
Понимание искусственного интеллекта: как мы учили компьютеры естественному языку
Опубликовано: 2023-11-28Фраза «искусственный интеллект» использовалась по отношению к компьютерам с 1950-х годов, но до прошлого года большинство людей, вероятно, думали, что ИИ все еще является скорее научной фантастикой, чем технической реальностью.
Появление ChatGPT от OpenAI в ноябре 2022 года внезапно изменило представление людей о том, на что способно машинное обучение. Но что именно в ChatGPT заставило мир сесть и осознать, что искусственный интеллект уже здесь?
Одним словом, язык. Причина, по которой ChatGPT показался таким замечательным шагом вперед, заключалась в том, что он свободно говорил на естественном языке так, как никогда раньше не говорил ни один чат-бот.
Это знаменует собой новый замечательный этап «обработки естественного языка» (НЛП), способности компьютеров интерпретировать естественный язык и выдавать убедительные ответы. ChatGPT построен на «большой языковой модели» (LLM), которая представляет собой тип нейронной сети, использующей глубокое обучение, обученной на массивных наборах данных, которые могут обрабатывать и генерировать контент.
«Как компьютерная программа достигла такой лингвистической беглости?»
Но как мы сюда попали? Как компьютерная программа достигла такой лингвистической беглости? Как это звучит так безошибочно по-человечески?
ChatGPT был создан не в вакууме — он основан на множестве различных инноваций и открытий последних десятилетий. Ряд прорывов, которые привели к созданию ChatGPT, стали вехами в компьютерной науке, но их можно рассматривать как имитацию этапов, на которых люди овладевают языком.
Как мы учим язык?
Чтобы понять, как ИИ достиг этой стадии, стоит рассмотреть природу самого изучения языка: мы начинаем с отдельных слов, а затем начинаем объединять их в более длинные последовательности, пока не сможем передавать сложные концепции, идеи и инструкции.
Например, некоторые распространенные этапы овладения языком у детей:
- Голофрастическая стадия: в возрасте от 9 до 18 месяцев дети учатся использовать отдельные слова, описывающие их основные потребности или желания. Общение одним словом означает, что ясность важнее концептуальной полноты. Если ребенок голоден, он не скажет «Я хочу поесть» или «Я голоден», вместо этого он просто скажет «Еда» или «Молоко».
- Этап двух слов: в возрасте 18–24 месяцев дети начинают использовать простые группы из двух слов, чтобы улучшить свои коммуникативные навыки. Теперь они могут выражать свои чувства и потребности с помощью таких выражений, как «еще еды» или «почитай книгу».
- Телеграфная стадия: в возрасте 24–30 месяцев дети начинают связывать несколько слов вместе, образуя более сложные фразы и предложения. Количество используемых слов по-прежнему невелико, но начинает проявляться правильный порядок слов и сложность. Дети начинают изучать базовое построение предложений, например «я хочу показать маме».
- Этап из нескольких слов: после 30 месяцев дети начинают переходить к этапу из нескольких слов. На этом этапе дети начинают использовать более грамматически правильные, сложные и многопредставительные предложения. Это заключительный этап овладения языком, и дети в конечном итоге общаются сложными предложениями, например: «Если пойдет дождь, я хочу остаться дома и поиграть в игры».
Одним из первых ключевых этапов овладения языком является способность начать использовать отдельные слова очень простым способом. Поэтому первое препятствие, которое необходимо было преодолеть исследователям ИИ, заключалось в том, как научить модели запоминать простые словесные ассоциации.
Модель 1. Изучение отдельных слов с помощью Word2Vec (документ 1 и документ 2)
Одной из первых моделей нейронных сетей, пытавшихся изучить словесные ассоциации таким способом, была Word2Vec, разработанная Томашем Миколовым и группой исследователей из Google. Оно было опубликовано в двух статьях в 2013 году (что показывает, насколько быстро развиваются дела в этой области).
Эти модели обучались путем обучения ассоциированию слов, которые обычно используются вместе. Этот подход основывался на интуиции первых пионеров лингвистики, таких как Джон Р. Ферт, который отмечал, что значение можно получить из словесных ассоциаций: «Вы узнаете слово по тому, в какой компании оно находится».
Идея состоит в том, что слова, имеющие схожее семантическое значение, чаще встречаются вместе. Слова «кошки» и «собаки» обычно встречаются чаще вместе, чем со словами «яблоки» или «компьютеры». Другими словами, слово «кошка» должно быть больше похоже на слово «собака», чем «кошка» на «яблоко» или «компьютер».
