
Почему мы перешли на бессерверные вычисления для развертывания пользовательских сборок
Опубликовано: 2018-11-22
Фото автора panumas nikhomkhai: Pexels
В рамках нашего стремления предоставить маркетологам возможностей делать больше, с меньшими затратами и без забот , команды TUNE всегда ищут новые способы обслуживания наших клиентов. В этом случае наша команда по разработке решений обнаружила технологию, которая упрощает развертывание и поддержку пользовательских сборок на нашей платформе. В результате теперь они могут тратить больше времени (и меньше денег) на работу с большим количеством клиентов для создания необходимых им решений.
В TUNE мы гордимся тем, что предоставляем гибкую, комплексную платформу для маркетинга производительности, которая позволяет сетям и рекламодателям управлять своими кампаниями цифрового маркетинга, отношениями с издателями, выплатами и многим другим — прямо из коробки, без необходимости писать ни одной строки кода. . Но иногда, как и в случае с другими полностью управляемыми системами SaaS, нашим клиентам требуются индивидуальные конфигурации, функциональные возможности или интеграции, которых можно достичь, только засучив рукава и запустив старый редактор кода. Недавно мы перешли на новую технологию, которая меняет способ создания этих решений: бессерверные вычисления.
В этом посте я расскажу о проблемах, с которыми мы столкнулись при индивидуальной разработке, о шагах, которые мы предприняли для настройки процесса бессерверной сборки, и о том, как эта новая методология решает проблемы стоимости и масштаба.
Задача: удовлетворить спрос на индивидуальные решения
Когда мы впервые создали команду разработки решений в TUNE, мы рассматривали каждую пользовательскую сборку как отдельную сборку. В большинстве этих сборок был интерфейсный компонент, который обычно развертывался как настраиваемая страница на нашей платформе, и внутренний компонент, состоящий из сервера, базы данных и любой другой инфраструктуры, необходимой для поддержания серверов в актуальном состоянии. -Дата и оперативность.
Сначала эта методика у нас работала. Имея небольшую, скудную команду с несколькими сложными пользовательскими сборками, наш метод подготовки и настройки отдельного сервера для каждой сборки работал на нас. Это позволило нам создавать удивительные впечатления для наших клиентов.
Но по мере роста количества сборок мы начали сталкиваться с проблемами:
- Слишком много серверов! Как вы можете себе представить, установка как минимум двух блоков на сборку привела к тому, что у нас стало слишком много серверов. Огромное количество серверов и все сопутствующие им хлопоты (такие как обновления безопасности и резервное копирование) стоили нам больше времени, чем мы хотели бы признать.
- Поддерживайте эти серверы. Поскольку каждый сервер был отдельным объектом, мы отвечали за то, чтобы каждый сервер всегда был включен и работал.
- PHP не для меня. Большинство наших сборок созданы из базового образа Docker PHP. Но по мере того, как наша команда росла, мы знали, что заставлять людей писать свои клиентские сборки на PHP 5.0, когда они были мастерами Python, не имело никакого смысла.
- Это становится дорого. Поскольку все наши серверы были развернуты на ec2/RDS, мы начали сталкиваться со значительными ежемесячными затратами.
- Безопасность прежде всего. Поскольку эти службы обрабатывали конфиденциальные данные клиентов, нам пришлось предоставить метод аутентификации для наших общедоступных URL-адресов, чтобы обеспечить безопасность этих данных.
- Кроны жесткие. Многие серверные службы состояли из cron-скриптов, и у нас не было эффективного способа ими управлять.
С появлением этих проблем мы поняли, что должны найти более простой и экономичный способ предоставления серверной функциональности сборкам наших клиентов. Но после долгих дебатов и отсутствия явного фаворита решения у нас начали заканчиваться идеи. (Кроме того, спрос на новые пользовательские сборки рос как сумасшедший, и время определенно было не на нашей стороне.)
Решение: бессерверные вычисления спешат на помощь
Если вы не слышали о бессерверных вычислениях , вам может быть интересно то же, что и нам, когда мы впервые услышали об этом. Как вы можете выполнять код без сервера? (Не волнуйтесь, ваше фундаментальное понимание программирования по-прежнему правильное, и нет, мы не злоупотребляли специальным предложением «счастливый час», прежде чем писать это.)
«Бессерверный» — действительно сбивающий с толку термин для новой технологии, потому что — не будем глупить — определенно все еще существует сервер, выполняющий код. Так что же такое бессерверное?
