
แยกแนวคิดและคำหลักออกจากข้อความโดยอัตโนมัติ (ตอนที่ 1 : วิธีการดั้งเดิม)
เผยแพร่แล้ว: 2022-02-22ที่แผนก R&D ของ Oncrawl เรากำลังมองหาการปรับปรุงเนื้อหาเชิงความหมายของหน้าเว็บของคุณมากขึ้น การใช้โมเดลแมชชีนเลิร์นนิงสำหรับการประมวลผลภาษาธรรมชาติ (NLP) เราสามารถเปรียบเทียบเนื้อหาในหน้าของคุณโดยละเอียด สร้างการสรุปอัตโนมัติ เติมหรือแก้ไขแท็กของบทความของคุณ เพิ่มประสิทธิภาพเนื้อหาตามข้อมูล Google Search Console ของคุณ ฯลฯ
ในบทความที่แล้ว เราได้พูดถึงการแยกเนื้อหาข้อความจากหน้า HTML ครั้งนี้ เราอยากจะพูดถึงการดึงคำหลักจากข้อความโดยอัตโนมัติ หัวข้อนี้จะแบ่งออกเป็นสองกระทู้:
- อันแรกจะครอบคลุมบริบทและวิธีการที่เรียกว่า "ดั้งเดิม" พร้อมตัวอย่างที่เป็นรูปธรรมหลายประการ
- อันที่สองที่จะมาในเร็วๆ นี้ จะจัดการกับแนวทางเชิงความหมายที่มากขึ้นตามหม้อแปลงและวิธีการประเมินผล เพื่อที่จะเปรียบเทียบวิธีการต่างๆ เหล่านี้
บริบท
นอกจากชื่อเรื่องหรือบทคัดย่อแล้ว อะไรจะดีไปกว่าการระบุเนื้อหาของข้อความ บทความทางวิทยาศาสตร์ หรือหน้าเว็บ มากกว่าการใช้คำสำคัญสองสามคำ เป็นวิธีที่ง่ายและมีประสิทธิภาพมากในการระบุหัวข้อและแนวคิดของข้อความที่ยาวกว่ามาก นอกจากนี้ยังเป็นวิธีที่ดีในการจัดหมวดหมู่ชุดข้อความ: ระบุข้อความและจัดกลุ่มตามคำหลัก ไซต์ที่นำเสนอบทความทางวิทยาศาสตร์ เช่น PubMed หรือ arxiv.org สามารถเสนอหมวดหมู่และคำแนะนำตามคำหลักเหล่านี้
คีย์เวิร์ดยังมีประโยชน์มากสำหรับการทำดัชนีเอกสารขนาดใหญ่และการดึงข้อมูล ซึ่งเป็นสาขาที่เชี่ยวชาญซึ่งรู้จักกันดีในเครื่องมือค้นหา
การขาดคีย์เวิร์ดเป็นปัญหาที่เกิดซ้ำในการจัดหมวดหมู่บทความทางวิทยาศาสตร์โดยอัตโนมัติ [1]: บทความจำนวนมากไม่มีการกำหนดคีย์เวิร์ด ดังนั้นจึงต้องพบวิธีการเพื่อดึงแนวคิดและคำหลักออกจากข้อความโดยอัตโนมัติ เพื่อประเมินความเกี่ยวข้องของชุดคำหลักที่แยกโดยอัตโนมัติ ชุดข้อมูลมักจะเปรียบเทียบคำหลักที่แยกโดยอัลกอริทึมกับคำหลักที่แยกโดยมนุษย์หลายคน
