
การรวบรวมข้อมูล การสร้างดัชนี และ Python: ทั้งหมดที่คุณต้องรู้
เผยแพร่แล้ว: 2021-05-31ฉันต้องการเริ่มต้นบทความนี้ด้วยสมการง่ายๆ: หากหน้าเว็บของคุณไม่ได้รับการรวบรวมข้อมูล หน้าเว็บจะไม่ได้รับการจัดทำดัชนี ดังนั้นประสิทธิภาพ SEO ของคุณจะได้รับผลกระทบ (และเหม็น) เสมอ
ด้วยเหตุนี้ SEO จึงจำเป็นต้องพยายามค้นหาวิธีที่ดีที่สุดในการทำให้เว็บไซต์ของตนสามารถรวบรวมข้อมูลได้ และจัดเตรียมหน้าที่สำคัญที่สุดแก่ Google เพื่อให้จัดทำดัชนีและเริ่มรับการเข้าชมผ่านหน้าเว็บเหล่านี้
โชคดีที่เรามีแหล่งข้อมูลมากมายที่สามารถช่วยปรับปรุงความสามารถในการรวบรวมข้อมูลเว็บไซต์ของเรา เช่น Screaming Frog, Oncrawl หรือ Python ฉันจะแสดงให้คุณเห็นว่า Python สามารถช่วยคุณวิเคราะห์และปรับปรุงความเป็นมิตรในการรวบรวมข้อมูลและดัชนีชี้วัดได้อย่างไร โดยส่วนใหญ่ การปรับปรุงประเภทนี้จะนำไปสู่อันดับที่ดีขึ้น การมองเห็นที่สูงขึ้นใน SERP และในที่สุด ผู้ใช้ก็เข้ามาที่เว็บไซต์ของคุณมากขึ้น
1. ขอสร้างดัชนีด้วย Python
1.1. สำหรับ Google
การขอสร้างดัชนีสำหรับ Google สามารถทำได้หลายวิธี แม้ว่าน่าเศร้าที่ฉันไม่มั่นใจนัก ฉันจะแนะนำคุณผ่านสามตัวเลือกที่แตกต่างกันพร้อมข้อดีและข้อเสีย:
- Selenium และ Google Search Console: จากมุมมองของฉันและหลังจากทดสอบและตัวเลือกอื่นๆ แล้ว นี่เป็นวิธีแก้ปัญหาที่มีประสิทธิภาพที่สุด อย่างไรก็ตาม หลังจากพยายามหลายครั้ง เป็นไปได้ว่าจะมีป๊อปอัป captcha ที่จะทำลายมัน
- การส่ง Ping แผนผังเว็บไซต์: ช่วยในการรวบรวมข้อมูลแผนผังเว็บไซต์ตามที่ร้องขอได้อย่างแน่นอน แต่ไม่ใช่ URL เฉพาะ เช่น ในกรณีที่มีการเพิ่มหน้าใหม่ในเว็บไซต์
- Google Indexing API: ไม่น่าเชื่อถือมาก ยกเว้นสำหรับผู้แพร่ภาพกระจายเสียงและเว็บไซต์แพลตฟอร์มงาน ช่วยเพิ่มอัตราการรวบรวมข้อมูลแต่ไม่สร้างดัชนี URL เฉพาะ
หลังจากภาพรวมคร่าวๆ เกี่ยวกับแต่ละวิธีแล้ว มาเจาะลึกกันทีละวิธี
1.1.1. ซีลีเนียมและ Google Search Console
โดยพื้นฐานแล้ว สิ่งที่เราจะทำในโซลูชันแรกนี้คือการเข้าถึง Google Search Console จากเบราว์เซอร์ที่มี Selenium และทำซ้ำกระบวนการเดียวกันกับที่เราจะปฏิบัติตามด้วยตนเองเพื่อส่ง URL จำนวนมากสำหรับการจัดทำดัชนีด้วย Google Search Console แต่เป็นแบบอัตโนมัติ
หมายเหตุ: อย่าใช้วิธีนี้มากเกินไป และส่งเฉพาะหน้าสำหรับการจัดทำดัชนีหากเนื้อหาได้รับการอัปเดตหรือหากหน้าเป็นหน้าใหม่ทั้งหมด
เคล็ดลับในการลงชื่อเข้าใช้ Google Search Console ด้วย Selenium คือการเข้าถึง OUATH Playground ก่อน ตามที่ฉันอธิบายในบทความนี้เกี่ยวกับวิธีการดาวน์โหลดรายงานสถิติการรวบรวมข้อมูล GSC โดยอัตโนมัติ
#เรานำเข้าโมดูลเหล่านี้
เวลานำเข้า
จากซีลีเนียมนำเข้า webdriver
จาก webdriver_manager.chrome นำเข้า ChromeDriverManager
จาก selenium.webdriver.common.keys นำเข้าคีย์
