
Что такое парсинг данных и как его использовать?
Опубликовано: 2017-09-13Что такое парсинг данных?
Очистка данных, также известная как очистка веб-страниц, представляет собой процесс импорта информации с веб-сайта в электронную таблицу или локальный файл, сохраненный на вашем компьютере. Это один из наиболее эффективных способов получения данных из Интернета, а в некоторых случаях и передачи этих данных на другой веб-сайт. Популярные способы извлечения данных включают:
- Исследование веб-контента/бизнес-аналитики
- Цены на сайтах бронирования путешествий/сайтах сравнения цен
- Поиск потенциальных клиентов/проведение маркетинговых исследований путем сканирования общедоступных источников данных (например, Yell и Twitter)
- Отправка данных о товарах с сайта электронной коммерции другому интернет-продавцу (например, Google Shopping)
И этот список только царапает поверхность. Парсинг данных имеет множество применений — он полезен практически в любом случае, когда данные необходимо переместить из одного места в другое.
Основы очистки данных относительно легко освоить. Давайте рассмотрим, как настроить простое действие очистки данных с помощью Excel.
Парсинг данных с помощью динамических веб-запросов в Microsoft Excel
Настройка динамического веб-запроса в Microsoft Excel — это простой и универсальный метод извлечения данных, который позволяет настроить поток данных с внешнего веб-сайта (или нескольких веб-сайтов) в электронную таблицу.
Посмотрите это отличное учебное видео, чтобы узнать, как импортировать данные из Интернета в Excel, или, если хотите, воспользуйтесь приведенными ниже письменными инструкциями:
- Откройте новую книгу в Excel
- Щелкните ячейку, в которую вы хотите импортировать данные.
- Перейдите на вкладку «Данные».
- Нажмите «Получить внешние данные».
- Щелкните значок «Из Интернета».
- Обратите внимание на маленькие желтые стрелки, которые появляются в левом верхнем углу веб-страницы и рядом с определенным содержимым.
- Вставьте URL-адрес веб-страницы, с которой вы хотите импортировать данные, в адресную строку (мы рекомендуем выбрать сайт, на котором данные отображаются в виде таблиц)
- Нажмите «Перейти»
- Щелкните желтую стрелку рядом с данными, которые вы хотите импортировать.
- Нажмите «Импорт»
- Появится диалоговое окно «Импорт данных».
- Нажмите «ОК» (или измените выбор ячейки, если хотите)
Если вы выполнили эти шаги, теперь вы сможете увидеть данные с веб-сайта, представленные в вашей электронной таблице.
Преимущество динамических веб-запросов заключается в том, что они не просто импортируют данные в вашу электронную таблицу как одноразовую операцию — они передают их, то есть электронная таблица регулярно обновляется последней версией данных, как они появляются на веб-сайте. исходный сайт. Вот почему мы называем их динамическими.
Чтобы настроить периодичность обновления импортируемых динамическим веб-запросом данных, перейдите в «Данные», затем в «Свойства», затем выберите частоту («Обновлять каждые X минут»).
Автоматизированный сбор данных с помощью инструментов
Знакомство с использованием динамических веб-запросов в Excel — полезный способ получить представление о парсинге данных. Однако, если вы намерены регулярно использовать в своей работе сбор данных, вам может оказаться более эффективным специальный инструмент для сбора данных.
Вот наши мысли о некоторых из самых популярных инструментов очистки данных на рынке:
Data Scraper (плагин для Chrome)
Data Scraper подключается прямо к расширениям вашего браузера Chrome, позволяя вам выбирать из ряда готовых «рецептов» очистки данных для извлечения данных с любой веб-страницы, загруженной в ваш браузер.
Этот инструмент особенно хорошо работает с популярными источниками сбора данных, такими как Twitter и Wikipedia, поскольку плагин включает в себя большее разнообразие вариантов рецептов для таких сайтов.
Мы опробовали Data Scraper, извлекая хэштег Twitter «#jourorequest» для возможностей PR, используя один из общедоступных рецептов инструмента. Вот часть данных, которые мы получили:
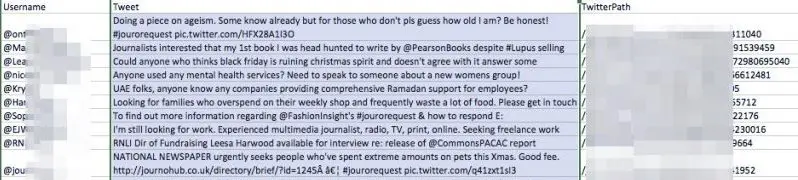
Как видите, инструмент предоставил таблицу с именем пользователя каждой учетной записи, которая недавно опубликовала хэштег, а также их твит и его URL.