อย่างที่คุณสามารถจินตนาการได้ นี่เป็นปัญหาที่เครื่องมือค้นหาใช้ร่วมกันเมื่อจัดหมวดหมู่หน้าเว็บ ความเข้าใจที่ดีขึ้นเกี่ยวกับกระบวนการแยกคำหลักแบบอัตโนมัติจะช่วยให้เข้าใจมากขึ้นว่าทำไมหน้าเว็บจึงถูกจัดตำแหน่งสำหรับคำหลักดังกล่าวหรือคำหลักดังกล่าว นอกจากนี้ยังสามารถเปิดเผยช่องว่างทางความหมายที่ป้องกันไม่ให้มีการจัดอันดับที่ดีสำหรับคำหลักที่คุณกำหนดเป้าหมาย
มีหลายวิธีในการแยกคำหลักออกจากข้อความหรือย่อหน้าอย่างชัดเจน ในโพสต์แรกนี้ เราจะอธิบายแนวทางที่เรียกว่า "คลาสสิก"
[Ebook] Data SEO: การผจญภัยครั้งยิ่งใหญ่ครั้งต่อไป
 อ่านอีบุ๊ก
อ่านอีบุ๊กพันธนาการ
อย่างไรก็ตาม เรามีข้อจำกัดและข้อกำหนดเบื้องต้นบางประการในการเลือกอัลกอริทึม:
- วิธีการจะต้องสามารถดึงคำหลักจากเอกสารเดียว วิธีการบางอย่างต้องการคลังข้อมูลที่สมบูรณ์ เช่น เอกสารหลายร้อยหรือหลายพันฉบับ แม้ว่าเสิร์ชเอ็นจิ้นสามารถใช้วิธีการเหล่านี้ได้ แต่ก็ไม่มีประโยชน์สำหรับเอกสารเดียว
- เราอยู่ในกรณีของแมชชีนเลิร์นนิงที่ไม่มีผู้ดูแล เราไม่มีชุดข้อมูลในภาษาฝรั่งเศส อังกฤษ หรือภาษาอื่นๆ พร้อมข้อมูลที่มีคำอธิบายประกอบ กล่าวอีกนัยหนึ่ง เราไม่มีเอกสารนับพันที่มีการแยกคำหลักแล้ว
- วิธีการต้องไม่ขึ้นกับโดเมน / ศัพท์ของเอกสาร เราต้องการแยกคีย์เวิร์ดออกจากเอกสารประเภทใดก็ได้ เช่น บทความข่าว หน้าเว็บ ฯลฯ โปรดทราบว่าชุดข้อมูลบางชุดที่มีการดึงคีย์เวิร์ดสำหรับเอกสารแต่ละฉบับแล้วมักจะเป็นยาเฉพาะโดเมน วิทยาการคอมพิวเตอร์ ฯลฯ
- วิธีการบางอย่างใช้โมเดลการติดแท็ก POS เช่น ความสามารถของแบบจำลอง NLP เพื่อระบุคำในประโยคตามประเภทไวยากรณ์: กริยา คำนาม ตัวกำหนด การพิจารณาความสำคัญของคีย์เวิร์ดที่เป็นคำนามแทนที่จะเป็นตัวกำหนดนั้นมีความเกี่ยวข้องอย่างชัดเจน อย่างไรก็ตาม ขึ้นอยู่กับภาษา บางครั้งโมเดลการติดแท็ก POS มีคุณภาพไม่สม่ำเสมอมาก
เกี่ยวกับวิธีการดั้งเดิม
เราแยกความแตกต่างระหว่างวิธีการที่เรียกว่า "ดั้งเดิม" กับวิธีล่าสุดที่ใช้ NLP - การประมวลผลภาษาธรรมชาติ - เทคนิคต่างๆ เช่น การฝังคำและการฝังตามบริบท หัวข้อนี้จะกล่าวถึงในโพสต์ในอนาคต แต่ก่อนอื่น กลับไปที่แนวทางคลาสสิก เราแยกความแตกต่างออกเป็นสองวิธี:
