
Понимание отчета об охвате Search Console
Опубликовано: 2019-08-15Введение в отчет о покрытии и как интерпретировать данные
Отчет об охвате Search Console предоставляет информацию о том, какие страницы вашего сайта были проиндексированы, и перечисляет URL-адреса, которые вызвали какие-либо проблемы, пока робот Googlebot пытается их просканировать и проиндексировать.
На главной странице отчета о покрытии отображаются URL-адреса вашего сайта, сгруппированные по статусу:
- Ошибка: страница не проиндексирована. Этому есть несколько причин, среди прочего страницы отвечают 404, мягкие страницы 404.
- Действительно с предупреждениями: страница проиндексирована, но есть проблемы.
- Действительно: страница проиндексирована.
- Исключено: страница не проиндексирована, Google следует правилам на сайте, таким как теги noindex в robots.txt или метатеги, канонические теги и т. д., которые препятствуют индексации страниц.
Этот отчет о покрытии дает гораздо больше информации, чем старая поисковая консоль Google. Google действительно улучшил данные, которыми он делится, но все еще есть некоторые вещи, которые нуждаются в улучшении.
Как вы можете видеть ниже, Google показывает график с количеством URL-адресов в каждой категории. Если происходит внезапное увеличение количества ошибок, вы можете увидеть столбцы и даже сопоставить их с показами, чтобы определить, может ли увеличение количества URL-адресов с ошибками или предупреждениями снизить количество показов.

После запуска сайта или создания новых разделов вы хотите увидеть увеличение количества действительных проиндексированных страниц. Google индексирует новые страницы в течение нескольких дней, но вы можете использовать инструмент проверки URL-адресов, чтобы запросить индексацию и сократить время, за которое Google найдет вашу новую страницу.

Однако, если вы видите уменьшение количества допустимых URL-адресов или внезапные всплески, важно поработать над идентификацией URL-адресов в разделе «Ошибки» и исправить проблемы, перечисленные в отчете. Google предоставляет хороший обзор действий, которые необходимо выполнить при увеличении количества ошибок или предупреждений.
Google предоставляет информацию о том, что это за ошибки и сколько URL-адресов имеют эту проблему:

Помните, что Google Search Console не показывает 100% точную информацию. На самом деле было несколько сообщений об ошибках и аномалиях данных. Кроме того, консоль поиска Google требует времени для обновления, известно, что данные отстают от 16 до 20 дней. Кроме того, в отчете иногда будет отображаться список из более чем 1000 страниц в категориях ошибок или предупреждений, как вы можете видеть на изображении выше, но он позволяет вам просмотреть и загрузить только образцы 1000 URL-адресов для аудита и проверки.
Тем не менее, это отличный инструмент для поиска проблем с индексацией вашего сайта:
Когда вы нажмете на конкретную ошибку, вы сможете увидеть страницу сведений, на которой перечислены примеры URL-адресов:

Как вы можете видеть на изображении выше, это страница сведений обо всех URL-адресах, отвечающих с ошибкой 404. В каждом отчете есть ссылка «Подробнее», которая ведет на страницу документации Google с подробной информацией об этой конкретной ошибке. Google также предоставляет график, показывающий количество затронутых страниц с течением времени.
Вы можете щелкнуть по каждому URL-адресу, чтобы проверить URL-адрес, который похож на старую функцию «выбрать как Googlebot» из старой консоли поиска Google. Вы также можете проверить, не заблокирована ли страница вашим файлом robots.txt.
После того, как вы исправите URL-адреса, вы можете попросить Google проверить их, чтобы ошибка исчезла из вашего отчета. Вы должны уделить первоочередное внимание исправлению проблем, которые находятся в состоянии проверки «сбой» или «не запущен».
