
Как формировать сниппет в эпоху Google как издателя
Опубликовано: 2019-10-22Google уже давно считает себя издателем контента, хотя в последние годы эту тенденцию стало трудно игнорировать. Этому частично способствовали достижения в области машинного обучения и новые функции страницы результатов поисковой системы (SERP).
«Google как издатель контента» — потенциальная проблема для многих владельцев веб-сайтов, так как это сложный выбор. Тебе следует:
- Защитите свой контент и рискуете быть исключенным из результатов Google?
- Предоставлять Google бесплатные источники контента, зная, что Google может не направлять посетителей на ваш сайт?
Новые теги управления сниппетами, которые вступят в силу в конце октября 2019 года, можно рассматривать как заявление о намерениях Google. Они также являются шагом в правильном направлении, предоставляя владельцам веб-сайтов средства для защиты своего контента и контроля за тем, как их страницы отображаются в поисковой выдаче.
Зачем беспокоиться о качественном контенте?
Недвижимость Google по-прежнему обеспечивает около 60% трафика на веб-сайты, в зависимости от вертикали, поэтому отказ от игры Google потенциально может иметь огромное негативное влияние на видимость веб-сайта и трафик. Но в то же время с помощью EAT и Руководства по оценке качества Google четко установил, что качественный контент — это то, что ищут интернет-пользователи, и что веб-сайты должны вкладывать средства в его производство, чтобы выжить.
Эти инвестиции в уникальный, высококачественный контент — это то, что владелец веб-сайта, естественно, должен хотеть защитить. Раздавая контент, веб-сайты позволяют другим провайдерам (в данном случае: поисковым системам) извлекать выгоду из их времени, денег и опыта.
Как Google использует контент?
Google использует, ремиксует и переписывает контент, чтобы дать ответы на вопросы, заданные пользователями поисковых систем. Эти ответы отображаются во многих формах в поисковой выдаче.
Списки результатов поиска или «фрагменты»
Google составляет фрагмент для данной веб-страницы в результатах поиска, используя различные элементы, изначально взятые из самой веб-страницы:
- Тег <название>
- Тег <meta description="Snippet text">
- Разметка Schema.org для поддерживаемых структурированных данных
- URL-адрес
- Фавикон (в мобильных результатах в некоторых регионах)
Сегодня немногие из них используются как есть. Google оставляет за собой право заменить значок. Google прямо заявляет, что их «генерация заголовков и описаний страниц полностью автоматизирована и… [Google использует] ряд различных источников для этой информации, включая описательную информацию в заголовке и метатегах для каждой страницы». Наконец, Google начал подавлять URL-адреса в поисковой выдаче, как показали недавние тесты.
Удаление Google URL-адресов в поисковой выдаче может немного помочь «плохим» TLD.
Если вы не можете сказать, является ли это доменом .io, .org, .net, .ie и т. д., вы не можете предвзято относиться к ним и щелкнуть тот .com, который кажется более законным. Возможно, это не будет огромным влиянием, но может быть незначительным, которое со временем станет больше. pic.twitter.com/CcQ2E0lVtZ
— Росс Хадженс (@RossHudgens) 21 октября 2019 г.
Избранные фрагменты
Google создает избранные фрагменты, которые появляются перед списками результатов поиска, извлекая контент с веб-страницы, который отвечает на вопрос пользователя. В феврале и июне 2019 года были различные эпизоды, когда избранные фрагменты появлялись без указания авторства (или без видимого или легкодоступного указания авторства). В каждом случае Google осуждал намерение обойти права издателя и утверждал, что отсутствие указания авторства было ошибка.
Определения, погода и еда
Поиск определений в словаре или погоды в определенном месте дает ответ в поле автозаполнения без указания авторства и без необходимости выполнять поиск.
