
วิธีตอบคำถามข้อมูลที่ซับซ้อนด้วยข้อมูล Oncrawl นอก Oncrawl
เผยแพร่แล้ว: 2022-01-04ข้อดีอย่างหนึ่งของ Oncrawl สำหรับ SEO ระดับองค์กรคือการเข้าถึงข้อมูลดิบของคุณได้อย่างเต็มที่ ไม่ว่าคุณจะเชื่อมต่อข้อมูล SEO ของคุณกับ BI หรือเวิร์กโฟลว์วิทยาศาสตร์ข้อมูล ดำเนินการวิเคราะห์ของคุณเอง หรือทำงานตามแนวทางการรักษาความปลอดภัยของข้อมูลสำหรับองค์กรของคุณ SEO ดิบและข้อมูลการตรวจสอบเว็บไซต์สามารถตอบสนองวัตถุประสงค์ได้มากมาย
วันนี้เราจะมาดูวิธีใช้ข้อมูล Oncrawl เพื่อตอบคำถามข้อมูลที่ซับซ้อน
คำถามข้อมูลที่ซับซ้อนคืออะไร?
คำถามข้อมูลที่ซับซ้อนเป็นคำถามที่ไม่สามารถตอบได้ด้วยการค้นหาฐานข้อมูลอย่างง่าย แต่ต้องมีการประมวลผลข้อมูลเพื่อให้ได้คำตอบ
ต่อไปนี้คือตัวอย่างทั่วไปของคำถามเกี่ยวกับข้อมูลที่ "ซับซ้อน" ที่ SEO มักมี:
- การสร้างรายการลิงก์ทั้งหมดที่ชี้ไปยังหน้าที่เปลี่ยนเส้นทางไปยังหน้าอื่นที่มีสถานะ 404
- การสร้างรายการลิงก์ทั้งหมดและ anchor text ที่ชี้ไปยังหน้าต่างๆ ในการแบ่งกลุ่มตามเมตริกที่ไม่ใช่ URL
วิธีตอบคำถามข้อมูลที่ซับซ้อนใน Oncrawl
โครงสร้างข้อมูลของ Oncrawl สร้างขึ้นเพื่อให้ไซต์เกือบทั้งหมดค้นหาข้อมูลได้ในเวลาที่เกือบเรียลไทม์ สิ่งนี้เกี่ยวข้องกับการจัดเก็บข้อมูลประเภทต่างๆ ในชุดข้อมูลต่างๆ เพื่อให้แน่ใจว่าเวลาในการค้นหาจะถูกเก็บไว้ให้น้อยที่สุดในอินเทอร์เฟซ ตัวอย่างเช่น เราจัดเก็บข้อมูลทั้งหมดที่เชื่อมโยงกับ URL ในชุดข้อมูลเดียว: รหัสตอบกลับ จำนวนลิงก์ขาออก ประเภทของข้อมูลที่มีโครงสร้าง จำนวนคำ จำนวนการเข้าชมที่เกิดขึ้นเอง... และเราจัดเก็บข้อมูลทั้งหมดที่เกี่ยวข้องกับลิงก์ในชุดข้อมูลแยกต่างหาก: เป้าหมายของลิงค์, ที่มาของลิงค์, ข้อความสมอ…
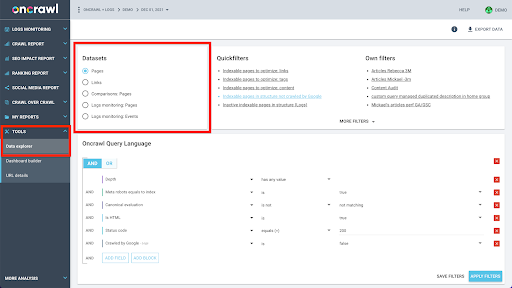
การเข้าร่วมชุดข้อมูลเหล่านี้มีความซับซ้อนในการคำนวณ และไม่รองรับอินเทอร์เฟซของแอปพลิเคชัน Oncrawl เสมอไป เมื่อคุณสนใจที่จะค้นหาบางสิ่งที่ต้องกรองชุดข้อมูลหนึ่งเพื่อค้นหาในอีกชุดหนึ่ง เราขอแนะนำให้จัดการข้อมูลดิบด้วยตัวคุณเอง
เนื่องจากข้อมูล Oncrawl ทั้งหมดพร้อมให้คุณใช้งาน จึงมีหลายวิธีในการรวมชุดข้อมูลและแสดงการสืบค้นที่ซับซ้อน
ในบทความนี้ เราจะพิจารณาหนึ่งในนั้นโดยใช้ Google Cloud และ BigQuery ซึ่งเหมาะสำหรับชุดข้อมูลขนาดใหญ่มาก เช่น ที่ลูกค้าของเราพบเมื่อตรวจสอบข้อมูลสำหรับไซต์ที่มีหน้าเว็บจำนวนมาก
สิ่งที่คุณต้องการ
ในการปฏิบัติตามวิธีการที่เราจะกล่าวถึงในบทความนี้ คุณจะต้องเข้าถึงเครื่องมือต่อไปนี้:
- รวบรวมข้อมูล
- API ของ Oncrawl พร้อม Big Data Export
- Google Cloud Storage
- BigQuery
- สคริปต์ Python สำหรับถ่ายโอนข้อมูลจาก Oncrawl ไปยัง BigQuery (เราจะสร้างสิ่งนี้ในบทความนี้)
ก่อนที่คุณจะเริ่มต้น คุณจะต้องมีสิทธิ์เข้าถึงรายงานการรวบรวมข้อมูลที่สมบูรณ์ใน Oncrawl
วิธีใช้ประโยชน์จากข้อมูล Oncrawl ใน Google BigQuery
แผนสำหรับบทความวันนี้มีดังนี้:
- อันดับแรก เราจะตรวจสอบให้แน่ใจว่าได้ตั้งค่า Google Cloud Storage ให้รับข้อมูลจาก Oncrawl แล้ว
- ต่อไป เราจะใช้สคริปต์ Python เพื่อเรียกใช้การส่งออก Big Data ของ Oncrawl เพื่อส่งออกข้อมูลจากการรวบรวมหนึ่งไปยังบัคเก็ต Google Cloud Storage เราจะส่งออกชุดข้อมูลสองชุด: หน้าและลิงก์
- เมื่อเสร็จแล้ว เราจะสร้างชุดข้อมูลใน Google BigQuery จากนั้นเราจะสร้างตารางจากการส่งออกทั้งสองรายการภายในชุดข้อมูล BigQuery
- สุดท้าย เราจะทำการทดลองกับการสืบค้นชุดข้อมูลแต่ละชุด จากนั้นจึงนำชุดข้อมูลทั้งสองมารวมกันเพื่อหาคำตอบสำหรับคำถามที่ซับซ้อน
การตั้งค่าภายใน Google Cloud เพื่อรับข้อมูล Oncrawl
หากต้องการเรียกใช้คู่มือนี้ในสภาพแวดล้อมแซนด์บ็อกซ์โดยเฉพาะ เราขอแนะนำให้คุณสร้างโปรเจ็กต์ Google Cloud ใหม่เพื่อแยกรายการนั้นออกจากโปรเจ็กต์ที่กำลังดำเนินอยู่
มาเริ่มกันที่หน้าแรกของ Google Cloud
