
Быстрый и грязный 11-шаговый технический SEO-аудит для общего состояния сайта
Опубликовано: 2020-02-27Техническое SEO имеет значение, потому что это отправная точка любого проекта. С точки зрения специалиста по поисковой оптимизации каждый веб-сайт — это новый проект. Веб-сайт должен иметь прочную основу, чтобы получать хорошие результаты и достигать наиболее важных KPI в SEO, таких как рейтинг.
Каждый раз, когда я начинаю новый проект, первое, что я делаю, — это технический SEO-аудит. В большинстве случаев устранение технических проблем может дать поразительные результаты, как только веб-сайт будет повторно просканирован.
Мне смешно, когда люди говорят о контенте и еще раз о контенте, но не говорят ни слова о техническом SEO. Одно можно сказать наверняка: здоровье веб-сайта и техническое SEO — две важные вещи, которые будут иметь решающее значение в 2020 году. Я не хочу сказать, что контент не важен. Это так, но я не думаю, что без исправления технических проблем на веб-сайте контент может принести результаты.
Я видел случаи, когда важные страницы были заблокированы директивами в файле robots.txt, или наиболее важные страницы категорий или услуг были повреждены или заблокированы мета-роботами, такими как noindex, nofollow. Как можно добиться успеха, не расставляя приоритеты, исправляя эти проблемы?
Удивительно видеть количество SEO-специалистов, которые не знают, как выявлять технические проблемы и сообщать об их устранении специалистам по веб-разработке. Я вспомнил, как однажды, работая в корпоративной сфере, я создал контрольный лист аудита технического SEO, который будет использоваться моей командой. В то время я понял, что, имея под рукой такой лист быстрых исправлений, он может очень помочь команде и дать быстрый толчок клиенту. Вот почему я считаю крайне важным инвестировать в инструмент / программное обеспечение, которое может помочь вам с технической диагностикой SEO и рекомендациями.
Давайте начнем практический процесс проведения быстрого технического SEO-аудита, который будет иметь большое значение. Это быстрое упражнение займет у вас около часа, даже если вы не профессионал. Для меня использование инструмента Tech SEO, такого как OnCrawl, для быстрой перемотки всех вещей за пять минут без необходимости выполнять всю ручную работу, упрощает мою жизнь.
Я расскажу о самых важных вещах, которые необходимо проверить при проведении технического SEO-аудита. Есть и другие вещи, которые мы можем проверить на наличие проблем на странице, но я хочу сосредоточиться только на вещах, которые создадут проблемы с индексацией и тратят бюджет на сканирование. Расстановка приоритетов — это способ убедиться, что наиболее важные страницы будут просканированы роботом Googlebot.
- Индексация
- Файл robots.txt
- Метатег роботов
- 4xx ошибки
- карты сайта
- HTTP/HTTPS (безопасность веб-сайтов, смешанный контент и дублирование контента)
- Пагинация
- 404 страница
- Глубина и структура сайта
- Длинные цепочки редиректов
- Реализация канонического тега
1) Индексация
Это первое, что нужно проверить. Во многих случаях на индексацию может повлиять конфигурация плагина или любая незначительная ошибка, но влияние на возможность поиска может быть огромным, поскольку сегодня проиндексировано более 6,16 миллиардов веб-страниц. Вы должны понимать, что любая поисковая система прилагает усилия, и даже Google должен отдавать приоритет наиболее релевантной странице для взаимодействия с пользователем. Если вы не подумаете об упрощении работы робота Googlebot, ваши конкуренты сделают это и завоюют гораздо больше доверия, чем здоровый веб-сайт.
Когда возникают проблемы с индексацией, проблемы со здоровьем вашего сайта отразятся на потере органического трафика. Процесс индексации означает, что поисковая система просматривает веб-страницу и упорядочивает информацию, которая позже предлагает ее в поисковой выдаче. Результаты зависят от релевантности намерениям пользователя. Если веб-страница не может или имеет проблемы со сканированием, это даст преимущество другим страницам в той же нише.