#เราติดตั้งไดรเวอร์ซีลีเนียม
ไดรเวอร์ = webdriver.Chrome(ChromeDriverManager().install())
#เราเข้าถึงบัญชีสนามเด็กเล่น OUATH เพื่อลงชื่อเข้าใช้บริการของ Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.google .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#เรารอสักครู่เพื่อให้แน่ใจว่าการเรนเดอร์เสร็จสมบูรณ์ก่อนที่จะเลือกองค์ประกอบด้วย Xpath และแนะนำที่อยู่อีเมลของเรา
เวลานอน(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<ที่อยู่อีเมลของคุณ>")
form1.send_keys(Keys.ENTER)
#เหมือนกันครับ รอสักครู่แล้วจึงแนะนำรหัสผ่านของเรา
เวลานอน(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<รหัสผ่านของคุณ>")
form2.send_keys(Keys.ENTER)
หลังจากนั้น เราสามารถเข้าถึง URL คอนโซลการค้นหาของ Google:
driver.get('https://search.google.com/search-console?resource_id=your_domain')
เวลานอน(5)
กล่อง=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/input[2]')
box.send_keys("your_URL")
box.send_keys(Keys.ENTER)
เวลานอน(5)
การสร้างดัชนี = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
การสร้างดัชนี.click()
เวลานอน(120)
น่าเสียดาย ตามที่ได้อธิบายไว้ในบทนำ ดูเหมือนว่าหลังจากมีคำขอจำนวนหนึ่ง มันเริ่มต้องใช้ captcha ปริศนาเพื่อดำเนินการตามคำขอสร้างดัชนี เนื่องจากวิธีการอัตโนมัติไม่สามารถแก้แคปต์ชาได้ นี่คือสิ่งที่ขัดขวางการแก้ปัญหานี้
1.1.2. ปิงแผนผังเว็บไซต์
URL แผนผังเว็บไซต์สามารถส่งไปยัง Google ได้ด้วยวิธี ping โดยพื้นฐานแล้ว คุณจะต้องส่งคำขอไปยังปลายทางต่อไปนี้เพื่อแนะนำ URL แผนผังเว็บไซต์เป็นพารามิเตอร์:
http://www.google.com/ping?sitemap=URL/of/file
สิ่งนี้สามารถทำได้โดยอัตโนมัติอย่างง่ายดายด้วย Python และคำขอดังที่ฉันอธิบายไว้ในบทความนี้
นำเข้า urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" ตอบกลับ = urllib.request.urlopen(url)
1.1.3. Google Indexing API
Google Indexing API อาจเป็นทางออกที่ดีในการปรับปรุงอัตราการรวบรวมข้อมูลของคุณ แต่โดยปกติแล้วไม่ใช่วิธีที่มีประสิทธิภาพมากในการจัดทำดัชนีเนื้อหาของคุณ เนื่องจากควรใช้เฉพาะในกรณีที่เว็บไซต์ของคุณมี JobPosting หรือ BroadcastEvent ที่ฝังอยู่ใน VideoObject อย่างไรก็ตาม หากคุณต้องการทดลองใช้และทดสอบด้วยตัวเอง คุณสามารถทำตามขั้นตอนต่อไปได้
ก่อนอื่น ในการเริ่มต้นใช้งาน API นี้ คุณต้องไปที่ Google Cloud Console สร้างโครงการและข้อมูลรับรองบัญชีบริการ หลังจากนั้น คุณจะต้องเปิดใช้งาน Indexing API จากไลบรารี และเพิ่มบัญชีอีเมลที่ได้รับพร้อมกับข้อมูลรับรองบัญชีบริการในฐานะเจ้าของพร็อพเพอร์ตี้บน Google Search Console คุณอาจต้องใช้ Google Search Console เวอร์ชันเก่าจึงจะเพิ่มที่อยู่อีเมลนี้เป็นเจ้าของพร็อพเพอร์ตี้ได้