Важно отметить, что вы не должны ожидать, что все URL-адреса на вашем сайте будут проиндексированы. Google заявляет, что цель веб-мастера должна состоять в том, чтобы проиндексировать все канонические URL-адреса. Дублирующиеся или альтернативные страницы будут классифицироваться как исключенные, поскольку их содержание похоже на каноническую страницу.
Для сайтов нормально иметь несколько страниц, включенных в исключенную категорию. Большинство веб-сайтов будут иметь несколько страниц без метатегов index или заблокированных через robots.txt. Когда Google идентифицирует дубликат или альтернативную страницу, вы должны убедиться, что эти страницы имеют канонический тег, указывающий на правильный URL-адрес, и попытаться найти канонический эквивалент в допустимой категории.
Google включил раскрывающийся фильтр в левом верхнем углу отчета, чтобы вы могли отфильтровать отчет по всем известным страницам, всем отправленным страницам или URL-адресам в определенной карте сайта. Отчет по умолчанию включает все известные страницы, включая все URL-адреса, обнаруженные Google. Все представленные страницы включают все URL-адреса, указанные вами через карту сайта. Если вы отправили несколько файлов Sitemap, вы можете фильтровать их по URL-адресам в каждом файле Sitemap.
[Пример успеха] Увеличьте краулинговый бюджет на стратегически важных страницах
 Читать тематическое исследование
Читать тематическое исследованиеОшибки, предупреждения, допустимые и исключенные URL-адреса
Ошибка
- Ошибка сервера (5xx): сервер вернул ошибку 500, когда робот Googlebot попытался просканировать страницу.
- Ошибка перенаправления. Когда робот Googlebot просканировал URL-адрес, произошла ошибка перенаправления, поскольку цепочка была слишком длинной, возникла петля перенаправления, URL-адрес превысил максимальную длину URL-адреса или в цепочке перенаправления был неверный или пустой URL-адрес.
- Отправленный URL-адрес заблокирован robots.txt: URL-адреса в этом списке заблокированы вашим файлом robts.txt.
- Отправленный URL-адрес с пометкой «noindex»: URL-адреса в этом списке имеют метатег robots «noindex» или заголовок http.
- Представленный URL-адрес выглядит как программная ошибка 404: программная ошибка 404 возникает, когда несуществующая страница (была удалена или перенаправлена) отображает пользователю сообщение «страница не найдена», но не возвращает код состояния HTTP 404. Мягкие ошибки 404 также возникают, когда страницы перенаправляются на нерелевантные страницы, например, страница перенаправляется на домашнюю страницу вместо возврата кода состояния 404 или перенаправления на соответствующую страницу.
- Отправленный URL-адрес возвращает неавторизованный запрос (401): страница, отправленная для индексации, возвращает неавторизованный HTTP-ответ 401.
- Отправленный URL-адрес не найден (404): страница ответила ошибкой 404 Not Found, когда робот Googlebot попытался просканировать страницу.
- При сканировании отправленного URL возникла ошибка: робот Googlebot обнаружил ошибку сканирования при сканировании этих страниц, не подпадающих ни под одну из других категорий. Вам нужно будет проверить каждый URL-адрес и определить, в чем может быть проблема.
Предупреждение
- Проиндексирована, но заблокирована robots.txt: страница была проиндексирована, потому что робот Googlebot получил к ней доступ по внешним ссылкам, указывающим на страницу, однако страница заблокирована вашим файлом robots.txt. Google помечает эти URL-адреса как предупреждения, потому что они не уверены, действительно ли страница должна быть заблокирована от отображения в результатах поиска. Если вы хотите заблокировать страницу, вы должны использовать метатег «noindex» или заголовок HTTP-ответа noindex.
Если Google прав и URL-адрес был заблокирован неправильно, вам следует обновить файл robots.txt, чтобы Google мог сканировать страницу.
Действительный
- Отправлено и проиндексировано: URL-адреса, которые вы отправили в Google через sitemap.xml для индексации и были проиндексированы.
