
[Дайджест вебинара] SEO in Orbit: новый взгляд на дублированный контент
Опубликовано: 2019-11-20Веб-семинар «Новые взгляды на дублированный контент» — это заключительный эпизод серии SEO in Orbit, который вышел в эфир 24 июня 2019 года. В этом эпизоде присоединяйтесь к амбассадору OnCrawl Оми Сидо и Алексис Сандерс, которые исследуют вопрос о дублирующемся контенте. Они решают такие вопросы, как: как факторы ранжирования и развивающиеся поисковые технологии влияют на то, как мы обрабатываем дублированный контент? И: какое будущее ждет аналогичный контент в Интернете?
SEO in Orbit — это первая серия вебинаров, отправляющая SEO в космос. На протяжении всей серии мы обсуждали настоящее и будущее технического SEO с некоторыми из лучших специалистов по SEO и 27 июня 2019 года отправили в космос их лучшие советы.
Смотрите повтор здесь:
Представляем Алексис Сандерс
Алексис Сандерс работает техническим менеджером по SEO в компании Merkle. Техническая команда SEO обеспечивает точность, осуществимость и масштабируемость технических рекомендаций агентства по всем вертикалям. Она является автором блога Moz и создателем задачи TechnicalSEO.expert и подкаста SEO in the Lab.
Этот выпуск вел Оми Сидо. Оми — опытный международный спикер, известный в индустрии своим юмором и умением излагать практические идеи, которые зрители могут сразу же использовать. От консультационных услуг по SEO в крупнейших мировых телекоммуникационных и туристических компаниях до управления собственным SEO в HostelWorld и Daily Mail — Оми любит погружаться в сложные данные и находить яркие пятна. В настоящее время Оми является старшим техническим специалистом по SEO в Canon Europe и амбассадором OnCrawl.
Что такое дублированный контент?
Omi дает следующее определение дублированного контента:
Дублированный контент, похожий или почти похожий на контент, размещенный по другому URL-адресу на том же (или другом) веб-сайте.
Миф о наказании за дублированный контент
Штрафа за дублирование контента нет.
Это проблема производительности. Мы не хотим, чтобы бот просматривал два конкретных URL-адреса и думал, что это два разных содержимого, которые можно ранжировать рядом друг с другом.
Алексис сравнивает понимание ботом вашего веб-сайта с картинками Джоуи из «10 вещей, которые я ненавижу в вас»: бот не может найти существенную разницу между двумя версиями.

Вы хотите избежать двух одинаковых вещей, которые должны конкурировать друг с другом в ситуации ранжирования в поисковых системах. Вместо этого вы хотите иметь единый консолидированный опыт, который может ранжироваться и работать в поисковых системах.
Разница между тем, что видят пользователи и боты
Пользователь может увидеть один убедительный URL-адрес, но бот может по-прежнему видеть несколько версий, которые выглядят для него практически одинаково.
– Влияние на краулинговый бюджет для очень большого сайта
Для очень больших сайтов, таких как Zillow или Walmart, краулинговый бюджет может различаться для разных страниц.
Как отметил Алексис в статье 2018 года, основанной на презентации Фредерика Дюбута на SMX East, бюджеты устанавливаются на разных уровнях — на уровнях субдоменов, на разных уровнях сервера. Поисковые системы, будь то Google или Bing, хотят быть вежливыми сканерами; они не хотят снижать производительность для реальных пользователей. Всякий раз, когда они чувствуют изменение производительности, они отступают. Это может происходить на разных уровнях, а не только на уровне сайта.
Если у вас большой сайт, вы хотите убедиться, что вы предоставляете наиболее консолидированный опыт, который актуален для ваших пользователей.
Является ли дублированный контент контентом или технической проблемой?
Несмотря на слово «контент» в «дублированном контенте», это отчасти техническая проблема.
