไม่ต้องการของคุณ
นี่คือรายการคำสั่งแท็ก meta robots ทั้งหมด:
- ดัชนี: บอกให้เครื่องมือค้นหาแสดงหน้านี้ในผลการค้นหา นี่เป็นสถานะเริ่มต้นหากไม่มีการระบุคำสั่ง
- noindex: บอกเครื่องมือค้นหาไม่ให้แสดงหน้านี้ในผลการค้นหา
- ติดตาม: บอกให้เสิร์ชเอ็นจิ้นติดตามลิงก์ทั้งหมดในหน้านี้และส่งผ่านส่วนได้เสียแม้ว่าหน้าจะไม่ได้รับการจัดทำดัชนีก็ตาม นี่เป็นสถานะเริ่มต้นหากไม่มีการระบุคำสั่ง
- nofollow: บอกเสิร์ชเอ็นจิ้นไม่ให้ติดตามลิงค์ใด ๆ ในหน้านี้หรือส่งผ่านอิควิตี้
- ทั้งหมด: เทียบเท่ากับ “ดัชนี ติดตาม”
- none: เทียบเท่ากับ “noindex, nofollow”
- noimageindex: บอกเครื่องมือค้นหาไม่ให้สร้างดัชนีรูปภาพใด ๆ ในหน้านี้
- noarchive: บอกเครื่องมือค้นหาไม่ให้แสดงลิงก์ที่แคชไปยังหน้านี้ในผลการค้นหา
- nocache: เหมือนกับ noarchive แต่ใช้โดย Internet Explorer และ Firefox เท่านั้น
- nosnippet: บอกเครื่องมือค้นหาไม่ให้แสดงคำอธิบายเมตาหรือตัวอย่างวิดีโอสำหรับหน้านี้ในผลการค้นหา
- notranslate: บอกเครื่องมือค้นหาไม่ให้เสนอการแปลหน้านี้ในผลการค้นหา
- available_after: บอกเครื่องมือค้นหาว่าจะไม่สร้างดัชนีหน้านี้อีกต่อไปหลังจากวันที่ระบุ
- noodp: เลิกใช้แล้ว ครั้งหนึ่งเคยป้องกันไม่ให้เครื่องมือค้นหาใช้คำอธิบายหน้าจาก DMOZ ในผลการค้นหา
- noydir: เลิกใช้แล้ว ครั้งหนึ่งเคยป้องกันไม่ให้ Yahoo ใช้คำอธิบายหน้าจากไดเรกทอรี Yahoo ในผลการค้นหา
- noyaca: ป้องกันไม่ให้ Yandex ใช้คำอธิบายหน้าจากไดเรกทอรี Yandex ในผลการค้นหา
ตามเอกสารของ Yoast เครื่องมือค้นหาบางโปรแกรมไม่สนับสนุนเมตาแท็กของโรบ็อตทั้งหมด หรือแม้แต่มีความชัดเจนในสิ่งที่พวกเขาทำและไม่สนับสนุน
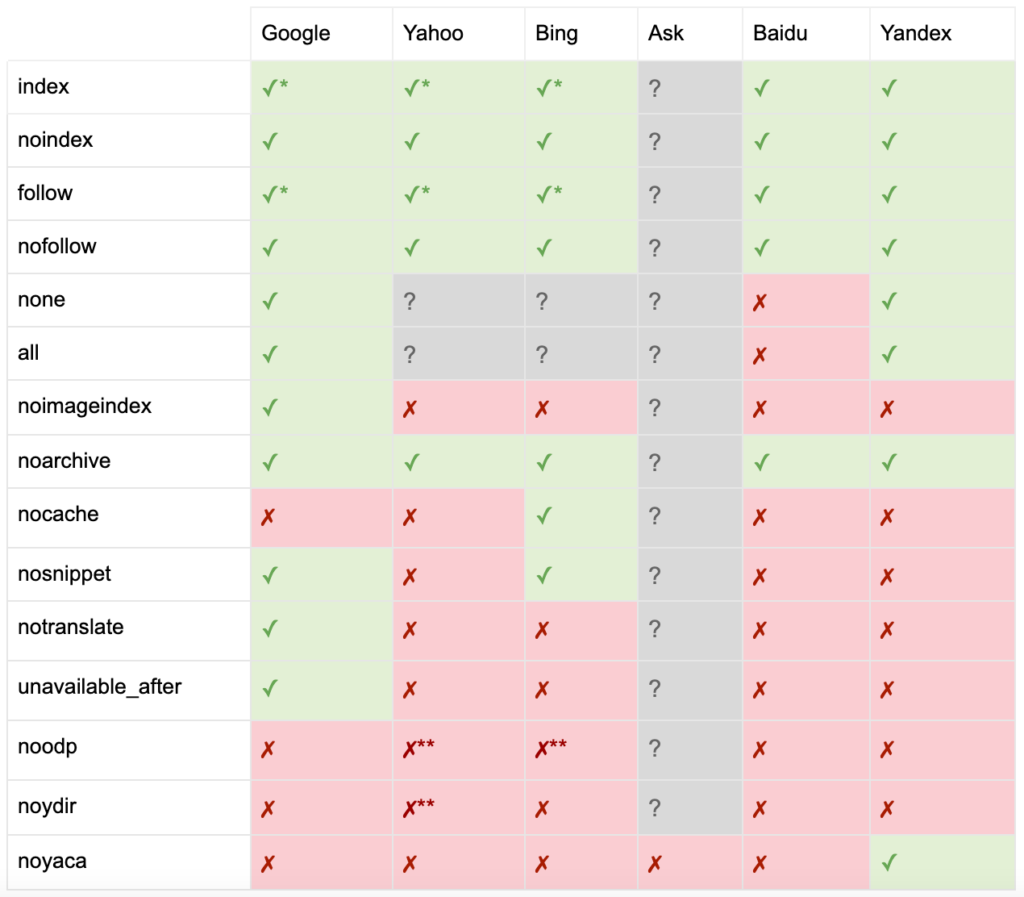
* เสิร์ชเอ็นจิ้นส่วนใหญ่ไม่มีเอกสารเฉพาะสำหรับสิ่งนี้ แต่สันนิษฐานว่าการสนับสนุนการยกเว้นพารามิเตอร์ (เช่น nofollow) หมายถึงการสนับสนุนสำหรับค่าที่เท่ากันในเชิงบวก (เช่น ติดตาม)