Самое интересное в Word2Vec то, как он был обучен запоминать эти словесные ассоциации:
- Угадайте целевое слово. В качестве входных данных модели предоставляется фиксированное количество слов, при этом целевое слово отсутствует, и она должна была угадать недостающее целевое слово. Это известно как «Непрерывный мешок слов» (CBOW).
- Угадайте окружающие слова: модели дается одно слово, а затем ей предлагается угадать окружающие слова. Это известно как Skip-Gram и представляет собой подход, противоположный CBOW, поскольку мы предсказываем окружающие слова.
Одним из преимуществ этих подходов является то, что вам не нужно иметь какие-либо размеченные данные для обучения модели — разметка данных, например, описание текста как «положительного» или «негативного» для обучения анализу настроений, в конце концов, — это медленная и трудоемкая работа.
Одной из самых удивительных особенностей Word2Vec были сложные семантические отношения, которые он фиксировал при относительно простом подходе к обучению. Word2Vec выводит векторы, которые представляют входное слово. Выполняя математические операции над этими векторами, авторы смогли показать, что векторы слов охватывают не только синтаксически схожие элементы, но и сложные семантические отношения.
Эти отношения связаны с тем, как используются слова. Примером, который отметили авторы, была связь между такими словами, как «Король» и «Королева», а также «Мужчина» и «Женщина».
Но хотя это был шаг вперед, у Word2Vec были ограничения. У каждого слова было только одно определение — например, мы все знаем, что «банк» может означать разные вещи в зависимости от того, планируете ли вы держать его в руках или ловить рыбу с него. Word2Vec это не волновало, у него было только одно определение слова «банк», и он мог использовать его во всех контекстах.
Прежде всего, Word2Vec не мог обрабатывать инструкции или даже предложения. Он мог только принимать слово в качестве входных данных и выводить «вложение слова» или векторное представление, которое он изучил для этого слова. Чтобы построить эту основу из одного слова, исследователям нужно было найти способ объединить два или более слов в последовательность. Мы можем представить это как этап овладения языком, состоящий из двух слов.
Модель 2 – Изучение последовательностей слов с помощью RNN и последовательностей текста.