– Источники дублирования – [07:50]
Есть много факторов, которые могут вызвать дублирование. Даже неполный список может продолжаться бесконечно:
- Повторяющиеся страницы
- Промежуточные сайты
- URL-адреса HTTP и HTTPS
- Различные поддомены
- Различные случаи
- Различные расширения файлов
- Косая черта в конце
- Индексные страницы
- URL-параметры
- Грани
- Сорта
- Версия для печати
- Дверная страница
- Инвентарь
- Синдицированный контент
- PR-релизы
- Перепубликация контента
- Плагиат
- Локализованный контент
- Тонкий контент
- Только изображения
- Внутренний поиск по сайту
- Отдельный мобильный сайт
- Неуникальный контент
- …
– Распределение проблем между техническим SEO и контентом
На самом деле, эти источники дублированного контента можно разделить на технические источники и источники разработки и источники контента, а некоторые из них попадают в зону перекрытия между ними.
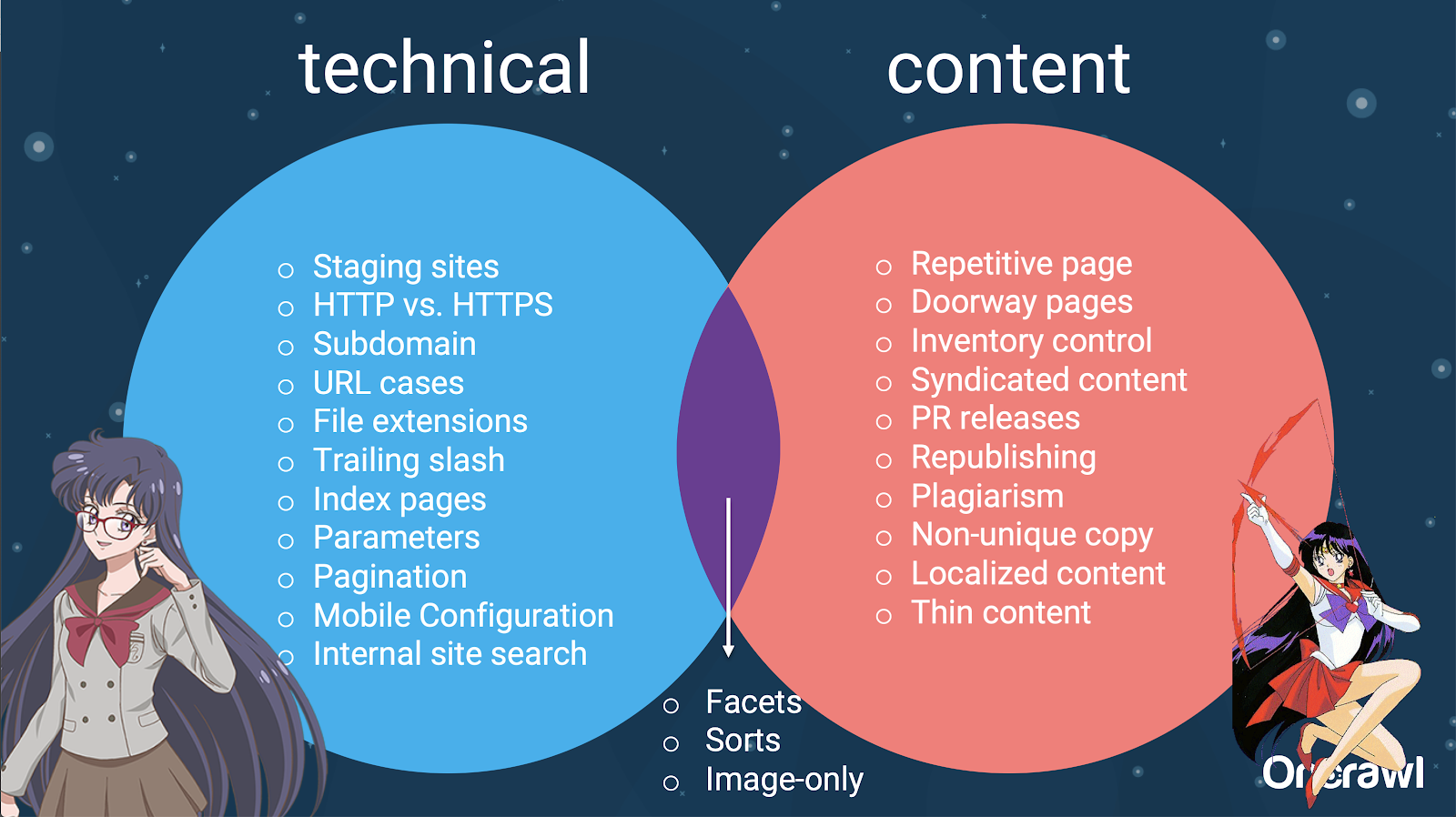
Это делает дублирование контента межкомандной проблемой, что отчасти делает его таким интересным.