- Проиндексировано, не отправлено в карту сайта: URL-адрес был обнаружен Google и проиндексирован, но он не был включен в вашу карту сайта. Рекомендуется обновить карту сайта и включить в нее все страницы, которые Google должен сканировать и индексировать.
Исключенный
- Исключено тегом «noindex»: когда Google попытался проиндексировать страницу, он обнаружил метатег роботов «noindex» или заголовок HTTP.
- Заблокировано инструментом удаления страницы: кто-то отправил запрос в Google, чтобы не индексировать эту страницу, используя запрос на удаление URL в Google Search Console. Если вы хотите, чтобы эта страница была проиндексирована, войдите в консоль поиска Google и удалите ее из списка удаленных страниц.
- Заблокировано robots.txt: в файле robots.txt есть строка, исключающая сканирование URL-адреса. Вы можете проверить, какая строка это делает, используя тестер robots.txt.
- Заблокировано из-за несанкционированного запроса (401): так же, как и в категории «Ошибка», страницы здесь возвращаются с HTTP-заголовком 401.
- Аномалия сканирования: это своего рода универсальная категория, URL-адреса здесь отвечают кодами ответа уровня 4xx или 5xx; Эти коды ответов предотвращают индексацию страницы.
- Просканировано – в настоящее время не проиндексировано: Google не указывает причину, по которой URL-адрес не был проиндексирован. Они предлагают повторно отправить URL для индексации. Тем не менее, важно проверить, содержит ли страница недостаточный или повторяющийся контент, канонизирована ли она для другой страницы, имеет ли директива noindex, метрики показывают плохое взаимодействие с пользователем, высокую скорость загрузки страницы и т. д. Может быть несколько причин, по которым Google не хочет индексировать страницу.
- Обнаружено – в настоящее время не проиндексировано: страница найдена, но Google не включил ее в свой индекс. Вы можете отправить URL-адрес для индексации, чтобы ускорить процесс, как мы упоминали выше. Google заявляет, что типичной причиной этого является то, что сайт был перегружен, и Google перепланировал сканирование.
- Альтернативная страница с правильным каноническим тегом: Google не проиндексировал эту страницу, поскольку у нее есть канонический тег, указывающий на другой URL. Google следовал каноническому правилу и правильно проиндексировал канонический URL. Если вы хотели, чтобы эта страница не индексировалась, то здесь нечего исправлять.
- Дублировать без выбранной пользователем канонической: Google обнаружил дубликаты страниц, перечисленных в этой категории, и ни одна из них не использует канонические теги. Google выбрал другую версию в качестве канонического тега. Вам необходимо просмотреть эти страницы и добавить канонический тег, указывающий на правильный URL.
- Дубликат, Google выбрал другой канонический, чем пользовательский: URL-адреса в этой категории были обнаружены Google без явного запроса на сканирование. Google нашел их по внешним ссылкам и определил, что есть другая страница, которая лучше соответствует каноничности. По этой причине Google не проиндексировал эти страницы. Google рекомендует помечать эти URL-адреса как дубликаты канонических.
- Не найдено (404): когда робот Googlebot пытается получить доступ к этим страницам, он отвечает ошибкой 404. Google заявляет, что эти URL-адреса не были отправлены, эти URL-адреса были найдены по внешним ссылкам, указывающим на эти URL-адреса. Рекомендуется перенаправить эти URL-адреса на похожие страницы, чтобы воспользоваться преимуществами ссылочного капитала, а также убедиться, что пользователи переходят на релевантную страницу.
- Страница удалена из-за судебной жалобы: кто-то жаловался на эти страницы из-за юридических проблем, таких как нарушение авторских прав. Вы можете обжаловать поданную юридическую жалобу здесь.
- Страница с перенаправлением: эти URL-адреса перенаправляют, поэтому они исключены.
