
ไปป์ไลน์ Business Intelligence ตามบริการของ AWS – กรณีศึกษา
เผยแพร่แล้ว: 2019-05-16ในช่วงไม่กี่ปีที่ผ่านมา เราได้เห็นความสนใจที่เพิ่มขึ้นในการวิเคราะห์ข้อมูลขนาดใหญ่ ผู้บริหาร ผู้จัดการ และผู้มีส่วนได้ส่วนเสียทางธุรกิจอื่นๆ ใช้ Business Intelligence (BI) ในการตัดสินใจอย่างมีข้อมูล ช่วยให้พวกเขาสามารถวิเคราะห์ข้อมูลที่สำคัญได้ทันที และตัดสินใจโดยอิงตามสัญชาตญาณของพวกเขาไม่เพียงเท่านั้น แต่ยังสามารถเรียนรู้จากพฤติกรรมที่แท้จริงของลูกค้าได้อีกด้วย
เมื่อคุณตัดสินใจที่จะสร้างโซลูชัน BI ที่มีประสิทธิภาพและให้ข้อมูล ขั้นตอนแรกที่ทีมพัฒนาของคุณต้องทำคือการวางแผนสถาปัตยกรรมไปป์ไลน์ข้อมูล มีเครื่องมือบนคลาวด์หลายอย่างที่สามารถนำมาใช้เพื่อสร้างไปป์ไลน์ดังกล่าวได้ และไม่มีโซลูชันใดที่จะดีที่สุดสำหรับทุกธุรกิจ ก่อนที่คุณจะตัดสินใจเลือกตัวเลือกใดตัวเลือกหนึ่ง คุณควรพิจารณากลุ่มเทคโนโลยีปัจจุบัน ราคาของเครื่องมือ และชุดทักษะของนักพัฒนาซอฟต์แวร์ของคุณ ในบทความนี้ ฉันจะแสดง สถาปัตยกรรมที่สร้างด้วยเครื่องมือของ AWS ที่ปรับใช้เป็นส่วนหนึ่งของแอปพลิเคชัน Timesheets ได้สำเร็จ
ภาพรวมสถาปัตยกรรม
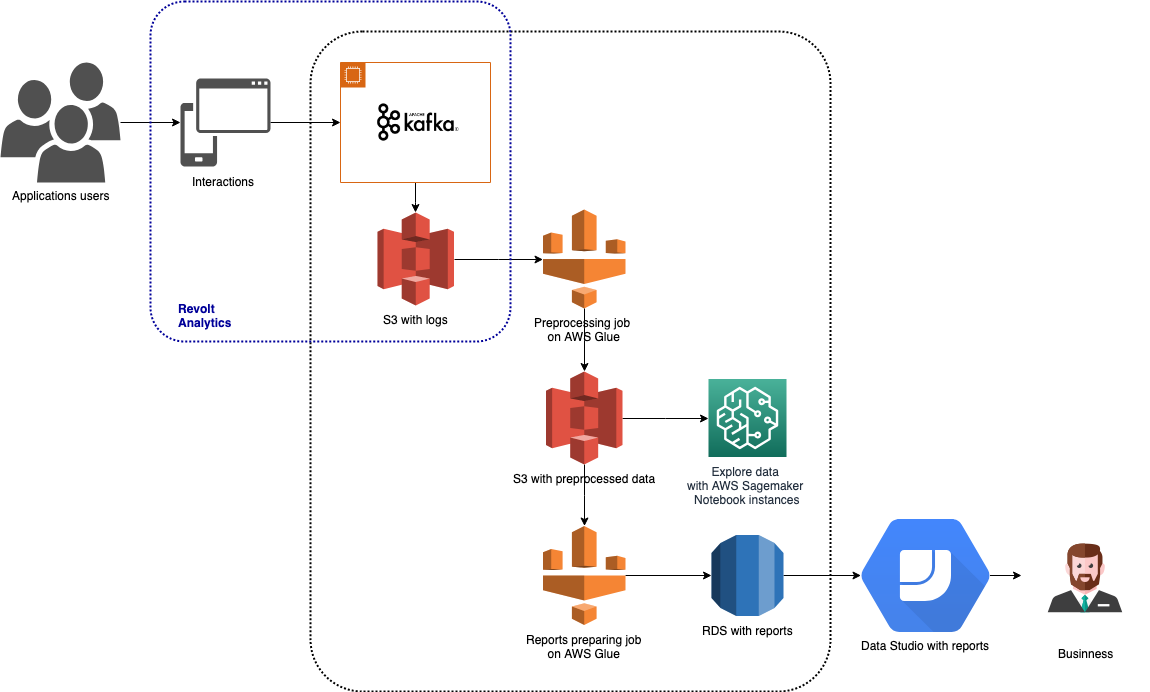
Timesheets เป็นเครื่องมือในการติดตามและรายงานเวลาของพนักงาน สามารถใช้ผ่านเว็บ, iOS, Android และแอปพลิเคชันเดสก์ท็อป, แชทบอทที่ผสานรวมกับแฮงเอาท์และ Slack และการดำเนินการบน Google Assistant เนื่องจากมีแอพหลายประเภท จึงมีข้อมูลที่หลากหลายให้ติดตาม ข้อมูลจะถูกรวบรวมผ่าน Revolt Analytics ซึ่งจัดเก็บไว้ใน Amazon S3 และประมวลผลด้วย AWS Glue และ Amazon SageMaker ผลลัพธ์ของการวิเคราะห์จะถูกเก็บไว้ใน Amazon RDS และใช้เพื่อสร้างรายงานที่เป็นภาพใน Google Data Studio สถาปัตยกรรมนี้ถูกนำเสนอในกราฟด้านบน
ในย่อหน้าต่อไปนี้ ฉันจะอธิบายสั้นๆ เกี่ยวกับเครื่องมือ Big Data แต่ละอย่างที่ใช้ในสถาปัตยกรรมนี้
Revolt Analytics