เมื่อคุณทำตามขั้นตอนก่อนหน้านี้แล้ว คุณจะสามารถเริ่มขอการจัดทำดัชนีและการแยกดัชนีด้วย API นี้โดยใช้โค้ดถัดไป:
จาก oauth2client.service_account นำเข้า ServiceAccountCredentials
นำเข้า httplib2
ขอบเขต = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
หนังสือรับรอง = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
หากข้อมูลประจำตัวเป็น None หรือ credentials.invalid:
หนังสือรับรอง = tools.run_flow (โฟลว์ ที่เก็บข้อมูล)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
สำหรับการวนซ้ำในช่วง (len(list_urls)):
เนื้อหา = '''{
'url': "'''+str(list_urls[iteration])+'''",
'type': "URL_UPDATED"
}'''
การตอบสนอง เนื้อหา = http.request(ENDPOINT, method="POST", body=content)
พิมพ์ (ตอบกลับ)
พิมพ์ (เนื้อหา)หากคุณต้องการขอยกเลิกการสร้างดัชนี คุณจะต้องเปลี่ยนประเภทคำขอจาก “URL_UPDATED” เป็น “URL_DELETED” โค้ดก่อนหน้าจะพิมพ์การตอบกลับจาก API พร้อมเวลาแจ้งเตือนและสถานะ หากสถานะเป็น 200 คำขอจะทำสำเร็จ
1.2. สำหรับ Bing
บ่อยครั้งเมื่อเราพูดเกี่ยวกับ SEO เรานึกถึง Google เท่านั้น แต่เราไม่สามารถลืมได้ว่าในบางตลาดมีเสิร์ชเอ็นจิ้นอื่นๆ และ/หรือเสิร์ชเอ็นจิ้นอื่นๆ ที่มีส่วนแบ่งการตลาดที่น่านับถือ เช่น Bing
สิ่งสำคัญคือต้องพูดถึงตั้งแต่ต้นว่า Bing มีคุณลักษณะที่สะดวกมากใน Bing Webmaster Tools ซึ่งช่วยให้คุณสามารถส่งคำขอส่ง URL ได้มากถึง 10,000 URL ต่อวันในกรณีส่วนใหญ่ บางครั้ง โควต้ารายวันของคุณอาจต่ำกว่า 10,000 URL แต่คุณสามารถเลือกขอเพิ่มโควต้าได้ หากคุณคิดว่าคุณต้องการโควต้าที่มากขึ้นเพื่อตอบสนองความต้องการของคุณ คุณสามารถอ่านเพิ่มเติมเกี่ยวกับเรื่องนี้ได้ในหน้านี้
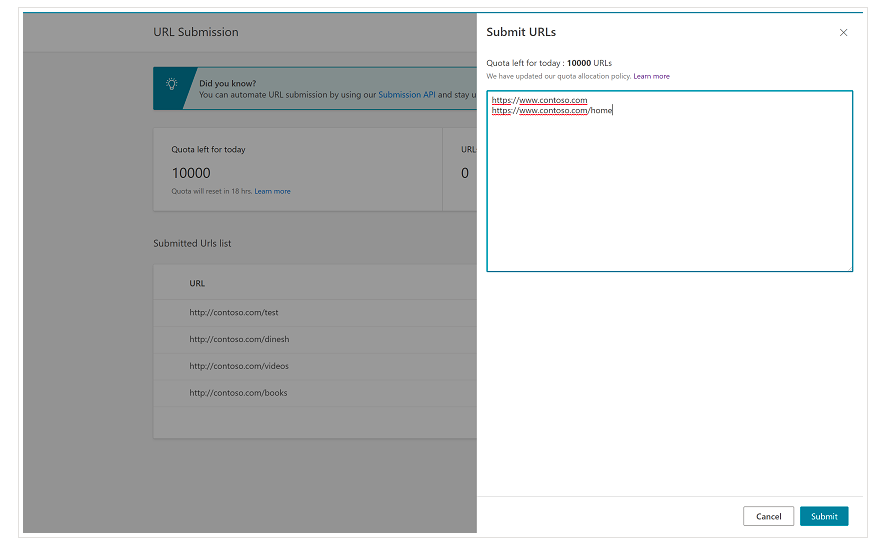
คุณลักษณะนี้สะดวกมากสำหรับการส่ง URL จำนวนมาก เนื่องจากคุณจะต้องแนะนำ URL ของคุณในบรรทัดต่างๆ ในเครื่องมือส่ง URL จากอินเทอร์เฟซปกติของ Bing Webmaster Tools
1.2.1. API การทำดัชนี Bing
Bing Indexing API สามารถใช้กับคีย์ API ที่จำเป็นต้องนำมาใช้เป็นพารามิเตอร์ สามารถรับคีย์ API นี้ได้จาก Bing Webmaster Tools ไปที่ส่วนการเข้าถึง API จากนั้นสร้างคีย์ API
เมื่อได้รับคีย์ API แล้ว เราสามารถเล่นกับ API ด้วยโค้ดต่อไปนี้ (คุณจะต้องเพิ่มคีย์ API และ URL ของเว็บไซต์เท่านั้น):
คำขอนำเข้า
list_urls = ["https://www.example.com", "https://www.example/test2/"]
สำหรับ y ใน list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
ส่วนหัว = {'ประเภทเนื้อหา': 'แอปพลิเคชัน/json; ชุดอักขระ=utf-8'}
x = คำขอโพสต์ (url, data=myobj, ส่วนหัว = ส่วนหัว)
พิมพ์(str(y) + ": " + str(x))การดำเนินการนี้จะพิมพ์ URL และรหัสตอบกลับในการทำซ้ำแต่ละครั้ง ตรงกันข้ามกับ Google Indexing API API นี้ใช้ได้กับเว็บไซต์ทุกประเภท
