
ความถูกต้อง Dalle-2 & Midjourney และความหลงใหลในรูปภาพและงานศิลปะที่สร้างโดย AI
เผยแพร่แล้ว: 2022-08-04บทความนี้เป็นเรื่องเกี่ยวกับเทคโนโลยีเบื้องหลังแพลตฟอร์มอย่าง Dalle-2 และ Midjourney และเหตุใดผู้สร้าง Open AI จึงควรจ่ายเงินให้คุณ – ไม่เรียกเก็บเงินจากคุณ …
ผู้คนจำนวนมากขึ้นบนอินเทอร์เน็ตกำลังตั้งชื่อ Dalle-2 และ Open AI ว่าเป็นกลโกง เหตุผลก็คือตอนนี้ Dalle-2 กลายเป็นบริการที่สร้างรายได้ ซึ่งคุณจำเป็นต้องซื้อเครดิต หากคุณใช้แพลตฟอร์มเกินขีดจำกัดเบต้า
DALLE 2 เป็นเพียงหนึ่งในแพลตฟอร์มใหม่มากมายที่ให้คุณเข้าถึงเนื้อหาที่สร้างโดย AI และอ้างว่าคุณสามารถใช้เพื่อวัตถุประสงค์ทางการค้าได้ แพลตฟอร์มอื่นๆ ได้แก่ Midjourney, Jasper Art, Nightcafe, Starry AI และ Craiyon เราจะเน้นที่ Dalle 2 ในบล็อกโพสต์นี้ แต่เกือบจะเหมือนกันทุกประการ เมื่อพูดถึงความท้าทายและปัญหาทางกฎหมาย
การหลอกลวงเป็นคำกล่าวที่ค่อนข้างรุนแรงในความคิดของเรา แต่มีปัญหาที่ชัดเจนในการใช้ข้อมูลที่ผู้อื่นสร้างขึ้น (รูปภาพ วิดีโอ คำอธิบายประกอบ ผู้คนบนรูปภาพ เป็นต้น) จากนั้นจึงเริ่มขายคืนให้กับคนกลุ่มเดิม
หลายคนอาจมองข้ามปัญหานี้ไป เนื่องจากเรารู้สึกทึ่งในเทคโนโลยีใหม่ สิ่งที่เข้าใจได้โดยสิ้นเชิง
อย่างไรก็ตาม แม้ว่า DALL-E 2 จะเป็นเพียงเครื่องจดจำรูปแบบขั้นสูง แต่ผลลัพธ์ก็ไม่ได้เป็นกลาง และรูปแบบไม่ได้มาจากอากาศบริสุทธิ์
ข้อมูลเหล่านี้อิงจากข้อมูลจำนวนมาก ซึ่งมีคำถามทางกฎหมายหลายข้อที่ต้องถาม คำถามที่มีความสำคัญสำหรับคุณในฐานะผู้มีโอกาสเป็นผู้ใช้รูปภาพที่คุณสร้างขึ้น
 รูปภาพที่สร้างโดย DALLE-2
รูปภาพที่สร้างโดย DALLE-2
โมเดล AI เทียบกับมนุษย์ไม่ได้
คุณควรเริ่มต้นด้วยการอ่านบทความที่ยอดเยี่ยมนี้ใน Engadget ก่อนที่คุณจะเริ่มพิจารณาใช้รูปภาพ DALL-E 2 เพื่อวัตถุประสงค์ทางการค้า
ในบทความ Engadget พวกเขาชี้ให้เห็นอีกสิ่งที่สำคัญมาก กล่าวคือข้อเท็จจริงที่ว่า DALL-E 2 และ OpenAI ไม่ได้สละสิทธิ์ของตนเองในการทำการค้าภาพที่ผู้ใช้สร้างขึ้นโดยใช้ DALL-E โดยทั่วไปหมายความว่าคุณสามารถสร้างภาพที่พวกเขาจะขายในเชิงพาณิชย์ให้กับผู้อื่น