- แนวทางสถิติ
- กราฟแนวทาง
วิธีการทางสถิติส่วนใหญ่จะอาศัยความถี่ของคำและการเกิดขึ้นร่วมของคำเหล่านั้น เราเริ่มต้นด้วยสมมติฐานง่ายๆ เพื่อสร้างฮิวริสติกและแยกคำที่สำคัญ: คำที่ใช้บ่อย ชุดคำที่ต่อเนื่องกันซึ่งปรากฏหลายครั้ง เป็นต้น วิธีการแบบกราฟจะสร้างกราฟโดยที่แต่ละโหนดสามารถสัมพันธ์กับคำได้ กลุ่มของ คำหรือประโยค จากนั้นแต่ละส่วนโค้งสามารถแสดงถึงความน่าจะเป็น (หรือความถี่) ของการสังเกตคำเหล่านี้ร่วมกัน
นี่คือวิธีการสองสามวิธี:
- ตามสถิติ
- TF-IDF
- คราด
- ยาเกะ
- แบบกราฟ
- TextRank
- อันดับกระทู้
- SingleRank
ตัวอย่างทั้งหมดที่ระบุข้อความการใช้งานที่นำมาจากหน้าเว็บนี้: Jazz au Tresor : John Coltrane – Impressions Graz 1962
แนวทางสถิติ
เราจะแนะนำให้คุณรู้จักกับสองวิธี Rake และ Yake ในบริบทของ SEO คุณอาจเคยได้ยินวิธี TF-IDF แต่เนื่องจากมันต้องการคลังเอกสาร เราจะไม่จัดการกับมันที่นี่
คราด
RAKE ย่อมาจาก Rapid Automatic Keyword Extraction มีการนำวิธีนี้ไปใช้หลายวิธีใน Python รวมถึง rake-nltk คะแนนของคำหลักแต่ละคำ ซึ่งเรียกอีกอย่างว่าคำหลักเนื่องจากมีหลายคำ ขึ้นอยู่กับสององค์ประกอบ: ความถี่ของคำและผลรวมของการเกิดขึ้นร่วมกัน รัฐธรรมนูญของคำหลักแต่ละคำนั้นง่ายมาก ประกอบด้วย:
- ตัดข้อความเป็นประโยค
- ตัดแต่ละประโยคออกเป็นวลีที่สำคัญ
ในประโยคต่อไปนี้ เราจะแยกกลุ่มคำทั้งหมดโดยคั่นด้วยเครื่องหมายวรรคตอนหรือคำหยุด:
เมื่อก่อน Coltrane เป็นผู้นำกลุ่ม โดยมี Eric Dolphy อยู่เคียงข้างและ Reggie Workman เล่นดับเบิลเบส
ซึ่งอาจส่งผลให้เกิดคีย์เวิร์ดต่อไปนี้:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass"
โปรดทราบว่าคำหยุดคือชุดของคำที่ใช้บ่อยมาก เช่น “ the “, “ in “, “and” or “ it “ เนื่องจากวิธีการแบบคลาสสิกมักใช้การคำนวณความถี่ของการเกิดคำ จึงควรเลือกคำหยุดอย่างระมัดระวัง โดยส่วนใหญ่ เราไม่ต้องการให้มีคำเช่น >"to" , "the" or "of" ในข้อเสนอวลีสำคัญของเรา อันที่จริง คำหยุดเหล่านี้ไม่เกี่ยวข้องกับเขตข้อมูลศัพท์เฉพาะ และดังนั้นจึงมีความเกี่ยวข้องน้อยกว่าคำว่า " jazz " หรือ " saxophone " มาก เป็นต้น