จากหน้าแรกของ Google Cloud คุณสามารถเข้าถึงสิ่งต่างๆ มากมายนอกเหนือจาก Cloud Storage เราสนใจที่เก็บข้อมูล Cloud Storage ซึ่งมีอยู่ในระดับพื้นที่เก็บข้อมูลบนคลาวด์ของ Google Cloud Platform: 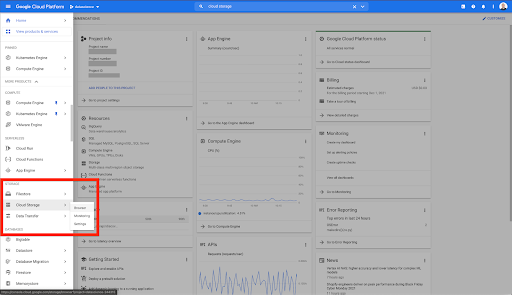
คุณยังสามารถเข้าถึงเบราว์เซอร์ Cloud Storage ได้โดยตรงที่ https://console.cloud.google.com/storage/browser
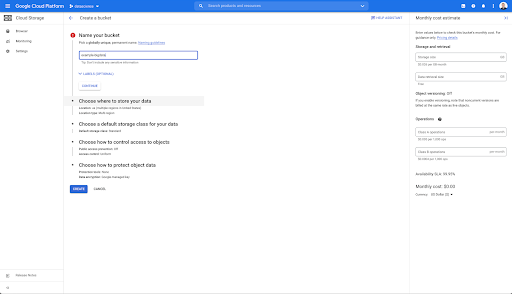
จากนั้น คุณต้องสร้างที่เก็บข้อมูล Cloud Storage และให้สิทธิ์ที่ถูกต้องเพื่อให้บัญชีบริการของ Oncrawl ได้รับอนุญาตให้เขียนลงในนั้น ภายใต้คำนำหน้าที่คุณเลือก
ที่เก็บข้อมูล Google Cloud Storage จะทำหน้าที่เป็นที่เก็บข้อมูลชั่วคราวเพื่อเก็บการส่งออก Big Data จาก Oncrawl ก่อนที่จะโหลดลงใน Google BigQuery
ในถังนี้ ฉันได้สร้างสองโฟลเดอร์ด้วย: "ลิงก์" และ "หน้า": 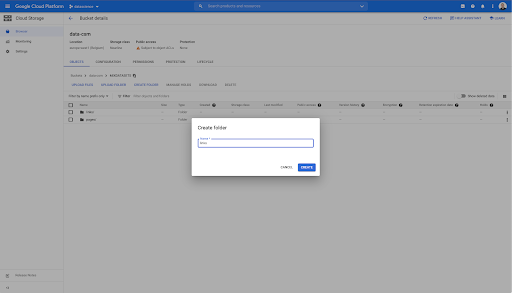
การส่งออกชุดข้อมูลจาก Oncrawl
ตอนนี้เราได้ตั้งค่าพื้นที่ที่เราต้องการบันทึกข้อมูลแล้ว เราต้องส่งออกจาก Oncrawl การส่งออกไปยังบัคเก็ต Google Cloud Storage ด้วย Oncrawl นั้นง่ายมาก เนื่องจากเราสามารถส่งออกข้อมูลในรูปแบบที่ถูกต้อง และบันทึกลงในบัคเก็ตโดยตรง ซึ่งจะช่วยขจัดขั้นตอนพิเศษใดๆ
การสร้างคีย์ API
การส่งออกข้อมูลจาก Oncrawl ในรูปแบบ Parquet สำหรับ BigQuery จะต้องใช้คีย์ API เพื่อดำเนินการกับ API โดยทางโปรแกรม ในนามของเจ้าของบัญชี Oncrawl แอปพลิเคชัน Oncrawl อนุญาตให้ผู้ใช้สร้างคีย์ API ที่มีชื่อเพื่อให้บัญชีของคุณมีการจัดการที่ดีและสะอาดอยู่เสมอ คีย์ API ยังเชื่อมโยงกับสิทธิ์ต่างๆ (ขอบเขต) เพื่อให้คุณสามารถจัดการคีย์และวัตถุประสงค์ได้
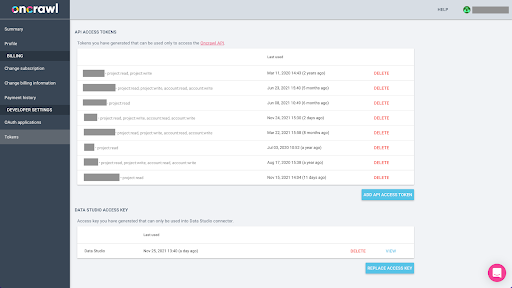
มาตั้งชื่อคีย์ใหม่ของเราว่า 'คีย์เซสชันความรู้' คุณลักษณะการส่งออกข้อมูลขนาดใหญ่ต้องมีสิทธิ์ในการเขียนในบัญชี เนื่องจากเรากำลังสร้างการส่งออกข้อมูล ในการดำเนินการนี้ เราจำเป็นต้องมีสิทธิ์การเข้าถึงแบบอ่านในโครงการ และการเข้าถึงแบบอ่านและเขียนในบัญชี
ตอนนี้ เรามีคีย์ API ใหม่ ซึ่งฉันจะคัดลอกไปที่คลิปบอร์ดของฉัน
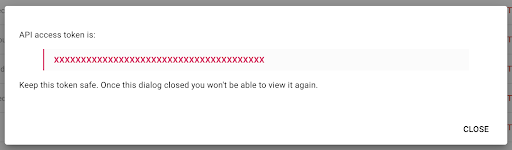
โปรดทราบว่า คุณสามารถ คัดลอกคีย์ได้เพียงครั้งเดียว ด้วยเหตุผลด้านความปลอดภัย หากคุณลืมคัดลอกคีย์ คุณจะต้องลบคีย์และสร้างใหม่
การสร้างสคริปต์ Python ของคุณ
ฉันสร้างสมุดบันทึก Google Colab สำหรับสิ่งนี้ แต่ฉันจะแบ่งปันรหัสด้านล่าง เพื่อให้คุณสามารถสร้างเครื่องมือของคุณเองหรือสมุดบันทึกของคุณเอง
1. จัดเก็บคีย์ API ของคุณในตัวแปรส่วนกลาง
ขั้นแรก เราบูตสแตรปสภาพแวดล้อมและเราประกาศคีย์ API ในตัวแปรส่วนกลางที่ชื่อว่า "Oncrawl Token" จากนั้น เราเตรียมตัวสำหรับการทดสอบที่เหลือ:
#@title เข้าถึง Oncrawl API
#@markdown ระบุโทเค็น API ของคุณด้านล่างเพื่อให้โน้ตบุ๊กนี้เข้าถึงข้อมูล Oncrawl ของคุณ:
# โทเค็นของคุณสำหรับ ONCRAWL API
ONCRAWL_TOKEN = "" #@param {ประเภท:"string"}
!pip ติดตั้งคุก
จาก IPython.display นำเข้า clear_output
clear_output()
print('โหลดทั้งหมดแล้ว') 
2. สร้างรายการแบบหล่นลงเพื่อเลือกโครงการ Oncrawl ที่คุณต้องการทำงานด้วย
จากนั้น ใช้คีย์นั้น เราต้องการเลือกโปรเจ็กต์ที่เราต้องการเล่นด้วยการรับรายชื่อโปรเจ็กต์ และสร้างวิดเจ็ตดรอปดาวน์จากรายการนั้น โดยการรันบล็อคโค้ดที่สอง ให้ทำตามขั้นตอนต่อไปนี้:
- เราจะเรียก Oncrawl API เพื่อรับรายการโครงการในบัญชีโดยใช้คีย์ API ที่เพิ่งส่ง
- เมื่อเราได้รายชื่อโครงการจากการตอบกลับ API แล้ว เราจะจัดรูปแบบเป็นรายการโดยใช้ชื่อโครงการและ URL เริ่มต้นของโครงการ
- เราเก็บ ID ของโปรเจ็กต์ที่ให้ไว้ในการตอบกลับ
- เราสร้างเมนูแบบเลื่อนลงและแสดงไว้ด้านล่างบล็อกโค้ด
#@title เลือกเว็บไซต์เพื่อวิเคราะห์โดยเลือกโครงการ Oncrawl ที่เกี่ยวข้อง
คำขอนำเข้า
นำเข้าคุก
นำเข้า ipywidgets เป็นวิดเจ็ต
นำเข้า json
# รับรายชื่อโครงการ
ตอบกลับ = Request.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
ขีด จำกัด = 1,000,
sort='name:asc'
),