Как только дети начинают осваивать использование отдельных слов, они пытаются складывать слова вместе, чтобы выразить более сложные мысли и чувства. Аналогично, следующим шагом в развитии НЛП было развитие способности обрабатывать последовательности слов. Проблема с обработкой последовательностей текста заключается в том, что они не имеют фиксированной длины. Длина предложения может варьироваться от нескольких слов до длинного абзаца. Не вся последовательность будет важна для общего значения и контекста. Но нам нужно иметь возможность обрабатывать всю последовательность, чтобы знать, какие части наиболее важны.
Именно здесь появились рекуррентные нейронные сети (RNN).
Разработанная в 1990-х годах RNN работает путем обработки входных данных в цикле, в котором выходные данные предыдущих шагов передаются по сети по мере прохождения каждого шага последовательности.
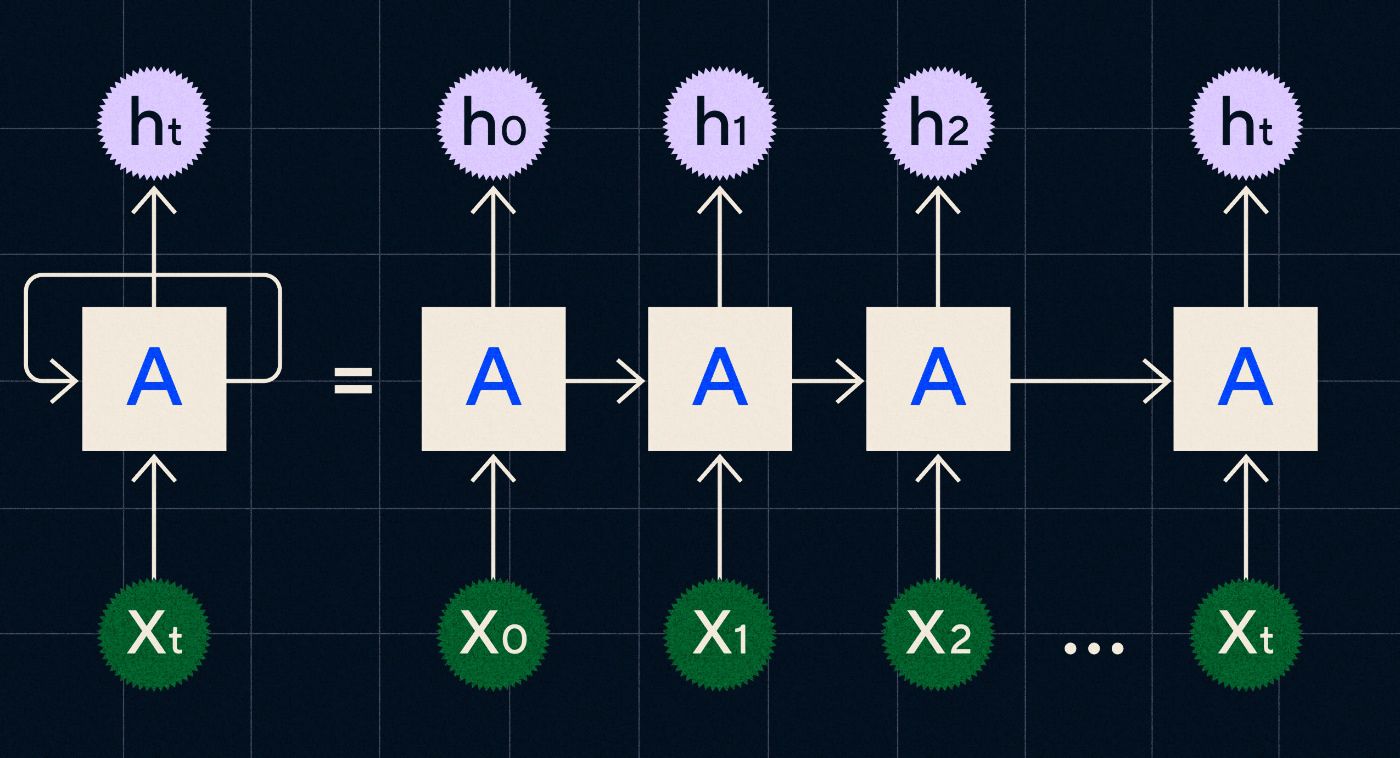
Источник: сообщение в блоге Кристофера Ола о RNN.
На диаграмме выше показано, как представить RNN как серию нейронных сетей (A), в которых выходные данные предыдущего шага (h0, h1, h2… ht) передаются на следующий шаг. На каждом этапе сеть также обрабатывает новый вход (X0, X1, X2… Xt).
RNN (и, в частности, сети долговременной краткосрочной памяти, или LSTM, особый тип RNN, представленный Зеппом Хохрейтером и Юргеном Шмидхубером в 1997 году) позволили нам создать архитектуру нейронных сетей, которые могут выполнять более сложные задачи, такие как перевод.
В 2014 году Илья Суцкевер (соучредитель OpenAI), Ориол Виньялс и Куок Ви Ле из Google опубликовали статью, в которой описывались модели Sequence to Sequence (Seq2Seq). В этой статье было показано, как можно научить нейронную сеть принимать входной текст и возвращать его перевод. Вы можете думать об этом как о раннем примере генеративной нейронной сети, где вы даете ей подсказку, а она возвращает ответ. Однако задача была фиксированной, поэтому, если она была обучена переводу, вы не могли «подсказать» ей сделать что-либо еще.
Помните, что предыдущая модель Word2Vec могла обрабатывать только отдельные слова. Поэтому, если вы передадите ему предложение типа «дантист вырвал мне зуб», он просто сгенерирует вектор для каждого слова, как если бы они не были связаны друг с другом.
Однако порядок и контекст важны для таких задач, как перевод. Нельзя просто переводить отдельные слова, нужно разбирать последовательности слов и потом выводить результат. Именно здесь RNN позволили моделям Seq2Seq обрабатывать слова таким образом.