[กรณีศึกษา] เพิ่มการมองเห็นโดยการปรับปรุงความสามารถในการรวบรวมข้อมูลเว็บไซต์สำหรับ Googlebot
 อ่านกรณีศึกษา
อ่านกรณีศึกษา2. การวิเคราะห์ สร้างและอัปโหลดแผนผังเว็บไซต์
อย่างที่เราทราบกันดีว่าแผนผังเว็บไซต์เป็นองค์ประกอบที่มีประโยชน์มากในการจัดเตรียม URL ของเครื่องมือค้นหาให้บอทของเครื่องมือค้นหาที่เราต้องการให้รวบรวมข้อมูล เพื่อให้บ็อตของเครื่องมือค้นหาทราบว่าแผนผังไซต์ของเราอยู่ที่ใด จึงควรอัปโหลดไปยัง Google Search Console และ Bing Webmaster Tools และรวมไว้ในไฟล์ robots.txt สำหรับส่วนที่เหลือของบอท
ด้วย Python เราสามารถทำงานกับแผนผังไซต์ได้สามด้านที่แตกต่างกัน: การวิเคราะห์ การสร้างและการอัปโหลดและการลบจาก Google Search Console
2.1. การนำเข้าและวิเคราะห์แผนผังเว็บไซต์ด้วย Python
Advertools เป็นไลบรารี่ที่ยอดเยี่ยมที่สร้างโดย Elias Dabbas ที่สามารถใช้สำหรับการนำเข้าแผนผังเว็บไซต์รวมถึงงาน SEO อื่นๆ อีกมากมาย คุณจะสามารถนำเข้าแผนผังเว็บไซต์ไปยัง Dataframes ได้โดยใช้:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
ไลบรารีนี้สนับสนุนแผนผังไซต์ XML แผนผังไซต์ข่าวสาร และแผนผังไซต์วิดีโอ
ในทางกลับกัน หากคุณสนใจเพียงนำเข้า URL จากแผนผังเว็บไซต์ คุณสามารถใช้คำขอห้องสมุดและ BeautifulSoup ได้
คำขอนำเข้า
จาก bs4 นำเข้า BeautifulSoup
r = request.get("https://www.example.com/your_sitemap.xml")
xml = r.text
ซุป = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] สำหรับ x ใน urls]
เมื่อนำเข้าแผนผังเว็บไซต์แล้ว คุณสามารถลองใช้ URL ที่แยกออกมาและทำการวิเคราะห์เนื้อหาตามที่ Koray Tugberk อธิบายในบทความนี้
2.2. การสร้างแผนผังเว็บไซต์ด้วย Python
คุณยังสามารถใช้ Python เพื่อสร้าง sitemaps.xml จากรายการ URL ตามที่ JC Chouinard อธิบายไว้ในบทความนี้ สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับเว็บไซต์ที่มีไดนามิกมากซึ่ง URL มีการเปลี่ยนแปลงอย่างรวดเร็วและเมื่อใช้ร่วมกับวิธีการ ping ที่อธิบายข้างต้น อาจเป็นทางออกที่ดีในการจัดหา URL ใหม่ให้กับ Google และรวบรวมข้อมูลและจัดทำดัชนีอย่างรวดเร็ว
เมื่อเร็ว ๆ นี้ Greg Bernhardt ได้สร้างแอปด้วย Streamlit และ Python เพื่อสร้างแผนผังเว็บไซต์
2.3. การอัปโหลดและการลบแผนผังเว็บไซต์จาก Google Search Console
Google Search Console มี API ที่สามารถใช้ได้หลักๆ สองวิธี: เพื่อดึงข้อมูลเกี่ยวกับประสิทธิภาพเว็บและจัดการแผนผังเว็บไซต์ ในโพสต์นี้ เราจะเน้นที่ตัวเลือกในการอัปโหลดและลบแผนผังเว็บไซต์
