
Оценка качества прогнозов причинно-следственных связей
Опубликовано: 2022-02-15CausalImpact — один из самых популярных пакетов, используемых в SEO-экспериментах. Его популярность понятна.
SEO-экспериментирование дает SEO-специалистам интересные идеи и способы сообщить о ценности их работы.
Тем не менее, точность любой модели машинного обучения зависит от входной информации, которую она получает.
Проще говоря, неправильный ввод может вернуть неправильную оценку.
В этом посте мы покажем, насколько надежным (и ненадежным) может быть CausalImpact. Мы также узнаем, как стать более уверенным в результатах своих экспериментов.
Во-первых, мы предоставим краткий обзор того, как работает CausalImpact. Затем мы обсудим надежность оценок CausalImpact. Наконец, мы узнаем о методологии, которую можно использовать для оценки результатов ваших собственных SEO-экспериментов.
Что такое каузальное влияние и как оно работает?
CausalImpact — это пакет, использующий байесовскую статистику для оценки влияния события в отсутствие эксперимента. Эта оценка называется причинным выводом.
Причинный вывод оценивает, было ли наблюдаемое изменение вызвано конкретным событием.
Он часто используется для оценки эффективности SEO-экспериментов.
Например, когда задана дата события, CausalImpact (CI) будет использовать точки данных до вмешательства для прогнозирования точек данных после вмешательства. Затем он сравнивает прогноз с наблюдаемыми данными и оценивает разницу с определенным доверительным порогом.
Кроме того, для повышения точности прогнозов можно использовать контрольные группы.
Различные параметры также будут влиять на точность прогноза:
- Размер тестовых данных.
- Продолжительность периода до эксперимента.
- Выбор контрольной группы для сравнения.
- Гиперпараметры сезонности.
- Количество итераций.
Все эти параметры помогают предоставить больше контекста модели и повысить ее надежность.
BI при сканировании
 Обнаружить
ОбнаружитьПочему важна оценка точности SEO-экспериментов?
В последние годы я проанализировал множество SEO-экспериментов, и меня что-то поразило.
Много раз использование разных контрольных групп и временных рамок на одинаковых наборах тестов и датах вмешательства давало разные результаты.
Для иллюстрации ниже приведены два результата одного и того же события.
Первый показал статистически значимое снижение. 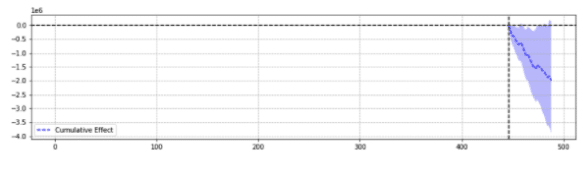
Второй не был статистически значимым. 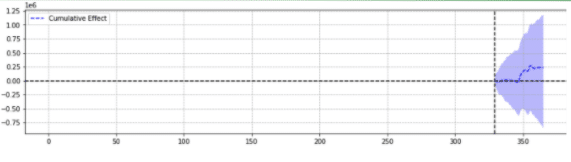
Проще говоря, для одного и того же события возвращались разные результаты в зависимости от выбранных параметров.
Нужно задаться вопросом, какой прогноз является точным.
В конце концов, разве «статистически значимый» не должен повышать уверенность в наших оценках?
Определения
Чтобы лучше понять мир SEO-экспериментов, читатель должен знать основные концепции SEO-экспериментов:
- Эксперимент : процедура, предпринятая для проверки гипотезы. В случае причинного вывода он имеет конкретную дату начала.
- Тестовая группа : подмножество данных, к которым применяется изменение. Это может быть весь сайт или его часть.
- Контрольная группа : подмножество данных, к которым не применялись никакие изменения. У вас может быть одна или несколько групп управления. Это может быть отдельный сайт в той же отрасли или другая часть того же сайта.