นี่แสดงให้เห็นว่าความตั้งใจนั้นแตกต่างอย่างมากจากการเปรียบเทียบที่บางครั้งใช้ ซึ่งโปรโมเตอร์ของ DALLE-2 จะเปรียบเทียบกับนักเรียนที่อ่านงานของนักเขียนที่เป็นที่ยอมรับ ในตัวอย่างนี้ นักเรียนอาจเรียนรู้รูปแบบและรูปแบบของผู้เขียน และต่อมาพบว่าสิ่งเหล่านี้ใช้ได้กับบริบทอื่นๆ และนำกลับมาใช้ใหม่ที่นั่น
อย่างไรก็ตาม เรื่องนี้ไม่เกี่ยวกับสมองของมนุษย์ที่ใช้หน่วยความจำที่สร้างสรรค์เพื่อสร้างผลงานสร้างสรรค์ใหม่ๆ นี่เป็นเรื่องเกี่ยวกับการนำเครื่องจดจำรูปแบบมาใช้ซ้ำ และในบางกรณี การสร้างข้อมูลการฝึกซ้ำในรูปภาพที่ใช้แล้วหรือขายในเชิงพาณิชย์ มันเป็นเพียงสองโลกที่แตกต่างกัน – ทั้งเชิงเปรียบเทียบและตามตัวอักษร
 ภาพถ่ายจริงจากโลกแห่งความจริง
ภาพถ่ายจริงจากโลกแห่งความจริง
คำมั่นสัญญาอันแท้จริงของ JumpStory
บทความนี้มีไว้สำหรับผู้ที่ต้องการทำความเข้าใจในระดับที่ลึกซึ้งยิ่งขึ้นว่าเทคโนโลยีการสร้างภาพ AI ใหม่นี้ทำงานอย่างไร แต่ก่อนที่เราจะเริ่มต้น เพียงไม่กี่คำว่าทำไม JumpStory จึงไม่สร้างเครื่องที่คล้ายกัน
แน่นอน เราถูกถามคำถามนั้นหลายครั้ง ไม่น้อยเมื่อพิจารณาว่าเราใช้ AI ในบริษัทของเราอยู่แล้ว และเนื่องจากเราสามารถเข้าถึงภาพจริงได้หลายล้านภาพ
อย่างไรก็ตาม นี่ไม่ใช่การสนทนาทางเทคโนโลยีสำหรับเรา แต่เป็นการสนทนาทางจริยธรรม การสนทนาที่ส่งผลให้เกิดคำมั่นสัญญาที่แท้จริงของเรา
โดยพื้นฐานแล้วเราต่อต้านอนาคตที่ภาพที่สร้างโดย AI กลายเป็นบรรทัดฐานมากกว่าที่จะเป็นข้อยกเว้น เรียกเราว่าหัวโบราณ แต่เราเชื่อว่าโลกที่แท้จริงนั้นสวยงาม
เราภูมิใจที่ภาพถ่ายและวิดีโอของเราแสดงถึงความเป็นมนุษย์ที่แท้จริงในรูปทรงและขนาดต่างๆ เราไม่ได้ต่อต้านการใช้ AI แต่เราไม่คิดว่าควรใช้เพื่อสร้างคนหรือความเป็นจริงปลอม