ส่วนหัว={ 'การอนุญาต': 'ผู้ถือ '+ONCRAWL_TOKEN }
)
json_res = ตอบกลับ json()
#เตรียมดรอปดาวน์เพื่อให้ผู้ใช้เลือกโปรเจ็กต์
โครงการ = []
สำหรับรายการใน json_res['projects']:
project.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
เอาต์พุต = widgets.Output()
dropdown_purpose = วิดเจ็ต ดรอปดาวน์ (ตัวเลือก = โครงการ, คำอธิบาย = "โครงการ: ")
def dropdown_project_eventhandler (เปลี่ยน):
output.clear_output()
ด้วยผลลัพธ์:
แสดง(โครงการ)
dropdown_purpose.observe (dropdown_project_eventhandler ชื่อ = 'ค่า')
จอแสดงผล (dropdown_purpose) จากเมนูแบบเลื่อนลงที่สร้างขึ้น คุณสามารถดูรายการทั้งหมดของโครงการที่คีย์ API สามารถเข้าถึงได้ 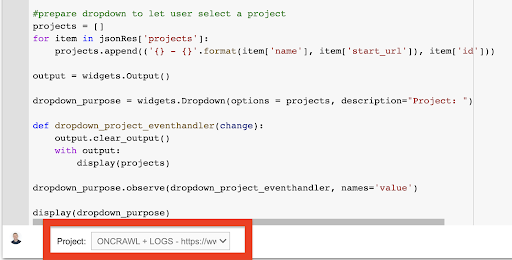
เพื่อจุดประสงค์ในการสาธิตวันนี้ เราใช้โปรเจ็กต์สาธิตที่อ้างอิงจากเว็บไซต์ Oncrawl
3. สร้างรายการแบบหล่นลงเพื่อเลือกโปรไฟล์การรวบรวมข้อมูลภายในโครงการที่คุณต้องการทำงานด้วย
ต่อไป เราจะตัดสินใจว่าจะใช้โปรไฟล์การรวบรวมข้อมูลใด เราต้องการเลือกโปรไฟล์การรวบรวมข้อมูลภายในโครงการนี้ โปรเจ็กต์สาธิตมีการกำหนดค่าการตระเวนที่แตกต่างกันมากมาย: 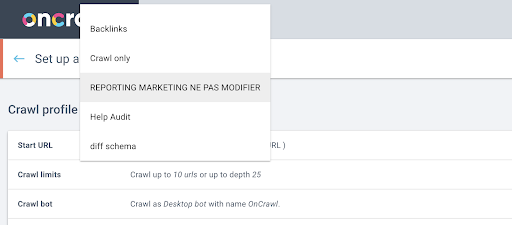
ในกรณีนี้ เรากำลังดูโครงการที่ทีม Oncrawl มักใช้สำหรับการทดสอบ ดังนั้นฉันจะเลือกโปรไฟล์การรวบรวมข้อมูลที่ทีมการตลาดใช้เพื่อตรวจสอบประสิทธิภาพของเว็บไซต์ Oncrawl เนื่องจากควรเป็นโปรไฟล์การรวบรวมข้อมูลที่เสถียรที่สุด จึงเป็นตัวเลือกที่ดีสำหรับการทดสอบในปัจจุบัน
ในการรับโปรไฟล์การรวบรวมข้อมูล เราจะใช้ Oncrawl API เพื่อขอการรวบรวมข้อมูลล่าสุดภายในทุกโปรไฟล์การรวบรวมข้อมูลในโปรเจ็กต์:
- เราเตรียมที่จะสืบค้น Oncrawl API สำหรับโครงการที่กำหนด
- เราจะขอการรวบรวมข้อมูลทั้งหมดที่ส่งคืนโดยเรียงลำดับจากมากไปน้อยตามวันที่ "สร้างเมื่อ"
คำขอนำเข้า
นำเข้า json
นำเข้า ipywidgets เป็นวิดเจ็ต
project_id = dropdown_purpose.value
# รับรายละเอียดโครงการ (รวมถึงการรวบรวมข้อมูลทั้งหมดในโครงการ)
โครงการ = request.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
ส่วนหัว={ 'การอนุญาต': 'ผู้ถือ '+ONCRAWL_TOKEN }).json()
# กลุ่มการรวบรวมข้อมูลตามโปรไฟล์การรวบรวมข้อมูล (ชื่อการรวบรวมข้อมูล)
crawls_by_config = {}
ลอง:
สำหรับการรวบรวมข้อมูลในโครงการ['crawls']:
ถ้า crawl['status'] ใน ["done"]:
ถ้า crawl['crawl_config']['name'] ไม่อยู่ใน crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : เท็จ}
ถ้า len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id']) รวบรวมข้อมูล
ถ้าการรวบรวมข้อมูล['สถานะ'] == "เก็บถาวร":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = จริง
ยกเว้นข้อยกเว้นเป็น e:
ยกข้อยกเว้น("ข้อผิดพลาด {} , {}".format(e โครงการ))
# สร้างรายการสำหรับดรอปดาวน์ select
รายการ = [("{} ({})".format(k, len(v['crawl_ids'])), k) สำหรับ k, v ใน crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs: ")
def dropdown_cc_eventhandler(เปลี่ยน):
output.clear_output()
ด้วยผลลัพธ์:
แสดง (crawls_by_config)
ถ้า len(crawls_by_config.values()) == 0:
print('ไม่พบการรวบรวมข้อมูลสดในโครงการนี้')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
แสดง (dropdown_crawl_configs)เมื่อรันโค้ดนี้ Oncrawl API จะตอบกลับเราด้วยรายการการตระเวนโดยคุณสมบัติ "created at" จากมากไปน้อย
จากนั้น เนื่องจากเราต้องการเน้นเฉพาะการรวบรวมข้อมูลที่เสร็จสิ้นแล้วเท่านั้น เราจะดูรายการการรวบรวมข้อมูล สำหรับการรวบรวมข้อมูลทุกรายการที่มีสถานะ "เสร็จสิ้น" เราจะบันทึกชื่อของโปรไฟล์การรวบรวมข้อมูลและเราจะจัดเก็บรหัสการรวบรวมข้อมูล
เราจะเก็บข้อมูลการรวบรวมข้อมูลไว้มากที่สุด 1 รายการตามโปรไฟล์การรวบรวมข้อมูล เพื่อไม่ให้เราเปิดเผยการรวบรวมข้อมูลมากเกินไป