Пример ниже поможет проиллюстрировать эти концепции:
Изменение заголовка (эксперимент) должно увеличить органический CTR на 1% (гипотеза) страниц продукта в пяти городах (тестовая группа). Оценки будут улучшены при неизменном заголовке по всем остальным городам (контрольная группа).
Столпы точного предсказания эксперимента SEO
- Для простоты я собрал несколько интересных идей для SEO-специалистов, изучающих, как повысить точность экспериментов:
- Некоторые входные данные в CausalImpact будут возвращать неправильные оценки, даже если они статистически значимы. Это то, что мы называем «ложноположительными» и «ложноотрицательными».
- Не существует общего правила, определяющего, какой элемент управления использовать для набора тестов. Эксперимент необходим для определения наилучших контрольных данных для использования в конкретном тестовом наборе.
- Использование CausalImpact с правильным контролем и правильной длиной данных до периода может быть очень точным, при этом средняя ошибка составляет всего 0,1%.
- В качестве альтернативы, использование CausalImpact с неправильным элементом управления может привести к большому количеству ошибок. Личные эксперименты показали статистически значимые отклонения до 20%, хотя на самом деле изменений не было.
- Не все можно протестировать. Некоторые группы тестов почти никогда не дают точных оценок.
- Эксперименты с контрольными группами или без них требуют различной длины данных до вмешательства.
Не все тестовые группы будут возвращать точные оценки
Некоторые группы тестов всегда будут возвращать неточные прогнозы. Их нельзя использовать для экспериментов.
Группы тестов с большими аномальными изменениями трафика часто возвращают ненадежные результаты.
Например, в том же году на сайте произошла миграция сайта, на него повлияла пандемия ковида, и часть сайта была «неиндексирована» в течение 2 недель из-за технической ошибки. Проведение экспериментов на этом сайте даст ненадежные результаты.
Вышеуказанные выводы были получены в результате обширной серии тестов, проведенных с использованием методологии, описанной ниже.
Когда не используются контрольные группы
- Использование элемента управления вместо простого пре-поста может увеличить точность оценки до 18 раз.
- Использование данных за 16 месяцев до этого было таким же точным, как использование данных за 3 года.
При использовании контрольных групп
- Использование правильного элемента управления часто лучше, чем использование нескольких элементов управления. Однако один элемент управления увеличивает риск ошибочного предсказания в случаях, когда трафик элемента управления сильно различается.
- Выбор правильного элемента управления может увеличить точность в 10 раз (например, один сообщает +3,1%, а другой +4,1%, хотя на самом деле он +3%).
- Наиболее коррелированные модели трафика между тестовыми данными и контрольными данными не обязательно означают лучшие оценки.
- Использование данных за 16 месяцев до этого было НЕ таким точным, как использование данных за 3 года.
Остерегайтесь длины данных перед экспериментами
Интересно, что при экспериментах с контрольными группами использование данных за 16 месяцев до этого может привести к очень большому количеству ошибок.
На самом деле ошибки могут быть такими же большими, как оценка трехкратного увеличения трафика при отсутствии реальных изменений.
Однако использование данных за 3 года устранило эту частоту ошибок. Это контрастирует с простыми экспериментами до и после, где частота ошибок не увеличивалась при увеличении продолжительности с 16 до 36 месяцев.
Это не значит, что использование элементов управления плохо. Это совсем наоборот.
Он просто показывает, как добавление контроля влияет на прогнозы.
Это тот случай, когда в контрольной группе есть большие различия.
Этот вывод особенно важен для веб-сайтов, на которых в прошлом году наблюдались аномальные колебания трафика (критическая техническая ошибка, пандемия COVID и т. д.).

Как оценить прогноз причинно-следственной связи?
Теперь в библиотеке CausalImpact нет встроенной оценки точности. Таким образом, это должно быть выведено иначе.
Можно посмотреть, как другие модели машинного обучения оценивают точность своих прогнозов, и понять, что сумма ошибок квадратов (SSE) является очень распространенной метрикой.
