
Что такое векторы слов и как структурированная разметка их превосходит
Опубликовано: 2021-07-28Как вы определяете векторы слов? В этом посте я познакомлю вас с концепцией векторов слов. Мы рассмотрим различные типы встраивания слов и, что более важно, то, как работают векторы слов. Затем мы сможем увидеть влияние векторов слов на SEO, что позволит нам понять, как разметка Schema.org для структурированных данных может помочь вам воспользоваться преимуществами векторов слов в SEO.
Продолжайте читать этот пост, если хотите узнать больше об этих темах.
Давайте погрузимся прямо в.
Что такое векторы слов?
Векторы слов (также называемые вложениями слов) — это тип представления слов, который позволяет словам с похожими значениями иметь одинаковое представление.
Проще говоря: вектор слова — это векторное представление определенного слова.
Согласно Википедии:
Это метод, используемый в обработке естественного языка (NLP) для представления слов для анализа текста, обычно в виде вектора с действительным знаком, который кодирует значение слова, так что слова, близкие в векторном пространстве, вероятно, будут иметь аналогичные значения.
Следующий пример поможет нам лучше понять это:
Посмотрите на эти похожие предложения:
Хорошего дня . и Хорошего дня.
Они едва ли имеют другое значение. Если мы создадим исчерпывающий словарь (назовем его V), он будет иметь V = {Have, a, good, great, day}, объединяющий все слова. Мы могли бы закодировать слово следующим образом.
Векторное представление слова может быть вектором с горячим кодированием, где 1 представляет позицию, в которой существует слово, а 0 представляет остальную часть.
Иметь = [1,0,0,0,0]
а=[0,1,0,0,0]
хорошо=[0,0,1,0,0]
отлично=[0,0,0,1,0]
день=[0,0,0,0,1]
Предположим, что в нашем словарном запасе всего пять слов: король, королева, мужчина, женщина и ребенок. Мы могли бы закодировать слова как:
Король = [1,0,0,0,0]
Королева = [0,1,0,0,0]
Человек = [0,0,1,00]
Женщина = [0,0,0,1,0]
Ребенок = [0,0,0,0,1]
Типы встраивания слов (векторы слов)
Встраивание слов — один из таких методов, в котором векторы представляют текст. Вот некоторые из наиболее популярных типов встраивания слов:
- Встраивание на основе частоты
- Встраивание на основе предсказания
Мы не будем здесь углубляться в встраивание на основе частоты и встраивание на основе предсказания, но вы можете найти следующие руководства полезными для понимания обоих:
Интуитивное понимание встраивания слов и краткое введение в Bag-of-Words (BOW) и TF-IDF для создания функций из текста
Краткое введение в WORD2Vec
Хотя встраивание на основе частоты приобрело популярность, все еще существует пробел в понимании контекста слов и ограниченности их словесных представлений.
Встраивание на основе предсказания (WORD2Vec) было создано, запатентовано и представлено сообществу НЛП в 2013 году группой исследователей во главе с Томасом Миколовым из Google.
Согласно Википедии, алгоритм word2vec использует модель нейронной сети для изучения словесных ассоциаций из большого корпуса текста (большой и структурированный набор текстов).
После обучения такая модель может обнаруживать синонимичные слова или предлагать дополнительные слова для неполного предложения. Например, с помощью Word2Vec можно легко создать такие результаты: Король — мужчина + женщина = Королева, что считалось почти волшебным результатом.
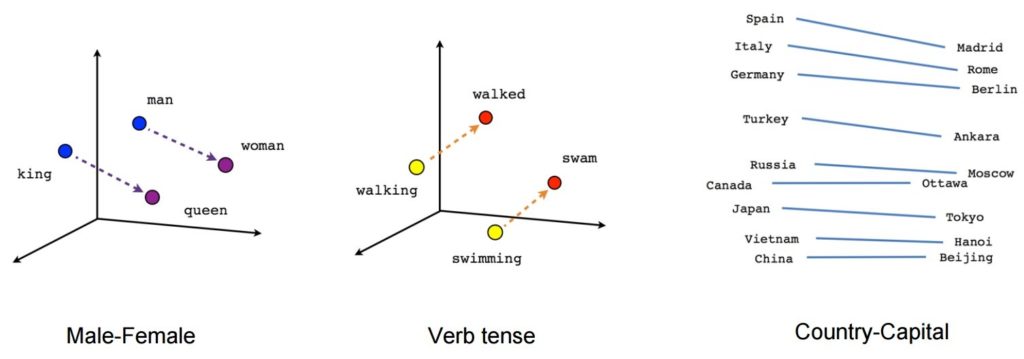 Источник изображения: Tensorflow
Источник изображения: Tensorflow
- [король] – [мужчина] + [женщина] ~= [королева] (другой способ думать об этом состоит в том, что [король] – [королева] кодирует только гендерную часть [монарха])
- [ходьба] – [плавание] + [плавание] ~= [шел] (или [плавание] – [плавание] кодирует просто «прошедшее время» глагола)
- [мадрид] – [испания] + [франция] ~= [париж] (или [мадрид] – [испания] ~= [париж] – [франция], что предположительно является примерно «столицей»)
Источник: Brainslab Digital.
