
Сканирование через Сканирование теперь доступно
Опубликовано: 2019-11-21Наша функция «Сканирование поверх сканирования» позволяет сравнивать два разных сканирования и отображать эволюцию сканирования .
В 2016 году он основывался на нашем предыдущем выпуске «Тенденции», который давал вам возможность определять глобальные тенденции между разными сканированиями. Теперь вы можете получить доступ к полному обзору ваших улучшений SEO и выделить различия между сканированиями по заданной теме . Обновление Crawl over Crawl включает новые типы графиков для чтения ваших данных.
В 2019 году функция «Сканирование поверх сканирования» была улучшена. Теперь вы можете изучить:
- Две версии веб-сайта, которые содержат одинаковые или похожие страницы, например, рабочий и тестовый веб-сайты или версии для мобильных устройств и настольных компьютеров .
- Один и тот же веб-сайт в два разных момента времени, например, до и после изменения на сайте.
Сравнение двух версий веб-сайта
Чтобы сравнить два веб-сайта, OnCrawl просматривает начальный URL-адрес, который вы предоставляете для двух разных обходов, чтобы определить различия в веб-адресах разных сайтов. Предполагается, что эти две версии веб-сайта содержат одинаковый (или почти одинаковый) контент. Это означает, что большинство слагов URL-адресов в двух доменах, папках или поддоменах, которые вы сравниваете, должны быть одинаковыми .
Вот несколько примеров сайтов, которые можно сравнить:
| Пример использования | Сканирование 1 – начальный URL | Сканирование 2 — Начальный URL |
|---|---|---|
| Производственные и промежуточные сайты | https://www.example.com | http://staging.example.com/site/ |
| Десктопные и мобильные сайты | https://www.example.com | https://m.example.com |
| Региональные версии | https://www.example.com/ru-ru/ | https://www.example.com/en-ca/ |
| Региональные версии | https://www.example.com | https://www.example.co.uk |
Для сложных различий между начальными URL-адресами автоматического сопоставления может быть недостаточно. В этом случае при настройке обхода вы увидите сообщение об ошибке, в котором вас попросят связаться с OnCrawl через чат. Мы можем переопределить автоматическое сопоставление, чтобы адаптироваться к вашему конкретному случаю.
Сравнение одного веб-сайта в два разных момента времени
Чтобы сравнить один веб-сайт в два разных момента времени, например, до и после улучшения или серьезного изменения на веб-сайте, вам необходимо предоставить:
- Те же стартовые URL
- Та же широта сканирования (те же правила исследования поддоменов)
Как настроить сканирование поверх сканирования
Вы можете запустить сканирование поверх сканирования между двумя существующими обходами или запросить сравнение с предыдущим обходом при создании нового. Дополнительную информацию о создании Crawl over Crawls можно найти в базе знаний OnCrawl.
Как читать ползание по ползанию солнечных лучей
Вы читаете солнечные лучи, как традиционный пирог. Эти графики очень полезны для отслеживания эволюции веб-сайта , сканирования за сканированием или для проверки различий между двумя версиями веб-сайта (например, между активной версией и во время реструктуризации).
Эта многоуровневая круговая диаграмма позволяет сравнить два сканирования в зависимости от заданной темы:
- Первый уровень и внутренний круг: показаны страницы, относящиеся к первому сканированию (более старому сканированию).
- Второй уровень и внешний круг: показаны страницы второго сканирования (более нового), которые соответствуют каждому сегменту внутреннего круга.
Таким образом, вы можете легко найти, например, индексируемые страницы в первом сканировании, которых уже нет во втором, и наоборот.
