
Нейронная сеть с одним нейроном на Python — с математической интуицией
Опубликовано: 2021-06-21Давайте построим простую сеть — очень-очень простую, но полноценную сеть — с одним слоем. Только один вход — и один нейрон (он же и выход), один вес, одно смещение.
Давайте сначала запустим код, а затем проанализируем его по частям.
Клонируйте проект Github или просто запустите следующий код в своей любимой среде IDE.
Если вам нужна помощь в настройке IDE, я описал процесс здесь.
Если все пойдет хорошо, вы получите этот вывод:
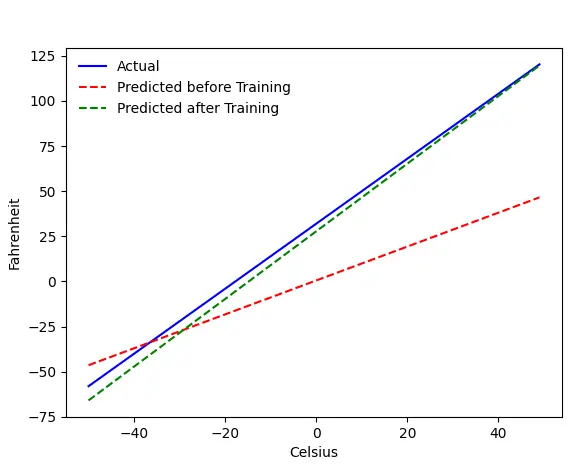
Проблема — Фаренгейты из Цельсия
Мы обучим нашу машину предсказывать градусы Фаренгейта по Цельсию. Как вы можете понять из кода (или графика), синяя линия — это реальное соотношение градусов Цельсия и Фаренгейта. Красная линия — это соотношение, предсказанное нашей детской машиной без какого-либо обучения. Наконец, мы обучаем машину, и зеленая линия — это прогноз после обучения.
Посмотрите на строку № 65–67 — до и после обучения она делает прогноз с использованием одной и той же функции ( get_predicted_fahrenheit_values() ). Так что же делает magic train()? Давай выясним.
Структура сети
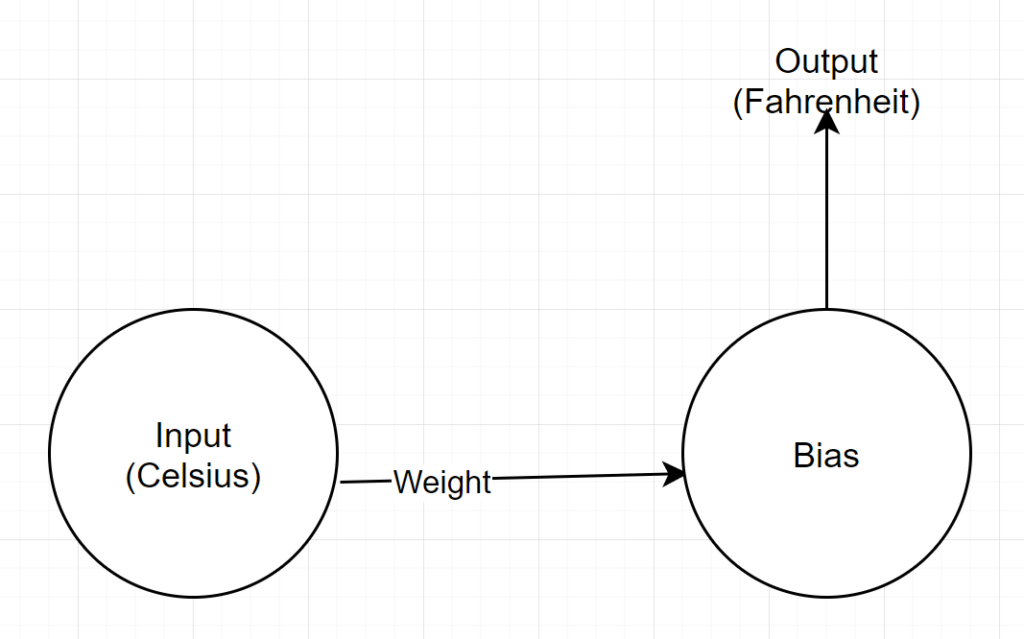
Вход: число, представляющее цельсий.
Вес: число с плавающей запятой, представляющее вес
Смещение: число с плавающей запятой, представляющее смещение
Выход: число с плавающей запятой, представляющее предсказанный Фаренгейт.
Итак, у нас всего 2 параметра — 1 вес и 1 смещение.
Анализ кода
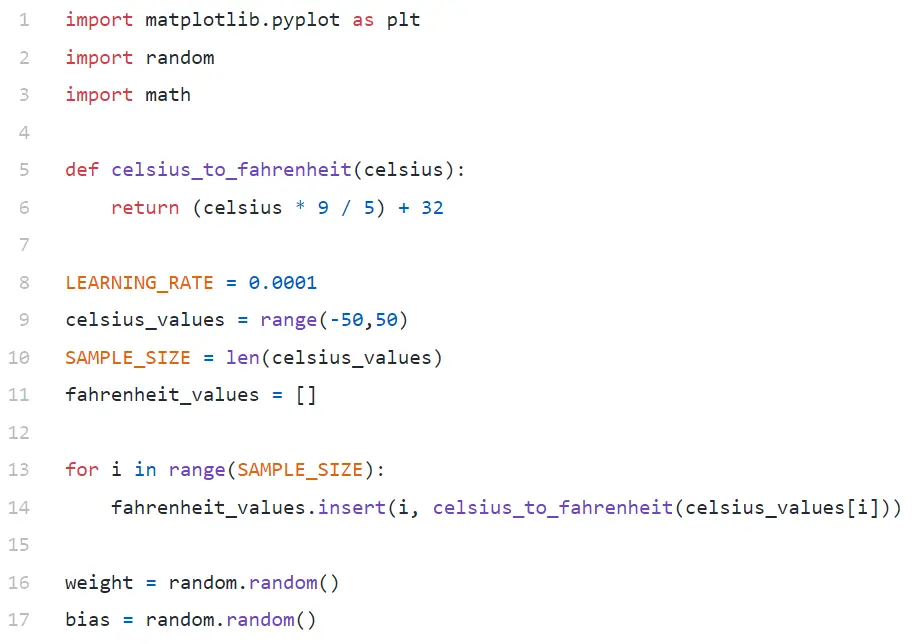
В строке № 9 мы генерируем массив из 100 чисел в диапазоне от -50 до +50 (исключая 50 — функция диапазона исключает значение верхнего предела).
В строке № 11–14 мы генерируем градусы Фаренгейта для каждого значения по Цельсию.
В строках № 16 и № 17 мы инициализируем вес и смещение.
тренироваться()

