
7 SEO-провалов, встречающихся в дикой природе (и как их избежать)
Опубликовано: 2022-06-12
Мы часто получаем вопросы от людей, интересующихся, почему их сайт не ранжируется или почему его не индексируют поисковые системы.
В последнее время я наткнулся на несколько сайтов с серьезными ошибками, которые можно было бы легко исправить, если бы владельцы знали, что нужно искать. Хотя некоторые SEO-ошибки довольно сложны, вот несколько часто упускаемых из виду ошибок «удара головой».
Так что проверьте эти ошибки SEO — и как вы можете избежать их самостоятельно.
SEO-ошибка №1: проблемы с robots.txt
Файл robots.txt обладает огромной силой. Он указывает ботам поисковых систем, что следует исключать из их индексов.
В прошлом я видел, как сайты забывали удалить одну-единственную строку кода из этого файла после редизайна сайта и опускали весь свой сайт в результатах поиска.
Поэтому, когда цветочный сайт выявил проблему, я начал с одной из первых проверок, которые я всегда делаю на сайте — просмотр файла robots.txt.
Я хотел знать, блокирует ли файл robots.txt сайта поисковые системы от индексации их контента. Но вместо ожидаемого текстового файла я увидел страницу с предложением доставить цветы в Robots.Txt.
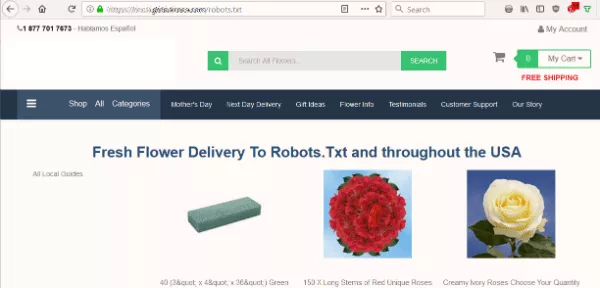
На сайте не было файла robots.txt, который бот ищет в первую очередь при сканировании сайта. Это была их первая ошибка. Но взять этот файл в качестве пункта назначения… серьезно?
SEO-ошибка № 2: автоматическая генерация вышла из-под контроля
Во-вторых, сайт автоматически генерировал бессмысленный контент. Вероятно, он доставил бы Санта-Клаусу или любому другому тексту, который я поместил в URL-адрес.
Я запустил инструмент Check Server Page, чтобы увидеть, какой статус показывает автоматически сгенерированная страница. Если бы это была ошибка 404 (не найдено), то боты проигнорировали бы страницу, как им и положено. Однако заголовок сервера страницы дал статус 200 (ОК). В результате поддельные страницы давали поисковым системам зеленый свет на индексацию.
Поисковые системы хотят видеть уникальный и содержательный контент на странице. Таким образом, индексация этих не-страниц может повредить их SEO.
Ошибка SEO № 3: канонические ошибки
Затем я проверил, что думают об этом сайте поисковые системы. Могут ли они сканировать и индексировать страницы?
Просматривая исходный код различных страниц, я заметил еще одну серьезную ошибку.
На каждой отдельной странице был элемент канонической ссылки, указывающий на домашнюю страницу:
<link rel="canonical" href="https://www.domain.com/" />
Другими словами, поисковым системам сообщали, что каждая страница на самом деле является копией главной страницы. Основываясь на этом теге, боты должны игнорировать остальные страницы этого домена.
К счастью, Google достаточно умен, чтобы выяснить, когда эти теги, вероятно, используются по ошибке. Так что он все еще индексировал некоторые страницы сайта. Но этот универсальный канонический запрос не помогал SEO сайта.
Как избежать этих ошибок SEO
Вот исправления многочисленных ошибок цветочного сайта:
- Имейте действительный файл robots.txt, чтобы сообщить поисковым системам, как сканировать и индексировать сайт. Даже если это пустой файл, он должен существовать в корне вашего домена.
- Создайте правильный элемент канонической ссылки для каждой страницы. И не уводите пальцем от страницы, которую хотите проиндексировать.
- Отображение пользовательской страницы 404, когда URL-адрес страницы не существует. Убедитесь, что он возвращает код сервера 404, чтобы дать поисковым системам четкое сообщение.
- Будьте осторожны с автоматически сгенерированными страницами. Избегайте создания бессмысленных или дублирующих страниц для поисковых систем и пользователей.
Даже если у вас нет проблем с сайтом, рекомендуется периодически просматривать эти моменты, просто на всякий случай.
О, и никогда не ставьте канонический тег на свою страницу 404 , особенно указывающий на вашу домашнюю страницу… просто не делайте этого.
SEO-провал № 4: быстрое падение позиций в рейтинге
Иногда простое изменение может дорого обойтись. Эта история основана на опыте работы с одним из наших SEO-клиентов.
Когда расширение .org их доменного имени стало доступным, они подхватили его. Все идет нормально. Но следующий их шаг привел к катастрофе.
Они сразу же установили редирект 301, указывающий недавно приобретенный домен .org на их основной веб-сайт .com. Их доводы имели смысл — поймать своенравных посетителей, которые могут ввести неправильное расширение.
Но на следующий день они позвонили нам в бешенстве. Посещаемость их сайта отсутствовала. Они понятия не имели, почему.
Несколько быстрых проверок показали, что их поисковый рейтинг исчез из Google в одночасье. Чтобы понять, что произошло, не потребовалось слишком много вопросов и ответов.
