
Использование Python и файлов Sitemap для аудита контент-стратегий
Опубликовано: 2020-10-08Интерес к тому, что можно сделать от имени SEO с библиотеками Python, больше не является секретом. Однако у большинства людей с небольшим опытом программирования возникают трудности с импортом и использованием большого количества библиотек или отправкой результатов, которые выходят за рамки того, что может сделать любой обычный поисковый робот или инструмент SEO.
Вот почему библиотека Python, созданная специально для SEO, SEM, SMO, проверки SERP и анализа контента, полезна для всех.
В этой статье мы рассмотрим несколько вещей, которые можно сделать с помощью библиотеки Python Advertools для SEO, созданной и разработанной Элиасом Даббасом, и для которых я вижу большой потенциал в SEO, PPC и возможностях кодирования. в очень короткое время. Кроме того, мы будем использовать пользовательские сценарии Python вместе с другими библиотеками Python в образовательных и адаптивных целях.
Мы собираемся изучить, что можно узнать для SEO из карты сайта благодаря функции sitemap_to_df Элиаса Даббаса, которая помогает загружать и анализировать карты сайта в формате XML (карта сайта — это документ в формате XML, используемый для сообщения поисковым системам об сканируемых и индексируемых URL-адресах).
Эта статья покажет вам, как вы можете писать собственные коды Python для анализа различных веб-сайтов в соответствии с их различной структурой, как интерпретировать данные с точки зрения SEO и как мыслить как поисковая система, когда речь идет о профилях контента, URL-адресах и структурах сайта. .
Анализ масштаба контента и стратегии веб-сайта на основе его карты сайта
Карта сайта — это компонент веб-сайта, который может собирать различные типы данных, например, как часто веб-сайт публикует контент, категории контента, даты публикации, информацию об авторе, тему контента…
В обычных условиях вы можете очистить карту сайта с помощью scrapy, преобразовать ее в DataFrame с помощью Pandas и, если хотите, интерпретировать ее с помощью множества различных вспомогательных библиотек.
Но в этой статье мы будем использовать только Advertools и некоторые методы и атрибуты библиотеки Pandas. Некоторые библиотеки будут активированы для визуализации полученных нами данных.
Давайте углубимся и выберем веб-сайт, чтобы использовать его карту сайта, чтобы сделать некоторые важные выводы о SEO.
Извлечение и создание фреймов данных из файлов Sitemap с помощью Advertools
В Advertools вы можете обнаруживать, просматривать и комбинировать все карты сайта веб-сайта с помощью всего одной строки кода.
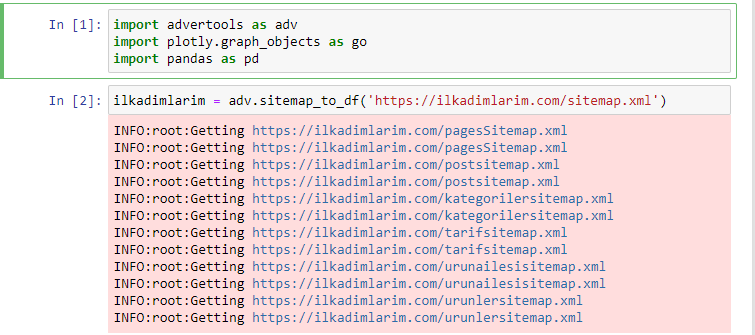
Мне нравится использовать Jupyter Notebook вместо обычного редактора кода или IDE.
В первую ячейку мы импортировали Pandas и Advertools для сбора и организации данных и Plotly.graph_objects для визуализации данных.
Команда adv.sitemap_to_df('адрес карты сайта') просто собирает все карты сайта и объединяет их в виде DataFrame.
Если вы сделаете то же самое с помощью Pandas и Advertools, вы сможете узнать, какой URL-адрес доступен в какой карте сайта.
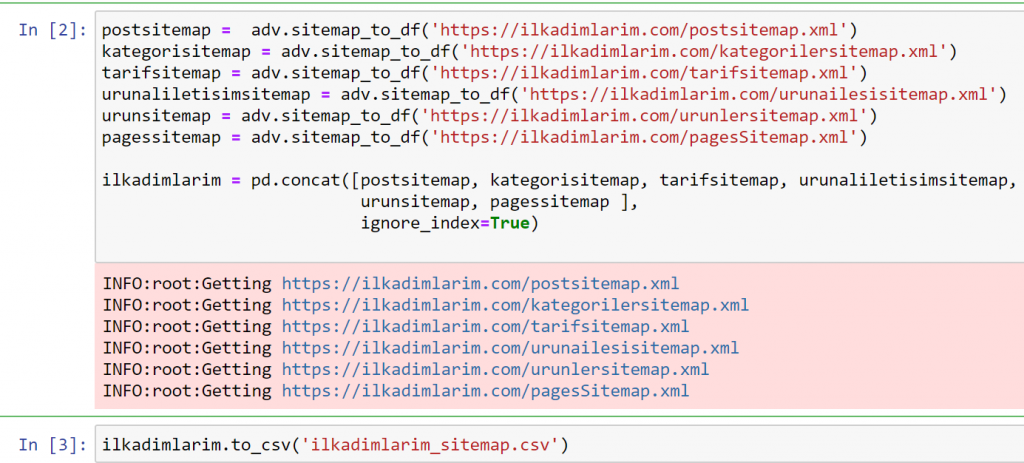
В приведенном выше примере мы извлекли те же карты сайта по отдельности, а затем объединили их с помощью команды pd.concat и передали результат в CSV. В предыдущем примере использовался файл индекса карты сайта, и в этом случае функция получает все остальные карты сайта. Таким образом, у вас есть возможность выбрать определенные карты сайта, как мы сделали здесь, если вас интересует определенный раздел веб-сайта.
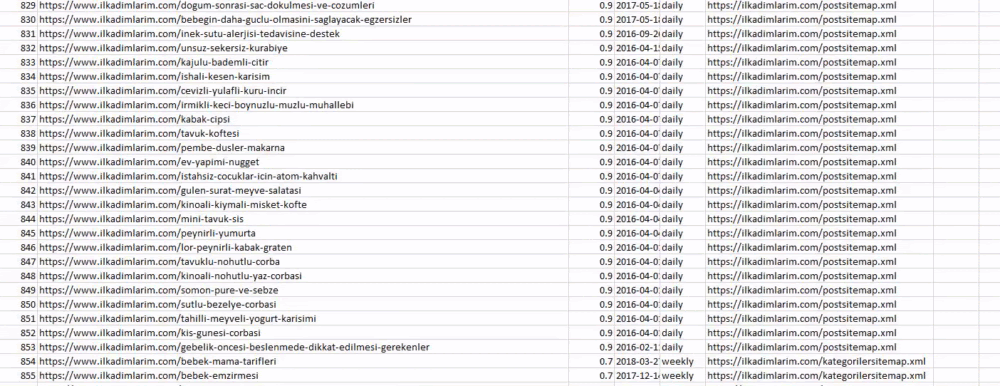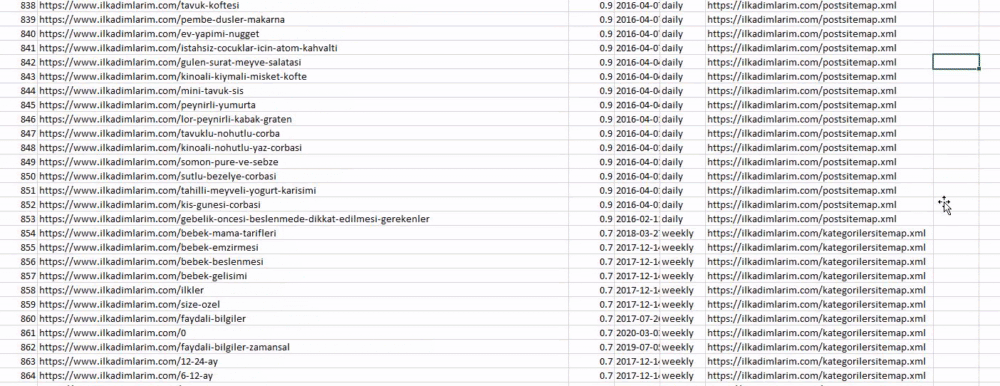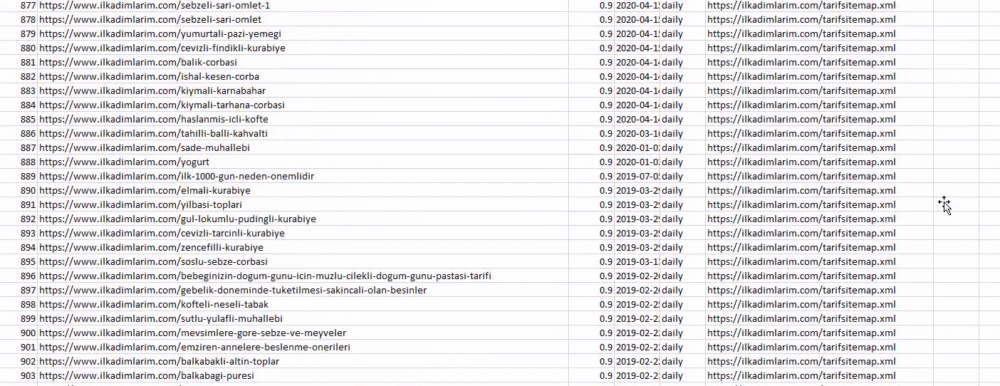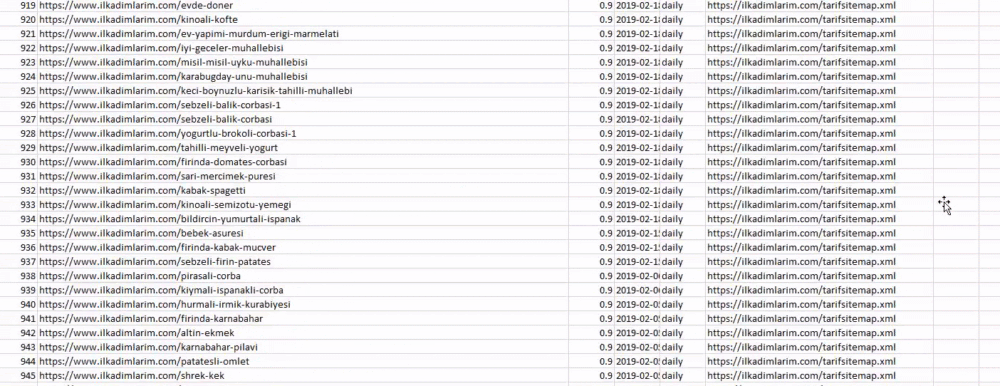
Вы можете увидеть столбец с разными названиями карты сайта выше. ignore_index=True предназначен для аккуратного упорядочения номеров индексов разных фреймов данных, если вы объединили несколько фреймов вместе.
Данные при сканировании³
 Учить больше
Учить большеОчистка и подготовка фрейма данных Sitemap для анализа контента с помощью Python
Чтобы понять профиль контента веб-сайта с помощью карты сайта, нам нужно подготовить ее, чтобы просмотреть DataFrame, который мы получили с помощью Advertools.
Мы будем использовать некоторые основные команды из библиотеки Pandas для формирования наших данных:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop (столбцы = 'Безымянный: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
«Ilkadimlarim» в переводе с турецкого означает «мои первые шаги», и, как вы понимаете, это сайт о детях, беременности и материнстве.
Мы выполнили три операции с этими линиями.
- Безымянные: Мы удалили пустой столбец с именем 0 из DataFrame. Кроме того, если вы используете «index = False» с функцией pd.to_csv() , вы не увидите этот столбец «Безымянный 0» в начале.
- Мы преобразовали данные в столбце «Последнее изменение» в дату и время.
- Мы вывели столбец «lastmod» на индексную позицию.
Ниже вы можете увидеть окончательную версию DataFrame.
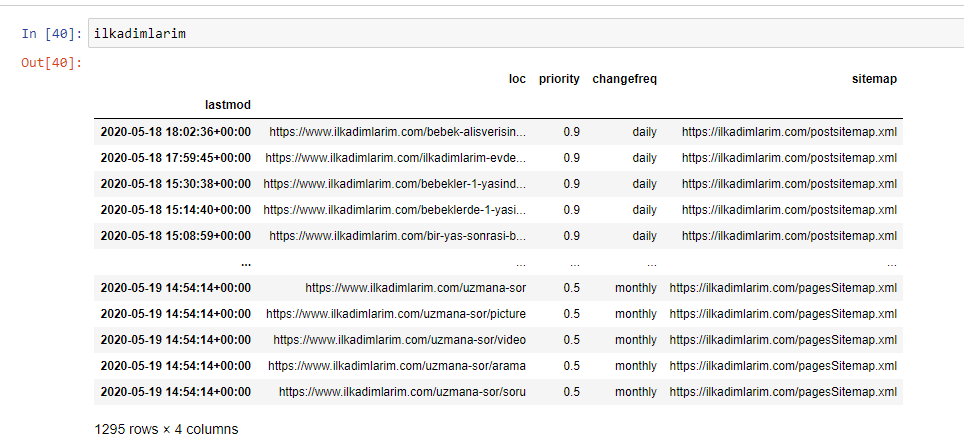
Мы знаем, что Google не использует информацию о приоритете и частоте изменений из карт сайта. Они называют это «мешком шума». Но если вы придаете большое значение производительности вашего веб-сайта для других поисковых систем, вам может быть полезно изучить и их. Лично меня эти данные мало волнуют, но удалять их из DataFrame мне все равно не нужно.
Нам нужна еще одна строка кода для категоризации карт сайта в другом столбце.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
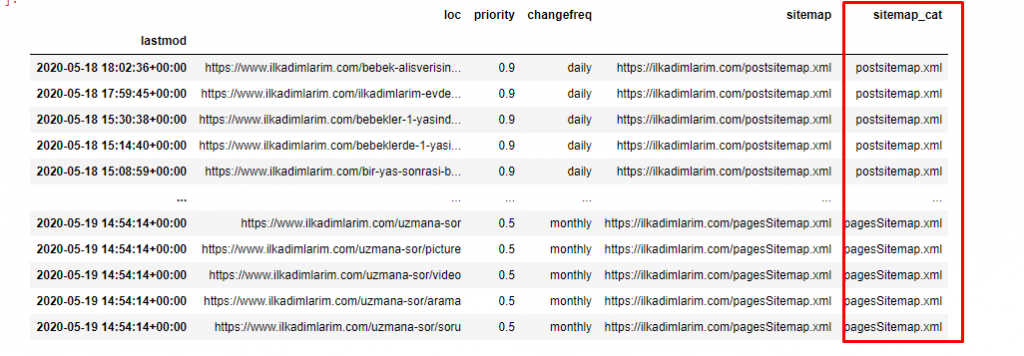
В Pandas вы можете добавлять новые столбцы или строки в DataFrame или легко обновлять их. Мы создали новый столбец с фрагментом кода DataFrame['new_columns'] . DataFrame['column_name'].str позволяет нам выполнять различные операции, изменяя тип данных в столбце. Мы делим строковые данные в столбце, относящемся к .split ('/'), на символ / и помещаем их в список. С помощью .str [число] мы создаем содержимое нового столбца, выбирая определенный элемент в этом списке.