Мы проводим здесь 10000 итераций обучения. Каждая итерация состоит из:
- пас вперед (строка № 57)
- проход назад (строка № 58)
- update_parameters (строка № 59)
Если вы новичок в python, это может показаться вам немного странным — функции python могут возвращать несколько значений в виде кортежа .
Обратите внимание, что update_parameters — это единственное, что нас интересует. Все остальное, что мы здесь делаем, — это оценка параметров этой функции, которые являются градиентами (ниже мы объясним, что такое градиенты) нашего веса и смещения.
- grad_weight: число с плавающей запятой, представляющее градиент веса
- grad_bias: число с плавающей запятой, представляющее градиент смещения
Мы получаем эти значения путем обратного вызова, но для этого требуется вывод, который мы получаем, вызывая прямой вызов в строке № 57.
вперед()

Обратите внимание, что здесь celsius_values и fahrenheit_values — это массивы из 100 строк:
После выполнения строки № 20–23 для значения по Цельсию, скажем, 42.
выход = 42 * вес + смещение
Таким образом, для 100 элементов в celsius_values вывод будет массивом из 100 элементов для каждого соответствующего значения Цельсия.
Строка № 25–30 вычисляет потери с использованием функции потерь среднеквадратичной ошибки (MSE), которая представляет собой просто причудливое название квадрата всех разностей, деленного на количество выборок (в данном случае 100).
Небольшие потери означают лучшее предсказание. Если вы сохраните потери при печати на каждой итерации, вы увидите, что они уменьшаются по мере обучения.
Наконец, в строке № 31 мы возвращаем прогнозируемый выход и потери.
назад