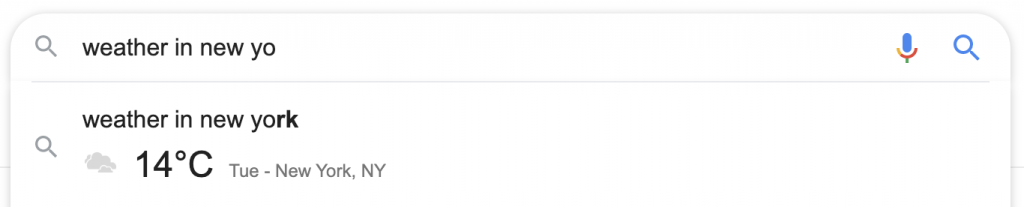
В случае определения, если нажата кнопка поиска, доступно полное определение со звуком, синонимами и другими функциями в SERP. Искателю не нужно посещать сайт Оксфордского словаря, а оксфордская атрибуция отображается небольшим серым текстом под полем определения.
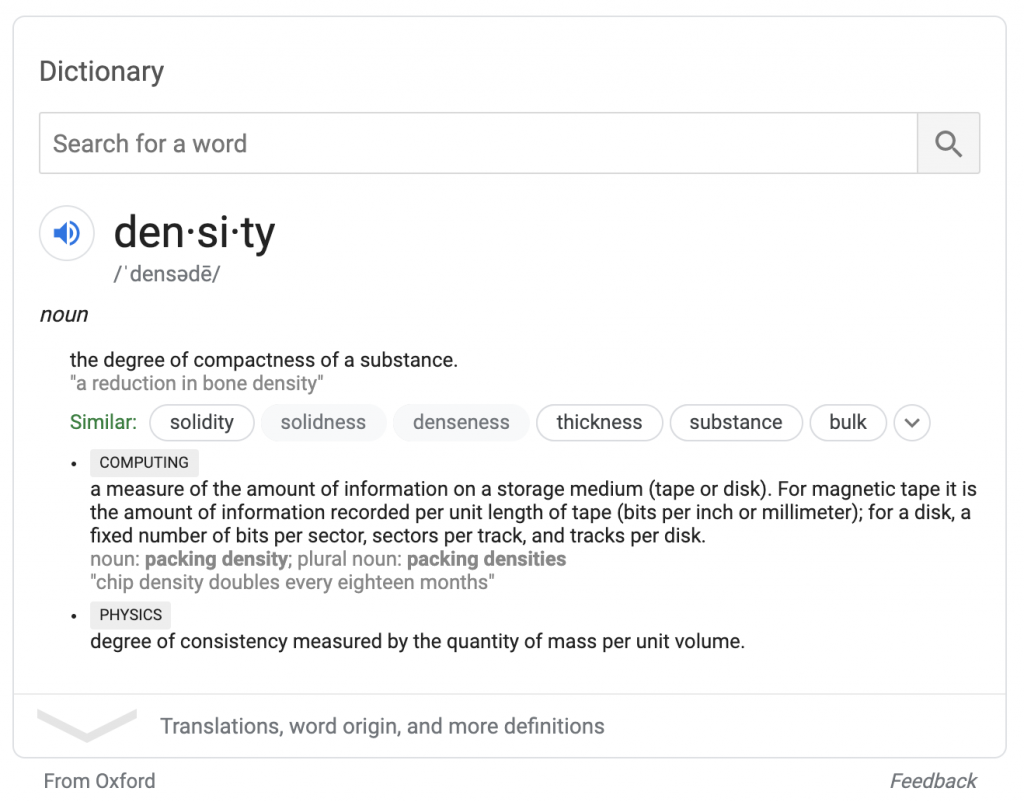
Полный поиск погоды предоставляет аналогичное окно прогноза на основе данных Weather.com. Как и оксфордская атрибуция, атрибуция Weather.com отображается под полем; искатели могут взаимодействовать с данными в поле, даже не посещая Weather.com.