Revolt Analytics เป็นเครื่องมือที่พัฒนาโดย Miquido เพื่อติดตามและวิเคราะห์ข้อมูลจากแอปพลิเคชันทุกประเภท เพื่อลดความซับซ้อนในการใช้งาน Revolt ในระบบไคลเอนต์ iOS, Android, JavaScript, Go, Python และ Java SDK ได้ถูกสร้างขึ้น หนึ่งในคุณสมบัติหลักของ Revolt คือประสิทธิภาพ: เหตุการณ์ทั้งหมดจะถูกจัดคิว จัดเก็บ และส่งเป็นแพ็กเก็ต ซึ่งทำให้มั่นใจได้ว่าจะถูกส่งไปอย่างรวดเร็วและมีประสิทธิภาพ Revolt ช่วยให้เจ้าของแอปพลิเคชันสามารถระบุผู้ใช้และติดตามพฤติกรรมของพวกเขาในแอปได้ ซึ่งช่วยให้เราสร้างโมเดล Machine Learning ที่สร้างคุณค่าได้ เช่น ระบบคำแนะนำที่ปรับให้เหมาะกับแต่ละบุคคลอย่างสมบูรณ์และแบบจำลอง Churn Prediction และสำหรับการทำโปรไฟล์ลูกค้าตามพฤติกรรมของผู้ใช้ Revolt ยังมีคุณสมบัติเซสชั่น ความรู้เกี่ยวกับเส้นทางและพฤติกรรมของผู้ใช้ในแอปพลิเคชันสามารถช่วยให้คุณเข้าใจเป้าหมายและความต้องการของลูกค้าของคุณ
สามารถติดตั้ง Revolt บนโครงสร้างพื้นฐานใดก็ได้ที่คุณเลือก วิธีนี้ช่วยให้คุณควบคุมต้นทุนและเหตุการณ์ที่ติดตามได้ทั้งหมด ในกรณี Timesheets ที่นำเสนอในบทความนี้ สร้างขึ้นบนโครงสร้างพื้นฐานของ AWS ด้วยการเข้าถึงที่จัดเก็บข้อมูลอย่างเต็มรูปแบบ เจ้าของผลิตภัณฑ์จึงสามารถรับข้อมูลเชิงลึกเกี่ยวกับแอปพลิเคชันของตนและใช้ข้อมูลนั้นในระบบอื่นๆ ได้อย่างง่ายดาย
Revolt SDKs ถูกเพิ่มเข้าไปในทุกองค์ประกอบของระบบ Timesheets ซึ่งประกอบด้วย:
- แอพ Android และ iOS (สร้างด้วย Flutter)
- แอปเดสก์ท็อป (สร้างด้วยอิเล็กตรอน)
- เว็บแอป (เขียนด้วย React)
- แบ็กเอนด์ (เขียนเป็นภาษาโกลัง)
- แฮงเอาท์และแชทออนไลน์แบบ Slack
- การดำเนินการกับ Google Assistant
Revolt ให้ความรู้แก่ผู้ดูแลระบบ Timesheets เกี่ยวกับอุปกรณ์ (เช่น ยี่ห้ออุปกรณ์ รุ่น) และระบบ (เช่น เวอร์ชันของระบบปฏิบัติการ ภาษา เขตเวลา) ที่ลูกค้าของแอปใช้ นอกจากนี้ยังส่งเหตุการณ์ที่กำหนดเองต่างๆ ที่เกี่ยวข้องกับกิจกรรมของผู้ใช้ในแอป ดังนั้น ผู้ดูแลระบบสามารถวิเคราะห์พฤติกรรมของผู้ใช้ และเข้าใจวัตถุประสงค์และความคาดหวังของพวกเขาได้ดีขึ้น พวกเขายังสามารถตรวจสอบความสามารถในการใช้งานของคุณลักษณะที่นำมาใช้ และประเมินว่าคุณลักษณะเหล่านี้เป็นไปตามสมมติฐานของเจ้าของผลิตภัณฑ์เกี่ยวกับวิธีการใช้งานหรือไม่