** แม้ว่าแอตทริบิวต์ noodp และ noydir อาจยัง 'ได้รับการสนับสนุน' แต่ไดเร็กทอรีก็ไม่มีอยู่แล้ว และมีแนวโน้มว่าค่าเหล่านี้จะไม่ทำอะไรเลย

โดยทั่วไป แท็กโรบ็อตจะถูกตั้งค่าเป็น “ดัชนี ติดตาม” SEO บางรายมองว่าการเพิ่มแท็กนี้ใน HTML นั้นซ้ำซ้อนเนื่องจากเป็นค่าเริ่มต้น ข้อโต้แย้งคือข้อกำหนดที่ชัดเจนของคำสั่งอาจช่วยหลีกเลี่ยงความสับสนของมนุษย์
หมายเหตุ: URL ที่มีแท็ก "noindex" จะถูกรวบรวมข้อมูลน้อยลง และหากมีอยู่เป็นเวลานาน ในที่สุด Google ก็จะไม่ติดตามลิงก์ของหน้า
ไม่ค่อยพบกรณีการใช้งานเพื่อ "nofollow" ลิงก์ทั้งหมด บนหน้าเว็บที่มีแท็ก meta robots เป็นเรื่องปกติมากขึ้นที่จะเห็น "nofollow" เพิ่มใน แต่ละลิงก์ โดยใช้แอตทริบิวต์ลิงก์ rel="nofollow" ตัวอย่างเช่น คุณอาจต้องการพิจารณาเพิ่มแอตทริบิวต์ rel=”nofollow” ให้กับความคิดเห็นที่ผู้ใช้สร้างขึ้นหรือลิงก์แบบชำระเงิน
ยากยิ่งกว่าที่จะมีกรณีการใช้งาน SEO สำหรับคำสั่งแท็กของโรบ็อตที่ไม่ได้ระบุถึงการจัดทำดัชนีพื้นฐานและพฤติกรรมการติดตาม เช่น การแคช การจัดทำดัชนีรูปภาพ และการจัดการข้อมูลโค้ด เป็นต้น
ความท้าทายของแท็ก meta robots คือแท็กเหล่านี้ใช้กับไฟล์ที่ไม่ใช่ HTML เช่น รูปภาพ วิดีโอ หรือเอกสาร PDF ไม่ได้ นี่คือที่ที่คุณสามารถเปลี่ยนไปใช้ X-Robots-Tags ได้
X-Robots-Tags คืออะไร
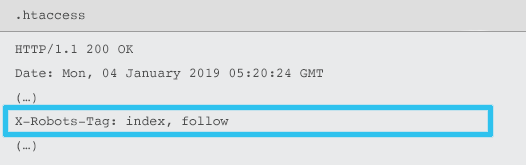
เซิร์ฟเวอร์ส่ง X-Robots-Tag เป็นองค์ประกอบของส่วนหัวตอบกลับ HTTP สำหรับ URL ที่กำหนดโดยใช้ไฟล์ .htaccess และ httpd.conf
นอกจากนี้ยังระบุคำสั่งเมตาแท็กของโรบ็อตเป็น X-Robots-Tag ได้อีกด้วย อย่างไรก็ตาม X-Robots-Tag มอบความยืดหยุ่นและฟังก์ชันการทำงานเพิ่มเติมบางส่วนไว้ด้านบน
คุณจะใช้ X-Robots-Tag แทนแท็ก meta robots หากคุณต้องการ:
- ควบคุมพฤติกรรมของโรบ็อตสำหรับไฟล์ที่ไม่ใช่ HTML แทนที่จะเป็นไฟล์ HTML เพียงอย่างเดียว
- ควบคุมการสร้างดัชนีขององค์ประกอบเฉพาะของหน้า แทนที่จะเป็นหน้าโดยรวม
- เพิ่มกฎว่าหน้าควรจะสร้างดัชนีหรือไม่ ตัวอย่างเช่น หากผู้เขียนมีบทความที่ตีพิมพ์มากกว่า 5 บทความ ให้จัดทำดัชนีหน้าโปรไฟล์ของพวกเขา
- ใช้ดัชนีและปฏิบัติตามคำสั่งที่ระดับทั่วทั้งไซต์ แทนที่จะใช้เฉพาะหน้า
- ใช้นิพจน์ทั่วไป