Наличие этих данных в этом формате было бы более полезным для представителя по связям с общественностью, чем просто просмотр данных в представлении браузера Twitter по ряду причин:
- Его можно использовать для создания базы данных контактов с прессой.
- Вы можете продолжать обращаться к этому списку и легко находить то, что ищете, тогда как Twitter постоянно обновляет
- Список можно сортировать и редактировать
- Это дает вам право собственности на данные, которые могут быть отключены или изменены в любой момент.
Мы впечатлены Data Scraper, хотя его общедоступные рецепты иногда немного грубоваты. Попробуйте установить бесплатную версию в Chrome и поэкспериментируйте с извлечением данных. Обязательно посмотрите вступительный ролик, который они предоставляют, чтобы получить представление о том, как работает инструмент, и о некоторых простых способах извлечения нужных данных.
WebHarvy
WebHarvy — это парсер данных «укажи и щелкни» с бесплатной пробной версией. Его самым большим преимуществом является его гибкость — вы можете использовать встроенный веб-браузер инструмента для перехода к данным, которые вы хотите импортировать, а затем можете создать свои собственные спецификации майнинга, чтобы извлечь именно то, что вам нужно, с исходного веб-сайта.
import.io
Import.io — это многофункциональный набор инструментов для интеллектуального анализа данных, который делает большую часть тяжелой работы за вас. Имеет несколько интересных функций, в том числе «Что изменилось?» отчеты, которые могут уведомлять вас об обновлениях на определенных веб-сайтах — идеально подходит для углубленного анализа конкурентов.
Как маркетологи используют парсинг данных?
Как вы уже поняли к этому моменту, парсинг данных может пригодиться практически везде, где используется информация. Вот несколько ключевых примеров того, как маркетологи используют эту технологию:
Сбор разрозненных данных
По словам Марцина Розински, генерального директора FeedOptimise, одно из больших преимуществ парсинга данных заключается в том, что он может помочь вам собрать разные данные в одном месте. «Сканирование позволяет нам брать неструктурированные, разбросанные данные из нескольких источников, собирать их в одном месте и структурировать», — говорит Марчин. «Если у вас есть несколько веб-сайтов, контролируемых разными организациями, вы можете объединить их все в один канал.

«Спектр вариантов использования для этого бесконечен».
FeedOptimise предлагает широкий спектр услуг по очистке данных и предоставлению данных, о которых вы можете узнать на их веб-сайте.
Ускорение исследования
Простейшее использование парсинга данных — получение данных из одного источника. Если есть веб-страница, содержащая много данных, которые могут быть вам полезны, самым простым способом получить эту информацию на вашем компьютере в упорядоченном формате, вероятно, будет очистка данных.
Попробуйте найти список полезных контактов в Твиттере и импортируйте данные с помощью очистки данных. Это даст вам представление о том, как этот процесс может вписаться в вашу повседневную работу.
Вывод XML-фида на сторонние сайты
Передача данных о продуктах с вашего сайта в Google Покупки и другим сторонним продавцам является ключевым применением очистки данных для электронной коммерции. Это позволяет вам автоматизировать потенциально трудоемкий процесс обновления информации о вашем продукте, что очень важно, если ваши запасы часто меняются.
«Очистка данных может вывести ваш XML-канал для Google Покупок», — говорит директор по маркетингу Target Internet Киаран Роджерс. « Я работал с несколькими розничными интернет-магазинами, которые постоянно добавляли новые артикулы на свои сайты по мере поступления товаров на склад. Если ваше решение для электронной коммерции не выводит подходящий XML-канал, который вы можете подключить к своему Google Merchant Center, чтобы рекламировать свои лучшие продукты, это может стать проблемой. Часто ваши последние продукты являются потенциально бестселлерами, поэтому вы хотите, чтобы они рекламировались, как только они появятся в продаже. Я использовал очистку данных для создания актуальных списков для подачи в Google Merchant Center. Это отличное решение, и на самом деле вы можете многое сделать с данными, когда они у вас есть. Используя фид, вы можете ежедневно отмечать продукты с наибольшей конверсией, чтобы вы могли поделиться этой информацией с Google Adwords и обеспечить более конкурентоспособные ставки для этих продуктов. Как только вы настроите его, все станет автоматическим. Гибкость хорошей ленты, которую вы контролируете таким образом, велика, и она может привести к некоторым очень определенным улучшениям в тех кампаниях, которые нравятся клиентам».
