
Что такое скрытое семантическое индексирование и как оно работает?
Опубликовано: 2020-04-02Скрытое семантическое индексирование (LSI) уже давно вызывает споры среди поисковых маркетологов. Погуглите термин «скрытое семантическое индексирование», и вы в равной степени встретите как сторонников, так и скептиков. Нет однозначного мнения о преимуществах использования LSI в контексте маркетинга в поисковых системах. Если вы не знакомы с этой концепцией, в этой статье будут обобщены дебаты о LSI, так что вы, надеюсь, сможете понять, что это значит для вашей стратегии SEO.
Что такое скрытое семантическое индексирование?
LSI — это процесс, используемый в обработке естественного языка (NLP). НЛП — это подмножество лингвистики и информационной инженерии, основное внимание в котором уделяется тому, как машины интерпретируют человеческий язык. Ключевой частью этого исследования является дистрибутивная семантика. Эта модель помогает нам понимать и классифицировать слова со схожим контекстуальным значением в больших наборах данных.
Разработанная в 1980-х годах, LSI использует математический метод, который делает поиск информации более точным. Этот метод работает путем выявления скрытых контекстуальных отношений между словами. Это может помочь вам разбить его следующим образом:
- Скрытый → Скрытый
- Семантика → Отношения между словами
- Индексирование → Поиск информации
Как работает скрытое семантическое индексирование?
LSI работает с частичным применением разложения по сингулярным значениям (SVD). SVD — это математическая операция, которая сводит матрицу к составным частям для простых и эффективных вычислений.
При анализе строки слов LSI удаляет союзы, местоимения и общеупотребительные глаголы, также известные как стоп-слова. Это изолирует слова, которые составляют основное «содержание» фразы. Вот краткий пример того, как это может выглядеть:
![]()
Затем эти слова помещаются в матрицу документов терминов (TDM). TDM представляет собой двумерную сетку, в которой указана частота появления каждого конкретного слова (или термина) в документах в наборе данных.
Затем к TDM применяются функции взвешивания. Простым примером является классификация всех документов, содержащих слово со значением 1, и всех, которые не содержат слова со значением 0. Когда слова встречаются в этих документах с одинаковой общей частотой, это называется совпадением . Ниже вы найдете базовый пример TDM и то, как он оценивает совпадение нескольких фраз:
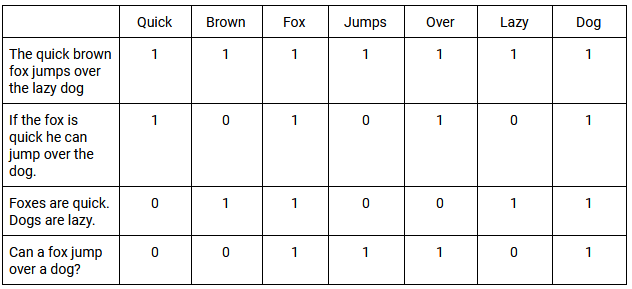
Использование SVD позволяет нам аппроксимировать шаблоны использования слов во всех документах. Векторы SVD, созданные LSI, предсказывают значение более точно, чем анализ отдельных терминов. В конечном счете, LSI может использовать отношения между словами, чтобы лучше понять их смысл или значение в конкретном контексте.
[Пример успеха] Стимулирование роста на новых рынках с помощью SEO на странице
 Читать тематическое исследование
Читать тематическое исследованиеКак латентное семантическое индексирование стало частью SEO?
В годы своего становления Google обнаружил, что поисковые системы ранжируют веб-сайты на основе частоты использования определенного ключевого слова. Это, однако, не гарантирует наиболее релевантных результатов поиска. Вместо этого Google начал ранжировать веб-сайты, которые они считали надежными арбитрами информации.
Со временем алгоритмы Google будут с большей точностью отфильтровывать некачественные и нерелевантные веб-сайты. Поэтому маркетологи должны понимать смысл поиска, а не полагаться на точные используемые слова. Вот почему Роджер Монтти назвал LSI «тренажерами для поисковых систем» в статье об устаревших представлениях о поисковой оптимизации, добавив, что LSI «практически не имеет отношения к тому, как поисковые системы ранжируют веб-сайты сегодня».
Значение поискового запроса тесно связано с намерением, стоящим за ним. Google поддерживает документ под названием «Руководство по оценке качества поиска». В этих рекомендациях они вводят четыре полезные категории для намерения пользователя:
- Знать запрос — представляет собой поиск информации по теме. Вариантом этого является запрос «Know Simple», когда пользователи ищут конкретный ответ.