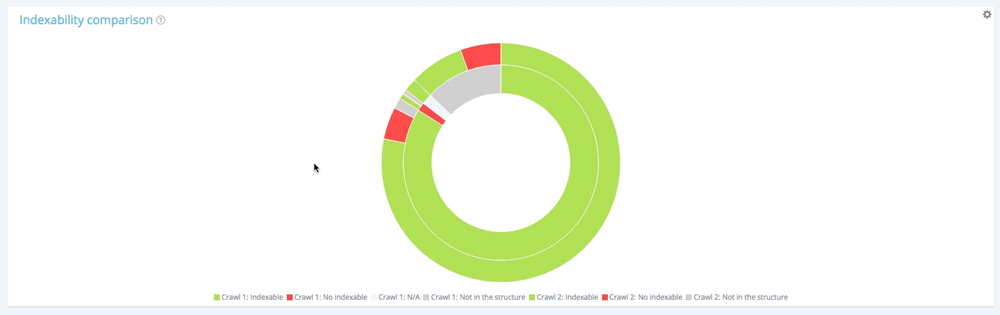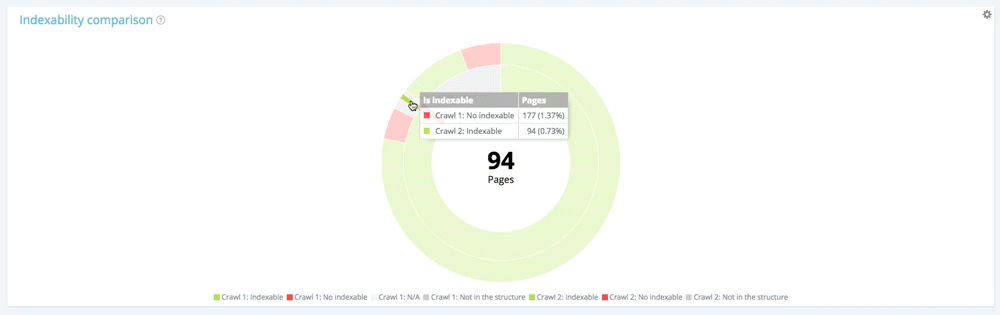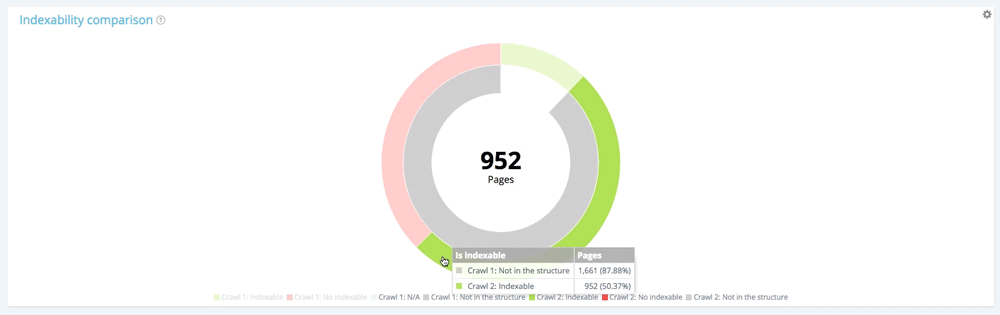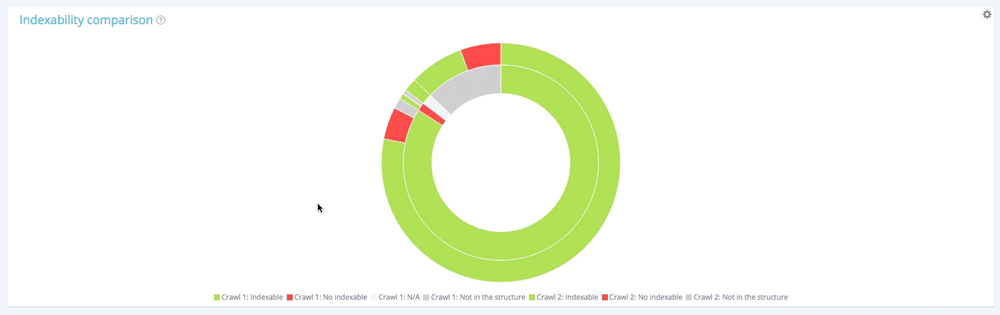
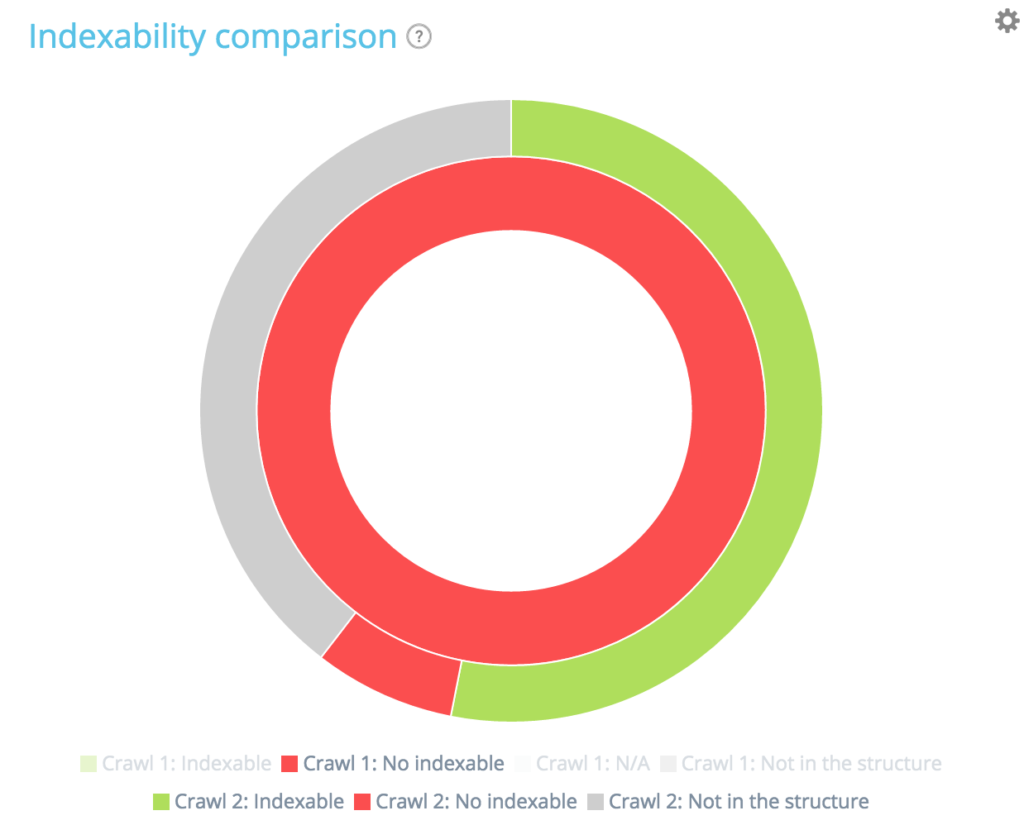
На этой диаграмме внутренний круг показывает перераспределение страниц с первой точки зрения сканирования (более старой). Вы можете видеть, что есть индексируемые страницы, нет индексируемых страниц и страницы, которые не были в первом сканировании, но появляются во втором (серая секция).
Затем для каждого раздела внутреннего круга вы можете увидеть перераспределение страниц данного раздела во втором сканировании. Внутренний серый раздел означает, что эти страницы не существовали при первом сканировании, но появляются при втором (внешний зеленый и красный раздел принадлежит внутреннему серому).

Серые разделы означают, что страницы являются новыми или нет в структуре в зависимости от того, к какому кругу они принадлежат.
Нажав на легенду, вы можете решить, какие данные вы хотите отобразить или на каких сосредоточить внимание. Crawl 2 предлагает более глобальный обзор.
Давайте посмотрим на внутренний круг.
