
Семантическая кластеризация ключевых слов в Python
Опубликовано: 2021-04-19В мире, полном мифов о цифровом маркетинге, мы считаем, что практические решения повседневных проблем — это то, что нам нужно.
В PEMAVOR мы всегда делимся своим опытом и знаниями, чтобы удовлетворить потребности энтузиастов цифрового маркетинга. Поэтому мы часто публикуем бесплатные скрипты Python, чтобы помочь вам повысить рентабельность инвестиций.
Наша Кластеризация ключевых слов SEO с помощью Python проложила путь к получению новой информации для крупных SEO-проектов, используя всего менее 50 строк кода Python.
Идея этого скрипта заключалась в том, чтобы позволить вам группировать ключевые слова, не платя «преувеличенных комиссий»… ну, мы знаем, кому…
Но мы поняли, что одного этого сценария недостаточно. Нужен еще один сценарий, чтобы вы, ребята, могли лучше понять свои ключевые слова: вам нужно « группировать ключевые слова по смыслу и семантическим отношениям». ”
Теперь пришло время сделать Python для SEO еще на один шаг вперед.
Данные при сканировании³
 Учить больше
Учить большеТрадиционный способ семантической кластеризации
Как вы знаете, традиционный метод семантики заключается в построении моделей word2vec , а затем кластеризации ключевых слов с помощью Word Mover’s Distance .
Но эти модели требуют много времени и усилий для создания и обучения. Итак, мы хотели бы предложить вам более простое решение. 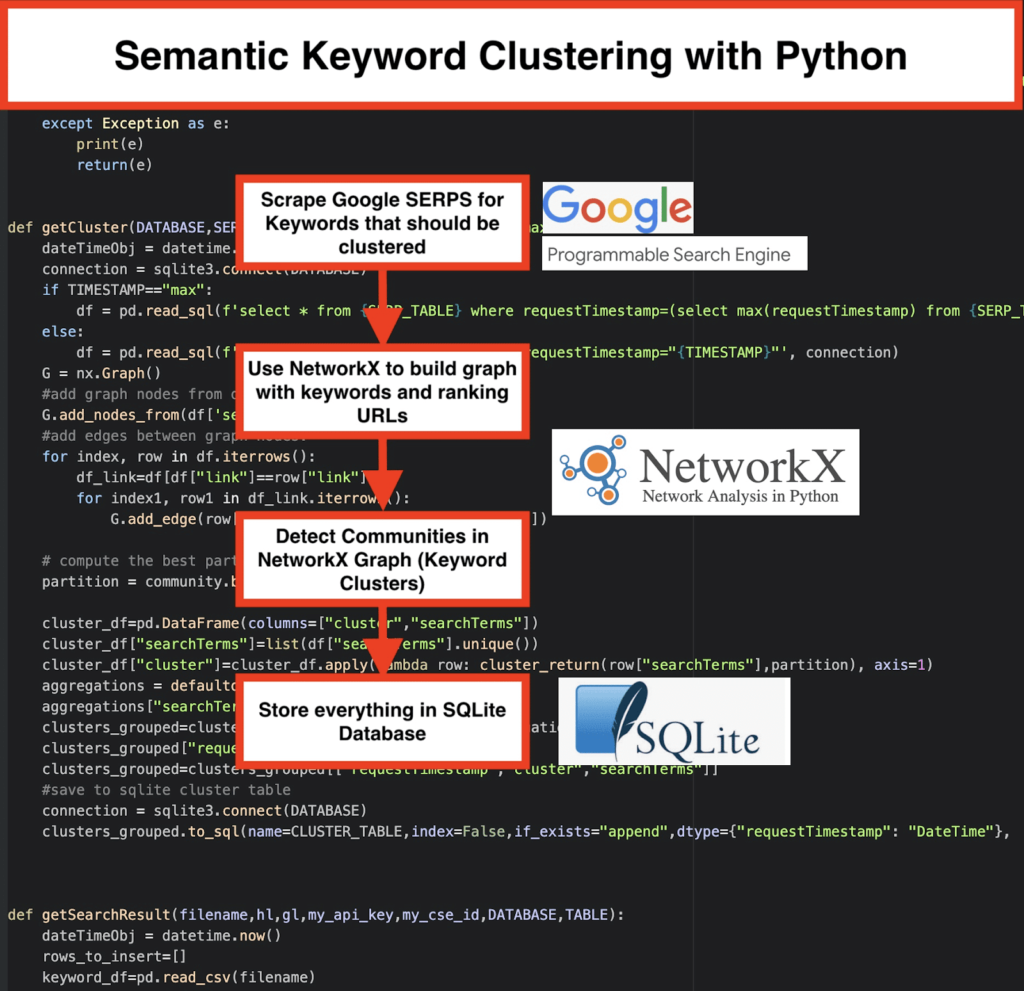
Результаты Google SERP и обнаружение семантики
Google использует модели НЛП, чтобы предлагать наилучшие результаты поиска. Это похоже на открытие ящика Пандоры, а мы этого точно не знаем.