- Мягкий 404: как объяснялось выше, эти URL-адреса исключены, потому что они должны отвечать 404. Проверьте страницы и убедитесь, что если на них есть сообщение «не найдено», они должны ответить HTTP-заголовком 404.
- Дублирующийся отправленный URL-адрес не выбран как канонический. Однако, как и в случае «Google выбрал другой канонический, чем пользовательский», URL-адреса в этой категории были отправлены вами. Рекомендуется проверить карты сайта и убедиться, что в них нет повторяющихся страниц.
Как использовать данные и действия для улучшения сайта
Работая в агентстве, я имею доступ к множеству различных сайтов и их отчетам о покрытии. Я потратил время на анализ ошибок, о которых Google сообщает в различных категориях.
Было полезно найти проблемы с канонизацией и дублированием контента, однако иногда вы сталкиваетесь с несоответствиями, о которых сообщил @jroakes:

Похоже, Google Search Console > Проверка URL > Живой тест неправильно сообщает обо всех файлах JS и CSS как о разрешенных сканировании: Нет: заблокировано robots.txt. Протестируйте около 20 файлов в 3 доменах. pic.twitter.com/fM3WAcvK8q
— JR%20Оукс ???? (@jroakes) 16 июля 2019 г.
AJ Koh написал отличную статью вскоре после того, как стала доступна новая консоль поиска Google, в которой он объясняет, что реальная ценность данных заключается в том, чтобы использовать их для создания картины здоровья для каждого типа контента на вашем сайте:
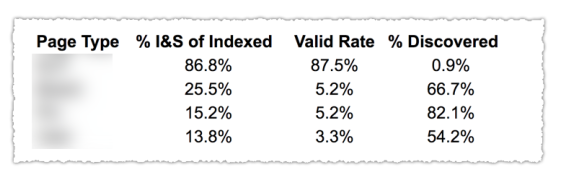
Как вы можете видеть на изображении выше, URL-адреса из разных категорий в отчете о покрытии были классифицированы по шаблонам страниц, таким как блог, страница службы и т. д. Использование нескольких карт сайта для разных типов URL-адресов может помочь с этой задачей, поскольку Google позволяет вам фильтровать информацию о покрытии по карте сайта. Затем он включил три столбца со следующей информацией: % проиндексированных и отправленных страниц, валидная ставка и % обнаруженных.
Эта таблица действительно дает вам отличный обзор состояния вашего сайта. Теперь, если вы хотите покопаться в разных разделах, я рекомендую просмотреть отчеты и дважды проверить ошибки, которые выдает Google.
Вы можете загрузить все URL-адреса, представленные в разных категориях, и использовать OnCrawl для проверки их статуса HTTP, канонических тегов и т. д., а также создать электронную таблицу, подобную этой:
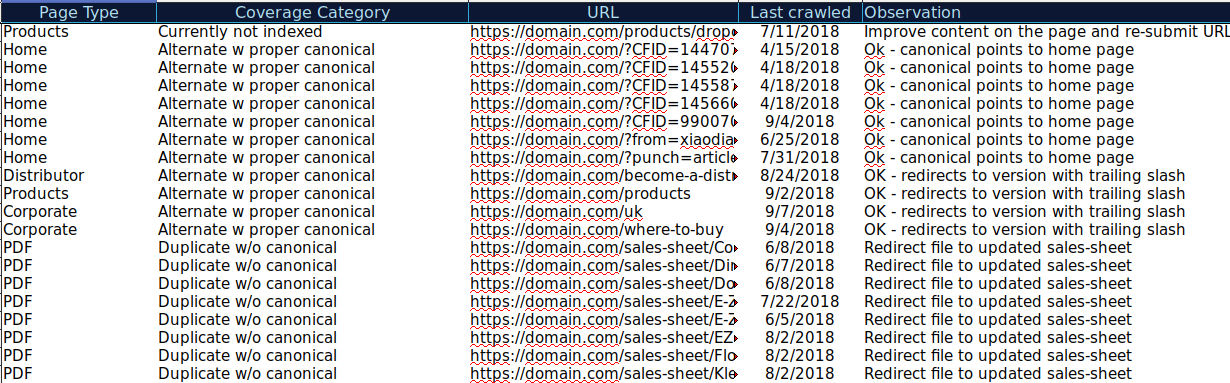
Подобная организация данных может помочь отслеживать проблемы, а также добавлять действия для URL-адресов, которые необходимо улучшить или исправить. Кроме того, вы можете отмечать правильные URL-адреса, и никаких действий не требуется в случае этих URL-адресов с параметрами с правильной реализацией канонического тега.