Сумма квадратов ошибок или остаточная сумма квадратов вычисляет сумму всех (n) различий между ожиданиями (yi) и фактическими результатами (f(xi)), возведённых в квадрат. 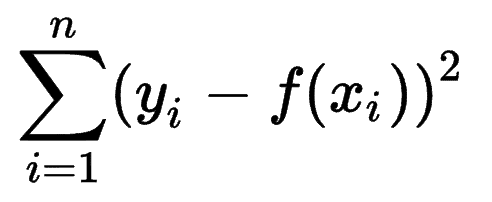
Чем ниже SSE, тем лучше результат.
Проблема в том, что эксперименты с SEO-трафиком до публикации не дают реальных результатов.
Хотя никаких изменений на месте не производилось, некоторые изменения могли произойти вне вашего контроля (например, обновление алгоритма Google, новый конкурент и т. д.). SEO-трафик также не зависит от фиксированного числа, а постепенно увеличивается и уменьшается.
SEO-специалисты могут задаться вопросом, как решить эту проблему.
Представляем поддельные вариации
Чтобы быть уверенным в размере вариации, вызванной событием, экспериментатор может ввести фиксированные вариации в разные моменты времени и посмотреть, успешно ли CausalImpact оценил изменение.
Более того, SEO-эксперт может повторить процесс для разных тестовых и контрольных групп.
Используя Python, к данным были введены фиксированные вариации в разные даты вмешательства для постпериода.
Затем была оценена сумма квадратов ошибок между вариацией, о которой сообщает CausalImpact, и введенной вариацией.
Идея звучит так:
- Выберите тест и контрольные данные.
- Ввести поддельные вмешательства в реальные данные в разные даты (например, увеличение на 5%).
- Сравните оценки CausalImpact с каждым из введенных вариантов.
- Вычислите сумму ошибок квадратов (SSE).
- Повторите шаг 1 с несколькими элементами управления.
- Выберите элемент управления с наименьшим значением SSE для реальных экспериментов.
Методология
С помощью приведенной ниже методологии я создал таблицу, которую мог использовать для определения того, какой элемент управления имел наилучшую и наихудшую частоту ошибок в разные моменты времени.
Сначала выберите тестовые и контрольные данные и введите вариации от -50% до 50%.
Затем запустите CausalImpact (CI) и вычтите вариации, о которых сообщает CI, из той вариации, которую вы фактически ввели.
После этого вычислите квадраты этих разностей и суммируйте все значения вместе.
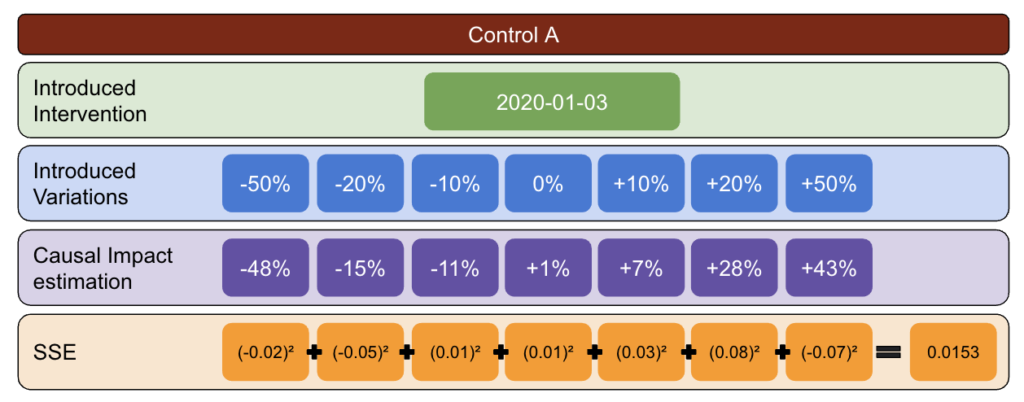
Затем повторите тот же процесс в разные даты, чтобы уменьшить риск систематической ошибки, вызванной реальной вариацией на конкретную дату.