Бессерверные вычисления — это модель выполнения облачных вычислений , в которой облачный провайдер выступает в роли сервера, динамически управляя распределением машинных ресурсов. - Википедия
Бессерверные облачные решения позволяют создавать и запускать приложения и службы, не задумываясь о проблемах, связанных с серверами. По сути, бессерверные вычисления позволяют вам делать то, что у вас получается лучше всего: писать код.
Процесс бессерверной установки
Чтобы показать вам суть работы бессерверной технологии, я расскажу о шагах, которые мы использовали для настройки этой функции.
Примечание. Существует множество облачных провайдеров с бессерверной функциональностью. В этом примере мы используем AWS Lambda .

- Сначала создайте новую функцию Lambda и выберите « Blueprints ». Затем введите « http » в поле ключевого слова и выберите Python или Node microservice-http-endpoint. (Чертежи — это предварительно созданные блоки кода, предназначенные для ускорения разработки. Как это здорово?) Сделав выбор, нажмите « Настроить ».
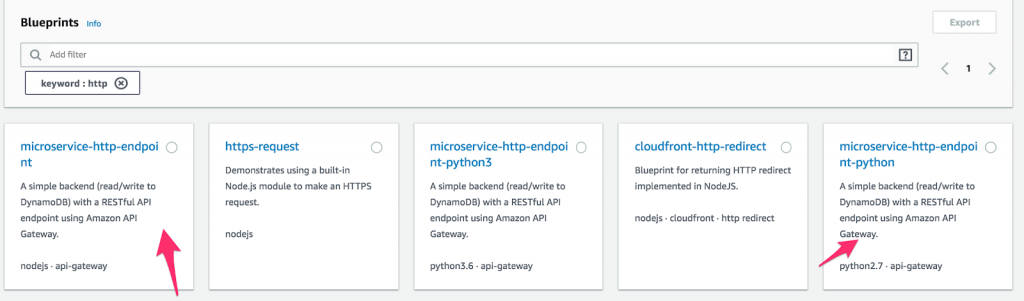
Как настроить функцию на AWS Lambda.
- Добавьте имя функции и роль. Затем выберите триггер шлюза API с параметром безопасности « Открыть с помощью ключа API ». Этот шлюз API предоставит общедоступный URL-адрес, который активирует вашу функцию Lambda. Добавление ключа API обеспечивает метод аутентификации, который настоятельно рекомендуется.
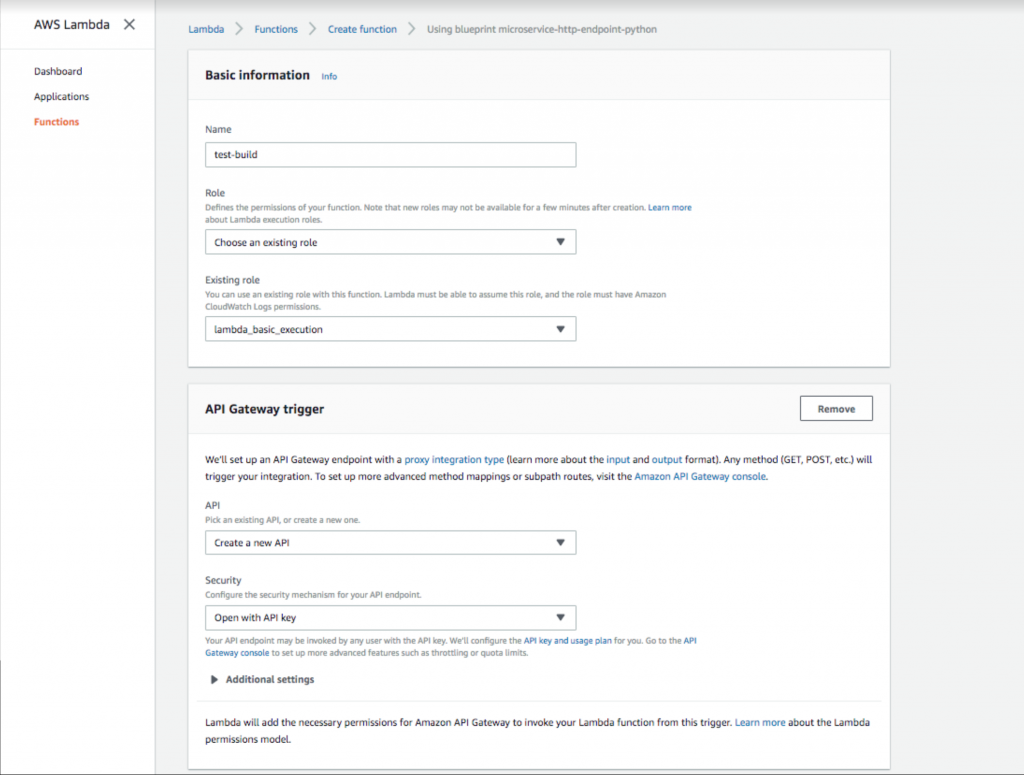
Настройка открытого ключа шлюза API в AWS Lambda.