Я знаю, что это немного технически, но Stitch Fix подготовил фантастический пост о семантических отношениях и векторах слов.
Алгоритм Word2Vec — это не отдельный алгоритм, а комбинация двух методов, в которой используется несколько методов ИИ для объединения человеческого и машинного понимания. Эта техника необходима для «решения» «многих» проблем «НЛП».
Эти две техники:
- – CBOW (непрерывный набор слов) или модель CBOW
- – Модель скип-грамм.
Обе представляют собой неглубокие нейронные сети, которые обеспечивают вероятность слов и доказали свою полезность в таких задачах, как сравнение слов и аналогия слов.
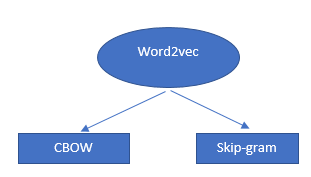
Как работают векторы слов и word2vecs
Word Vector — это модель искусственного интеллекта, разработанная Google, и она помогает нам решать очень сложные задачи НЛП.
«Векторные модели Word имеют одну главную цель, о которой вы должны знать:
Это алгоритм, который помогает Google определять семантические отношения между словами».
Каждое слово кодируется в векторе (как число, представленное в нескольких измерениях), чтобы соответствовать векторам слов, которые появляются в аналогичном контексте. Следовательно, для текста формируется плотный вектор.
Эти векторные модели сопоставляют семантически похожие фразы с соседними точками на основе эквивалентности, сходства или родства идей и языка.
[Пример успеха] Стимулирование роста на новых рынках с помощью SEO на странице
 Читать тематическое исследование
Читать тематическое исследованиеWord2Vec - Как это работает?
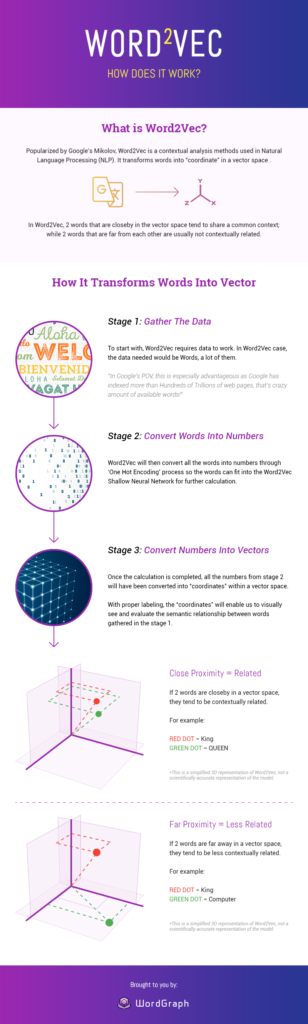
Источник изображения: Seopressor
Плюсы и минусы Word2Vec
Мы видели, что Word2vec — очень эффективная техника для создания дистрибутивного сходства. Я перечислил некоторые из его других преимуществ здесь:
- Нет никаких трудностей в понимании концепций Word2vec. Word2Vec не настолько сложен, чтобы вы не знали, что происходит за кулисами.
- Архитектура Word2Vec очень мощная и простая в использовании. По сравнению с другими техниками, обучается быстро.
- Обучение здесь почти полностью автоматизировано, поэтому данные, помеченные человеком, больше не требуются.
- Этот метод работает как для небольших, так и для больших наборов данных. В результате модель легко масштабируется.
- Если вы знаете концепции, вы можете легко воспроизвести всю концепцию и алгоритм.
- Он исключительно хорошо фиксирует семантическое сходство.
- Точный и вычислительно эффективный
- Поскольку этот подход не контролируется, он очень экономит время с точки зрения усилий.
Проблемы Word2Vec
Концепция Word2vec очень эффективна, но некоторые моменты могут показаться вам немного сложными. Вот несколько наиболее распространенных проблем.