Ключом к моделям Seq2Seq был дизайн нейронной сети, в которой использовались две RNN подряд. Один из них представлял собой кодировщик, который превращал входные данные из текста во встроенные элементы, а другой был декодером, который принимал в качестве входных данных встроенные элементы, выводимые кодировщиком:
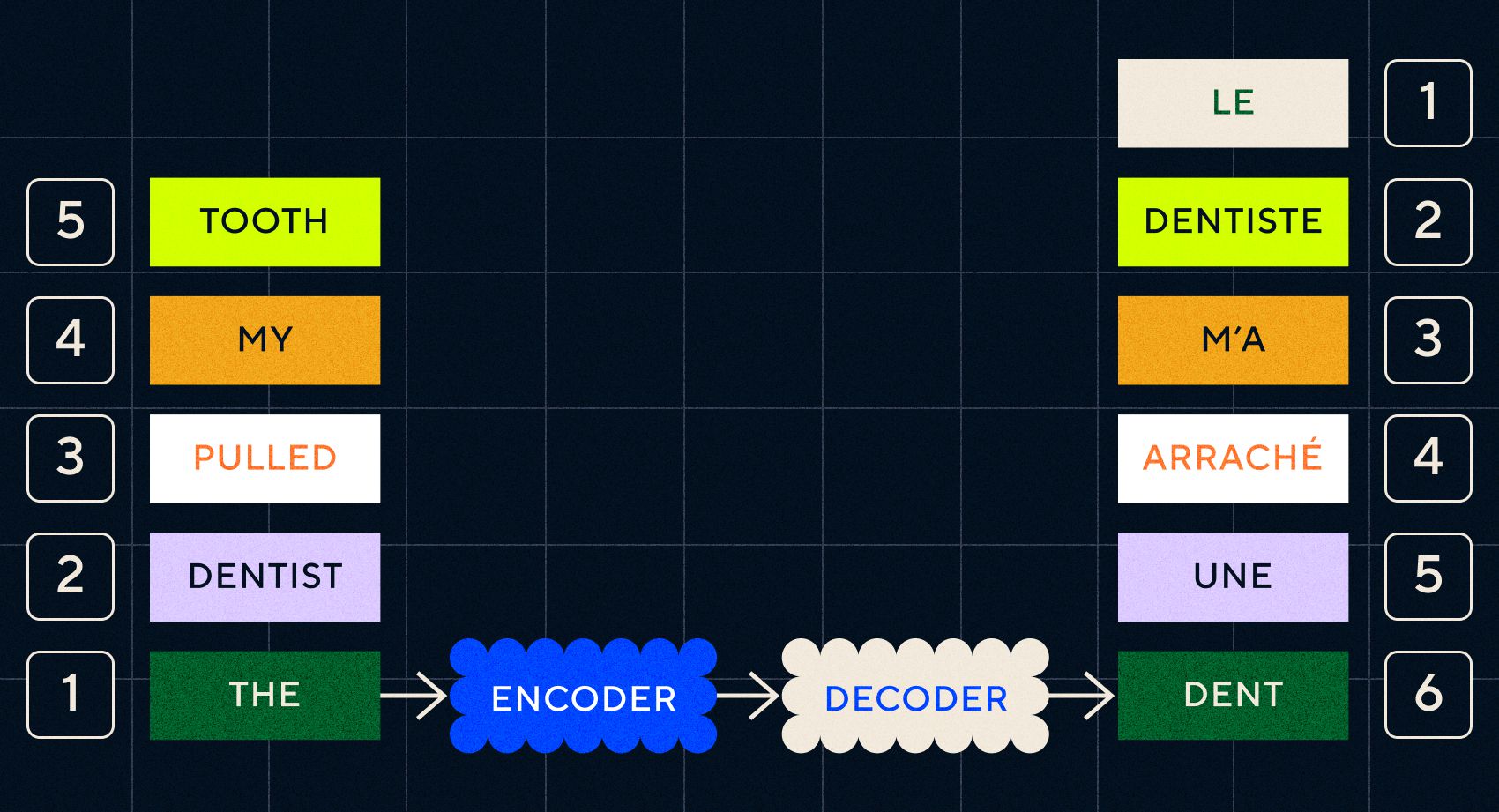
После того как кодер обработал входные данные на каждом этапе, он начинает передавать выходные данные декодеру, который превращает вложения в переведенный текст.
По мере развития этих моделей мы видим, что они начинают в какой-то простой форме напоминать то, что мы видим сегодня в ChatGPT. Однако мы также можем видеть, насколько ограниченными были эти модели в сравнении. Как и в случае с развитием нашего собственного языка, чтобы действительно улучшить лингвистические способности, нам нужно точно знать, на что следует обращать внимание, чтобы создавать более сложные фразы и предложения.
Модель 3 – Обучение вниманием и масштабирование с помощью Transformers
Ранее мы отмечали, что на телеграфном этапе дети начинали составлять короткие предложения из двух и более слов. Одним из ключевых аспектов этого этапа овладения языком является то, что дети начинают учиться строить правильные предложения.
Модели RNN и Seq2Seq помогли языковым моделям обрабатывать несколько последовательностей слов, но они по-прежнему были ограничены в длине предложений, которые они могли обрабатывать. По мере увеличения длины предложения нам нужно обращать внимание на большинство вещей в предложении.