Распределение страниц при первом сканировании в зависимости от их индексируемости
 Первый обход содержит 10 854 индексируемых страниц и 177 неиндексируемых страниц. 1 661 страница была найдена только при втором сканировании.
Первый обход содержит 10 854 индексируемых страниц и 177 неиндексируемых страниц. 1 661 страница была найдена только при втором сканировании.
Теперь взгляните на внешний круг. Для каждого сегмента первого круга находим распределение этих страниц при втором сканировании.
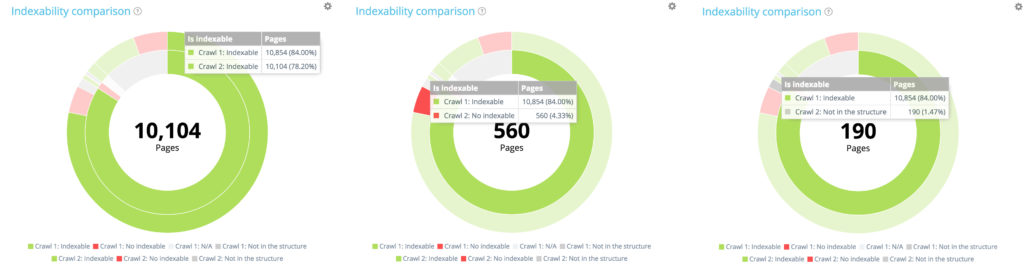
Из 10 854 индексируемых страниц при первом сканировании только 10 104 остаются индексируемыми при втором. 560 теперь не индексируются, а 190 страниц больше не были частью доступного для сканирования веб-сайта во время второго сканирования.
Давайте сосредоточимся на небольшом разделе: неиндексируемые страницы при первом сканировании.
Используя легенду, чтобы скрыть индексируемые страницы и страницы, не входящие в структуру веб-сайта во время первого обхода, мы можем сосредоточиться только на неиндексируемых страницах при первом обходе.
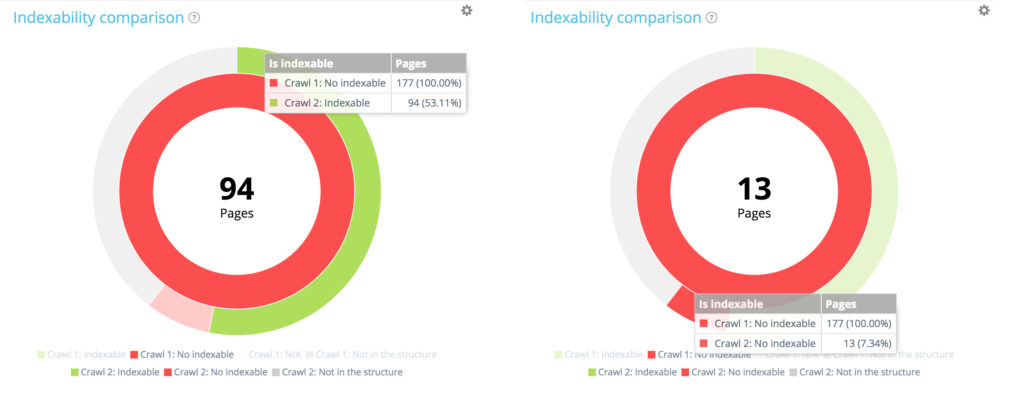 Среди 177 неиндексируемых страниц, полученных при первом сканировании, 94 стали индексироваться при втором, а 13 остаются индексируемыми.
Среди 177 неиндексируемых страниц, полученных при первом сканировании, 94 стали индексироваться при втором, а 13 остаются индексируемыми.