Например, используя операторы поиска:
Сайт: www.abc.com
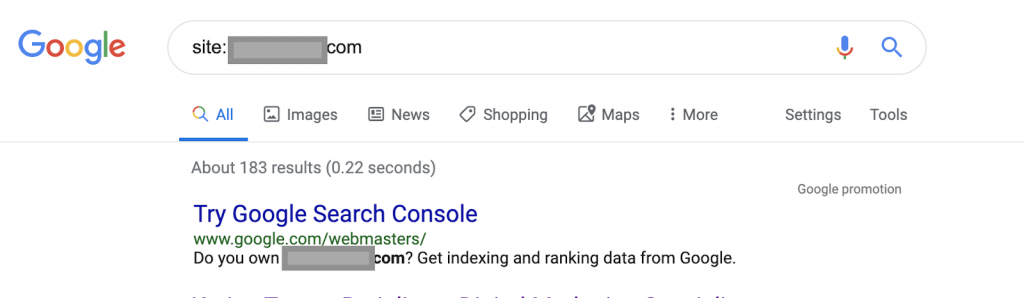
Запрос вернет 183 страницы, проиндексированные Google. Это приблизительная оценка количества страниц, проиндексированных Google. Вы можете проверить консоль поиска Google для точного числа.
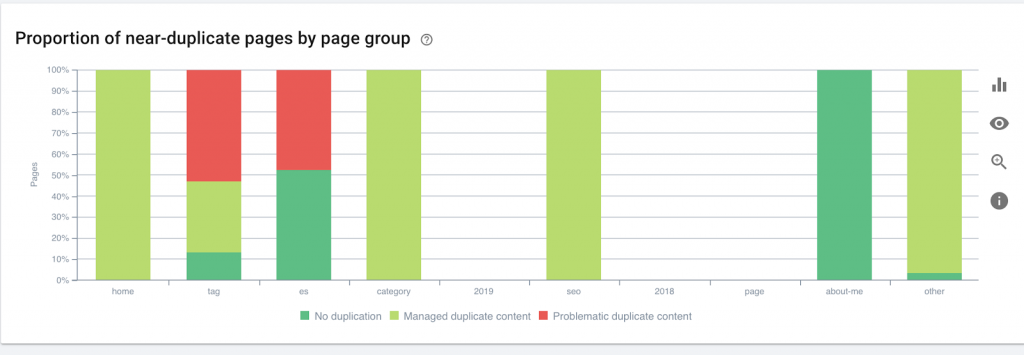
Вам также следует использовать веб-краулер, такой как OnCrawl, чтобы составить список всех страниц, к которым у Google есть доступ. Это показывает другое число, как вы можете видеть ниже:
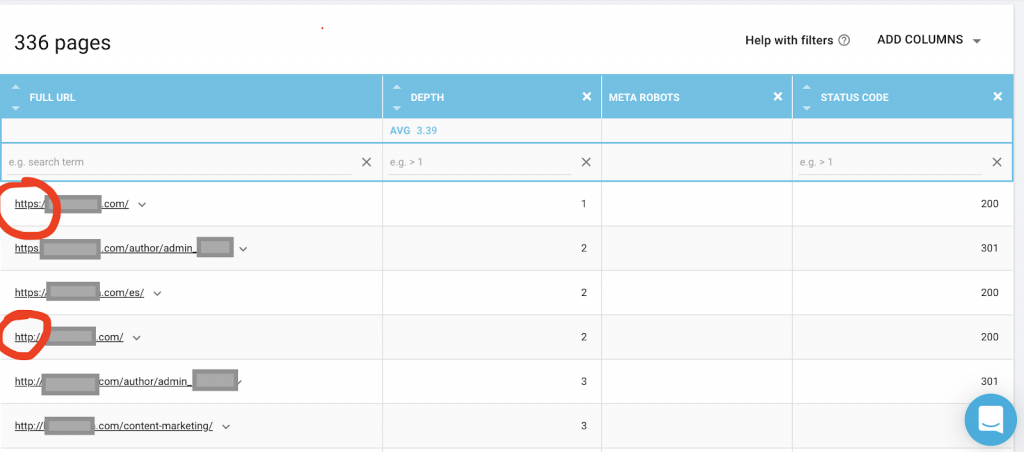
На этом веб-сайте почти в два раза больше сканируемых страниц, чем проиндексированных страниц.