Например, возьмем следующее предложение: «В комнате было такое напряжение, что его можно было порезать ножом». Там много чего происходит. Чтобы знать, что здесь мы не режем что-то ножом в буквальном смысле, нам нужно связать «разрезать» с «напряжением» в начале предложения.
По мере увеличения длины предложения становится все труднее понять, какие слова к какому относятся, чтобы сделать вывод о правильном значении. Именно здесь RNN начали сталкиваться с ограничениями, и нам понадобилась новая модель, чтобы перейти к следующему этапу овладения языком.
«Подумайте о том, чтобы подвести итог разговору, который становится все длиннее и длиннее, с фиксированным лимитом слов. С каждым шагом начинаешь терять все больше и больше информации»
В 2017 году группа исследователей из Google опубликовала статью, в которой предложила метод, позволяющий моделям лучше обращать внимание на важный контекст в фрагменте текста.
Они разработали способ, позволяющий языковым моделям более легко находить необходимый им контекст при обработке входной последовательности текста. Они назвали этот подход «архитектурой-трансформером», и на сегодняшний день он представляет собой самый большой шаг вперед в области обработки естественного языка.
Этот механизм поиска облегчает модели определение того, какое из предыдущих слов предоставило больше контекста текущему обрабатываемому слову. RNN пытаются предоставить контекст, передавая агрегированное состояние всех слов, которые уже были обработаны на каждом этапе. Подумайте о том, чтобы подвести итог разговору, который становится все длиннее и длиннее, с фиксированным количеством слов. С каждым шагом вы начинаете терять все больше и больше информации. Вместо этого преобразователи взвешивали слова (или токены, которые являются не целыми словами, а частями слов) на основе их важности для текущего слова с точки зрения его контекста. Это облегчило обработку все более и более длинных последовательностей слов без узких мест, наблюдаемых в RNN. Этот новый механизм внимания также позволил обрабатывать текст параллельно, а не последовательно, как в RNN.
Итак, представьте себе предложение типа «Животное не перешло улицу, потому что слишком устало». Для RNN необходимо будет представлять все предыдущие слова на каждом этапе. По мере увеличения количества слов между «оно» и «животное» RNN становится все труднее определить правильный контекст.

Благодаря архитектуре-трансформеру модель теперь имеет возможность искать слово, которое, скорее всего, относится к «оно». На диаграмме ниже показано, как модели-трансформеры могут сосредоточиться на «животной» части текста при попытке обработать предложение.
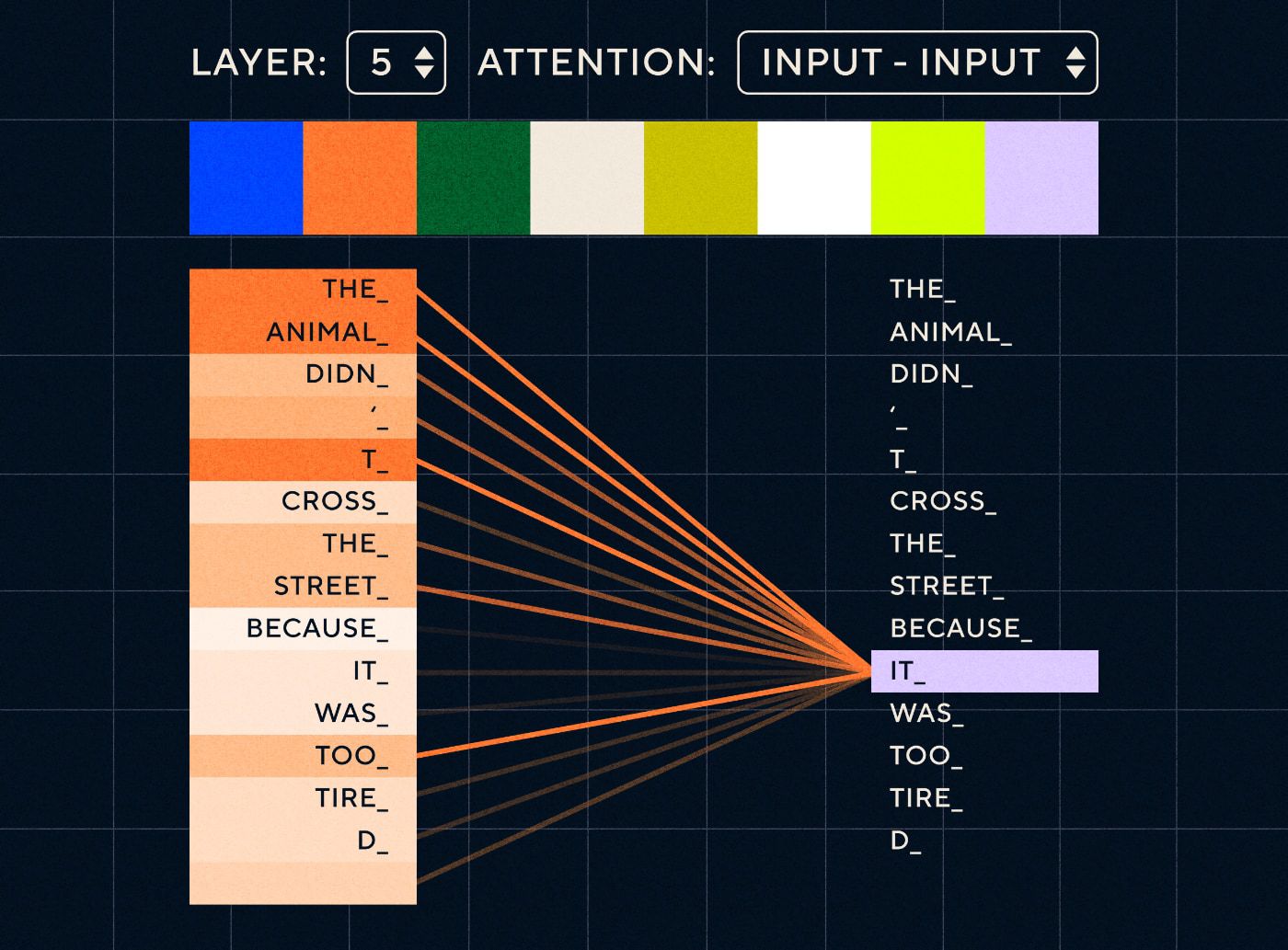
Источник: Иллюстрированный трансформер.
