
Взлом The Topic Graph с помощью Википедии и Google Language API
Опубликовано: 2019-08-27Одна из моих любимых презентаций за последние десять лет была сделана Марком Джонстоном в 2014 году, когда он еще работал в Distilled. Колода называлась «Как создавать лучшие идеи контента», и я использовал ее как свою библию в течение нескольких лет, создавая команды для выполнения тяжелой работы по продвижению контента.
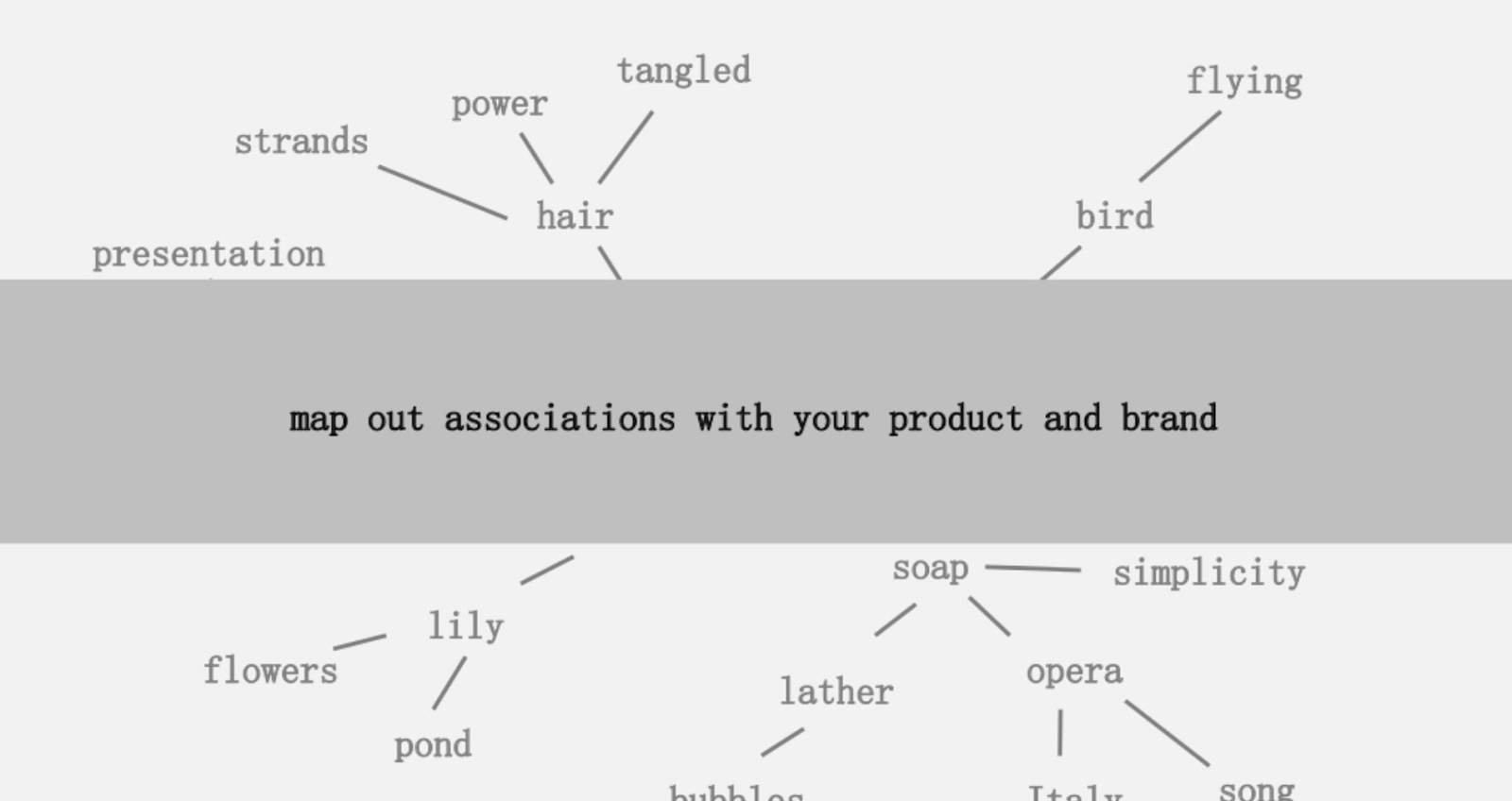
Одна из предложенных идей заключалась в том, чтобы создать визуальную карту связи слов, связанных с вашим продуктом или брендом, чтобы вы могли отойти в сторону и искать способы объединить ассоциации во что-то интересное. Целью является производство идей, которые он определяет как « новую комбинацию ранее не связанных элементов таким образом, чтобы повысить ценность».