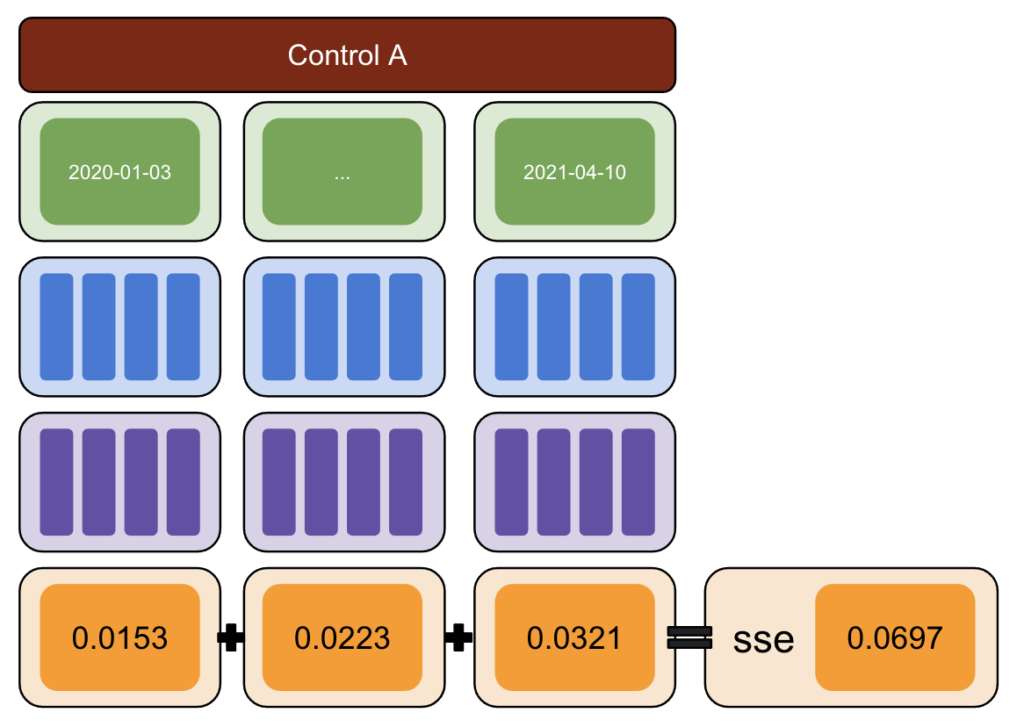
Снова повторите с несколькими контрольными группами.
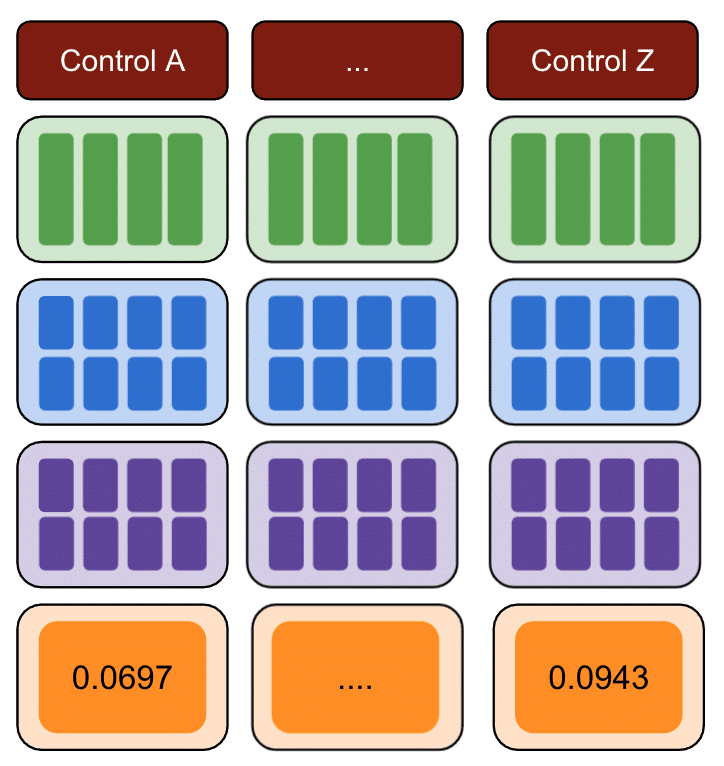
Наконец, контрольная группа с наименьшей суммой квадратов ошибок является лучшей контрольной группой для ваших тестовых данных.
