
Как автоматизировать моделирование маркетингового комплекса с помощью электронной таблицы данных MMM
Опубликовано: 2022-06-16Моделирование комплекса маркетинга или МММ переживает возрождение спустя более 60 лет с тех пор, как оно стало широко использоваться. В отличие от большинства маркетинговых методов атрибуции, МММ не требует данных на уровне пользователя, вместо того, чтобы моделировать, какие каналы заслуживают признания продаж, путем статистического сопоставления всплесков и спадов расходов с действиями и событиями в ваших маркетинговых каналах. Переходя от простой линейной регрессии к таким методам, как гребенчатая регрессия или байесовские методы, моделирование комплекса маркетинга заново изобретается для современной эпохи.

Хотите узнать больше о МММ?
Ознакомьтесь с плюсами и минусами моделирования маркетингового комплекса и моделирования атрибуции.
Однако есть серьезные препятствия, которые необходимо преодолеть. По данным Meta/Facebook, создание модели может занять от 3 до 6 месяцев, которые работают над своей библиотекой MMM с открытым исходным кодом с октября 2021 года. По его оценкам, около 50% времени тратится на сбор и очистку данных перед началом моделирования. . Это совпадает с моим опытом работы в Recast, а ранее с Гарри, а также с результатами исследования CrowdFlower, которое показало, что 60% времени, затрачиваемого на науку о данных, тратится на очистку и организацию данных.
Перемотка вперед >>
- Очистка данных
- Построение модели комплекса маркетинга
- Автоматизированное моделирование
Очистка данных — это 60% работы, а как сделать 0%
Чтобы построить точную модель, вам нужны данные в определенном формате. Подготовка данных требует времени, поэтому проекты МММ занимают больше времени, чем нужно. Это делает MMM специализированным и дорогостоящим навыком, поэтому большинство компаний могут создавать только одну-две модели в год. Если вы можете автоматизировать процесс с помощью такого инструмента, как Supermetrics, для создания потока данных MMM, вы можете регулярно обновлять свою модель, что позволит вам лучше оптимизировать свой маркетинговый бюджет.
Табличный формат данных
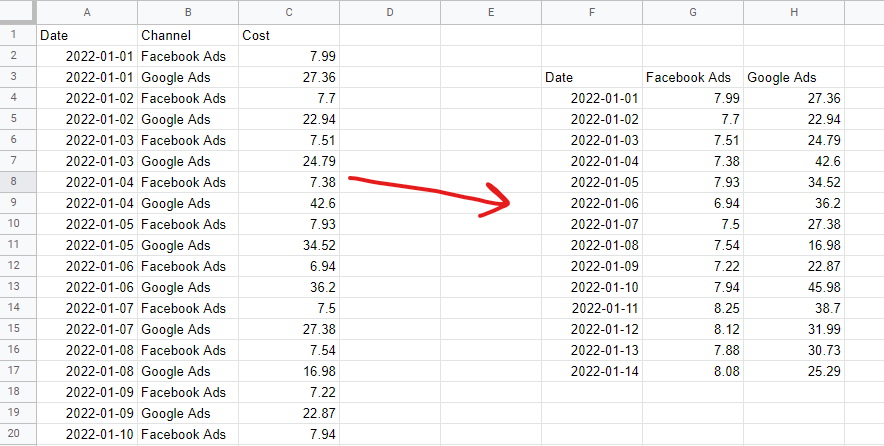
Чтобы построить модель комплекса маркетинга, вы должны представить свои данные в несложенном табличном формате. Это означает одну строку на наблюдение — обычно дни или недели — и один столбец на «функция» модели — обычно расходы на медиа и органические или внешние переменные. Категориальные данные — например, список национальных праздников — необходимо закодировать в фиктивные переменные — 1, если это праздник, и 0, если нет.