Анализ профиля контента по количеству и видам карты сайта
Поместив карты сайта в разные столбцы в соответствии с их типами, мы можем проверить, какой процент содержимого содержится в каждой карте сайта. Таким образом, мы также можем сделать вывод о том, какая часть веб-сайта более важна.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] выбирает столбец, который мы хотим сделать процессом.
- value_counts() подсчитывает частоту значений в столбце.
- normalize=True принимает отношение значений в десятичном виде.
- Мы упростили чтение, увеличив десятичные числа на *100.
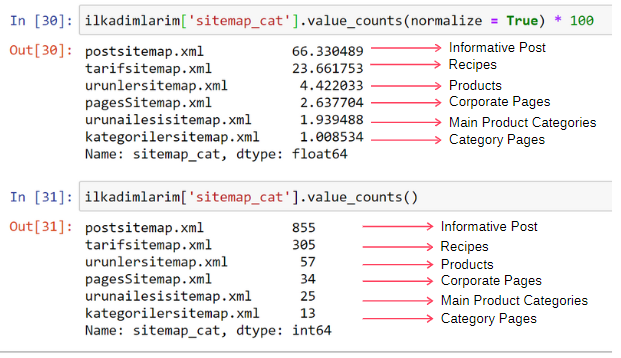
Мы видим, что 65% контента находится в файле Sitemap для сообщений, а 23% — в файле Sitemap для рецептов. Карта сайта продукта содержит только 2% контента.
Это показывает, что у нас есть веб-сайт, который должен создавать информативный контент для широкой аудитории, чтобы продвигать свои собственные продукты. Проверим, верен ли наш тезис.
Прежде чем продолжить, нам нужно изменить имя столбца ilkadimlarim['sitemap_cat'] на «URL_Count» с помощью кода ниже:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- Функция rename() полезна для изменения имени ваших столбцов или индексов для связи данных и их значения на более глубоком уровне.
- Мы изменили имя столбца на постоянное благодаря атрибуту inplace=True .
- Вы также можете изменить стили букв столбцов и индексов с помощью ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . При этом записываются только первые буквы каждого столбца в Ilkadimlarim как заглавные.

Теперь мы можем продолжить.
Чтобы увидеть эту информацию в одном кадре, вы можете использовать следующий код:
(илкадимларим['sitemap_cat']
.value_counts()
.к кадру()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', процент='{:.1%}')))
- to_frame() используется для кадрирования значений, измеренных с помощью value_counts() в выбранном столбце.
- assign() используется для добавления определенных значений во фрейм.
- lambda относится к анонимным функциям в Python.
- Здесь функция Lambda и типы карты сайта делятся на общее количество карт сайта с помощью метода Pandas div() .
- style() определяет, как записываются окончательные указанные значения.
- Здесь мы устанавливаем, сколько цифр записывается после точки с помощью метода format() .
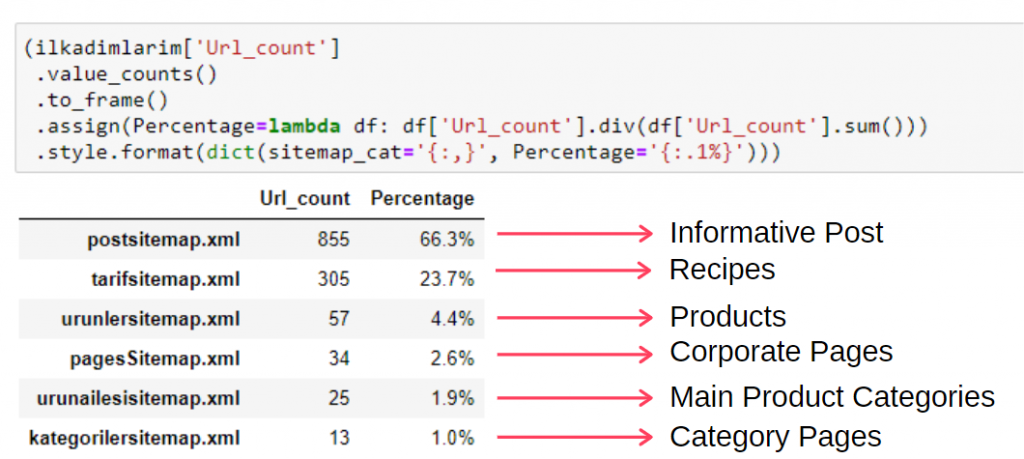
Таким образом, мы видим важность контент-маркетинга для этого сайта. Мы также можем проверить тенденции публикации их статей по годам с помощью двух отдельных строк кода, чтобы более глубоко изучить их ситуацию.
Изучение и визуализация тенденций публикации контента по годам с помощью файлов Sitemap и Python
Мы выполнили сопоставление контента и намерений исследованного веб-сайта в соответствии с категориями карты сайта, но мы еще не сделали временную классификацию. Для этого мы воспользуемся методом resample() .
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample — это метод в библиотеке Pandas. resample('A') проверяет ряд данных для годового DataFrame. В течение нескольких недель вы можете использовать «W», в течение нескольких месяцев вы можете использовать «M».
Loc здесь символизирует индекс; count означает, что вы хотите подсчитать сумму примеров данных.
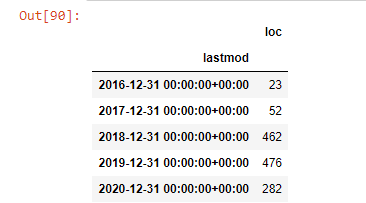
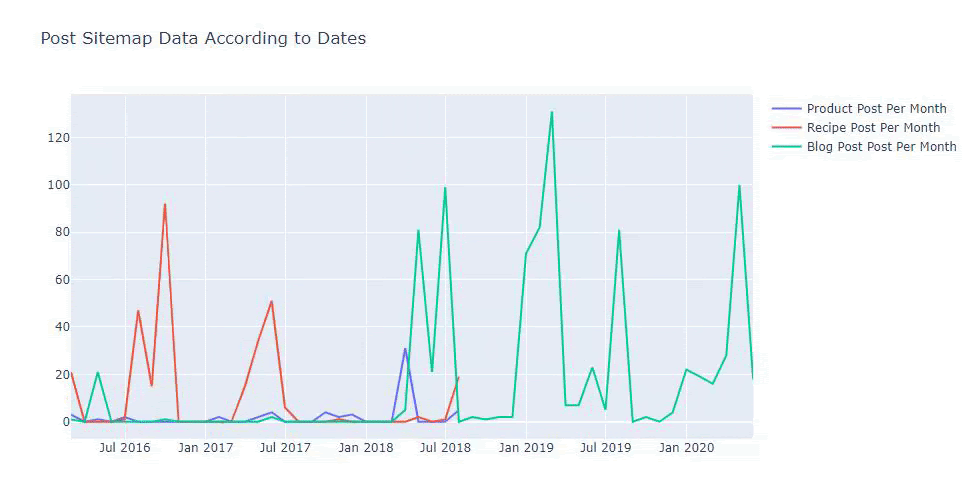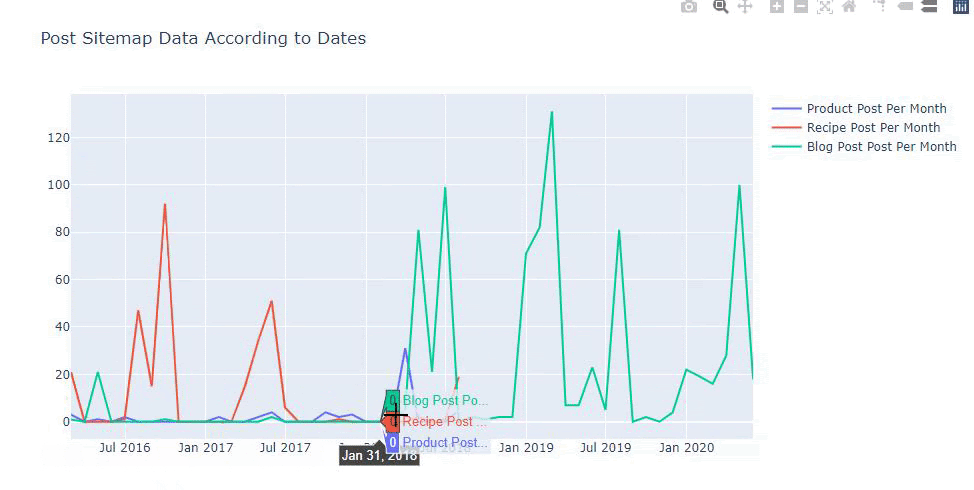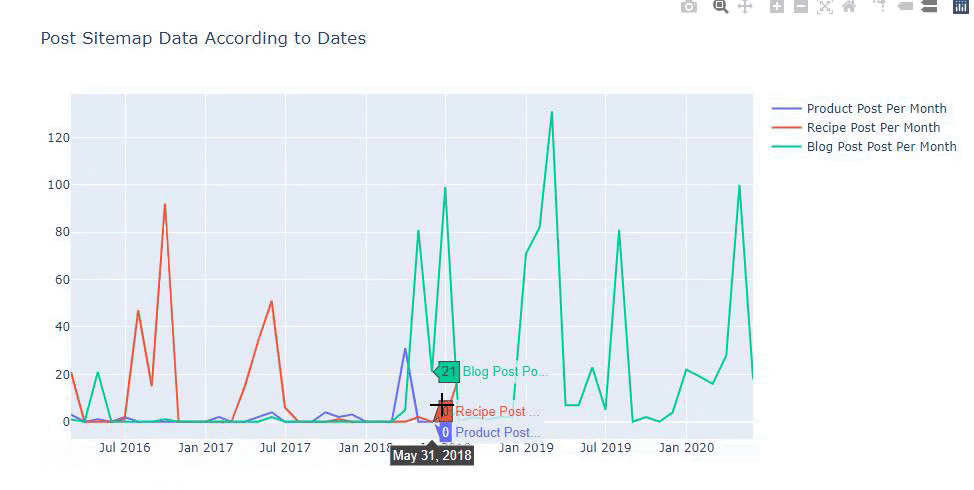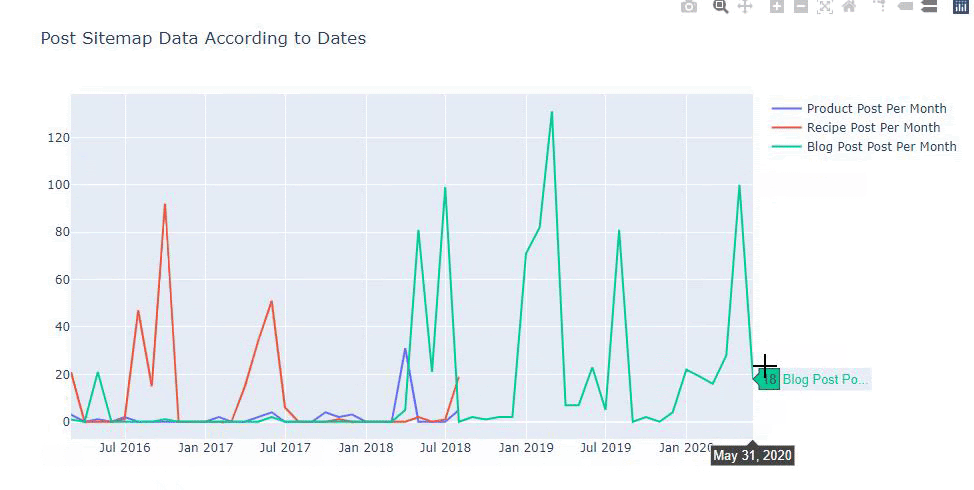
Мы видим, что они начали публиковать статьи в 2016 году, но их основная тенденция публикации увеличилась после 2017 года. Мы также можем изобразить это на графике с помощью объектов Plotly Graph.