Нас интересует только обновление нашего веса и предвзятости. Чтобы обновить эти значения, нам нужно знать их градиенты, и это то, что мы здесь вычисляем.
Градиенты уведомлений рассчитываются в обратном порядке. Сначала вычисляется градиент вывода, а затем вес и смещение, отсюда и название «обратное распространение». Причина в том, что для расчета градиента веса и смещения нам нужно знать градиент выхода, чтобы мы могли использовать его в формуле цепного правила .
Теперь давайте посмотрим, что такое градиент и цепное правило.
Градиент
Для простоты предположим, что у нас есть только одно значение celsius_values и fahrenheit_values , 42 и 107,6 соответственно.
Теперь разбивка расчета в строке № 30 выглядит следующим образом:
потеря = (107,6 — (42 * вес + смещение))² / 1
Как видите, лосс зависит от 2-х параметров — веса и смещения. Учитывайте вес. Представьте, мы инициализировали его случайным значением, скажем, 0,8, и после вычисления уравнения выше мы получаем 123,45 в качестве значения потерь . Основываясь на этом значении потери, вы должны решить, как вы будете обновлять вес. Вы должны сделать это 0,9 или 0,7?
Вы должны обновить вес таким образом, чтобы в следующей итерации вы получили меньшее значение потерь (помните, что конечной целью является минимизация потерь). Итак, если увеличение веса увеличивает потерю, мы ее уменьшим. И если увеличение веса уменьшает потерю, мы ее увеличим.
Теперь вопрос, как мы узнаем, увеличится или уменьшится потеря при увеличении веса. Здесь в дело вступает градиент . Вообще говоря, градиент определяется производной. Помните из своего школьного исчисления, что ∂y/∂x (частная производная/градиент y по отношению к x) показывает, как изменится y при небольшом изменении x.
Если ∂y/∂x положителен, это означает, что небольшое увеличение x увеличит y.
Если ∂y/∂x отрицательно, это означает, что небольшое увеличение x приведет к уменьшению y.

Если ∂y/∂x большое, небольшое изменение x вызовет большое изменение y.
Если ∂y/∂x мало, небольшое изменение x вызовет небольшое изменение y.
Итак, из градиентов мы получаем 2 информации. В каком направлении должен обновляться параметр (увеличиваться или уменьшаться) и насколько (больше или меньше).
Правило цепи
Неформально говоря, цепное правило гласит:
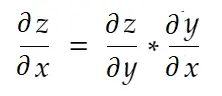
Рассмотрим пример веса выше. Нам нужно вычислить grad_weight , чтобы обновить этот вес, который будет рассчитан:
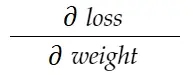
С помощью формулы цепного правила мы можем вывести ее:
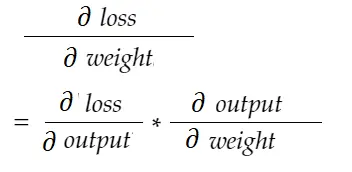
Точно так же градиент для смещения:
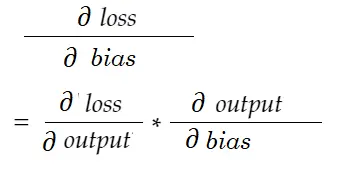
Нарисуем диаграмму зависимости.
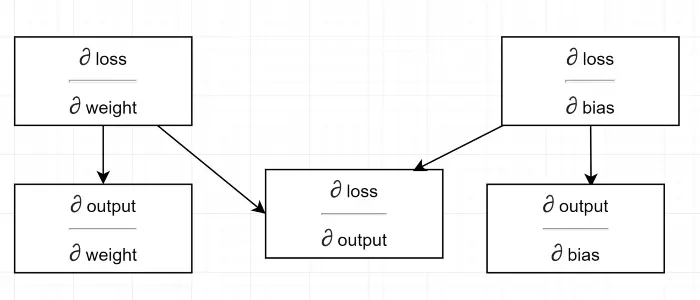
См. все расчеты, зависящие от градиента выхода (∂ потерь/∂ выхода) . Поэтому мы сначала вычисляем его на обратном проходе (строки №34–36).
На самом деле, в высокоуровневых ML-фреймворках, например в PyTorch, не нужно писать коды для обратного прохода! Во время прямого прохода он создает вычислительные графы, а во время обратного прохода он проходит противоположное направление в графе и вычисляет градиенты, используя цепное правило.
∂ потери / ∂ выход
Мы определяем эту переменную с помощью grad_output в коде, который мы вычислили в строках № 34–36. Давайте выясним причину формулы, которую мы использовали в коде.
Помните, что мы загружаем все 100 значений celsius_values в машину вместе. Таким образом, grad_output будет массивом из 100 элементов, каждый из которых содержит градиент вывода для соответствующего элемента в celsius_values . Для простоты давайте рассмотрим, что в celsius_values всего 2 элемента.
Итак, разбивая строку № 30,
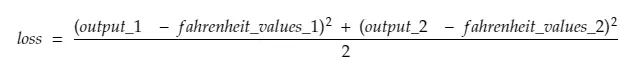
куда,
output_1 = выходное значение для 1-го значения по Цельсию
output_2 = выходное значение для 2-го значения по Цельсию
fahreinheit_values_1 = Фактическое значение по Фаренгейту для 1-го значения по Цельсию
fahreinheit_values_1 = Фактическое значение по Фаренгейту для 2-го значения по Цельсию
Теперь результирующая переменная grad_output будет содержать 2 значения — градиент output_1 и output_2, что означает:
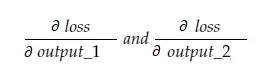
Давайте рассчитаем градиент только для output_1, а затем мы можем применить то же правило для остальных.
Время расчета!