กาว AWS
AWS Glue เป็นบริการ ETL (แยก แปลง และโหลด) ที่ช่วยเตรียมข้อมูลสำหรับงานวิเคราะห์ มันรันงาน ETL ในสภาพแวดล้อมที่ไม่มีเซิร์ฟเวอร์ Apache Spark โดยปกติประกอบด้วยสามองค์ประกอบต่อไปนี้:
- คำจำกัดความ ของโปรแกรมรวบรวมข้อมูล – โปรแกรมรวบรวมข้อมูลใช้เพื่อสแกนข้อมูลในที่เก็บและแหล่งที่มาทุกประเภท จัดประเภท ดึงข้อมูลสคีมาจากข้อมูลเหล่านั้น และจัดเก็บข้อมูลเมตาเกี่ยวกับข้อมูลเหล่านั้นใน Data Catalog ตัวอย่างเช่น สามารถสแกนบันทึกที่จัดเก็บไว้ในไฟล์ JSON บน Amazon S3 และจัดเก็บข้อมูลสคีมาใน Data Catalog
- สคริปต์งาน – งาน AWS Glue แปลงข้อมูลให้อยู่ในรูปแบบที่ต้องการ AWS Glue สามารถสร้างสคริปต์เพื่อโหลด ล้างข้อมูล และแปลงข้อมูลของคุณได้โดยอัตโนมัติ คุณยังสามารถจัดเตรียมสคริปต์ Apache Spark ของคุณเองที่เขียนด้วย Python หรือ Scala ที่จะเรียกใช้การแปลงที่ต้องการ ซึ่งอาจรวมถึงงานต่างๆ เช่น การจัดการค่า Null, sessionization, aggregations เป็นต้น
- ทริกเกอร์ – สามารถเรียกใช้โปรแกรมรวบรวมข้อมูลและงานได้ตามต้องการ หรือสามารถตั้งค่าให้เริ่มทำงานเมื่อมีทริกเกอร์ที่ระบุได้ ทริกเกอร์อาจเป็นกำหนดการตามเวลาหรือเหตุการณ์ (เช่น การดำเนินการที่สำเร็จของงานที่ระบุ) ตัวเลือกนี้ช่วยให้คุณสามารถจัดการความใหม่ของข้อมูลในรายงานของคุณได้อย่างง่ายดาย
ในสถาปัตยกรรม Timesheets ของเรา ไปป์ไลน์ส่วนนี้แสดงดังต่อไปนี้:
- ทริกเกอร์ตามเวลาเริ่มงานการประมวลผลล่วงหน้า ซึ่งดำเนินการล้างข้อมูล กำหนดบันทึกเหตุการณ์ที่เหมาะสมกับเซสชัน และคำนวณการรวมเริ่มต้น ข้อมูลผลลัพธ์ของงานนี้ถูกเก็บไว้ใน AWS S3
- ทริกเกอร์ที่สองถูกตั้งค่าให้ทำงานหลังจากดำเนินการงานพรีโพรเซสซิงเสร็จสมบูรณ์และสำเร็จ ทริกเกอร์นี้เริ่มงานที่เตรียมข้อมูลซึ่งใช้โดยตรงในรายงานที่วิเคราะห์โดยเจ้าของผลิตภัณฑ์