เทคโนโลยีเช่นสื่อสังเคราะห์และ DALL-E 2 อาจน่าสนใจบนพื้นผิว แต่ก็มีความเสี่ยงเช่นกัน พวกเขาเสี่ยงที่จะเบลอเส้นแบ่งระหว่างของจริงและของปลอม ซึ่งจะเป็นภัยคุกคามพื้นฐานต่อความไว้วางใจระหว่างมนุษย์
นี่คือเหตุผลที่ JumpStory ไม่ใช้ปัญญาประดิษฐ์เพื่อสร้างภาพปลอม แต่ใช้ AI แทนเพื่อระบุว่าภาพใดเป็นภาพต้นฉบับ ของแท้ และแน่นอนว่าถูกกฎหมายเพื่อใช้ในเชิงพาณิชย์
นี่คือภาพที่คุณพบเมื่อใช้บริการของเรา และเราได้ตั้งชื่อแนวทางของเราว่า 'Authentic Intelligence'

ทำความเข้าใจว่าภาพ AI ถูกสร้างขึ้นอย่างไร
เพียงพอเกี่ยวกับ JumpStory และประเด็นทางกฎหมายกับ DALL-E 2 สำหรับตอนนี้ ให้เราดูว่าภาพ AI ถูกสร้างขึ้นบนแพลตฟอร์มเช่น DALLE-2, Imagen, Crayion (เดิมคือ Dall-E Mini) อย่างไร Midjourney เป็นต้น … การใช้ DALLE-2 เป็นตัวอย่างที่ได้รับความนิยมมากที่สุดในปัจจุบัน
ในการเริ่มต้นกับ DALLE-2 สามารถทำงานประเภทต่างๆ ได้ แต่เราจะเน้นที่งานการสร้างภาพในบล็อกโพสต์นี้
วิธีการทำงานคือใส่ข้อความแจ้งลงในตัวเข้ารหัสข้อความ ตัวเข้ารหัสนี้ได้รับการฝึกฝนให้แมปพรอมต์กับพื้นที่การแสดง หลังจากนั้น แบบจำลองที่เรียกว่าก่อนหน้าจะแมปข้อความที่เข้ารหัสกับการเข้ารหัสรูปภาพที่เกี่ยวข้อง ซึ่งจะรวบรวมข้อมูลเชิงความหมายของข้อความแจ้งการเข้ารหัสข้อความ
(ถ้ากลายเป็นว่าเกินบรรยายไปบ้างแล้ว ก็ขออภัยอย่างสูง แต่จะยิ่งแย่ลงไปอีก)
ขั้นตอนสุดท้ายสำหรับตัวเข้ารหัสรูปภาพคือการสร้างรูปภาพที่แสดงข้อมูลเชิงความหมายที่ตัวเข้ารหัสได้รับ นี่คือพื้นฐานของเครื่องจักรอย่าง Open AI
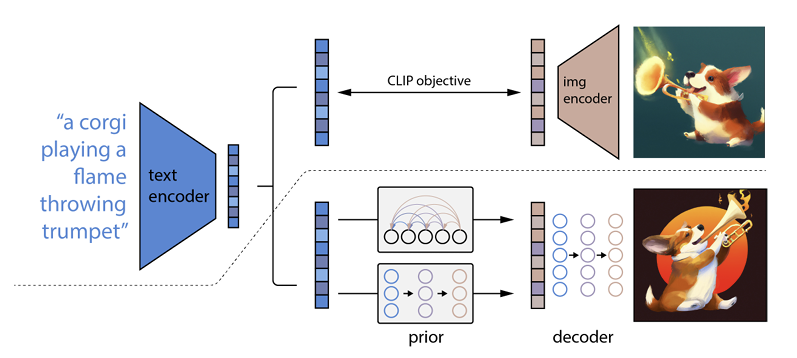
ความสัมพันธ์ระหว่างข้อความและภาพ
DALL-E 2 และเทคโนโลยีที่คล้ายกันมักถูกเรียกว่าเครื่องมือสร้างข้อความเป็นรูปภาพ เหตุผลก็คือความสามารถในการรับข้อความและส่งออกรูปภาพ
เพื่อยกตัวอย่าง นี่คือ "นักบินอวกาศขี่ม้าในสไตล์ของ Andy Warhol:

ที่มา: DALLE-2
สิ่งที่เกิดขึ้นที่นี่ขึ้นอยู่กับโมเดลของ Open AI ที่ชื่อว่า CLIP CLIP ย่อมาจาก “Contrastive Language-Image Pre-training” และเป็นแบบจำลองที่ซับซ้อนมากซึ่งได้รับการฝึกฝนจากรูปภาพและคำบรรยายภาพนับล้าน