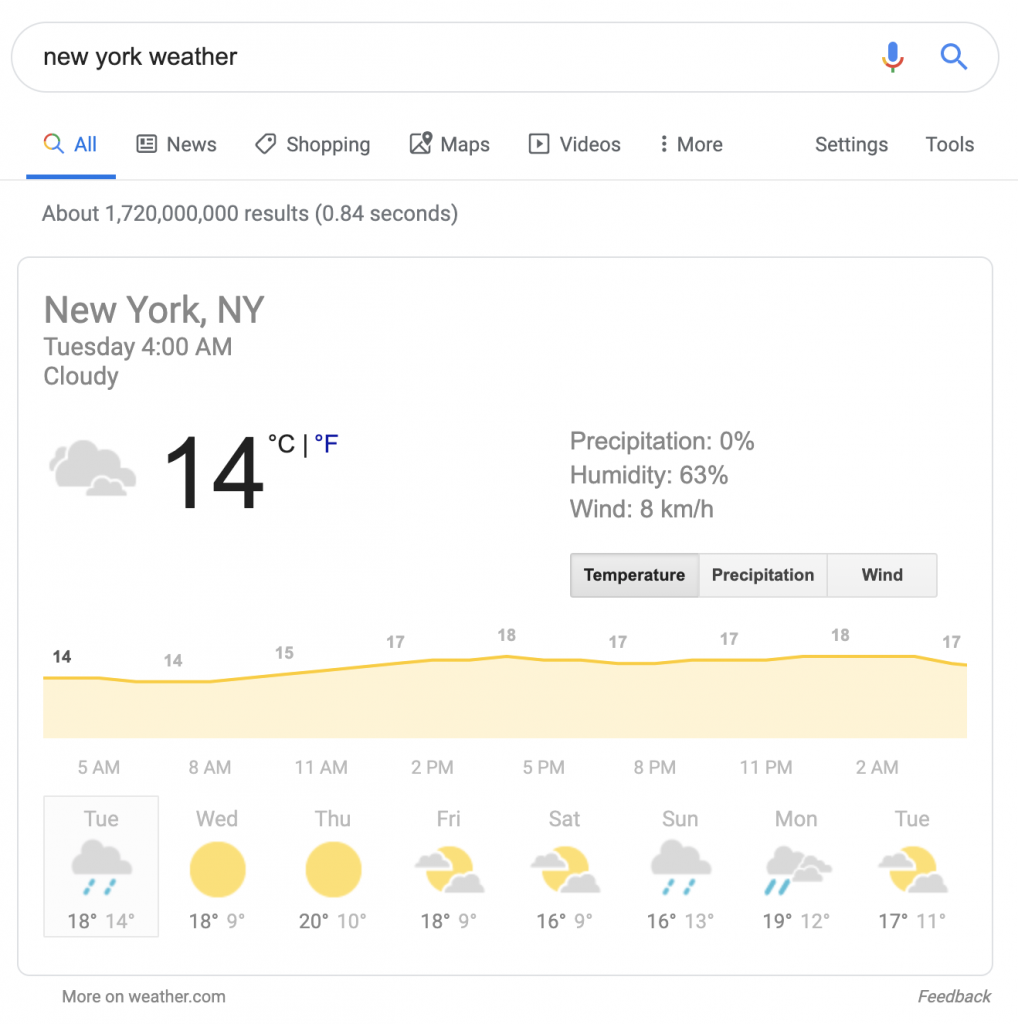
Другой похожий результат поиска относится к пищевой ценности и составу пищи:
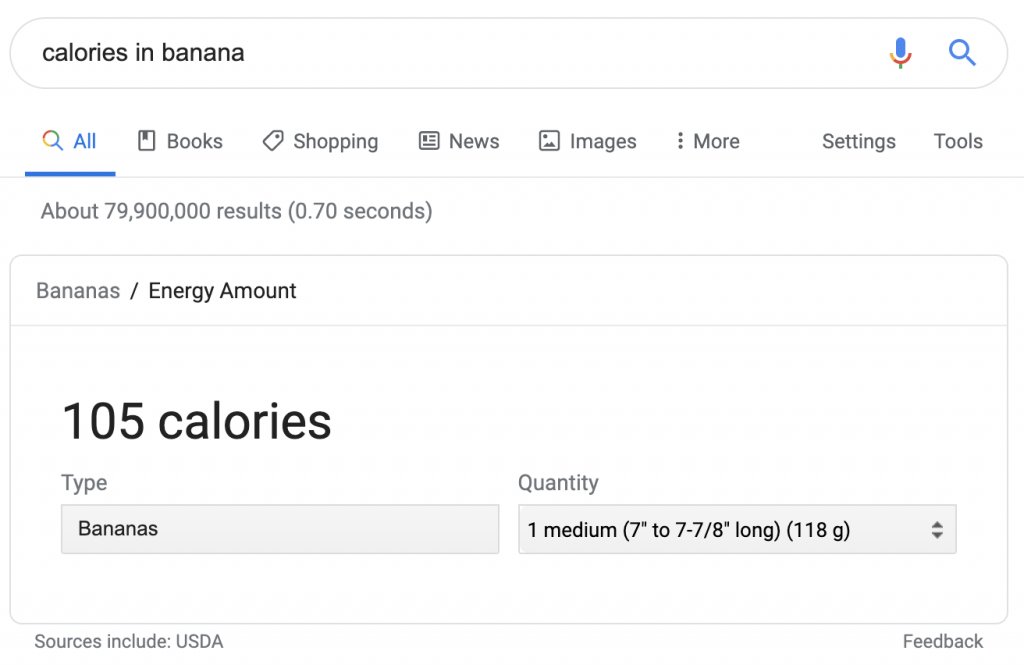
Однако в этом случае атрибуция указана как «источники включают». Если используются другие источники, они не видны и не доступны.
Местные результаты
Многие результаты, связанные с местной деятельностью, также берутся из различных источников для создания поисковой выдачи, которая предоставляет разнообразную агрегированную и сопоставленную