Это может выявить проблему дублирования контента или даже проблему версии безопасности веб-сайта между HTTP и HTTPS. Я расскажу об этом позже в этой статье.
В данном случае сайт был перенесен с HTTP на HTTPS. В OnCrawl мы видим, что HTTP-страницы были перенаправлены. Версии HTTP и HTTPS по-прежнему доступны для робота Googlebot, и он может сканировать все повторяющиеся страницы вместо того, чтобы отдавать приоритет наиболее важным страницам, которые владелец хочет ранжировать, что приводит к пустой трате краулингового бюджета.
Еще одна распространенная проблема среди запущенных веб-сайтов или крупных веб-сайтов, таких как сайты электронной коммерции, — это проблемы смешанного контента. Короче говоря, проблемы возникают, когда на вашей защищенной странице есть ресурсы, такие как медиафайлы (чаще всего: изображения), загруженные из незащищенной версии.
Как это исправить:
Вы можете попросить веб-разработчика перевести все HTTP-страницы на HTTPS-версию и один раз перенаправить HTTP-адреса на HTTPS, используя код состояния 301.
В случае проблем со смешанным содержимым вы можете вручную проверить источник страницы и выполнить поиск ресурсов, загруженных как «src=http://example.com/media/images», что почти безумно, особенно для больших веб-сайтов. Вот почему нам нужно использовать технический инструмент SEO.
2) файл robots.txt:
Файл robots.txt сообщает агентам сканирования, какие страницы им не следует сканировать. В руководстве по спецификациям robots.txt указано, что формат файла должен быть простым текстом с максимальным размером 500 КБ.
Я рекомендую добавить карту сайта в robots.txt.file. Не все так делают, но я считаю, что это хорошая практика. Файл robots.txt должен быть размещен на вашем размещенном сервере в public_html и идет после корневого домена.
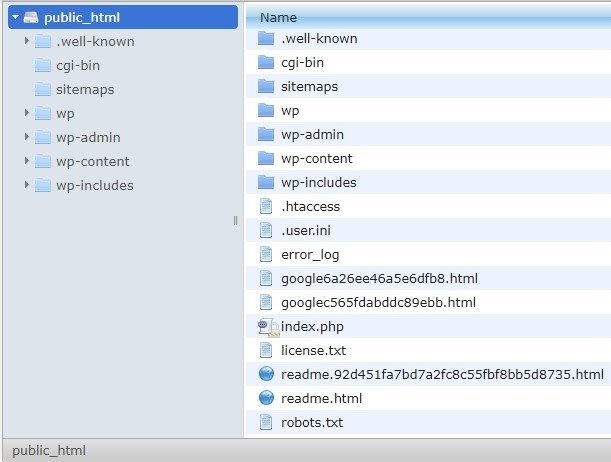
Мы можем использовать директивы в файле robots.txt, чтобы запретить поисковым системам сканировать ненужные страницы или страницы с конфиденциальной информацией, такой как страница администратора, шаблоны или корзина покупок (/cart, /checkout, /login, папки, такие как /tag, используемые в блогах). , добавив эти страницы в файл robots.txt.
Совет . Убедитесь, что вы не заблокируете папку с мультимедийными файлами, потому что это исключит индексирование ваших изображений, видео или других размещенных на собственном хостинге медиафайлов. Медиа могут быть очень важны для релевантности страницы, а также для органического ранжирования и трафика для изображений или видео.
3) Метатег роботов
Это фрагмент HTML-кода, который указывает поисковым системам, следует ли сканировать и индексировать страницу со всеми ссылками на этой странице. Тег HTML находится в заголовке вашей веб-страницы. Существует 4 общих HTML-тега для роботов:
- Не следует
- Следовать
- Показатель
- Без индекса
Когда нет мета-тегов robots, поисковые системы будут следовать и индексировать контент по умолчанию.