Как найти дублированный контент
Большая часть дублированного контента является непреднамеренной. Для Оми это означает, что между контент- и технической группами есть общая ответственность за поиск и исправление дублирующегося контента.
– Любимый инструмент Оми: Grammarly
Grammarly — любимый инструмент Оми для поиска дублирующегося контента, и это даже не инструмент SEO. Он использует проверку на плагиат. Он просит издателя контента проверить, не публиковался ли уже новый контент где-либо еще.
– Объем непреднамеренного дублированного контента
Проблема непреднамеренного дублирования контента хорошо знакома инженерам. В книге «Введение в поиск информации» (2008 г.), которая явно сильно устарела, они подсчитали, что около 40% Интернета в то время было дублировано.

– Приоритизация стратегий борьбы с дублирующимся контентом
Чтобы справиться с дублирующимся контентом, вам необходимо:
- Начните с изучения своего пользовательского пути, который поможет вам понять, где подходит каждый фрагмент контента. Это может быть чрезвычайно трудно сделать, особенно когда веб-сайты были созданы 20 лет назад, когда мы не знали, насколько большими они станут или как они будут масштабироваться. Знание того, где находится ваш пользователь в любой момент своего путешествия, поможет вам расставить приоритеты на некоторых следующих шагах.
- Вам понадобится работающая иерархия, чтобы обеспечить место для каждого типа контента. Понимание вашей информационной архитектуры очень важно на этапе борьбы с дублирующимся контентом.
- Приоритизируйте повторяющийся контент, который влияет на производительность. Приведенный выше неполный список источников слишком длинный, чтобы вы могли реально атаковать все сразу.
- Борьба со 100% дублированием
- Сигнализировать о дублирующемся содержании
- Сделайте стратегический выбор того, как справляться с дублированием: консолидировать, создавать, удалять, оптимизировать
- Работа с украденным контентом

– Инструменты: Использование сегментации в OnCrawl
Алексису очень нравится возможность сегментировать ваш сайт в OnCrawl, что позволяет вам погрузиться в значимые для вас вещи.
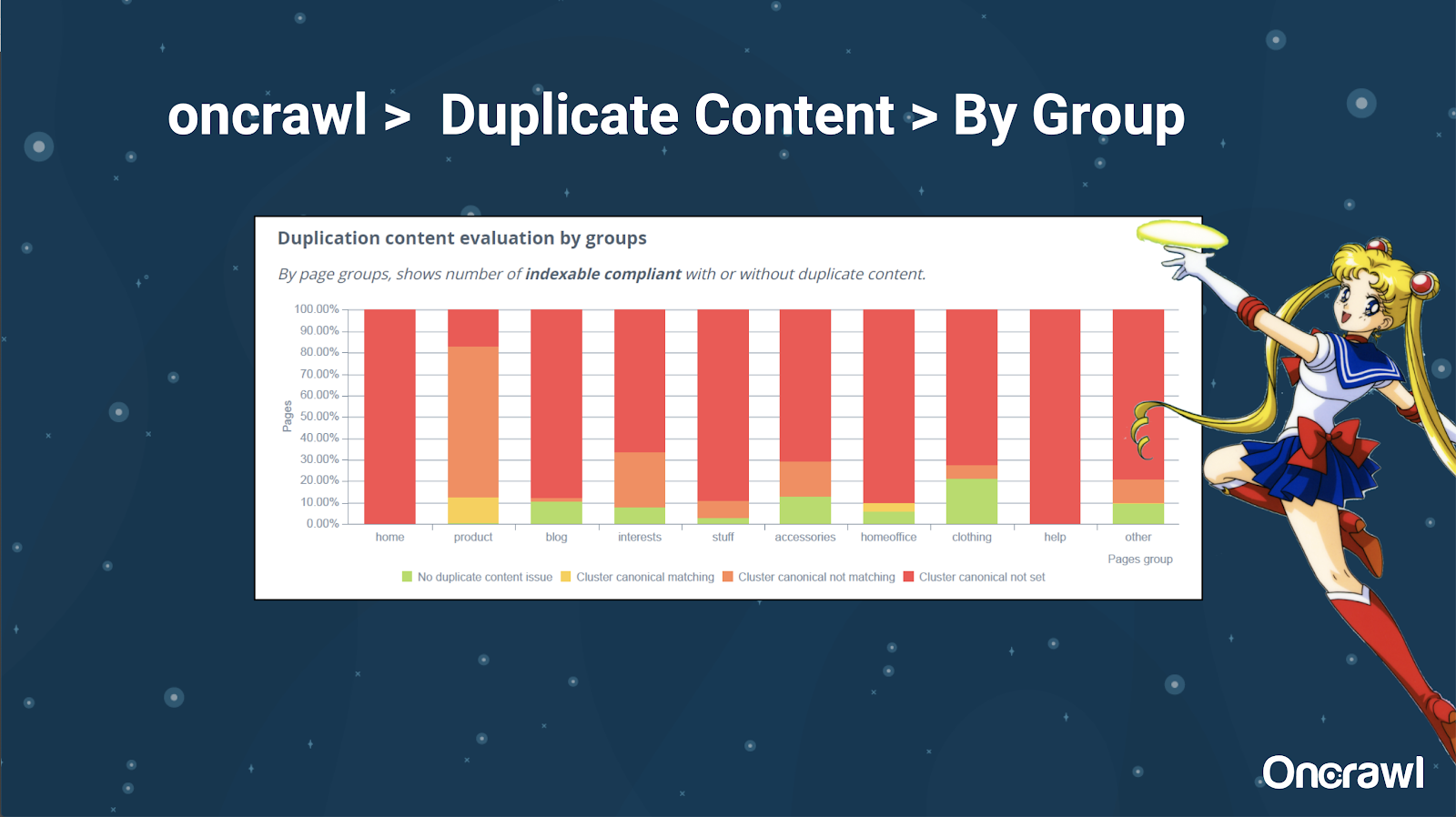
Страницы разных типов имеют разную степень дублирования; это позволяет получить представление о разделах с наибольшим количеством проблем. В приведенном выше примере сайт требует много внимания.
– Инструменты: поиск Google и GSC
Вы также можете проверить дублированный контент с помощью самой поисковой системы. В Гугле можно:
- Используйте прямые кавычки
- Использовать сайт: поиск
- Используя дополнительные операторы, такие как inurl:, intitle: или тип файла:

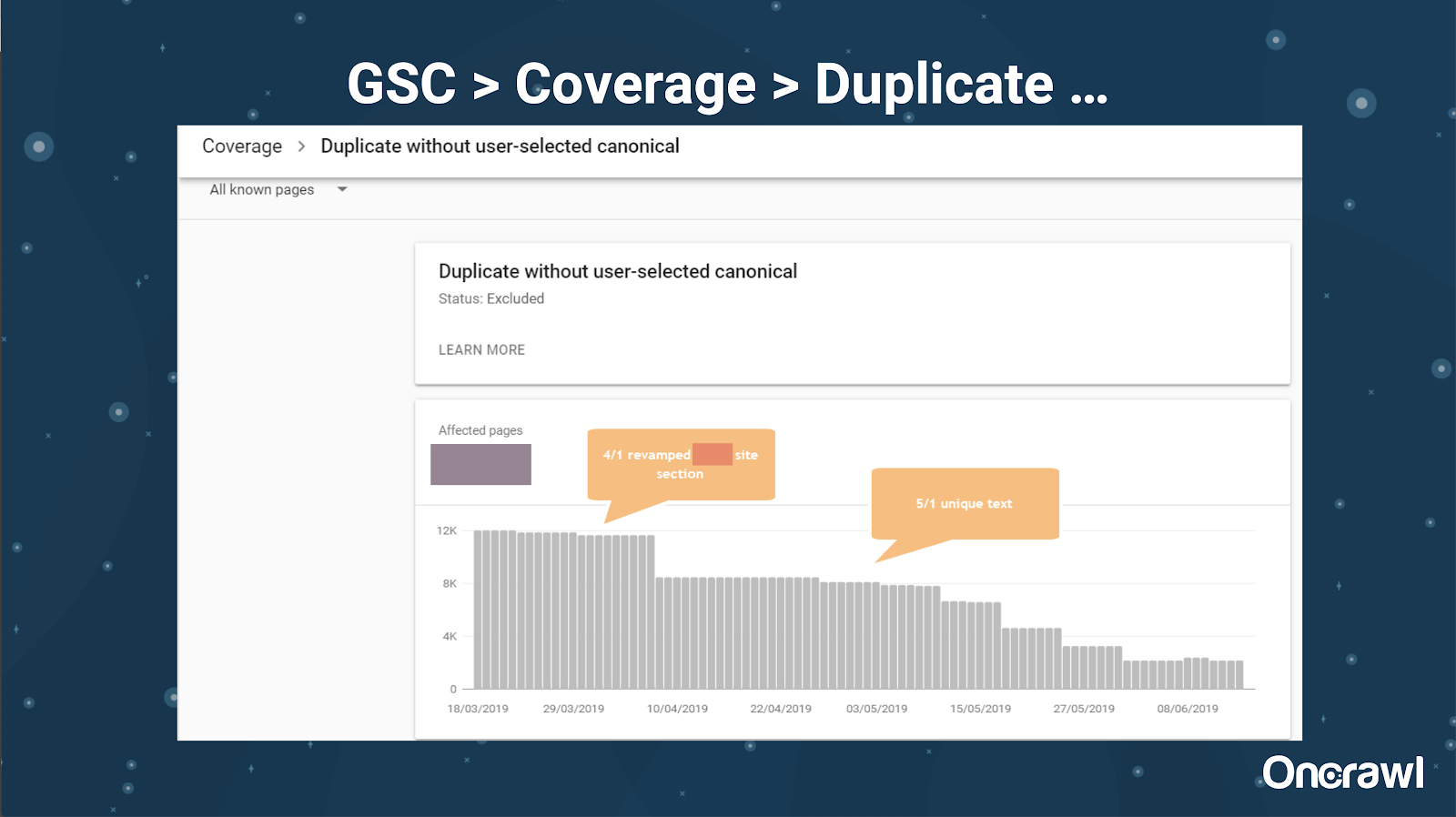