Объединенные источники данных
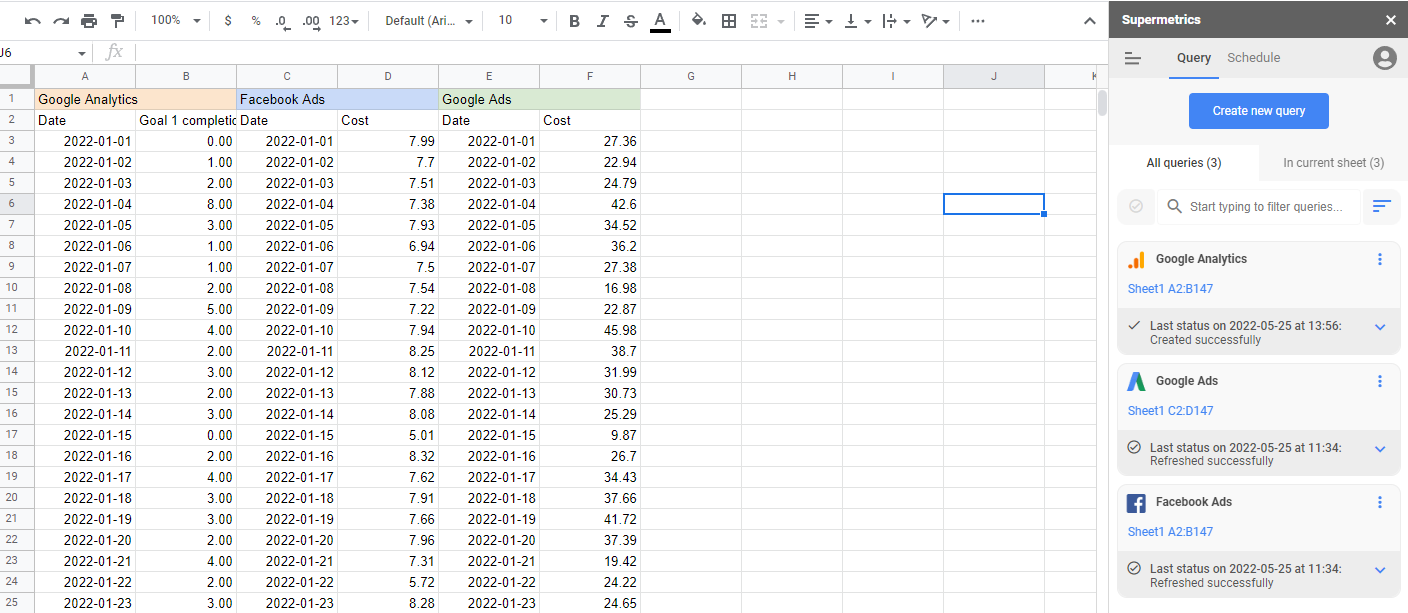
Чтобы построить модель маркетинговой атрибуции, вам необходимо собрать все маркетинговые данные в одном месте. Это то, что Supermetrics обрабатывает для вас автоматически. Благодаря более чем 90 соединителям все ваши маркетинговые расходы, события и действия можно собрать в одном месте, управлять ими по мере необходимости, а затем экспортировать в нужный формат и место.
Экспорт в Google Таблицы
Если у вас есть учетная запись Supermetrics, вам просто нужно перейти в «Расширения»> «Дополнения»> «Получить надстройки» и установить их. Он попросит вас пройти аутентификацию с помощью вашей учетной записи Google, связанной с вашей учетной записью Supermetrics, а затем в меню расширений появится боковая панель.
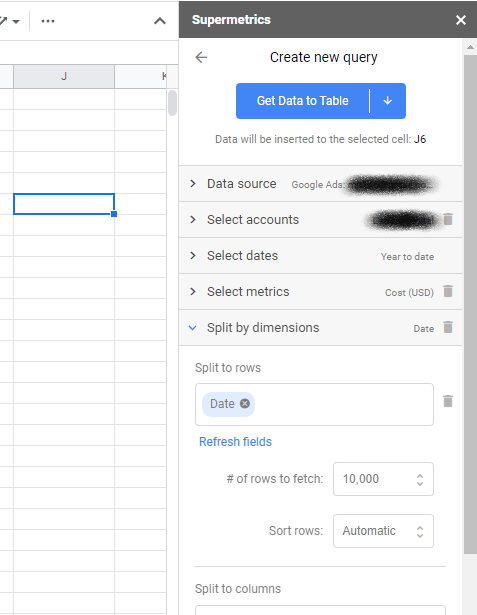
Как только это будет сделано, вы можете запустить боковую панель — если она еще не запущена — и щелкнуть, чтобы создать новый запрос. Запросы — это то, как вы решаете, какие данные извлекать и из каких учетных записей. Когда вы выбираете одну из рекламных платформ, таких как Facebook Ads и Google Ads, вам будет предложено пройти аутентификацию и предоставить доступ к Supermetrics.