เมื่อเราแยกวลีคีย์เวิร์ดของผู้สมัครหลายคนแล้ว เราจะให้คะแนนตามความถี่ของคำและการเกิดขึ้นร่วม ยิ่งคะแนนสูงเท่าใด วลีสำคัญก็ยิ่งมีความเกี่ยวข้องมากขึ้นเท่านั้น
มาลองอย่างรวดเร็วกับข้อความจากบทความเกี่ยวกับ John Coltrane
# ตัวอย่างหลามสำหรับคราด จาก rake_nltk นำเข้า Rake # สมมติว่าคุณมีบทความในตัวแปร 'ข้อความ' แล้ว เรค = คราด (คำหยุด = FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(ข้อความ) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
นี่คือ 5 คีย์เวิร์ดแรก:
“วิทยุสาธารณะแห่งชาติของออสเตรีย”, “ยอดโคลงสั้น ๆ ขึ้นสวรรค์”, “กราซมีลักษณะเฉพาะสองอย่าง”, “จอห์น โคลทราน เทเนอร์แซกโซโฟน”, “เฉพาะเวอร์ชันที่บันทึกเท่านั้น”
มีข้อเสียบางประการสำหรับวิธีนี้ อย่างแรกคือความสำคัญของการเลือกคำหยุดเพราะใช้เพื่อแยกประโยคออกเป็นวลีคีย์เวิร์ดของผู้สมัคร อย่างที่สองคือเมื่อคำสำคัญยาวเกินไป มักจะมีคะแนนสูงกว่าเพราะคำที่มีอยู่ซ้ำกัน เพื่อจำกัดความยาวของข้อความสำคัญ เราได้ตั้งค่าวิธีการด้วย max_length=4
ยาเกะ
YAKE ย่อมาจาก Yet Another Keyword Extractor วิธีนี้อ้างอิงจากบทความต่อไปนี้ YAKE! การแยกคำหลักจากเอกสารเดียวโดยใช้คุณสมบัติท้องถิ่นหลายรายการซึ่งเริ่มตั้งแต่ปี 2020 เป็นวิธีการที่ใหม่กว่า RAKE ซึ่งผู้เขียนได้เสนอการนำ Python ไปใช้บน Github
สำหรับ RAKE เราจะพึ่งพาความถี่ของคำและการเกิดขึ้นร่วม ผู้เขียนยังจะเพิ่มฮิวริสติกที่น่าสนใจอีกด้วย:
- เราจะแยกความแตกต่างระหว่างคำที่เป็นตัวพิมพ์เล็กและคำที่เป็นตัวพิมพ์ใหญ่ (ไม่ว่าจะเป็นตัวอักษรตัวแรกหรือทั้งคำ) เราจะถือว่าคำที่ขึ้นต้นด้วยตัวพิมพ์ใหญ่ (ยกเว้นที่จุดเริ่มต้นของประโยค) มีความเกี่ยวข้องมากกว่าคำอื่นๆ: ชื่อผู้คน เมือง ประเทศ แบรนด์ นี่เป็นหลักการเดียวกันสำหรับคำที่เป็นตัวพิมพ์ใหญ่ทั้งหมด