หลีกเลี่ยงการใช้ทั้ง meta robots และ x-robots-tag ในหน้าเดียวกัน การทำเช่นนั้นจะซ้ำซาก
หากต้องการดู X-Robots-Tag คุณสามารถใช้คุณลักษณะ "ดึงข้อมูลเหมือนเป็น Google" ใน Google Search Console
คำสั่งหุ่นยนต์ & SEO
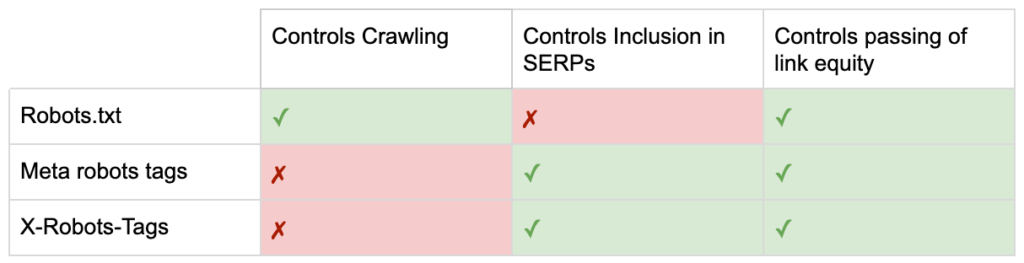
ตอนนี้คุณรู้ความแตกต่างระหว่างคำสั่งของหุ่นยนต์ทั้งสาม
robots.txt มุ่งเน้นที่การบันทึกงบประมาณการรวบรวมข้อมูล แต่จะไม่ได้ป้องกันไม่ให้หน้าแสดงในผลการค้นหา มันทำหน้าที่เป็นผู้รักษาประตูคนแรกของเว็บไซต์ของคุณ สั่งให้บอทไม่เข้าถึง ก่อนที่จะขอหน้า
แท็กโรบ็อตทั้งสองประเภทมุ่งเน้นไปที่การควบคุมการจัดทำดัชนีและการส่งต่อส่วนของลิงก์ เมตาแท็กของโรบ็อตจะมีผล หลังจากโหลดหน้าเว็บ แล้วเท่านั้น ในขณะที่ส่วนหัว X-Robots-Tag ให้การควบคุมที่ละเอียดยิ่งขึ้นและมีประสิทธิภาพ หลังจากที่เซิร์ฟเวอร์ตอบสนองต่อคำขอของหน้า
ด้วยความเข้าใจนี้ SEO สามารถพัฒนาวิธีที่เราใช้คำสั่งของโรบ็อตเพื่อแก้ปัญหาความท้าทายในการรวบรวมข้อมูลและการจัดทำดัชนี
การบล็อกบอทเพื่อบันทึกแบนด์วิดท์ของเซิร์ฟเวอร์
ปัญหา: จากการวิเคราะห์ไฟล์บันทึก คุณจะเห็นตัวแทนผู้ใช้จำนวนมากใช้แบนด์วิดท์แต่กลับให้คุณค่าเพียงเล็กน้อย
- โปรแกรมรวบรวมข้อมูล SEO เช่น MJ12bot (จาก Majestic) หรือ Ahrefsbot (จาก Ahrefs)
- เครื่องมือที่บันทึกเนื้อหาดิจิทัลแบบออฟไลน์ เช่น Webcopier หรือ Teleport
- เครื่องมือค้นหาที่ไม่เกี่ยวข้องในตลาดของคุณ เช่น Baiduspider หรือ Yandex
โซลูชันที่ไม่เหมาะสม: การบล็อกสไปเดอร์เหล่านี้ด้วย robots.txt เนื่องจากไม่รับประกันว่าจะได้รับการยกย่องและเป็นการประกาศต่อสาธารณะ ซึ่งอาจให้ข้อมูลเชิงลึกด้านการแข่งขันแก่ผู้มีส่วนได้ส่วนเสีย
แนวทางปฏิบัติที่ดีที่สุด: คำสั่งที่ละเอียดยิ่งขึ้นของการบล็อก user-agent สามารถทำได้หลายวิธี แต่โดยทั่วไปแล้วจะทำโดยการแก้ไขไฟล์ .htaccess ของคุณเพื่อเปลี่ยนเส้นทางคำขอของสไปเดอร์ที่ไม่ต้องการไปยัง 403 – หน้าต้องห้าม
หน้าการค้นหาไซต์ภายในโดยใช้งบประมาณการรวบรวมข้อมูล