ผลลัพธ์คือเมนูดรอปดาวน์ใหม่นี้ซึ่งสร้างจากรายการโปรไฟล์การตระเวนในโครงการ เราจะเลือกอันที่เราต้องการ การดำเนินการนี้จะใช้เวลารวบรวมข้อมูลล่าสุดที่ดำเนินการโดยทีมการตลาด: 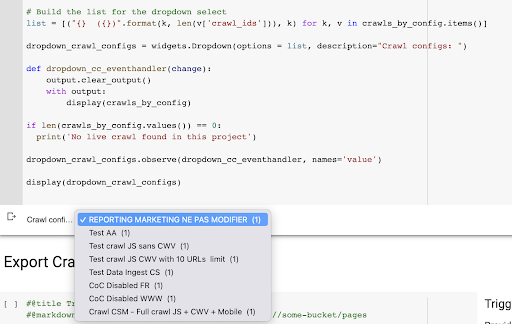
4. ระบุการรวบรวมข้อมูลครั้งล่าสุดด้วยโปรไฟล์ที่เราต้องการใช้
เรามีรหัสการรวบรวมข้อมูลที่เชื่อมโยงกับการรวบรวมข้อมูลครั้งล่าสุดในโปรไฟล์ที่เลือกแล้ว มันถูกซ่อนอยู่ในพจนานุกรมวัตถุ “crawl_by_config” 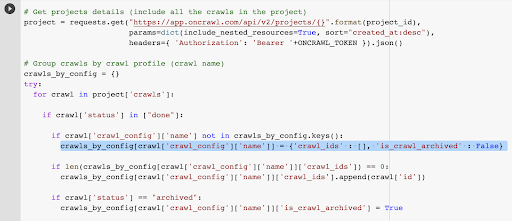
คุณสามารถตรวจสอบได้อย่างง่ายดายในอินเทอร์เฟซ: ค้นหาการรวบรวมข้อมูลที่เสร็จสิ้นล่าสุดในการวิเคราะห์โปรไฟล์นี้ 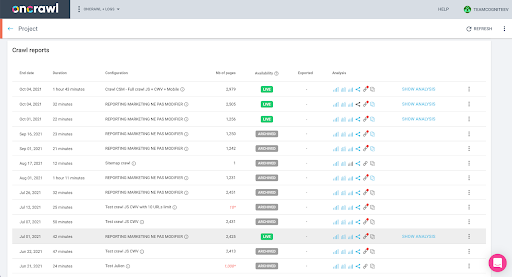
หากเราคลิกเพื่อดูการวิเคราะห์ เราจะเห็นว่ารหัสการรวบรวมข้อมูลลงท้ายด้วย E617 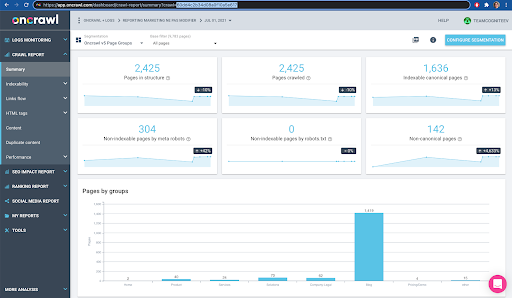
มาจดบันทึกรหัสการรวบรวมข้อมูลเพื่อการสาธิตในวันนี้
แน่นอน ถ้าคุณรู้ว่าคุณกำลังทำอะไรอยู่ คุณสามารถข้ามขั้นตอนที่เราเพิ่งพูดถึงเพื่อเรียก Oncrawl API เพื่อรับรายการโครงการและรายการการรวบรวมข้อมูลตามโปรไฟล์การรวบรวมข้อมูล: คุณมี ID การรวบรวมข้อมูลจาก อินเทอร์เฟซ และ ID นี้คือทั้งหมดที่คุณต้องการเพื่อเรียกใช้การส่งออก
ขั้นตอนที่เราได้ดำเนินการจนถึงตอนนี้เป็นเพียงการทำให้กระบวนการรับการรวบรวมข้อมูลล่าสุดของโปรไฟล์การรวบรวมข้อมูลที่กำหนดของโปรเจ็กต์ที่กำหนดนั้นง่ายขึ้น โดยพิจารณาจากสิ่งที่คีย์ API เข้าถึงได้ ซึ่งจะมีประโยชน์หากคุณนำเสนอโซลูชันนี้แก่ผู้ใช้รายอื่น หรือหากคุณต้องการทำให้เป็นอัตโนมัติ
5. ส่งออกผลการรวบรวมข้อมูล
ตอนนี้เราจะดูคำสั่งส่งออก:
#@title ทริกเกอร์การส่งออกข้อมูลขนาดใหญ่
#@markdown ระบุ GCS Bucket และคำนำหน้า gs://some-bucket/pages
# ถัง GCS ของคุณ
gcs_bucket = #@param {ประเภท:"string"}
gcs_prefix = #@param {ประเภท:"string"}
# รับรหัสการรวบรวมข้อมูลล่าสุดจากโครงการที่กำหนด / โปรไฟล์การรวบรวมข้อมูล
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# เพย์โหลดเทมเพลตสำหรับแบบสอบถามการส่งออกข้อมูล
น้ำหนักบรรทุก = {
"data_export": {
"data_type": 'หน้า',
"resource_id": last_crawl_id,
"output_format": 'ปาร์เก้',
"เป้าหมาย": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# ทริกเกอร์การส่งออก
ส่งออก = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# แสดงการตอบสนอง API
จอแสดงผล (ส่งออก)
# เก็บรหัสส่งออกสำหรับการใช้งานในอนาคต
export_id = ส่งออก['data_export']['id']เราต้องการส่งออกไปยังที่เก็บข้อมูล Cloud Storage ที่เราตั้งค่าไว้ก่อนหน้านี้
ภายในนั้นเราจะส่งออกหน้าสำหรับรหัสการรวบรวมข้อมูลล่าสุด:
- รหัสการรวบรวมข้อมูลล่าสุดได้มาจากรายการรหัสการรวบรวมข้อมูล ซึ่งจัดเก็บไว้ที่ใดที่หนึ่งในพจนานุกรม "crawls_by_config" ซึ่งสร้างขึ้นในขั้นตอนที่ 3
- เราต้องการเลือกรายการที่เกี่ยวข้องกับเมนูแบบเลื่อนลงในขั้นตอนที่ 4 ดังนั้นเราจึงใช้แอตทริบิวต์ค่าของเมนูแบบเลื่อนลง
- จากนั้น เราแยกแอตทริบิวต์ crawl_ID นี่คือรายการ เราจะเก็บ 50 อันดับแรกไว้ในรายการ เราจำเป็นต้องทำเช่นนี้เพราะในขั้นตอนที่ 2 อย่างที่คุณจำได้ เมื่อเราสร้างพจนานุกรม crawls_by_config เราเก็บรหัสการรวบรวมข้อมูลเพียงหนึ่ง ID ต่อชื่อการกำหนดค่าเท่านั้น
ฉันตั้งค่าช่องใส่เพื่อให้ง่ายต่อการจัดเตรียมที่เก็บข้อมูลและคำนำหน้าของ Google Cloud Storage หรือโฟลเดอร์ที่เราต้องการส่งการส่งออก 
สำหรับวัตถุประสงค์ของการสาธิต วันนี้ เราจะเขียนไปยังโฟลเดอร์ "mixed dataset" ในโฟลเดอร์ใดโฟลเดอร์หนึ่งที่ฉันตั้งค่าไว้แล้ว เมื่อเราตั้งค่าที่เก็บข้อมูลใน Google Cloud Storage คุณจะจำได้ว่าฉันเตรียมโฟลเดอร์สำหรับการส่งออก "ลิงก์" และสำหรับการส่งออก "หน้า"
สำหรับการส่งออกครั้งแรก เราจะต้องการส่งออกหน้าไปยังโฟลเดอร์ "หน้า" สำหรับรหัสการรวบรวมข้อมูลล่าสุดโดยใช้รูปแบบไฟล์ Parquet 
ในผลลัพธ์ด้านล่าง คุณจะเห็นเพย์โหลดที่จะส่งไปยังปลายทางการส่งออกข้อมูล ซึ่งเป็นปลายทางเพื่อขอส่งออก Big Data โดยใช้คีย์ API:
# เพย์โหลดเทมเพลตสำหรับแบบสอบถามการส่งออกข้อมูล
น้ำหนักบรรทุก = {
"data_export": {
"data_type": 'หน้า',
"resource_id": last_crawl_id,
"output_format": 'ปาร์เก้',
"เป้าหมาย": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
ซึ่งมีองค์ประกอบหลายอย่าง รวมถึงประเภทของชุดข้อมูลที่คุณต้องการส่งออก คุณส่งออกชุดข้อมูลของเพจ ชุดข้อมูลลิงก์ ชุดข้อมูลคลัสเตอร์ หรือชุดข้อมูลที่มีโครงสร้างได้ หากคุณไม่ทราบว่าสามารถทำอะไรได้บ้าง คุณสามารถป้อนข้อผิดพลาดที่นี่ และเมื่อคุณเรียกใช้ API คุณจะได้รับข้อความแจ้งว่าตัวเลือกสำหรับประเภทข้อมูลจะต้องเป็นหน้าหรือลิงก์หรือคลัสเตอร์หรือข้อมูลที่มีโครงสร้าง ข้อความมีลักษณะดังนี้:

{'fields': [{'message': 'ไม่ใช่ตัวเลือกที่ถูกต้อง ต้องเป็นหนึ่งใน "เพจ" "ลิงก์" "คลัสเตอร์" "structured_data".',
'ชื่อ': 'data_type',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
สำหรับวัตถุประสงค์ของการทดสอบในวันนี้ เราจะส่งออกชุดข้อมูลหน้าและชุดข้อมูลลิงก์ในการส่งออกแยกกัน
เริ่มจากชุดข้อมูลของเพจกันก่อน เมื่อฉันเรียกใช้บล็อคโค้ดนี้ ฉันได้พิมพ์ผลลัพธ์ของการเรียก API ซึ่งมีลักษณะดังนี้:
{'data_export': {'data_type': 'หน้า',
'export_failure_reason': ไม่มี
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'ปาร์เก้',
'output_format_parameters': ไม่มี
'output_row_count': ไม่มี
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'สถานะ': 'ร้องขอ',
'เป้าหมาย': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
สิ่งนี้ทำให้ฉันเห็นว่ามีการร้องขอการส่งออก
หากเราต้องการตรวจสอบสถานะการส่งออกก็ง่ายมาก การใช้ ID การส่งออกที่เราบันทึกไว้ที่ส่วนท้ายของบล็อคโค้ดนี้ เราสามารถขอสถานะของการส่งออกได้ตลอดเวลาด้วยการเรียก API ต่อไปนี้:
# สถานะของการส่งออก
export_status =การร้องขอ.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json ()
แสดง(export_status)
สิ่งนี้จะระบุสถานะเป็นส่วนหนึ่งของวัตถุ JSON ที่ส่งคืน:
{'data_export': {'data_type': 'หน้า',
'export_failure_reason': ไม่มี
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'ปาร์เก้',
'output_format_parameters': ไม่มี
'output_row_count': ไม่มี
'output_size_in_bytes': ไม่มี
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'สถานะ': 'กำลังส่งออก',
'เป้าหมาย': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} เมื่อการส่งออกเสร็จสมบูรณ์ ( 'status': 'DONE' ) เราสามารถกลับไปที่ Google Cloud Storage
ถ้าเราดูในบัคเก็ตของเราแล้วไปที่โฟลเดอร์ "links" ก็ยังไม่มีอะไรที่นี่เนื่องจากเราส่งออกเพจ 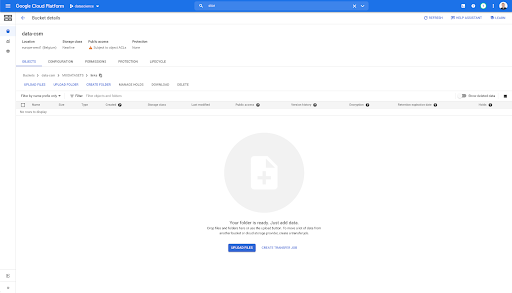
อย่างไรก็ตาม เมื่อเราดูในโฟลเดอร์ "หน้า" เราจะเห็นว่าการส่งออกสำเร็จ เรามีไฟล์ปาร์เก้: 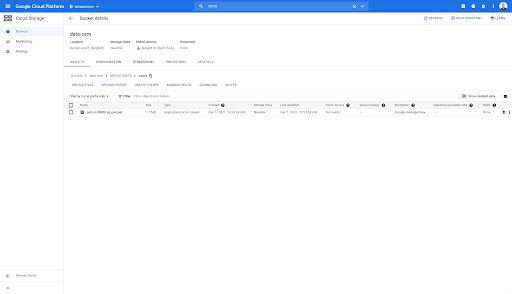
ในขั้นตอนนี้ ชุดข้อมูลของเพจพร้อมสำหรับการนำเข้าใน BigQuery แต่ก่อนอื่น เราจะทำซ้ำขั้นตอนด้านบนเพื่อรับไฟล์ Parquet สำหรับลิงก์:
- อย่าลืมตั้งค่าคำนำหน้าลิงก์
- เลือกประเภทข้อมูล "ลิงค์"
- เรียกใช้บล็อกโค้ดนี้อีกครั้งเพื่อขอการส่งออกครั้งที่สอง

ไฟล์ Parquet จะอยู่ในโฟลเดอร์ "links"
การสร้างชุดข้อมูล BigQuery
ในขณะที่การส่งออกกำลังทำงาน เราสามารถก้าวไปข้างหน้าและเริ่มสร้างชุดข้อมูลใน BigQuery และนำเข้าไฟล์ Parquet ลงในตารางแยกกัน แล้วเราจะมารวมโต๊ะกัน
สิ่งที่เราอยากทำตอนนี้คือเล่นกับ Google Big Query ซึ่งเป็นส่วนหนึ่งของ Google Cloud Platform คุณสามารถใช้แถบค้นหาที่ด้านบนของหน้าจอ หรือไปที่ https://console.cloud.google.com/bigquery โดยตรง
การสร้างชุดข้อมูลสำหรับงานของคุณ
เราจะต้องสร้างชุดข้อมูลภายใน Google BigQuery: 