- При разработке модели word2vec для вашего набора данных отладка может стать серьезной проблемой, поскольку модель word2vec легко разрабатывать, но сложно отлаживать.
- Он не имеет дело с двусмысленностью. Таким образом, в случае слов с несколькими значениями Embedding будет отражать среднее значение этих значений в векторном пространстве.
- Невозможность обработки неизвестных слов или слов OOV. Самая большая проблема с word2vec — невозможность обрабатывать неизвестные слова или слова вне словарного запаса (OOV).
Векторы слов: переломный момент в поисковой оптимизации?
Многие эксперты по SEO считают, что Word Vector влияет на рейтинг сайта в результатах поиска.
За последние пять лет Google представил два обновления алгоритма, в которых особое внимание уделяется качеству контента и языковой полноте.
Давайте сделаем шаг назад и поговорим об обновлениях:
Колибри
В 2013 году Hummingbird предоставил поисковым системам возможность семантического анализа. Используя и включив теорию семантики в свои алгоритмы, они открыли новый путь в мир поиска.
Google Hummingbird стал самым большим изменением в поисковой системе со времен Caffeine в 2010 году. Он получил свое название из-за того, что он «точный и быстрый».
По данным Search Engine Land, Hummingbird уделяет больше внимания каждому слову в запросе, гарантируя, что будет рассмотрен весь запрос, а не только отдельные слова.

Основная цель Hummingbird заключалась в том, чтобы предоставить лучшие результаты за счет понимания контекста запроса, а не возврата результатов по конкретным ключевым словам.
«Google Hummingbird был выпущен в сентябре 2013 года».
RankBrain
В 2015 году Google анонсировала RankBrain, стратегию, включающую искусственный интеллект (ИИ).
RankBrain — это алгоритм, который помогает Google разбивать сложные поисковые запросы на более простые. RankBrain преобразует поисковые запросы с «человеческого» языка на язык, понятный Google.
Google подтвердил использование RankBrain 26 октября 2015 года в статье, опубликованной Bloomberg.
БЕРТ
21 октября 2019 года BERT начал развертывание в поисковой системе Google.
BERT расшифровывается как Bidirectional Encoder Representations from Transformers, метод на основе нейронной сети, используемый Google для предварительного обучения обработке естественного языка (NLP).
Короче говоря, BERT помогает компьютерам понимать язык лучше, чем люди, и это самое большое изменение в поиске с тех пор, как Google представил RankBrain.
Это не замена RankBrain, а скорее дополнительный метод для понимания контента и запросов.
Google использует BERT в своей системе ранжирования в качестве дополнения. Алгоритм RankBrain по-прежнему существует для некоторых запросов и продолжит свое существование. Но когда Google почувствует, что BERT может лучше понять запрос, они воспользуются этим.
Для получения дополнительной информации о BERT ознакомьтесь с этим постом Барри Шварца, а также с подробным описанием Дон Андерсон.
Оцените свой сайт с помощью Word Vectors
Я предполагаю, что вы уже создали и опубликовали уникальный контент, и даже после его полировки снова и снова это не улучшит ваш рейтинг или трафик.
Вы задаетесь вопросом, почему это происходит с вами?
Это может быть связано с тем, что вы не включили Word Vector: модель искусственного интеллекта Google.
- Первый шаг — определить векторы слов из 10 лучших результатов поисковой выдачи для вашей ниши.
- Знайте, какие ключевые слова используют ваши конкуренты и что вы можете упустить из виду.
Применяя Word2Vec, который использует передовые методы обработки естественного языка и структуру машинного обучения, вы сможете увидеть все в деталях.
Но это возможно, если вы знаете методы машинного обучения и NLP, но мы можем применять векторы слов в контенте, используя следующий инструмент:
WordGraph, первый в мире векторный инструмент Word
Этот инструмент искусственного интеллекта создан с помощью нейронных сетей для обработки естественного языка и обучен с помощью машинного обучения.
Основанный на искусственном интеллекте, WordGraph анализирует ваш контент и помогает повысить его релевантность для сайтов, входящих в десятку лучших.
Он предлагает ключевые слова, которые математически и контекстуально связаны с вашим основным ключевым словом.
Лично я сочетаю его с BIQ, мощным инструментом SEO, который хорошо работает с WordGraph.