Консоль поиска Google также добавила отчет о дублирующемся контенте, который очень полезен для определения того, что Google считает дублирующим контентом со своей стороны.
– Инструменты: инструменты плагиата
Как и Оми, Алексис также использует различные инструменты для борьбы с плагиатом:
Квест
Noplag
PaperRater
грамматически
Копискейп
Вы хотите убедиться, что ваш контент не только оригинален, но и с точки зрения бота, что он не воспринимается как взятый из другого источника.
Это также может помочь вам найти сегменты в статье, которые могут быть похожи на контент в других местах в Интернете.
Алексис нравится, что у нас есть эти инструменты, которые позволяют нам быть «чуткими к ботам поисковых систем», поскольку никто из нас не робот. Когда инструменты дают нам сигналы о том, что контент слишком похож, даже если мы знаем, что есть разница, это хороший признак того, что здесь есть что покопаться.
– Инструменты: инструменты плотности ключевых слов
Два примера инструментов плотности ключевых слов, которые использует Алексис:
ТегТолпа
SEOкнига

Проблемы, зависящие от типа сайта
Устранение повторяющегося контента действительно зависит от типа контента, который вы публикуете, и типа проблемы, с которой вы сталкиваетесь. Например, блоги не сталкиваются с теми же случаями дублирования контента, что и сайты электронной коммерции.