Затем вы выберете учетную запись, из которой хотите получить данные, и диапазон дат. Наконец, выберите свои показатели — обычно стоимость или показы для МММ — и размеры — выберите только дату, чтобы она соответствовала табличному формату.
При желании вы можете добавить фильтр, если вам нужно выбрать определенный набор кампаний. Например, если у вас есть «YT:» в названии ваших кампаний на YouTube, вы можете выбрать их как отдельный источник, а затем продублировать запрос и отфильтровать для каждого из ваших других типов кампаний.
Когда вы закончите свой запрос, убедитесь, что вы выбрали ячейку, в которую вы хотите вставить данные, и нажмите «Получить данные в таблицу». Если вы допустили ошибку, просто продублируйте запрос и поместите его в нужное место, удалив другой.
Я считаю полезным помещать название каждого источника в ячейку над таблицей, чтобы знать, откуда я извлекаю данные. Результат должен выглядеть так:
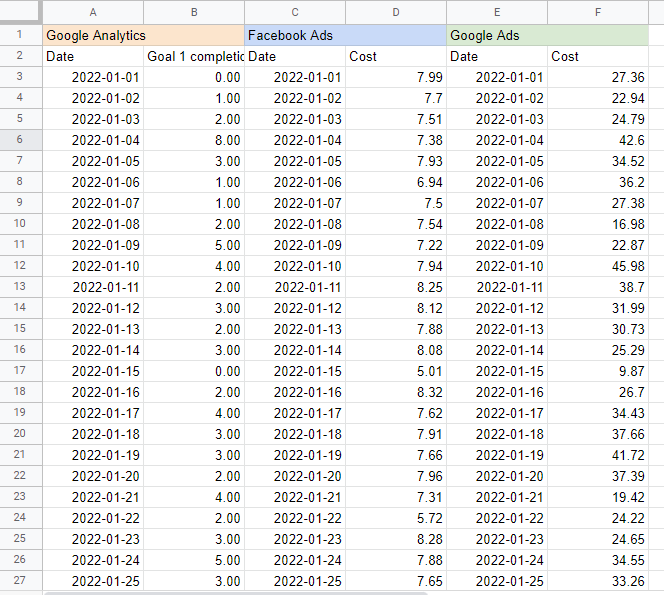
Построение модели комплекса маркетинга в Google Sheets
Моделирование маркетингового комплекса — мощный инструмент атрибуции, но на самом деле он более доступен, чем вы думаете. Большинство практиков используют пользовательский код и расширенную статистику, но вы можете сделать основы за полдня, используя только Excel или Google Sheets.
Линейная регрессия с функцией ЛИНЕЙН
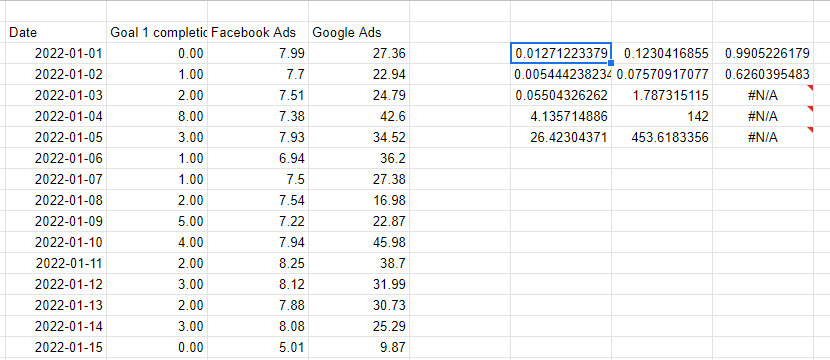
И Excel, и Google Таблицы предоставляют простой метод, функцию ЛИНЕЙН, для выполнения линейной регрессии с несколькими переменными. ЛИНЕЙН работает, передавая столбец, который мы пытаемся предсказать, затем несколько столбцов, представляющих переменные, которые мы используем для предсказания. Последние два параметра — нужна ли нам линия пересечения — обычно 1 означает «да» — и хотим ли мы, чтобы выходные данные были подробными — содержащими всю статистику для модели, а не только коэффициенты.
