
Ключи к созданию работающего файла Robots.txt
Опубликовано: 2020-02-18Боты, также известные как сканеры или пауки, представляют собой программы, которые автоматически «путешествуют» по сети с одного веб-сайта на другой, используя ссылки в качестве дороги. Хотя файлы robot.txt всегда представляли собой определенные курьезы, они могут быть очень эффективными инструментами. Поисковые системы, такие как Google и Bing, используют ботов для сканирования веб-контента. Файл robots.txt предоставляет различным ботам указания относительно того, какие страницы вашего сайта им не следует сканировать. Вы также можете связать свою XML-карту сайта с robots.txt, чтобы бот имел карту каждой страницы, которую он должен сканировать.
Чем полезен robots.txt?
robots.txt ограничивает количество страниц, которые бот должен сканировать и индексировать в случае ботов поисковых систем. Если вы хотите, чтобы Google не сканировал административные страницы, вы можете заблокировать их в файле robots.txt, чтобы попытаться сохранить страницу вне серверов Google.
Помимо предотвращения индексации страниц, файл robots.txt отлично подходит для оптимизации краулингового бюджета. Бюджет сканирования — это количество страниц, которые Google определил для сканирования на вашем сайте. Обычно сайты с большим авторитетом и большим количеством страниц имеют больший краулинговый бюджет, чем сайты с небольшим количеством страниц и низким авторитетом. Поскольку мы не знаем, какой бюджет сканирования назначен нашему сайту, мы хотим максимально использовать это время, позволяя роботу Googlebot добраться до наиболее важных страниц, а не сканировать страницы, которые мы не хотим индексировать.
Очень важная деталь, которую вам нужно знать о robots.txt, заключается в том, что, хотя Google не будет сканировать страницы, заблокированные robots.txt, они все же могут быть проиндексированы, если на страницу есть ссылка с другого веб-сайта. Чтобы ваши страницы не индексировались и не появлялись в результатах поиска Google, вам необходимо защитить паролем файлы на вашем сервере, использовать метатег noindex или заголовок ответа или полностью удалить страницу (ответьте 404 или 410). Для получения дополнительной информации о сканировании и управлении индексацией вы можете прочитать руководство OnCrawl robots.txt.
[Пример успеха] Управление сканированием ботов Google
 Читать тематическое исследование
Читать тематическое исследованиеПравильный синтаксис robots.txt
Синтаксис robots.txt иногда может быть немного сложным, поскольку разные поисковые роботы интерпретируют синтаксис по-разному. Кроме того, некоторые недобросовестные поисковые роботы рассматривают директивы robots.txt как предложения, а не как определенные правила, которым они должны следовать. Если на вашем сайте есть конфиденциальная информация, важно использовать защиту паролем, помимо блокировки сканеров с помощью файла robots.txt.
Ниже я перечислил несколько моментов, о которых вам нужно помнить при работе с файлом robots.txt:
- Файл robots.txt должен находиться в домене, а не в подкаталоге. Сканеры не проверяют файлы robots.txt в подкаталогах.