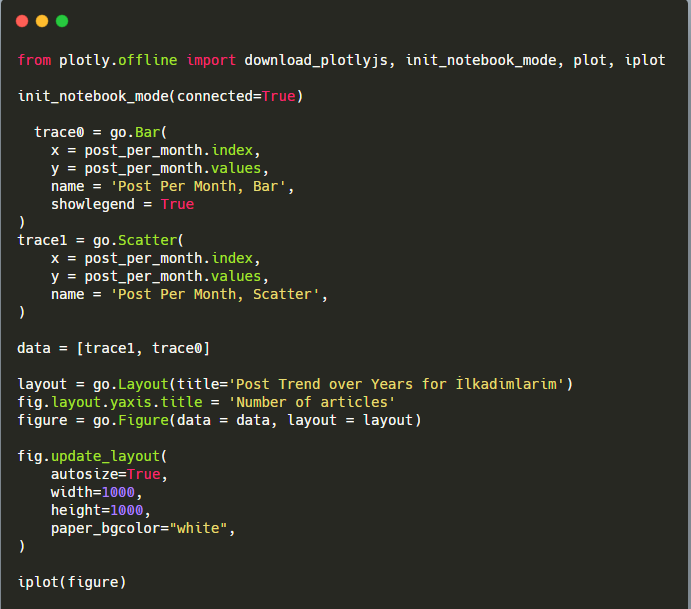
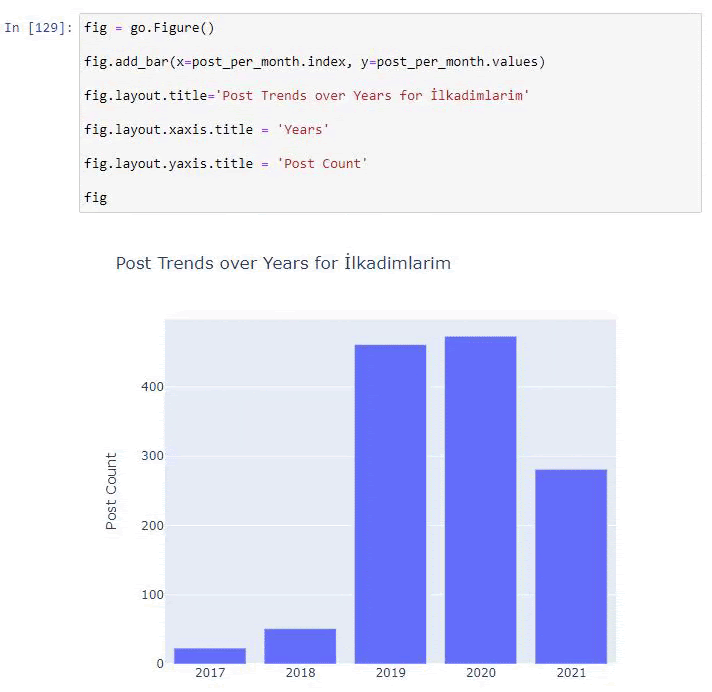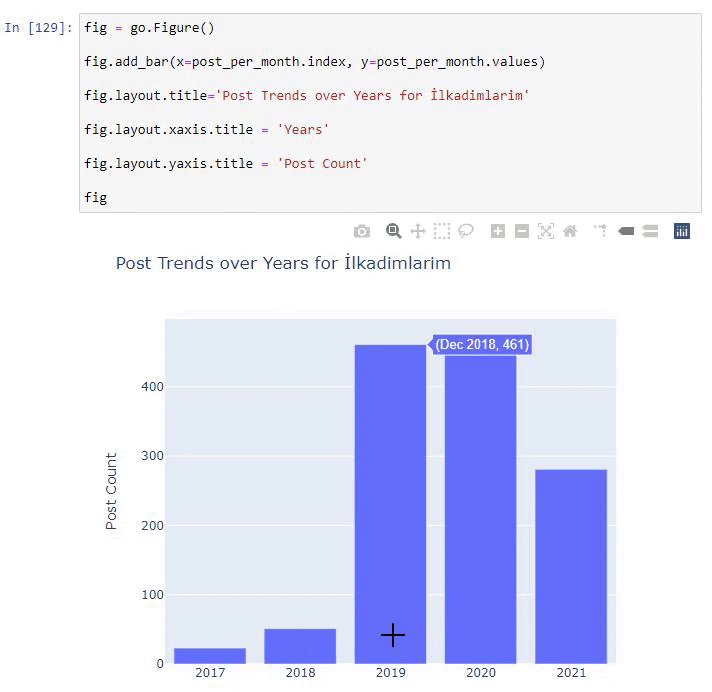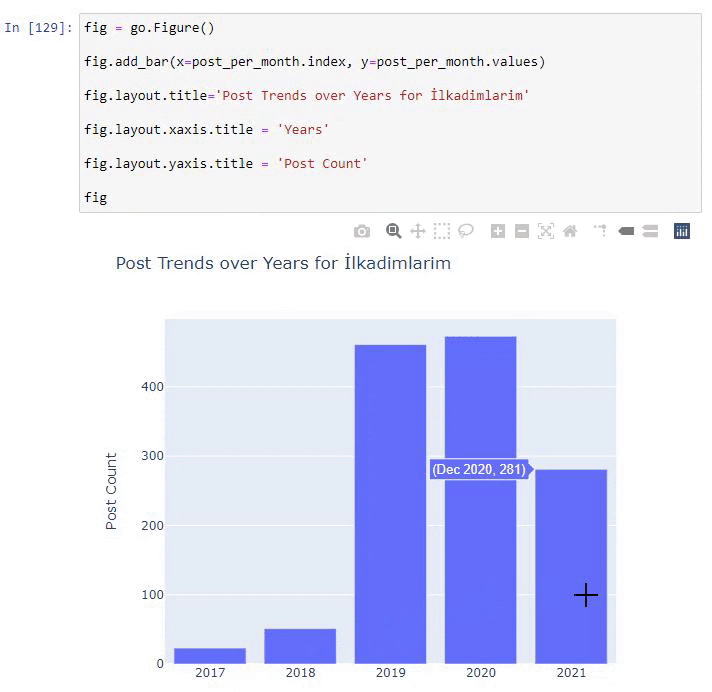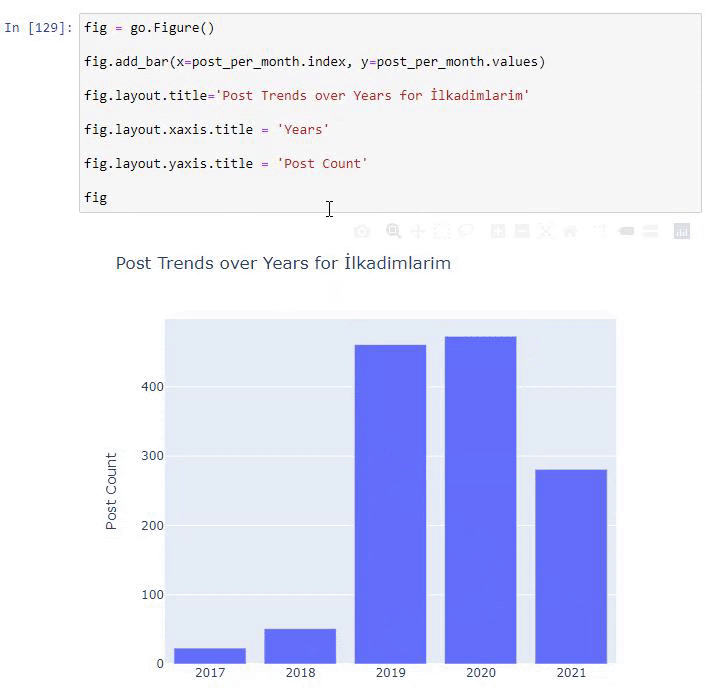
Объяснение этого фрагмента кода Plotly Bar Plot:
- fig = go.Figure() предназначен для создания фигуры.
- fig.add_bar() предназначен для добавления гистограммы на рисунок. Мы также определяем, какие оси X и Y будут в скобках.
- Fig.layout предназначен для создания общего заголовка для фигуры и осей.
- В последней строке мы вызываем график, который мы создали, с помощью команды fig, которая равна go. Figure ()
Ниже вы найдете те же данные по месяцам с диаграммой рассеяния и гистограммой:
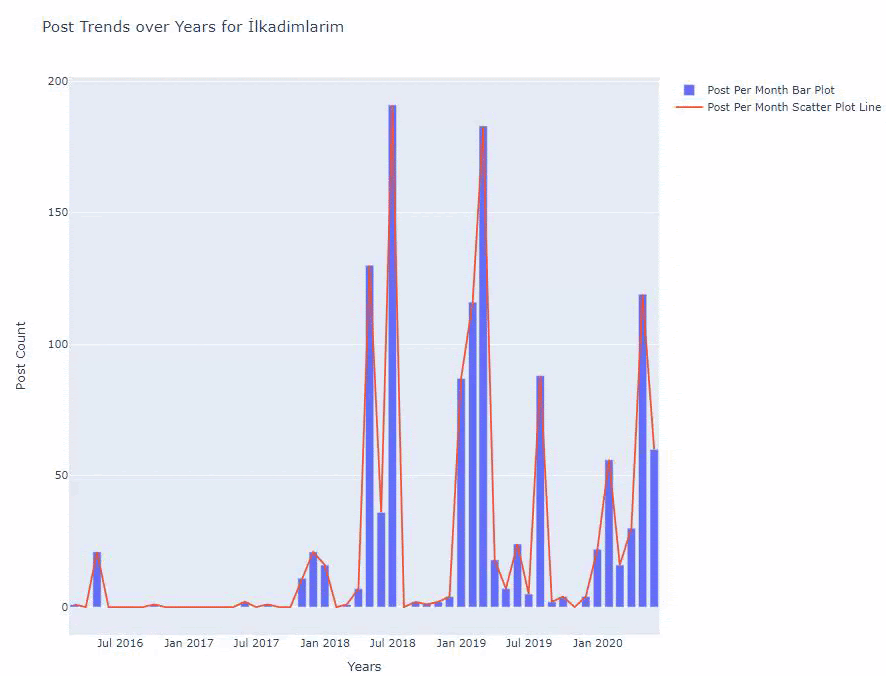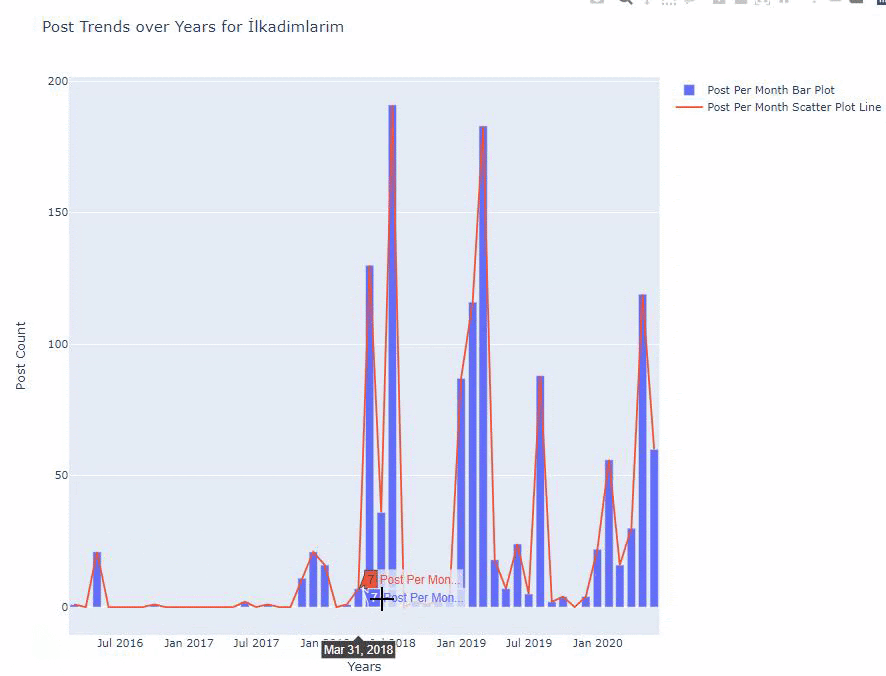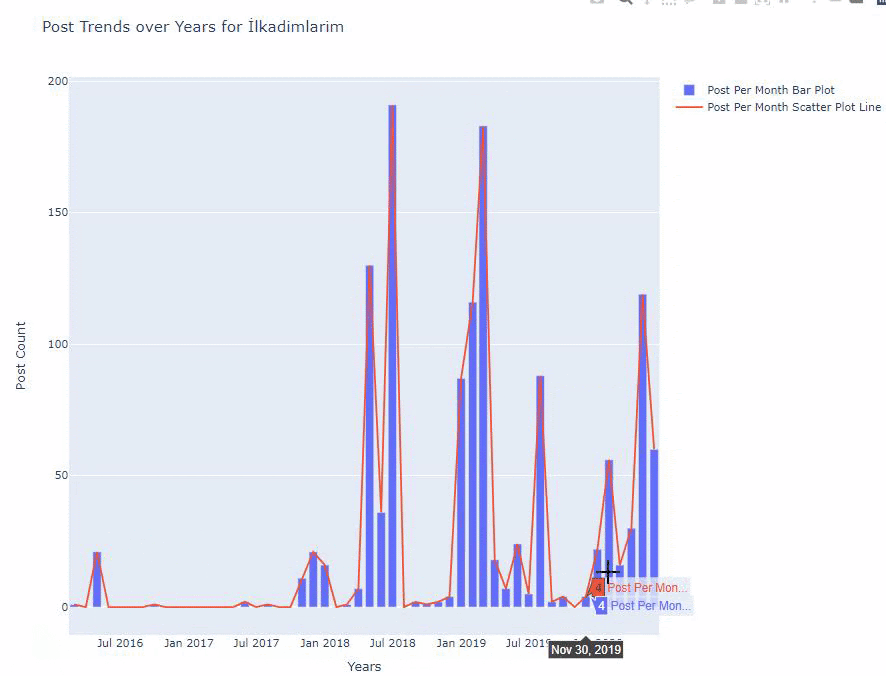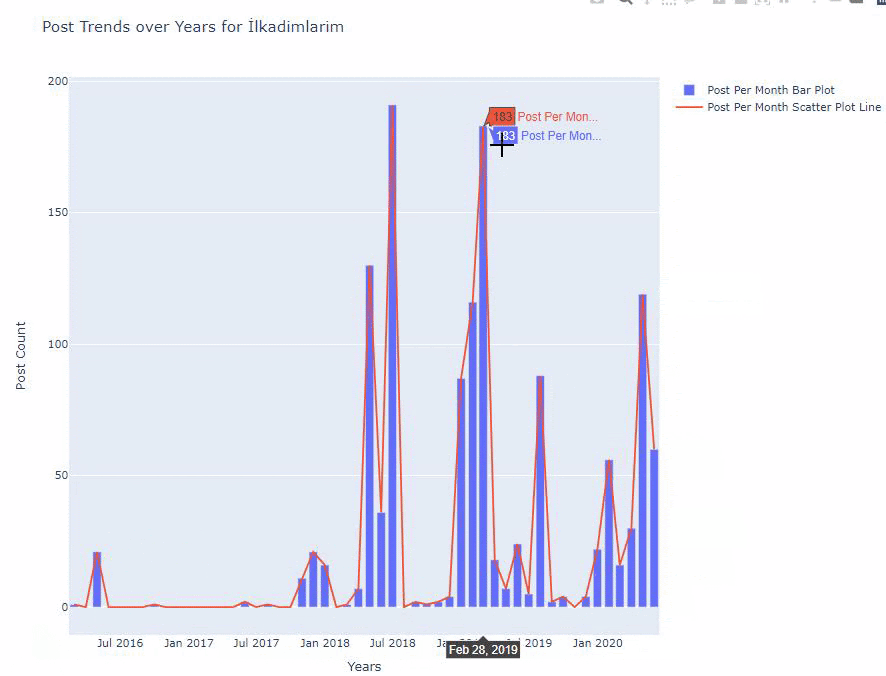
Вот коды для создания этой фигуры:
Мы добавили второй график с помощью fig.add_scatter() , а также изменили имена, используя атрибут name. fig.update_layout() предназначен для изменения размера и цвета фона графика.
Вы также можете изменить режим наведения, расстояние между полосами и многое другое. Я думаю, что достаточно только поделиться кодами, так как объяснение каждого кода здесь по отдельности может заставить нас отойти от основного предмета.