В этой статье мы используем гораздо более левополушарный подход, используя Python, языковой API Google и Википедию для изучения ассоциаций сущностей, которые существуют из исходной темы. Целью является высокоуровневое представление взаимосвязей сущностей по тематическому графику. Эта статья не для среднего читателя. Читатели, знакомые с Python и обладающие хотя бы базовым уровнем навыков кодирования, сочтут его гораздо более поучительным.
Идея
Следуя идее картирования Марка Джонстона, я подумал, что было бы интересно позволить Google и Википедии определять структуру темы, начиная с исходной темы или веб-страницы. Цель состоит в том, чтобы визуально построить сопоставление отношений с основной темой в виде древовидного графика, который можно просматривать для поиска связей и, возможно, генерировать идеи контента. На следующем изображении представлена первоначальная идея дизайна.
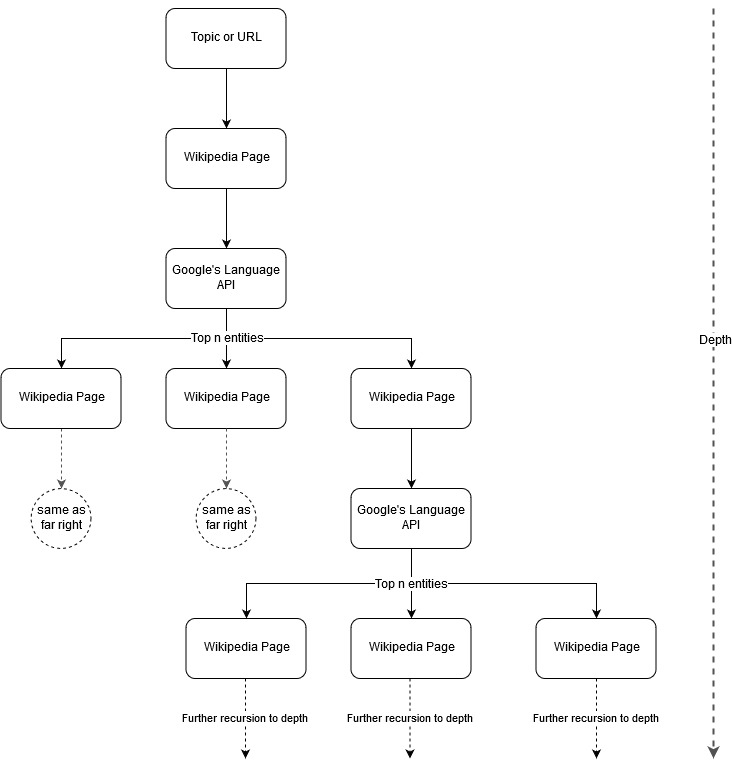
По сути, мы даем инструменту тему или URL-адрес и позволяем Language API Google выбирать первые n (3 в наших примерах) объектов (которые включают URL-адреса Википедии) для каждой страницы объекта, и мы продолжаем рекурсивно строить сетевой график для каждого найденного объекта. до максимальной глубины.