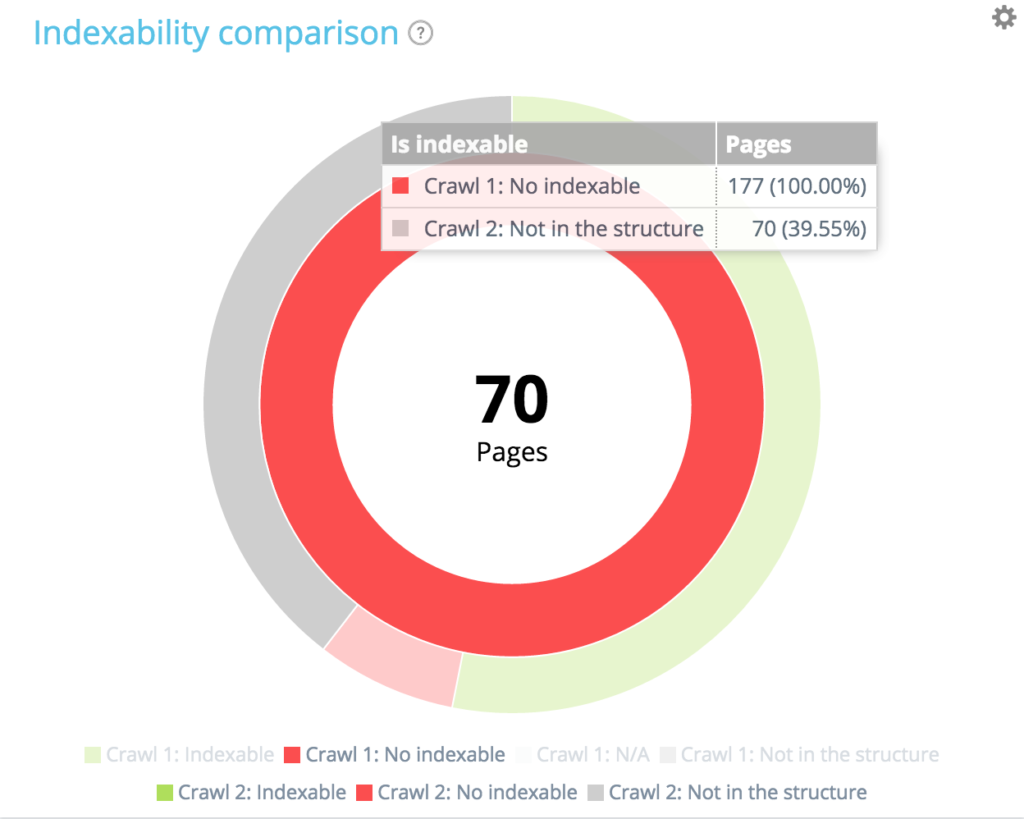
Из 177 неиндексируемых страниц при первом сканировании 70 больше не присутствуют при втором сканировании. 94 + 13 + 70 = 177. Находим ожидаемую разбивку 177 неиндексируемых страниц с первого сканирования.
Сосредоточьтесь на новых страницах: страницы, найденные только при втором сканировании
Теперь воспользуемся легендой, чтобы скрыть как индексируемые, так и неиндексируемые страницы при первом обходе и показать только те страницы, которые не были частью структуры веб-сайта во время этого обхода. Это позволяет вам видеть статус новых страниц с точки зрения индексации.
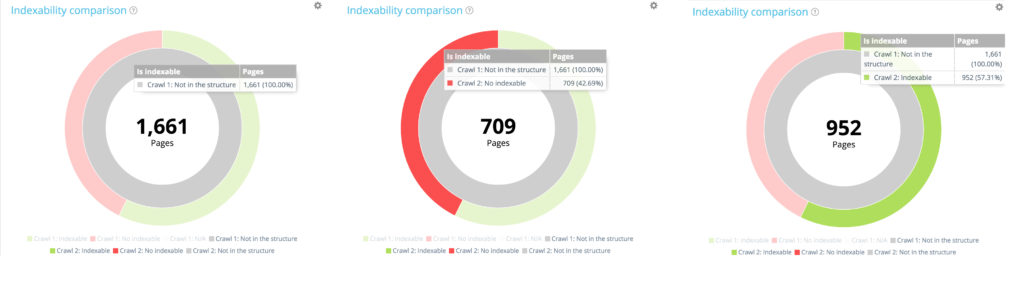
Всего новых страниц: 1 661 страница.