Мы также можем сравнить тенденции публикации контента конкурентов по категориям, как показано ниже:
Эта диаграмма была создана вторым методом, как видите, разницы нет, но один из них достаточно прост.
Чтобы отобразить частоту и тенденцию публикации контента из трех отдельных карт сайта, мы должны поместить карту сайта с самым длинным интервалом на оси X. Таким образом, мы можем сравнить частоту, с которой изучаемый нами веб-сайт публикует каждый тип контента для разных целей поиска.
Когда вы изучите соответствующие коды ниже, вы увидите, что он не сильно отличается от приведенного выше.
Для создания точечной диаграммы с несколькими осями Y вы можете использовать приведенный ниже код.
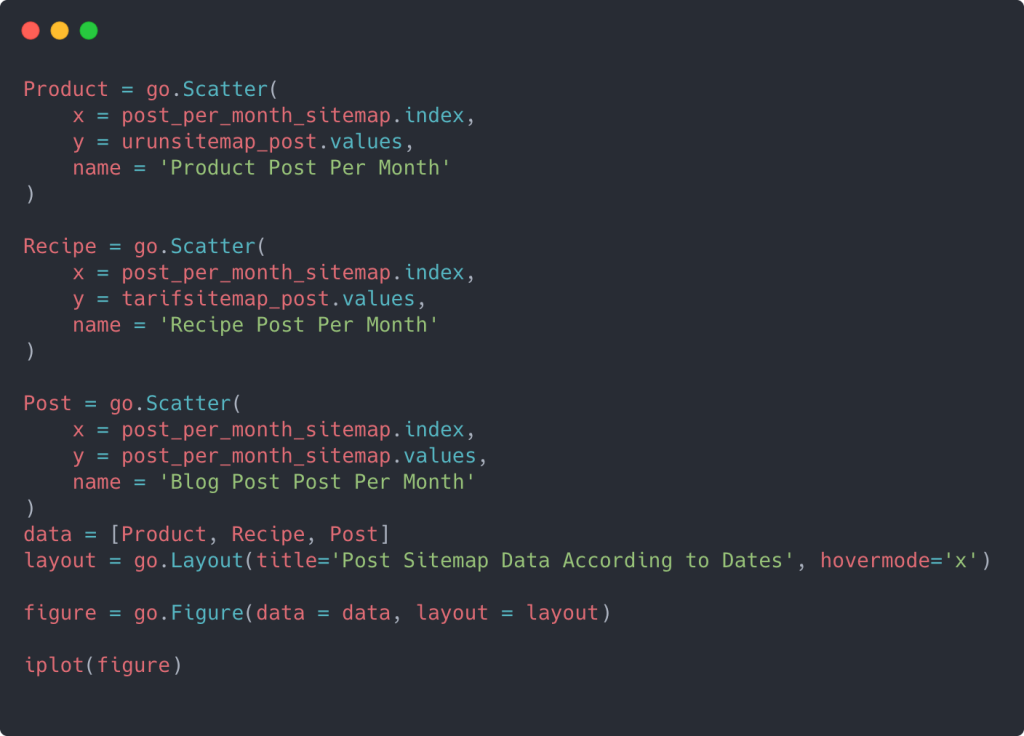
Существуют и другие методы, такие как объединение разных карт сайта и использование цикла for для столбцов, чтобы использовать несколько осей Y в точечной диаграмме, но для такого маленького сайта нам это не нужно. По большей части логичнее было бы использовать этот метод на сайтах с сотнями карт сайта.
Кроме того, поскольку веб-сайт небольшой, графика может выглядеть неглубокой, но, как вы увидите позже в статье о веб-сайте с миллионами URL-адресов, такая графика — отличный способ сравнить разные сайты, а также сравнить разные категории ресурсов. тот же сайт.
Изучение и визуализация категорий контента, намерений и тенденций публикации с помощью файлов Sitemap и Python
В этом разделе мы проверим, написали ли они большое количество контента в конкретной области знаний для продвижения небольшого количества продуктов, о чем мы говорили в начале статьи. Благодаря этому мы можем видеть, есть ли у них контент-партнерство с другими брендами или нет.
Чтобы показать, что еще можно найти на картах сайта, мы продолжим копать дальше. Мы также можем получить некоторую информацию из части «loc» карты сайта, например, другие.
В URL-адресах Ilkadimlarim нет разбивки по категориям. Если веб-сайт имеет разбивку по категориям в своих URL-адресах, мы можем узнать гораздо больше о распространении контента. Если нет, мы можем получить доступ к тем же данным, написав дополнительный код, но с меньшей уверенностью.
На этом этапе вы можете себе представить, насколько менее дорогостоящими становятся разбивки URL-адресов для поисковых систем, которые сканируют миллиарды сайтов, чтобы понять ваш веб-сайт.
a = ilkadimlarim['loc'].str.contains("bebek|hamile|haftalik")
Бебек: детка
Хэмиль: беременна
Хафталик: еженедельно или «недели беременности»
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Метод str() снова позволяет нам установить столбец, в котором мы выбираем определенные операции.
С помощью метода contains() мы определяем данные, чтобы проверить, включены ли они в данные, преобразованные в строку.
Здесь «|» между терминами означает «или» .
Затем мы присваиваем отфильтрованные данные переменной и используем метод resample() , который мы использовали ранее.
С другой стороны, метод count измеряет, какие данные используются и сколько раз.
Результат, полученный с помощью count(), снова заключен в to_frame() .
Кроме того, str.contains() по умолчанию принимает значения Regex, что означает, что вы можете создавать более сложные условия фильтрации с меньшим количеством кода.
Другими словами, на этом этапе мы назначаем URL-адреса, содержащие слова «ребенок», «еженедельно», «беременна», переменной в ilkadimlarim , а затем помещаем дату публикации URL-адресов в соответствующие условия для этого фильтра, который мы создан в рамке.
Затем мы делаем то же самое для URL-адресов, содержащих слово «аптамил». Aptamil — это название продукта для детского питания, представленного Ilkadimlarim. Поэтому мы также можем обратить внимание на плотность трансляции информационного и коммерческого контента.
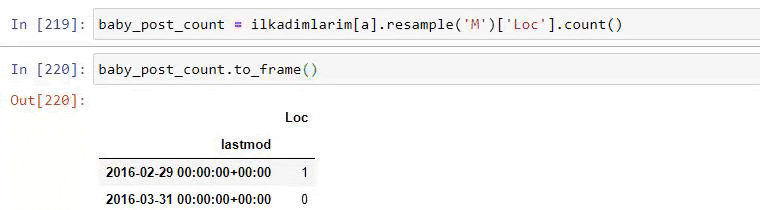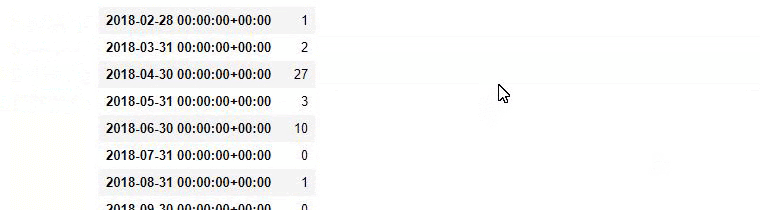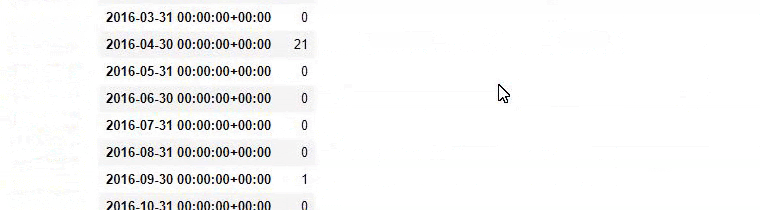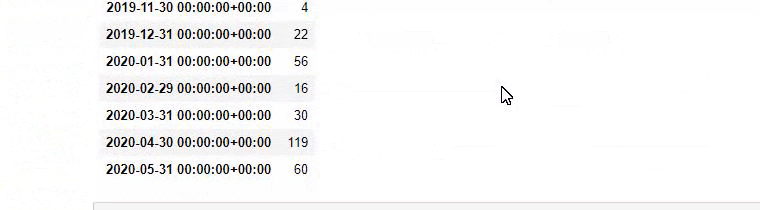
И вы можете увидеть графики публикации двух разных групп контента в течение многих лет для разных целей поиска с большей уверенностью и точной информацией из URL-адресов.
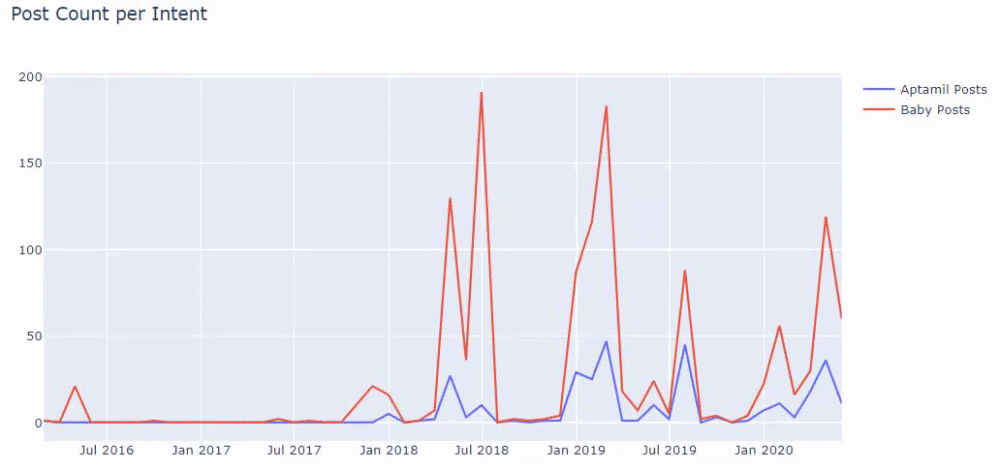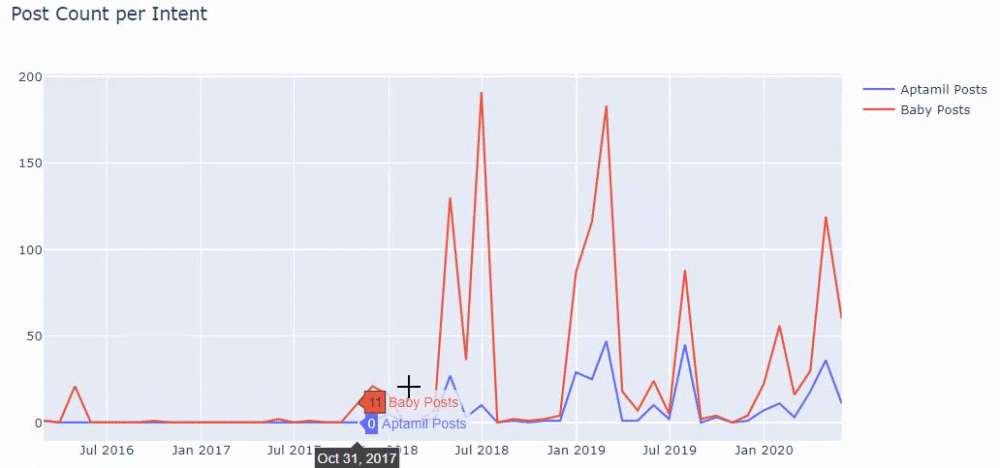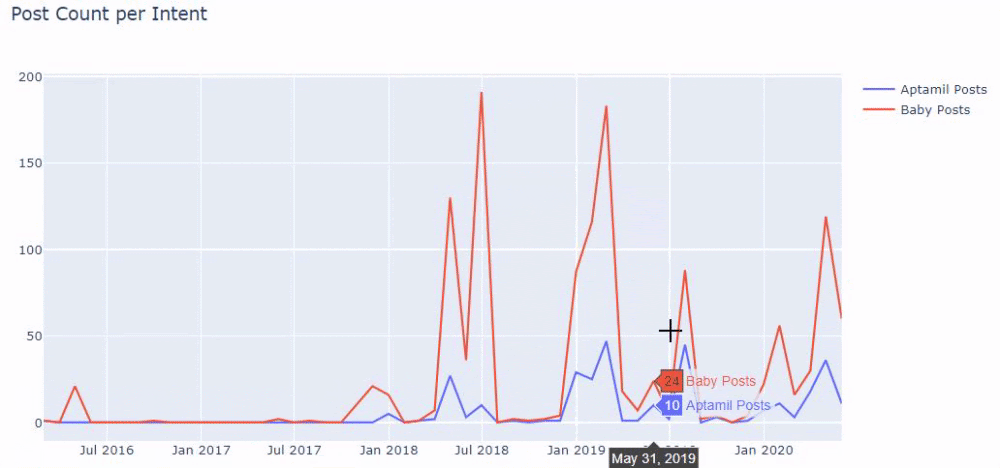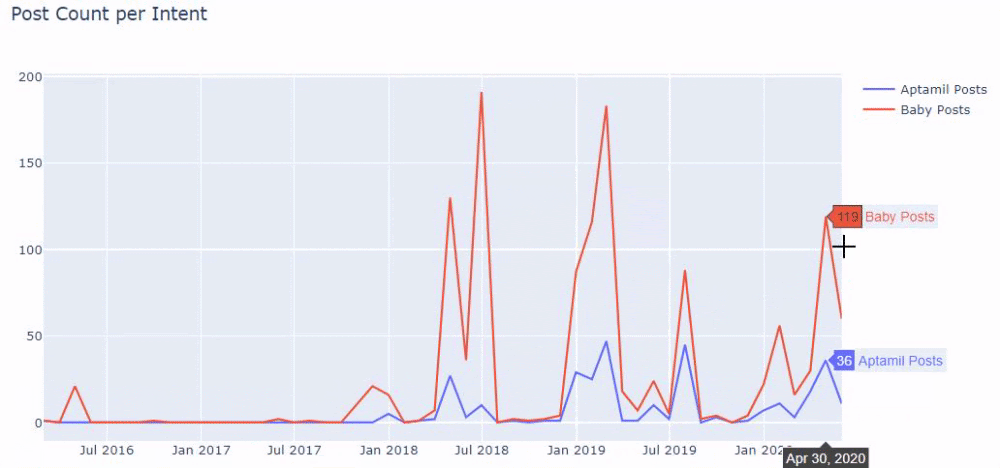
Код для создания этой диаграммы не разглашается, поскольку он такой же, как и для предыдущей диаграммы.
С помощью операторов поиска в Google я получаю 38 результатов, когда мне нужны страницы, на которых слово Aptamil используется в якорном тексте на Ilkadimlarim.com. Многие из этих страниц носят информационный характер и содержат ссылки на коммерческий контент.