информацию. Вместо того, чтобы посещать разные веб-сайты, пользователь может, например, просмотреть список фильмов, которые сейчас идут рядом с ним, посмотреть расписание сеансов в разных кинотеатрах и найти подробную информацию — обзоры, синопсис и многое другое — об отдельных фильмах. Ни в коем случае поисковику не нужно покидать поисковую выдачу, созданную Google.
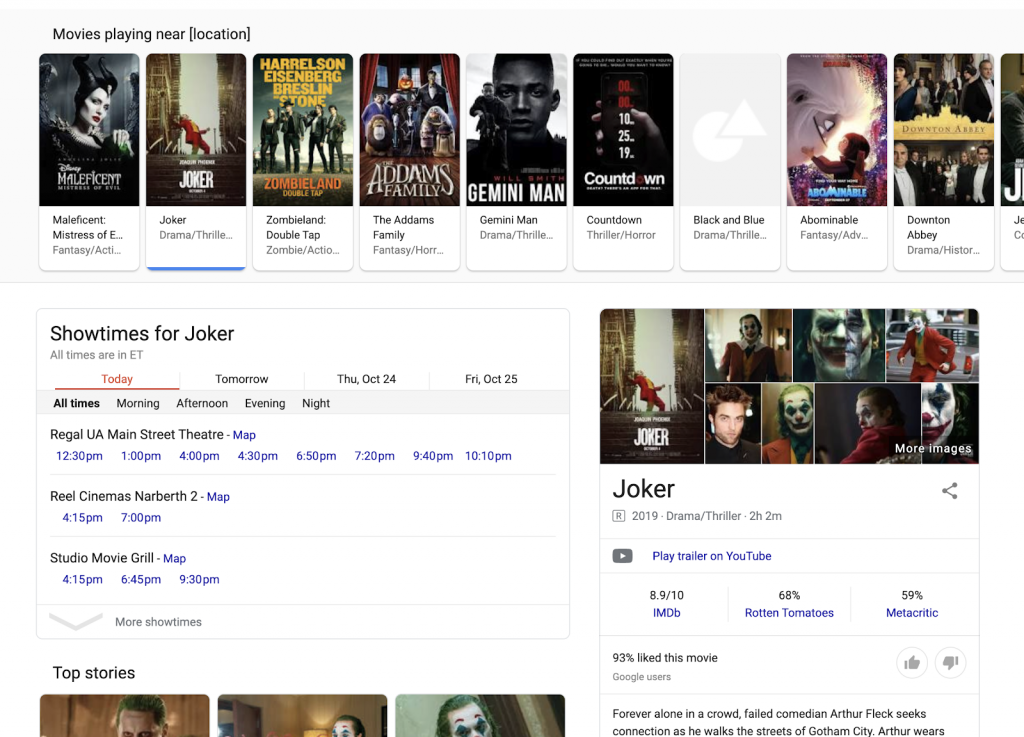
Этот тип поисковой выдачи расширяется во многих различных областях, включая путешествия.