- После того, как вы создадите функцию, вы можете настроить свой код. Как видите, схема уже предоставила вам классную точку входа, позволяющую взаимодействовать с таблицей Dynamo (если вы хотите добавить базу данных). Все, что находится под lambda_handler , будет выполнено при загрузке общедоступного URL-адреса. Поскольку мы также добавляем базу данных, давайте перейдем к Dynamo и создадим ее.
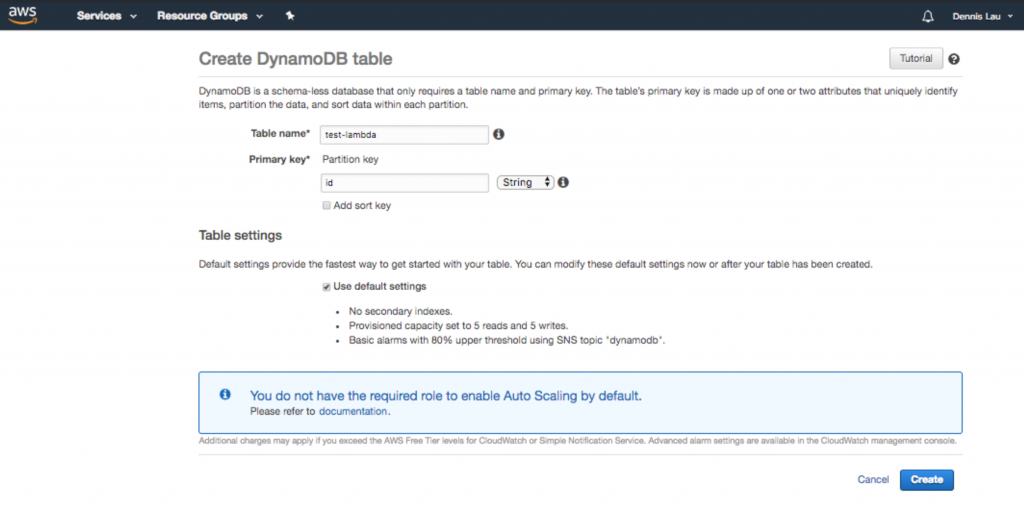
Создание таблицы базы данных Dynamo в AWS Lambda.
- После создания таблицы Dynamo давайте вызовем эту лямбда-функцию из общедоступного URL-адреса. Вернитесь к своей функции и щелкните значок « API Gateway » вверху. Вы должны увидеть, что конечная точка и ключ API уже созданы для вас.