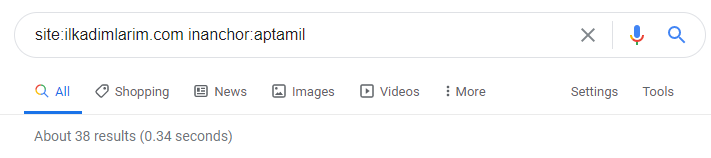
Наш тезис подтвердился.
«Мои первые шаги» использует сотни информативных материалов о материнстве, уходе за ребенком и беременности, чтобы охватить свою целевую аудиторию. «Ilkadimlarim» связывает страницы, содержащие продукты Aptamil, с этого контента и направляет туда пользователей.
Сравнительное профилирование контента и анализ стратегии контента с помощью файлов Sitemap с Python
Теперь, если хотите, давайте проделаем то же самое для компании из той же отрасли и проведем сравнение, чтобы понять общий аспект этой отрасли и различия в стратегии между этими двумя брендами.

В качестве второго примера я выбрал Prima.com.tr, который называется Pampers, но использует торговую марку Prima в Турции. Поскольку у Prima одна карта сайта, мы не сможем классифицировать по картам сайта, но, по крайней мере, у них разные разрывы в URL-адресах. Так что нам очень повезло: нам придется писать меньше кода.
Представьте, насколько дороже обходятся алгоритмы, которые Google должен запускать для вас, когда вы делаете сложный для понимания сайт! Это может помочь сделать расчет стоимости обхода более ощутимым для вас, даже в отношении структуры URL.
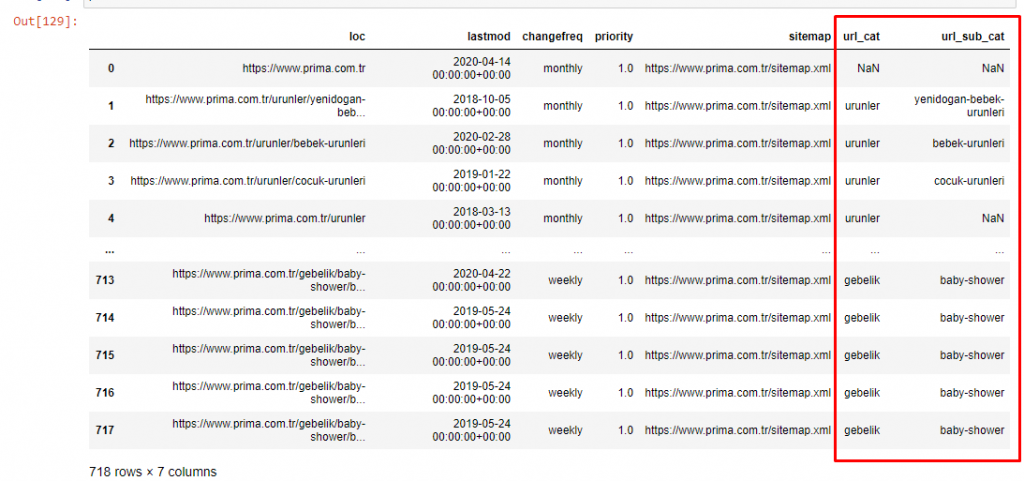
Чтобы не увеличивать объем статьи дальше, мы не размещаем коды процессов, аналогичных уже проделанным нами.
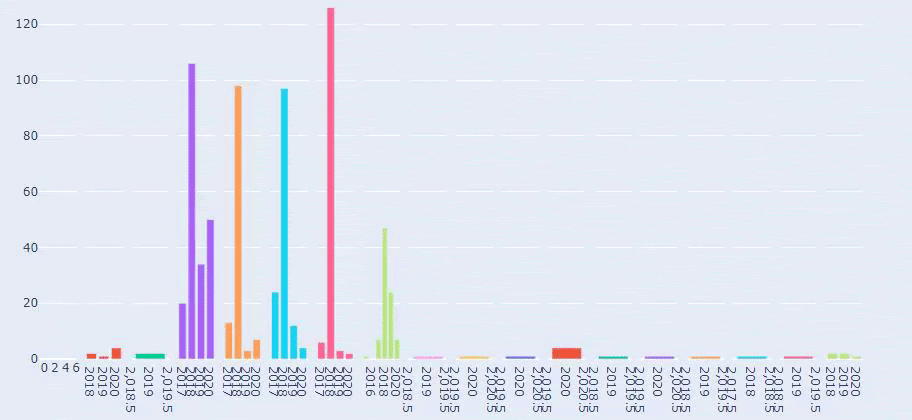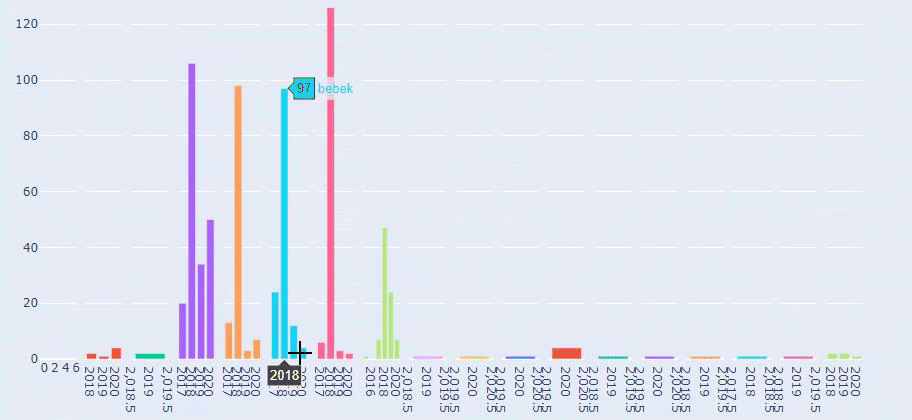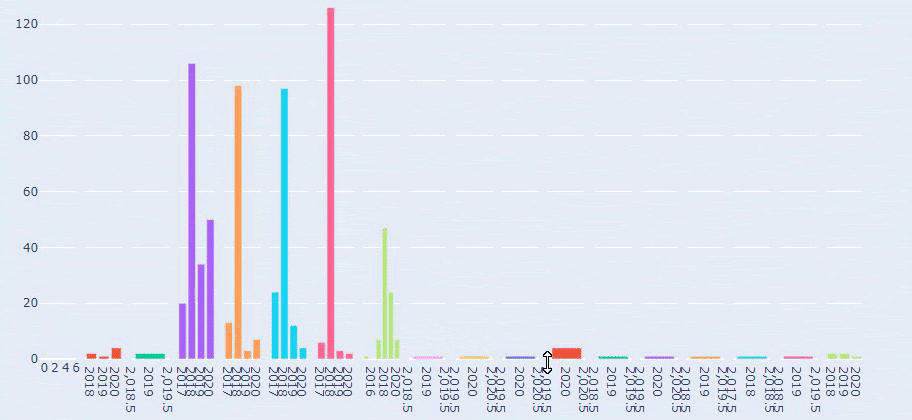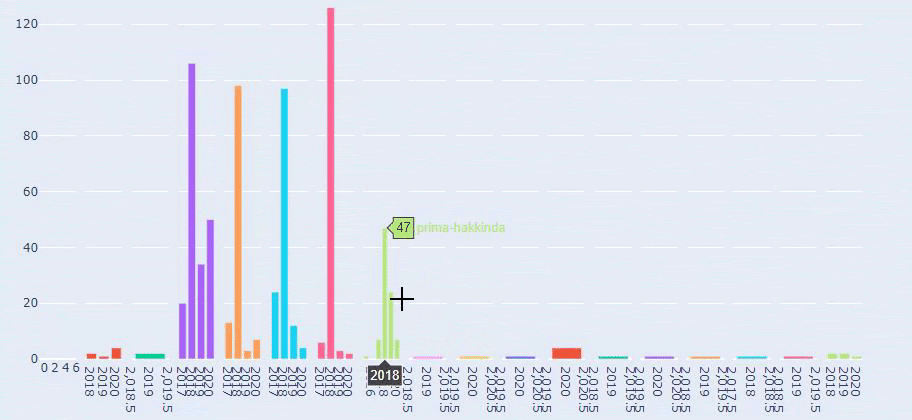
Теперь мы можем изучить их распределение категорий контента по категориям URL и подкатегориям URL. Мы видим, что у них слишком много корпоративных веб-страниц. Эти корпоративные веб-страницы размещены в разделе «prima-hakkinda» («О Prima»). Но когда я проверяю их с помощью Python, я вижу, что они объединили свои продукты и корпоративные веб-страницы в одну категорию. Вы можете увидеть их распределение контента ниже:

Мы можем сделать то же самое для следующих подкатегорий.
Интересно отметить, что Прима использует «гебелик» (беременность по-турецки), что является вариантом «хамилелик» (беременность по-арабски), и оба означают период беременности.

Теперь мы видим более глубокую категоризацию по их содержанию. 9,2% контента о здоровой беременности, 7,3% о процессе роста младенцев, 8,3% контента о занятиях, которые можно делать с младенцами, 0,7% о порядке сна младенцев. Есть даже такие темы, как прорезывание зубов с 3,9%, безопасность ребенка с 1,9% и раскрытие беременности семье с 1,4%. Как видите, вы можете познакомиться с отраслью, используя только URL-адреса и процент их распространения.
Это не идеальная категоризация, но, по крайней мере, мы можем видеть мышление наших конкурентов и тенденции контент-маркетинга, а также содержание их веб-сайтов по категориям. Теперь проверим частоту публикации контента по месяцам.
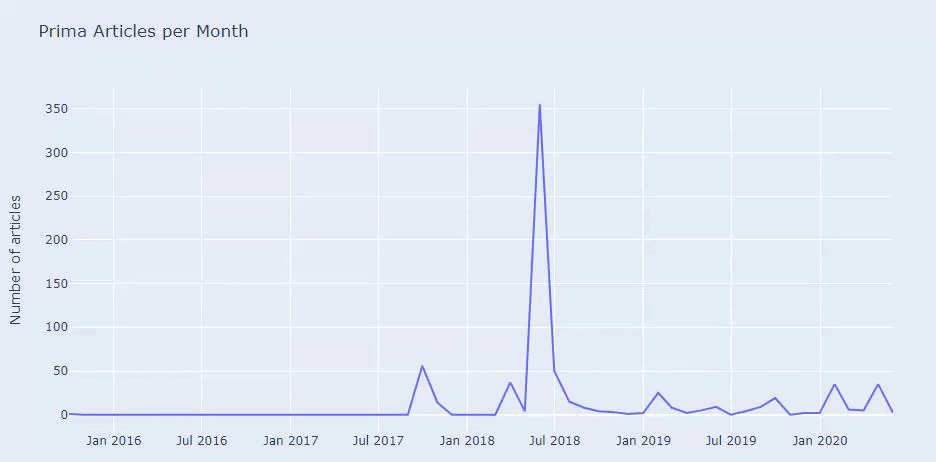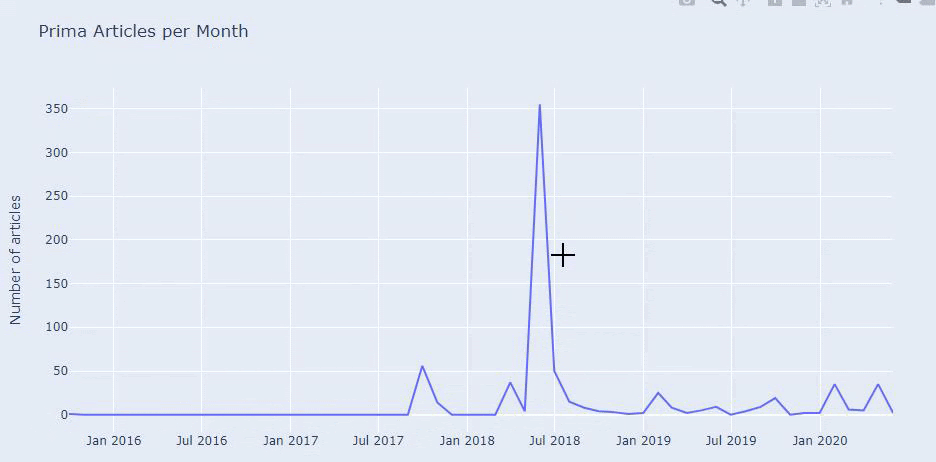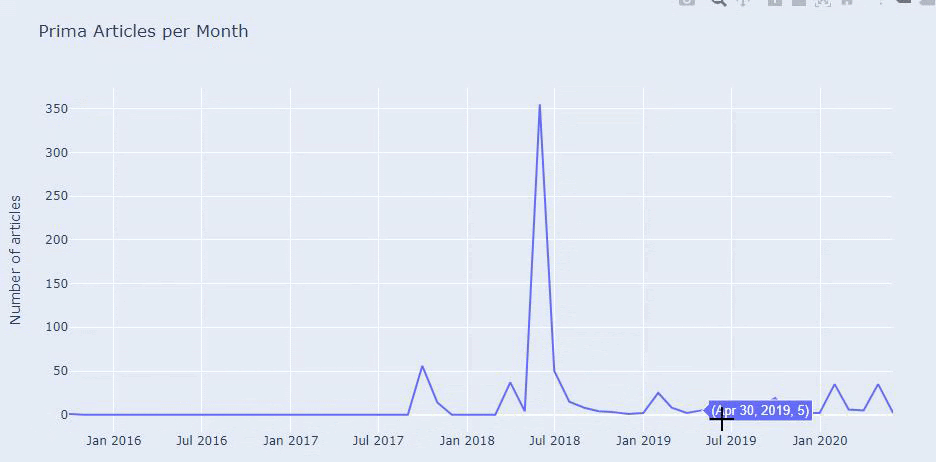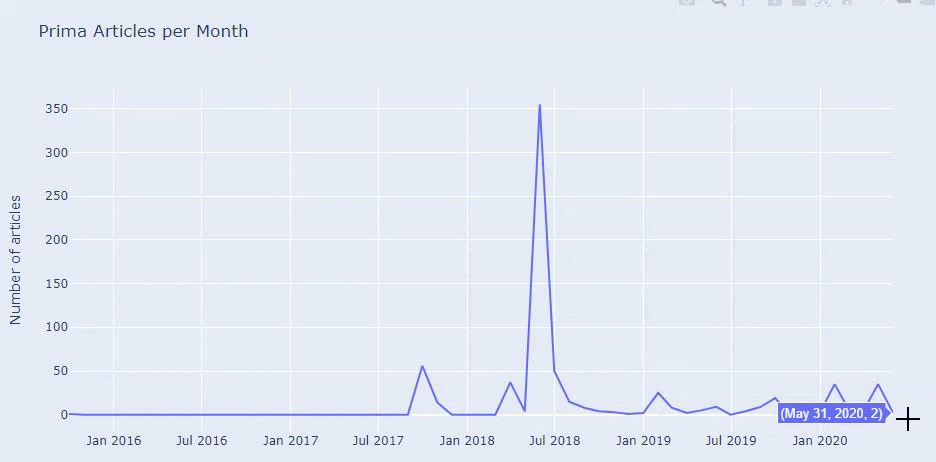
Мы видим, что они опубликовали 355 статей в июле 2018 года, и, согласно Sitemap, их содержание с тех пор не обновлялось. Мы также можем сравнить их тенденции публикации контента по категориям за прошедшие годы. Как видите, их контент в основном расположен в четырех разных категориях, и большинство из них публикуются в одном и том же месяце.