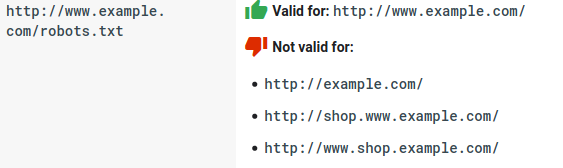
- Для каждого субдомена нужен свой файл robots.txt:
- Robots.txt чувствителен к регистру:
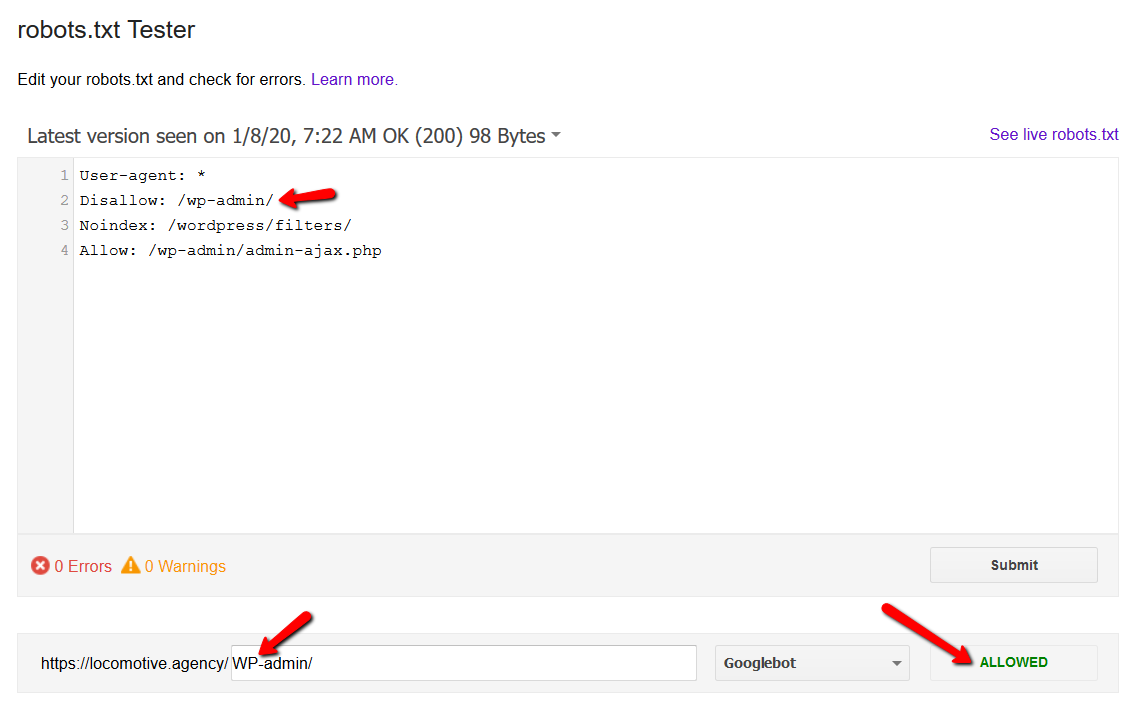
- Директива noindex: когда вы используете noindex в robots.txt, она будет работать так же, как и disallow. Google прекратит сканирование страницы, но сохранит ее в своем индексе. @jroakes и я создали тест, в котором мы использовали директиву Noindex для статьи /wordpress/filters/ и отправили страницу в Google. На скриншоте ниже видно, что URL-адрес заблокирован:
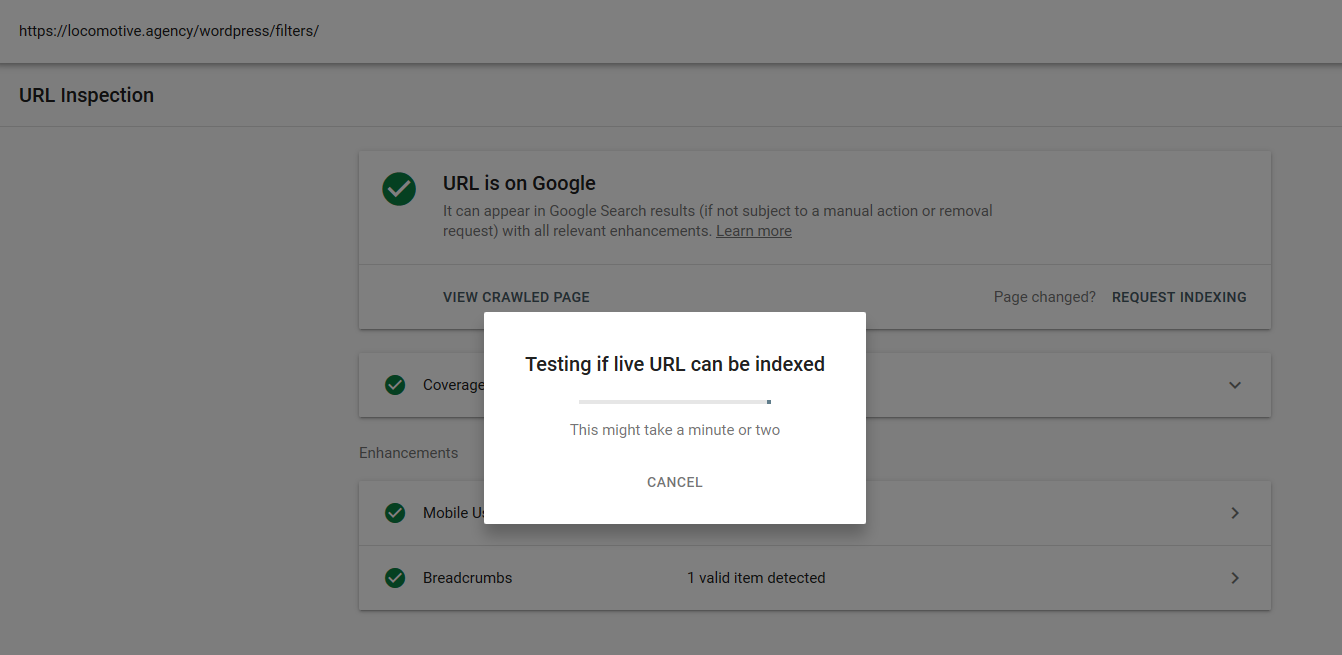
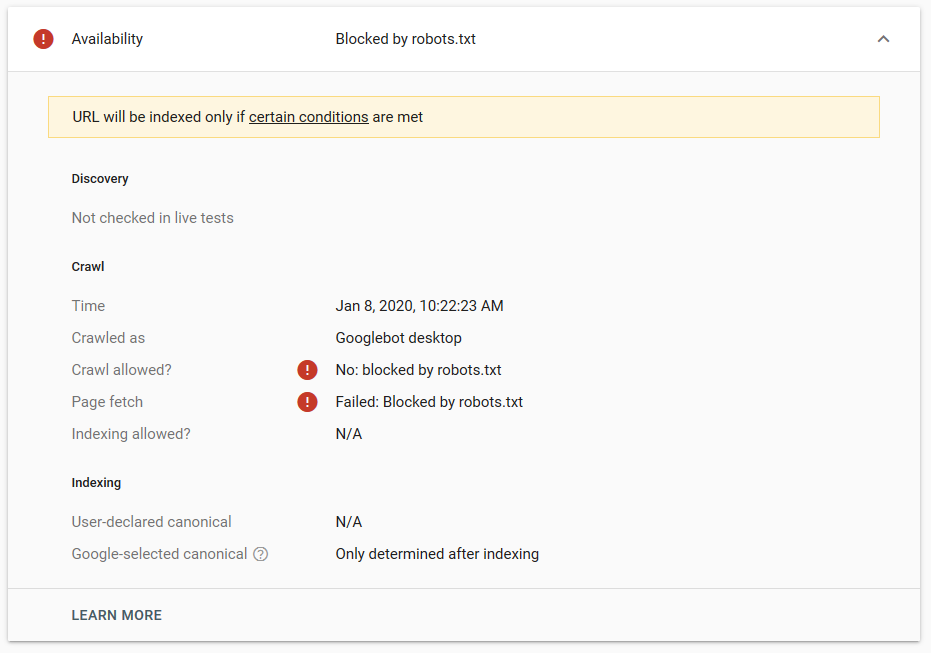
Мы провели несколько тестов в Google, и страница ни разу не была удалена из индекса:

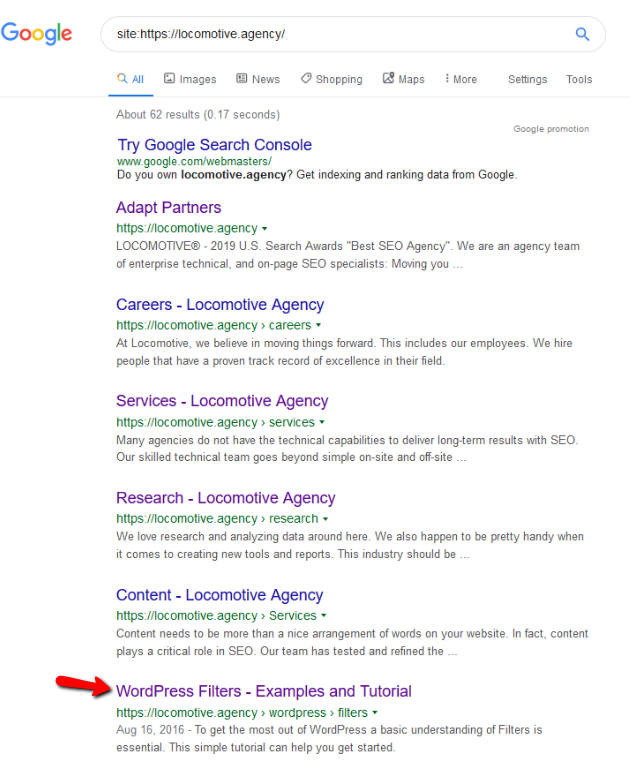
В прошлом году обсуждалась директива noindex, работающая в файле robots.txt и удаляющая страницы, кроме Google. Вот ветка, где Гэри Иллиес заявил, что она уходит. На этом тесте мы видим, что решение Google работает, так как директива noindex не удалила страницу из результатов поиска.