- ผลลัพธ์ของงานที่สองจะถูกเก็บไว้ในฐานข้อมูล AWS RDS ทำให้เข้าถึงและใช้งานได้ง่ายในเครื่องมือ Business Intelligence เช่น Google Data Studio, PowerBI หรือ Tableau
AWS SageMaker
Amazon SageMaker มีโมดูลสำหรับสร้าง ฝึกฝน และปรับใช้โมเดลแมชชีนเลิร์นนิง
ช่วยให้สามารถฝึกอบรมและปรับแต่งโมเดลได้ในทุกขนาด และช่วยให้สามารถใช้อัลกอริธึมประสิทธิภาพสูงที่ AWS จัดหาให้ อย่างไรก็ตาม คุณยังสามารถใช้อัลกอริธึมแบบกำหนดเองได้หลังจากที่คุณให้ภาพนักเทียบท่าที่เหมาะสมแล้ว นอกจากนี้ AWS SageMaker ยังช่วยลดความยุ่งยากในการปรับแต่งไฮเปอร์พารามิเตอร์ด้วยงานที่กำหนดค่าได้ซึ่งเปรียบเทียบเมตริกสำหรับชุดพารามิเตอร์โมเดลต่างๆ
ใน Timesheets อินสแตนซ์โน้ตบุ๊กของ SageMaker ช่วยเราสำรวจข้อมูล ทดสอบสคริปต์ ETL และเตรียมต้นแบบของแผนภูมิการแสดงภาพเพื่อใช้ในเครื่องมือ BI สำหรับการสร้างรายงาน โซลูชันนี้สนับสนุนและปรับปรุงการทำงานร่วมกันของนักวิทยาศาสตร์ข้อมูล เนื่องจากทำให้แน่ใจว่าพวกเขาทำงานในสภาพแวดล้อมการพัฒนาเดียวกัน ยิ่งไปกว่านั้น สิ่งนี้ช่วยให้แน่ใจว่าไม่มีข้อมูลที่ละเอียดอ่อน (ซึ่งอาจเป็นส่วนหนึ่งของเอาต์พุตของเซลล์ของโน้ตบุ๊ก) ถูกจัดเก็บไว้นอกเหนือโครงสร้างพื้นฐานของ AWS เนื่องจากโน้ตบุ๊กจะถูกจัดเก็บในบัคเก็ต AWS S3 เท่านั้น และไม่จำเป็นต้องมีที่เก็บ git เพื่อแบ่งปันงานระหว่างเพื่อนร่วมงาน .
สรุป
การตัดสินใจว่าจะใช้เครื่องมือ Big Data และ Machine Learning ใดเป็นสิ่งสำคัญในการออกแบบสถาปัตยกรรมไปป์ไลน์สำหรับโซลูชัน Business Intelligence ตัวเลือกนี้อาจส่งผลกระทบอย่างมากต่อความสามารถของระบบ ต้นทุน และความสะดวกในการเพิ่มคุณสมบัติใหม่ในอนาคต แน่นอนว่าเครื่องมือของ AWS นั้นควรค่าแก่การพิจารณา แต่คุณควรเลือกเทคโนโลยีที่เหมาะสมกับ Tech-stack ในปัจจุบันและทักษะของทีมพัฒนาของคุณ
ใช้ประโยชน์จากประสบการณ์ของเราในการสร้างโซลูชันที่มุ่งเน้นอนาคตและติดต่อเรา!