ปัญหา: ในหลาย ๆ เว็บไซต์ หน้าผลการค้นหาเว็บไซต์ภายในจะถูกสร้างขึ้นแบบไดนามิกบน URL แบบคงที่ ซึ่งจะกินงบประมาณในการรวบรวมข้อมูลและอาจทำให้เกิดเนื้อหาบางส่วนหรือปัญหาเนื้อหาที่ซ้ำกันหากจัดทำดัชนี
โซลูชันรองที่เหมาะสม: ไม่อนุญาตไดเรกทอรีที่มี robots.txt แม้ว่าสิ่งนี้อาจป้องกันกับดักของโปรแกรมรวบรวมข้อมูล แต่ก็จำกัดความสามารถของคุณในการจัดอันดับสำหรับการค้นหาลูกค้าที่สำคัญและสำหรับหน้าดังกล่าวเพื่อส่งผ่านส่วนลิงก์
แนวทางปฏิบัติที่ดีที่สุด: จับคู่คำค้นหาที่เกี่ยวข้องและมีปริมาณมากกับ URL ที่เป็นมิตรกับเครื่องมือค้นหาที่มีอยู่ ตัวอย่างเช่น ถ้าฉันค้นหา "samsung phone" แทนที่จะสร้างหน้าใหม่สำหรับ /search/samsung-phone ให้เปลี่ยนเส้นทางไปที่ /phones/samsung
ในกรณีที่เป็นไปไม่ได้ ให้สร้าง URL ตามพารามิเตอร์ จากนั้น คุณสามารถระบุได้อย่างง่ายดายว่าคุณต้องการให้รวบรวมข้อมูลพารามิเตอร์หรือไม่ภายใน Google Search Console
หากคุณอนุญาตให้รวบรวมข้อมูล ให้วิเคราะห์ว่าหน้าดังกล่าวมีคุณภาพเพียงพอที่จะจัดอันดับหรือไม่ หากไม่เป็นเช่นนั้น ให้เพิ่มคำสั่ง “noindex, follow” เป็นวิธีแก้ปัญหาระยะสั้น ขณะที่คุณวางกลยุทธ์ในการปรับปรุงคุณภาพผลลัพธ์เพื่อช่วยทั้ง SEO และประสบการณ์ของผู้ใช้
การบล็อกพารามิเตอร์ด้วยหุ่นยนต์
ปัญหา: พารามิเตอร์สตริงการสืบค้น เช่น พารามิเตอร์ที่สร้างขึ้นโดยการนำทางหรือการติดตามแบบเหลี่ยม ขึ้นชื่อเรื่องการใช้งบประมาณในการรวบรวมข้อมูล การสร้าง URL เนื้อหาที่ซ้ำกัน และการแยกสัญญาณการจัดอันดับ
โซลูชันรองที่เหมาะสม: ไม่อนุญาตให้รวบรวมข้อมูลพารามิเตอร์ด้วย robots.txt หรือด้วยเมตาแท็ก "noindex" ของโรบ็อต เนื่องจากทั้งสองอย่าง (แบบเดิมในทันที ภายหลังในระยะเวลาที่นานขึ้น) จะป้องกันการไหลของส่วนของลิงก์
แนวทางปฏิบัติที่ดีที่สุด: ตรวจสอบให้แน่ใจว่าทุกพารามิเตอร์มีเหตุผลที่ชัดเจนในการมีอยู่ และใช้กฎการเรียงลำดับ ซึ่งใช้คีย์เพียงครั้งเดียวและป้องกันค่าว่าง เพิ่มแอตทริบิวต์ลิงก์ rel=canonical ในหน้าพารามิเตอร์ที่เหมาะสมเพื่อรวมความสามารถในการจัดอันดับ จากนั้นกำหนดค่าพารามิเตอร์ทั้งหมดใน Google Search Console ซึ่งมีตัวเลือกที่ละเอียดยิ่งขึ้นในการสื่อสารการตั้งค่าการรวบรวมข้อมูล สำหรับรายละเอียดเพิ่มเติม โปรดดูคู่มือการจัดการพารามิเตอร์ของ Search Engine Journal