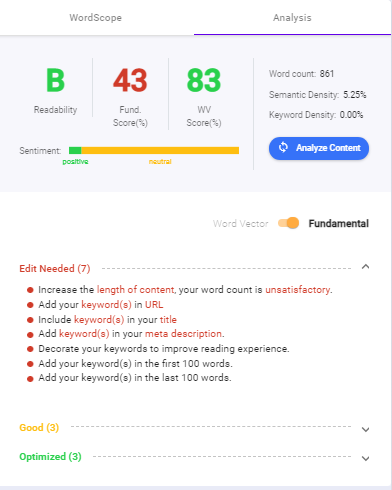
Добавьте свой контент в инструмент анализа контента, встроенный в Biq. Он покажет вам целый список советов по SEO на странице , которые вы можете добавить, если хотите занять первое место.
В этом примере вы можете увидеть, как работает контент-аналитика. Списки помогут вам освоить SEO на странице и ранжировать с помощью действенных методов!
Как перегрузить векторы слов: использование разметки структурированных данных
Разметка схемы или структурированные данные — это тип кода (написанного в формате JSON, нотации объектов Java-Script), созданного с использованием словаря schema.org, который помогает поисковым системам сканировать, упорядочивать и отображать ваш контент.
Как добавить структурированные данные
Структурированные данные можно легко добавить на ваш веб-сайт, добавив встроенный скрипт в ваш HTML-код.
В приведенном ниже примере показано, как определить структурированные данные вашей организации в максимально простом формате.
Чтобы создать разметку схемы, я использую этот генератор разметки схемы (JSON-LD).
Вот живой пример разметки схемы для https://www.telecloudvoip.com/. Проверьте исходный код и найдите JSON.
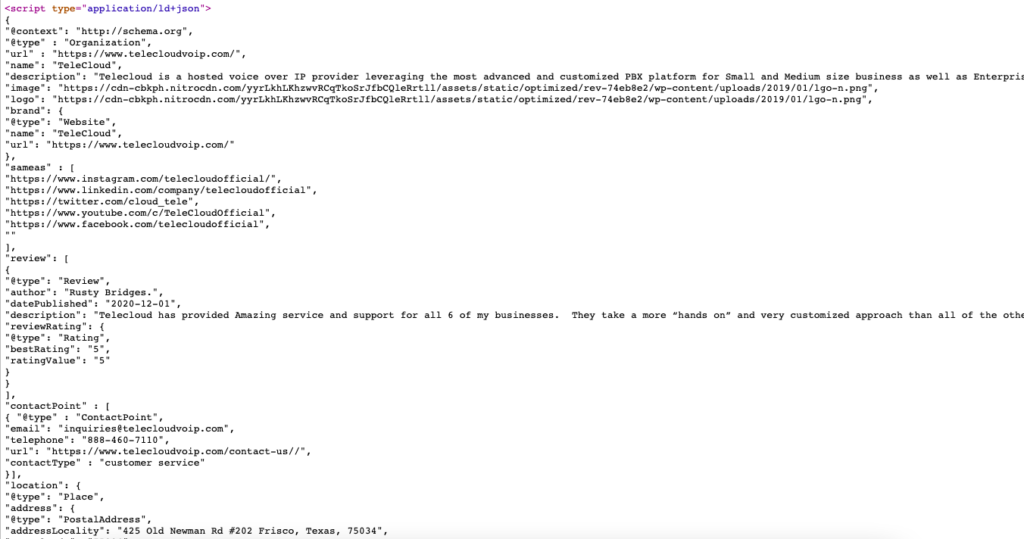
После того, как код разметки схемы создан, используйте тест расширенных результатов Google, чтобы узнать, поддерживает ли страница расширенные результаты.
Вы также можете использовать инструмент аудита сайта Semrush, чтобы изучить элементы структурированных данных для каждого URL-адреса и определить, какие страницы имеют право на участие в расширенных результатах. 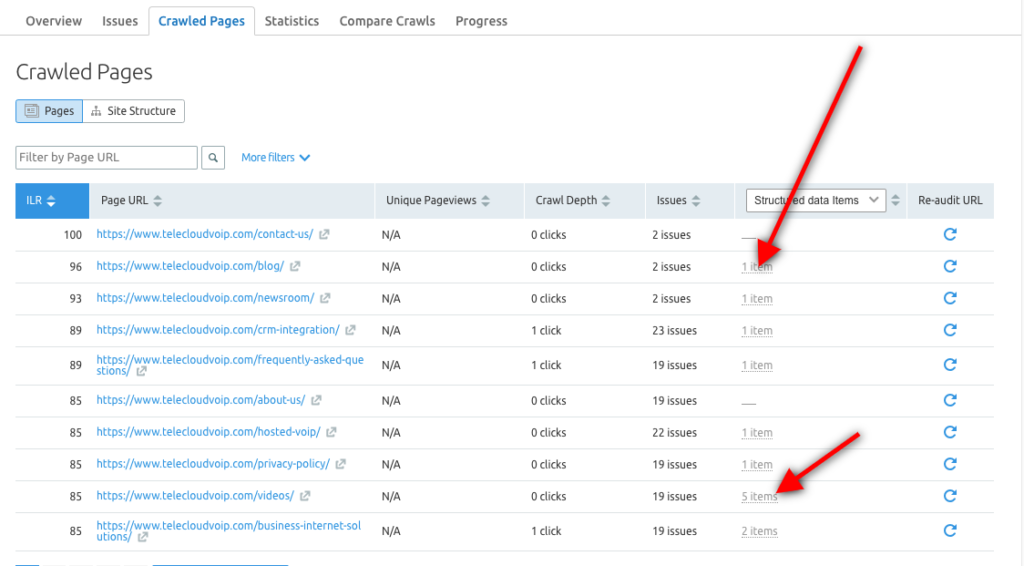
Почему структурированные данные важны для SEO?