Можно настроить для себя простой поток данных в Google Merchant Center. Вот как это делается:
Как настроить подачу данных в Google Merchant Center
Используя один из методов или инструментов, описанных ранее, создайте файл, который использует динамический запрос веб-сайта для импорта сведений о продуктах, перечисленных на вашем сайте. Этот файл должен автоматически обновляться через регулярные промежутки времени.
Детали должны быть изложены, как указано здесь.
- Загрузите этот файл на защищенный паролем URL-адрес
- Перейдите в Google Merchant Center и войдите в систему (сначала убедитесь, что ваша учетная запись Merchant Center правильно настроена).
- Перейти к продуктам
- Нажмите кнопку плюс
- Введите целевую страну и создайте название фида
- Выберите параметр «запланированное получение».
- Добавьте URL-адрес файла данных вашего продукта вместе с именем пользователя и паролем, необходимыми для доступа к нему.
- Выберите частоту загрузки, которая лучше всего соответствует графику загрузки вашего продукта.
- Нажмите Сохранить
- Теперь данные о вашем продукте должны быть доступны в Google Merchant Center. Просто убедитесь, что вы щелкнули вкладку «Диагностика», чтобы проверить ее статус и убедиться, что все работает гладко.
Темная сторона очистки данных
Есть много положительных применений очистки данных, но небольшое меньшинство также злоупотребляет ими.
Наиболее распространенным неправомерным использованием очистки данных является сбор электронной почты — сбор данных с веб-сайтов, социальных сетей и каталогов для выявления адресов электронной почты людей, которые затем продаются спамерам или мошенникам. В некоторых юрисдикциях использование автоматизированных средств, таких как очистка данных, для сбора адресов электронной почты с коммерческими целями является незаконным и почти повсеместно считается плохой маркетинговой практикой.
Многие веб-пользователи внедрили методы, помогающие снизить риск того, что сборщики электронной почты завладеют их адресом электронной почты, в том числе:
- Фальсификация адресов: изменение формата вашего адреса электронной почты при публичной публикации, например, ввод «patrick[at]gmail.com» вместо «[email protected]». Это простой, но немного ненадежный подход к защите вашего адреса электронной почты в социальных сетях — некоторые сборщики данных будут искать различные комбинации, а также электронные письма в обычном формате, поэтому он не совсем герметичен.
- Контактные формы: использование контактной формы вместо размещения вашего адреса электронной почты на вашем веб-сайте.
- Изображения: если ваш адрес электронной почты представлен на вашем веб-сайте в виде изображения, это будет за пределами технической досягаемости большинства людей, занимающихся сбором электронной почты.
Будущее парсинга данных
Независимо от того, собираетесь ли вы использовать парсинг данных в своей работе, рекомендуется изучить этот вопрос, так как он, вероятно, станет еще более важным в ближайшие несколько лет.
В настоящее время на рынке есть ИИ для очистки данных, который может использовать машинное обучение, чтобы продолжать совершенствоваться в распознавании входных данных, которые традиционно могли интерпретировать только люди, например изображения.
Большие улучшения в извлечении данных из изображений и видео будут иметь далеко идущие последствия для цифровых маркетологов. По мере углубления анализа изображений мы сможем узнать об онлайн-изображениях гораздо больше, чем увидим их сами, и это, как и анализ данных на основе текста, поможет нам делать многие вещи лучше.
Тогда есть самый большой парсер данных из всех — Google. Весь опыт веб-поиска изменится, когда Google сможет точно делать выводы из изображения так же, как и из копии страницы — и это вдвойне с точки зрения цифрового маркетинга.
Если вы сомневаетесь, может ли это произойти в ближайшем будущем, попробуйте API интерпретации изображений Google, Cloud Vision, и дайте нам знать, что вы думаете. получите бесплатное членство прямо сейчас - кредитная карта не требуется
БЕСПЛАТНОЕ ЧЛЕНСТВО 