- คะแนนของคำหลักของผู้สมัครแต่ละคนจะขึ้นอยู่กับตำแหน่งในข้อความ หากวลีคีย์เวิร์ดของผู้สมัครปรากฏที่จุดเริ่มต้นของข้อความ พวกเขาจะได้คะแนนสูงกว่าที่ปรากฏตอนท้าย ตัวอย่างเช่น บทความข่าวมักกล่าวถึงแนวคิดที่สำคัญในตอนต้นของบทความ
# ตัวอย่าง python สำหรับ yake จาก yake นำเข้า Keyword Extractor เป็น Yake yake = Yake(lan="fr", คำหยุด = FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords (ข้อความ)
เช่นเดียวกับ RAKE นี่คือผลลัพธ์ 5 อันดับแรก:
“เทรเชอร์ แจ๊ส”, “จอห์น โคลทราน”, “อิมเพรสชั่นส์ กราซ”, “กราซ”, “โคลทราน”
แม้จะมีคำบางคำซ้ำกันในวลีสำคัญบางคำ แต่วิธีนี้ก็ดูน่าสนใจทีเดียว
กราฟแนวทาง
วิธีการประเภทนี้อยู่ไม่ไกลจากวิธีการทางสถิติในแง่ที่ว่าเราจะคำนวณการเกิดขึ้นร่วมของคำด้วย คำต่อท้ายอันดับที่เกี่ยวข้องกับชื่อวิธีการบางอย่าง เช่น TextRank นั้นใช้หลักการของอัลโก PageRank เพื่อคำนวณความนิยมของแต่ละหน้าตามลิงก์ขาเข้าและขาออก
[Ebook] ทำ SEO อัตโนมัติด้วย Oncrawl
 อ่านอีบุ๊ก
อ่านอีบุ๊กTextRank
อัลกอริธึมนี้มาจาก TextRank ของกระดาษ: Bringing Order into Texts จากปี 2004 และอิงตามหลักการเดียวกันกับอัลกอริธึม PageRank อย่างไรก็ตาม แทนที่จะสร้างกราฟที่มีหน้าและลิงก์ เราจะสร้างกราฟด้วยคำ แต่ละคำจะเชื่อมโยงกับคำอื่นๆ ตามการเกิดขึ้นพร้อมกัน
มีการใช้งานหลายอย่างใน Python ในบทความนี้ ผมจะแนะนำ pytextrank เราจะทำลายหนึ่งในข้อจำกัดของเราเกี่ยวกับการติดแท็ก POS อันที่จริง เมื่อสร้างกราฟ เราจะไม่รวมคำทั้งหมดเป็นโหนด เฉพาะคำกริยาและคำนามเท่านั้นที่จะนำมาพิจารณา เช่นเดียวกับวิธีการก่อนหน้านี้ที่ใช้คำหยุดเพื่อกรองตัวเลือกที่ไม่เกี่ยวข้องออกไป TextRank algo ใช้คำประเภทไวยากรณ์
นี่คือตัวอย่างส่วนหนึ่งของกราฟที่จะสร้างโดย algo : 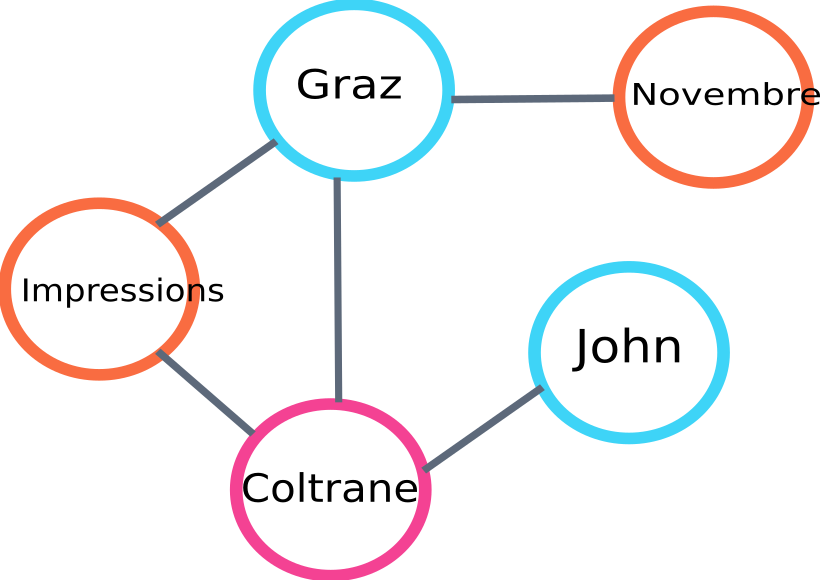
ตัวอย่างกราฟอันดับข้อความ
นี่คือตัวอย่างการใช้งานใน Python โปรดทราบว่าการใช้งานนี้ใช้กลไกไปป์ไลน์ของไลบรารี spaCy ห้องสมุดนี้สามารถทำการติดแท็ก POS ได้
# ตัวอย่าง python สำหรับ pytextrank
นำเข้า spacy
นำเข้า pytextrank
#โหลดโมเดลฝรั่งเศส
nlp = spacy.load("fr_core_news_sm")