Обратите внимание, что переменные X, которые мы используем для прогнозирования, должны быть последовательными, поэтому я просто сослался на столбцы слева, чтобы повторять значения рядом друг с другом.
Перепрогнозирование с использованием коэффициентов модели
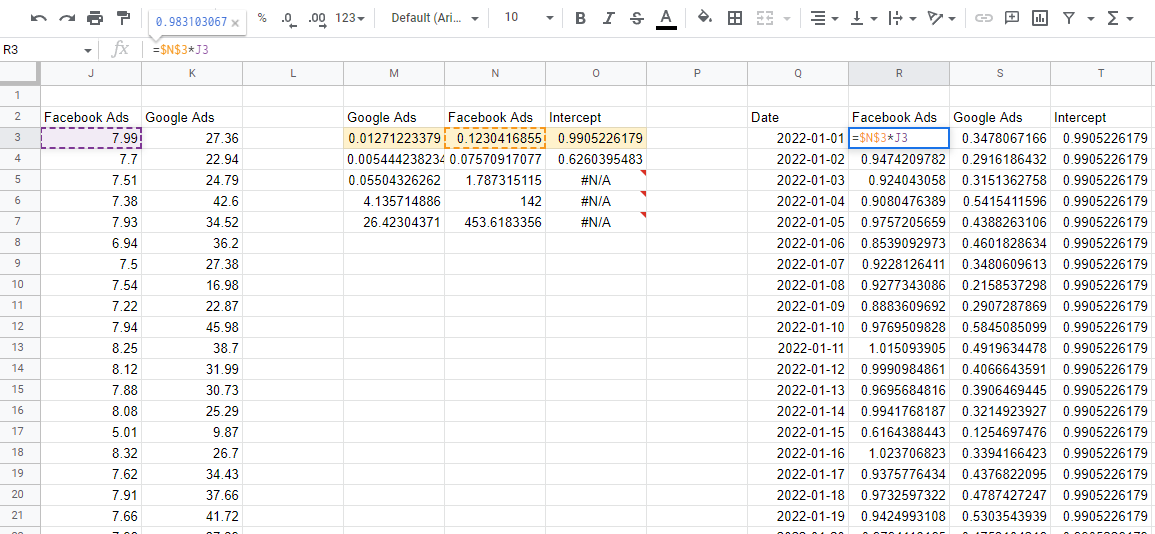
Теперь, когда у нас есть модель, нам нужно использовать коэффициенты для оценки влияния каждого канала. Если мы возьмем верхнюю строку чисел, это коэффициенты, и умножим их на соответствующие входные значения из наших данных, мы получим вклад каждой переменной в общий объем продаж.

Одна вещь, на которую следует обратить внимание, это то, что ЛИНЕЙН выводит коэффициенты в обратном порядке. Первое значение, начиная слева, всегда является последней введенной вами переменной, затем они продолжаются в обратном порядке, пока вы не дойдете до последнего значения, которое является точкой пересечения. Если вы сложите все эти значения вклада, это даст вам прогнозы из модели, которые вы можете сравнить с фактическими данными, чтобы убедиться, что модель точна.
Проверка метрик точности модели
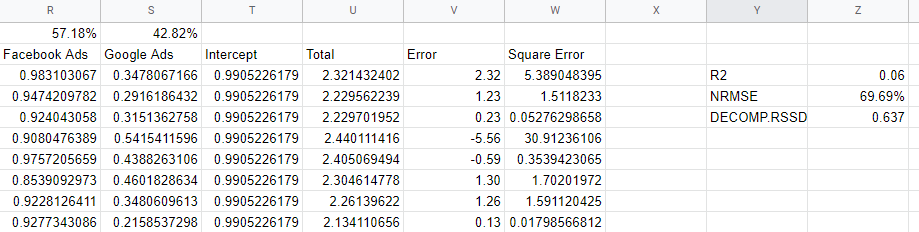
Как узнать, надежна ли наша модель? Модель должна хорошо соответствовать данным, она должна быть способна предсказывать новые данные, которых она не видела, и должна иметь правдоподобные коэффициенты. Несколько показателей проверки отражают эти требования.
Проверьте функции в шаблоне, чтобы узнать, как рассчитать эти показатели.