คุณจะต้องระบุชื่อชุดข้อมูล และเลือกตำแหน่งที่จะจัดเก็บข้อมูล นี่เป็นสิ่งสำคัญเพราะจะเป็นเงื่อนไขว่าข้อมูลจะถูกประมวลผลที่ใดและไม่สามารถเปลี่ยนแปลงได้ ซึ่งอาจมีผลกระทบหากข้อมูลของคุณมีข้อมูลที่ครอบคลุมโดย GDPR หรือกฎหมายความเป็นส่วนตัวอื่นๆ 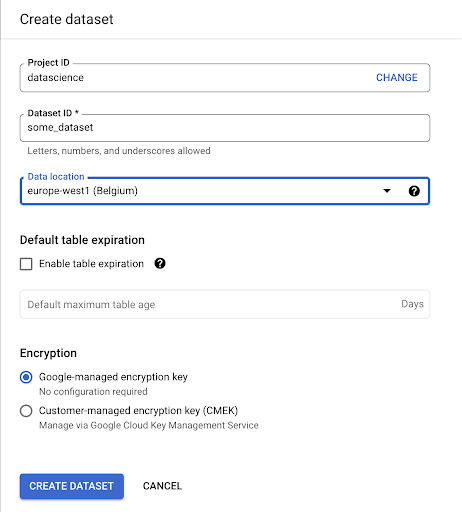
ชุดข้อมูลนี้ว่างเปล่าในตอนแรก เมื่อคุณเปิดขึ้นมา คุณจะสามารถสร้างตาราง แชร์ชุดข้อมูล คัดลอก ลบ และอื่นๆ
การสร้างตารางสำหรับข้อมูลของคุณ
เราจะสร้างตารางในชุดข้อมูลนี้ 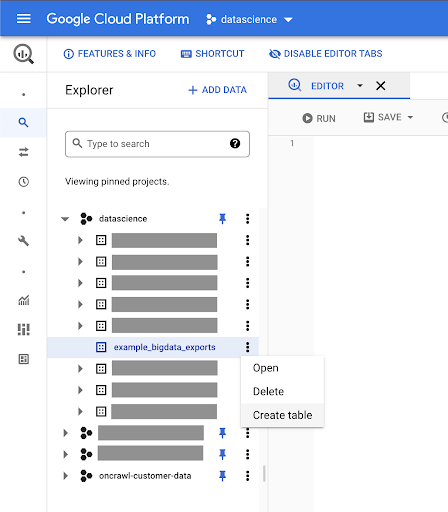
คุณสามารถสร้างตารางเปล่าแล้วจัดเตรียมสคีมา สคีมาคือคำจำกัดความของคอลัมน์ในตาราง คุณสามารถกำหนดของคุณเองหรือคุณสามารถเรียกดู Google Cloud Storage เพื่อเลือกสคีมาจากไฟล์
เราจะใช้ตัวเลือกสุดท้ายนี้ เราจะไปที่ถังของเรา จากนั้นไปที่โฟลเดอร์ "หน้า" มาเลือกไฟล์เพจกัน มีเพียงไฟล์เดียว เราจึงสามารถเลือกได้เพียงไฟล์เดียว แต่ถ้าการส่งออกสร้างไฟล์หลายไฟล์ เราก็สามารถเลือกได้ทั้งหมด 
เมื่อเราเลือกไฟล์ มันจะตรวจพบโดยอัตโนมัติว่าอยู่ในรูปแบบไฟล์ปาร์เก้ เราต้องการสร้างตารางชื่อ "หน้า" และสคีมาจะถูกกำหนดโดยไฟล์ต้นฉบับ 
เมื่อเราโหลดไฟล์ Parquet ไฟล์จะฝังสคีมา กล่าวอีกนัยหนึ่ง คำจำกัดความของคอลัมน์ของตารางที่เรากำลังสร้างจะอนุมานจากสคีมาที่มีอยู่แล้วภายในไฟล์ Parquet นี่คือส่วนหนึ่งของเวทมนตร์ที่เกิดขึ้นจริง
ไปข้างหน้าและสร้างตารางจากไฟล์ Parquet กัน 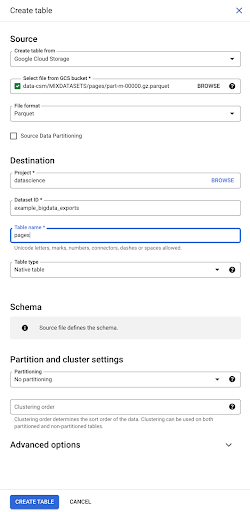
ในแถบด้านข้างทางซ้ายมือ เราจะเห็นได้ว่าตารางปรากฏขึ้นในชุดข้อมูลของเรา ซึ่งเป็นสิ่งที่เราต้องการอย่างแท้จริง:
ดังนั้น ตอนนี้ เรามีสคีมาของตารางเพจที่มีฟิลด์ทั้งหมดที่ได้รับการอนุมานโดยอัตโนมัติจากไฟล์ Parquet เรามีอันดับ ความลึกของหน้า หากหน้ามีการเปลี่ยนเส้นทางเป็นต้น: 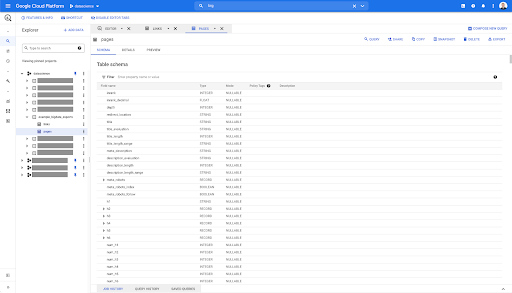
ฟิลด์เหล่านี้ส่วนใหญ่จะเหมือนกับฟิลด์ที่มีอยู่ใน Data Studio ผ่านตัวเชื่อมต่อ Oncrawl Data Studio และเหมือนกับฟิลด์ที่คุณเห็นใน Data Explorer ในอินเทอร์เฟซ Oncrawl 
อย่างไรก็ตาม มีความแตกต่างบางประการ เมื่อเราเล่นกับการส่งออกข้อมูลดิบขนาดใหญ่ คุณมีข้อมูลดิบทั้งหมด
- ใน Data Studio บางฟิลด์มีการเปลี่ยนชื่อ บางฟิลด์ถูกซ่อน และบางฟิลด์ถูกเพิ่ม เช่น สถานะ
- ใน Data Explorer บางฟิลด์คือสิ่งที่เราเรียกว่า "ฟิลด์เสมือน" ซึ่งหมายความว่าอาจเป็นทางลัดประเภทหนึ่งไปยังฟิลด์พื้นฐาน ฟิลด์เสมือนเหล่านี้ที่มีอยู่ใน Data Explorer จะไม่อยู่ในสคีมา แต่สามารถสร้างใหม่ได้ขึ้นอยู่กับสิ่งที่มีอยู่ในไฟล์ Parquet
ตอนนี้เรามาปิดตารางนี้แล้วทำอีกครั้งสำหรับลิงก์
สำหรับตารางลิงก์ สคีมามีขนาดเล็กกว่าเล็กน้อย 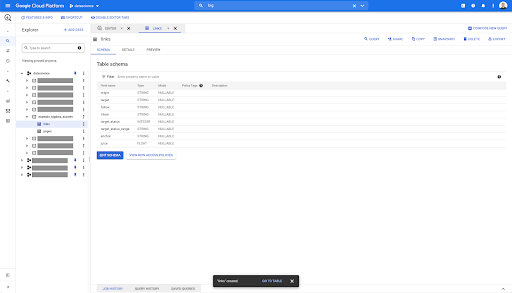
มีเฉพาะฟิลด์ต่อไปนี้:
- ที่มาของลิงค์
- เป้าหมายของลิงค์,
- ทรัพย์สินดังต่อไปนี้
- ทรัพย์สินภายใน,
- สถานะเป้าหมาย
- ช่วงของสถานะเป้าหมาย
- ข้อความสมอและ
- น้ำผลไม้หรือทุนที่ซื้อโดยลิงค์
ในตารางใดๆ ใน BigQuery เมื่อคุณคลิกที่แท็บแสดงตัวอย่าง คุณจะมีการแสดงตัวอย่างตารางโดยไม่ต้องสืบค้นฐานข้อมูล: 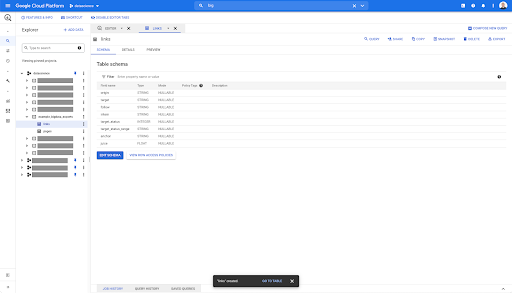
ข้อมูลนี้จะช่วยให้คุณเห็นได้อย่างรวดเร็วว่ามีอะไรอยู่ในนั้นบ้าง ในการแสดงตัวอย่างสำหรับตารางลิงก์ด้านบน คุณมีการแสดงตัวอย่างทุกแถวและทุกคอลัมน์
ในชุดข้อมูล Oncrawl บางชุด คุณอาจเห็นบางแถวที่ครอบคลุมหลายแถว ฉันไม่มีตัวอย่างสำหรับคุณ แต่ถ้าเป็นกรณีนี้ อาจเป็นเพราะบางฟิลด์มีรายการค่าต่างๆ ตัวอย่างเช่น ในรายการส่วนหัว h2 บนหน้า แถวเดียวจะครอบคลุมหลายแถวใน Big Query เราจะดูในภายหลังถ้าเราเห็นตัวอย่าง
กำลังสร้างคำถามของคุณ
หากคุณไม่เคยสร้างการสืบค้นข้อมูลใน BigQuery มาก่อน ตอนนี้เป็นเวลาที่คุณควรลองใช้เพื่อสร้างความคุ้นเคยกับวิธีการทำงาน BigQuery ใช้ SQL เพื่อค้นหาข้อมูล
แบบสอบถามทำงานอย่างไร
ตัวอย่างเช่น ลองดูที่ URL ทั้งหมดและอันดับ...
SELECT url, ลำดับชั้น ...
จากชุดข้อมูลเพจ...
SELECT url อยู่ในอันดับจาก `datascience-oncrawl.example_bigdata_exports.pages` ...