Прежде чем продолжить, я должен сказать, что данные карты сайта не всегда могут быть правильными. Например, данные Lastmod могли быть обновлены для всех URL-адресов, потому что они обновили все карты сайта в этот день. Чтобы обойти это, мы также можем проверить, не изменился ли их контент с тех пор, используя Wayback Machine.
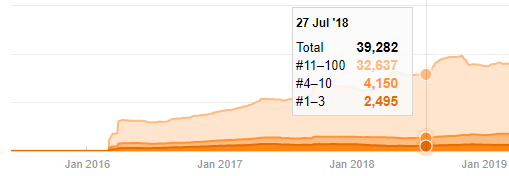
Даже если это выглядит подозрительно, эти данные могут быть реальными. Многие компании в Турции имеют тенденцию отдавать большое количество заказов и публиковать контент на мгновение раньше. Когда я проверяю их количество ключевых слов, я вижу скачок в этот период времени. Так что, если вы проводите сравнительный контент-профиль и анализ стратегии, вам также следует подумать об этих вопросах.
Это сравнение между тенденциями публикации контента каждой категории за последние годы для Prima.com.tr.
Теперь мы можем сравнить категории контента двух разных веб-сайтов и тенденции их публикации.
Когда мы смотрим на то, как часто Prima публикует статьи о росте детей, беременности и материнстве, мы видим сходство с Ilkadimlarim:
- Большинство статей были опубликованы в определенное время.
- Они давно не обновлялись.
- Количество продуктов и страниц было очень низким по сравнению с количеством страниц с информативным контентом.
- Недавно они просто добавили новые продукты на свои сайты.
Мы можем рассматривать эти четыре особенности как образ мышления по умолчанию в отрасли, и мы можем использовать эти недостатки в пользу нашей кампании. В конце концов, качество требует свежести (как сказал Амит Сингхал, научный сотрудник Google).
На данный момент мы также видим, что индустрия не знакома с поведением Googlebot. Вместо того, чтобы загружать 250 единиц контента за один день, а затем не вносить никаких изменений в течение года, лучше периодически добавлять новый контент и регулярно обновлять старый. Таким образом, вы можете поддерживать качество контента, Googlebot может легче понять ваш сайт, а ваши значения частоты запросов на сканирование будут выше, чем у ваших конкурентов.
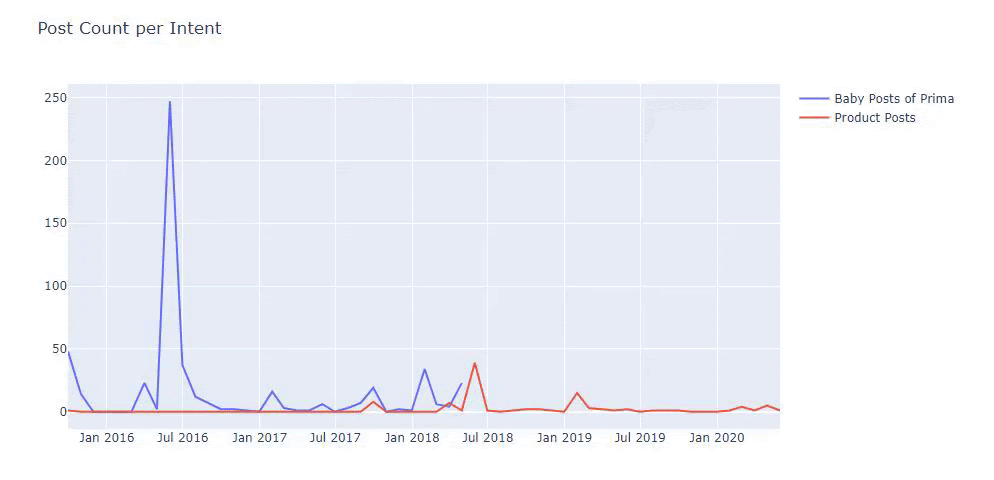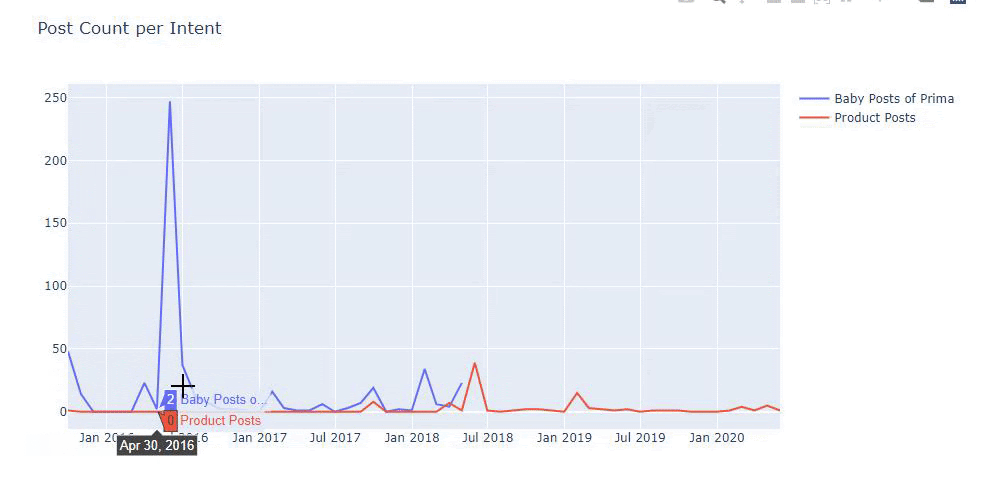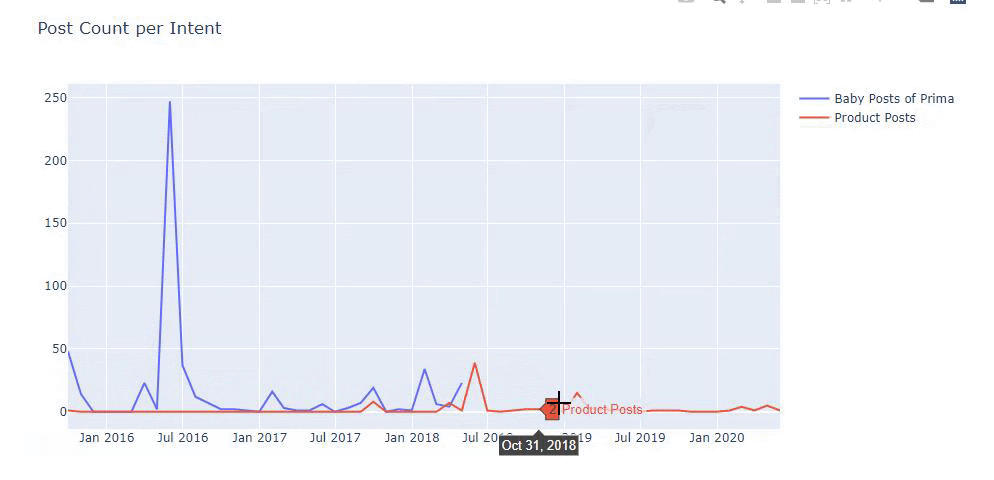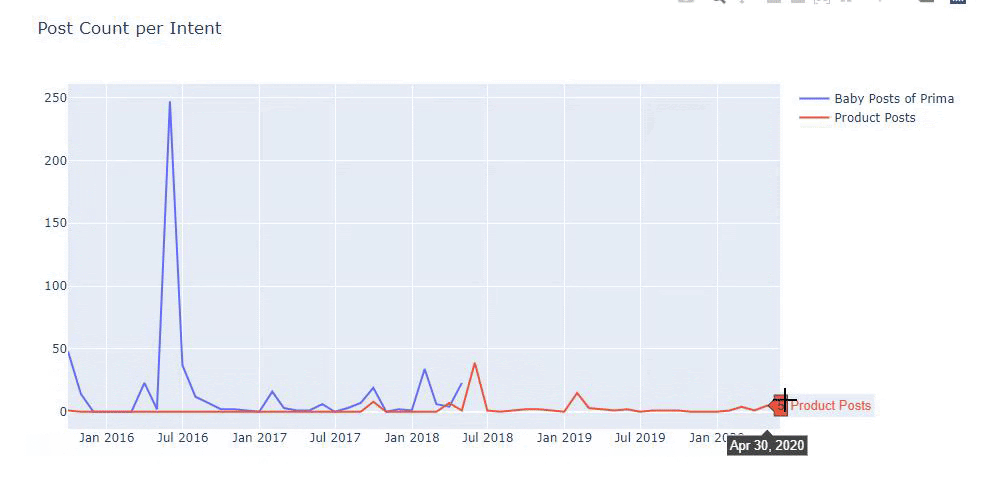
Я использовал предыдущие методы, чтобы различать страницы продукта и страницы с информативным контентом, и профилировал наиболее часто используемые слова в URL-адресах. Детские посты здесь означают, что это информативный контент.
Как видите, за один день они добавили 247 контента. Кроме того, они не публиковали и не обновляли информативный контент более года, а лишь время от времени добавляли страницы с новыми продуктами.
Теперь давайте сравним тенденции их публикации на одном рисунке, но с двумя разными графиками. Я использовал приведенные ниже коды для создания этой фигуры:
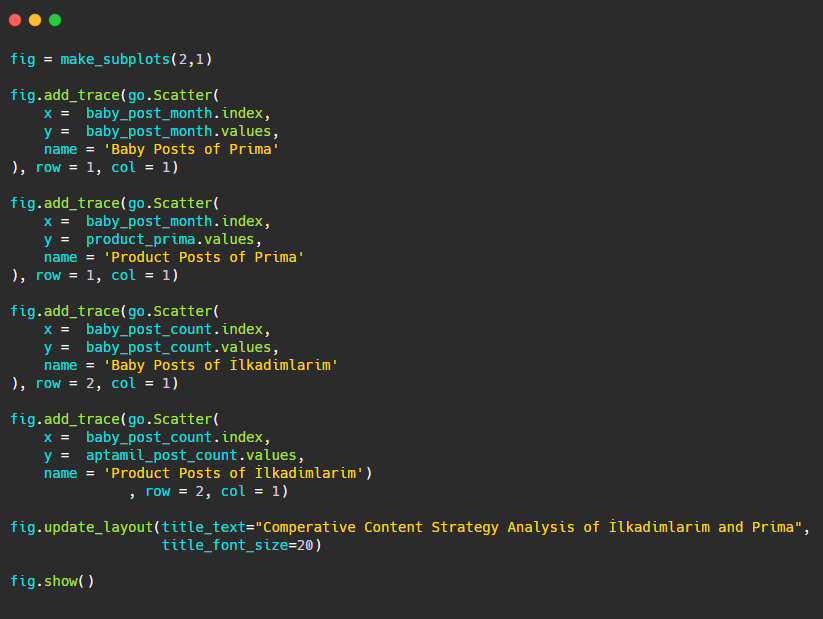
Поскольку этот рисунок отличается от предыдущих, я хотел показать вам код. Здесь два отдельных графика размещены на одном рисунке. Для этого был вызван метод make_subplots с командой из plotly.subplots import make_subplots.
Он был создан как фигура из двух строк и одного столбца с помощью make_subplots (2,1) .
Поэтому столбец и строка записываются в конце трасс и указываются их позиции. Это система, которую легко узнает любой, кто знаком с системой сетки в CSS.