อันดับแรก สิ่งสำคัญคือต้องสร้างหรือใช้โปรเจ็กต์ที่มีอยู่จาก Google Cloud Console เพื่อรับข้อมูลรับรอง OUATH และเปิดใช้บริการ Google Search Console JC Chouinard อธิบายอย่างดีถึงขั้นตอนที่คุณต้องปฏิบัติตามเพื่อเข้าถึง Google Search Console API ด้วย Python และวิธีส่งคำขอครั้งแรกของคุณในบทความนี้ โดยพื้นฐานแล้ว เราสามารถใช้โค้ดของเขาได้อย่างสมบูรณ์ แต่โดยการแนะนำการเปลี่ยนแปลงเท่านั้น เราจะเพิ่ม “https://www.googleapis.com/auth/webmasters” ลงในขอบเขตแทน “https://www.googleapis.com” /auth/webmasters.readonly” เนื่องจากเราจะใช้ API ไม่เพียงเพื่ออ่านแต่เพื่ออัปโหลดและลบแผนผังเว็บไซต์

ครั้งหนึ่ง เราเชื่อมต่อกับ API เราสามารถเริ่มเล่นกับมันและแสดงรายการแผนผังเว็บไซต์ทั้งหมดจากคุณสมบัติของ Google Search Console ด้วยโค้ดส่วนถัดไป:
สำหรับ site_url ใน Verified_sites_urls:
พิมพ์ (site_url)
# ดึงรายชื่อแผนผังเว็บไซต์ที่ส่ง
แผนผังเว็บไซต์ = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
ถ้า 'แผนผังเว็บไซต์' ในแผนผังเว็บไซต์:
sitemap_urls = [s['path'] สำหรับ s ในแผนผังไซต์['sitemap']]
พิมพ์ (" " + "\n ".join(sitemap_urls))
เมื่อพูดถึงแผนผังไซต์ที่เฉพาะเจาะจง เราสามารถทำงานสามอย่างที่เราจะทำอย่างละเอียดในหัวข้อถัดไป ได้แก่ การอัปโหลด การลบ และการขอข้อมูล
2.3.1. กำลังอัปโหลดแผนผังเว็บไซต์
ในการอัปโหลดแผนผังเว็บไซต์ด้วย Python เราเพียงแค่ระบุ URL ของเว็บไซต์และเส้นทางแผนผังเว็บไซต์และเรียกใช้โค้ดนี้:
เว็บไซต์ = 'คุณสมบัติ GSC ของคุณ' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. การลบแผนผังเว็บไซต์
อีกด้านหนึ่งของเหรียญคือเมื่อเราต้องการลบแผนผังเว็บไซต์ นอกจากนี้เรายังสามารถลบแผนผังเว็บไซต์จาก Google Search Console ด้วย Python โดยใช้วิธี "ลบ" แทน "ส่ง"
เว็บไซต์ = 'คุณสมบัติ GSC ของคุณ' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. การขอข้อมูลจากแผนผังเว็บไซต์
สุดท้าย เรายังสามารถขอข้อมูลจากแผนผังเว็บไซต์โดยใช้วิธีการ "รับ"
เว็บไซต์ = 'คุณสมบัติ GSC ของคุณ' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
สิ่งนี้จะส่งคืนการตอบกลับในรูปแบบ JSON เช่น: 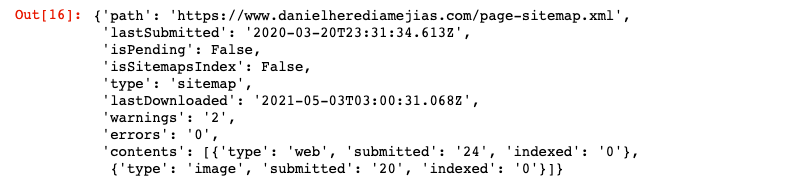
3. การวิเคราะห์การเชื่อมโยงภายในและโอกาส
การมีโครงสร้างการเชื่อมโยงภายในที่เหมาะสมจะมีประโยชน์มากในการอำนวยความสะดวกให้บอทเครื่องมือค้นหารวบรวมข้อมูลเว็บไซต์ของคุณ ปัญหาหลักบางประการที่ฉันพบโดยการตรวจสอบเว็บไซต์จำนวนหนึ่งที่มีการตั้งค่าทางเทคนิคที่ซับซ้อนมาก ได้แก่:
- ลิงก์ที่นำมาใช้กับเหตุการณ์เมื่อคลิก กล่าว โดยย่อ Googlebot จะไม่คลิกที่ปุ่ม ดังนั้น หากลิงก์ของคุณถูกแทรกด้วยเหตุการณ์เมื่อคลิก Googlebot จะไม่สามารถติดตามได้
- ลิงก์ที่แสดงผลฝั่งไคลเอ็นต์: แม้ว่า Googlebot และเครื่องมือค้นหาอื่นๆ จะใช้งาน JavaScript ได้ดีขึ้นมาก แต่ก็ยังเป็นสิ่งที่ค่อนข้างท้าทายสำหรับพวกเขา ดังนั้นจึงเป็นการดีกว่ามากที่จะแสดงผลลิงก์เหล่านี้ในฝั่งเซิร์ฟเวอร์และให้บริการใน HTML แบบดิบไปยัง บอทของเสิร์ชเอ็นจิ้นมากกว่าที่คาดหวังให้รันสคริปต์ JavaScript