โดยที่รหัสสถานะของเพจคือ 200…
SELECT url, inrank จาก `datascience-oncrawl.example_bigdata_exports.pages` โดยที่ status_code = 200 ...
และเก็บเพียง 10 ผลลัพธ์แรก:
SELECT url, inrank จาก `datascience-oncrawl.example_bigdata_exports.pages` โดยที่ status_code = 200 LIMIT 10
เมื่อเราเรียกใช้แบบสอบถามนี้ เราจะได้รับ 10 แถวแรกของรายการหน้าที่รหัสสถานะคือ 200
คุณสมบัติเหล่านี้สามารถแก้ไขได้ ฉ ฉันต้องการ 1,000 แถวแทนที่จะเป็น 10 ฉันสามารถตั้งค่า 1,000 แถว:
SELECT url, inrank จาก `datascience-oncrawl.example_bigdata_exports.pages` โดยที่ status_code = 200 LIMIT 1000
ถ้าฉันต้องการจัดเรียง ฉันสามารถทำได้โดยใช้ "order-by" ซึ่งจะให้แถวทั้งหมดที่ฉันเรียงโดยเรียงจากมากไปน้อย
SELECT url, inrank จาก `datascience-oncrawl.example_bigdata_exports.links` เรียงลำดับตามอันดับ DESC LIMIT 1000
นี่เป็นคำถามแรกของฉัน ฉันสามารถบันทึกได้หากต้องการ ซึ่งจะทำให้ฉันสามารถนำแบบสอบถามนี้มาใช้ซ้ำได้ในภายหลังหากต้องการ: 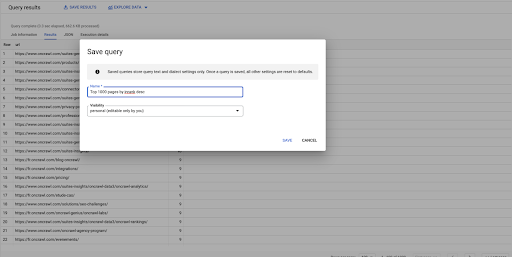
การใช้คำถามเพื่อตอบคำถามง่ายๆ: การแสดงรายการลิงก์ภายในทั้งหมดไปยังหน้าที่มีสถานะ 301
ตอนนี้เรารู้วิธีเขียนแบบสอบถามแล้ว ให้กลับไปที่ปัญหาเดิมของเรา
เราต้องการตอบคำถามเกี่ยวกับข้อมูลไม่ว่าจะง่ายหรือซับซ้อน เริ่มต้นด้วยคำถามง่ายๆ เช่น "ลิงก์ภายในทั้งหมดที่ชี้ไปยังหน้าที่มีสถานะ 301 (เปลี่ยนเส้นทาง) คืออะไร และฉันจะหาได้จากที่ไหน"
การสร้างแบบสอบถามใหม่
เราจะเริ่มต้นด้วยการสำรวจวิธีการทำงาน
ฉันต้องการคอลัมน์สำหรับองค์ประกอบต่อไปนี้จากฐานข้อมูล "ลิงก์":
- ต้นทาง
- เป้า
- รหัสสถานะเป้าหมาย
เลือกต้นทาง เป้าหมาย target_status จาก `datascience-oncrawl.example_bigdata_exports.links`
ฉันต้องการจำกัดลิงก์เหล่านี้ไว้เป็นลิงก์ภายในเท่านั้น แต่สมมติว่าฉันจำชื่อคอลัมน์หรือค่าที่ระบุว่าลิงก์นั้นเป็นลิงก์ภายในหรือภายนอกไม่ได้ ฉันสามารถไปที่สคีมาเพื่อค้นหาและใช้การแสดงตัวอย่างเพื่อดูค่า: 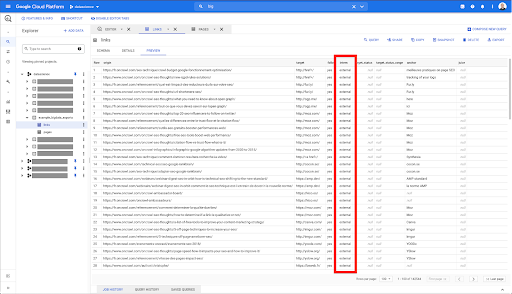
สิ่งนี้บอกฉันว่าคอลัมน์ชื่อ "ฝึกงาน" และช่วงค่าที่เป็นไปได้คือ "ภายนอก" หรือ "ภายใน"
ในข้อความค้นหาของฉัน ฉันต้องการระบุว่า "ฝึกงานอยู่ที่ไหน" และจำกัดผลลัพธ์ไว้ที่ 100 คนแรกในตอนนี้:
เลือกต้นทาง เป้าหมาย target_status จาก `datascience-oncrawl.example_bigdata_exports.links` โดยที่ผู้ฝึกงาน LIKE 'ภายใน' LIMIT 100
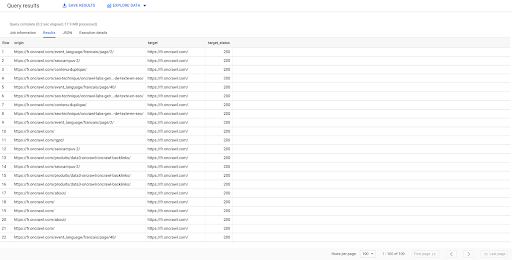
ผลลัพธ์ด้านบนแสดงรายการลิงก์ที่มีสถานะเป้าหมาย เรามีลิงก์ภายในเท่านั้น และเรามี 100 ลิงก์ตามที่ระบุในข้อความค้นหา
หากเราต้องการมีเพียงลิงก์ภายในที่ไปยังจุดนั้นไปยังหน้าที่เปลี่ยนเส้นทาง เราสามารถพูดได้ว่า 'ตำแหน่งผู้ฝึกงานภายในและสถานะเป้าหมายเท่ากับ 301':
เลือกต้นทาง เป้าหมาย target_status จาก `datascience-oncrawl.example_bigdata_exports.links` โดยที่ผู้ฝึกงาน LIKE 'ภายใน' และ target_status = 301
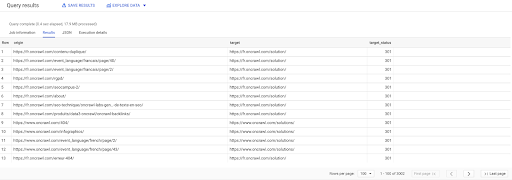
หากเราไม่ทราบว่ามีกี่ลิงก์ เราสามารถเรียกใช้การค้นหาใหม่นี้ และเราจะเห็นว่ามีลิงก์ภายใน 3002 ลิงก์ที่มีสถานะเป้าหมาย 301
เข้าร่วมตาราง: ค้นหารหัสสถานะสุดท้ายของลิงก์ที่ชี้ไปยังหน้าที่เปลี่ยนเส้นทาง
บนเว็บไซต์ คุณมักจะมีลิงก์ไปยังหน้าที่เปลี่ยนเส้นทาง เราต้องการทราบรหัสสถานะของหน้าที่เปลี่ยนเส้นทางไป (หรือ URL เป้าหมายสุดท้าย)
ในชุดข้อมูลเดียว คุณมีข้อมูลเกี่ยวกับลิงก์: หน้าต้นทาง หน้าเป้าหมาย และรหัสสถานะ (เช่น 301) แต่ไม่ใช่ URL ที่หน้าเปลี่ยนเส้นทางชี้ไป และในอีกทางหนึ่ง คุณมีข้อมูลเกี่ยวกับการเปลี่ยนเส้นทางและเป้าหมายสุดท้าย แต่ไม่ใช่หน้าเดิมที่พบลิงก์ไปยังพวกเขา