Фон используемых инструментов
Языковой API Google
Языковой API Google позволяет вам передавать ему либо обычный текст, либо HTML, и он волшебным образом возвращает все различные объекты, связанные с контентом. API делает больше, но для этого анализа мы сосредоточимся только на этой части. Вот список типов объектов, которые он возвращает:
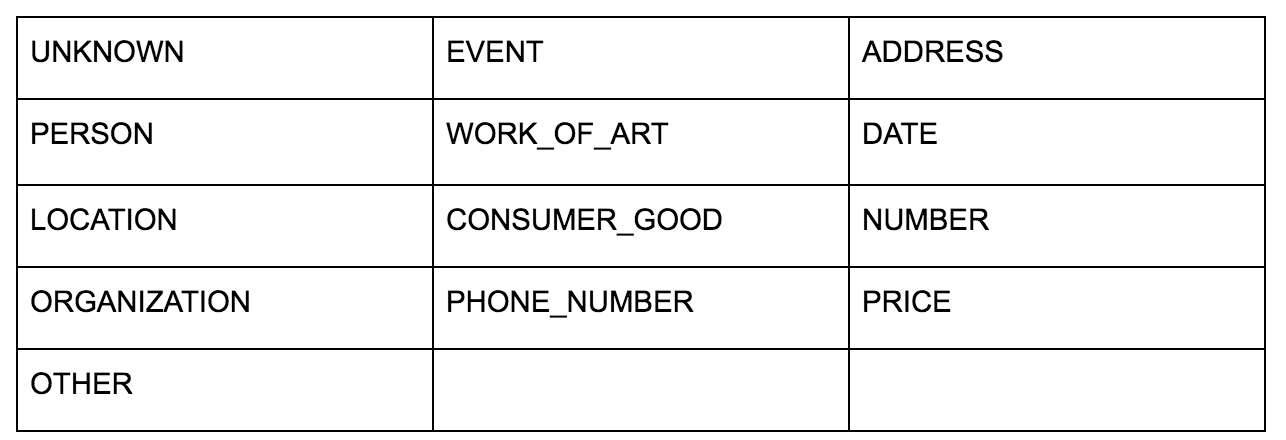
Идентификация сущностей долгое время была фундаментальной частью обработки естественного языка (NLP), и правильной терминологией для этой задачи является распознавание именованных сущностей (NER). NER — сложная задача, потому что многие слова имеют разные значения в зависимости от используемого контекста, поэтому инструменты NLP или API должны понимать полный контекст, окружающий термины, чтобы иметь возможность правильно идентифицировать их как конкретную сущность.
Я дал довольно подробный обзор этого API и, в частности, сущностей, в статье на opensource.com, если вы хотите наверстать упущенное, прежде чем закончить эту статью.
Одна интересная особенность Google Language API заключается в том, что в дополнение к поиску релевантных сущностей он также отмечает, насколько они связаны с документом в целом (заметность), а для некоторых предоставляет соответствующую статью в Википедии (граф знаний), представляющую сущность.
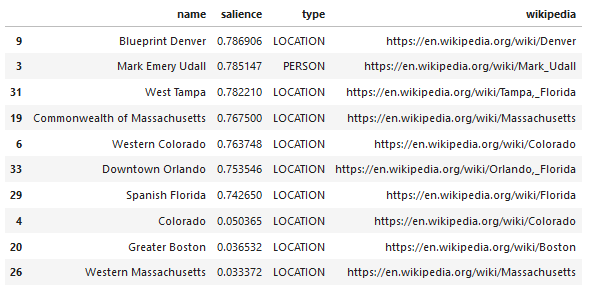
Вот пример того, что возвращает API (отсортировано по значимости):
Разработчик oncrawl
 Учить больше
Учить большепитон
Python — это программный язык, ставший популярным в области науки о данных благодаря большому и растущему набору библиотек, которые упрощают прием, очистку, манипулирование и анализ больших наборов данных. Он также извлекает выгоду из среды совместной работы, называемой блокнотами Jupyter, которая позволяет пользователям легко тестировать и комментировать свой код без особых усилий.
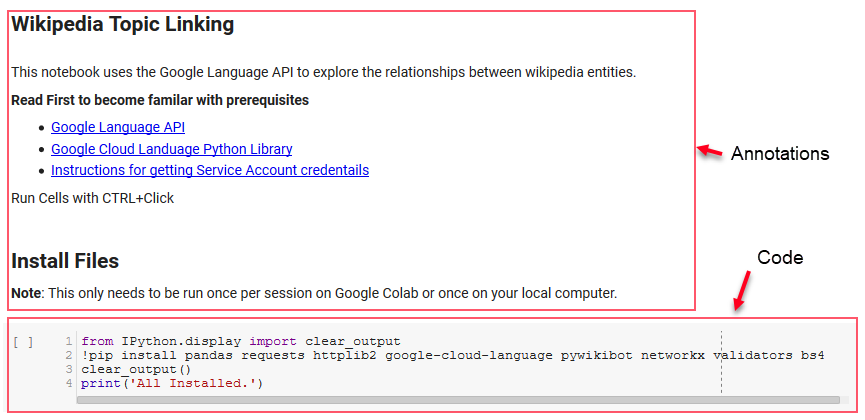
В этом обзоре мы будем использовать несколько ключевых библиотек, которые позволят нам делать некоторые интересные вещи с данными Google NLP.