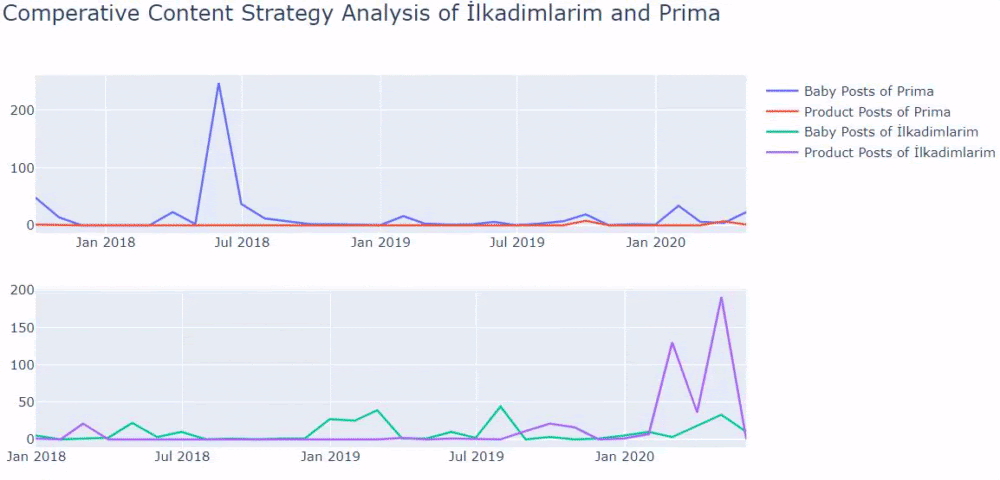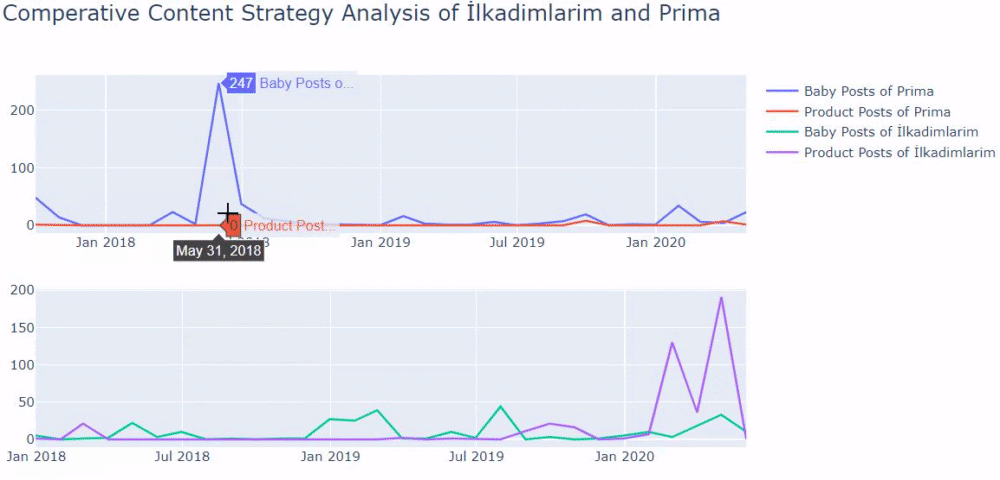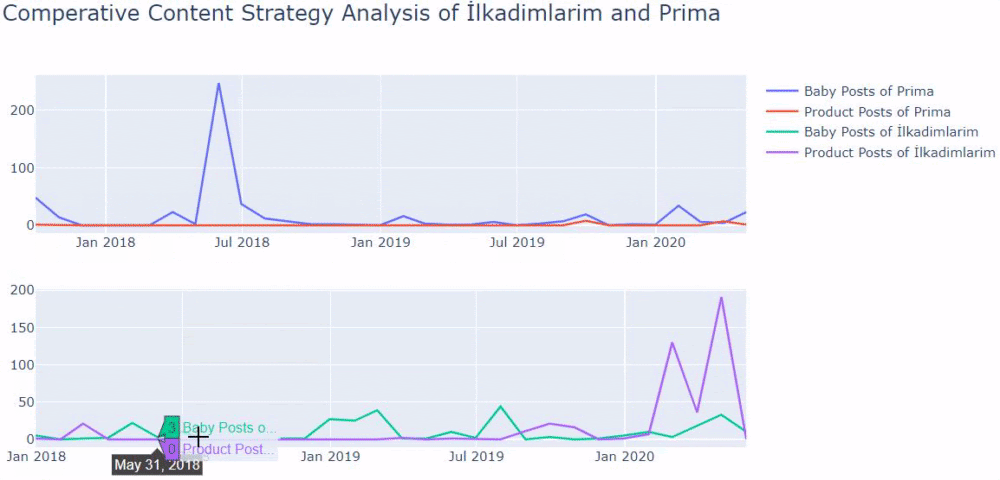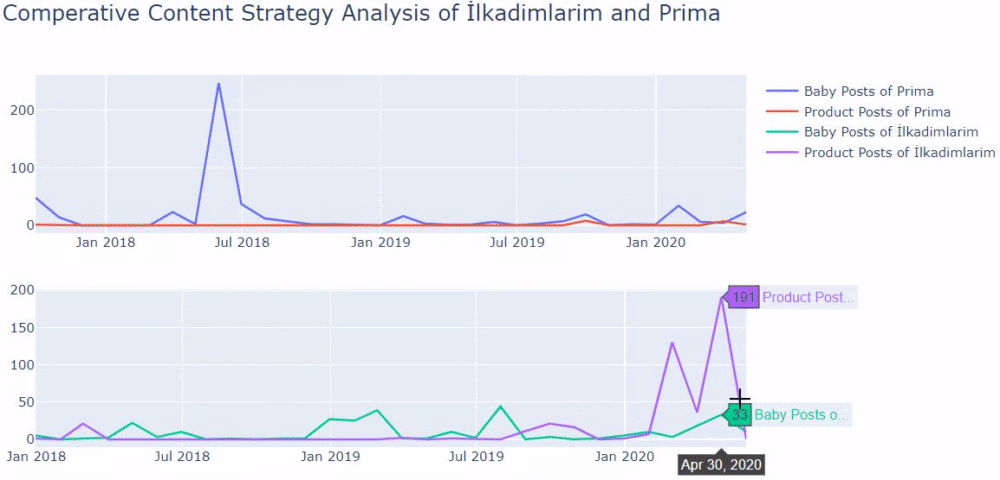
Если у вас есть клиент в том же секторе, вы можете использовать эти данные для создания стратегии контента, чтобы увидеть слабые стороны ваших конкурентов и их сеть запросов/целевых страниц в поисковой выдаче. Кроме того, вы можете понять, какой объем контента вы должны опубликовать в одной и той же области знаний или для одного и того же намерения пользователя.
Прежде чем закончить с тем, что мы можем узнать из карт сайта в рамках анализа стратегии контента, мы можем изучить последний веб-сайт с гораздо большим количеством URL-адресов из другой отрасли.
Анализ контент-стратегии новостных веб-объектов в зависимости от валюты с помощью Python и файлов Sitemap
В этом разделе мы будем использовать график тепловой карты Seaborn, а также некоторые более сложные методы кадрирования и извлечения данных.

У Элиаса Даббаса есть интересный и действительно полезный архив Kaggle с точки зрения Data Science и SEO. В этом месяце он открыл новый раздел набора данных Kaggle для турецких новостных сайтов, чтобы я мог написать необходимые коды и выполнить анализ стратегии контента с помощью Advertools через карты сайта.
Прежде чем я начну использовать эти методы в Kaggle, я хотел бы показать в этой статье несколько примеров того, что произойдет, если мы будем использовать те же методы для более крупных веб-объектов.
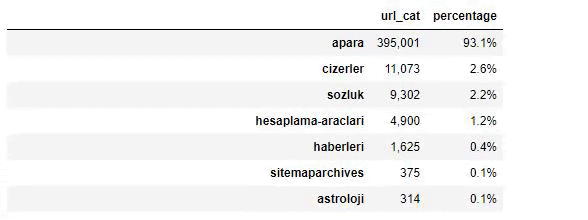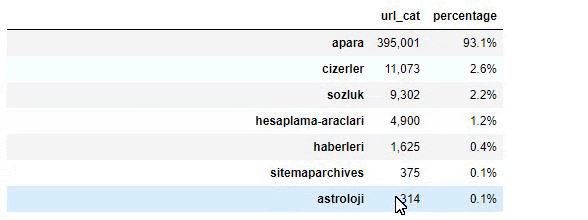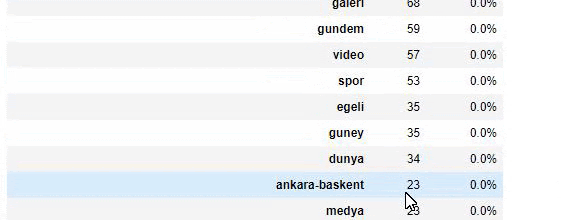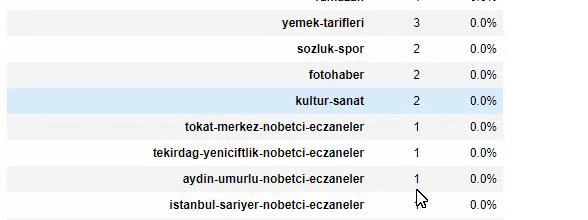
Когда мы анализируем содержание газеты Сабах, мы видим, что значительная часть ее содержания (81%) относится к категории под названием «апара». Кроме того, у них есть несколько больших категорий для астрологии, расчетов, словарей, погоды и мировых новостей. (Para означает деньги на турецком языке)
Для газеты Sabah мы также можем анализировать контент с картами сайта, которые мы собрали только с помощью Advertools, но, поскольку рассматриваемая газета очень большая, я не предпочел ее из-за большого количества карт сайта и содержания разных карт сайта, содержащих один и тот же URL-адрес. Категория.
Ниже вы также можете увидеть избыток карт сайта с помощью Advertools.
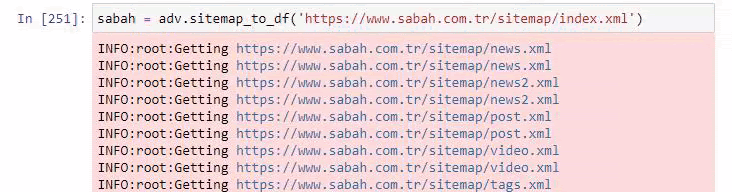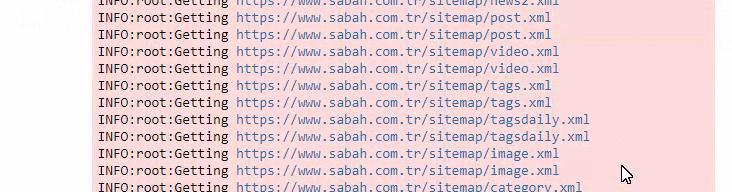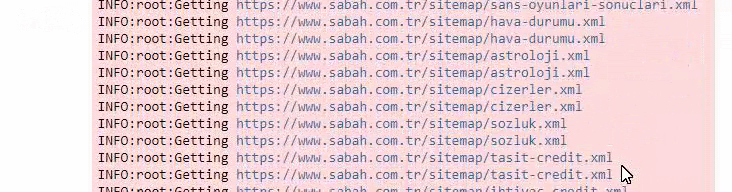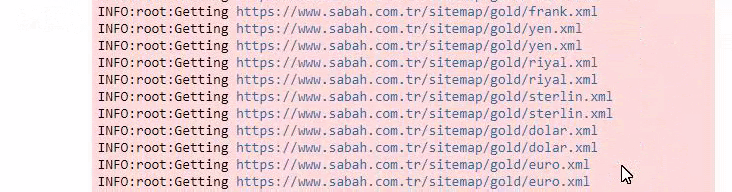
Мы можем видеть, что у них разные карты сайта для одних и тех же категорий URL, таких как золото, кредит, валюта, теги, время молитвы и часы работы аптеки и т. д.
Короче говоря, мы можем получить эти детали, сосредоточившись на подкатегориях URL-адресов. Вместо того, чтобы объединять разные карты сайта с помощью переменных. Итак, я объединил все карты сайта с помощью метода sitemap_to_df() Advertools, как в начале статьи.
Мы также можем использовать другой набор функций, созданный Элиасом Даббасом, для создания лучших фреймов данных. Если вы проверите функции dataset_utitilites, вы увидите несколько примеров. В приведенном ниже коде указано общее и процентное значение указанного регулярного выражения URL, а также совокупная сумма путем стилизации.
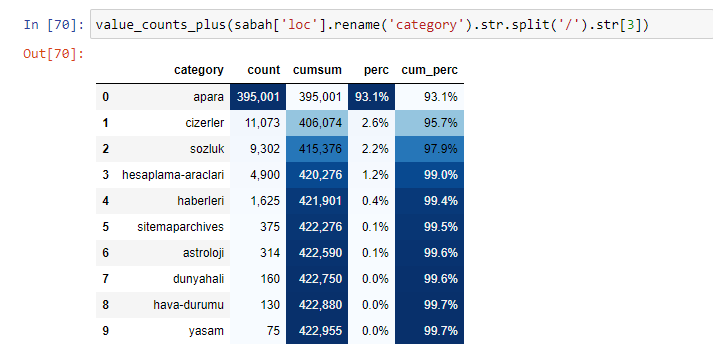
Если мы сделаем то же самое с разбивкой суб-URL газеты Сабах, мы получим следующий результат.
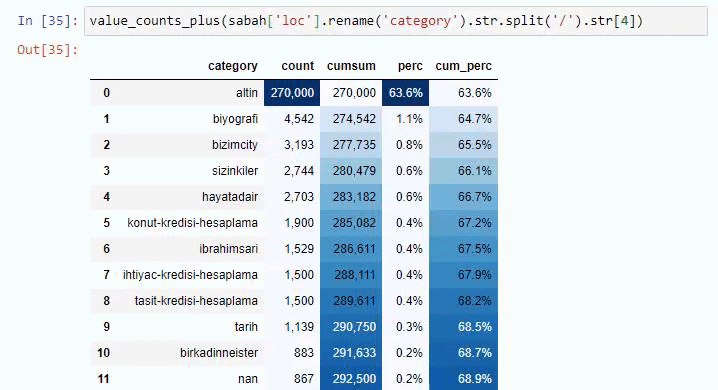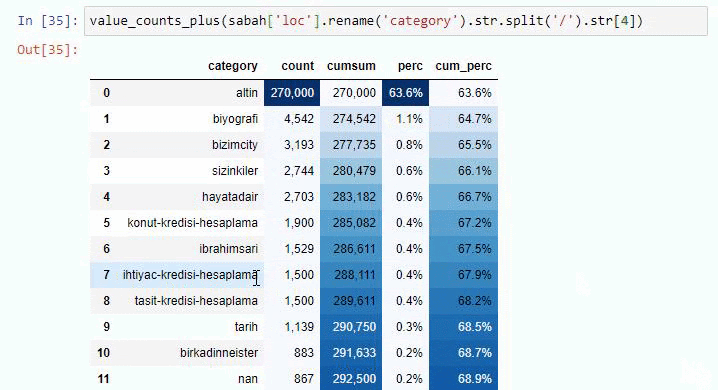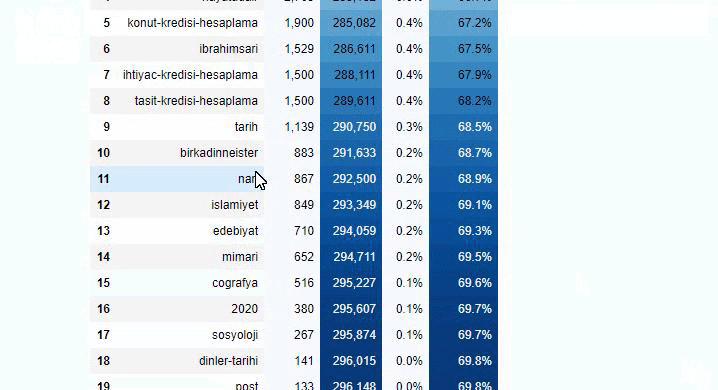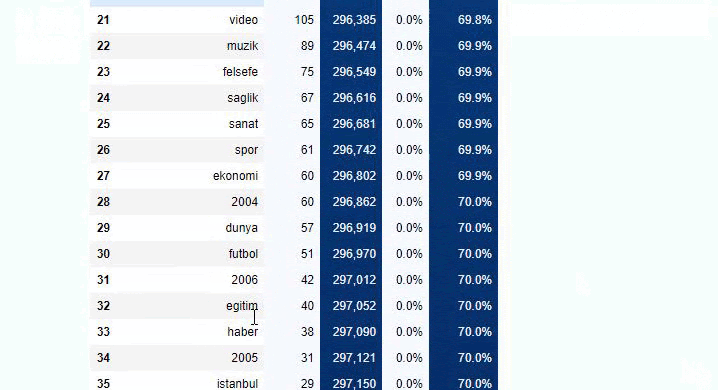
Вы можете увеличить количество строк, которые будет выводить рассматриваемая функция, изменив строку ниже. Кроме того, если вы изучите содержимое функции, вы увидите, что оно похоже на те, которые мы использовали ранее.