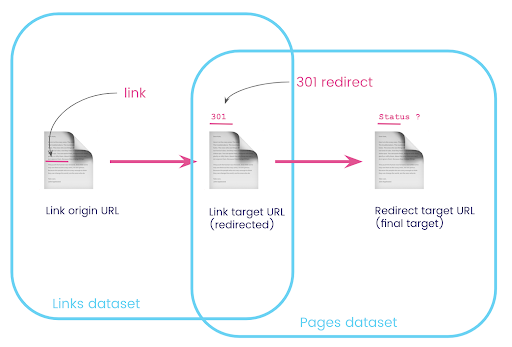
มาทำลายสิ่งนี้กันเถอะ:
อันดับแรก เราต้องการลิงก์ไปยังการเปลี่ยนเส้นทาง ลองเขียนสิ่งนี้ลงไป พวกเราต้องการ:
- ที่มา
- เป้าหมาย. เป้าหมายต้องมีรหัสสถานะ 301
- เป้าหมายสุดท้ายของการเปลี่ยนเส้นทาง
กล่าวอีกนัยหนึ่ง ในชุดข้อมูลลิงก์ เราต้องการ:
- ที่มาของลิงค์
- เป้าหมายของลิงค์
ในชุดข้อมูลเพจ เราต้องการ:
- เป้าหมายทั้งหมดที่เปลี่ยนเส้นทาง
- เป้าหมายสุดท้ายของการเปลี่ยนเส้นทาง
สิ่งนี้จะทำให้เรามีคำถามเช่น:
SELECT url, final_redirect_location, final_redirect_status จาก `datascience-oncrawl.example_bigdata_exports.pages` AS หน้าโดยที่ status_code = 301 หรือ status_code = 302
นี่ควรให้ส่วนแรกของสมการมา
ตอนนี้ ฉันต้องการลิงก์ทั้งหมดที่ลิงก์ไปยังหน้าซึ่งเป็นผลลัพธ์ของการสืบค้นข้อมูลที่ฉันเพิ่งสร้างขึ้น โดยใช้นามแฝงสำหรับชุดข้อมูลของฉัน และเข้าร่วมกับลิงก์ดังกล่าวใน URL เป้าหมายของลิงก์และ URL ของหน้า ซึ่งสอดคล้องกับพื้นที่ทับซ้อนของชุดข้อมูลสองชุดในไดอะแกรมที่จุดเริ่มต้นของส่วนนี้
เลือก ลิงค์.origin, หน้า.url, pages.final_redirect_location, pages.final_redirect_status จาก `datascience-oncrawl.example_bigdata_exports.pages` หน้า AS เข้าร่วม `datascience-oncrawl.example_bigdata_exports.links` ลิงก์ AS บน links.target = pages.url ที่ไหน pages.status_code = 301 หรือ pages.status_code = 302 สั่งโดย ที่มา ASC
ในผลลัพธ์ของ Query ฉันสามารถเปลี่ยนชื่อคอลัมน์เพื่อให้ชัดเจนขึ้นได้ แต่ฉันเห็นแล้วว่าฉันมีลิงก์จากหน้าในคอลัมน์แรกซึ่งไปที่หน้าในคอลัมน์ที่สองซึ่งจะเปลี่ยนเส้นทางไปที่ หน้าในคอลัมน์ที่สาม ในคอลัมน์ที่สี่ ฉันมีรหัสสถานะของเป้าหมายสุดท้าย: 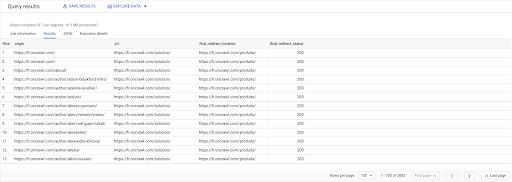
ตอนนี้ ฉันสามารถบอกได้ว่าลิงก์ใดชี้ไปยังหน้าที่เปลี่ยนเส้นทางซึ่งแก้ไขไม่ได้ถึง 200 หน้า ตัวอย่างเช่น อาจเป็น 404 ซึ่งให้รายการลิงก์ที่มีลำดับความสำคัญในการแก้ไข
เราเห็นก่อนหน้านี้ถึงวิธีการบันทึกแบบสอบถาม นอกจากนี้เรายังสามารถบันทึกผลลัพธ์ได้ถึง 16000 บรรทัดของผลลัพธ์: 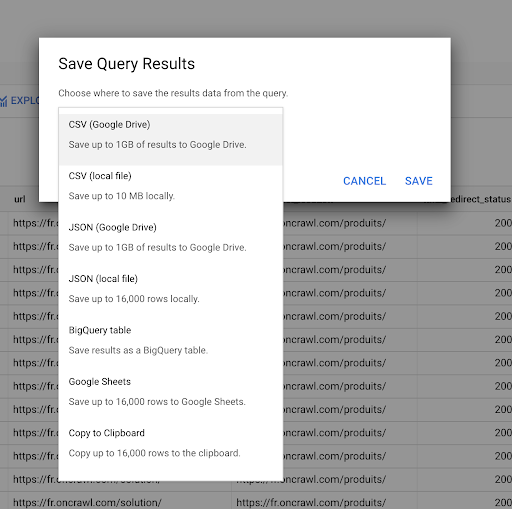
จากนั้นเราสามารถใช้ผลลัพธ์เหล่านี้ได้หลายวิธี นี่คือตัวอย่างบางส่วน:
- เราสามารถบันทึกเป็นไฟล์ CSV หรือ JSON ในเครื่องได้
- เราสามารถบันทึกเป็นสเปรดชีตของ Google ชีตและแชร์กับทีมที่เหลือ
- เรายังส่งออกไปยัง Data Studio ได้โดยตรงอีกด้วย
ข้อมูลเป็นข้อได้เปรียบเชิงกลยุทธ์
ด้วยความเป็นไปได้ทั้งหมดเหล่านี้ การใช้คำตอบสำหรับคำถามที่ซับซ้อนของคุณอย่างมีกลยุทธ์จึงเป็นเรื่องง่าย คุณอาจมีประสบการณ์ในการเชื่อมต่อผลลัพธ์ของ BigQuery กับ Data Studio หรือแพลตฟอร์มการแสดงข้อมูลอื่นๆ หรือคุณอาจมีกระบวนการอยู่แล้วที่ส่งข้อมูลไปยังทีมวิศวกร หรือแม้แต่ใน Business Intelligence หรือเวิร์กโฟลว์การวิเคราะห์ข้อมูล
หากคุณรวมขั้นตอนในบทความนี้ไว้เป็นส่วนหนึ่งของกระบวนการ โปรดทราบว่าคุณสามารถทำให้ขั้นตอนทั้งหมดใน BigQuery เป็นไปโดยอัตโนมัติ: การดำเนินการทั้งหมดที่เราทำในบทความนี้สามารถเข้าถึงได้ผ่าน BigQuery API ซึ่งหมายความว่าสามารถเรียกใช้โดยทางโปรแกรมโดยเป็นส่วนหนึ่งของสคริปต์หรือเครื่องมือที่กำหนดเอง
ไม่ว่าขั้นตอนต่อไปของคุณจะเป็นอย่างไร ขั้นตอนแรกคือการเข้าถึงดิบ SEO และข้อมูลเว็บไซต์เสมอ เราเชื่อว่าการเข้าถึงข้อมูลเป็นส่วนที่สำคัญที่สุดอย่างหนึ่งของการวิเคราะห์ทางเทคนิค: ด้วย Oncrawl คุณจะสามารถเข้าถึงข้อมูลดิบของคุณได้อย่างเต็มที่เสมอ
การเข้าถึงข้อมูลยังหมายความว่าคุณสามารถไปไกลกว่าสิ่งที่เป็นไปได้ในอินเทอร์เฟซ Oncrawl และสำรวจความสัมพันธ์ทั้งหมดระหว่างข้อมูลของคุณ ไม่ว่าคุณจะถามคำถามที่ซับซ้อนเพียงใด