Вы можете использовать любую комбинацию, которая лучше всего соответствует вашим потребностям. Например, с помощью OnCrawl я обнаружил, что на «странице автора» с этого сайта нет мета-роботов. Это означает, что по умолчанию направление («следовать, индексировать»)
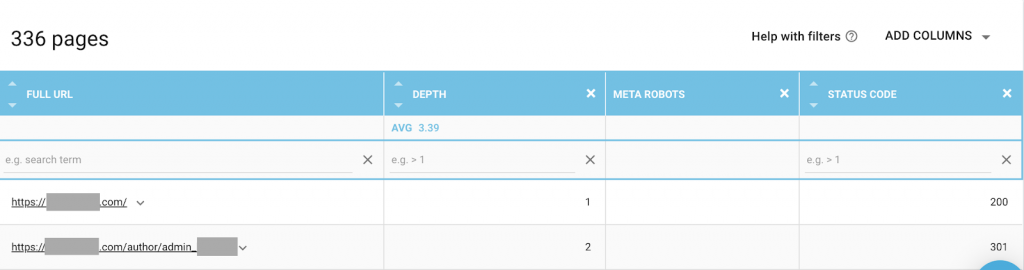
Это должно быть («noindex, nofollow»).
Почему?
Каждый случай индивидуален, но этот сайт представляет собой небольшой личный блог. В блоге публикуется только один автор, и домен — это имя автора. В этом случае страница «автор» не предоставляет никакой дополнительной информации, даже если она создается платформой блогов.
Другим сценарием может быть веб-сайт, на котором важны категории в блоге. Когда владелец хочет ранжироваться по категориям в своем блоге, мета-роботы должны быть («следить, индексировать») или по умолчанию на страницах категорий.
В другом сценарии для крупного и известного веб-сайта, на котором крупные SEO-специалисты пишут статьи, за которыми следит сообщество, имя автора в Google выступает в роли бренда. В этом случае вы, вероятно, захотите проиндексировать имена некоторых авторов.
Как видите, метароботов можно использовать по-разному.
Как это исправить:
Попросите веб-разработчика изменить метатег робота по мере необходимости. В приведенном выше случае для небольшого веб-сайта я могу сделать это сам, зайдя на каждую страницу и изменив ее вручную. Если вы используете WordPress, вы можете изменить это в настройках RankMath или Yoast.
4) 4xx ошибки:
Это ошибки на стороне клиента, и они могут быть 401, 403 и 404.
- 404 Страница не найдена:
Эта ошибка возникает, когда страница недоступна по проиндексированному URL-адресу. Он мог быть перемещен или удален, а старый адрес не был должным образом перенаправлен с помощью функции веб-сервера 301. Ошибки 404 являются негативным опытом для пользователей и представляют собой техническую проблему SEO, которую необходимо решить. Хорошо часто проверять ошибки 404 и исправлять их, а не оставлять их снова и снова для обхода агентов, которые тратят впустую свой бюджет.
Как это исправить:
Нам нужно найти адреса, которые возвращают 404, и исправить их с помощью переадресации 301, если контент все еще существует. Или, если это изображения, их можно заменить новыми, сохраняя то же имя файла.
- 401 Неавторизованный
Это проблема разрешения. Ошибка 401 обычно возникает, когда требуется аутентификация, например имя пользователя и пароль.
Как это исправить:
Вот два варианта: первый — заблокировать страницу от поисковых систем с помощью robots.txt. Второй — убрать требование аутентификации.
- 403 Запрещено
Эта ошибка аналогична ошибке 401. Ошибка 403 возникает из-за того, что на странице есть ссылки, недоступные для публики.

Как это исправить:
Измените требование в сервере, чтобы разрешить доступ к странице (только если это ошибка). Если вам нужно, чтобы эта страница была недоступна, удалите со страницы все внутренние и внешние ссылки.
- ошибка 400, неверный запрос
Это происходит, когда браузер не может связаться с веб-сервером. Эта ошибка обычно возникает из-за неправильного синтаксиса URL.