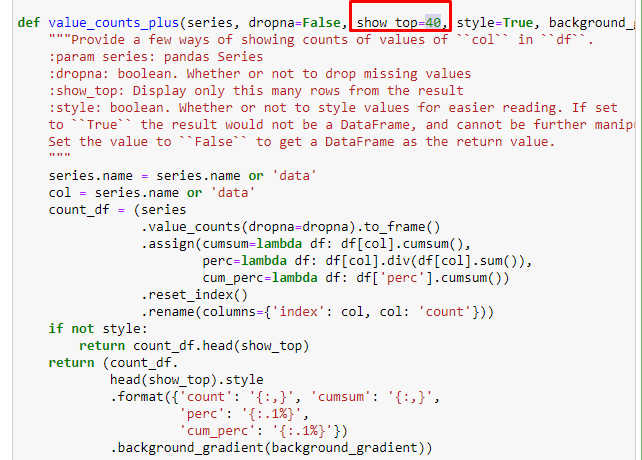
В подразделах мы видим разные разбивки, такие как «История религии», «Биография», «Названия городов», «Футбол», «Бизимсити (карикатура)», «Ипотечный кредит». Самая большая разбивка – в категории «Золото».
Так как же газета может иметь 295 000 URL-адресов для цен на золото?
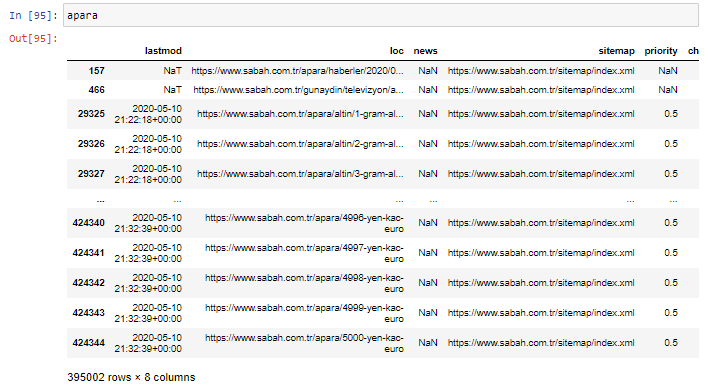
Прежде всего, я бросаю все URL-адреса, содержащие «апара» в первой разбивке URL-адресов Sabah Newspaper, в переменную.
апара = сабах[сабах['loc'].str.contains('апара')]
Вот результат:
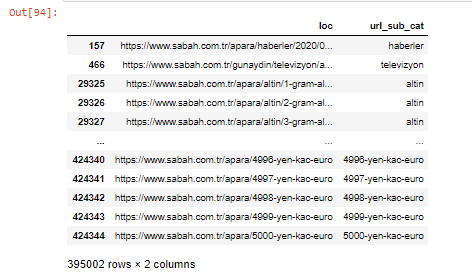
Мы также можем фильтровать столбцы с помощью метода .filter():
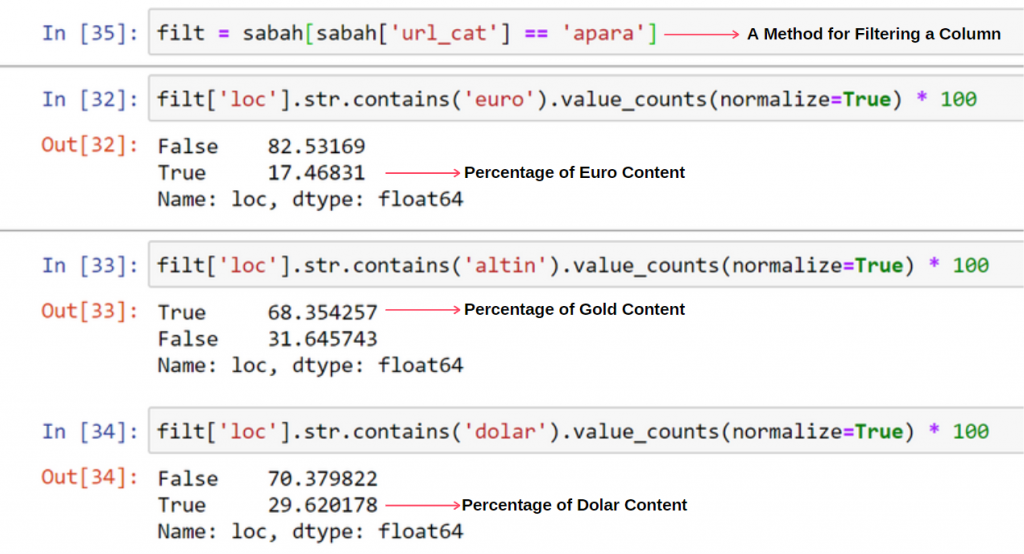
Теперь мы можем видеть в нижней части DataFrame, почему газета Sabah Newspaper имеет чрезмерное количество URL-адресов Apara, потому что они открывали разные веб-страницы для каждой суммы расчета валюты, такой как 5000 евро, 4999 евро, 4998 евро и т. д.
Но прежде чем делать какие-либо выводы, мы должны быть уверены, потому что более 250 000 этих URL-адресов относятся к категории «алтин (золото)».
apara.filter(['loc', 'url_sub_cat' ]).tail(60) покажет нам последние 60 строк этого фрейма данных:

Мы можем сделать то же самое для разбивки золотого URL-адреса в группе Apara.
gold = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
На данный момент мы видим, что газета Сабах открыла 5000 различных страниц для конвертации каждой валюты в доллары, евро, золото и TL (турецкие лиры). Для каждой денежной единицы от 1 до 5000 существует отдельная страница расчета. Вы можете увидеть пример первых 85 и последних 85 строк золотой группы ниже. Для каждого грамма цены золота открыта отдельная страница.


Мы не сомневаемся, что эти страницы ненужны, содержат много дублированного контента и слишком велики, но Sabah Newspaper — это сайт с таким сильным брендом, что Google продолжает показывать его почти по каждому запросу, занимая первое место в рейтинге.
На этом этапе мы также видим, что допустимая стоимость сканирования высока для старого новостного сайта с высоким авторитетом.
Однако это не объясняет, почему в золотой категории больше URL-адресов, чем в других.
Я не вижу ничего странного в том, что сумма перекрывающихся значений превышает 100%.
Если я что-то пропустил?
Как вы заметили, когда мы складываем все истинные значения, мы получаем результат 115,16%. Причина этого ниже.
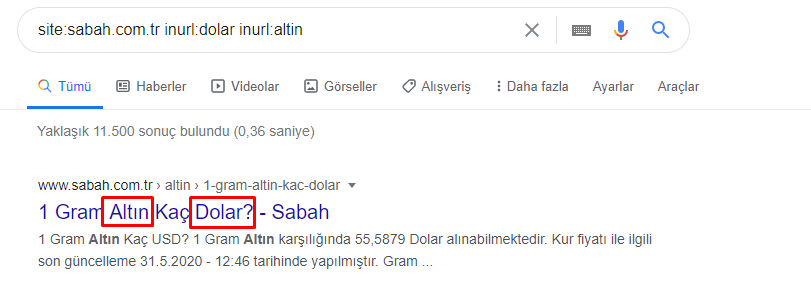
Даже основная группа имеет такое пересечение друг с другом. Мы могли бы также проанализировать эти пересечения, но это может быть предметом другой статьи.
Мы видим, что 68% контента в группе URL-адресов Apara связаны с GOLD.
Чтобы лучше понять эту ситуацию, первое, что нам нужно сделать, это отсканировать URL-адреса в преломлении золота.
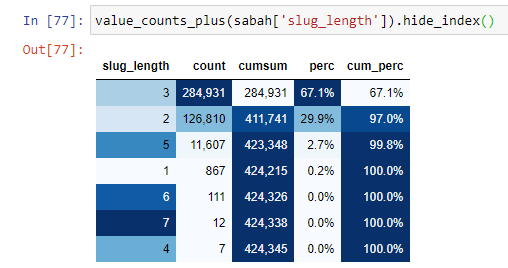
Когда мы классифицируем URL-адреса в соответствии с количеством символов «/», которые они имеют после корневого раздела, мы видим, что количество URL-адресов с максимум 3 разрывами велико. Когда мы анализируем эти URL-адреса, мы видим, что 270 000 из 3 URL-адресов slug_length относятся к категории Gold.
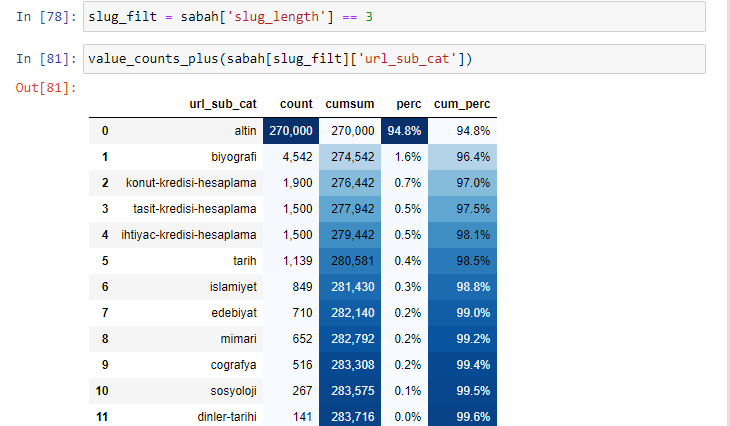
утро_филт = утро ['slug_length'] == 3 Это означает, что вы получаете только те, которые равны 3 из группы данных типа данных int в определенном столбце определенного фрейма данных. Затем, на основе этой информации, мы формируем URL-адреса, которые удобны для условия, с количеством, суммами и коэффициентами агрегации с кумулятивной суммой.
Когда мы извлекаем наиболее часто используемые слова в золотых URL-адресах, мы сталкиваемся со словами, которые представляют «полный», «республику», «четверть», «грамм», «половину», «предок». Типы золота «Ата» и «Республика» уникальны для Турции. Один из них представляет турецкий суверенитет, а другой — основатель республики Кемаль Ататюрк. Вот почему их объемы поисковых запросов высоки.
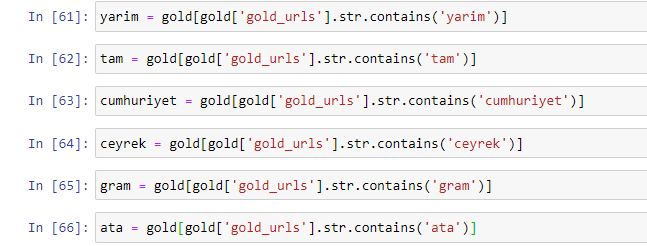
Прежде всего, мы удалили общие слова, встречающиеся в URL-адресах, и назначили их отдельным переменным. Далее мы будем использовать эти переменные в Gold DataFrame для создания столбцов, специфичных для их типов.
После создания новых столбцов через переменные мы должны отфильтровать их вместе с логическими значениями.
Как видите, мы смогли классифицировать все золотые URL-адреса с 270 000 строк и 6 столбцов. Основная причина большого количества страниц, посвященных золоту, заключается в том, что доллар или евро не имеют отдельных типов, в то время как золото имеет отдельные типы. В то же время разнообразие пересечений между золотом и различными валютами выше, чем у других валют из-за их традиционного доверия к турецкому народу.
На мой взгляд, все типы золотых страниц должны быть распределены поровну, верно?
Мы можем легко проверить это с помощью функции тепловой карты Seaborn.
импортировать Seaborn как sns
импортировать matplotlib.pyplot как plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
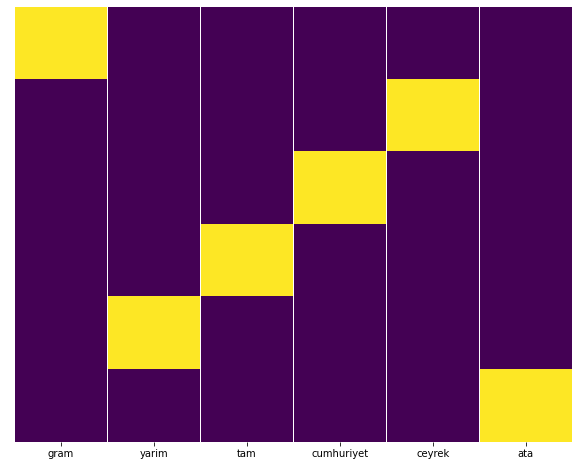
Здесь на тепловой карте просто отмечены Истина в каждом столбце. Как видно, размер каждого симметричен друг другу и аккуратно расположен на карте.
Таким образом, мы получили широкое представление о политике содержания газеты Sabah.com.tr о валютах и валютных расчетах.
В будущем я буду писать о турецких новостных веб-сайтах и их контент-стратегиях на основе Sitemaps Kaggle, который был запущен Элиасом Даббасом, но в этой статье мы достаточно рассказали о том, что можно обнаружить как на больших, так и на малых веб-сайтах с картами сайта. .
Заключение и выводы
Я думаю, мы видели, как легко понять веб-сайт благодаря гладкой и семантической структуре URL. Мы также должны помнить, насколько ценной может быть правильная структура URL для Google.
В будущем мы увидим множество SEO-специалистов, которые все больше знакомятся с наукой о данных, визуализацией данных, интерфейсным программированием и многим другим… Я вижу этот процесс как начало неизбежных изменений: разрыв между SEO-специалистами и разработчиками будет полностью закрыт. через несколько лет.
С Python вы можете пойти еще дальше в этом виде анализа: можно получить данные от понимания политических взглядов новостного сайта до того, кто о чем пишет, как часто и с какими чувствами. Я предпочитаю не вдаваться в подробности здесь, поскольку эти процессы больше связаны с чистой наукой о данных, чем с SEO (и эта статья уже довольно длинная).
Но если вам интересно, существует множество других типов аудита, которые можно выполнить с помощью файлов Sitemap и Python, например, проверка кодов состояния URL-адресов в карте сайта.
Я с нетерпением жду возможности поэкспериментировать и поделиться другими SEO-задачами, которые вы можете решить с помощью Python и Advertools.