Начните бесплатную 14-дневную пробную версию
 Начать пробную версию
Начать пробную версиюВы даже можете добавить в эту таблицу дополнительную информацию из других источников, таких как ahrefs, Majestic и Google Analytics, с интеграцией OnCrawl. Это позволит вам извлекать данные о ссылках, а также данные о трафике и конверсиях для каждого из URL-адресов в Google Search Console. Все эти данные могут помочь вам принять более правильное решение о том, что делать с каждой страницей, например, если у вас есть список страниц с ошибками 404, вы можете связать его с обратными ссылками, чтобы определить, теряете ли вы какой-либо ссылочный вес от доменов, ссылающихся на битые страницы на вашем сайте. Или вы можете проверить проиндексированные страницы и объем органического трафика, который они получают. Вы можете определить проиндексированные страницы, которые не получают органического трафика, и поработать над их оптимизацией (улучшить содержание и удобство использования), чтобы привлечь больше трафика на эту страницу.
С помощью этих дополнительных данных вы можете создать сводную таблицу в другой электронной таблице. Вы можете использовать формулу =СЧЁТЕСЛИ(диапазон, критерии) для подсчёта URL-адресов для каждого типа страницы (эта таблица может дополнить таблицу, предложенную А. Дж. Коном выше). Вы также можете использовать другую формулу, чтобы добавить обратные ссылки, посещения или конверсии, которые вы извлекли для каждого URL-адреса, и отобразить их в сводной таблице с помощью следующей формулы =СУММЕСЛИ (диапазон, критерии, [суммарный_диапазон]). Вы получите что-то вроде этого:
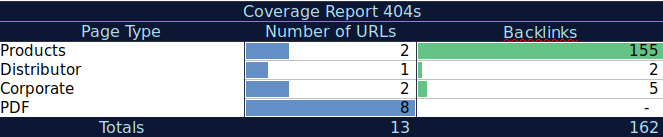
Мне очень нравится работать со сводными таблицами, которые могут дать мне сводное представление данных и могут помочь мне определить разделы, на исправлении которых мне нужно сосредоточиться в первую очередь.
Последние мысли
Когда вы работаете над устранением проблем и просматриваете данные в этом отчете, вам нужно подумать о следующем: оптимизирован ли мой сайт для сканирования? Количество проиндексированных и действительных страниц увеличивается или уменьшается? Страницы с ошибками увеличиваются или уменьшаются? Позволяю ли я Google тратить время на URL-адреса, которые принесут больше пользы моим пользователям, или он находит много бесполезных страниц? Получив ответы на эти вопросы, вы сможете начать улучшать свой сайт, чтобы робот Googlebot мог тратить свой краулинговый бюджет на страницы, которые могут принести пользу вашим пользователям, а не на бесполезные страницы. Вы можете использовать файл robots.txt, чтобы повысить эффективность сканирования, по возможности удалить бесполезные URL-адреса или использовать теги canonical или noindex для предотвращения дублирования контента.
Google продолжает добавлять функциональные возможности и обновлять точность данных в различных отчетах в поисковой консоли Google, поэтому мы надеемся, что мы продолжим видеть больше данных в каждой из категорий в отчете о покрытии, а также в других отчетах в Google Search Console.