AMP-истории
AMP-истории обеспечивают «ориентированный на историю» режим для «просмотра новостей на мобильных устройствах». Они являются примером того, как индексирование на основе сущностей улучшило способность Google извлекать контент из разных источников и смешивать его. Например, в некоторых историях, созданных Google для выступлений знаменитостей, Google соединил изображение из одного источника с текстом из другого.
Панели знаний
Панели знаний — это «информационные окна, которые появляются в Google при поиске объектов», которые являются частью сети знаний Google. Информация, отображаемая на этих панелях, взята из нескольких источников, которые Google перечисляет как:
- партнеры по данным, которые предоставляют достоверные данные по определенным темам, таким как фильмы или музыка
- открытые веб-источники
- проверенные лица, которые предложили правки фактов в своих собственных панелях знаний
- предварительный просмотр результатов Google Images для объекта
Google ранее указывал, что их сеть знаний опирается на такие источники, как Википедия/Викиданные, Всемирная книга фактов ЦРУ, структурированные данные из общедоступной сети, Google My Business и другие.
Они также могут отображать связанные объекты, позволяя пользователям поиска перемещаться по сети знаний, не покидая веб-сайт поисковой системы.
Другие функции поисковой выдачи
Другие функции SERP включают элементы прогнозирования запросов, которые пытаются ответить или перенаправить поисковую активность, не отправляя поискового пользователя на другой веб-сайт. Примеры включают безрезультатные ответы в мобильном поиске или автозаполнении, а также поля «Люди также спрашивают» (PAA).


Пример безрезультатного поиска (мобильный), который отображается как ответ непосредственно в поле автозаполнения на рабочем столе.
Управление контентом в результатах поиска
Разметка Schema.org
Имея небольшой прямой контроль над другими элементами, формирующими список результатов поиска, SEO-специалисты массово полагались на мощь расширенных фрагментов с помощью разметки Schema.org, чтобы выделить свои списки в поисковой выдаче.
Тем не менее, Google борется со злоупотреблением расширенной разметкой, включая звезды отзывов и разметку часто задаваемых вопросов:
Звезды Google Review в результатах поиска упали на 14% с момента обновления:
— Финансовые сайты упали на 46%
— Сайты недвижимости упали на 46%
— Сайты Law & Government упали на 28%Новые данные от @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
— Сайрус (@CyrusShepard) 24 сентября 2019 г.
Чтобы поисковая выдача не была полна результатов #FAQ, #Google, кажется, установил ограничение на 3 результата FAQ #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— Эй Джей Гергич (@SEO) 8 октября 2019 г.
Явные указания на то, какой контент нельзя использовать
На этой неделе Google внедряет теги управления сниппетами, которые можно использовать, чтобы указать Google на несколько ограничений на то, что можно использовать для создания сниппета в поисковой выдаче.
Новые теги управления имеют два основных ограничения:
- Они не применяются к структурированным данным (разметка Schema.org) на странице . Структурированные данные Schema.org, поддерживаемые Google, всегда подходят для отображения в результатах поиска.
- Они могут препятствовать использованию вашей страницы в определенных «специальных функциях» в поисковой выдаче, включая избранные фрагменты , если они не соответствуют минимальной длине, требуемой функцией SERP. Поскольку длина зависит от языка, Google не публикует минимальную длину избранных фрагментов. Кроме того, «те, кто не хочет, чтобы контент отображался в виде избранных фрагментов, могут поэкспериментировать с меньшими максимальными длинами фрагментов».
У владельцев веб-сайтов есть два варианта реализации этих тегов:
1. Метатеги роботов
Начиная с конца октября во всем мире эти метатеги robots можно добавлять на страницу <head> или в HTTP-заголовок x-robots.
- <meta name="robots" content=" nosnippet "> — не показывать текст сниппета для этой страницы. Миниатюру изображения все еще можно использовать.