Они вводят перенаправление, не задумываясь о риске. Мы немного покопались и обнаружили, что у .org было грязное прошлое.

Предыдущий владелец сайта .org использовал его для спама. С помощью редиректа Google назначал весь этот яд основному сайту компании! Нам понадобилось всего два дня, чтобы восстановить позиции сайта в Google.
Как избежать этого SEO-провала
Всегда изучайте ссылочный профиль и историю любого доменного имени, под которым вы регистрируетесь.
Это может сделать квалифицированный SEO-консультант. Есть также инструменты, которые вы можете запустить, чтобы увидеть, какие скелеты могут лежать в шкафу сайта.
Всякий раз, когда я беру новый домен, я предпочитаю оставить его бездействующим на срок от шести месяцев до года, по крайней мере, прежде чем пытаться что-то с ним сделать. Я хочу, чтобы поисковые системы четко отличали новое воплощение моего сайта от его прошлой жизни. Это дополнительная мера предосторожности для защиты ваших инвестиций.
SEO-ошибка № 5: страницы, которые не исчезают
Иногда у сайтов может быть другая проблема — слишком много страниц в поисковом индексе.
Поисковые системы иногда сохраняют страницы, которые больше не действительны. Если люди попадают на страницы с ошибками, когда они приходят из результатов поиска, это плохой пользовательский опыт.
Некоторые владельцы сайтов, разочаровавшись, перечисляют отдельные URL-адреса в файле robots.txt. Они надеются, что Google поймет намек и перестанет их индексировать.
Но этот подход не работает! Если Google соблюдает robots.txt, он не будет сканировать эти страницы. Таким образом, Google никогда не увидит статус 404 и не узнает, что страницы недействительны.
Как избежать этой SEO-ошибки
Первая часть исправления заключается в том, чтобы не запрещать эти URL-адреса в файле robots.txt. Вы ХОТИТЕ, чтобы боты сканировали и знали, какие URL-адреса следует исключить из поискового индекса.
После этого настройте редирект 301 на старый URL. Направьте посетителя (и поисковые системы) на ближайшую замещающую страницу на сайте. Это заботится о ваших посетителях, приходят ли они из поиска или по прямой ссылке.
SEO-ошибка № 6: недостающие ссылки
Я перешел по ссылке с веб-сайта университета и получил ошибку 404 (не найдено).
Это не редкость, за исключением того, что ссылка была на /home.html — прежний URL домашней страницы сайта.
В какой-то момент они, должно быть, изменили архитектуру своего веб-сайта и удалили старый /home.html, потеряв перенаправление в случайном порядке.
По иронии судьбы, их страница 404 говорит, что вы можете начать сначала с главной страницы, что я и пытался достичь в первую очередь.
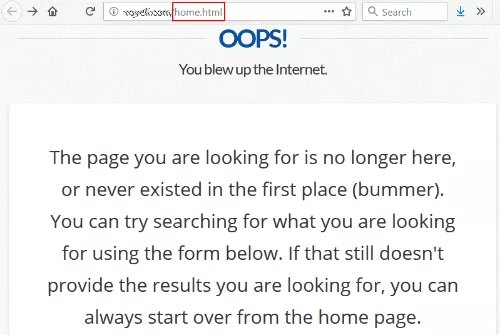
Можно с уверенностью сказать, что этому сайту хотелось бы получить хорошую ссылку от уважаемого университета на свою домашнюю страницу. И выполнение этого полностью в их власти. Им даже не нужно связываться с сайтом ссылок.
Как исправить эту ошибку
Чтобы исправить эту ссылку, им просто нужно установить переадресацию 301, указывающую /home.html на текущую домашнюю страницу. (См. нашу статью о том, как настроить перенаправление 301 для получения инструкций.)
Чтобы получить дополнительные баллы, перейдите в Google Search Console и просмотрите отчет о статусе покрытия индекса. Посмотрите на все страницы, которые, как сообщается, возвращают ошибку 404, и работайте над исправлением как можно большего количества ошибок здесь.
Ошибка SEO № 7: ошибка копирования/вставки
Запускается редизайн сайта, расставляются канонические теги и устанавливается новый Диспетчер тегов Google. Тем не менее, есть еще проблемы с ранжированием. Фактически, одна новая целевая страница не показывает посетителей в Google Analytics.
Команда разработчиков отвечает, что они сделали все по инструкции и буквально следовали примерам.
Они совершенно правы. Они следовали примерам — в том числе оставляли в примере код! После копирования и вставки разработчики забыли ввести информацию о своем целевом сайте.
Вот три примера, с которыми наши аналитики столкнулись в коде веб-сайта:
- <ссылка rel="canonical" href="http://example.com/">
- 'analyticsAccountNumber': 'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
Как избежать этого SEO-провала
Когда что-то работает неправильно, не ограничивайтесь вопросом «есть ли этот элемент в исходном коде?» Возможно, в вашем HTML-коде никогда не были указаны правильные коды подтверждения, номера счетов и URL-адреса.
Ошибки случаются, а люди всего лишь люди. Я надеюсь, что эти примеры помогут вам избежать подобных ошибок в SEO. Для вашего удобства мы создали подробное руководство по SEO, в котором изложены советы и рекомендации по SEO.
Но некоторые вопросы SEO сложнее, чем вы думаете. Если у вас есть проблемы с индексацией, мы здесь, чтобы помочь. Позвоните нам или заполните форму заявки, и мы свяжемся с вами.
Нравится этот пост? Подпишитесь на наш блог, чтобы получать новые сообщения на свой почтовый ящик.