На диаграмме выше показано внимание на уровне 5 сети. На каждом уровне модель строит свое понимание предложения и «обращает внимание» на определенную часть входных данных, которая, по ее мнению, более соответствует шагу, который она обрабатывает в данный момент, то есть она уделяет больше внимания « животное» для «оно» в этом слое. Источник: Иллюстрированный Трансформер.
Думайте об этом как о базе данных, в которой можно найти слово с наивысшим баллом, которое, скорее всего, связано с «оно».
Благодаря этому развитию языковые модели не ограничивались анализом коротких текстовых последовательностей. Вместо этого вы можете использовать более длинные текстовые последовательности в качестве входных данных. Мы знаем, что предоставление детям большего количества слов посредством «увлеченного разговора» помогает улучшить их языковое развитие.
Аналогичным образом, благодаря новому механизму внимания языковые модели смогли анализировать больше разнообразных типов текстовых обучающих данных. Сюда входили статьи в Википедии, онлайн-форумы, Twitter и любые другие текстовые данные, которые вы могли проанализировать. Как и в случае с развитием детей, знакомство со всеми этими словами и их использование в различных контекстах помогло языковым моделям развить новые и более сложные лингвистические способности.
Именно на этом этапе мы начали наблюдать гонку масштабирования, когда люди добавляли в эти модели все больше и больше данных, чтобы увидеть, чему они могут научиться. Людям не нужно было маркировать эти данные — исследователи могли просто очистить Интернет, передать их модели и посмотреть, что она изучила.
«Такие модели, как BERT, побили все доступные рекорды по обработке естественного языка. Фактически, наборы тестовых данных, которые использовались для этих задач, были слишком простыми для этих моделей трансформаторов».
Модель BERT (представления двунаправленного кодировщика от трансформаторов) заслуживает особого упоминания по нескольким причинам. Это была одна из первых моделей, в которой использовалась функция внимания, лежащая в основе архитектуры Transformer. Во-первых, BERT был двунаправленным, поскольку мог просматривать текст как слева, так и справа от текущего ввода. Это отличалось от RNN, которые могли обрабатывать текст только последовательно слева направо. Во-вторых, BERT также использовал новую технику обучения, называемую «маскирование», которая в некотором смысле заставляла модель изучать значение различных входных данных путем «скрытия» или «маскировки» случайных токенов, чтобы гарантировать, что модель не сможет «обмануть» и сосредоточьтесь на одном токене в каждой итерации. И, наконец, BERT можно настроить для выполнения различных задач НЛП. Для выполнения этих задач его не нужно было обучать с нуля.
Результаты были потрясающими. Такие модели, как BERT, побили все доступные рекорды обработки естественного языка. Фактически, наборы тестовых данных, которые использовались для этих задач, были слишком простыми для этих моделей трансформаторов.