- <meta name="robots" content=" max-snippet: 50″> — установите максимальную длину сниппета в количестве символов. Фрагмент длины «0» эквивалентен «nosnippet»; длина фрагмента «-1» интерпретируется как означающая, что длина фрагмента не ограничена.
- <meta name="robots" content=" max-video-preview: 3″> — установите максимальную длину в секундах для предварительного просмотра видео. Длина видео «0» предотвратит показ превью видео; длина видео «-1» интерпретируется как отсутствие ограничений на длину предварительного просмотра видео.
- <meta name="robots" content=" max-image-preview: standard"> — установить максимальный размер изображения для изображений с этой страницы. Возможные варианты: «нет», «стандартный» или «большой».
Вы можете использовать более одного оператора управления сниппетами в одном и том же метатеге robots. Разделите каждый оператор запятой.
2. HTML-атрибут data-nosnippet
В конце 2019 года Google распознает новый HTML-атрибут: data-nosnippet . Его можно применять к тегам <span>, <div> или <selection>.
Атрибут data-nosnippet предотвращает отображение текста внутри тега, к которому он применяется, во фрагменте страницы.
Явное разрешение на повторное использование контента для европейской прессы во Франции
Ремикширование и повторная публикация новостного контента Google уже выходит за рамки закона об авторском праве в некоторых странах. Франция недавно была в центре внимания:
Из-за изменений в законодательстве об авторском праве во Франции Google Поиск не будет отображать текстовые фрагменты или миниатюры изображений для затронутых публикаций европейской прессы во Франции, если только на веб-сайте не реализованы метатеги, позволяющие выполнять предварительный просмотр в результатах поиска. (Источник)
Другими словами, Google исключит из результатов поиска во Франции любое европейское издание, которое прямо не разрешает ему повторно публиковать и, в конечном итоге, ремикшировать контент.
По иронии судьбы, способ предоставления разрешения не совсем ясен: единственный явно разрешающий метатег robots — «все», который «является значением по умолчанию и не имеет никакого эффекта, если явно указан», за исключением, теперь, во французской поисковой выдаче.
В противном случае издатели могут указать отсутствие ограничений на длину превью текста и видео с помощью соглашения, не включенного в объявление об управлении фрагментами, или они могут наложить произвольные ограничения, чтобы показать, что они не хотят запрещать превью поиска. .
Хождение по канату
Каждому веб-сайту необходимо будет найти правильный баланс между защитой своего контента и формированием своего присутствия в поисковой выдаче Google.
Поскольку Google все больше ведет себя как издатель контента, мы можем ожидать больше функций SERP с минимальной атрибуцией, а также больше стран, где закон об авторском праве, предназначенный для защиты владельцев и создателей контента, влияет на то, что Google может и не может отображать.
Что я действительно считаю интересным, так это последствия авторского права… Люди жалуются на то, что G берет контент без разрешения — теги фрагментов будут молчаливым разрешением. Пройдет ли много времени, прежде чем они потребуются?
— Дженни Халас (@jennyhalasz) 15 октября 2019 г.
К счастью, новые инструменты управления сниппетами предоставляют владельцам веб-сайтов набор инструментов для определения того, какие части — и сколько — их контента могут быть повторно использованы Google в поисковой выдаче.
На данный момент я считаю, что будет разумно реализовать соответствующие теги управления фрагментами на веб-сайтах с существенным оригинальным содержанием, хотя я беспокоюсь, что теги, которые носят только ограничительный характер, не будут полезны для всех веб-сайтов. Несмотря на это предостережение, все еще есть способы использовать их для оптимизации работы с поисковой выдачей и увеличения трафика.
Я думаю, люди примут новые теги. Я думаю, что есть несколько возможностей «сформировать» фрагмент с помощью этих тегов, чтобы обеспечить лучший опыт, чем то, что Google извлекает автоматически, и оптимизировать CTR.
— Кевин_Индиг (@Kevin_Indig) 16 октября 2019 г.
Я с нетерпением жду экспериментов в разных вертикалях, чтобы найти то, что работает лучше всего.