- ป๊อปอัปการเข้าสู่ระบบและ/หรือประตูอายุ: ป๊อปอัปการเข้าสู่ระบบและประตูอายุสามารถป้องกันไม่ให้บอทของเครื่องมือค้นหารวบรวมข้อมูลเนื้อหาที่อยู่เบื้องหลัง "อุปสรรค" เหล่านี้
- การใช้แอตทริบิวต์ Nofollow มากเกินไป: การใช้แอตทริบิวต์ nofollow จำนวนมากที่ชี้ไปยังหน้าภายในที่มีค่าจะป้องกันไม่ให้บอทของเครื่องมือค้นหารวบรวมข้อมูลได้
- Noindex และ follow: ในทางเทคนิค การรวมกันของ noindex และ follow directives ควรให้บอทของเครื่องมือค้นหารวบรวมข้อมูลลิงก์ที่อยู่ในหน้านั้น อย่างไรก็ตาม ดูเหมือนว่า Googlebot จะหยุดรวบรวมข้อมูลหน้าเว็บเหล่านั้นด้วยคำสั่ง noindex เมื่อเวลาผ่านไป
ด้วย Python เราสามารถวิเคราะห์โครงสร้างการเชื่อมโยงภายในของเราและค้นหาโอกาสในการเชื่อมโยงภายในใหม่ในโหมดเป็นกลุ่ม
3.1. การวิเคราะห์การเชื่อมโยงภายในกับ Python
หลายเดือนก่อน ฉันเขียนบทความเกี่ยวกับวิธีใช้ Python และไลบรารี Networkx เพื่อสร้างกราฟเพื่อแสดงโครงสร้างการเชื่อมโยงภายในในลักษณะที่มองเห็นได้ชัดเจน:
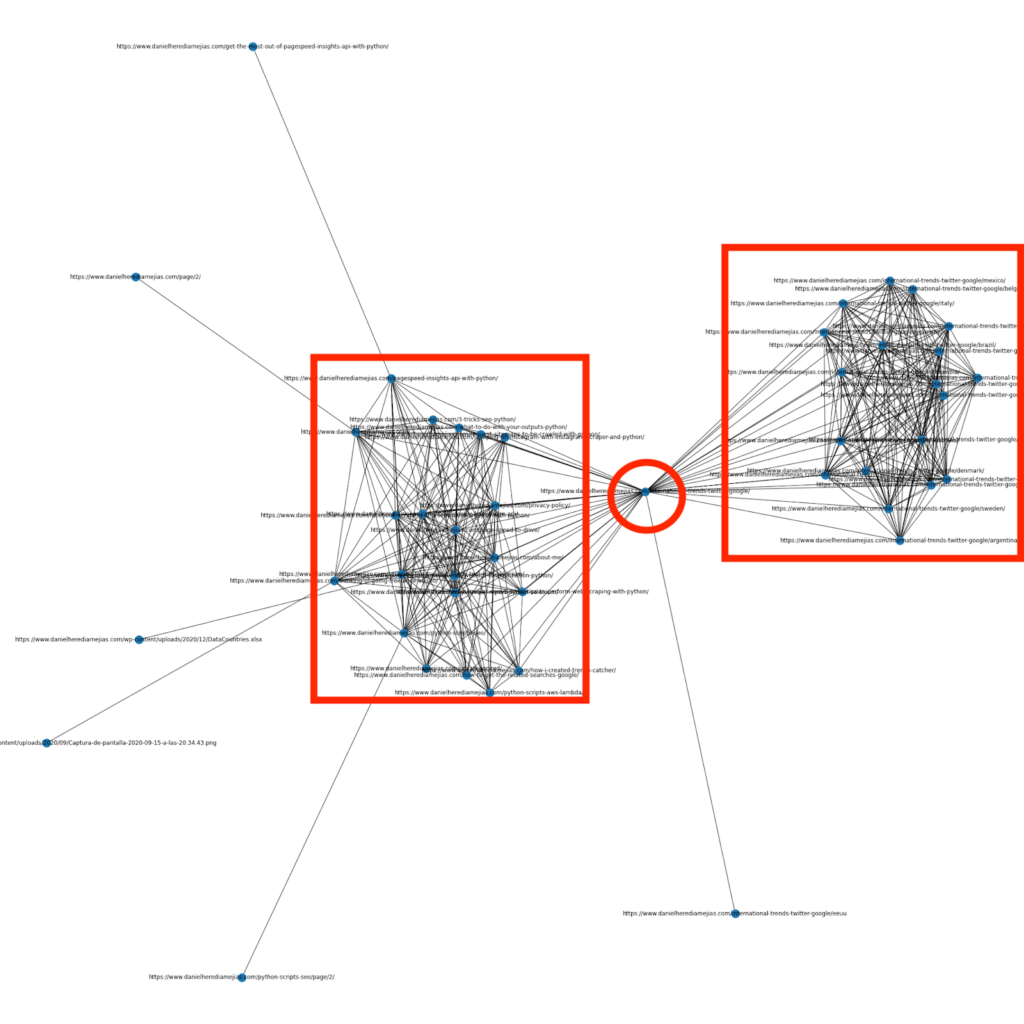
นี่คือสิ่งที่คล้ายกับสิ่งที่คุณจะได้รับจาก Screaming Frog มาก แต่ข้อดีของการใช้ Python สำหรับการวิเคราะห์ประเภทนี้คือ โดยพื้นฐานแล้วคุณสามารถเลือกข้อมูลที่คุณต้องการรวมไว้ในกราฟเหล่านี้และควบคุมองค์ประกอบกราฟส่วนใหญ่ได้ เช่น เป็นสี ขนาดโหนด หรือแม้แต่หน้าที่คุณต้องการเพิ่ม
3.2. ค้นหาโอกาสในการเชื่อมโยงภายในใหม่ด้วย Python
นอกเหนือจากการวิเคราะห์โครงสร้างเว็บไซต์แล้ว คุณยังสามารถใช้ Python เพื่อค้นหาโอกาสในการเชื่อมโยงภายในใหม่ๆ โดยการให้คำหลักและ URL จำนวนหนึ่ง และวนซ้ำ URL เหล่านั้นเพื่อค้นหาเงื่อนไขที่ให้ไว้ในชิ้นส่วนของเนื้อหา
นี่คือสิ่งที่สามารถทำงานได้ดีกับการส่งออก Semrush หรือ Ahrefs เพื่อค้นหาลิงก์ภายในที่มีประสิทธิภาพจากบางหน้าที่มีการจัดอันดับสำหรับคำหลักอยู่แล้ว ดังนั้นจึงมีอำนาจบางประเภทอยู่แล้ว
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับวิธีการนี้ได้ที่นี่
4. ความเร็วของเว็บไซต์ 5xx และหน้าข้อผิดพลาดซอฟต์
ตามที่ Google ระบุไว้ในหน้านี้เกี่ยวกับความหมายของงบประมาณการรวบรวมข้อมูลสำหรับ Google การทำให้ไซต์ของคุณเร็วขึ้นช่วยปรับปรุงประสบการณ์ของผู้ใช้และเพิ่มอัตราการรวบรวมข้อมูล ในทางกลับกัน ยังมีปัจจัยอื่นๆ ที่อาจส่งผลต่องบประมาณการตระเวน เช่น หน้าข้อผิดพลาดแบบซอฟต์ เนื้อหาคุณภาพต่ำ และเนื้อหาที่ซ้ำกันในไซต์
4.1. ความเร็วเพจและ Python
4.2.1 การวิเคราะห์ความเร็วเว็บไซต์ของคุณด้วย Python
Page Speed Insights API มีประโยชน์อย่างยิ่งในการวิเคราะห์ว่าเว็บไซต์ของคุณทำงานอย่างไรในแง่ของความเร็วของหน้า และรับข้อมูลจำนวนมากเกี่ยวกับตัววัดความเร็วหน้าเว็บต่างๆ (เกือบ 50) บวกกับ Core Web Vitals
การทำงานกับ Page Speed Insights กับ Python นั้นตรงไปตรงมามาก มีเพียงคีย์ API และคำขอเท่านั้นจึงจะสามารถใช้งานได้ ตัวอย่างเช่น:
นำเข้า urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Note คุณสามารถแทรก URL ของคุณด้วย URL พารามิเตอร์ และคุณยังสามารถแก้ไขพารามิเตอร์ของอุปกรณ์ได้หากต้องการรับข้อมูลสำหรับเดสก์ท็อป ตอบกลับ = urllib.request.urlopen(url) ข้อมูล = json.loads(response.read())
นอกจากนี้ คุณยังสามารถคาดการณ์ได้ด้วยเครื่องคำนวณ Python และ Lighthouse Scoring ว่าคะแนนประสิทธิภาพโดยรวมของคุณจะดีขึ้นมากเพียงใด ในกรณีที่ทำการเปลี่ยนแปลงที่ร้องขอเพื่อเพิ่มความเร็วหน้าเว็บของคุณตามที่อธิบายไว้ในบทความนี้
4.2.2 การเพิ่มประสิทธิภาพและการปรับขนาดภาพด้วย Python
ที่เกี่ยวข้องกับความเร็วของเว็บไซต์ Python ยังสามารถใช้เพื่อเพิ่มประสิทธิภาพ บีบอัด และปรับขนาดรูปภาพตามที่อธิบายไว้ในบทความเหล่านี้ซึ่งเขียนโดย Koray Tugberk และ Greg Bernhardt:
- บีบอัดรูปภาพโดยอัตโนมัติด้วย Python ผ่าน FTP
- ปรับขนาดรูปภาพด้วย Python เป็นกลุ่ม
- ปรับแต่งรูปภาพด้วย Python สำหรับ SEO และ UX
4.2. 5xx และการแยกข้อผิดพลาดรหัสตอบกลับอื่น ๆ ด้วย Python
ข้อผิดพลาดรหัสตอบกลับ 5xx อาจบ่งบอกว่าเซิร์ฟเวอร์ของคุณไม่เร็วพอที่จะจัดการกับคำขอทั้งหมดที่ได้รับ ซึ่งอาจส่งผลเสียอย่างมากต่ออัตราการรวบรวมข้อมูลของคุณ และยังสามารถสร้างความเสียหายต่อประสบการณ์ของผู้ใช้ได้อีกด้วย
เพื่อให้แน่ใจว่าเว็บไซต์ของคุณทำงานได้ตามที่คาดไว้ คุณสามารถทำให้รายงานสถิติการรวบรวมข้อมูลดาวน์โหลดโดยอัตโนมัติด้วย Python และ Selenium และคุณสามารถติดตามไฟล์บันทึกของคุณได้อย่างใกล้ชิด
4.3. การแยกหน้าข้อผิดพลาดแบบซอฟต์ด้วย Python
เมื่อเร็ว ๆ นี้ Jose Luis Hernando ได้ตีพิมพ์บทความเพื่อเป็นเกียรติแก่ Hamlet Batista เกี่ยวกับวิธีที่คุณสามารถแยกรายงานความครอบคลุมโดยอัตโนมัติด้วย Node.js นี่อาจเป็นวิธีแก้ปัญหาที่ยอดเยี่ยมในการดึงหน้าข้อผิดพลาดแบบซอฟต์และแม้แต่ข้อผิดพลาดการตอบสนอง 5xx ที่อาจส่งผลเสียต่ออัตราการรวบรวมข้อมูลของคุณ
นอกจากนี้เรายังสามารถทำซ้ำกระบวนการเดียวกันนี้ด้วย Python เพื่อคอมไพล์ URL ทั้งหมดที่ Google Search Console ให้ไว้ในแท็บเดียวในแท็บเดียวว่าไม่ถูกต้อง ถูกต้องโดยมีคำเตือน ถูกต้อง และยกเว้น
อันดับแรก เราต้องลงชื่อเข้าใช้ Google Search Console ตามที่อธิบายไว้ก่อนหน้านี้ในบทความนี้ด้วย Python with Selenium หลังจากนั้น เราจะเลือกช่องสถานะ URL ทั้งหมด เราจะเพิ่มแถวได้มากถึง 100 แถวต่อหน้า และเราจะเริ่มทำซ้ำกับ URL ทุกประเภทที่รายงานโดย GSC และดาวน์โหลดไฟล์ Excel ทุกไฟล์
เวลานำเข้า
จากซีลีเนียมนำเข้า webdriver
จาก webdriver_manager.chrome นำเข้า ChromeDriverManager
จาก selenium.webdriver.common.keys นำเข้าคีย์
ไดรเวอร์ = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.google .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