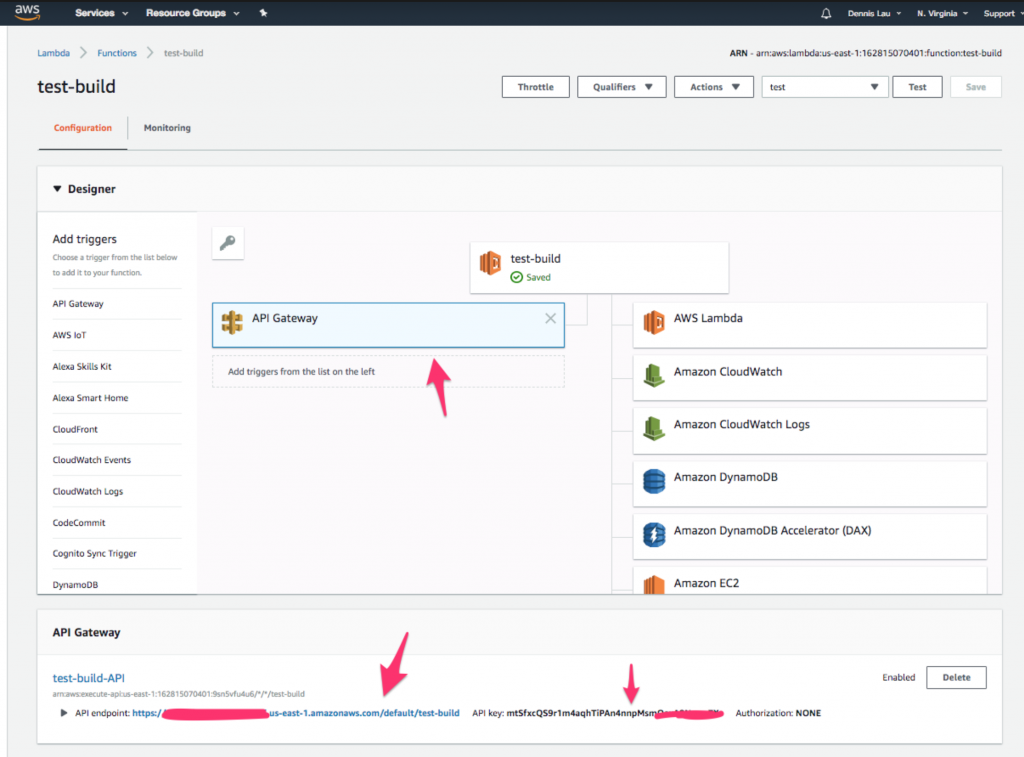
Где найти значок шлюза API в функциях AWS Lambda.
- Теперь откройте терминал и добавьте ключ API под заголовком « x-api-key» , затем добавьте имя таблицы, созданное вами, в параметре строки запроса TableName .

Введите свой ключ и имя базы данных в терминал, чтобы закончить.
- Сначала создайте новую функцию Lambda и выберите « Blueprints ». Затем введите « http » в поле ключевого слова и выберите Python или Node microservice-http-endpoint. (Чертежи — это предварительно созданные блоки кода, предназначенные для ускорения разработки. Как это здорово?) Сделав выбор, нажмите « Настроить ».
Вот и все! Теперь у вас есть работающая, защищенная серверная часть, подключенная к базе данных. Все, что для этого потребовалось, — это пять простых шагов.
Как бессерверные вычисления решили наши проблемы
Теперь, когда мы показали вам, как настраивать бессерверные сборки, давайте посмотрим, как эта облачная модель справляется с нашим контрольным списком проблем.
- Слишком много серверов! Без сервера… то есть без серверов, верно?
- Поддерживайте эти серверы. Поскольку бессерверные вычисления управляются облачным провайдером, вы получаете преимущество от этих провайдеров (вместе с их закаленными в боях и проверенными методами) для мониторинга ваших серверов. Для тех из вас, кто хочет поиграть в Шерлока Холмса, вы также можете увидеть все журналы сервера, выводимые вашей функцией, в Cloudwatch .
- PHP не для меня. Бессерверные модели позволяют писать на C#, Python, NodeJS, Go и даже на Java.
- Это становится дорого. В бессерверных решениях затраты измеряются на основе времени выполнения (за 100 миллисекунд) и объема переданных данных. В отличие от помесячной оплаты, которая включает в себя время простоя ваших серверов, вы платите только за то, что используете. При стоимости всего 0,000000208 долларов США за 100 мс выполнения бессерверные вычисления могут сэкономить вам значительную часть денег.
- Безопасность прежде всего. Безопасен ли бессерверный доступ? Со встроенной системой аутентификации по ключу API вы можете поспорить.
- Кроны жесткие. Благодаря системе управления cron, встроенной в Cloudwatch, просто установите временное окно и забудьте об этом. Cloudwatch обрабатывает все журналы и выполнение.
Последние мысли
Для команды разработчиков решений здесь, в TUNE, переход на бессерверные вычисления изменил правила игры. Его простота использования, экономия средств и адаптивные функции изменили то, как мы работаем со всеми новыми клиентскими сборками. Бессерверные облачные решения призваны изменить мир серверных вычислений. Не знаю, как вы, но одно можно сказать точно: инженерная команда TUNE Solutions готова.
Чтобы узнать больше о платформе TUNE и услугах по индивидуальной разработке, которые мы предоставляем, посетите нашу страницу профессиональных услуг .