- Pandas: подумайте о том, что вы можете написать сценарий Microsoft Excel для чтения, сохранения, анализа или перестановки электронных таблиц, и вы получите представление о том, что делает Pandas. Панды потрясающие. (связь)
- Networkx: Networkx — это инструмент для построения графов узлов и ребер, которые определяют отношения между узлами. Он также имеет встроенную поддержку построения графиков, поэтому их легко визуализировать. (связь)
- Pywikibot: Pywikibot — это библиотека, которая позволяет вам взаимодействовать с Википедией для поиска, редактирования, поиска взаимосвязей и т. д. со всем содержимым каждого сайта Википедии. (связь)
Процесс
Здесь мы делимся блокнотом Google Colab, который можно использовать для отслеживания. (Особая благодарность Тайлеру Рирдону за проверку статьи и этого блокнота на вменяемость.)
Настройка
Первые несколько ячеек в записной книжке связаны с установкой некоторых библиотек, предоставлением доступа к этим библиотекам для Python и предоставлением учетных данных и файла конфигурации для Google Language API и Pywikibot соответственно. Вот все библиотеки, которые нам нужно установить, чтобы инструмент мог работать:
- панды
- Запросы
- httplib2
- облачный язык Google
- pywikibot
- сетьx
- валидаторы
- Бс4
Примечание. Самая сложная часть работы с этим блокнотом — это получение учетных данных от Google для доступа к их API. Для тех, кто не знаком с этим, это займет час или около того, чтобы понять. Чтобы помочь вам, мы связали инструкции по получению учетных данных служебной учетной записи в верхней части записной книжки. Ниже приведен пример того, как мы включили наши.
Функции для победы
В ячейке, обозначенной «Определить некоторые функции для Google NLP», мы разрабатываем восемь функций, которые обрабатывают такие вещи, как запросы к Language API, взаимодействие с Википедией, извлечение текста веб-страницы, построение и построение графиков. Функции — это, по сути, небольшие блоки кода, которые принимают некоторые данные о настройках, выполняют некоторую работу и что-то производят. Все функции прокомментированы, чтобы сообщить переменные, которые они принимают, и то, что они производят.

Тестирование API
Следующие две ячейки принимают URL-адрес, извлекают текст из URL-адреса и извлекают объекты из Google Language API. Один извлекает только объекты, имеющие URL-адреса Википедии, а другой извлекает все объекты с этой страницы.
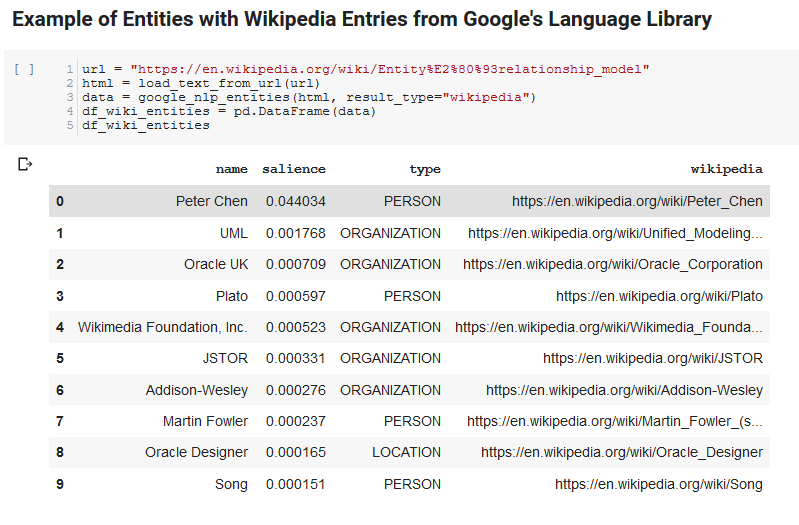
Это был важный первый шаг, чтобы получить правильную часть извлечения контента и понять, как Language API работает и возвращает данные.