Чтобы использовать шаблон, перейдите в «Файл» > «Создать копию» > «Запустить Supermetrics» из списка надстроек > продублируйте этот файл для другой учетной записи, а затем перейдите к выбору учетной записи.
R2 или R-квадрат — это мера того, какая часть дисперсии данных объясняется моделью, и находится в диапазоне от 0 до 1: хорошая модель должна быть выше 0,7, но все, приближающееся к 1, вероятно, подозрительно. Близость к 0, как и в нашей модели, является признаком того, что мы не включаем достаточное количество переменных в нашу модель и должны учитывать такие вещи, как органические каналы, праздники и макроэкономические факторы.
«Нормализованная среднеквадратическая ошибка» — это то, как мы измеряем точность, и она определяется путем определения разницы между предсказаниями модели и фактическими значениями, а затем нахождения корня квадрата значений в процентах от фактического значения. В идеале это делается на основе невидимых данных — группы удержания, — но в нашей простой модели мы просто рассчитали ошибку по данным в выборке.
Процедура извлечения корня и возведения в квадрат обрабатывает отрицательные значения для нас и наказывает действительно большие ошибки. Это можно интерпретировать как процент отклонений модели в любой день, так что это полезная, интуитивно понятная мера.
Правдоподобие — это большая тема, и обычно за аналитиком остается последнее слово. Однако полезно иметь метрику, которую можно рассчитать программно, чтобы иметь представление о том, насколько модель отличается с точки зрения ее результатов от вашего текущего набора каналов.
Decomp RSSD — это метрика, изобретенная командой Робина в Facebook, которая измеряет разницу между вашим текущим распределением расходов и тем, какие каналы принесли наибольший эффект, как и предсказывает модель. Если бы модель говорила, что ваш самый крупный канал на самом деле не обеспечивает столько продаж, тогда у вас был бы высокий RSSD декомпрессии.
В нашем случае у нас высокое значение 0,6, потому что модель слишком много доверяет Facebook, что представляет собой небольшую сумму расходов.
Доставка MMM автоматически и в масштабе
Моделирование маркетингового комплекса — одно из тех действий, которые можно масштабировать бесконечно. Вы можете получить приличные результаты за полдня с помощью Excel или Google Sheets и Supermetrics, как мы сделали здесь, но вы также можете потратить 3 месяца с командой из 6 специалистов по данным, написав собственный код с использованием сложных алгоритмов, таких как байесовский MCMC, чтобы создать что-то большее. надежный и точный.
Существует контрольный список функций, которые входят в состав расширенной модели, некоторые из которых требуют дополнительных знаний статистики. Добавьте к этому несколько дорогостоящих инженеров по обработке данных для построения конвейеров данных, если вы не используете Supermetrics для автоматизации этой части.
Хотите узнать больше об автоматизации моделирования микса?
Ознакомьтесь с нашей статьей о моделировании автоматизированного комплекса маркетинга.
Предупреждаю: МММ — это сложно. Вы можете потратить 500, 5000 или 50 тысяч долларов на моделирование и увидеть совершенно разные результаты по точности и надежности. Что действительно имеет значение, так это альтернативные издержки неправильного распределения маркетинговых расходов.
Если вы тратите 10 тысяч долларов в месяц, то модель электронных таблиц раз в квартал будет вполне приемлемой. Однако, если вы тратите более 100 000 долларов в месяц, даже скидка на 5% может стоить вам десятки тысяч долларов в год.
Не знаете, какая модель доступа к данным вам нужна для вашей ленты МММ?
Ознакомьтесь с нашей статьей, чтобы выбрать подходящий для вашего бизнеса
Именно тогда имеет смысл инвестировать в более продвинутое моделирование. Проведите анализ сборки и покупки, чтобы выбрать между индивидуальным решением, основанным на библиотеках с открытым исходным кодом, таким как Robyn от Facebook, или передовым программным обеспечением для атрибуции, таким как то, что мы создали в Recast.
Об авторе
Майкл Камински — дипломированный эконометрист с опытом работы в области здравоохранения и экономики окружающей среды. Ранее он создал команду маркетинговых исследований в бренде мужской косметики Harry's, а затем стал соучредителем Recast.

Улучшите эффективность вашего бизнеса
объединяя маркетинг и бизнес-аналитику в вашем хранилище данных