Недавно в твиттере появилась еще одна интересная ветка от Кристиана Оливейры, где он поделился некоторыми деталями, которые следует учитывать при работе с файлом robots.txt.
- Если мы хотим иметь общие правила и правила только для робота Googlebot, нам нужно продублировать все общие правила в User-agent: набор правил для робота Google. Если они не включены, робот Googlebot проигнорирует все правила:

- Еще одно запутанное поведение заключается в том, что приоритет правил (внутри одной и той же группы User-agent) определяется не их порядком, а длиной правила.
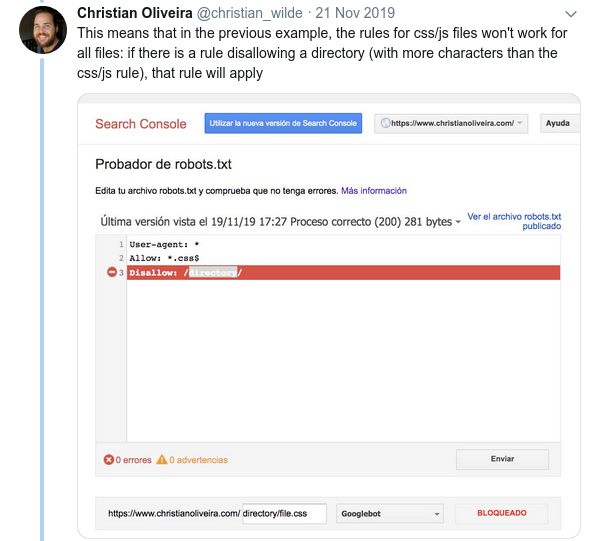
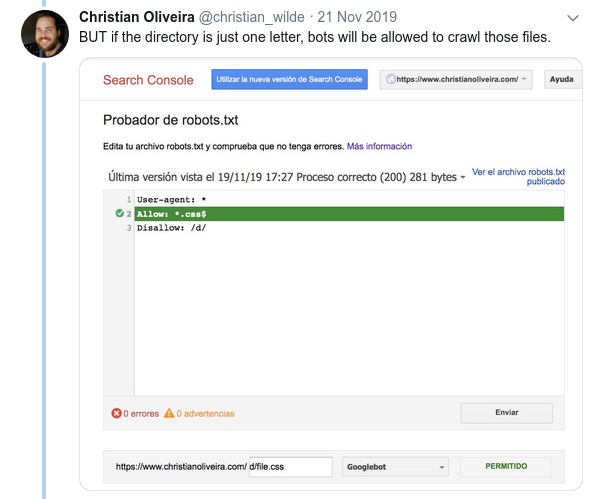
- Теперь, когда у вас есть два правила одинаковой длины и противоположного поведения (одно разрешает сканирование, а другое запрещает его), применяется правило с меньшими ограничениями:
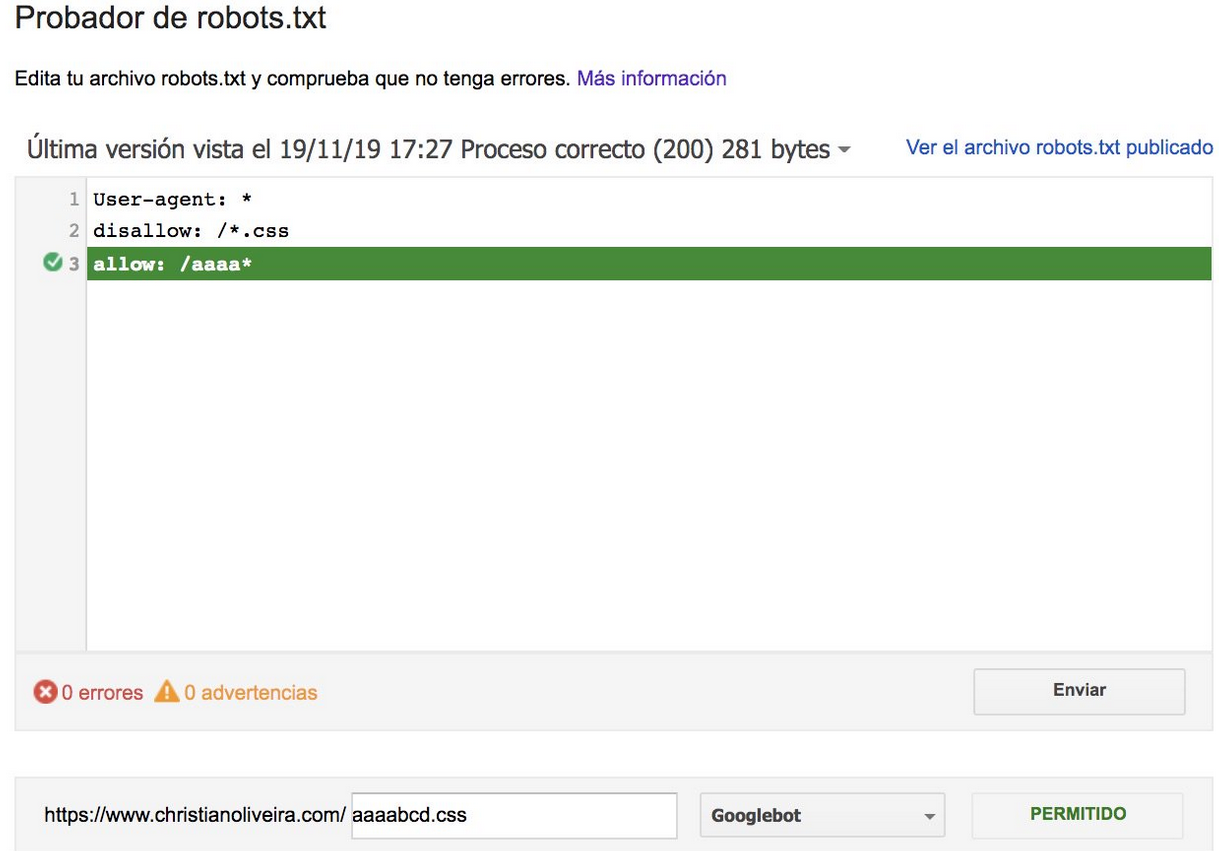
Дополнительные примеры см. в спецификациях robots.txt, предоставленных Google.