Теперь у нас появилась возможность обучать большие языковые модели, которые служили основой для новых задач обработки естественного языка. Раньше люди в основном обучали свои модели с нуля. Но теперь предварительно обученные модели, такие как BERT и ранние модели GPT, были настолько хороши, что не было смысла делать это самостоятельно. На самом деле эти модели были настолько хороши, что люди обнаружили, что они могут выполнять новые задачи с относительно небольшим количеством примеров — их описывали как «обучающихся с небольшим количеством попыток», подобно тому, как большинству людей не нужно слишком много примеров, чтобы понять новые концепции.
Это был переломный момент в развитии этих моделей и их лингвистических возможностей. Теперь нам просто нужно было лучше научиться создавать инструкции.
Модель 4. Инструкции по обучению с помощью InstructGPT
Одна из вещей, которой дети учатся на заключительном этапе овладения языком, на этапе составления нескольких слов, — это способность использовать служебные слова для соединения элементов, несущих информацию, в предложении. Служебные слова рассказывают нам об отношениях между разными словами в предложении. Если мы хотим создавать инструкции, то языковые модели должны иметь возможность создавать предложения со словами содержания и функциональными словами, которые отражают сложные отношения. Например, в следующей инструкции функциональные слова выделены жирным шрифтом:
- « Я хочу, чтобы ты написал письмо…»
- «Скажите мне , что вы думаете о приведенном выше тексте»
Но прежде чем мы смогли попытаться обучить языковые модели следовать инструкциям, нам нужно было точно понять, что они уже знают об инструкциях.
GPT-3 от OpenAI был выпущен в 2020 году. Это было представление о том, на что способны эти модели, но нам все еще нужно было понять, как раскрыть основные возможности этих моделей. Как мы могли бы взаимодействовать с этими моделями, чтобы заставить их выполнять различные задачи?
Например, GPT-3 показал, что увеличение размера модели и данных обучения позволило осуществить то, что авторы назвали «метаобучением» — именно здесь языковая модель развивает широкий набор лингвистических способностей, многие из которых были неожиданными, и может использовать эти способности. навыки понимания поставленной задачи.
«Сможет ли модель понять смысл инструкции и выполнить задачу, а не просто предсказывать следующее слово?»
Помните, что GPT-3 и более ранние языковые модели не были предназначены для развития этих навыков — их в основном обучали просто предсказывать следующее слово в последовательности текста. Но благодаря достижениям в области RNN, Seq2Seq и сетей внимания, эти модели смогли обрабатывать больше текста в более длинных последовательностях и лучше фокусироваться на соответствующем контексте.
Вы можете думать о GPT-3 как о тесте, чтобы увидеть, как далеко мы можем зайти. Насколько большими мы могли бы сделать модели и сколько текста мы могли бы в них передать? Затем, после этого, вместо того, чтобы просто передавать модели некоторый входной текст для завершения, мы могли бы использовать входной текст в качестве инструкции. Сможет ли модель понять смысл инструкции и выполнить задачу, а не просто предсказывать следующее слово? В каком-то смысле это было похоже на попытку понять, на каком этапе освоения языка достигли эти модели.
Сейчас мы называем это «подсказкой», но в 2020 году, на момент выхода статьи, это была совершенно новая концепция.
Галлюцинации и выравнивание
Проблема с GPT-3, как мы теперь знаем, заключалась в том, что он не очень хорошо следил за инструкциями во входном тексте. GPT-3 может следовать инструкциям, но легко теряет внимание, понимает только простые инструкции и склонен что-то выдумывать. Другими словами, модели не «согласованы» с нашими намерениями. Таким образом, проблема сейчас не столько в улучшении языковых способностей моделей, сколько в их способности следовать инструкциям.
Стоит отметить, что GPT-3 никогда особо не обучался по инструкциям. Не говорилось, что такое инструкция, чем она отличается от другого текста и как она должна следовать инструкциям. В каком-то смысле его «обманули» и заставили следовать инструкциям, заставив «завершить» подсказку, как и другие последовательности текста. В результате OpenAI необходимо было обучить модель, которая могла бы лучше следовать инструкциям, как человек. И они сделали это в статье с метким названием «Обучение языковых моделей следованию инструкциям с обратной связью от людей», опубликованной в начале 2022 года. Позднее в том же году InstructGPT окажется предшественником ChatGPT.