การปิดกั้นผู้ดูแลระบบหรือพื้นที่บัญชี
ปัญหา: ป้องกันไม่ให้เครื่องมือค้นหารวบรวมข้อมูลและจัดทำดัชนีเนื้อหาส่วนตัว
โซลูชันรองที่เหมาะสม: การใช้ robots.txt เพื่อบล็อกไดเร็กทอรี เนื่องจากไม่รับประกันว่าจะป้องกันไม่ให้เพจส่วนตัวออกจาก SERP
แนวทางปฏิบัติที่ดีที่สุด: ใช้การป้องกันด้วยรหัสผ่านเพื่อป้องกันไม่ให้โปรแกรมรวบรวมข้อมูลเข้าถึงหน้าและถอยกลับของคำสั่ง "noindex" ในส่วนหัวของ HTTP
การปิดกั้นหน้า Landing Page ทางการตลาด & ขอบคุณเพจ
ปัญหา: บ่อยครั้งที่คุณจำเป็นต้องยกเว้น URL ที่ไม่ได้มีไว้สำหรับการค้นหาทั่วไป เช่น อีเมลเฉพาะหรือหน้า Landing Page ของแคมเปญ CPC ในทำนองเดียวกัน คุณไม่ต้องการให้ผู้ที่ไม่ได้เปลี่ยนใจเลื่อมใสมาที่หน้าขอบคุณผ่าน SERP
โซลูชันรองที่เหมาะสม: ไม่อนุญาตให้ใช้ไฟล์ที่มี robots.txt เนื่องจากจะไม่ป้องกันลิงก์ที่รวมอยู่ในผลการค้นหา
แนวทางปฏิบัติที่ดีที่สุด: ใช้เมตาแท็ก "noindex"
จัดการเนื้อหาที่ซ้ำกันบนเว็บไซต์
ปัญหา: บางเว็บไซต์จำเป็นต้องมีสำเนาของเนื้อหาเฉพาะเนื่องจากเหตุผลด้านประสบการณ์ของผู้ใช้ เช่น หน้าเวอร์ชันที่เป็นมิตรกับเครื่องพิมพ์ แต่ต้องการให้แน่ใจว่าเครื่องมือค้นหารู้จักหน้า Canonical ไม่ใช่หน้าที่ซ้ำกัน ในเว็บไซต์อื่น เนื้อหาที่ซ้ำกันนั้นเกิดจากแนวทางการพัฒนาที่ไม่ดี เช่น การแสดงสินค้าเดียวกันเพื่อขายใน URL หมวดหมู่หลายรายการ
โซลูชันรองที่เหมาะสม: การไม่อนุญาต URL ที่มี robots.txt จะป้องกันไม่ให้หน้าที่ซ้ำกันส่งสัญญาณการจัดอันดับใดๆ Noindexing สำหรับโรบ็อต ในที่สุดจะนำไปสู่ Google ถือว่าลิงก์เป็น "nofollow" เช่นกัน จะป้องกันไม่ให้หน้าที่ซ้ำกันส่งผ่านส่วนของลิงก์ใดๆ
แนวทางปฏิบัติที่ดีที่สุด: หากเนื้อหาที่ซ้ำกันไม่มีเหตุผลที่จะมีอยู่ ให้ลบแหล่งที่มาและเปลี่ยนเส้นทาง 301 ไปยัง URL ที่จำง่ายของเครื่องมือค้นหา หากมีเหตุผลที่มีอยู่ ให้เพิ่มแอตทริบิวต์ลิงก์ rel=canonical รวมสัญญาณการจัดอันดับ
เนื้อหาบางส่วนของหน้าที่เกี่ยวข้องกับบัญชีที่เข้าถึงได้