Как это исправить:
Найдите ссылки на эти URL-адреса и исправьте синтаксис. Если это невозможно исправить, вам нужно будет связаться с веб-разработчиком, чтобы исправить их.
Примечание. Мы можем найти 400 ошибок с помощью инструментов или в консоли Google.

5) Карта сайта
Карта сайта — это список всех URL-адресов, которые содержит веб-сайт. Наличие карты сайта улучшает возможности поиска, поскольку помогает поисковым роботам находить и понимать ваш контент.
У нас есть разные типы карт сайта, и нам нужно убедиться, что все они в хорошем состоянии.
Карты сайта, которые у нас должны быть:
- Карта сайта в формате HTML: она будет на вашем веб-сайте и поможет пользователям перемещаться и находить страницы на вашем веб-сайте.
- XML-карта сайта: это файл, который поможет поисковым системам сканировать ваш веб-сайт (рекомендуется включить его в файл robots.txt).
- Видео XML-карта сайта: То же, что и выше.
- XML-карта сайта изображений: тоже самое, что и выше. Рекомендуется создавать отдельные карты сайта для изображений, видео и контента.
Для больших веб-сайтов рекомендуется иметь несколько файлов Sitemap для лучшего сканирования, поскольку файлы Sitemap не должны содержать более 50 000 URL-адресов.
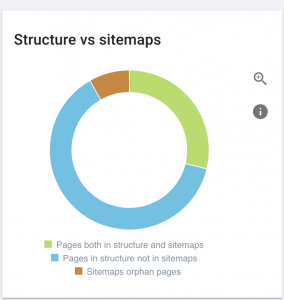
У этого сайта проблемы с картой сайта.
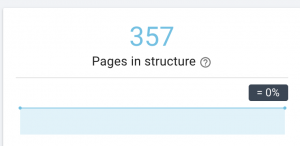
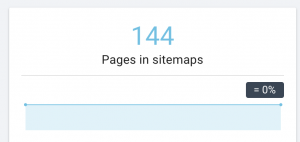
Как мы это исправим:
Мы исправляем это, создавая разные карты сайта для контента, изображений и видео. Затем мы отправляем их через консоль поиска Google, а также создаем карту сайта в формате HTML для веб-сайта. Нам не нужен веб-разработчик для этого. Мы можем использовать любой бесплатный онлайн-инструмент для создания карты сайта.
6) HTTP/HTTPS (дублированный контент)
Многие веб-сайты имеют эти проблемы в результате перехода с HTTP на HTTPS. Если это так, веб-сайт будет показывать версии HTTP и HTTPS в поисковых системах. Как следствие этой общей технической проблемы, рейтинги размыты. Эти проблемы также вызывают проблемы с дублированием контента.
![]()

Как это исправить:
Попросите веб-разработчика исправить эту проблему, заменив все HTTP на HTTPS.
Примечание . Никогда не перенаправляйте все HTTP-запросы на домашнюю страницу HTTPS, поскольку это приведет к программным ошибкам 404. (Вы должны сказать это веб-разработчику; помните, что они не оптимизаторы.)
7) Пагинация
Это использование тега HTML («rel = prev» и «rel = next»), который устанавливает отношения между страницами и показывает поисковым системам, что контент, представленный на разных страницах, должен быть идентифицирован или связан с одной. Пагинация используется для ограничения контента для UX и веса страницы для технической части, сохраняя их размер менее 3 МБ. Мы можем использовать бесплатный инструмент для проверки нумерации страниц.
Пагинация должна иметь самоканонические ссылки и указывать «отн. = предыд.» и «отн. = следующий». Единственной дублирующейся информацией будут мета-заголовок и мета-описание, но разработчики могут изменить их, чтобы создать небольшой алгоритм, чтобы каждая страница имела сгенерированный мета-заголовок и мета-описание.
Как это исправить:
Попросите веб-разработчика внедрить HTML-теги разбивки на страницы с самоканоническим тегом.