Из 1 661 вновь созданной страницы 709 не индексируются.
Из 1661 вновь созданных страниц 952 индексируются.
Сводка: все страницы со второго сканирования
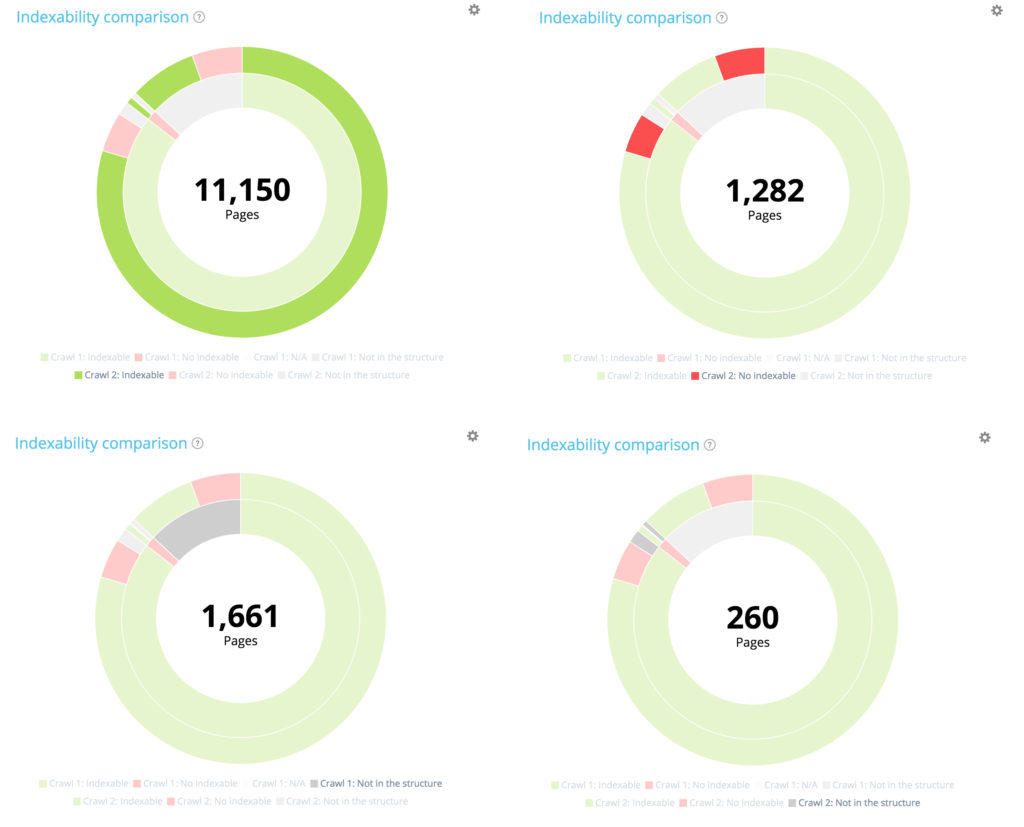 10 104 страницы были проиндексированы при первом сканировании. 11 150 теперь индексируются во втором. 177 страниц не индексировались при первом сканировании, но 1 282 теперь не индексируются при втором.
10 104 страницы были проиндексированы при первом сканировании. 11 150 теперь индексируются во втором. 177 страниц не индексировались при первом сканировании, но 1 282 теперь не индексируются при втором.
Создана 1661 страница, из структуры удалено 260 страниц.