# เพิ่ม pytextrank ให้กับไพพ์
nlp.add_pipe("ลำดับข้อความ")
doc = nlp (ข้อความ)
textrank_keyphrases = doc._.phrases
นี่คือผลลัพธ์ 5 อันดับแรก:
“โคเปนเฮก”, “โนเวมเบร”, “อิมเพรสชั่นส์กราซ”, “กราซ”, “จอห์น โคลทราน”
นอกจากการแยกข้อความสำคัญแล้ว TextRank ยังแยกประโยคอีกด้วย สิ่งนี้มีประโยชน์มากสำหรับการทำสิ่งที่เรียกว่า “การสรุปแบบแยกส่วน” – ประเด็นนี้จะไม่ครอบคลุมในบทความนี้
บทสรุป
ในบรรดาวิธีทดสอบสามวิธีที่นี่ สองวิธีสุดท้ายดูเหมือนกับเราค่อนข้างเกี่ยวข้องกับหัวเรื่องของข้อความ เพื่อเปรียบเทียบวิธีการเหล่านี้ได้ดีขึ้น เห็นได้ชัดว่าเราจะต้องประเมินแบบจำลองต่างๆ เหล่านี้ด้วยตัวอย่างจำนวนมากขึ้น มีหน่วยวัดสำหรับวัดความเกี่ยวข้องของแบบจำลองการแยกคำหลักเหล่านี้จริงๆ
รายการคำหลักที่สร้างโดยรูปแบบดั้งเดิมที่เรียกว่าเหล่านี้เป็นพื้นฐานที่ดีในการตรวจสอบว่าหน้าเว็บของคุณกำหนดเป้าหมายได้ดี นอกจากนี้ ยังให้การประมาณเบื้องต้นว่าเสิร์ชเอ็นจิ้นอาจเข้าใจและจัดประเภทเนื้อหาอย่างไร
ในทางกลับกัน วิธีอื่นๆ ที่ใช้โมเดล NLP ที่ผ่านการฝึกอบรมล่วงหน้า เช่น BERT สามารถใช้เพื่อแยกแนวคิดออกจากเอกสารได้ ตรงกันข้ามกับวิธีการแบบคลาสสิกที่เรียกว่า วิธีการเหล่านี้มักจะช่วยให้จับความหมายได้ดีขึ้น
วิธีการประเมินที่แตกต่างกัน การฝังตามบริบท และหม้อแปลงไฟฟ้าจะนำเสนอในบทความที่สองในหัวข้อต่อไป!
นี่คือรายการคำหลักที่ดึงมาจากบทความนี้โดยใช้วิธีใดวิธีหนึ่งจากสามวิธีที่กล่าวถึง:
“วิธีการ”, “คำหลัก”, “ข้อความสำคัญ”, “ข้อความ”, “คำหลักที่แยกออกมา”, “การประมวลผลภาษาธรรมชาติ”
การอ้างอิงทางบรรณานุกรม
- [1] ปรับปรุงการแยกคำหลักโดยอัตโนมัติด้วยความรู้ทางภาษาศาสตร์ที่มากขึ้น, Anette Hulth, 2003
- [2] การแยกคำหลักอัตโนมัติจากเอกสารส่วนบุคคล, Stuart Rose et. al, 2010
- [3] ยะเกะ! การแยกคำหลักจากเอกสารเดียวโดยใช้คุณสมบัติท้องถิ่นหลายรายการ, Ricardo Campos et. al, 2020
- [4] TextRank: การนำคำสั่งเข้าสู่ตำรา, Rada Mihalcea et. al, 2004
เริ่มทดลองใช้งานฟรี 14 วัน
 เริ่มการทดลองใช้ของคุณ
เริ่มการทดลองใช้ของคุณ