Однако вместо того, чтобы строить наши модели, мы можем использовать это поле для группировки ключевых слов по их семантике и значению.
Вот как мы это делаем:
️ Для начала придумайте список ключевых слов по теме.
️ Затем соскребите данные поисковой выдачи по каждому ключевому слову.
️ Далее создается график с взаимосвязью между страницами ранжирования и ключевыми словами.
️ Если одни и те же страницы ранжируются по разным ключевым словам, это означает, что они связаны друг с другом. Это основной принцип создания семантических кластеров ключевых слов.
Время собрать все вместе в Python
Сценарий Python предлагает следующие функции:
- Используя систему пользовательского поиска Google, загрузите SERP для списка ключевых слов. Данные сохраняются в базу данных SQLite . Здесь вы должны настроить собственный поисковый API.
- Затем используйте бесплатную квоту в 100 запросов в день. Но они также предлагают платный план по 5 долларов за 1000 квестов, если вы не хотите ждать или если у вас большие наборы данных.
- Лучше использовать решения SQLite, если вы не спешите — результаты SERP будут добавляться в таблицу при каждом запуске. (Просто возьмите новую серию из 100 ключевых слов, когда у вас снова будет квота на следующий день.)
- Тем временем вам нужно настроить эти переменные в скрипте Python .
- CSV_FILE="keywords.csv" => сохраните здесь свои ключевые слова
- ЯЗЫК = «en»
- СТРАНА = "ru"
- API_KEY="ххххххх"
- CSE_ID="xxxxxxx"
- Запуск
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)запишет результаты поисковой выдачи в базу данных. - Кластеризация выполняется networkx и модулем обнаружения сообщества. Данные извлекаются из базы данных SQLite — кластеризация вызывается с помощью
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Результаты кластеризации можно найти в таблице SQLite — если вы ничего не меняете, имя по умолчанию — «keyword_clusters».
Ниже вы увидите полный код:
# Семантическая кластеризация ключевых слов от Pemavor.com # Автор: Стефан Нифишер ([email protected]) из сборки импорта googleapiclient.discovery импортировать панд как pd импорт Левенштейна из даты и времени импортировать дату и время из fuzzywuzzy импортировать fuzz из urllib.parse импортировать urlparse из tld импортировать get_tld импортный тяжелый импортировать json импортировать панд как pd импортировать numpy как np импортировать networkx как nx импортировать сообщество импортировать sqlite3 импортировать математику импорт io из коллекций импортировать defaultdict def cluster_return (термин поиска, раздел): вернуть раздел[searchTerm] определение языка_обнаружения (str_lan): lan=langid.classify(str_lan) вернуть лан [0] def extract_domain (url, remove_http = True): uri = анализ URL-адреса (url-адрес) если удалить_http: имя_домена = f"{uri.netloc}" еще: имя_домена = f"{uri.netloc}://{uri.netloc}" вернуть имя_домена def Extract_mainDomain (URL): res = get_tld (url, as_object = True) вернуть res.fld def fuzzy_ratio (str1,str2): вернуть fuzz.ratio (str1,str2) определение fuzzy_token_set_ratio (str1,str2): вернуть fuzz.token_set_ratio (str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): пытаться: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() вернуть разрешение кроме Исключения как e: печать (е) возврат (е) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): пытаться: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() вернуть разрешение кроме Исключения как e: печать (е) возврат (е) def getCluster (DATABASE, SERP_TABLE, CLUSTER_TABLE, TIMESTAMP = "max"): dateTimeObj = datetime.now() подключение = sqlite3.connect (база данных) если TIMESTAMP=="max": df = pd.read_sql(f'выберите * из {SERP_TABLE}, где requestTimestamp=(выберите max(requestTimestamp) из {SERP_TABLE})', подключение) еще: df = pd.read_sql(f'выберите * из {SERP_TABLE}, где requestTimestamp="{TIMESTAMP}"', соединение) G = nx.График() # добавить узлы графа из столбца фрейма данных G.add_nodes_from(df['searchTerms']) #добавляем ребра между узлами графа: для индекса, строка в df.iterrows(): df_link=df[df["ссылка"]==строка["ссылка"]] для index1, row1 в df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # вычислить лучший раздел для сообщества (кластеров) раздел = сообщество.best_partition(G) cluster_df=pd.DataFrame(столбцы=["кластер","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(лямбда-строка: cluster_return(строка["searchTerms"],раздел), ось=1) агрегаты = defaultdict() агрегации["searchTerms"]=' | '.присоединиться clusters_grouped=cluster_df.groupby("кластер").agg(агрегации).