เวลานอน(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<ที่อยู่ของคุณ>")
searchBox.send_keys(Keys.ENTER)
เวลานอน(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input') : ค้นหา
searchBox.send_keys("<รหัสผ่านของคุณ>")
searchBox.send_keys(Keys.ENTER)
เวลานอน(5)
yourdomain = str(input("Insert your http property or domain. if it is a domain include: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] สำหรับฉันในช่วง (len(df1["URL"]))]
df1['Type'] = รายการค่า
list_results = df1.values.tolist()
อื่น:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","")).replace("/","_")).replace(":","_") + "-Coverage-Drilldown-" + วันนี้ + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] สำหรับฉันในช่วง (len(df2["URL"]))]
df2['Type'] = รายการค่า
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<filename>.csv', header=True, index=False, encoding = "utf-8")
ผลลัพธ์สุดท้ายดูเหมือนว่า: 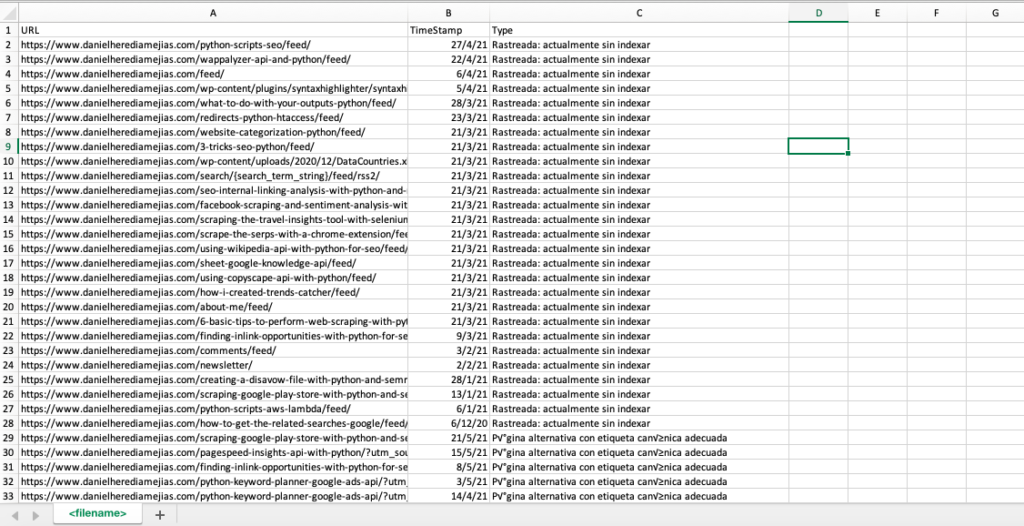
4.4. บันทึกการวิเคราะห์ไฟล์ด้วย Python
นอกจากข้อมูลที่มีอยู่ในรายงานสถิติการรวบรวมข้อมูลจาก Google Search Console แล้ว คุณยังสามารถวิเคราะห์ไฟล์ของคุณเองโดยใช้ Python เพื่อรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีการที่บอทของเครื่องมือค้นหารวบรวมข้อมูลเว็บไซต์ของคุณ หากคุณยังไม่ได้ใช้เครื่องมือวิเคราะห์บันทึกสำหรับ SEO คุณสามารถอ่านบทความนี้จาก SEO Garden ซึ่งจะอธิบายการวิเคราะห์บันทึกด้วย Python
[Ebook] สี่กรณีการใช้งานเพื่อใช้ประโยชน์จากการวิเคราะห์บันทึก SEO
ดาวน์โหลดฟรี5. บทสรุปสุดท้าย
เราได้เห็นแล้วว่า Python สามารถเป็นเครื่องมือที่ยอดเยี่ยมในการวิเคราะห์และปรับปรุงการรวบรวมข้อมูลและการทำดัชนีของเว็บไซต์ของเราได้หลายวิธี เรายังได้เห็นวิธีทำให้ชีวิตง่ายขึ้นมากด้วยการทำงานอัตโนมัติที่น่าเบื่อและต้องทำด้วยตนเอง ซึ่งต้องใช้เวลาหลายพันชั่วโมงของคุณ
ฉันต้องบอกว่าน่าเสียดายที่ฉันไม่มั่นใจอย่างเต็มที่กับโซลูชันที่ Google เสนอในขณะนี้เพื่อขอจัดทำดัชนีสำหรับ URL จำนวนมาก แม้ว่าฉันจะเข้าใจในระดับหนึ่งว่ากลัวที่จะเสนอวิธีแก้ปัญหาที่ดีกว่า: SEO จำนวนมากอาจมีแนวโน้ม เพื่อใช้มากเกินไป
ในทางตรงกันข้าม มี Bing ซึ่งนำเสนอโซลูชันที่ยอดเยี่ยมและสะดวกสบายในการขอสร้างดัชนี URL ผ่าน API และแม้กระทั่งผ่านอินเทอร์เฟซปกติบน Bing Webmaster Tools
เนื่องจาก API การจัดทำดัชนีของ Google มีพื้นที่สำหรับการปรับปรุง องค์ประกอบอื่นๆ เช่น การมีแผนผังเว็บไซต์ที่เข้าถึงได้และอัปเดต การเชื่อมโยงภายใน ความเร็วของหน้า หน้าข้อผิดพลาดที่อ่อนนุ่ม และเนื้อหาที่ซ้ำกันและมีคุณภาพต่ำจึงมีความสำคัญมากขึ้น ว่าเว็บไซต์ของคุณได้รับการรวบรวมข้อมูลอย่างเหมาะสมและมีการจัดทำดัชนีหน้าที่สำคัญที่สุดของคุณ