ปัญหา: หน้าที่เกี่ยวข้องกับบัญชี เช่น การเข้าสู่ระบบ การลงทะเบียน ตะกร้าสินค้า การชำระเงิน หรือแบบฟอร์มการติดต่อ มักมีเนื้อหาที่บางเบาและให้คุณค่าเพียงเล็กน้อยแก่เครื่องมือค้นหา แต่จำเป็นสำหรับผู้ใช้
โซลูชันรองที่เหมาะสม: ไม่อนุญาตให้ใช้ไฟล์ที่มี robots.txt เนื่องจากจะไม่ป้องกันลิงก์ที่รวมอยู่ในผลการค้นหา
แนวทางปฏิบัติที่ดีที่สุด: สำหรับเว็บไซต์ส่วนใหญ่ หน้าเหล่านี้ควรมีจำนวนน้อยมาก และคุณอาจไม่เห็นผลกระทบ KPI ของการนำหุ่นยนต์ไปใช้งาน หากคุณรู้สึกว่าจำเป็น ควรใช้คำสั่ง "noindex" เว้นแต่จะมีคำค้นหาสำหรับหน้าดังกล่าว
หน้าแท็กโดยใช้งบประมาณการรวบรวมข้อมูล
ปัญหา: การติดแท็กที่ไม่สามารถควบคุมได้กินงบประมาณการรวบรวมข้อมูลและมักนำไปสู่ปัญหาเนื้อหาบางส่วน
โซลูชันที่ไม่เหมาะสม: ไม่อนุญาตให้ใช้ robots.txt หรือเพิ่มแท็ก "noindex" เนื่องจากทั้งคู่จะขัดขวางแท็กที่เกี่ยวข้องกับ SEO จากการจัดอันดับและ (ในทันทีหรือในท้ายที่สุด) ป้องกันการส่งต่อส่วนของลิงก์
แนวทางปฏิบัติที่ดีที่สุด: ประเมินมูลค่าของแต่ละแท็กปัจจุบันของคุณ หากข้อมูลแสดงหน้าเว็บเพิ่มคุณค่าให้กับเครื่องมือค้นหาหรือผู้ใช้เพียงเล็กน้อย 301 เปลี่ยนเส้นทางพวกเขา สำหรับเพจที่รอดจากการคัดเลือก ให้พยายามปรับปรุงองค์ประกอบในหน้าเพื่อให้มีคุณค่าต่อทั้งผู้ใช้และบอท
การรวบรวมข้อมูลของ JavaScript & CSS
ปัญหา: ก่อนหน้านี้ บอทไม่สามารถรวบรวมข้อมูล JavaScript และเนื้อหาสื่อสมบูรณ์อื่นๆ มีการเปลี่ยนแปลง และขอแนะนำอย่างยิ่งให้อนุญาตให้เครื่องมือค้นหาเข้าถึงไฟล์ JS และ CSS เพื่อแสดงผลหน้าเว็บ
โซลูชันรองที่เหมาะสม: ไม่อนุญาตไฟล์ JavaScript และ CSS ที่มี robots.txt เพื่อบันทึกงบประมาณการรวบรวมข้อมูลอาจส่งผลให้การจัดทำดัชนีไม่ดีและส่งผลเสียต่อการจัดอันดับ ตัวอย่างเช่น การบล็อกไม่ให้เครื่องมือค้นหาเข้าถึง JavaScript ที่แสดงโฆษณาคั่นระหว่างหน้าหรือเปลี่ยนเส้นทางผู้ใช้อาจถูกมองว่าเป็นการปิดบังหน้าเว็บจริง