Памятные случаи
Алексис делится недавними делами клиентов, в которых она обнаружила запоминающиеся проблемы с дублированием контента.
– Очень большой сайт: результаты после добавления уникального контента
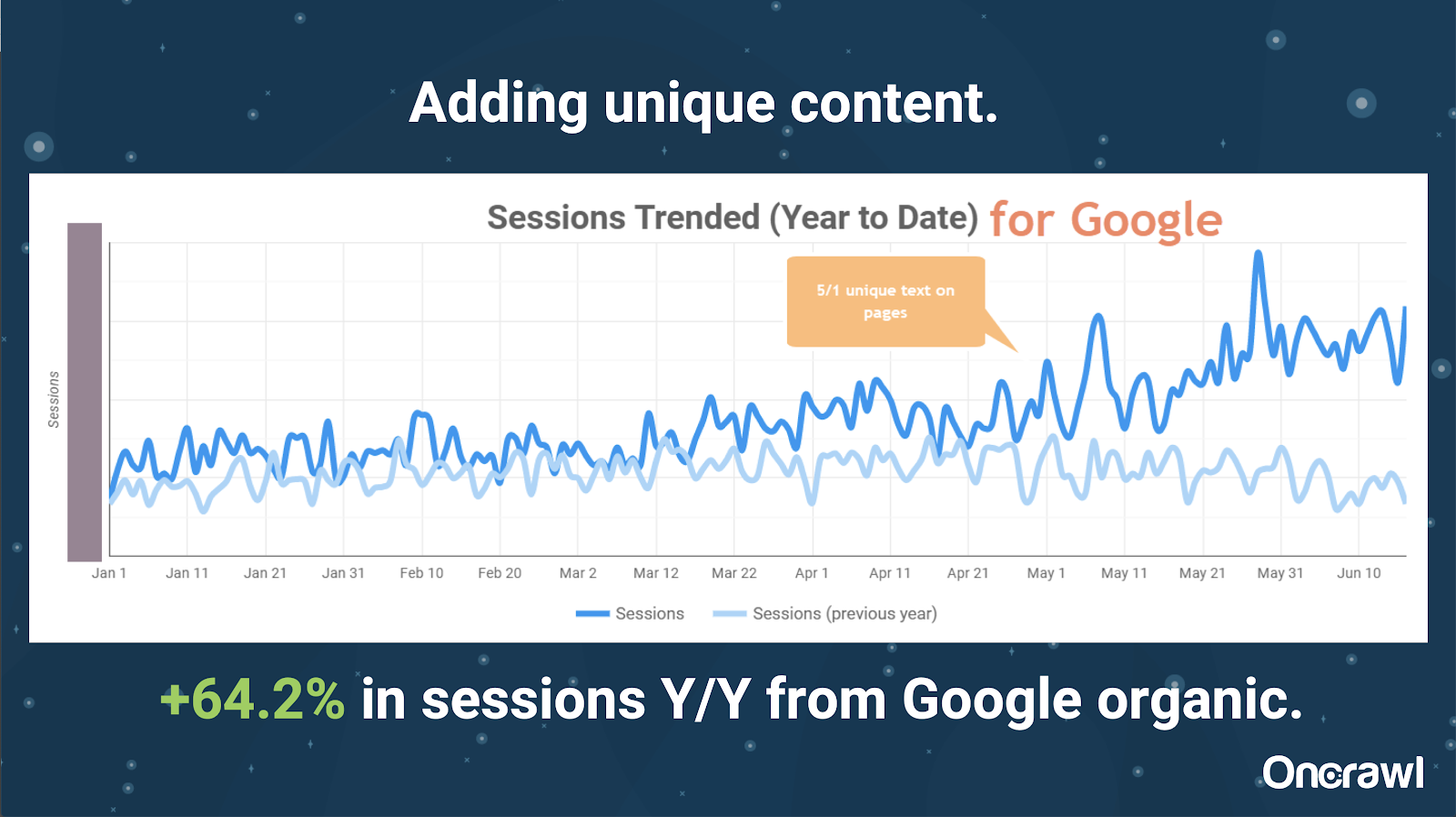
Этот сайт был очень большим и столкнулся с проблемами краулингового бюджета. У него 86 миллионов страниц, которые еще не проиндексированы, и только около 1% его страниц были проиндексированы.