Инструменты для тестирования файла Robots.txt
Если вы хотите протестировать файл robots.txt, есть несколько инструментов, которые могут вам помочь, а также пара репозиториев на github, если вы хотите создать свой собственный:
- Дистиллированный
- Google оставил здесь инструмент для тестирования robots.txt из старой консоли поиска Google.
- На Питоне
- На С++
Пример результатов: эффективное использование файла robots.txt для электронной коммерции
Ниже я привел случай, когда мы работали с сайтом Magento, на котором не было файла robots.txt. Magento, как и другие CMS, имеет административные страницы и каталоги с файлами, которые мы не хотим, чтобы Google сканировал. Ниже мы привели примеры некоторых каталогов, включенных в robots.txt:
# # Общие каталоги Magento Запретить: /приложение/ Запретить: /загрузчик/ Запретить: /ошибки/ Запретить: / включает / Запретить: /lib/ Запретить: /pkginfo/ Запретить: /shell/ Запретить: /var/ # # Не индексировать страницу поиска и неоптимизированные категории ссылок Запретить: /catalog/product_compare/ Запретить: /каталог/категория/просмотр/ Запретить: /catalog/product/view/ Запретить: /каталог/товар/галерея/ Запретить: /catalogsearch/
Огромное количество страниц, которые не предназначались для сканирования, сказывалось на их краулинговом бюджете, а роботу Googlebot не удавалось просканировать все страницы продуктов на сайте.
На изображении ниже вы можете увидеть, как количество проиндексированных страниц увеличилось после 25 октября, когда был реализован файл robots.txt:
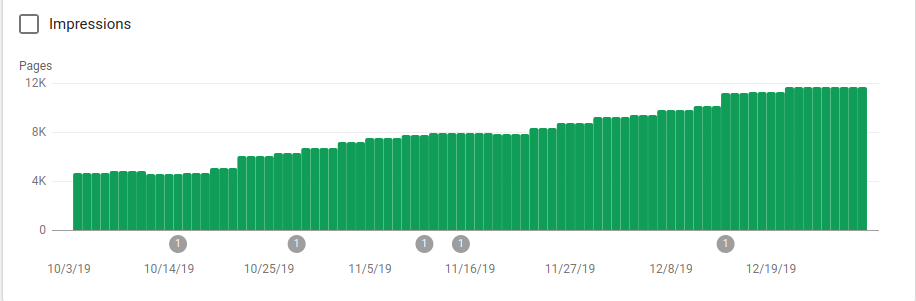
Помимо блокировки нескольких каталогов, которые не должны были сканироваться, роботы включали ссылку на карту сайта. На скриншоте ниже видно, как увеличилось количество проиндексированных страниц по сравнению с исключенными:
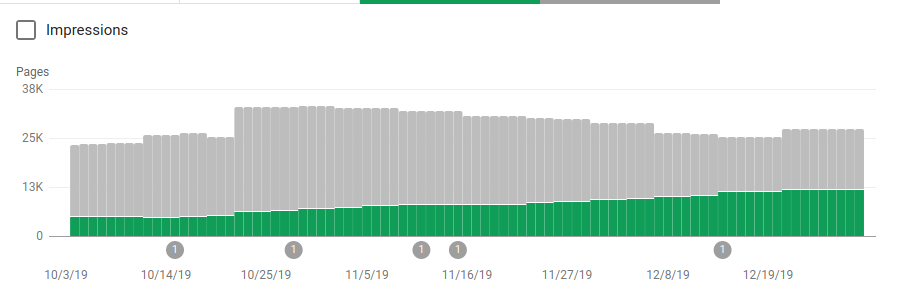
На проиндексированных действительных страницах наблюдается положительная тенденция, показанная зелеными полосами, и отрицательная тенденция на исключенных страницах, представленная серыми полосами.
Подведение итогов
Важность robots.txt иногда можно недооценить, и, как вы можете видеть из этого поста, при его создании необходимо учитывать множество деталей. Но работа окупается: я показал некоторые положительные результаты, которые можно получить, правильно настроив файл robots.txt.