Сетьx
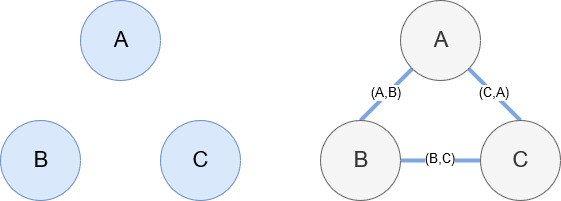
Networkx, как упоминалось ранее, — замечательная библиотека, с которой довольно легко работать. По сути, вы должны сообщить ему, какие у вас узлы и как они связаны. Например, на изображении ниже мы даем Networkx три узла (A, B, C). Затем мы сообщаем Networkx, что они соединены ребрами (A,B), (B,C), (C,A), определяющими отношения между узлами. Для нашего использования объекты с URL-адресами Википедии будут узлами, а ребра определяются новыми объектами, найденными на текущей странице объекта. Итак, если мы просматриваем страницу Википедии для сущности А и на этой странице обнаруживаем сущность Б, то это граница между сущностью А и сущностью Б.
Собираем все вместе
Следующий раздел записной книжки называется Ветвление темы Википедии по URL. Вот где происходит волшебство. Ранее мы определили специальную функцию (recurse_entities), которая выполняет рекурсию по страницам Википедии вслед за новыми сущностями, определенными языковым API Google. Мы также добавили очень неудобную для понимания функцию (hierarchy_pos), взятую из Stack Overflow, которая хорошо справляется с представлением древовидного графа с множеством узлов. В ячейке ниже мы определяем ввод как «Поисковая оптимизация» и указываем глубину 3 (это количество страниц, которые он рекурсивно отслеживает) и ограничение 3 (это количество объектов, которые он извлекает на странице).
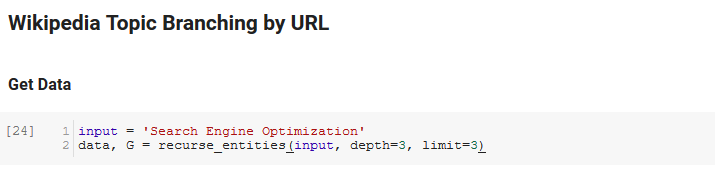
Запустив его для термина «Поисковая оптимизация», мы можем увидеть следующий путь, по которому прошел инструмент, начиная со страницы поисковой оптимизации Википедии (уровень 0) и следуя рекурсивно страницам до указанной максимальной глубины (3).

Затем мы берем все найденные объекты и добавляем их в Pandas DataFrame, что упрощает сохранение в формате CSV. Мы сортируем эти данные по заметности (по тому, насколько важен объект для страницы, на которой он был найден), но эта оценка в этом контексте немного вводит в заблуждение, поскольку она не говорит вам, насколько объект связан с вашим исходным термином (« Поисковая оптимизация»). Мы оставим эту дальнейшую работу читателю.

Наконец, мы строим график, построенный инструментом, чтобы показать связанность всех объектов. В приведенной ниже ячейке параметры, которые вы можете передать функции, следующие: ( G : график, построенный ранее с помощью функции recurse_entities, w: ширина графика, h: высота графика, c: круговой процент график и имя файла: файл PNG, сохраненный в папке изображений.)