Это сайт недвижимости, поэтому большая часть контента не особенно уникальна, и многие их страницы очень и очень похожи. Алексис закончил тем, что добавил контент на страницу, чтобы добавить информацию о местоположении, чтобы различать страницы. Удивительно, как быстро это дало результаты. (Это просто органические данные Google.)
Для Алексис это довольно общий пример. Сколько бы мы ни говорили сегодня о EAT и подобных вещах, это демонстрирует, что, как только поисковые системы считают контент уникальным и ценным, он все равно вознаграждается.

На этом сайте случайная проблема с каноническим тегом привела к тому, что около 250 страниц были отправлены по неправильному протоколу.
Это один из случаев, когда канонические теги указывают на неправильную основную страницу, подталкивая страницы HTTP вместо страницы HTTPS.
Изменения за последние 18 месяцев
Алексис написала очень полную статью «Дублированный контент и стратегическое решение» примерно за 18 месяцев до этого вебинара. SEO быстро меняется, и вам постоянно нужно обновлять и переоценивать свои знания.
Для Алексиса большая часть того, что упоминается в статье, актуальна и сегодня, за исключением rel=next/prev. Однако она надеется, что в ближайшие пять-десять лет это перестанет быть актуальным.
Технические вопросы решаются разработчиками: слишком ручной
Многие проблемы, связанные с дублированием контента, решаются разработчиками слишком вручную. Алексис считает, что ими должны заниматься CMS и Adobe. Например, вам не нужно проходить вручную и убеждаться, что все канонические значения установлены и согласованы.
– Возможности автоматизации/уведомления
Существует много возможностей для автоматизации в области технических проблем с дублирующимся контентом. Чтобы привести пример: мы должны быть в состоянии немедленно определить, идут ли какие-либо ссылки на HTTP, когда они должны идти на HTTPS, и исправлять их.
– Возраст сайта и устаревшая инфраструктура как помеха
Некоторые серверные системы слишком устарели, чтобы поддерживать определенные изменения и средства автоматизации. Мигрировать старую CMS на новую крайне сложно. Оми приводит пример переноса веб-сайтов Canon на новую, специально созданную CMS. Это было не только дорого, но и заняло у них 12 месяцев.
Предыдущая/следующая версия и сообщение от Google
Иногда общение с Google немного сбивает с толку. Оми приводит пример, когда при применении rel=prev/next его клиент увидел значительное увеличение производительности в 2018 году, несмотря на объявление Google в 2019 году о том, что эти теги не использовались годами.
- Отсутствие универсальных решений.
Сложность с SEO заключается в том, что то, что один человек наблюдает на своем веб-сайте, не обязательно совпадает с тем, что другой SEO видит на своем собственном веб-сайте; не существует универсального SEO.
Способность Google делать объявления, которые имеют отношение ко всем SEO-специалистам, следует признать большим достижением, даже если некоторые из их заявлений являются промахом, как в случае с rel=next/prev.
Надежды на будущее управления дублирующимся контентом
Надежды Алексея на будущее:
- Меньше технического дублирования контента (по мере развития CMS).
- Больше автоматизации (модульное тестирование и внешнее тестирование). Например, такие инструменты, как OnCrawl, могут регулярно сканировать ваш сайт и уведомлять вас, как только заметят определенные ошибки.
- Автоматически определяйте страницы и типы страниц с высоким уровнем сходства для авторов и менеджеров контента. Это позволит автоматизировать некоторые проверки, которые в настоящее время выполняются вручную в таких инструментах, как Grammarly: когда кто-то пытается опубликовать, CMS должна сказать: «Это похоже на то, что вы уверены, что хотите опубликовать это?» Очень полезно смотреть на отдельные веб-сайты, а также сравнивать их между собой.
- Google продолжают совершенствовать свои существующие системы и средства обнаружения.