Если вы повторите каждый из шагов для каждого из ваших тестовых данных, результат будет другим.
В результирующей таблице каждая строка представляет контрольную группу, каждый столбец представляет тестовую группу. Данные внутри - это SSE.
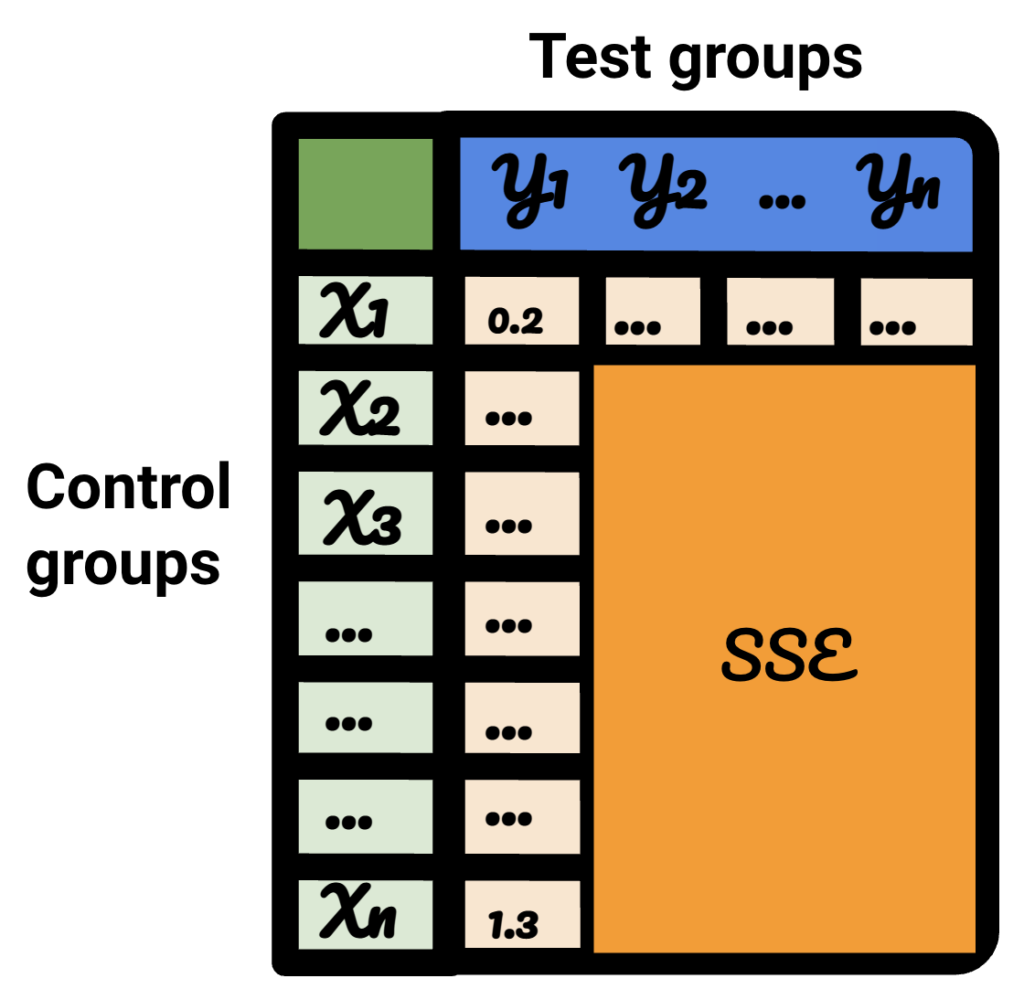
Отсортировав эту таблицу, я теперь уверен, что для каждой из тестовых групп я могу выбрать для нее лучшую контрольную группу.