SEO-краулер OnCrawl
 Декуврир
Декуврир8) Пользовательская страница 404 не найдена
Ответ 404, как мы обсуждали ранее, представляет собой ошибку « Не найдено », которая приводит пользователей к неработающей ссылке или несуществующей странице. Это возможность перенаправить пользователей в нужное место. Есть отличные примеры пользовательских страниц 404. Это необходимая вещь.
Вот пример отличной пользовательской страницы 404:

Как это исправить:
Создайте собственную страницу 404: подумайте, что добавить на нее. Превратите эту ошибку в возможность для вашего бизнеса.
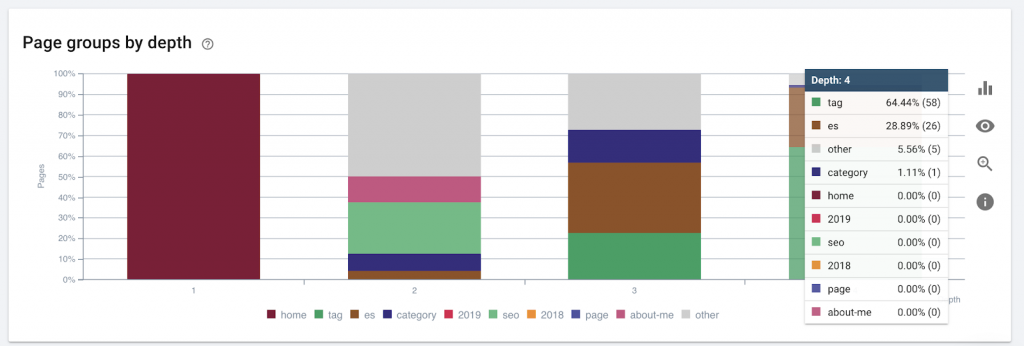
9) Глубина/структура сайта
Глубина страницы — это количество кликов, на которые ваша страница находится из корневого домена. Джон Мюллер из Google сказал, что «страницы, расположенные ближе к главной, имеют больший вес». Например, давайте представим, что для доступа к странице здесь требуется следующая навигация:

Страница «коврики» находится в 4 кликах от главной страницы. Не рекомендуется иметь страницы, расположенные дальше, чем в 4 кликах от дома, так как поисковым системам трудно сканировать более глубокие страницы.
На этом рисунке показана группа страниц по глубине. Это помогает нам понять, нуждается ли структура веб-сайта в переработке.
Как это исправить:
Страницы, которые являются наиболее важными, должны быть ближе всего к домашней странице для UX, для легкого доступа пользователей и для лучшей структуры веб-сайта. Очень важно учитывать это во время создания структуры веб-сайта или реструктуризации веб-сайта.
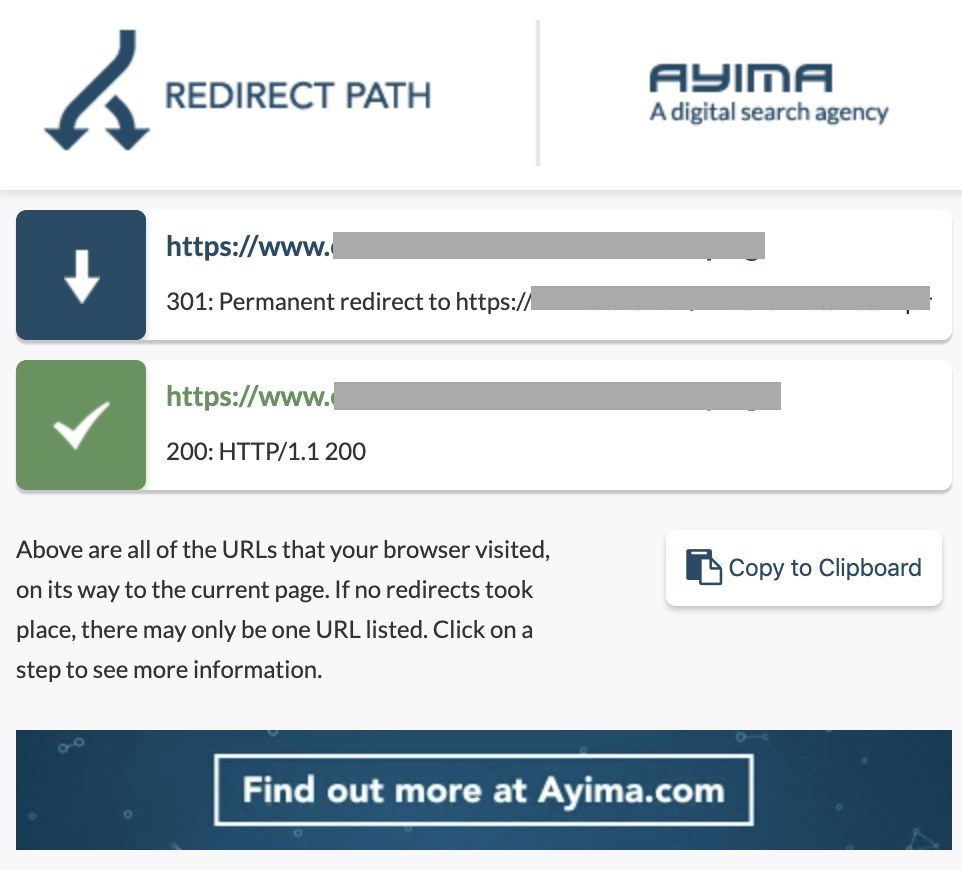
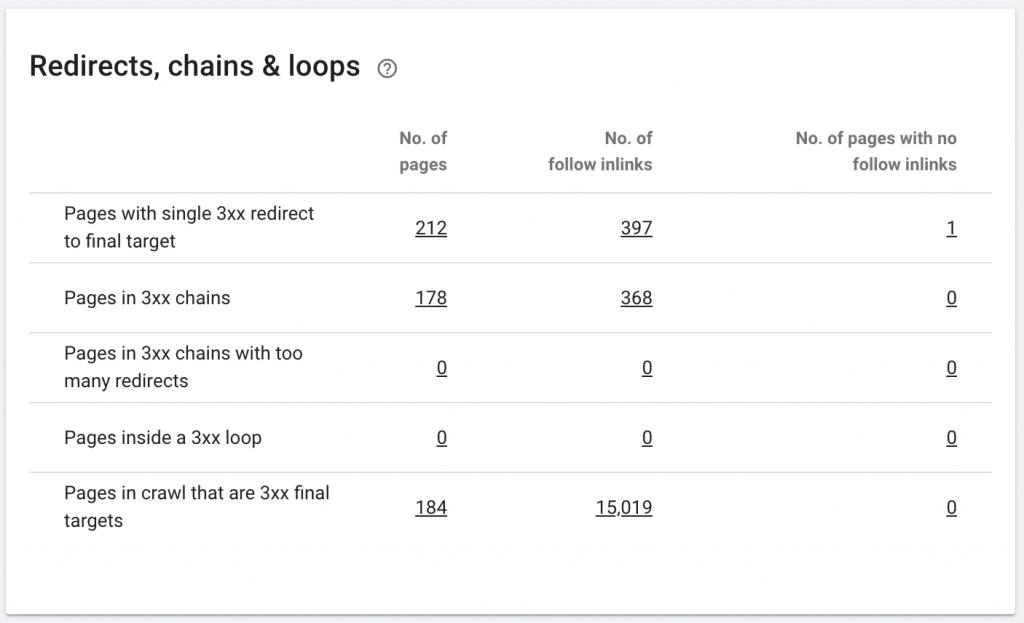
10. Цепочки переадресации
Цепочка перенаправлений — это когда между URL-адресами происходит серия перенаправлений. Эти цепочки перенаправления также могут создавать петли. Это также создает проблемы для робота Googlebot и приводит к трате краулингового бюджета.
Мы можем идентифицировать цепочки перенаправлений, используя путь перенаправления расширения Chrome или в OnCrawl.