- Возможно, система оповещения для эскалации проблемы Google не использует правильный канонический. Было бы полезно иметь возможность предупредить Google о проблеме и решить ее.
Нам нужны лучшие инструменты, лучшие внутренние инструменты, но, надеюсь, по мере того, как Google будет развивать свои системы, они добавят элементы, которые нам немного помогут.
Любимые технические трюки Алексис
У Алексиса есть несколько любимых технических приемов:
- Экземпляр удаленного компьютера EC2. Это действительно отличный способ получить доступ к реальному компьютеру для очень больших обходов или всего, что требует большой вычислительной мощности. Это очень быстро, как только вы его настроите. Просто убедитесь, что вы прекратили его, когда закончите, так как это стоит денег.
- Проверьте инструмент тестирования Mobile First. Google упомянул, что это наиболее точная картина того, на что они смотрят. Он смотрит на DOM.
- Переключите пользовательский агент на Googlebot. Это даст вам представление о том, что на самом деле видят роботы Google.
- Использование инструмента robots.txt от TechnicalSEO.com. Это один из инструментов Меркла, но Алексис действительно любит его, потому что robots.txt иногда может быть очень запутанным.
- Используйте анализатор логов.
- Сделано с помощью программы проверки htaccess от Love.
- Использование Google Data Studio для отчетов об изменениях (синхронизация Таблиц с обновлениями, фильтрация каждой страницы по релевантным обновлениям).
Технические трудности SEO: robots.txt
Robots.txt действительно сбивает с толку.
Это архаичный файл, который выглядит так, будто должен поддерживать RegEx, но не поддерживает.
Он имеет разные правила приоритета для запрещающих и разрешающих правил, что может привести к путанице.
Разные боты могут игнорировать разные вещи, даже если не должны.
Ваши предположения о том, что правильно, не всегда верны.

вопросы и ответы
– HSTS: требуется ли раздельный протокол?
У вас должен быть весь HTTPS для дублированного контента, если у вас есть HSTS.
– Дублируется ли переведенный контент?
Часто, когда вы используете hreflang, вы используете его для устранения неоднозначности между локализованными версиями на одном языке, например, на американской и ирландской англоязычных страницах. Алексис не стала бы рассматривать этот дублированный контент, но она определенно рекомендовала бы убедиться, что ваши теги hreflang настроены правильно, чтобы указать, что это один и тот же опыт, оптимизированный для разных аудиторий.
– Можно ли использовать канонические теги вместо переадресации 301 для миграции HTTP/HTTPS?
Было бы полезно проверить, что на самом деле происходит в поисковой выдаче. Инстинкт Алексис подсказывает, что все будет в порядке, но все зависит от того, как на самом деле ведет себя Google. В идеале, если это одна и та же страница, вы бы хотели использовать 301, но она видела, что канонические теги в прошлом работали для этого типа миграции. Она даже видела, как это случайно произошло.
По опыту Оми, он настоятельно рекомендует использовать 301, чтобы избежать проблем: если вы переносите веб-сайт, вы можете перенести его правильно, чтобы избежать текущих и будущих ошибок.
- Эффект дублирования заголовков страниц
Допустим, у вас есть название, которое очень похоже для разных мест, но содержание очень разное. Хотя для Алексис это не дублированный контент, она считает, что поисковые системы относятся к этому как к «общему» типу, а заголовки — это то, что можно использовать для выявления областей с возможными проблемами.
Здесь вы можете использовать поиск [site: + intitle: ].
Однако только потому, что у вас один и тот же тег заголовка, это не вызовет проблемы с дублированием контента.
Вы по-прежнему должны стремиться к уникальным заголовкам и метаописаниям, даже на разбитых на страницы или других очень похожих страницах. Это связано не с дублированием контента, а скорее с желанием оптимизировать то, как вы представляете свои страницы в поисковой выдаче.
Верхний совет
«Дубликат контента — это проблема как техническая, так и контент-маркетинговая».
SEO на Орбите ушло в космос
Если вы пропустили наш полет в космос 27 июня, поймайте его здесь и узнайте все советы, которые мы отправили в космос.