แนวทางปฏิบัติที่ดีที่สุด: ตรวจสอบปัญหาการแสดงผลด้วยเครื่องมือ "ดึงข้อมูลเหมือนเป็น Google" หรือดูภาพรวมคร่าวๆ ว่าทรัพยากรใดบ้างที่ถูกบล็อกด้วยรายงาน "ทรัพยากรที่ถูกบล็อก" ทั้งสองรายการมีอยู่ใน Google Search Console หากทรัพยากรใดๆ ถูกบล็อกที่อาจป้องกันไม่ให้เครื่องมือค้นหาแสดงผลหน้าเว็บอย่างถูกต้อง ให้นำ robots.txt ที่ไม่อนุญาตออก
โปรแกรมรวบรวมข้อมูล SEO Oncrawl
 เรียนรู้เพิ่มเติม
เรียนรู้เพิ่มเติมรายการตรวจสอบหุ่นยนต์ฝึกหัดที่ดีที่สุด
เป็นเรื่องปกติที่น่ากลัวที่เว็บไซต์จะถูกลบออกจาก Google โดยไม่ได้ตั้งใจโดยหุ่นยนต์ที่ควบคุมข้อผิดพลาด
อย่างไรก็ตาม การจัดการหุ่นยนต์สามารถเป็นส่วนเสริมที่ทรงพลังให้กับคลังแสง SEO ของคุณ เมื่อคุณรู้วิธีใช้งาน เพียงให้แน่ใจว่าได้ดำเนินการอย่างชาญฉลาดและด้วยความระมัดระวัง
เพื่อช่วย นี่คือรายการตรวจสอบด่วน:
- รักษาความปลอดภัยข้อมูลส่วนตัวโดยใช้การป้องกันด้วยรหัสผ่าน
- บล็อกการเข้าถึงไซต์การพัฒนาโดยใช้การพิสูจน์ตัวตนฝั่งเซิร์ฟเวอร์
- จำกัดโปรแกรมรวบรวมข้อมูลที่ใช้แบนด์วิดท์แต่ให้คุณค่าเพียงเล็กน้อยด้วยการบล็อก user-agent
- ตรวจสอบให้แน่ใจว่าโดเมนหลักและโดเมนย่อยมีไฟล์ข้อความชื่อ “robots.txt” ในไดเรกทอรีระดับบนสุดซึ่งส่งคืนรหัส 200
- ตรวจสอบให้แน่ใจว่าไฟล์ robots.txt มีอย่างน้อยหนึ่งบล็อกที่มีบรรทัด user-agent และ disallow line
- ตรวจสอบให้แน่ใจว่าไฟล์ robots.txt มีอย่างน้อยหนึ่งบรรทัดแผนผังเว็บไซต์ ป้อนเป็นบรรทัดสุดท้าย
- ตรวจสอบไฟล์ robots.txt ในตัวทดสอบ GSC robots.txt
- ตรวจสอบให้แน่ใจว่าทุกหน้าที่จัดทำดัชนีได้ระบุคำสั่งแท็กโรบ็อตของตน
- ตรวจสอบให้แน่ใจว่าไม่มีคำสั่งที่ขัดแย้งหรือซ้ำซ้อนระหว่าง robots.txt, เมตาแท็กของโรบ็อต, X-Robots-Tags, ไฟล์ .htaccess และการจัดการพารามิเตอร์ GSC
- แก้ไขข้อผิดพลาด "URL ที่ส่งที่ทำเครื่องหมาย 'noindex'" หรือ "URL ที่ส่งถูกบล็อกโดย robots.txt" ในรายงานความครอบคลุม GSC
- ทำความเข้าใจสาเหตุของการยกเว้นที่เกี่ยวข้องกับโรบ็อตในรายงานความครอบคลุม GSC
- ตรวจสอบให้แน่ใจว่าแสดงเฉพาะหน้าที่เกี่ยวข้องในรายงาน "ทรัพยากรที่ถูกบล็อก" ของ GSC
ไปตรวจสอบการจัดการหุ่นยนต์ของคุณและให้แน่ใจว่าคุณทำถูกต้อง