Структурированные данные важны для SEO, потому что они помогают Google понять, о чем ваш веб-сайт и страницы, что приводит к более точному ранжированию вашего контента.
Структурированные данные улучшают как работу поискового робота, так и пользователя, улучшая SERP (страницы результатов поисковой системы) с большей информацией и точностью.
Чтобы увидеть влияние на поиск Google, перейдите в консоль поиска и в разделе «Производительность» > «Результат поиска» > «Внешний вид» вы можете просмотреть разбивку по всем типам расширенных результатов, таким как «видео» и «часто задаваемые вопросы», и увидеть органические показы и клики, которые они привели. для вашего контента.
Ниже приведены некоторые преимущества структурированных данных:
- Структурированные данные поддерживают семантический поиск
- Он также поддерживает ваш E‑AT (опыт, авторитетность и доверие).
- Наличие структурированных данных также может повысить коэффициент конверсии, поскольку больше людей увидят ваши объявления, что увеличит вероятность того, что они купят у вас.
- Используя структурированные данные, поисковые системы лучше понимают ваш бренд, ваш веб-сайт и ваш контент.
- Поисковым системам будет легче различать страницы контактов, описания продуктов, страницы рецептов, страницы событий и отзывы клиентов.
- С помощью структурированных данных Google строит более точную диаграмму знаний и панель знаний о вашем бренде.
- Эти улучшения могут привести к большему количеству органических показов и органических кликов.
В настоящее время Google использует структурированные данные для улучшения результатов поиска. Когда люди ищут ваши веб-страницы по ключевым словам, структурированные данные могут помочь вам получить лучшие результаты. Поисковые системы будут лучше замечать ваш контент, если мы добавим разметку Schema.
Разметку схемы можно реализовать для ряда различных элементов. Ниже перечислены несколько областей, в которых может применяться схема:
- Статьи
- Сообщения в блоге
- Новости Статьи
- События
- Товары
- Видео
- Услуги
- Отзывы
- Совокупные рейтинги
- Рестораны
- Местные предприятия
Вот полный список элементов, которые вы можете разметить с помощью схемы.
Структурированные данные с внедрением сущностей
Термин «сущность» относится к представлению любого типа объекта, понятия или субъекта. Объектом может быть человек, фильм, книга, идея, место, компания или событие.
Хотя машины на самом деле не могут понимать слова, с встраиванием сущностей они могут легко понять отношения между королем — королевой = мужем — женой.
Внедрение сущностей работает лучше, чем однократное кодирование
Алгоритм вектора слов используется Google для обнаружения семантических отношений между словами, и в сочетании со структурированными данными мы получаем семантически улучшенную сеть.
Используя структурированные данные, вы вносите свой вклад в более семантическую сеть. Это расширенная сеть, в которой мы описываем данные в машиночитаемом формате.
Структурированные семантические данные на вашем веб-сайте помогают поисковым системам сопоставлять ваш контент с нужной аудиторией. Использование НЛП, машинного обучения и глубокого обучения помогает сократить разрыв между тем, что люди ищут, и тем, какие названия доступны.
Последние мысли
Теперь, когда вы понимаете концепцию векторов слов и их важность, вы можете сделать свою стратегию органического поиска более эффективной и действенной, используя векторы слов, встраивания сущностей и структурированные семантические данные.
Чтобы добиться наивысшего рейтинга, трафика и конверсий, вы должны использовать векторы слов, встраивание сущностей и структурированные семантические данные, чтобы продемонстрировать Google, что контент на вашей веб-странице точен, точен и заслуживает доверия.