Как это исправить:
Исправить это очень просто, если вы работаете с веб-сайтом WordPress. Просто зайдите в перенаправление и найдите цепочку — удалите все ссылки, участвующие в цепочке, если эти изменения произошли более 2-3 месяцев назад, и просто оставьте последнюю переадресацию на текущий URL. Веб-разработчики также могут помочь с этим, внеся все необходимые изменения в файл .htacces, если это необходимо. Вы можете проверить и изменить длинные цепочки редиректов в своих SEO-плагинах.
11) Канонические
Канонический тег сообщает поисковым системам, что URL-адрес является копией другой страницы. Это большая проблема, которая присутствует на многих веб-сайтах. Неправильное внедрение канонических правил или их реализация вообще создадут проблемы с дублированием контента.
Canonicals обычно используются на веб-сайтах электронной коммерции, где продукт можно найти несколько раз в разных категориях, таких как: размер, цвет и т. д.

Вы можете использовать OnCrawl, чтобы узнать, есть ли на ваших страницах канонические теги и правильно ли они реализованы. Затем вы можете изучить и исправить любые проблемы.
Как мы это исправим:
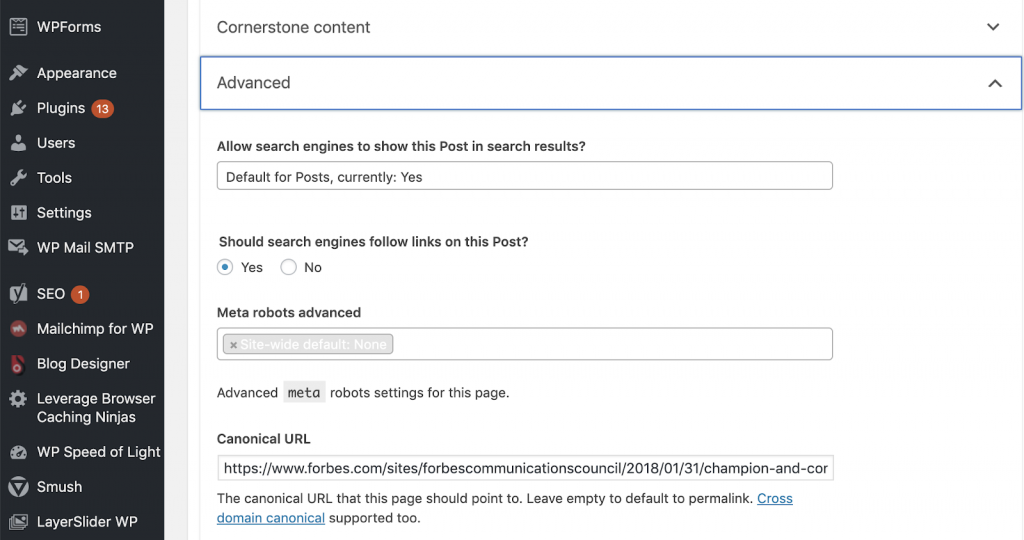
Мы можем исправить канонические проблемы с помощью Yoast SEO, если мы работаем в WordPress. Заходим в панель управления WordPress, а затем в Yoast — настройка — расширенная.
Проведение собственного аудита
SEO-специалистам, которые хотят начать заниматься техническим SEO, необходимо руководство по быстрым шагам, которым нужно следовать, чтобы улучшить SEO-здоровье. Разговор о техническом SEO с Джоном Шехатой, вице-президентом по расширению аудитории в Conde Nast и основателем NewzDash, на Глобальном дне маркетинга в Нью-Йорке в октябре 2019 года.
Вот что он сказал мне:
«Многие люди в индустрии SEO не являются техническими специалистами. Теперь не каждый SEO понимает, как кодировать, и трудно попросить людей сделать это. Некоторые компании нанимают разработчиков и обучают их тому, как стать SEO-специалистами, чтобы восполнить пробел в техническом SEO».
На мой взгляд, SEO-специалисты, не обладающие полным знанием кода, все же могут преуспеть в Tech SEO, зная, как проводить аудит, определять ключевые элементы, составлять отчеты, запрашивать веб-разработчиков для реализации и, наконец, тестировать изменения.
Готовы начать? Загрузите контрольный список для этих основных вопросов.