Должны ли мы использовать контрольные группы или нет?
Фактические данные показывают, что использование контрольных групп помогает получить более точные оценки, чем просто предварительная обработка.
Однако это верно только в том случае, если мы выберем правильную контрольную группу.
Как долго должен быть период оценки?
Ответ на этот вопрос зависит от элементов управления, которые мы выбираем.
Если не использовать контроль, 16 месяцев до эксперимента кажется достаточным.
При использовании контроля использование только 16 месяцев может привести к большому количеству ошибок. Использование 3 лет помогает снизить риск неправильного толкования.
Должны ли мы использовать 1 элемент управления или несколько элементов управления?
Ответ на этот вопрос зависит от тестовых данных.
Очень стабильные тестовые данные могут хорошо работать по сравнению с несколькими контролями. В данном случае это хорошо, потому что использование большого количества элементов управления делает модель менее подверженной влиянию неожиданных колебаний одного из элементов управления.
В других наборах данных использование нескольких элементов управления может сделать модель в 10–20 раз менее точной, чем использование одного элемента.
Интересная работа в SEO сообществе
CausalImpact — не единственная библиотека, которую можно использовать для SEO-тестирования, и описанная выше методология не является единственным решением для проверки ее точности.
Чтобы узнать об альтернативных решениях, прочитайте некоторые из невероятных статей, которыми поделились люди в сообществе SEO.
Во-первых, Андреа Вольпини написала интересную статью об измерении эффективности SEO с помощью анализа причинно-следственных связей.
Затем Даниэль Эредиа рассказал о пакете Facebook Prophet для прогнозирования SEO-трафика с помощью Prophet и Python.
Хотя библиотека Prophet больше подходит для прогнозирования, чем для экспериментов, стоит изучить различные библиотеки, чтобы получить четкое представление о мире прогнозов.
Наконец, меня очень порадовала презентация Сэнди Ли на Брайтонском SEO, где он поделился своими мыслями о науке о данных для SEO-тестирования и рассказал о некоторых подводных камнях SEO-тестирования.
Что следует учитывать при проведении SEO-экспериментов
- Сторонние инструменты сплит-тестирования SEO хороши, но также могут быть неточными. Будьте внимательны при выборе решения.
- Хотя я писал об этом в прошлом, вы не можете проводить эксперименты по сплит-тестированию SEO с Google Tag Manager, кроме как на стороне сервера. Лучший способ — развертывание через CDN.
- Будьте смелее при тестировании. Небольшие изменения обычно не улавливаются CausalImpact.
- SEO-тестирование не всегда должно быть вашим первым выбором.
- Существуют альтернативы тестированию небольших изменений, таких как теги заголовков. A/B-тесты Google Ads или A/B-тесты на платформе. Настоящие A/B-тесты более точны, чем сплит-тесты SEO, и обычно дают больше информации о качестве ваших заголовков.
Воспроизводимые результаты
В этом уроке я хотел сосредоточиться на том, как можно повысить точность SEO-экспериментов, не зная, как программировать. Кроме того, источник данных может быть разным, и каждый сайт индивидуален.
Следовательно, код Python, который я использовал для создания этого контента, не был частью этой статьи.
Однако с логикой вы можете воспроизвести приведенные выше эксперименты.
Вывод
Если бы у вас был только один вывод из этой статьи, это был бы тот факт, что анализ CausalImpact может быть очень точным, но всегда может быть далеким.
SEO-специалистам, желающим использовать этот пакет, очень важно понимать, с чем они имеют дело. Результатом моего собственного путешествия стало то, что я бы не стал доверять CausalImpact, не проверив сначала точность модели на входных данных.