สิ่งที่ CLIP ทำได้ดีเป็นพิเศษคือการทำความเข้าใจว่าข้อความหนึ่งๆ เกี่ยวข้องกับภาพหนึ่งๆ มากเพียงใด กุญแจสำคัญในที่นี้ไม่ใช่คำอธิบายภาพ แต่คำอธิบายภาพมีความเกี่ยวข้องกับภาพใดภาพหนึ่งอย่างไร
เทคโนโลยีประเภทนี้มีชื่อว่า 'ตรงกันข้าม' และสิ่งที่ CLIP สามารถทำได้คือการเรียนรู้ความหมายจากภาษาธรรมชาติ วิธีที่ CLIP ได้เรียนรู้สิ่งนี้คือผ่านกระบวนการ โดยมีวัตถุประสงค์เพื่อ (ตอนนี้กำลังอ้างอิงเอกสารทางเทคโนโลยี): “เพิ่มความคล้ายคลึงของโคไซน์ให้มากที่สุดพร้อมกันระหว่างคู่รูปภาพ/คำบรรยายที่เข้ารหัส Ncorrect และลดความคล้ายคลึงของโคไซน์ระหว่าง N 2 – N ภาพที่เข้ารหัสไม่ถูกต้อง /คู่คำบรรยาย”
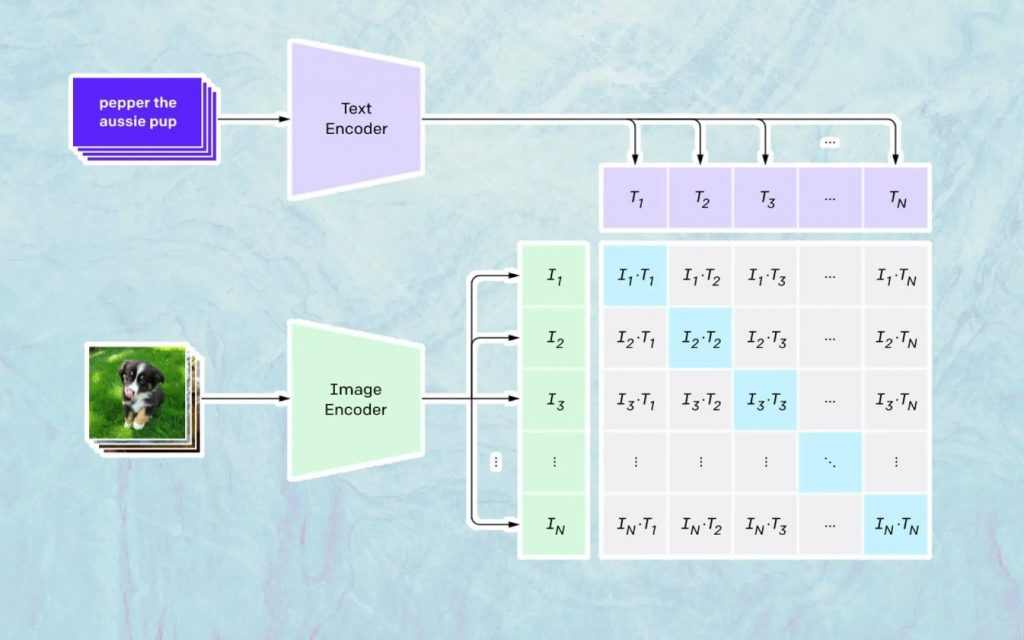
การสร้างภาพ
ตามที่อธิบายไว้ข้างต้น โมเดล CLIP จะเรียนรู้พื้นที่การแสดงซึ่งสามารถระบุได้ว่าการเข้ารหัสของรูปภาพและข้อความมีความเกี่ยวข้องกันอย่างไร
งานต่อไปคือการใช้พื้นที่นี้เพื่อสร้างภาพ เพื่อจุดประสงค์นี้ Open AI ได้พัฒนาอีกรุ่นหนึ่งชื่อว่า GLIDE ซึ่งสามารถใช้อินพุตจาก CLIP และ – โดยใช้แบบจำลองการแพร่กระจาย – ดำเนินการสร้างภาพ
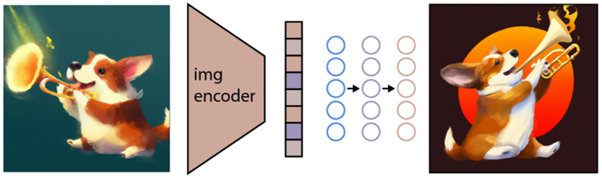
เพื่ออธิบายสั้น ๆ ว่ารูปแบบการแพร่กระจายคืออะไร โดยพื้นฐานแล้วมันคือแบบจำลองที่เรียนรู้การสร้างข้อมูลโดยการย้อนกลับกระบวนการทำให้เกิดสัญญาณรบกวนอย่างค่อยเป็นค่อยไป ขออภัยที่ตอนนี้กลายเป็นเรื่องทางเทคนิคมาก ดังนั้นเพื่ออ้างอิงคำอธิบายที่พบในเอกสาร Open AI:
“กระบวนการสร้างสัญญาณรบกวนถูกมองว่าเป็นห่วงโซ่ของ Markov ที่มีการกำหนดพารามิเตอร์ ซึ่งจะค่อยๆ เพิ่มสัญญาณรบกวนให้กับภาพเพื่อทำให้ภาพเสียหาย ในที่สุด (แบบไม่แสดงอาการ) ส่งผลให้เกิดสัญญาณรบกวนแบบเกาส์เซียนบริสุทธิ์ แบบจำลองการแพร่กระจายเรียนรู้ที่จะถอยหลังไปตามสายโซ่นี้ โดยค่อย ๆ ขจัดเสียงรบกวนตามขั้นตอนต่างๆ เพื่อย้อนกลับกระบวนการนี้”

หากคุณต้องการเจาะลึกเทคโนโลยี เราแนะนำให้อ่านบทความที่ยอดเยี่ยมนี้โดย Ryan O'Connor