- Do Query — это отражает желание участвовать в определенном действии, таком как онлайн-покупка или загрузка. Все эти запросы можно определить по смыслу «взаимодействия».
- Запрос веб -сайта — это когда пользователи ищут определенный веб-сайт или страницу. Эти поиски указывают на предыдущую осведомленность о конкретном веб-сайте или бренде.
- Запрос о личном посещении — пользователь ищет физическое местоположение, например, физический магазин или ресторан.
Теория LSI — определение контекстуального значения слова внутри фразы — дала Google конкурентное преимущество. Однако начала распространяться идея о том, что «ключевые слова LSI» внезапно стали золотым билетом к успеху в SEO.

Существуют ли на самом деле «Ключевые слова LSI»?
Многие известные публикации остаются твердыми сторонниками ключевых слов LSI. Тем не менее, несколько источников, таких как аналитик тенденций Google для веб-мастеров Джон Мюллер, заявляют, что это миф. Эти источники начали поднимать следующие вопросы:
- LSI была разработана до появления World Wide Web и не предназначалась для применения к такому большому и динамичному набору данных.
- Патент США на латентное семантическое индексирование, выданный организации Bell Communications Research Inc. в 1989 г., истекал бы в 2008 г. Таким образом, по словам Билла Славски, использование Google LSI было бы сродни «использованию интеллектуального телеграфного устройства для подключения к мобильный Интернет.
- Google использует RankBrain, метод машинного обучения, который преобразует объемы текста в «векторы» — математические объекты, которые помогают компьютерам понимать письменный язык. RankBrain рассматривает Интернет как постоянно расширяющийся набор данных, что делает его пригодным для использования Google, в отличие от LSI.
В конечном счете, LSI раскрывает правду, которой должны придерживаться маркетологи: изучение уникального контекста слова помогает нам лучше понять намерения пользователя, чем ключевые слова, вставленные в контент. Однако это не обязательно подтверждает, что ранжирование Google основано на LSI. Следовательно, можно ли с уверенностью сказать, что LSI работает в SEO как философия, а не как точная наука?
Вернемся к цитате Роджера Монтти о LSI как о «тренировочных колесах для поисковых систем». Как только вы научитесь кататься на велосипеде, вы, как правило, снимаете тренировочные колеса. Можно ли считать, что в 2020 году Google больше не использует тренировочные колеса?
Мы можем рассмотреть недавнее обновление алгоритма Google. В октябре 2019 года Панду Наяк, вице-президент по поиску, объявил, что Google начал использовать систему искусственного интеллекта под названием BERT (представления двунаправленного кодировщика от трансформаторов). Это одно из крупнейших обновлений Google за последние годы, затрагивающее более 10% всех поисковых запросов.
При анализе поискового запроса BERT рассматривает одно слово по отношению ко всем словам в этой конкретной фразе. Этот анализ является двунаправленным, поскольку он рассматривает все слова до или после определенного слова. Удаление одного слова может существенно повлиять на то, как BERT понимает уникальный контекст фразы.
В этом отличие от LSI, в анализе которого исключаются стоп-слова. В приведенном ниже примере показано, как удаление стоп-слов может изменить то, как мы понимаем фразу:
![]()
Несмотря на то, что это стоп-слово, «найти» является сутью поиска, который мы бы определили как запрос «личное посещение».
Так что же делать маркетологам?
Первоначально предполагалось, что LSI сможет помочь Google сопоставлять контент с релевантными запросами. Тем не менее, похоже, что дискуссия в маркетинге вокруг использования LSI еще не привела к единому выводу. Несмотря на это, маркетологи все же могут предпринять множество шагов, чтобы их работа оставалась стратегически актуальной.
Во-первых, статьи, веб-копии и платные кампании должны быть оптимизированы для включения синонимов и вариантов. Это объясняет то, как люди с одинаковыми намерениями используют язык по-разному.
Маркетологи должны продолжать писать убедительно и ясно. Это абсолютно необходимо, если они хотят, чтобы их контент решал конкретную проблему. Этой проблемой может быть недостаток информации или потребность в определенном продукте или услуге. Когда маркетологи делают это, это показывает, что они действительно понимают намерения пользователей.
Наконец, они также должны часто использовать структурированные данные. Будь то веб-сайт, рецепт или часто задаваемые вопросы, структурированные данные предоставляют Google контекст, позволяющий понять, что он сканирует.