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["Временная метка запроса","кластер","условия поиска"]] # сохранить в таблицу кластеров sqlite подключение = sqlite3.connect (база данных) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult (имя файла, hl, gl, my_api_key, my_cse_id, DATABASE, TABLE): dateTimeObj = datetime.now() строки_to_insert=[] keyword_df=pd.read_csv(имя файла) ключевые слова=keyword_df.iloc[:,0].tolist() для запроса по ключевым словам: если hl=="по умолчанию": результат = google_search_default_language(запрос, my_api_key, my_cse_id,gl) еще: результат = google_search(запрос, my_api_key, my_cse_id,hl,gl) если "элементы" в результате и "запросы" в результате: для позиции в диапазоне (0, len (результат ["элементы"])): результат["элементы"][позиция]["позиция"]=позиция+1 результат["элементы"][позиция]["основной_домен"]= extract_mainDomain(результат["элементы"][позиция]["ссылка"]) результат["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],запрос) результат["элементы"][позиция]["snippet_matchScore_token"]=fuzzy_token_set_ratio(результат["элементы"][позиция]["фрагмент"],запрос) результат["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],запрос) результат["элементы"][позиция]["snippet_matchScore_order"]=fuzzy_ratio(результат["элементы"][позиция]["фрагмент"],запрос) результат["элементы"][позиция]["snipped_language"]=language_detection(результат["элементы"][позиция]["фрагмент"]) для позиции в диапазоне (0, len (результат ["элементы"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":запрос,"gl":gl,"hl":hl, "totalResults":результат["запросы"]["запрос"][0]["totalResults"],"ссылка":результат["элементы"][позиция]["ссылка"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":результат["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":результат["items"][position]["title_matchScore_order"],"title_matchScore_token":результат["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #сохраняем результаты поисковой выдачи в базе данных sqlite подключение = sqlite3.connect(база данных) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) ################################################### ################################################### ########################################### #Прочти меня: # ################################################### ################################################### ########################################### № 1. Вам необходимо настроить систему пользовательского поиска Google. # # Укажите ключ API и SearchId. # # Также установите свою страну и язык, на которых вы хотите отслеживать результаты SERP. # # Если у вас еще нет ключа API и идентификатора поиска, # # вы можете выполнить шаги в разделе «Предварительные требования» на этой странице https://developers.google.com/custom-search/v1/overview#prerequisites # # # # 2- Вам также необходимо ввести имена базы данных, таблицы поисковой выдачи и таблицы кластера, которые будут использоваться для сохранения результатов. # # # #3- введите имя файла csv или полный путь, который содержит ключевые слова, которые будут использоваться для поисковой выдачи # # # #4- Для кластеризации ключевых слов введите метку времени для результатов поисковой выдачи, которая будет использоваться для кластеризации. # # Если вам нужно сгруппировать последние результаты поисковой выдачи, введите «max» для метки времени. # # или вы можете ввести конкретную временную метку, например "2021-02-18 17:18:05.195321" # # # # 5- Просмотрите результаты через браузер БД для программы Sqlite # ################################################### ################################################### ########################################### Имя файла #csv, в котором есть ключевые слова для поисковой выдачи CSV_FILE="ключевые слова.csv" # определить язык ЯЗЫК = "ru" #определить город СТРАНА = "ru" #ключ json пользовательского поиска Google API API_KEY="ВВЕДИТЕ КЛЮЧ ЗДЕСЬ" #Идентификатор поисковой системы СПП_ # имя базы данных sqlite БАЗА ДАННЫХ="keywords.db" #название таблицы для сохранения в ней результатов выдачи SERP_TABLE="keywords_serps" # запустить поисковую выдачу по ключевым словам getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #имя таблицы, в которую будут сохраняться результаты кластера. CLUSTER_TABLE="кластеры ключевых слов" #Пожалуйста, введите временную метку, если вы хотите создать кластеры для определенной временной метки #Если вам нужно сделать кластеры для последнего результата поисковой выдачи, отправьте его со значением «max» #TIMESTAMP="2021-02-18 17:18:05.195321" ТАЙМСТАМП="макс" # запускать кластеры ключевых слов в соответствии с алгоритмами сетей и сообщества getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Результаты Google SERP и обнаружение семантики
Мы надеемся, что вам понравился этот скрипт с его быстрой группировкой ключевых слов в семантические кластеры, не полагаясь на семантические модели. Поскольку эти модели часто бывают сложными и дорогостоящими, важно рассмотреть другие способы определения ключевых слов, имеющих общие семантические свойства.
Обрабатывая семантически связанные ключевые слова вместе, вы можете лучше охватить тему, лучше связать статьи на своем сайте друг с другом и повысить рейтинг своего сайта по заданной теме.