То же, что и строка № 34–36.
Градиент веса
Представьте, у нас есть только один элемент в celsius_values. Теперь:

То же, что и строка № 38–40. Для 100 celsius_values значения градиента для каждого из значений будут суммироваться. Очевидный вопрос: почему мы не уменьшаем результат (т.е. не делим на SAMPLE_SIZE). Так как перед обновлением параметров мы умножаем все градиенты с малым коэффициентом, в этом нет необходимости (см. последний раздел Обновление параметров).
Градиент смещения

То же, что и строка № 42. Как и градиенты веса, эти значения для каждого из 100 входных данных суммируются. Опять же, это нормально, так как градиенты умножаются с небольшим коэффициентом перед обновлением параметров.
Обновление параметров

Наконец, мы обновляем параметры. Обратите внимание, что градиенты умножаются на небольшой коэффициент (LEARNING_RATE) перед вычитанием, чтобы сделать обучение стабильным. Большое значение LEARNING_RATE вызовет проблему перерегулирования , а очень маленькое значение замедлит обучение, что может потребовать гораздо большего количества итераций. Мы должны найти оптимальное значение для него методом проб и ошибок. На нем есть много онлайн-ресурсов, включая этот, чтобы узнать больше об обучении Rate.
Обратите внимание, что точная величина, которую мы корректируем, не является чрезвычайно важной. Например, если вы немного настроите LEARNING_RATE, переменные descent_grad_weight и descent_grad_bias (строки № 49–50) будут изменены, но машина может по-прежнему работать. Важно убедиться, что эти суммы получены путем уменьшения градиентов с тем же коэффициентом (в данном случае LEARNING_RATE). Другими словами, «сохранение пропорционального снижения градиентов» имеет большее значение, чем «насколько они снижаются ».
Также обратите внимание, что эти значения градиента на самом деле представляют собой сумму градиентов, оцененных для каждого из 100 входных данных. Но поскольку они масштабируются с одинаковым значением, все в порядке, как указано выше.
Чтобы обновить параметры, мы должны объявить их с помощью глобального ключевого слова (в строке № 47).
Куда пойти отсюда
Код был бы намного меньше, если бы циклы for были заменены пониманием списка в pythonic. Взгляните на это сейчас — это займет не более нескольких минут, чтобы понять.
Если вы до сих пор все поняли, возможно, самое время увидеть внутренности простой сети с несколькими нейронами/слоями — вот статья.