Шаги, описанные в этом документе, также использовались для обучения ChatGPT. Обучение обучению проходило в 3 основных этапа:
- Шаг 1. Точная настройка GPT-3. Поскольку GPT-3, казалось, так хорошо справлялся с обучением за несколько шагов, было решено, что было бы лучше, если бы он был точно настроен на примерах инструкций высокого качества. Цель заключалась в том, чтобы упростить согласование намерения инструкции с сгенерированным ответом. Для этого OpenAI попросила людей-маркировщиков создавать ответы на некоторые запросы, отправленные людьми, использующими GPT-3. Используя реальные инструкции, авторы надеялись отразить реалистичное «распределение» задач, которые пользователи пытались выполнить с помощью GPT-3. Они использовались для точной настройки GPT-3, чтобы помочь ему улучшить способность быстрого реагирования.
- Шаг 2. Попросите людей оценить новый и улучшенный GPT-3. Чтобы оценить новую доработанную инструкцию GPT-3, маркировщики теперь оценивали производительность моделей по различным подсказкам без заранее определенного ответа. Рейтинг был связан с важными факторами соответствия, такими как полезность, правдивость, отсутствие токсичности, предвзятости или вреда. Итак, дайте модели задачу и оцените ее производительность на основе этих показателей. Результаты этого ранжирования затем использовались для обучения отдельной модели, чтобы предсказать, какие результаты, скорее всего, предпочтут производители этикеток. Эта модель известна как модель вознаграждения (RM).
- Шаг 3. Используйте RM для обучения на дополнительных примерах. Наконец, RM использовался для обучения новой модели инструкций, чтобы лучше генерировать ответы, соответствующие предпочтениям человека.
Трудно полностью понять, что здесь происходит с обучением с подкреплением на основе обратной связи с людьми (RLHF), моделями вознаграждения, обновлениями политики и так далее.
Самый простой способ думать об этом состоит в том, что это всего лишь способ дать людям возможность генерировать лучшие примеры того, как следовать инструкциям. Например, подумайте, как бы вы попытались научить ребенка говорить спасибо:
- Родитель: «Когда кто-то дает тебе Х, ты говоришь спасибо». Это шаг 1, пример набора данных с подсказками и соответствующими ответами.
- Родитель: «Что ты скажешь Y здесь?». Это шаг 2, на котором мы просим ребенка дать ответ, а затем родитель его оценивает. "Да, это хорошо."
- Наконец, при последующих встречах родитель будет вознаграждать ребенка на основе хороших или плохих примеров ответов в аналогичных сценариях в будущем. Это шаг 3, на котором происходит поведение подкрепления.
Со своей стороны, OpenAI утверждает, что все, что она делает, — это просто раскрывает возможности, которые уже присутствовали в таких моделях, как GPT-3, «но которые было трудно получить только с помощью быстрого проектирования», как говорится в документе.
Другими словами, ChatGPT на самом деле не изучает « новые » возможности, а просто изучает лучший лингвистический « интерфейс » для их использования.
Магия языка
ChatGPT кажется волшебным скачком вперед, но на самом деле это результат кропотливого технологического прогресса, продолжавшегося десятилетиями.
Глядя на некоторые основные разработки в области искусственного интеллекта и НЛП за последнее десятилетие, мы можем увидеть, что ChatGPT «стоит на плечах гигантов». Более ранние модели впервые научились определять значение слов. Затем последующие модели соединили эти слова вместе, и мы смогли обучить их выполнять такие задачи, как перевод. Как только они научились обрабатывать предложения, мы разработали методы, которые позволили этим языковым моделям обрабатывать все больше и больше текста и развивать способность применять эти знания для новых и непредвиденных задач. А затем, с помощью ChatGPT, мы наконец разработали возможность лучше взаимодействовать с этими моделями, определяя наши инструкции в формате естественного языка.
«Поскольку язык является средством выражения наших мыслей, приведет ли обучение компьютеров всей мощи языка к созданию независимого искусственного интеллекта?»
Однако эволюция НЛП раскрывает более глубокую магию, к которой мы обычно слепы – магию самого языка и то, как мы, люди, его приобретаем.
До сих пор остается много открытых вопросов и споров о том, как дети изучают язык. Также возникают вопросы о том, существует ли общая базовая структура для всех языков. Эволюционировали ли люди, чтобы использовать язык, или все наоборот?
Любопытно то, что по мере того, как ChatGPT и его потомки улучшают свое лингвистическое развитие, эти модели могут помочь ответить на некоторые из этих важных вопросов.
Наконец, поскольку язык является средством выражения наших мыслей, приведет ли обучение компьютеров всей мощи языка к созданию независимого искусственного интеллекта? Как всегда в жизни, еще так многому предстоит научиться.