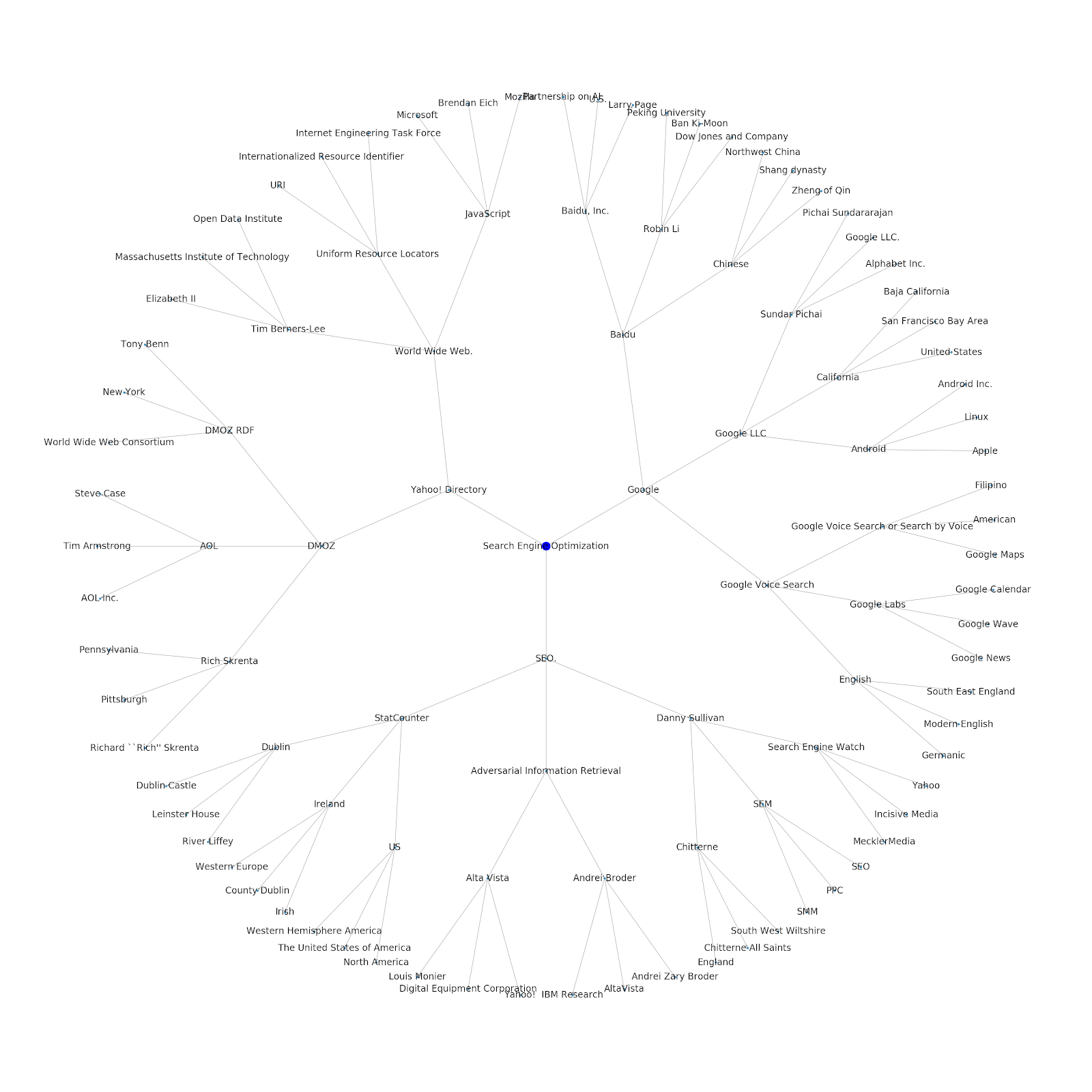
Мы добавили возможность указать исходную тему или исходный URL-адрес. В этом случае мы смотрим на объекты, связанные со статьей Проблемы индексации Google продолжаются, но это другое.
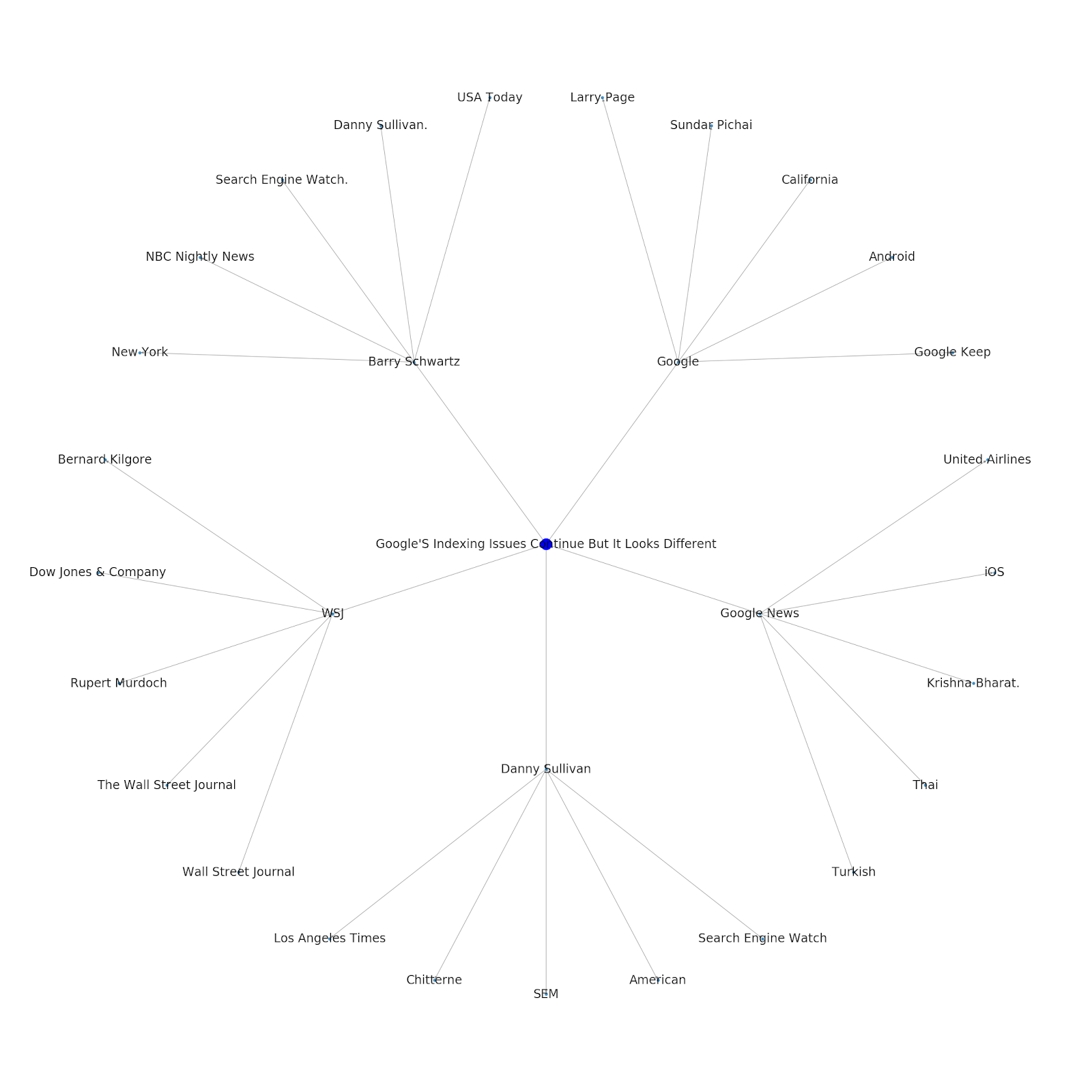
Вот график сущностей Google/Wikipedia для Python.
Что это значит
Понимание тематического уровня Интернета интересно с точки зрения SEO, поскольку оно заставляет вас думать о том, как вещи связаны, а не только об отдельных запросах. Поскольку Google использует этот слой, чтобы сопоставлять интересы отдельных пользователей с темами, как упоминалось в их повторном представлении Google Discover, он может стать более важным рабочим процессом для SEO-специалистов, ориентированных на данные. На приведенном выше графике «Python» можно сделать вывод, что знакомство пользователя с темами, связанными с исходной темой, может быть разумным показателем их уровня знаний по исходной теме.
В приведенном ниже примере показаны два пользователя с зелеными выделениями, показывающие их исторический интерес или близость к связанным темам. Пользователь слева, понимающий, что такое IDE, и понимающий, что означают PyPy и CPython, будет гораздо более опытным пользователем Python, чем тот, кто знает, что это язык, но не более того. Это было бы легко превратить в числовые оценки по каждой теме для каждого пользователя.

Вывод
Моя цель сегодня состояла в том, чтобы поделиться довольно стандартным процессом, который я выполняю для тестирования и проверки эффективности различных инструментов или API-интерфейсов с помощью Jupyter Notebooks. Изучение тематического графа невероятно интересно, и мы надеемся, что вы обнаружите, что общие инструменты дадут вам преимущество, необходимое для самостоятельного изучения. С помощью этих инструментов вы можете строить тематические диаграммы, которые исследуют множество уровней отношений, ограниченных только квотой Google Language API (которая составляет 800 000 в день). (Обновление: цена основана на единицах из 1000 символов Юникода, отправленных в API, и бесплатно до 5 тысяч единиц. Поскольку статьи в Википедии могут быть длинными, вы хотите следить за своими расходами. Спасибо Джону Марчу за указание на это.) Если вы улучшите блокнот или найдете интересные случаи, я надеюсь, вы сообщите мне об этом. Вы можете найти меня на @jroakes в Твиттере.