Crawl over Crawl: доступные данные
Эта новая функция разделена по бизнес-опыту и между следующими вкладками:
- Структура
- Внутренняя перелинковка
- Содержание
- Коды состояния
- Спектакль
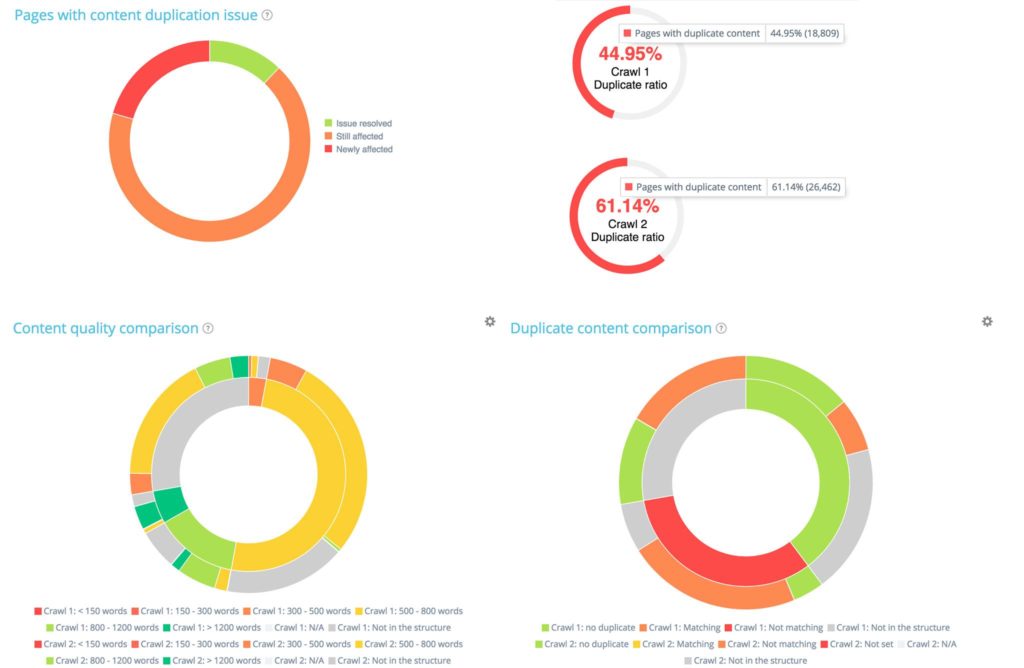
Например, в разделе «Контент» вы обнаружите сильное внимание к различиям в дублировании между двумя сканированиями:
Кроме того, вы можете проанализировать, как глубина вашей страницы отличается между двумя сканированиями. На графике ниже вы можете увидеть разницу в глубине:
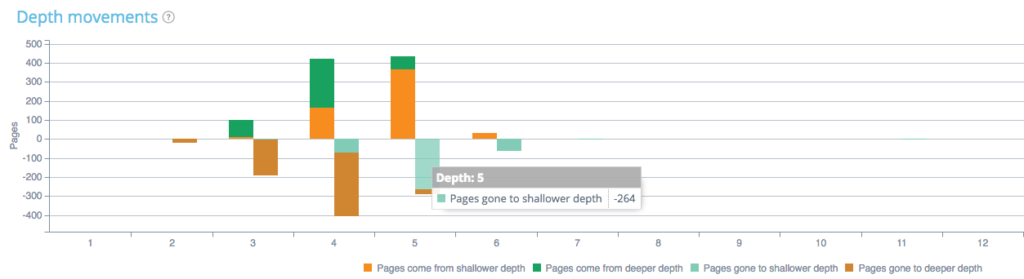
Например, если мы посмотрим на глубину 5, мы увидим страницы, которые ушли на меньшую или большую глубину, или страницы, которые пришли с меньшей или большей глубины между сканированием 1 и 2. Здесь 264 страницы, которые были на сканировании 1 и на глубине 5. ушли на меньшую глубину (глубина 4, 3 или 2).
Это просто обзор того, что есть в наличии. Наш обозреватель данных также позволяет изучить более 700 метрик для сравнения сканирования.